| БрМЭЦМі: |
| БОЮФЖдећЬхНјааСЫНщЩмЃЌЪЕМљгХЛЏЁЂШЛКѓНщЩмСЫСїХњвЛЬхЁЂзюКѓЖдЮДРДНјааСЫЙцЛЎЁЃ
БОЮФРДздЮЂаХЙЋжкКХFlink жаЮФЩчЧјЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂећЬхНщЩм

2018 Фъ 12 дТ Blink аћВМПЊдДЃЌОРњСЫдМвЛФъЕФЪБМф Flink 1.9 гк 2019
Фъ 8 дТ 22 ЗЂВМЁЃдк Flink 1.9 ЗЂВМжЎЧАзжНкЬјЖЏФкВПЛљгк master ЗжжЇНјааФкВПЕФ
SQL ЦНЬЈЙЙНЈЁЃОРњСЫ 2~3 ИідТЕФЪБМфзжНкФкВПдк 19 Фъ 10 дТЗнЗЂВМСЫЛљгк Flink
1.9 ЕФ Blink planner ЙЙНЈЕФ Streaming SQL ЦНЬЈЃЌВЂНјааФкВПЭЦЙуЁЃдкетИіЙ§ГЬжаЗЂЯжСЫвЛаЉБШНЯгавтЫМЕФашЧѓГЁОАЃЌвдМАвЛаЉНЯЮЊЦцЙжЕФ
BUGЁЃ
Лљгк 1.9 ЕФ Flink SQL РЉеЙ
ЫфШЛзюаТЕФ Flink АцБОвбОжЇГж SQL ЕФ DDLЃЌЕЋ Flink 1.9 ВЂВЛжЇГжЁЃзжНкФкВПЛљгк
Flink 1.9 НјааСЫ DDL ЕФРЉеЙжЇГжвдЯТгяЗЈЃК
create table
create view
create function
add resource
ЭЌЪБ Flink 1.9 АцБОВЛжЇГжЕФ watermark ЖЈвхдк DDL РЉеЙКѓвВжЇГжСЫЁЃ
ЮвУЧдкЭЦМіДѓМвОЁСПЕФШЅгУ SQL БэДязївЕЪБЪеЕНКмЖрЁАSQL ЮоЗЈБэДяИДдгЕФвЕЮёТпМЁБЕФЗДРЁЁЃЪБМфОУСЫЗЂЯжЦфЪЕКмЖргУЛЇЫљЮНЕФИДдгвЕЮёТпМгаЕФЪЧзівЛаЉЭтВПЕФ
RPC ЕїгУЃЌзжНкФкВПеыЖдетИіГЁОАзіСЫвЛИі RPC ЕФЮЌБэКЭ sinkЃЌШУгУЛЇПЩвдШЅЖСаД RPC ЗўЮёЃЌМЋДѓЕФРЉеЙСЫ
SQL ЕФЪЙгУГЁОАЃЌАќРЈ FaaS ЦфЪЕИњ RPC вВЪЧРрЫЦЕФЁЃдкзжНкФкВПЬэМгСЫ Redis/Abase/Bytable/ByteSQL/RPC/FaaS
ЕШЮЌБэЕФжЇГжЁЃ
ЭЌЪБЛЙЪЕЯжСЫЖрИіФкВПЪЙгУЕФ connectorsЃК
source: RocketMQ
sink: RocketMQ/ClickHouse/Doris/LogHouse/Redis/Abase/Bytable/ByteSQL/RPC/Print/Metrics
ВЂЧвЮЊ connector ПЊЗЂСЫХфЬзЕФ formatЃКPB/Binlog/BytesЁЃ
