| 编辑推荐: |
本文主要介绍
Pravega 的云原生特性,核心组件,安装部署实践以及 Reader/Writer
的基本应用实践。
本文来自于微信 AI前线,由火龙果软件Anna编辑、推荐。 |
|
云原生(Cloud Native)与 Pravega
随着容器技术和云服务的发展,Kubernetes 和云原生运动已大规模地重定义了应用设计和开发的一些方面。云原生是一种基于微服务架构思想、以容器技术为载体,产品研发运营的模式。通过这样的软件开发模式才能真正的发挥云的弹性、动态调度、自动伸缩等云所特有的能力。
Pravega 从设计之初就是云原生(Cloud Native)的应用,可以在各大公有 / 私有云平台上进行部署和运行。
它的组件都是以低耦合的微服务形式存在,通过运行多个服务实例保证高可用性。
每个服务实例运行于单独的容器中,使用容器实现服务的相互隔离。
可以使用容器编排工具(如 Kubernetes)进行统一的服务发现、治理和编排,提高资源利用率,降低运营成本。
Kubernetes 是由 Google 在 2014 年开源的一个允许自动化部署、管理和伸缩容器的工具,目前已经成为容器编排调度的实际标准。它提供了一些强大的功能,例如容器之间的负载均衡,重启失败的容器以及编排容器使用的存储等。Kubernetes
通过将云应用进行抽象简化出各种概念对象,如 Pod、Deployment、Job、StatefulSet
等,形成了云原生应用的通用可移植的模型,让云应用可以在云之间无缝迁移。
Pravega 团队通过第三方资源机制扩展了 Kubernetes
的 API,开发了能够使得 Pravega 集群的创建、配置和管理更高效和自动化的 Operator,包括
Pravega Operator 和 Zookeeper Operator,通过他们可以使得 Pravega
在 Kubernetes 环境中快速创建集群和动态扩展。这些 Operator 以及其他相关的容器镜像会上传至
Pravega 在 DockerHub 官方的镜像仓库
中,用户也可以直接拉取使用,源代码也在
GitHub 网站。
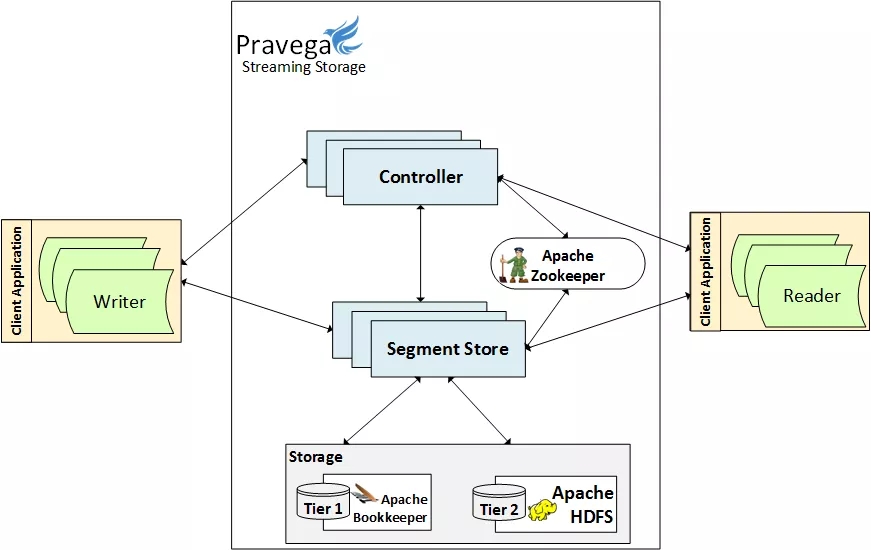
Pravega 核心组件及交互
Pravega 能够以一致的方式灵活地存储不断变化的流数据,主要得益于控制面(Control Plane)和数据面(Data
Plane)的有机结合。两者都由低耦合的分布式微服务组件管理,前者主要由控制器(Controller)实现,后者主要由段存储器(Segment
Store)实现,它们通常以多实例的形式运行在集群中。除此以外,一个完整的 Pravage 集群还包括一组
Zookeeper 实例,一组 Bookkeeper 实例,以及用于提供第二层的存储的服务或接口。
它们的关系如图:
控制器(Controller)是 Pravega 的控制中心,对外提供 JAVA 和 REST 接口,接收客户端对于
Stream 的创建、删除、读写等请求;对内负责 Segment 的管理和集群的管理。客户端对于 Stream
的读写请求在控制器中被分拆为对 Segment 的请求,控制器确定需要使用哪些 Segment,从而分发给相应的段存储器来操作。
段存储器(Segment Store)提供了 Segment 的管理入口,实现了 Segment
的创建,删除,修改和读取功能。数据被存储在一层和二层存储上,由段存储器负责数据的存储和降层操作。其中一层存储由低延迟的
Bookkeeper 担任,通常运行于集群的内部;二层存储由容量大且成本较低存储的担任,一般运行于集群的外部。
Zookeeper 做为集群的协调者, 它维护可用的控制器和段存储器列表,控制器会监听它们的变化。当一个控制器从集群中删除时,它的工作会被其他的控制器自动接管。当段存储器发生变化时,控制器也会将段容器重新映射以保证系统的正常运行。
