| БрМЭЦМі: |
БОЮФЮЊФњНщЩмЬсЩ§адФмЕФFlink
SQLЭЦМіаДЗЈЁЂХфжУМАКЏЪ§ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкАЂРядЦЃЌгЩAliceБрМЁЂЭЦМіЁЃ
|
|
Group AggregateгХЛЏММЧЩ
ПЊЦєMicroBatchЛђMiniBatchЃЈЬсЩ§ЭЬЭТЃЉ
MicroBatchКЭMiniBatchЖМЪЧЮЂХњДІРэЃЌжЛЪЧЮЂХњЕФДЅЗЂЛњжЦТдгаВЛЭЌЁЃдРэЭЌбљЪЧЛКДцвЛЖЈЕФЪ§ОнКѓдйДЅЗЂДІРэЃЌвдМѕЩйЖдStateЕФЗУЮЪЃЌДгЖјЬсЩ§ЭЬЭТВЂМѕЩйЪ§ОнЕФЪфГіСПЁЃ
MiniBatchжївЊвРППдкУПИіTaskЩЯзЂВсЕФTimerЯпГЬРДДЅЗЂЮЂХњЃЌашвЊЯћКФвЛЖЈЕФЯпГЬЕїЖШадФмЁЃMicroBatchЪЧMiniBatchЕФЩ§МЖАцЃЌжївЊЛљгкЪТМўЯћЯЂРДДЅЗЂЮЂХњЃЌЪТМўЯћЯЂЛсАДФњжИЖЈЕФЪБМфМфИєдкдДЭЗВхШыЁЃMicroBatchдкдЊЫиађСаЛЏаЇТЪЁЂЗДбЙБэЯжЁЂЭЬЭТКЭбгГйадФмЩЯЖМвЊгХгкMiniBatchЁЃ
ЪЪгУГЁОА
ЮЂХњДІРэЭЈЙ§діМгбгГйЛЛШЁИпЭЬЭТЃЌШчЙћФњгаГЌЕЭбгГйЕФвЊЧѓЃЌВЛНЈвщПЊЦєЮЂХњДІРэЁЃЭЈГЃЖдгкОлКЯЕФГЁОАЃЌЮЂХњДІРэПЩвдЯджјЕФЬсЩ§ЯЕЭГадФмЃЌНЈвщПЊЦєЁЃ
ЫЕУї MicroBatchФЃЪНвВФмНтОіСНМЖОлКЯЪ§ОнЖЖЖЏЮЪЬтЁЃ
ПЊЦєЗНЪН
MicroBatchКЭMiniBatchФЌШЯЙиБеЃЌПЊЦєЗНЪНШчЯТЁЃ
# 3.2МАвдЩЯАцБОПЊЦєWindow miniBatchЗНЗЈЃЈ3.2МАвдЩЯАцБОФЌШЯВЛПЊЦєWindow
miniBatchЃЉЁЃ
sql.exec.mini-batch.window.enabled=true
# ХњСПЪфГіЕФМфИєЪБМфЃЌдкЪЙгУmicroBatchВпТдЪБЃЌашвЊдіМгИУХфжУЃЌЧвНЈвщКЭblink.miniBatch.allowLatencyMsБЃГжвЛжТЁЃ
blink.microBatch.allowLatencyMs=5000
# дкЪЙгУmicroBatchЪБЃЌашвЊБЃСєвдЯТСНИіminiBatchХфжУЁЃ
blink.miniBatch.allowLatencyMs=5000
# ЗРжЙOOMЩшжУУПИіХњДЮзюЖрЛКДцЪ§ОнЕФЬѕЪ§ЁЃ
blink.miniBatch.size=20000 |
ПЊЦєLocalGlobalЃЈНтОіГЃМћЪ§ОнШШЕуЮЪЬтЃЉ