дкЯпЕФНчУцЛЏ SQL ЦНЬЈ

Г§СЫЖд Flink БОЩэЙІФмЕФРЉеЙЃЌзжНкФкВПвВЩЯЯпСЫвЛИі SQL ЦНЬЈЃЌжЇГжвдЯТЙІФмЃК
SQL БрМ
SQL НтЮі
SQL ЕїЪд
здЖЈвх UDF КЭ Connector
АцБОПижЦ
ШЮЮёЙмРэ
ЖўЁЂЪЕМљгХЛЏ
Г§СЫЖдЙІФмЕФРЉеЙЃЌеыЖд Flink 1.9 SQL ЕФВЛзужЎДІвВзіСЫвЛаЉгХЛЏЁЃ
Window адФмгХЛЏ
1ЁЂжЇГжСЫ window Mini-Batch
Mini-Batch ЪЧ Blink planner ЕФвЛИіБШНЯгаЬиЩЋЕФЙІФмЃЌЦфжївЊЫМЯыЪЧЛ§дмвЛХњЪ§ОнЃЌдйНјаавЛДЮзДЬЌЗУЮЪЃЌДяЕНМѕЩйЗУЮЪзДЬЌЕФДЮЪ§НЕЕЭађСаЛЏЗДађСаЛЏЕФПЊЯњЁЃетИігХЛЏжївЊЪЧдк
RocksDB ЕФГЁОАЁЃШчЙћЪЧ Heap зДЬЌ Mini-Batch ВЂУЛЪВУДгХЛЏЁЃдквЛаЉЕфаЭЕФвЕЮёГЁОАжаЃЌЕУЕНЕФЗДРЁЪЧФмМѕЩй
20~30% зѓгвЕФ CPU ПЊЯњЁЃ
2ЁЂРЉеЙ window РраЭ
ФПЧА SQL жаЕФШ§жжФкжУ windowЃЌЙіЖЏДАПкЁЂЛЌЖЏДАПкЁЂsession ДАПкЃЌетШ§жжгявтЕФДАПкЮоЗЈТњзувЛаЉгУЛЇГЁОАЕФашЧѓЁЃБШШчдкжБВЅЕФГЁОАЃЌЗжЮіЪІЯыЭГМЦвЛИіжїВЅдкПЊВЅжЎКѓЃЌУПвЛИіаЁЪБЕФ
UV(Unique Visitor)ЁЂGMV(Gross Merchandise Volume) ЕШжИБъЁЃздШЛЕФЙіЖЏДАПкЕФЛЎЗжЗНЪНВЂВЛФмЙЛТњзугУЛЇЕФашЧѓЃЌзжНкФкВПОЭзіСЫвЛаЉЖЈжЦЕФДАПкРДТњзугУЛЇЕФвЛаЉЙВадашЧѓЁЃ
-- my_window
ЮЊздЖЈвхЕФДАПкЃЌТњзуЬиЖЈЕФЛЎЗжЗНЪН
SELECT
room_id,
COUNT(DISTINCT user_id)
FROM MySource
GROUP BY
room_id,
my_window(ts, INTERVAL '1' HOURS) |
3ЁЂwindow offset
етЪЧвЛИіНЯЮЊЭЈгУЕФЙІФмЃЌдк Datastream API ВуЪЧжЇГжЕФЃЌЕЋ
SQL жаВЂУЛгаЁЃетРягаИіБШНЯгавтЫМЕФГЁОАЃЌгУЛЇЯывЊПЊвЛжмЕФДАПкЃЌвЛжмЕФДАПкБфГЩСЫДгжмЫФПЊЪМЕФЗЧздШЛжмЁЃвђЮЊЫвВВЛЛсЯыЕН
1970 Фъ 1 дТ 1 КХФЧЬьОгШЛЪЧжмЫФЁЃдкМгШыСЫ offset ЕФжЇГжКѓОЭПЩвджЇГже§ШЗЕФздШЛжмДАПкЁЃ
SELECT