Pravega 的部署
了解 Pravega 最好方法就是自己动手部署一个,然后跑一下 Pravega
示例程序:
单机版部署
单机版部署是最快捷的方式,你只需要从 Pravega Release Github:
下载一个 Pravega 发行版,解压后运行:
单机版部署只能用来学习和测试,不能用于生产环境中,程序一旦关闭所有的数据也会丢失。
集群部署
Pravega 可以运行于多个主机所组成的集群中,也可以运行于云平台中。这里我们只介绍
Kubernetes 环境下的部署,其他的方式参考
运行之前,需要保证你拥有一套 Kubernetes 环境,可以是公有云上的 Kubernetes
服务(如 GKE,Amazon EKS),或者是分布式集群上自建的 Kubernetes 环境(如通过
Kubeadm),以及命令行工具 kubectl,helm。
首先,在你的 Kubernetes 环境中创建一个 Zookeeper 集群。
Zookeeper 集群可以使用 Zookeeper Operator 来创建,你可以直接使用 deploy
文件夹中的资源描述文件来部署。
然后,为 Pravega 第二层存储创建单独的持久化存储卷(PV)及持久化存储卷声明(PVC)。
这里我们使用NFS Server Provisioner ,其他的方式请参考
Pravega Operator 的自述文件。
NFS Server Provisioner 是一个开源工具,它提供一个内置的 NFS 服务器,可以根据
PVC 声明动态地创建基于 NFS 的持久化存储卷。
通过 helm chart 创建 nfs-server-provisioner,执行helm install
stable/nfs-server-provisioner 将会创建一个名为 nfs 的存储类(StorageClass)、nfs-server-provisioner
服务与实例、以及相应的服务账户和角色绑定。
新建一个持久化存储卷声明文件 pvc.yaml,这里 storageClassName 指定为 nfs。当它被创建时,NFS
Server Provisioner 会自动创建相应的持久化存储卷。pvc.yaml 内容如下:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pravega-tier2
spec:
storageClassName: "nfs"
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
|
通过kubectl create -f pvc.yaml创建该持久化存储卷声明,你会发现相应的持久化存储卷也被创建。
接着,部署一个 Pravega Operator。
你可以直接使用 deploy 文件夹中的资源描述文件部署:
这里会创建一个名为 PravegaCluster 自定义资源定义(Custom Resource Definition)、服务账号、角色、角色绑定,并把
Pravega Operator 部署到 Kubernetes 集群中。
最后,修改资源描述文件并创建 Pravega 集群。
资源描述文件 cr.yaml 指定了 Zookeeper 地址、各组件的实例数和存储空间。完整文件可以从这里获得
apiVersion: "pravega.pravega.io/v1alpha1"
kind: "PravegaCluster"
metadata:
name: "pravega"
spec:
# 配置 zookeeper 集群的地址
zookeeperUri: example-zookeepercluster-client:2181
# 配置 bookkeeper,建议至少三个实例
bookkeeper:
replicas: 3
...