LocalGlobalгХЛЏНЋдЯШЕФAggregateЗжГЩLocal+GlobalСННзЖЮОлКЯЃЌМДMapReduceФЃаЭжаЕФCombine+ReduceДІРэФЃЪНЁЃЕквЛНзЖЮдкЩЯгЮНкЕуБОЕидмвЛХњЪ§ОнНјааОлКЯЃЈlocalAggЃЉЃЌВЂЪфГіетДЮЮЂХњЕФдіСПжЕЃЈAccumulatorЃЉЁЃЕкЖўНзЖЮдйНЋЪеЕНЕФAccumulatorКЯВЂЃЈMergeЃЉЃЌЕУЕНзюжеЕФНсЙћЃЈGlobalAggЃЉЁЃ
LocalGlobalБОжЪЩЯФмЙЛППLocalAggЕФОлКЯЩИГ§ВПЗжЧуаБЪ§ОнЃЌДгЖјНЕЕЭGlobalAggЕФШШЕуЃЌЬсЩ§адФмЁЃФњПЩвдНсКЯЯТЭМРэНтLocalGlobalШчКЮНтОіЪ§ОнЧуаБЕФЮЪЬтЁЃ
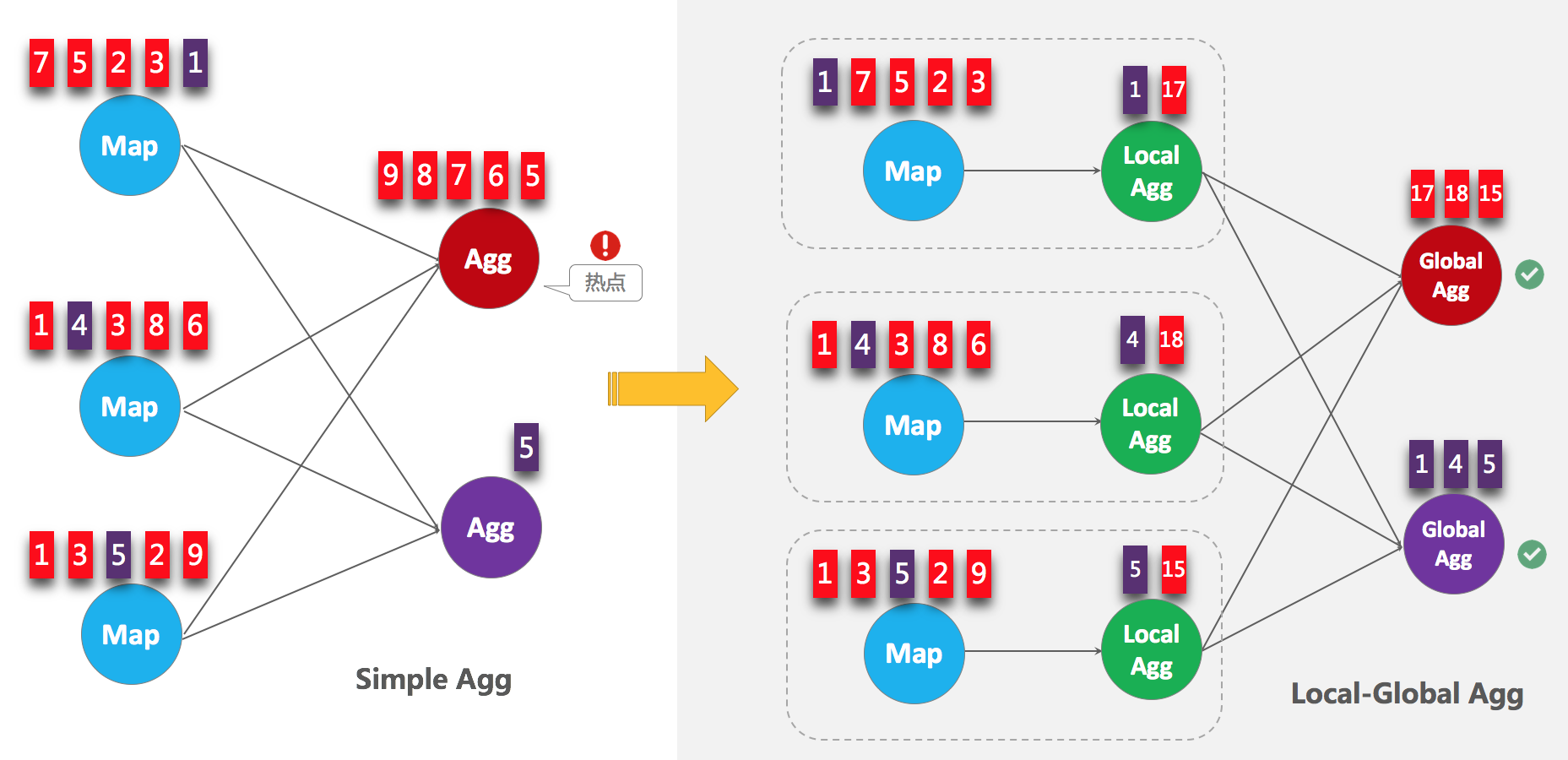
ЪЪгУГЁОА
LocalGlobalЪЪгУгкЬсЩ§ШчSUMЁЂCOUNTЁЂMAXЁЂMINКЭAVGЕШЦеЭЈОлКЯЕФадФмЃЌвдМАНтОіетаЉГЁОАЯТЕФЪ§ОнШШЕуЮЪЬтЁЃ
ЫЕУї ПЊЦєLocalGlobalашвЊUDAFЪЕЯжMergeЗНЗЈЁЃ
ПЊЦєЗНЪН
ЪЕЪБМЦЫу2.0АцБОПЊЪМЃЌLocalGlobalЪЧФЌШЯПЊЦєЕФЃЌВЮЪ§ЪЧblink.localAgg.enabled=true
ЃЌЕЋЪЧашвЊдкmicrobatchЛђminibatchПЊЦєЕФЧАЬсЯТВХФмЩњаЇЁЃ
ХаЖЯЪЧЗёЩњаЇ
ЙлВьзюжеЩњГЩЕФЭиЦЫЭМЕФНкЕуУћзжжаЪЧЗёАќКЌGlobalGroupAggregateЛђLocalGroupAggregateЁЃ
ПЊЦєPartialFinalЃЈНтОіCOUNT DISTINCTШШЕуЮЪЬтЃЉ
LocalGlobalгХЛЏеыЖдЦеЭЈОлКЯЃЈР§ШчSUMЁЂCOUNTЁЂMAXЁЂMINКЭAVGЃЉгаНЯКУЕФаЇЙћЃЌЖдгкCOUNT
DISTINCTЪеаЇВЛУїЯдЃЌвђЮЊCOUNT DISTINCTдкLocalОлКЯЪБЃЌЖдгкDISTINCT
KEYЕФШЅжиТЪВЛИпЃЌЕМжТдкGlobalНкЕуШдШЛДцдкШШЕуЁЃ
жЎЧАЃЌЮЊСЫНтОіCOUNT DISTINCTЕФШШЕуЮЪЬтЃЌЭЈГЃашвЊЪжЖЏИФаДЮЊСНВуОлКЯЃЈдіМгАДDistinct
KeyШЁФЃЕФДђЩЂВуЃЉЁЃзд2.2.0АцБОПЊЪМЃЌЪЕЪБМЦЫуЬсЙЉСЫCOUNT DISTINCTздЖЏДђЩЂЃЌМДPartialFinalгХЛЏЃЌФњЮоашздааИФаДЮЊСНВуОлКЯЁЃPartialFinalКЭLocalGlobalЕФдРэЖдБШВЮМћЯТЭМЁЃ
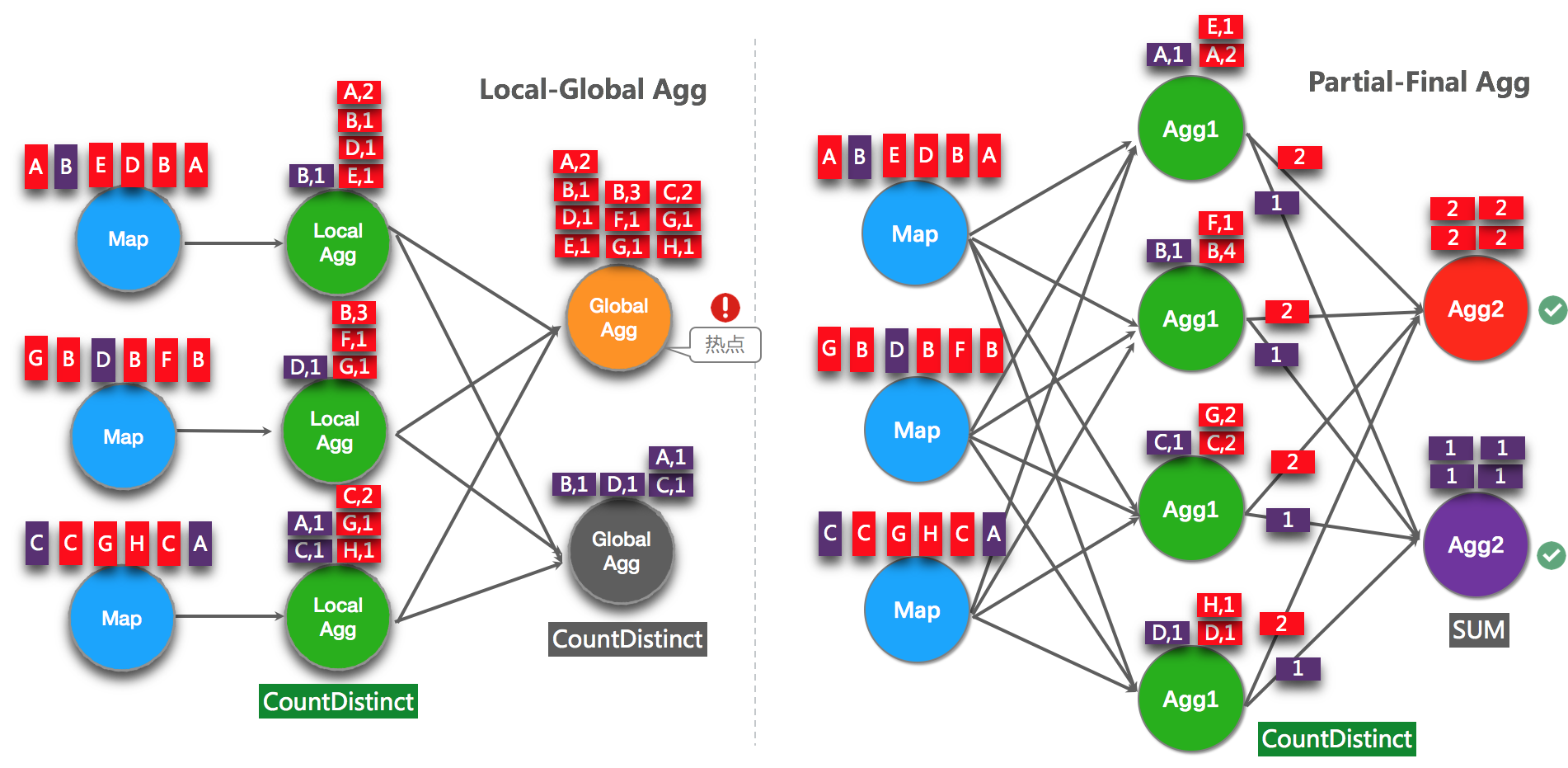