room_id,
COUNT(DISTINCT user_id)
FROM MySource
GROUP BY
room_id,
TUMBLE(ts, INTERVAL '7' DAY, INTERVAL '3', DAY) |
ЮЌБэгХЛЏ
1ЁЂбгГй Join
ЮЌБэ Join ЕФГЁОАЯТвђЮЊЮЌБэОГЃЗЂЩњБфЛЏгШЦфЪЧаТдіЮЌЖШЃЌЖј Join ВйзїЗЂЩњдкЮЌЖШаТдіжЎЧАЃЌОГЃЕМжТЙиСЊВЛЩЯЁЃ
ЫљвдгУЛЇЯЃЭћШчЙћ Join ВЛЕНЃЌдђднЪБНЋЪ§ОнЛКДцЦ№РДжЎКѓдйНјааГЂЪдЃЌВЂЧвПЩвдПижЦГЂЪдДЮЪ§ЃЌФмЙЛздЖЈвхбгГй
Join ЕФЙцдђЁЃетИіашЧѓГЁОАВЛЕЅЕЅдкзжНкФкВПЃЌЩчЧјЕФКмЖрЭЌбЇвВгаРрЫЦЕФашЧѓЁЃ
ЛљгкЩЯУцЕФГЁОАЪЕЯжСЫбгГй Join ЙІФмЃЌЬэМгСЫвЛИіПЩвджЇГжбгГй Join ЮЌБэЕФЫузгЁЃЕБ Join
УЛгаУќжаЃЌlocal cache ВЛЛсЛКДцПеЕФНсЙћЃЌЭЌЪБНЋЪ§ОнднЪББЃДцдквЛИізДЬЌжаЃЌжЎКѓИљОнЩшжУЖЈЪБЦївдМАЫќЕФжиЪдДЮЪ§НјаажиЪдЁЃ
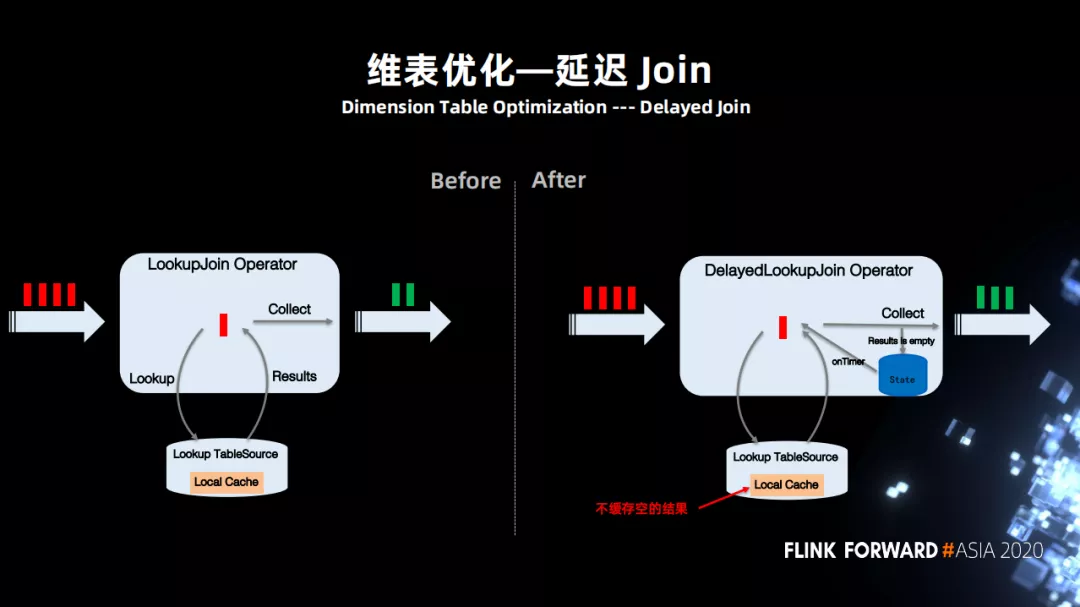
2ЁЂЮЌБэ Keyby ЙІФм

ЭЈЙ§ЭиЦЫЮвУЧЗЂЯж Cacl ЫузгКЭ lookUpJoin ЫузгЪЧ chain дквЛЦ№ЕФЁЃвђЮЊЫќУЛгавЛИі
key ЕФгявхЁЃ
ЕБзївЕВЂааЖШБШНЯДѓЃЌУПвЛИіЮЌБэ Join ЕФ subtaskЃЌЗУЮЪЕФЪЧЫљгаЕФЛКДцПеМфЃЌетбљЖдЛКДцРДЫЕгаКмДѓЕФбЙСІЁЃ
ЕЋЙлВь Join ЕФ SQLЃЌЕШжЕ Join ЪЧЬьШЛОпга Hash ЪєадЕФЁЃжБНгПЊЗХСЫХфжУЃЌдЫаагУЛЇжБНгАбЮЌБэ
Join ЕФ key зїЮЊ Hash ЕФЬѕМўЃЌНЋЪ§ОнНјааЗжЧјЁЃетбљОЭФмБЃжЄЯТгЮУПвЛИіЫузгЕФ subtask
жЎМфЕФЗУЮЪПеМфЪЧЖРСЂЕФЃЌетбљПЩвдДѓДѓЕФЬсЩ§ПЊЪМЕФЛКДцУќжаТЪЁЃ
Г§СЫвдЩЯЕФгХЛЏЃЌЛЙгаСНЕуФПЧАе§дкПЊЗЂЕФЮЌБэгХЛЏЁЃ
ЙуВЅЮЌБэЃКгааЉГЁОАЯТЮЌБэБШНЯаЁЃЌЖјЧвИќаТВЛЦЕЗБЃЌЕЋзївЕЕФ QPS ЬиБ№ИпЁЃШчЙћвРШЛЗУЮЪЭтВПЯЕЭГНјаа
JoinЃЌФЧУДбЙСІЛсЗЧГЃДѓЁЃВЂЧвЕБзївЕ Failover ЕФЪБКђ local cache ЛсШЋВПЪЇаЇЃЌНјЖјгжЖдЭтВПЯЕЭГдьГЩКмДѓЗУЮЪбЙСІЁЃФЧУДИФНјЕФЗНАИЪЧЖЈЦкШЋСП
