| БрМЭЦМі: |
БОЮФНЋДгДѓЪ§ОнМмЙЙБфЧЈРњЪЗЃЌPravega
МђНщЃЌPravega НјНзЬиадвдМАГЕСЊЭјЪЙгУГЁОАетЫФИіЗНУцНщЩм PravegaЃЌжиЕуНщЩм
DellEMC ЮЊКЮвЊбаЗЂ PravegaЃЌPravega НтОіСЫДѓЪ§ОнДІРэЦНЬЈЕФФФаЉЭДЕувдМАгы
Flink НсКЯЛсХізВГідѕбљЕФЛ№ЛЈЁЃ
БОЮФРДздFlink жаЮФЩчЧј ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
БОЮФНЋДгДѓЪ§ОнМмЙЙБфЧЈРњЪЗЃЌPravega МђНщЃЌPravega
НјНзЬиадвдМАГЕСЊЭјЪЙгУГЁОАетЫФИіЗНУцНщЩм PravegaЃЌжиЕуНщЩм DellEMC ЮЊКЮвЊбаЗЂ PravegaЃЌPravega
НтОіСЫДѓЪ§ОнДІРэЦНЬЈЕФФФаЉЭДЕувдМАгы Flink НсКЯЛсХізВГідѕбљЕФЛ№ЛЈЁЃ
ДѓЪ§ОнМмЙЙБфЧЈ
Lambda МмЙЙжЎЭД
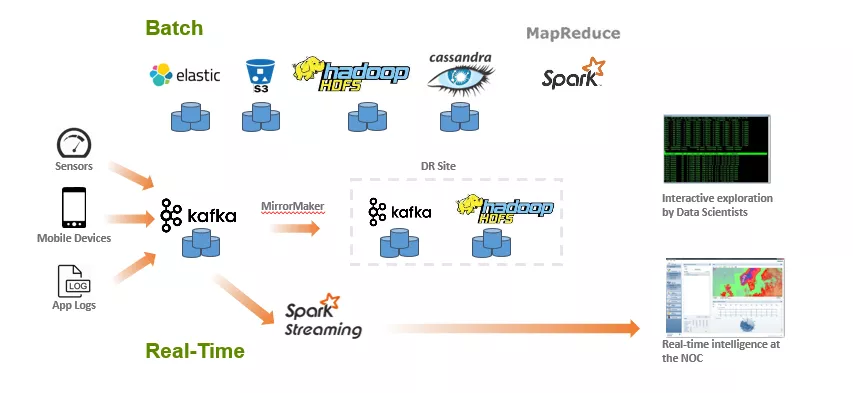
ШчКЮгааЇЕиЬсШЁКЭЬсЙЉЪ§ОнЃЌЪЧДѓЪ§ОнДІРэгІгУМмЙЙЪЧЗёГЩЙІЕФЙиМќжЎДІЁЃгЩгкДІРэЫйЖШКЭЦЕТЪЕФВЛЭЌЃЌЪ§ОнЕФЩуШЁашвЊЭЈЙ§СНжжВпТдРДНјааЁЃЩЯЭМОЭЪЧЕфаЭЕФ
LambdaМмЙЙЃКАбДѓЪ§ОнДІРэМмЙЙЗжЮЊХњДІРэКЭЪЕЪБСїДІРэСНЬзЖРСЂЕФМЦЫуЛљДЁМмЙЙЁЃ
ЖдгкЪЕЪБДІРэРДЫЕЃЌРДздДЋИаЦїЃЌвЦЖЏЩшБИЛђепгІгУШежОЕФЪ§ОнЭЈГЃаДШыЯћЯЂЖгСаЯЕЭГЃЈШч Kafka),
ЯћЯЂЖгСаИКд№ЮЊСїДІРэгІгУЬсЙЉЪ§ОнЕФСйЪБЛКГхЁЃШЛКѓдйЪЙгУ Spark Streaming Дг Kafka
жаЖСШЁЪ§ОнзіЪЕЪБЕФСїМЦЫуЁЃЕЋгЩгк Kafka ВЛЛсвЛжББЃДцРњЪЗЪ§ОнЃЌвђДЫШчЙћгУЛЇЕФЩЬвЕТпМЪЧНсКЯРњЪЗЪ§ОнКЭЪЕЪБЪ§ОнЭЌЪБзіЗжЮіЃЌФЧУДетЬѕСїЫЎЯпЪЕМЪЩЯЪЧУЛгаАьЗЈЭъГЩЕФЁЃвђДЫЮЊСЫВЙГЅЃЌашвЊЖюЭтПЊБйвЛЬѕХњДІРэЕФСїЫЎЯпЃЌМДЭМжа"