ЪЪгУГЁОА
ЪЙгУCOUNT DISTINCTЃЌЕЋЮоЗЈТњзуОлКЯНкЕуадФмвЊЧѓЁЃ
ЫЕУї
ВЛФмдкАќКЌUDAFЕФFlink SQLжаЪЙгУPartialFinalгХЛЏЗНЗЈЁЃ
Ъ§ОнСПВЛДѓЕФЧщПіЯТЃЌВЛНЈвщЪЙгУPartialFinalгХЛЏЗНЗЈЁЃPartialFinalгХЛЏЛсздЖЏДђЩЂГЩСНВуОлКЯЃЌв§ШыЖюЭтЕФЭјТчShuffleЃЌдкЪ§ОнСПВЛДѓЕФЧщПіЯТЃЌРЫЗбзЪдДЁЃ
ПЊЦєЗНЪН
ФЌШЯВЛПЊЦєЃЌЪЙгУВЮЪ§ЯдЪНПЊЦєblink.partialAgg.enabled=trueЁЃ
ХаЖЯЪЧЗёЩњаЇ
ЙлВьзюжеЩњГЩЕФЭиЦЫЭМЕФНкЕуУћжаЪЧЗёАќКЌExpandНкЕуЃЌЛђепдРДвЛВуЕФОлКЯБфГЩСЫСНВуЕФОлКЯЁЃ
ИФаДЮЊAGG WITH FILTERгяЗЈЃЈЬсЩ§ДѓСПCOUNT DISTINCTГЁОАадФмЃЉ
ЫЕУї НіЪЕЪБМЦЫу2.2.2МАвдЩЯАцБОжЇГжAGG WITH FILTERгяЗЈЁЃ
ЭГМЦзївЕашвЊМЦЫуИїжжЮЌЖШЕФUVЃЌР§ШчШЋЭјUVЁЂРДздЪжЛњПЭЛЇЖЫЕФUVЁЂРДздPCЕФUVЕШЕШЁЃНЈвщЪЙгУБъзМЕФAGG
WITH FILTERгяЗЈРДДњЬцCASE WHENЪЕЯжЖрЮЌЖШЭГМЦЕФЙІФмЁЃЪЕЪБМЦЫуФПЧАЕФSQLгХЛЏЦїФмЗжЮіГіFilterВЮЪ§ЃЌДгЖјЭЌвЛИізжЖЮЩЯМЦЫуВЛЭЌЬѕМўЯТЕФCOUNT
DISTINCTФмЙВЯэStateЃЌМѕЩйЖдStateЕФЖСаДВйзїЁЃадФмВтЪджаЃЌЪЙгУAGG WITH FILTERгяЗЈРДДњЬцCASE
WHENФмЙЛЪЙадФмЬсЩ§1БЖЁЃ
ЪЪгУГЁОА
НЈвщФњНЋAGG WITH CASE WHENЕФгяЗЈЖМЬцЛЛГЩAGG WITH FILTERЕФгяЗЈЃЌгШЦфЪЧЖдЭЌвЛИізжЖЮЩЯМЦЫуВЛЭЌЬѕМўЯТЕФCOUNT
DISTINCTНсЙћЃЌадФмЬсЩ§КмДѓЁЃ
дЪМаДЗЈ
| COUNT(distinct visitor_id)
as UV1 , COUNT(distinct case when is_wireless='y'
then visitor_id else null end) as UV2 |
гХЛЏаДЗЈ
| COUNT(distinct visitor_id)
as UV1 , COUNT(distinct visitor_id) filter (where
is_wireless='y') as UV2 |
TopNгХЛЏММЧЩ
TopNЫуЗЈ