scan ЮЌБэЃЌЭЈЙ§Join key hash ЕФЗНЪНЗЂЫЭЕНЯТгЮЃЌИќаТУПИіЮЌБэ subtask ЕФЛКДцЁЃ
Mini-BatchЃКжївЊеыЖдвЛаЉ I/O ЧыЧѓБШНЯИпЃЌЯЕЭГгжжЇГж batch ЧыЧѓЕФФмСІЃЌБШШчЫЕ
RPCЁЂHBaseЁЂRedis ЕШЁЃвдЭљЕФЗНЪНЖМЪЧж№ЬѕЕФЧыЧѓЃЌЧв Async I/O жЛФмНтОі I/O
бгГйЕФЮЪЬт,ВЂВЛФмНтОіЗУЮЪСПЕФЮЪЬтЁЃЭЈЙ§ЪЕЯж Mini-Batch АцБОЕФЮЌБэЫузгЃЌДѓСПНЕЕЭЮЌБэЙиСЊЗУЮЪЭтВПДцДЂДЮЪ§ЁЃ
Join гХЛЏ
ФПЧА Flink жЇГжЕФШ§жж Join ЗНЪНЃЛЗжБ№ЪЧ Interval JoinЁЂRegular JoinЁЂTemporal
Table FunctionЁЃ
ЧАСНжжгявхЪЧвЛбљЕФСїКЭСї JoinЁЃЖј Temporal Table ЪЧСїКЭБэЕФЕФ JoinЃЌгвБпЕФСїЛсвджїМќЕФаЮЪНаЮГЩвЛеХБэЃЌзѓБпЕФСїШЅ
Join етеХБэЃЌетбљвЛДЮ Join жЛФмгавЛЬѕЪ§ОнВЮгыВЂЧвжЛЗЕЛивЛИіНсЙћЁЃЖјВЛЪЧгаЖрЩйЬѕЖМФм Join
ЕНЁЃ
ЫќУЧжЎМфЕФЧјБ№СаСЫМИЕуЃК
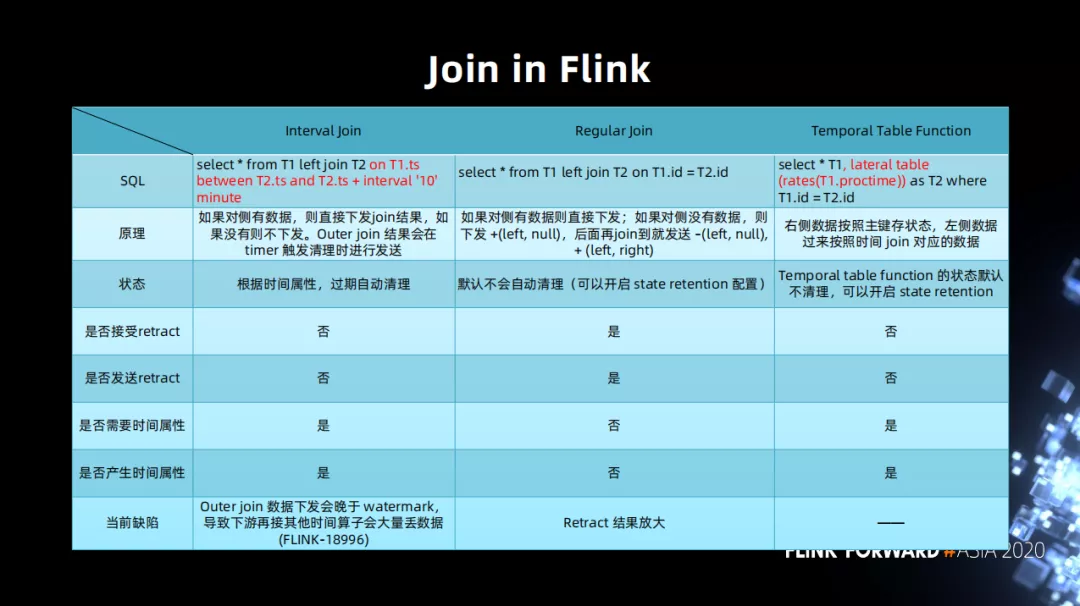
ПЩвдПДЕНШ§жж Join ЗНЪНЖМгаЫќБОЩэЕФвЛаЉШБЯнЁЃ
Interval Join ФПЧАЪЙгУЩЯЕФШБЯнЪЧЫќЛсВњЩњвЛИі out join Ъ§ОнКЭ watermark
ТвађЕФЧщПіЁЃ
Regular Join ЕФЛАЃЌЫќзюДѓЕФШБЯнЪЧ retract ЗХДѓ(жЎКѓЛсЯъЯИЫЕУїетИіЮЪЬт)ЁЃ
Temporal table function ЕФЮЪЬтНЯЦфЫќЖрвЛаЉЃЌгаШ§ИіЮЪЬтЁЃ
ВЛжЇГж DDl
ВЛжЇГж out join ЕФгявх (FLINK-7865 ЕФЯожЦ)
гвВрЪ§ОнЖЯСїЕМжТ watermark ВЛИќаТЃЌЯТгЮЮоЗЈе§ШЗМЦЫу (FLINK-18934)
ЖдгквдЩЯЕФВЛзужЎДІзжНкФкВПЖМзіСЫЖдгІЕФаоИФЁЃ
діЧП Checkpoint ЛжИДФмСІ
Ждгк SQL зївЕРДЫЕвЛЕЉЗЂЩњЬѕМўБфЛЏЖМКмФбДг checkpoint жаЛжИДЁЃ
SQL зївЕШЗЪЕДг checkpoint ЛжИДЕФФмСІБШНЯШѕЃЌвђЮЊгаЪБКђзівЛаЉПДЦ№РДВЛЬЋгАЯь checkpoint
ЕФаоИФЃЌЫќШдШЛЮоЗЈЛжИДЁЃЮоЗЈЛжИДжївЊгаСНЕуЃЛ