pravega:
# 配置控制器实例,建议至少两个实例
controllerReplicas: 2
# 配置段存储器实例,建议至少三个实例
segmentStoreReplicas: 3
# 配置第二层存储,使用之前创建的持久化存储卷声明
tier2:
filesystem:
persistentVolumeClaim:
claimName: pravega-tier2
... |
根据描述文件(cr.yaml)创建一个 Pravega 集群:
| kubectl create
-f pravega-operator/example/cr.yaml |
集群创建成功后,你可以通过以下命令查看集群的运行状态:
| kubectl get all
-l pravega_cluster=pravega |
创建一个简单的应用
让我们来看看如何构建一个简单的 Pravega 应用程序。最基本的
Pravega 应用就是使用读客户端(Reader)从 Stream 中读取数据或使用写客户端(Writer)向
Stream 中写入数据。两个简单的例子都可以在 Pravega 示例中的
应用程序中找到:
要正确实现这些应用,首先回顾一下 Pravega 是如何高效并发地读写 Stream:
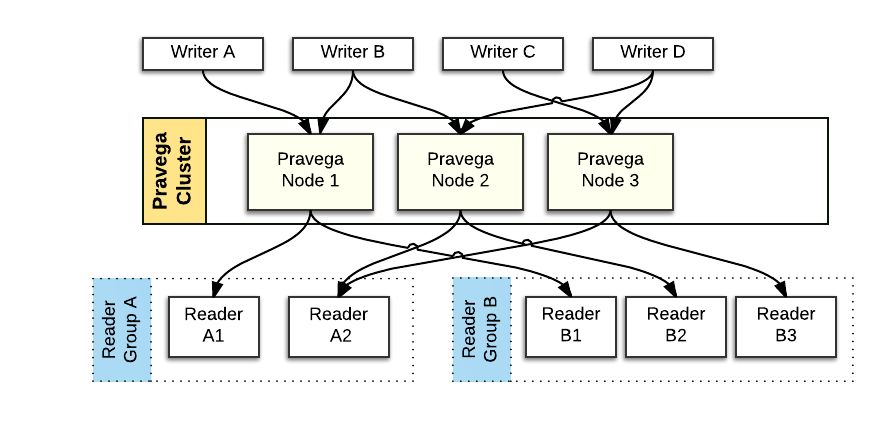
为了实现并发地读写,Stream 被分为一个或多个 Segment,系统可以根据 I/O 负载动态调整
Segment 的数目。
写数据 时,多个 Writer 可以同时向多个 Segment 追加数据而无需知道它们的变化,由
路由键(Routing key) 保证顺序的一致性。
路由键是一个字符串,控制器会根据它的哈希值而决定该事件将会被派发到哪个 Segment 中。具有同样路由键的事件会被派发到同一个
Segment,这样可以保证它们能以一致的顺序被访问。
如果 Segment 发生了变化,具有相同路由键的事件也会一致的被映射到新的 Segment 中。
读数据 时,读者组(ReaderGroup) 中的一组 Reader 可以同时从不同的 Segment
中读数据。
一个 ReaderGroup 包含一个或多个 Reader,每个 Reader 从一个或多个 Segment
中读数据。
为了保证每个事件只被读取一次,一个 Segment 只能被当前 ReaderGroup 中的一个
Reader 读。
一个 ReaderGroup 可以从一个或多个 Stream 中读数据,不同的 ReaderGroup
是相互独立的。
写数据只能向 Stream 的尾部追加,读数据可以从指定位置读。
使用 Writer 向流中写数据
示例 HelloWorldWriter 举例说明了如何使用 EventStreamWriter 向
Stream 中写一个事件。 我们来看一下其中最关键的 run() 方法:
1) 使用 StreamManager 创建一个 Scope。
StreamManager
streamManager = StreamManager.create(controllerURI);
final boolean scopeCreation = streamManager.createScope(scope); |
StreamManager 是创建、删除和管理 stream 及 scope 的接口,通过指定一个控制器地址与控制器通信。
2) 使用 StreamManager 创建一个 Stream。
StreamConfiguration
streamConfig = StreamConfiguration.builder()
.scalingPolicy( ScalingPolicy.fixed(1))
.build();
final boolean streamCreation = streamManager.createStream(scope,
streamName, streamConfig); |
创建 stream 的时候需要指定 scope,名称和配置项。
其中,流配置项包括流的伸缩策略(Scaling Policy)和降层策略(Retention Policy)。Pravega
支持三种伸缩策略,将会在下一篇《Pravega 动态弹性伸缩特性》中具体介绍。降层策略已经在上一篇中介绍过。
3) 使用 ClientFactory 创建一个 Writer,并向
Stream 中写数据。
try (ClientFactory
clientFactory = ClientFactory.withScope(scope,
controllerURI);
EventStreamWriter<String> writer = clientFactory.createEventWriter(streamName,