ЕБTopNЕФЪфШыЪЧЗЧИќаТСїЃЈР§ШчSourceЃЉЃЌTopNжЛгавЛжжЫуЗЈAppendRankЁЃЕБTopNЕФЪфШыЪЧИќаТСїЪБЃЈР§ШчОЙ§СЫAGG/JOINМЦЫуЃЉЃЌTopNга3жжЫуЗЈЃЌадФмДгИпЕНЕЭЗжБ№ЪЧЃКUpdateFastRank
ЁЂ UnaryUpdateRankКЭRetractRankЁЃЫуЗЈУћзжЛсЯдЪОдкЭиЦЫЭМЕФНкЕуУћзжЩЯЁЃ
UpdateFastRank ЃКзюгХЫуЗЈЁЃ
ашвЊОпБИ2ИіЬѕМўЃК
ЪфШыСїгаPKЃЈPrimary KeyЃЉаХЯЂЃЌР§ШчORDER BY AVGЁЃ
ХХађзжЖЮЕФИќаТЪЧЕЅЕїЕФЃЌЧвЕЅЕїЗНЯђгыХХађЗНЯђЯрЗДЁЃР§ШчЃЌORDER BY COUNT/COUNT_DISTINCT/SUMЃЈе§Ъ§ЃЉDESCЃЈНіЪЕЪБМЦЫу2.2.2МАвдЩЯАцБОжЇГжЃЉЁЃ
ШчЙћФњвЊЛёШЁЕНгХЛЏPlanЃЌдђФњашвЊдкЪЙгУORDER BY SUM DESCЪБЃЌЬэМгSUMЮЊе§Ъ§ЕФЙ§ТЫЬѕМўЃЌШЗБЃtotal_feeЮЊе§Ъ§ЁЃ
insert
into print_test
SELECT
cate_id,
seller_id,
stat_date,
pay_ord_amt --ВЛЪфГіrownumзжЖЮЃЌФмМѕаЁНсЙћБэЕФЪфГіСПЁЃ
FROM (
SELECT
*,
ROW_NUMBER () OVER (
PARTITION BY cate_id,
stat_date --зЂвтвЊгаЪБМфзжЖЮЃЌЗёдђstateЙ§ЦкЛсЕМжТЪ§ОнДэТвЁЃ
ORDER
BY pay_ord_amt DESC
) as rownum --ИљОнЩЯгЮsumНсЙћХХађЁЃ
FROM (
SELECT
cate_id,
seller_id,
stat_date,
--жиЕуЁЃЩљУїSumЕФВЮЪ§ЖМЪЧе§Ъ§ЃЌЫљвдSumЕФНсЙћЪЧЕЅЕїЕндіЕФЃЌвђДЫTopNФмЪЙгУгХЛЏЫуЗЈЃЌжЛЛёШЁЧА100ИіЪ§ОнЁЃ
sum (total_fee) filter (
where
total_fee >= 0
) as pay_ord_amt
FROM
random_test
WHERE
total_fee >= 0
GROUP
BY cate_name,
seller_id,
stat_date
) a
WHERE
rownum <= 100
); |
UnaryUpdateRankЃКНіДЮгкUpdateFastRankЕФЫуЗЈЁЃашвЊОпБИ1ИіЬѕМўЃКЪфШыСїжаДцдкPKаХЯЂЁЃ
RetractRankЃКЦеЭЈЫуЗЈЃЌадФмзюВюЃЌВЛНЈвщдкЩњВњЛЗОГЪЙгУИУЫуЗЈЁЃЧыМьВщЪфШыСїЪЧЗёДцдкPKаХЯЂЃЌШчЙћДцдкЃЌдђПЩНјааUnaryUpdateRankЛђUpdateFastRankгХЛЏЁЃ