Batch "ВПЗжЁЃ
ЖдгкХњДІРэетЬѕСїЫЎЯпРДЫЕЃЌМЏКЯСЫЗЧГЃЖрЕФЕФПЊдДДѓЪ§ОнзщМўШч ElasticSearch, Amazon
S3, HDFS, Cassandra вдМА Spark ЕШЁЃжївЊМЦЫуТпМЪЧЪЧЭЈЙ§ Spark РДЪЕЯжДѓЙцФЃЕФ
Map-Reduce ВйзїЃЌгХЕудкгкНсЙћБШНЯОЋШЗЃЌвђЮЊПЩвдНсКЯЫљгаРњЪЗЪ§ОнРДНјааМЦЫуЗжЮіЃЌШБЕудкгкбгГйЛсБШНЯДѓЁЃ
етЬзОЕфЕФДѓЪ§ОнДІРэМмЙЙПЩвдзмНсГіШ§ИіЮЪЬтЃК
СНЬѕСїЫЎЯпДІРэЕФбгГйЯрВюНЯДѓЃЌЮоЗЈЭЌЪБНсКЯСНЬѕСїЫЎЯпНјаабИЫйЕФОлКЯВйзїЃЌЭЌЪБНсКЯРњЪЗЪ§ОнКЭЪЕЪБЪ§ОнЕФДІРэадФмЕЭЯТЁЃ
Ъ§ОнДцДЂГЩБОДѓЁЃЖјдкЩЯЭМЕФМмЙЙжаЃЌЯрЭЌЕФЪ§ОнЛсдкЖрИіДцДЂзщМўжаЖМДцдквЛЗнЛђЖрЗнПНБДЃЌЪ§ОнЕФШпгрЮовЩЛсДѓДѓдіМгЦѓвЕПЭЛЇЕФГЩБОЁЃВЂЧвПЊдДДцДЂЕФЪ§ОнШнДэКЭГжОУЛЏПЩППадвЛжБвВЪЧжЕЕУЩЬШЖЕФЕиЗНЃЌЖдгкЪ§ОнАВШЋУєИаЕФЦѓвЕгУЛЇРДЫЕЃЌашвЊбЯИёБЃжЄЪ§ОнЕФВЛЖЊЪЇЁЃ
жиИДПЊЗЂЁЃЭЌбљЕФДІРэСїГЬБЛСНЬѕСїЫЎЯпНјааСЫСНДЮЃЌЯрЭЌЕФЪ§ОнНіНівђЮЊДІРэЪБМфВЛЭЌЖјвЊдкВЛЭЌЕФПђМмФкЗжБ№МЦЫувЛДЮЃЌЮовЩЛсдіМгЪ§ОнПЊЗЂепжиИДПЊЗЂЕФИКЕЃЁЃ
СїЪНДцДЂЕФЬиЕу
дке§ЪННщЩм Pravega жЎЧАЃЌЪзЯШМђЕЅЬИЬИСїЪНЪ§ОнДцДЂЕФвЛаЉЬиЕуЁЃ
ШчЙћЮвУЧЯывЊЭГвЛСїХњДІРэЕФДѓЪ§ОнДІРэМмЙЙЃЌЦфЪЕЖдДцДЂгаЛьКЯЕФвЊЧѓЁЃ
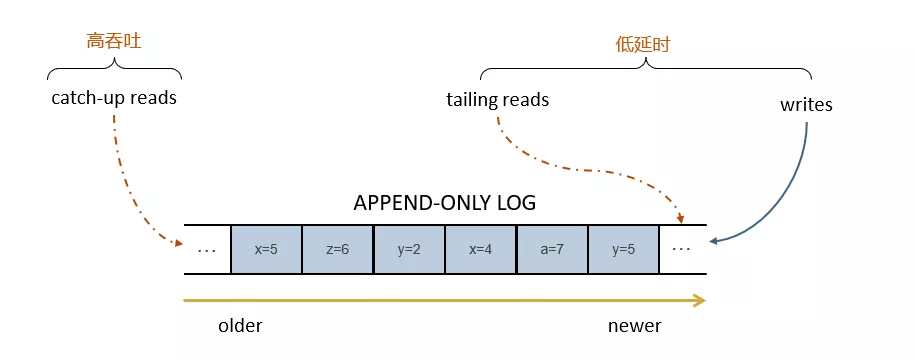