ЕквЛЕуЃКoperate ID ЪЧздЖЏЩњГЩЕФЃЌШЛКѓвђЮЊФГаЉдвђЕМжТЫќЩњГЩЕФ ID ИФБфСЫЁЃ
ЕкЖўЕуЃКЫузгЕФМЦЫуЕФТпМЗЂЩњСЫИФБфЃЌМДЫузгФкВПЕФзДЬЌЕФЖЈвхЗЂЩњСЫБфЛЏЁЃ
Р§зг1ЃКВЂааЖШЗЂЩњаоИФЕМжТЮоЗЈЛжИДЁЃ

source ЪЧвЛИізюГЃМћЕФгазДЬЌЕФЫузгЃЌsource ШчЙћКЭжЎКѓЕФЫузгЕФ operator chain
ТпМЗЂЩњСЫИФБфЃЌЪЧЭъШЋЮоЗЈЛжИДЕФЁЃ
ЯТЭМзѓЩЯЪЧе§ГЃЕФЩчЧјАцЕФзївЕЛсВњЩњЕФвЛИіТпМЃЌ source КЭКѓУцЕФВЂааЖШвЛбљЕФЫузгЛсБЛ chain
дквЛЦ№ЃЌгУЛЇЪЧЮоЗЈШЅИФБфЕФЁЃЕЋЫузгВЂааЖШЪЧГЃЛсЛсЗЂЩњаоИФЃЌБШШчЫЕ source гЩдРДЕФ 100 аоИФЮЊ
50ЃЌcacl ЕФВЂЗЂЪЧ 100ЁЃДЫЪБ chain ЕФТпМОЭЛсЗЂЩњБфЛЏЁЃ
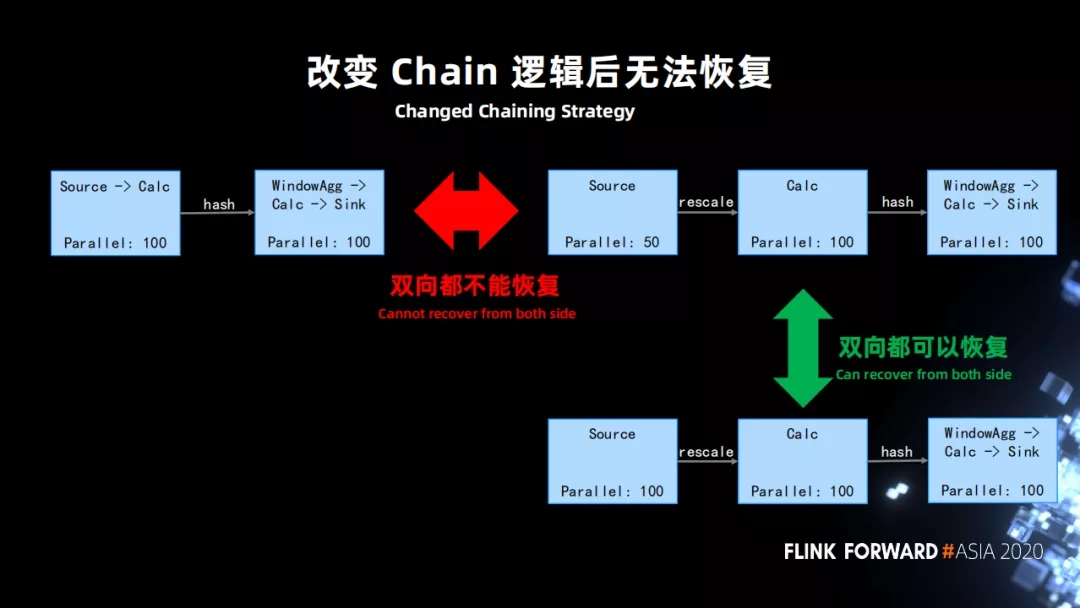
еыЖдетжжЧщПіЃЌзжНкФкВПзіСЫаоИФЃЌдЪаэгУЛЇШЅХфжУЃЌМДЪЙ source ЕФВЂааЖШИњКѓУцећЬхЕФзївЕЕФВЂааЖШЪЧвЛбљЕФЃЌвВШУЦфВЛгыжЎКѓЕФЫузг
chain дквЛЦ№ЁЃ
Р§зг2ЃКDAG ИФБфЕМжТЮоЗЈЛжИДЁЃ
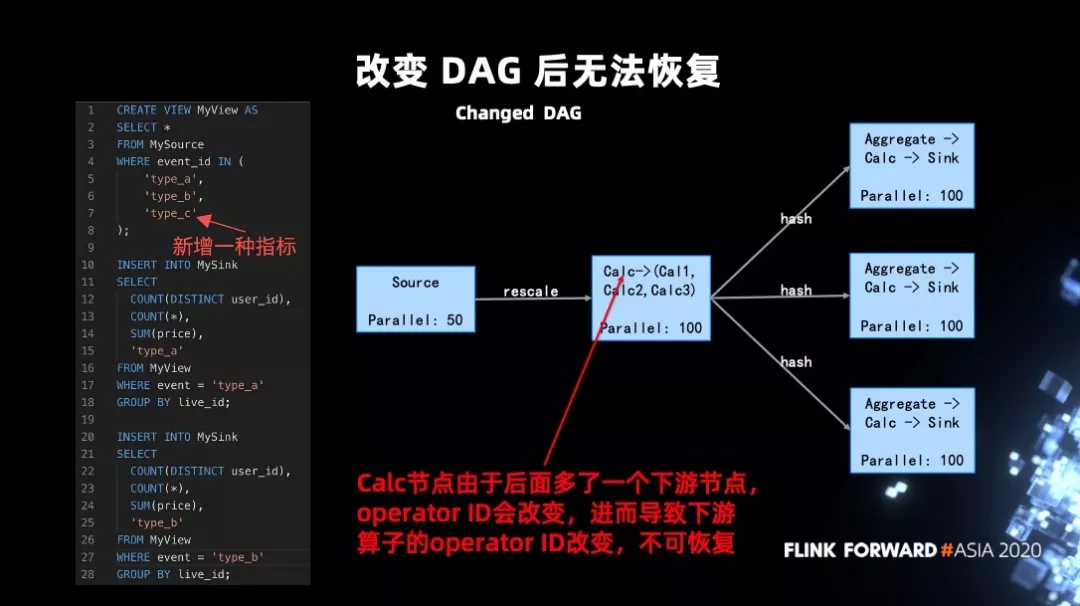
етЪЧвЛжжБШНЯЬиЪтЕФЧщПіЃЌгавЛЬѕ SQL (ЩЯЭМ)ЃЌПЩвдПДЕН source УЛгаЗЂЩњБфЛЏЃЌжЎКѓЕФШ§ИіОлКЯЛЅЯржЎМфУЛгаЙиЯЕЃЌзДЬЌОЙШЛвВЪЧЮоЗЈЛжИДЁЃ
зївЕжЎЫљвдЮоЗЈЛжИДЃЌЪЧвђЮЊ operator ID ЩњГЩЙцдђЕМжТЕФЁЃФПЧА SQL жа operator
ID ЕФЩњГЩЕФЙцдђгыЩЯгЮЁЂБОЩэХфжУвдМАЯТгЮПЩвд chain дквЛЦ№ЕФЫузгЕФЪ§СПЖМгаЙиЯЕЁЃ вђЮЊаТдіжИБъЃЌЛсЕМжТаТдівЛИі
Calc ЕФЯТгЮНкЕуЃЌНјЖјЕМжТ operator ID ЗЂЩњБфЛЏЁЃ
ЮЊСЫДІРэетжжЧщПіЃЌжЇГжСЫвЛжжЬиЪтЕФХфжУФЃЪНЃЌдЪаэгУЛЇХфжУЩњГЩ operator ID ЕФЪБКђПЩвдКіТдЯТгЮ
chain дквЛЦ№ЫузгЪ§СПЕФЬѕМўЁЃ
Р§зг3ЃКаТдіОлКЯжИБъЕМжТЮоЗЈЛжИД
етПщЪЧгУЛЇЫпЧѓзюДѓЕФЃЌвВЪЧзюИДдгЕФВПЗжЁЃгУЛЇЦкЭћаТдівЛаЉОлКЯжИБъКѓЃЌдРДЕФжИБъвЊФмДг checkpoint