TopNгХЛЏЗНЗЈ
ЮоХХУћгХЛЏ
TopNЕФЪфГіНсЙћЮоашвЊЯдЪОrownumжЕЃЌНіашдкзюжеЧАЖЫЯдЪНЪБНјаа1ДЮХХађЃЌМЋДѓЕиМѕЩйЪфШыНсЙћБэЕФЪ§ОнСПЁЃЮоХХУћгХЛЏЗНЗЈЯъЧщЧыВЮМћTopNгяОфЁЃ
діМгTopNЕФCacheДѓаЁ
TopNЮЊСЫЬсЩ§адФмгавЛИіState CacheВуЃЌCacheВуФмЬсЩ§ЖдStateЕФЗУЮЪаЇТЪЁЃTopNЕФCacheУќжаТЪЕФМЦЫуЙЋЪНЮЊЁЃ
| cache_hit = cache_size*parallelism/top_n/partition_key_num |
Р§ШчЃЌTop100ХфжУЛКДц10000ЬѕЃЌВЂЗЂ50ЃЌЕБФњЕФPatitionByЕФkeyЮЌЖШНЯДѓЪБЃЌР§Шч10ЭђМЖБ№ЪБЃЌCacheУќжаТЪжЛга10000*50/100/100000=5%ЃЌУќжаТЪЛсКмЕЭЃЌЕМжТДѓСПЕФЧыЧѓЖМЛсЛїжаStateЃЈДХХЬЃЉЃЌадФмЛсДѓЗљЯТНЕЁЃвђДЫЕБPartitionKeyЮЌЖШЬиБ№ДѓЪБЃЌПЩвдЪЪЕБМгДѓTopNЕФCacheS
izeЃЌЯрЖдгІЕФвВНЈвщЪЪЕБМгДѓTopNНкЕуЕФHeap MemoryЃЈЧыВЮМћЪжЖЏХфжУЕїгХЃЉЁЃ
##ФЌШЯ10000ЬѕЃЌЕїећTopN cahceЕН20ЭђЃЌФЧУДРэТлУќжаТЪФмДя200000*50/100/100000
= 100%ЁЃ
blink.topn.cache.size=200000 |
PartitionByЕФзжЖЮжавЊгаЪБМфРрзжЖЮ
Р§ШчУПЬьЕФХХУћЃЌвЊДјЩЯDayзжЖЮЁЃЗёдђTopNЕФНсЙћЕНзюКѓЛсгЩгкState ttlгаДэТвЁЃ
ИпаЇШЅжиЗНАИ
ЫЕУї НіBlink 3.2.1АцБОжЇГжИпаЇШЅжиЗНАИЁЃ
ЪЕЪБМЦЫуЕФдДЪ§ОндкВПЗжГЁОАжаДцдкжиИДЪ§ОнЃЌШЅжиГЩЮЊСЫгУЛЇОГЃЗДРЁЕФашЧѓЁЃЪЕЪБМЦЫугаБЃСєЕквЛЬѕЃЈDeduplicate
Keep FirstRowЃЉКЭБЃСєзюКѓвЛЬѕЃЈDeduplicate Keep LastRowЃЉ2жжШЅжиЗНАИЁЃ
гяЗЈ
гЩгкSQLЩЯУЛгажБНгжЇГжШЅжиЕФгяЗЈЃЌЛЙвЊСщЛюЕФБЃСєЕквЛЬѕЛђБЃСєзюКѓвЛЬѕЁЃвђДЫЮвУЧЪЙгУСЫSQLЕФROW_NUMBER
OVER WINDOWЙІФмРДЪЕЯжШЅжигяЗЈЁЃШЅжиБОжЪЩЯЪЧвЛжжЬиЪтЕФTopNЁЃ
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER ([PARTITION BY col1[, col2..]