ЖдгкРДздађСаОЩВПЗжЕФРњЪЗЪ§ОнЃЌашвЊЬсЙЉИпЭЬЭТЕФЖСадФмЃЌМД catch-up read
ЖдгкРДздађСааТВПЗжЕФЪЕЪБЪ§ОнЃЌашвЊЬсЙЉЕЭбгГйЕФ append-only ЮВаД tailing write
вдМАЮВЖС tailing read
жиЙЙЕФСїЪНДцДЂМмЙЙ
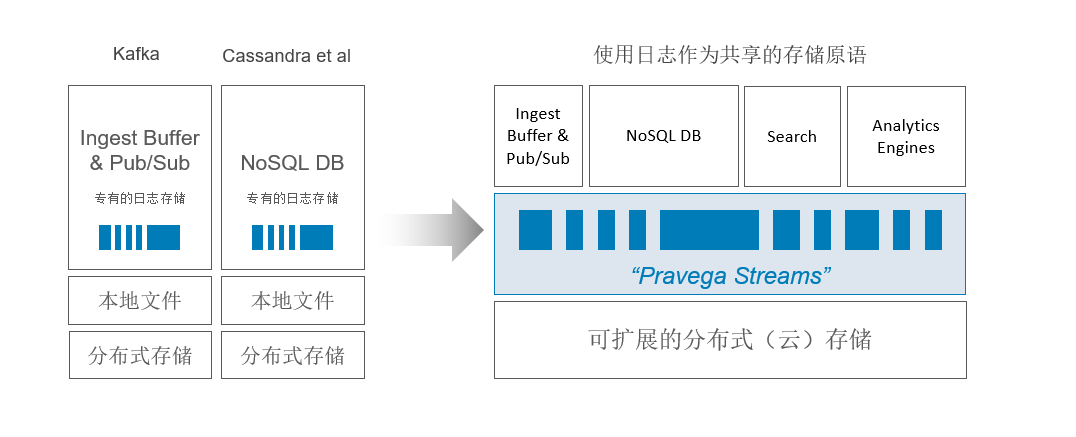
Яё KafkaЃЌCassandra ЕШЗжВМЪНДцДЂзщМўРДЫЕЃЌЦфДцДЂМмЙЙЖМДгЩЯЭљЯТзёбДгзЈгаЕФШежОДцДЂЃЌЕНБОЕиЮФМўЃЌдйЕНМЏШКЩЯЕФЗжВМЪНДцДЂЕФетжжФЃЪНЁЃ
Жј Pravega ЭХЖгЪдЭМжиЙЙСїЪНДцДЂЕФМмЙЙЃЌв§Шы Pravega Stream етвЛГщЯѓИХФюзїЮЊСїЪНЪ§ОнДцДЂЕФЛљБОЕЅЮЛЁЃStream
ЪЧУќУћЕФЁЂГжОУЕФЁЂНізЗМгЕФЁЂЮоЯоЕФзжНкађСаЁЃ
ШчЩЯЭМЫљЪОЃЌДцДЂМмЙЙзюЕзВуЪЧЛљгкПЩРЉеЙЗжВМЪНдЦДцДЂЃЌжаМфВуБэЪОШежОЪ§ОнДцДЂЮЊ Stream РДзїЮЊЙВЯэЕФДцДЂдгяЃЌШЛКѓЛљгк
Stream ПЩвдЯђЩЯЬсЙЉВЛЭЌЙІФмЕФВйзї:ШчЯћЯЂЖгСаЃЌNoSQLЃЌСїЪНЪ§ОнЕФШЋЮФЫбЫївдМАНсКЯ Flink
РДзіЪЕЪБКЭХњЗжЮіЁЃЛЛОфЛАЫЕЃЌPravega ЬсЙЉЕФ Stream дгяПЩвдБмУтЯжгаДѓЪ§ОнМмЙЙжадЪМЪ§ОндкЖрИіПЊдДДцДЂЫбЫїВњЦЗжавЦЖЏЖјВњЩњЕФЪ§ОнШпгрЯжЯѓЃЌЦфдкДцДЂВуОЭЭъГЩСЫЭГвЛЕФЪ§ОнКўЁЃ
жиЙЙЕФДѓЪ§ОнМмЙЙ
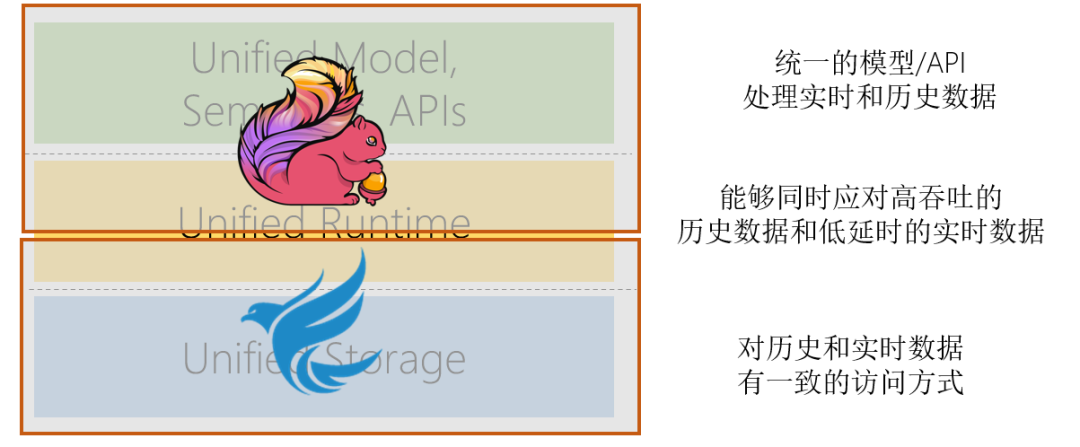
ЮвУЧЬсГіЕФДѓЪ§ОнМмЙЙЃЌвд Apache Flink зїЮЊМЦЫув§ЧцЃЌЭЈЙ§ЭГвЛЕФФЃаЭ/APIРДЭГвЛХњДІРэКЭСїДІРэЁЃвд