new JavaSerializer<String>(),
EventWriterConfig.builder().build())) {
final CompletableFuture<Void> writeFuture
= writer.writeEvent (routingKey, message);
} |
ClientFactory 是用于创建 Readers,Writers 和其它类型的客户端对象的工具,它是在
Scope 的上下文中创建的。ClientFactory 以及由它创建的对象会消耗 Pravega
的资源,所以在示例中用 try-with-resources 来创建这些对象,以保证程序结束时这些对象会被正确的关闭。如果你使用其他的方式创建对象,请确保在使用结束后正确的调用这些对象的
close() 方法。
在创建 Writer 的时候还需要指定一个序列化器,它负责把 Java 对象转化为字节码。事件在
Pravega 中是以字节码的形式存储的,Pravega 并不需要知道事件的具体类型,这使得 Pravega
可以存储任意类型的对象,由客户端负责提供序列化 / 反序列化的方法。
用 writeEvent 方法将事件写入流,需要指定一个路由键(Routing key)。
使用 Reader 从流中数据
示例 HelloWorldReader 举例说明了如何使用 EventStreamReader 从
Stream 中读取事件,其关键部分也是在 run() 方法中。
1) 使用 ReaderGroupManager 创建一个 ReaderGroup。
final ReaderGroupConfig
readerGroupConfig = ReaderGroupConfig.builder()
.stream(Stream.of(scope, streamName))
.build();
try (ReaderGroupManager readerGroupManager = ReaderGroupManager.withScope
(scope, controllerURI)) {
readerGroupManager.createReaderGroup (readerGroup,
readerGroupConfig);
} |
ReaderGroupManager 类似于 ClientFactory,也是在 scope 的上下文中创建的。
创建 ReaderGroup 需要指定名称和配置项,其中配置项规定了该 ReaderGroup 从哪些
Stream 中读数据,以及所要读取的 Stream 的起止位置。Pravega 具有 Position
的概念,它表示 Reader 当前所在的 Stream 中的位置。应用保留 Reader 最后成功读取的位置,Position
的信息可以用于 Checkpoint 恢复机制,如果读失败了就从这个保存的检查点重新开始读。
2) 创建一个 Reader 并从流中读数据。
try (ClientFactory
clientFactory = ClientFactory.withScope(scope,
controllerURI);
EventStreamReader<String> reader = clientFactory.createReader("reader",
readerGroup,
new JavaSerializer<String>(),
ReaderConfig.builder().build())) {
EventRead<String> event = null;
do {
event = reader.readNextEvent(READER_TIMEOUT_MS);
} while (event.getEvent() != null);
} |
Reader 也是由 ClientFactory 创建的。一个新建的 Reader 会被加入到相应的
ReadGroup 中,系统根据当前 ReaderGroup 的工作负载自动分配相应的段给新创建的
Reader。Reader 可以通过 readNextEvent 读取事件。
由于 Pravega 的自动伸缩功能,Segment 的数量会随着负载的变化而变化,当 ReaderGroup
管理的 Segment 总数发生变化时,会触发段通知(SegmentNotification),ReaderGroup
可以监听该事件并适时地调整 Reader 的数量。 如果当前的 Segment 比较多,为了保证读的并发性,建议增加
Reader;反之,如果当前的 Segment 比较少,建议减少 Reader。由于 Reader
和 Segment 是一对多的关系,Reader 的数量大于 Segment 的数量是没有意义的。
|