ORDER BY timeAttributeCol [asc|desc]) AS rownum
FROM table_name)
WHERE rownum = 1 |
ЪЙгУROW_NUMBER() ДАПкКЏЪ§РДЖдЪ§ОнИљОнЪБМфЪєадСаНјааХХађВЂБъЩЯХХУћЁЃ
ЫЕУї
ЕБХХађзжЖЮЪЧProctimeСаЪБЃЌFlinkОЭЛсАДееЯЕЭГЪБМфШЅжиЃЌЦфУПДЮдЫааЕФНсЙћЪЧВЛШЗЖЈЕФЁЃ
ЕБХХађзжЖЮЪЧRowtimeСаЪБЃЌFlinkОЭЛсАДеевЕЮёЪБМфШЅжиЃЌЦфУПДЮдЫааЕФНсЙћЪЧШЗЖЈЕФЁЃ
ЖдХХУћНјааЙ§ТЫЃЌжЛШЁЕквЛЬѕЃЌДяЕНСЫШЅжиЕФФПЕФЁЃ
ЫЕУї ХХађЗНЯђПЩвдЪЧАДееЪБМфСаЕФЫГађЃЌвВПЩвдЪЧЕЙађЃК
Deduplicate Keep FirstRowЃКЫГађВЂШЁЕквЛЬѕааЪ§ОнЁЃ
Deduplicate Keep LastRowЃКЕЙађВЂШЁЕквЛЬѕааЪ§ОнЁЃ
Deduplicate Keep FirstRow
БЃСєЪзааЕФШЅжиВпТдЃКБЃСєKEYЯТЕквЛЬѕГіЯжЕФЪ§ОнЃЌжЎКѓГіЯжИУKEYЯТЕФЪ§ОнЛсБЛЖЊЦњЕєЁЃвђЮЊSTATEжажЛДцДЂСЫKEYЪ§ОнЃЌЫљвдадФмНЯгХЃЌЪОР§ШчЯТЁЃ
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime)
as rowNum
FROM T
)
WHERE rowNum = 1 |
ЫЕУї вдЩЯЪОР§ЪЧНЋTБэАДееbзжЖЮНјааШЅжиЃЌВЂАДееЯЕЭГЪБМфБЃСєЕквЛЬѕЪ§ОнЁЃProctimeдкетРяЪЧдДБэTжаЕФвЛИіОпгаProcessing
TimeЪєадЕФзжЖЮЁЃШчЙћФњАДееЯЕЭГЪБМфШЅжиЃЌвВПЩвдНЋProctimeзжЖЮМђЛЏPROCTIME()КЏЪ§ЕїгУЃЌПЩвдЪЁТдProctimeзжЖЮЕФЩљУїЁЃ
Deduplicate Keep LastRow
БЃСєФЉааЕФШЅжиВпТдЃКБЃСєKEYЯТзюКѓвЛЬѕГіЯжЕФЪ§ОнЁЃБЃСєФЉааЕФШЅжиВпТдадФмТдгХгкLAST_VALUEКЏЪ§ЃЌЪОР§ШчЯТЁЃ
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY
rowtime DESC) as rowNum
FROM T
)
WHERE rowNum = 1 |
ЫЕУї вдЩЯЪОР§ЪЧНЋTБэАДееbКЭdзжЖЮНјааШЅжиЃЌВЂАДеевЕЮёЪБМфБЃСєзюКѓвЛЬѕЪ§ОнЁЃRowtimeдкетРяЪЧдДБэTжаЕФвЛИіОпгаEvent
TimeЪєадЕФзжЖЮЁЃ
ИпаЇЕФФкжУКЏЪ§
ЪЙгУФкжУКЏЪ§ЬцЛЛздЖЈвхКЏЪ§
ЪЕЪБМЦЫуЕФФкжУКЏЪ§дкГжајЕФгХЛЏЕБжаЃЌЧыОЁСПЪЙгУФкВПКЏЪ§ЬцЛЛздЖЈвхКЏЪ§ЁЃЪЕЪБМЦЫу2.0АцБОЖдФкжУКЏЪ§жївЊНјааСЫШчЯТгХЛЏЃК
гХЛЏЪ§ОнађСаЛЏКЭЗДађСаЛЏЕФКФЪБЁЃ
аТдіжБНгЖдзжНкЕЅЮЛНјааВйзїЕФЙІФмЁЃ
KEY VALUEКЏЪ§ЪЙгУЕЅзжЗћЕФЗжИєЗћ
KEY VALUE ЕФЧЉУћЃКKEYVALUE(content, keyValueSplit, keySplit,