Pavega зїЮЊДцДЂв§ЧцЃЌЮЊСїЪНЪ§ОнДцДЂЬсЙЉЭГвЛЕФГщЯѓЃЌЪЙЕУЖдРњЪЗКЭЪЕЪБЪ§ОнгавЛжТЕФЗУЮЪЗНЪНЁЃСНепЭГвЛаЮГЩСЫДгДцДЂЕНМЦЫуЕФБеЛЗЃЌФмЙЛЭЌЪБгІЖдИпЭЬЭТЕФРњЪЗЪ§ОнКЭЕЭбгЪБЕФЪЕЪБЪ§ОнЁЃЭЌЪБ
Pravega ЭХЖгЛЙПЊЗЂСЫ Flink-Pravega ConnectorЃЌЮЊМЦЫуКЭДцДЂЕФећЬзСїЫЎЯпЬсЙЉ
Exactly-Once ЕФгявхЁЃ
Pravega МђНщ
Pravega ЕФЩшМЦзкжМЪЧЮЊСїЕФЪЕЪБДцДЂЬсЙЉНтОіЗНАИЁЃгІгУГЬађНЋЪ§ОнГжОУЛЏДцДЂЕН Pravega
жаЃЌPravega ЕФ Stream ПЩвдгаЮоЯожЦЕФЪ§СПВЂЧвГжОУЛЏДцДЂШЮвтГЄЪБМфЃЌЪЙгУЭЌбљЕФ Reader
API ЬсЙЉЮВЖС (tail read) КЭзЗИЯЖС (catch-up read) ЙІФмЃЌФмЙЛгааЇТњзуРыЯпМЦЫуКЭЪЕЪБМЦЫуСНжжДІРэЗНЪНЕФЭГвЛЁЃ
Pravega ЛљБОИХФю
НсКЯЩЯЭММђвЊНщЩм Pravega ЕФЛљБОИХФюЃК
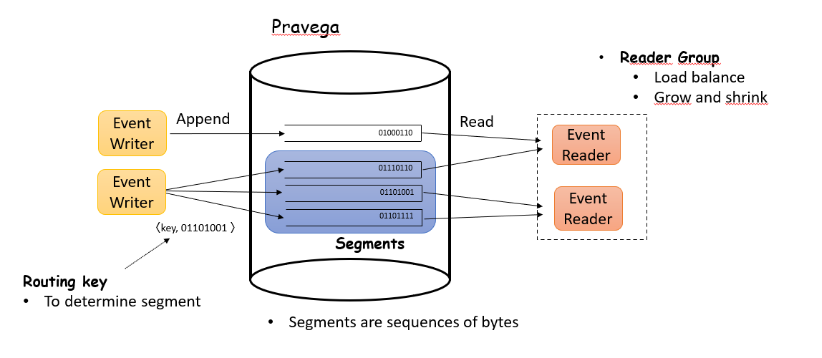
Stream
Pravega ЛсАбаДШыЕФЪ§ОнзщжЏГЩ Stream,Stream ЪЧУќУћЕФЁЂГжОУЕФЁЂНізЗМгЕФЁЂЮоЯоЕФзжНкађСаЁЃ
Stream Segments
Pravega Stream ЛсЛЎЗжЮЊвЛИіЛђЖрИі SegmentsЃЌЯрЕБгк Stream жаЪ§ОнЕФЗжЦЌЃЌЫќЪЧвЛИі
append-only ЕФЪ§ОнПщЃЌЖј Pravega вВЪЧЛљгк Segment ЛљДЁЩЯЪЕЯжздЖЏЕФЕЏадЩьЫѕЁЃSegment
ЕФЪ§СПвВЛсИљОнЪ§ОнЕФСїСПНјааздЖЏЕФСЌајИќаТЁЃ
Event
Pravega's client API дЪаэгУЛЇвд Event ЮЊЛљБОЕЅЮЛаДШыКЭЖСШЁЪ§ОнЃЌEvent
ОпЬхЪЧStream ФкВПзжНкСїЕФМЏКЯЁЃШч IOT ДЋИаЦїЕФвЛДЮЮТЖШМЧТМаДШы Pravega ОЭПЩвдРэНтГЩЮЊвЛИі
Event.