жаЛжИДЁЃ
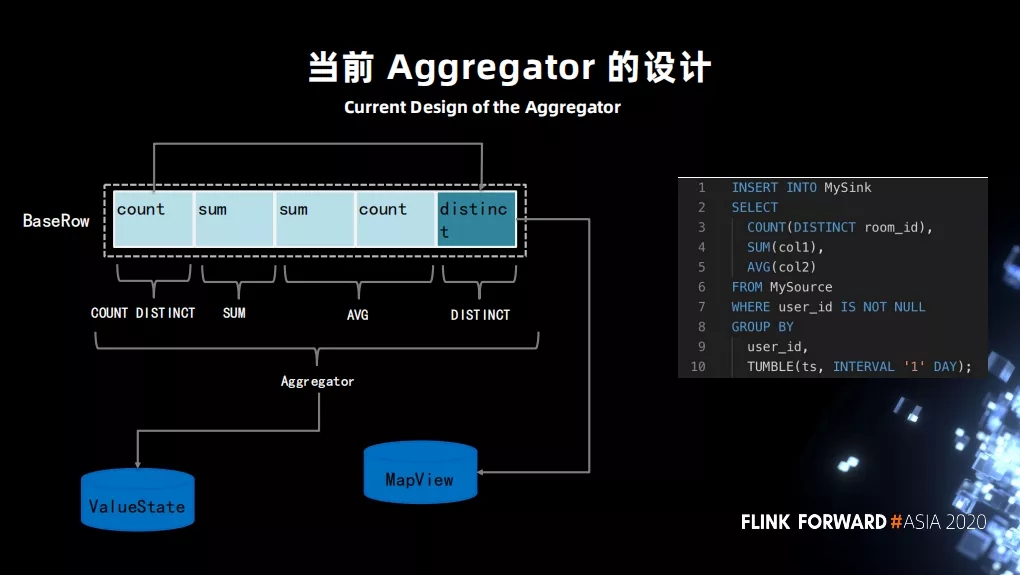
ПЩвдПДЕНЭМжазѓВПЗжЪЧ SQL ЩњГЩЕФЫузгТпМЁЃcountЃЌsumЃЌsumЃЌcountЃЌdistinct
ЛсвдвЛИі BaseRow ЕФНсЙЙДцДЂдк ValueState жаЁЃdistinct БШНЯЬиЪтвЛаЉЃЌЛЙЛсЕЅЖРДцДЂдквЛИі
MapState жаЁЃ
етЕМжТСЫШчаТдіЛђепМѕЩйжИБъЃЌЖМЛсЪЙдЯШЕФзДЬЌУЛАьЗЈДг ValueState жае§ГЃЛжИДЃЌвђЮЊ VauleState
жаДцДЂЕФзДЬЌ ЁАschemaЁБ КЭаТЕФЃЈаоИФжИБъКѓЃЉЕФ ЁАschemaЁБВЛЦЅХфЃЌЮоЗЈе§ГЃЗДађСаЛЏЁЃ
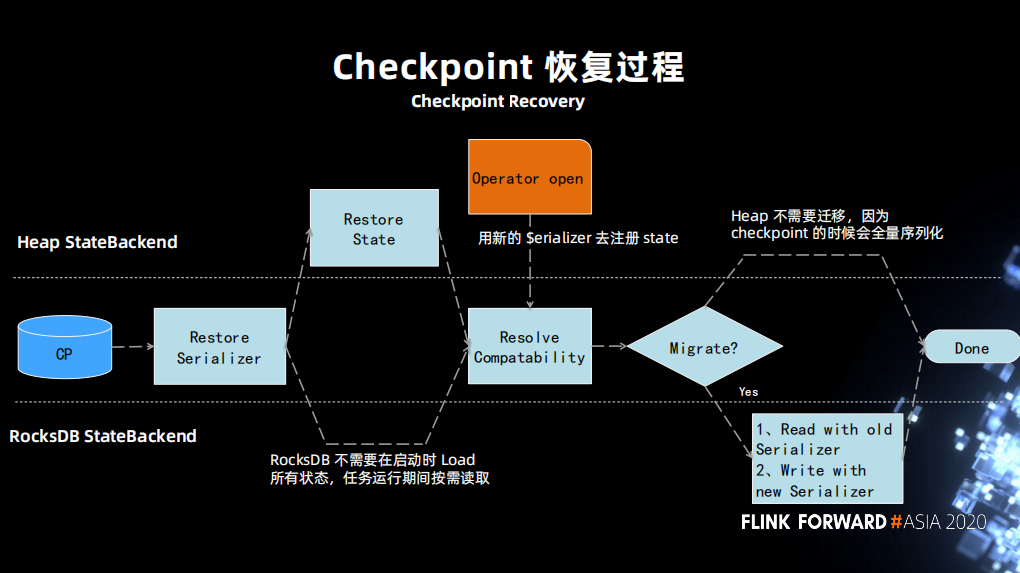
дкЬжТлНтОіЗНАИжЎЧАЃЌЮвУЧЯШЛиЙЫвЛЯТе§ГЃЕФЛжИДСїЁЃЯШДг checkpoint жаЛжИДГізДЬЌЕФ serializerЃЌдйЭЈЙ§
serializer АбзДЬЌЛжИДЁЃНгЯТРД operator ШЅзЂВсаТЕФзДЬЌЖЈвхЃЌаТЕФзДЬЌЖЈвхЛсКЭдЯШЕФзДЬЌЖЈвхНјаавЛИіМцШнадЖдБШЃЌШчЙћЪЧМцШндђзДЬЌЛжИДГЩЙІЃЌШчЙћВЛМцШндђХзГівьГЃШЮЮёЪЇАмЁЃ
ВЛМцШнЕФСэвЛжжДІРэЧщПіЪЧдЪаэЗЕЛивЛИі migrationЃЈЪЕЯжСНИіВЛЦЅХфРраЭЕФзДЬЌЛжИДЃЉФЧУДвВПЩвдЛжИДГЩЙІЁЃ
еыЖдЩЯУцЕФСїГЬзіГіЖдгІЕФаоИФЃК
ЕквЛВНЪЙаТОЩ serializer ЛЅЯржЊЕРЖдЗНЕФаХЯЂЃЌЬэМгвЛИіНгПкЃЌЧваоИФСЫ statebackend
resolve compatibility ЕФЙ§ГЬЃЌАбОЩЕФаХЯЂДЋЕнИјаТЕФЃЌВЂЪЙЦфЛёШЁећИі migrate
Й§ГЬЁЃ
ЕкЖўВНХаЖЯаТРЯжЎМфЪЧЗёМцШнЃЌШчЙћВЛМцШнЪЧЗёашвЊзівЛДЮ migrationЁЃШЛКѓШУОЩЕФ serializer
ШЅЛжИДвЛБщзДЬЌЃЌВЂЪЙгУаТЕФ serializer аДШыаТЕФзДЬЌЁЃ
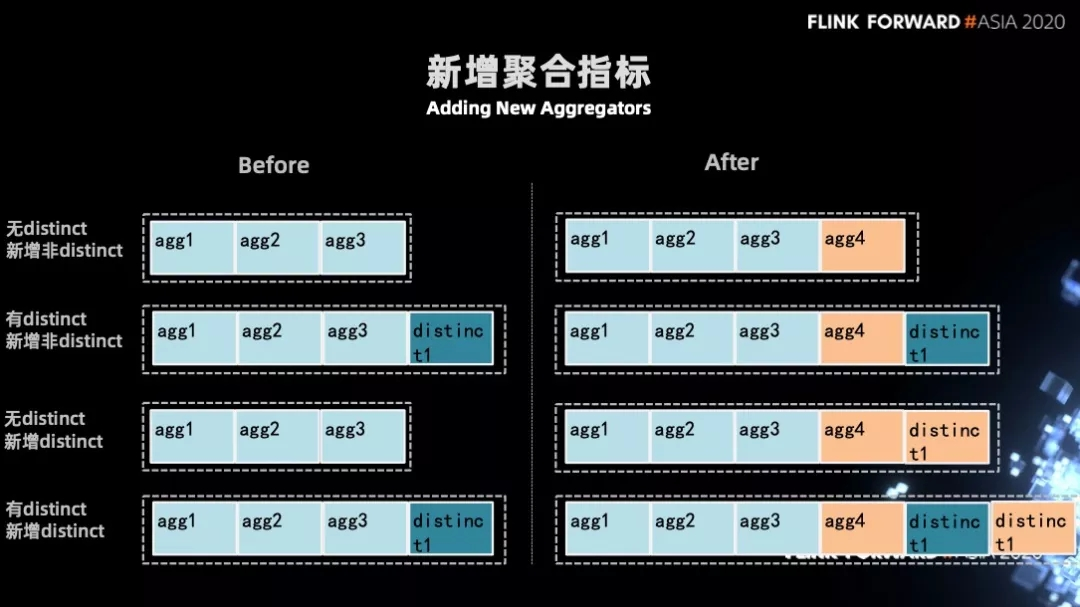
Жд aggregation ЕФДњТыЩњГЩНјааДІРэЃЌЕБЗЂЯж aggregation ФУЕНЕФЪЧжИБъЪЧ nullЃЌФЧУДНЋзівЛаЉГѕЪМЛЏЕФЙЄзїЁЃ
ЭЈЙ§вдЩЯЕФаоИФЛљБООЭПЩвдзіЕНе§ГЃЕФЃЌаТдіЕФОлКЯжИБъДгВ№ПЊЕФЗНАИЛжИДЁЃ
Ш§ЁЂСїХњвЛЬхЬНЫї