keyName)ЃЌЕБkeyValueSplitКЭKeySplitЪЧЕЅзжЗћЃЈР§ШчЃЌУАКХЃЈ:ЃЉЁЂЖККХЃЈ,ЃЉЃЉЪБЃЌЯЕЭГЛсЪЙгУгХЛЏЫуЗЈЃЌдкЖўНјжЦЪ§ОнЩЯжБНгбАевЫљашЕФkeyName
ЕФжЕЃЌЖјВЛЛсНЋећИіcontentзіЧаЗжЁЃадФмдМЬсЩ§30%ЁЃ
ЖрKEY VALUEГЁОАЪЙгУMULTI_KEYVALUE
ЫЕУї НіЪЕЪБМЦЫу2.2.2МАвдЩЯАцБОжЇГжMULTI_KEYVALUEЁЃ
дкQueryжаЖдЭЌвЛИіContentНјааДѓСПKEY VALUEЕФВйзїЃЌЛсЖдадФмВњЩњКмДѓгАЯьЁЃР§ШчContentжаАќКЌ10ИіKey-ValueЖдЃЌШчЙћФњЯЃЭћАб10ИіValueЕФжЕЖМШЁГіРДзїЮЊзжЖЮЃЌФњОЭашвЊаД10ИіKEY
VALUEКЏЪ§ЃЌдђЯЕЭГОЭЛсЖдContentНјаа10ДЮНтЮіЃЌЕМжТадФмНЕЕЭЁЃ
дкетжжЧщПіЯТЃЌНЈвщФњЪЙгУMULTI_KEYVALUEБэжЕКЏЪ§ЃЌИУКЏЪ§ПЩвдЖдContentжЛНјаавЛДЮSplitНтЮіЃЌадФмдМФмЬсЩ§50%~100%ЁЃ
LIKEВйзїзЂвтЪТЯю
ШчЙћашвЊНјааStartWithВйзїЃЌЪЙгУLIKE 'xxx%'ЁЃ
ШчЙћашвЊНјааEndWithВйзїЃЌЪЙгУLIKE '%xxx'ЁЃ
ШчЙћашвЊНјааContainsВйзїЃЌЪЙгУLIKE '%xxx%'ЁЃ
ШчЙћашвЊНјааEqualsВйзїЃЌЪЙгУLIKE 'xxx'ЃЌЕШМлгкstr = 'xxx'ЁЃ
ШчЙћашвЊЦЅХф _ зжЗћЃЌЧызЂвтвЊЭъГЩзЊвхLIKE '%seller/id%' ESCAPE '/'ЁЃ_дкSQLжаЪєгкЕЅзжЗћЭЈХфЗћЃЌФмЦЅХфШЮКЮзжЗћЁЃШчЙћЩљУїЮЊ
LIKE '%seller_id%'ЃЌдђВЛЕЅЛсЦЅХфseller_idЛЙЛсЦЅХфseller#idЁЂsellerxidЛђseller1id
ЕШЃЌЕМжТНсЙћДэЮѓЁЃ
ЩїгУе§дђКЏЪ§ЃЈREGEXPЃЉ
е§дђБэДяЪНЪЧЗЧГЃКФЪБЕФВйзїЃЌЖдБШМгМѕГЫГ§ЭЈГЃгаАйБЖЕФадФмПЊЯњЃЌЖјЧве§дђБэДяЪНдкФГаЉМЋЖЫЧщПіЯТПЩФмЛсНјШыЮоЯобЛЗЃЌЕМжТзївЕзшШћЁЃНЈвщЪЙгУLIKEЁЃе§дђКЏЪ§АќРЈЃК
REGEXP
REGEXP_EXTRACT
REGEXP_REPLACE
ЭјТчДЋЪфЕФгХЛЏ
ФПЧАГЃМћЕФPartitionerВпТдАќРЈЃК
KeyGroup/HashЃКИљОнжИЖЈЕФKeyЗжХфЁЃ
RebalanceЃКТжбЏЗжХфИјИїИіChannelЁЃ
Dynamic-RebalanceЃКИљОнЯТгЮИКдиЧщПіЖЏЬЌбЁдёЗжХфИјИКдиНЯЕЭЕФChannelЁЃ
ForwardЃКЮДChainвЛЦ№ЪБЃЌЭЌRebalanceЁЃChainвЛЦ№ЪБЪЧвЛЖдвЛЗжХфЁЃ
RescaleЃКЩЯгЮгыЯТгЮвЛЖдЖрЛђЖрЖдвЛЁЃ
ЪЙгУDynamic-RebalanceЬцДњRebalance