Routing Key
УПвЛИі Event ЖМЛсгавЛИі Routing KeyЃЌЫќЪЧгУЛЇздЖЈвхЕФвЛИізжЗћДЎЃЌгУРДЖдЯрЫЦЕФ
Event НјааЗжзщЁЃгЕгаЯрЭЌ Routing Key ЕФ Event ЖМЛсБЛаДШыЯрЭЌЕФ Stream
Segment жаЁЃPravega ЭЈЙ§ Routing Key РДЬсЙЉЖСаДгявхЁЃ
Reader Group
гУгкЪЕЯжЖСШЁЪ§ОнЕФИКдиОљКтЁЃПЩвдЭЈЙ§ЖЏЬЌдіМгЛђМѕЩй Reader Group жа ReaderЕФЪ§СПРДИФБфЖСШЁЪ§ОнЕФВЂЗЂЖШЁЃИќЮЊЯъЯИЕФНщЩмЧыВЮПМ
Pravega ЙйЗНЮФЕЕЃК
http://pravega.io/docs/latest/pravega-concepts
Pravega ЯЕЭГМмЙЙ
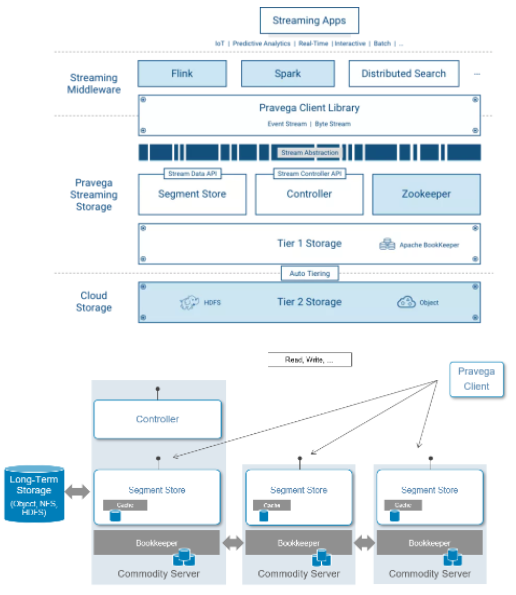
дкПижЦВуУцЃЌController зїЮЊ Pravega МЏШКЕФжїНкЕуЖдЪ§ОнВуУцЕФ Segment
StoreзіЙмРэЃЌЬсЙЉЖдСїЪ§ОнЕФДДНЈЃЌИќаТвдМАЩОГ§ЕШВйзїЁЃЭЌЪБЫќЛЙГаЕЃЪЕЪБМрВтМЏШКНЁПЕзДЬЌЃЌЛёШЁСїЪ§ОнаХЯЂЃЌЪеМЏМрПижИБъЕШЙІФмЁЃЭЈГЃМЏШКжаЛсга3Зн
Controller РДБЃжЄИпПЩгУЁЃ
дкЪ§ОнВуУцЃЌSegment Store ЬсЙЉЖСаД Stream ФкЪ§ОнЕФ APIЁЃдк Pravega
РяУцЃЌЪ§ОнЪЧЗжВуДцДЂЕФЃК
Tier 1 ДцДЂ
Tier1 ЕФДцДЂЭЈГЃВПЪ№дк Pravega МЏШКФкВПЃЌжївЊЪЧЬсЙЉЖдЕЭбгГйЃЌЖЬЦкЕФШШЪ§ОнЕФДцДЂЁЃдкУПИі
Segment Store НсЕуЖМга Cache вдМгПьЪ§ОнЖСШЁЫйТЪЃЌPravega ЪЙгУApache
Bookeeper РДБЃжЄЕЭбгГйЕФШежОДцДЂЗўЮёЁЃ
Long-term ДцДЂ
Long-term ЕФДцДЂЭЈГЃВПЪ№дк Pravega МЏШКЭтВПЃЌжївЊЪЧЬсЙЉЖдСїЪ§ОнЕФГЄЦкДцДЂЃЌМДРфЪ§ОнЕФДцДЂЁЃВЛНіжЇГж