вЕЮёЯжзД
зжНкЬјЖЏФкВПЖдСїХњвЛЬхКЭвЕЮёЭЦЙужЎЧАЃЌММЪѕЭХЖгЬсЧАзіСЫДѓСПММЪѕЗНУцЕФЬНЫїЁЃећЬхХаЖЯЪЧ SQL етвЛВуЪЧПЩвдзіЕНСїХњвЛЬхЕФгявхЃЌЕЋЪЕМљжаШДгжЗЂЯжВЛЩйВЛЭЌЁЃ
БШШчЫЕСїМЦЫуЕФ session windowЃЌЛђЪЧЛљгкДІРэЪБМфЕФ windowЃЌдкХњМЦЫужаЮоЗЈзіЕНЁЃЭЌЪБ
SQL дкХњМЦЫужавЛаЉИДдгЕФ over windowЃЌдкСїМЦЫужавВУЛгаЖдгІЕФЪЕЯжЁЃ
ЕЋетаЉЬиБ№ЕФГЁОАПЩФмжЛеМ 10% ЩѕжСИќЩйЃЌЫљвдгУ SQL ШЅТфЪЕСїХњвЛЬхЪЧПЩааЕФЁЃ

СїХњвЛЬх
етеХЭМЪЧБШНЯГЃМћЕФКЭДѓЖрЪ§ЙЋЫОРяЕФМмЙЙЖМРрЫЦЁЃетжжМмЙЙгаЪВУДШБЯнФиЃП
Ъ§ОнВЛЭЌдДЃКХњШЮЮёвЛАуЛсгавЛДЮЧАжУДІРэШЮЮёЃЌВЛЙмЪЧРыЯпЕФвВКУЪЕЪБЕФвВКУЃЌдЄЯШНјЙ§вЛВуМгЙЄКѓаДШы HiveЁЃЖјЪЕЪБШЮЮёЪЧДг
kafka ЖСШЁдЪМЕФЪ§ОнЃЌПЩФмЪЧ json ИёЪНЃЌвВПЩФмЪЧ avro ЕШЕШЁЃжБНгЕМжТХњШЮЮёжаПЩжДааЕФ
SQL дкСїШЮЮёжаУЛгаНсЙћЩњГЩЛђепжДааНсЙћВЛЖдЁЃ
МЦЫуВЛЭЌдДЃКХњШЮЮёвЛАуЪЧ Hive + Spark ЕФМмЙЙЃЌЖјСїШЮЮёЛљБОЖМЪЧЛљгк FlinkЁЃВЛЭЌЕФжДаав§ЧцдкЪЕЯжЩЯЖМЛсгавЛаЉВювьЃЌЕМжТНсЙћВЛвЛжТЁЃВЛЭЌЕФжДаав§ЧцгаВЛЭЌЕФ
API ЖЈвх UDFЃЌЫќУЧжЎМфвВЪЧЮоЗЈБЛЙЋгУЕФЁЃДѓВПЗжЧщПіЯТЖМЪЧЮЌЛЄСНЬзЛљгкВЛЭЌ API ЪЕЯжЕФЯрЭЌЙІФмЕФ
UDFЁЃ
МјгкЩЯУцЕФЮЪЬтЃЌЬсГіСЫЛљгк Flink ЕФСїХњвЛЬхМмЙЙРДНтОіЁЃ
Ъ§ОнВЛЭЌдДЃКСїЪНДІРэЯШЭЈЙ§ Flink ДІРэжЎКѓаДШы MQ ЙЉЯТгЮСїЪН Flink job ШЅЯћЗбЃЌЖдгкХњЪНДІРэгЩ
Flink ДІРэКѓСїЪНаДШыЕН HiveЃЌдйгЩХњЪНЕФ Flink job ШЅДІРэЁЃ
в§ЧцВЛЭЌдДЃКМШШЛЖМЪЧЛљгк Flink ПЊЗЂЕФСїЪНЃЌХњЪН jobЃЌздШЛУЛгаМЦЫуВЛЭЌдДЮЪЬтЃЌЭЌЪБвВБмУтСЫЮЌЛЄЖрЬзЯрЭЌЙІФмЕФ
UDFЁЃ
Лљгк Flink ЪЕЯжЕФСїХњвЛЬхМмЙЙЃК
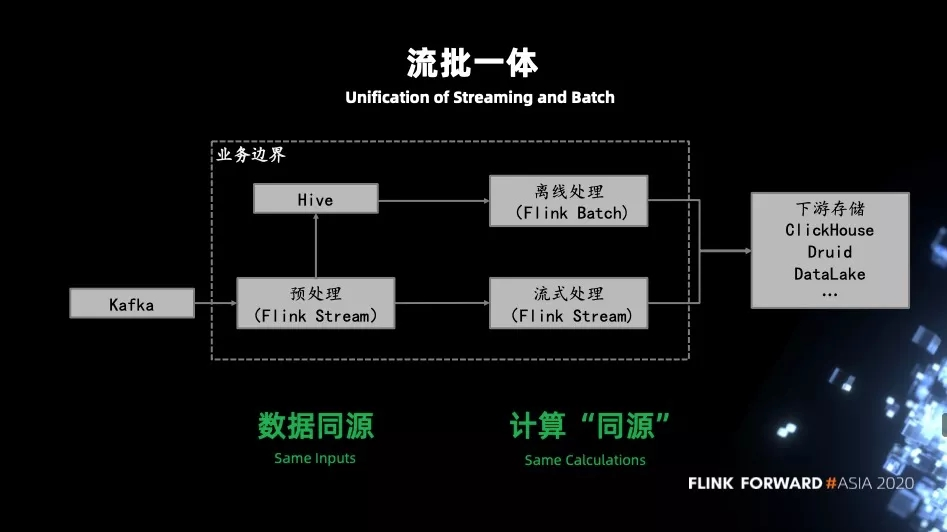
вЕЮёЪевц