Dynamic-RebalanceПЩвдИљОнЕБЧАИїSubpartitionжаЖбЛ§ЕФBufferЕФЪ§СПЃЌбЁдёИКдиНЯЧсЕФSubpartitionНјаааДШыЃЌДгЖјЪЕЯжЖЏЬЌЕФИКдиОљКтЁЃЯрБШгкОВЬЌЕФRebalanceВпТдЃЌдкЯТгЮИїШЮЮёМЦЫуФмСІВЛОљКтЪБЃЌПЩвдЪЙИїШЮЮёЯрЖдИКдиИќМгОљКтЃЌДгЖјЬсИпећИізївЕЕФадФмЁЃР§ШчЃЌдкЪЙгУRebalanceЪБЃЌЗЂЯжЯТгЮИїИіВЂЗЂИКдиВЛОљКтЪБЃЌПЩвдПМТЧЪЙгУDynamic-RebalanceЁЃВЮЪ§ЃКtask.dynamic.rebalance.enabled=trueЃЌ
ФЌШЯЙиБеЁЃ
ЪЙгУRescaleЬцДњRebalance
ЫЕУї НіЪЕЪБМЦЫу2.2.2МАвдЩЯАцБОжЇГжRescaleЁЃ
Р§ШчЃЌЩЯгЮЪЧ5ИіВЂЗЂЃЌЯТгЮЪЧ10ИіВЂЗЂЁЃЕБЪЙгУRebalanceЪБЃЌЩЯгЮУПИіВЂЗЂЛсТжбЏЗЂИјЯТгЮ10ИіВЂЗЂЁЃЕБЪЙгУRescaleЪБЃЌЩЯгЮУПИіВЂЗЂжЛашТжбЏЗЂИјЯТгЮ2ИіВЂЗЂЁЃвђЮЊChannelИіЪ§БфЩйСЫЃЌSubpartitionЕФBufferЬюГфЫйЖШФмБфПьЃЌФмЬсИпЭјТчаЇТЪЁЃЕБЩЯгЮЕФЪ§ОнБШНЯОљдШЪБЃЌЧвЩЯЯТгЮЕФВЂЗЂЪ§ГЩБШР§ЪБЃЌПЩвдЪЙгУRescaleЬцЛЛRebalanceЁЃВЮЪ§ЃКenable.rescale.shuffling=trueЃЌФЌШЯЙиБеЁЃ
ЭЦМіЕФгХЛЏХфжУЗНАИ
злЩЯЫљЪіЃЌзївЕНЈвщЪЙгУШчЯТЕФЭЦМіХфжУЁЃ
# EXACTLY_ONCEгявхЁЃ
blink.checkpoint.mode=EXACTLY_ONCE
# checkpointМфИєЪБМфЃЌЕЅЮЛКСУыЁЃ
blink.checkpoint.interval.ms=180000
blink.checkpoint.timeout.ms=600000
# 2.xЪЙгУniagaraзїЮЊstatebackendЃЌвдМАЩшЖЈstateЪ§ОнЩњУќжмЦкЃЌ
ЕЅЮЛКСУыЁЃ
state.backend.type=niagara
state.backend.niagara.ttl.ms=129600000
# 2.xПЊЦє5УыЕФmicrobatchЁЃ
blink.microBatch.allowLatencyMs=5000
# ећИіJobдЪаэЕФбгГйЁЃ
blink.miniBatch.allowLatencyMs=5000
# ЕЅИіbatchЕФsizeЁЃ
blink.miniBatch.size=20000
# local гХЛЏЃЌ2.xФЌШЯвбОПЊЦєЃЌ1.6.4ашЪжЖЏПЊЦєЁЃ
blink.localAgg.enabled=true
# 2.xПЊЦєPartialFinaгХЛЏЃЌНтОіCOUNT DISTINCTШШЕуЁЃ
blink.partialAgg.enabled=true
# union allгХЛЏЁЃ
blink.forbid.unionall.as.breakpoint.in.subsection.
optimization=true
# object reuseгХЛЏЃЌФЌШЯвбПЊЦєЁЃ
#blink.object.reuse=true
# GCгХЛЏЃЈSLSзідДБэВЛФмЩшжУИУВЮЪ§ЃЉЁЃ
blink.job.option=-yD heartbeat.timeout=180000
-yD env.java.opts='-verbose:gc -XX:NewRatio=3
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:
ParallelGCThreads=4'
# ЪБЧјЩшжУЁЃ
blink.job.timeZone=Asia/Shanghai |
|