HDFSЃЌNFSЃЌЛЙЛсжЇГжЦѓвЕМЖЕФДцДЂШч Dell EMCЕФ ECSЃЌIsilon ЕШВњЦЗЁЃ
Pravega НјНзЬиад
ЖСаДЗжРы
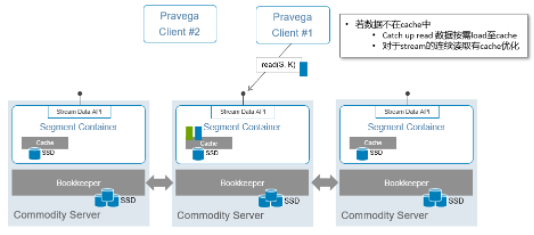
дк Tier1 ДцДЂВПЗжЃЌаДШыЪ§ОнЕФЪБКђЭЈЙ§ Bookkeeper БЃжЄСЫЪ§ОнвбОдкЫљгаЕФ Segment
Store жаТфХЬЃЌБЃжЄСЫЪ§ОнаДШыГЩЙІЁЃ
ЖСаДЗжРыгажњгкгХЛЏЖСаДадФмЃКжЛДг Tier1 ЕФ Cache КЭ Long-term ДцДЂШЅЖСЃЌВЛШЅЖС
Tier1 жаЕФ BookkeeperЁЃ
дкПЭЛЇЖЫЯђ Pravega ЗЂЦ№ЖСЪ§ОнЕФЧыЧѓЕФЪБКђЃЌPravega ЛсОіЖЈетИіЪ§ОнОПОЙЪЧДгTier1
ЕФ Cache НјааЕЭбгЪБЕФ tail-readЃЌЛЙЪЧШЅ Long-term ЕФГЄЦкДцДЂЪ§Он(ЖдЯѓДцДЂ/NFS)ШЅНјаавЛИіИпЭЬЭТСПЕФ
catch-up readЃЈШчЙћЪ§ОнВЛдк CacheЃЌашвЊАДашload ЕН Cache жаЃЉЁЃЖСВйзїЪЧЖдПЭЛЇЖЫЭИУїЕФЁЃ
Tier1 ЕФ Bookkeeper дкМЏШКВЛГіЯжЙЪеЯЕФЧщПіЯТгРдЖВЛНјааЖСШЁВйзїЃЌжЛНјаааДШыВйзїЁЃ
ЕЏадЩьЫѕ
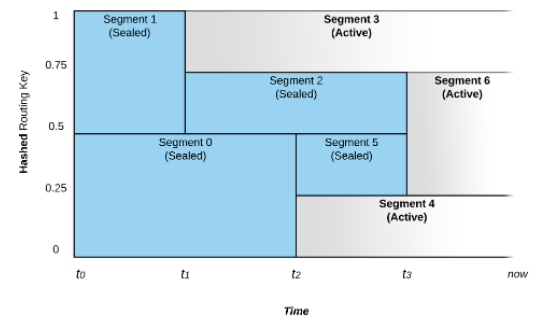
Stream жаЕФ Segment Ъ§СПЛсЫцзХ IO ИКдиЖјНјааЕЏадЕФздЖЏЩьЫѕЁЃвдЩЯЭМЮЊР§згМђЕЅВћЪіЃК
Ъ§ОнСїдк t0 ЪБПЬаДШы PravegaЃЌИљОнТЗгЩМќЪ§ОнЛсТЗгЩЕН Segment0 КЭSegment1
жаЃЌШчЙћЪ§ОнаДШыЫйЖШБЃГжКуЖЈВЛБфЃЌФЧУД Segemnt Ъ§СПВЛЛсЗЂЩњБфЛЏЁЃ
дк t1 ЪБПЬЯЕЭГИажЊЕН segment1 Ъ§ОнаДШыЫйТЪМгПьЃЌгкЪЧНЋЦфЛЎЗжЮЊСНИіВПЗж:Segment2
КЭ Segment3ЁЃетЪБКђ Segment1 ЛсНјШы Sealed зДЬЌЃЌВЛдйНгЪмаДШыЪ§ОнЃЌЪ§ОнЛсИљОнТЗгЩМќЗжБ№жиЖЈЯђЕН
Segment2 КЭ Segment3.