ЭГвЛЕФ SQLЃКЭЈЙ§вЛЬз SQL РДБэДяСїКЭХњМЦЫуСНжжГЁОАЃЌМѕЩйПЊЗЂЮЌЛЄЙЄзїЁЃ
ИДгУ UDFЃКСїЪНКЭХњЪНМЦЫуПЩвдЙВгУвЛЬз UDFЁЃетЖдвЕЮёРДЫЕЪЧгаЛ§МЋвтвхЕФЁЃ
в§ЧцЭГвЛЃКЖдгквЕЮёЕФбЇЯАГЩБОКЭМмЙЙЕФЮЌЛЄГЩБОЖМЛсНЕЕЭКмЖрЁЃ
гХЛЏЭГвЛЃКДѓВПЗжЕФгХЛЏЖМЪЧПЩвдЭЌЪБзїгУдкСїЪНКЭХњЪНМЦЫуЩЯЃЌБШШчЖд plannerЁЂoperator
ЕФгХЛЏСїКЭХњПЩвдЙВЯэЁЃ
ЫФЁЂЮДРДЙЄзїКЭЙцЛЎ
гХЛЏ retract ЗХДѓЮЪЬт

ЪВУДЪЧ retract ЗХДѓЃП
ЩЯЭМга 4 еХБэЃЌЕквЛеХБэНјааШЅжиВйзї (Dedup)ЃЌжЎКѓЗжБ№КЭСэЭтШ§еХБэзі JoinЁЃТпМБШНЯМђЕЅЃЌБэ
A ЪфШы(A1)ЃЌзюКѓВњГі (A1,B1,C1,D1) ЕФНсЙћЁЃ
ЕББэ A ЪфШывЛИі A2ЃЌвђЮЊ Dedup ЫузгЃЌЕМжТЪ§ОнашвЊШЅжиЃЌдђЯђЯТгЮЗЂЫЭвЛИіГЗЛи A1 ЕФВйзї
-(A1) КЭвЛИіаТді A2 ЕФВйзї +(A2)ЁЃЕквЛИі Join ЫузгЪеЕН -(A1) КѓЛсНЋ -(A1)
БфГЩ -(A1,B1) КЭ +(null,B1)(ЮЊСЫБЃГжЫќШЯЮЊЕФе§ШЗгявх) ЗЂЫЭЕНЯТгЮЁЃжЎКѓгжЪеЕНСЫ
+(A2) ЃЌдђгжЯђЯТгЮЗЂЫЭ -(null,B1) КЭ +(A2,B1) етбљВйзїОЭЗХДѓСЫСНБЖЁЃдйОгЩЯТгЮЕФЫузгВйзїЛсвЛжББЛЗХДѓЃЌЕНзюжеЕФ
sink ЪфГіПЩФмЛсБЛЗХДѓ 1000 БЖжЎЖрЁЃ
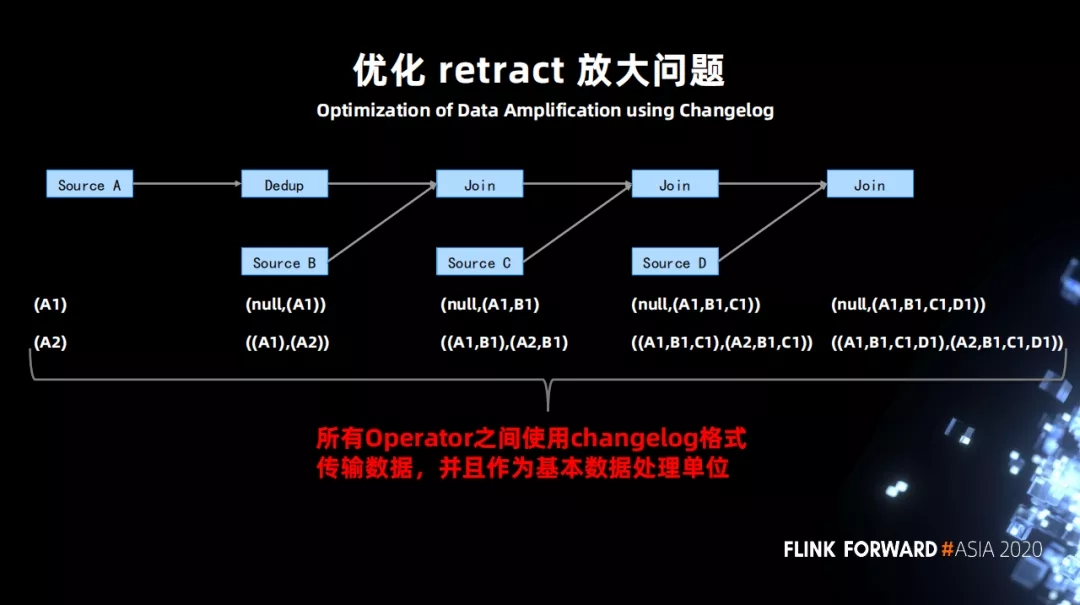
ШчКЮНтОіЃП
НЋдЯШ retract ЕФСНЬѕЪ§ОнБфГЩвЛЬѕ changelog ЕФИёЪНЪ§ОнЃЌдкЫузгжЎМфДЋЕнЁЃЫузгНгЪеЕН
changelog КѓДІРэБфИќЃЌШЛКѓНіНіЯђЯТгЮЗЂЫЭвЛИіБфИќ changelog МДПЩЁЃ
ЮДРДЙцЛЎ

1.ЙІФмгХЛЏ
жЇГжЫљгаРраЭОлКЯжИБъБфИќЕФ checkpoint ЛжИДФмСІ
window local-global
ЪТМўЪБМфЕФ Fast Emit
ЙуВЅЮЌБэ
ИќЖрЫузгЕФ Mini-Batch жЇГж:ЮЌБэЃЌTopNЃЌJoin ЕШ
ШЋУцМцШн Hive SQL гяЗЈ
2.вЕЮёРЉеЙ
НјвЛВНЭЦЖЏСїЪН SQL ДяЕН 80%
ЬНЫїТфЕиСїХњвЛЬхВњЦЗаЮЬЌ
ЭЦЖЏЪЕЪБЪ§ВжБъзМЛЏ
|