гы Scale-Up ВйзїЯрЖдгІЃЌЯЕЭГвВПЩвдИљОнЪ§ОнаДШыЫйЖШБфТ§КѓЬсЙЉ Scale-Down ВйзїЁЃШчдк
t3 ЪБПЬЯЕЭГ Segment2 КЭ Segment5 аДШыСїСПМѕЩйЃЌвђДЫКЯВЂГЩаТЕФ Segment6ЁЃ
ЖЫЕНЖЫЕФЕЏадЩьЫѕ
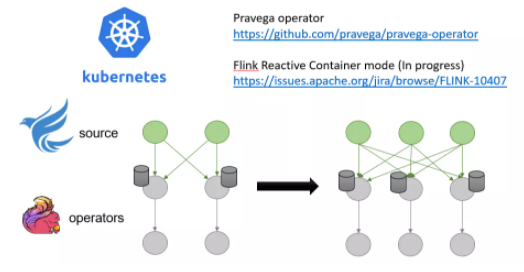
Pravega ЪЧвд Kubernetes Operator РДЖдМЏШКИїзщМўНјаагазДЬЌЕФгІгУВПЪ№ЃЌетПЩвдЪЙЕУгІгУЕФЕЏадЩьЫѕИќЮЊСщЛюЗНБуЁЃ
Pravega зюНќвВдкКЭ Ververica НјааЩюЖШКЯзї,жТСІгкдк Pravega ЖЫЪЕЯж Kubernetes
Pod МЖБ№ЕФЕЏадЩьЫѕЭЌЪБдк Flink ЖЫЭЈЙ§ rescaling Flink ЕФ Task Ъ§СПРДЪЕЯжЕЏадЩьЫѕЁЃ
ЪТЮёадаДШы
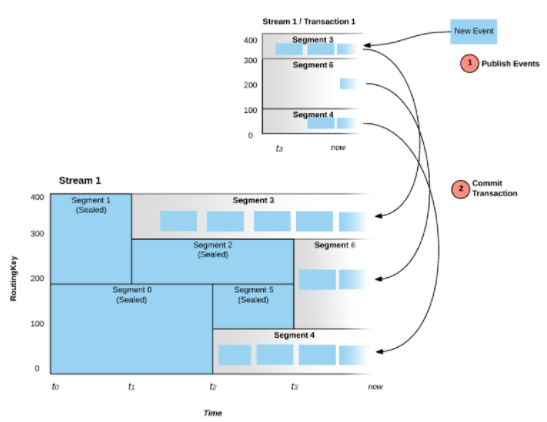
Pravega ЭЌбљЬсЙЉЪТЮёадЕФаДШыВйзїЁЃдкЬсНЛЪТЮёжЎЧАЃЌЪ§ОнЛсИљОнТЗгЩМќаДШыЕНВЛЭЌЕФ Transaction
Segment жаЃЌетЪБКђ Segment Ждгк Reader РДЫЕЪЧВЛПЩМћЕФЁЃжЛгадкЪТЮёЬсНЛжЎКѓЃЌTransaction
Segment ВХЛсИїздзЗМгЕН Stream Segment ЕФФЉЮВЃЌетЪБКђ Segment Ждгк
Reader ВХЪЧПЩМћЕФЁЃаДШыЪТЮёЕФжЇГжвВЪЧЪЕЯжгы Flink ЕФЖЫЕНЖЫ Exactly-Once
гявхЕФЙиМќЁЃ
Pravega vs. Kafka
< 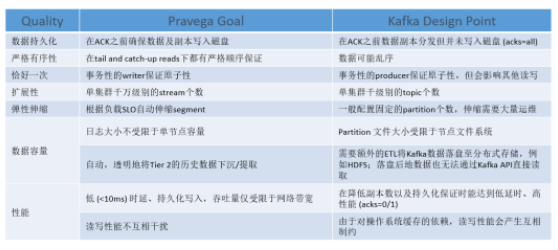
ЪзЯШзюЙиМќЕФВЛЭЌдкгкСНепЕФЖЈЮЛЃКKafka ЕФЖЈЮЛЪЧЯћЯЂЖгСаЃЌЖј Pravega ЕФЖЈЮЛЪЧДцДЂЃЌЛсИќЙизЂгкЪ§ОнЕФЖЏЬЌЩьЫѕЃЌАВШЋадЃЌЭъећадЕШДцДЂЬиадЁЃ
ЖдгкСїЪНЪ§ОнДІРэРДЫЕЃЌЪ§ОнгІИУБЛЪгЮЊСЌајКЭЮоЯоЕФЁЃKafka зїЮЊЛљгкБОЕиЮФМўЯЕЭГЕФвЛИіЯћЯЂЖгСаЃЌЭЈЙ§ВЩгУЬэМгЕНШежОЮФМўЕФФЉЮВВЂИњзйЦфФкШн(
offset ЛњжЦ)ЕФЗНЪНРДФЃФтЮоЯоЕФЪ§ОнСїЁЃШЛЖјетжжЗНЪНБиШЛЪмЯогкБОЕиЮФМўЯЕЭГЕФЮФМўУшЪіЗћЩЯЯовдМАДХХЬШнСПЃЌвђДЫВЂЗЧЮоЯоЁЃ
ЖјСНепЕФБШНЯдкЭМжаИјГіСЫБШНЯЯъЯИЕФзмНсЃЌВЛдйзИЪіЁЃ
Pravega Flink Connector
ЮЊСЫИќЗНБугы Flink ЕФНсКЯЪЙгУЃЌЮвУЧЛЙЬсЙЉСЫ Pravega Flink ConnectorЃЈhttps://github.com/pravega/flink-connectors),
Pravega ЭХЖгЛЙМЦЛЎНЋИУ Connector ЙБЯзЕН Flink ЩчЧјЁЃConnector ЬсЙЉвдЯТЬиадЃК
Жд Reader КЭ Writer ЖМЬсЙЉСЫ Exactly-once гявхБЃжЄЃЌШЗБЃећЬѕСїЫЎЯпЖЫЕНЖЫЕФ
Exactly-Once
гы Flink ЕФ checkpoints КЭ savepoints ЛњжЦЕФЮоЗьёюКЯ
жЇГжИпЭЬЭТЕЭбгГйЕФВЂЗЂЖСаД
Table API РДЭГвЛЖд Pravega Sream ЕФСїХњЭГвЛДІРэ
ГЕСЊЭјЪЙгУГЁОА
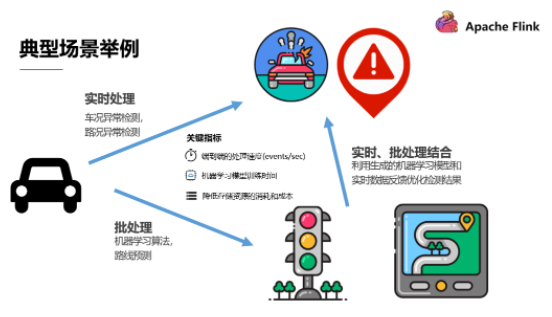
вдЮоШЫМнЪЛГЕСЊЭјетжжФмЙЛВњЩњКЃСП PB МЖЪ§ОнЕФгІгУГЁОАЮЊР§ЃК
ашвЊЖдГЕПіТЗПіЪ§ОнзіЪЕЪБЕФДІРэвдМАЪБЖдТЗЯпЙцЛЎзіГіЮЂЙлЕФдЄВтКЭЙцЛЎ
ашвЊЖдНЯГЄЦкааЪЛЪ§ОндЫааЛњЦїбЇЯАЫуЗЈРДзіТЗЯпЕФКъЙлдЄВтКЭЙцЛЎЃЌетЪєгкХњДІРэ
ЭЌЪБашвЊНсКЯЪЕЪБДІРэКЭХњДІРэЃЌРћгУРњЪЗЪ§ОнЩњГЩЕФЛњЦїбЇЯАФЃаЭКЭЪЕЪБЪ§ОнЗДРЁРДгХЛЏМьВтНсЙћ
ЖјПЭЛЇЙизЂЕФЙиМќжИБъжївЊдкЃК
ШчКЮБЃжЄИпаЇЕиЖЫЕНЖЫДІРэЫйЖШ
ШчКЮОЁПЩФмМѕЩйЛњЦїбЇЯАФЃаЭЕФбЕСЗЪБМф
ШчКЮОЁПЩФмНЕЕЭДцДЂЪ§ОнЕФЯћКФгыГЩБО
ЯТУцИјГів§Шы Pravega ЧАКѓЕФНтОіЗНАИБШНЯЁЃ
НтОіЗНАИБШНЯ
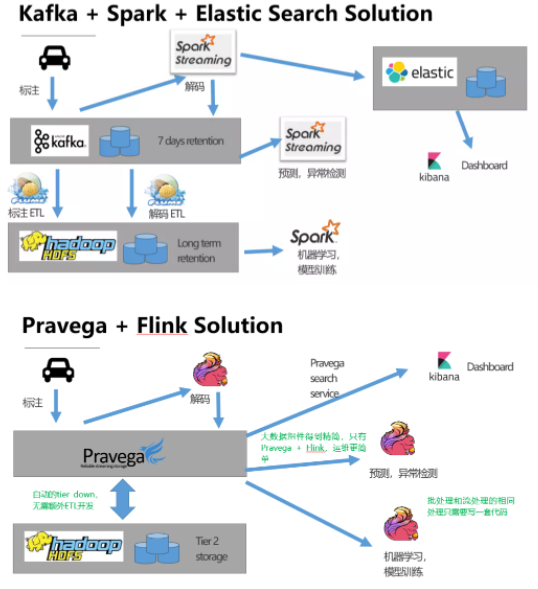
Pravega ЕФв§ШыЮовЩДѓДѓМђНрСЫДѓЪ§ОнДІРэЕФМмЙЙЃК
Pravega зїЮЊГщЯѓЕФДцДЂНгПкЃЌЪ§Ондк Pravega ВуОЭЪЕЯжСЫвЛИіЪ§ОнКўЃКХњДІРэ,ЪЕЪБДІРэКЭШЋЮФЫбЫїЖМжЛашвЊДг
Pravega жаЛёШЁЪ§ОнЁЃЪ§ОнжЛдк Pravega ДцДЂвЛЗнЃЌЖјВЛашвЊЯёЕквЛжжЗНАИжаЪ§ОнШпгрЕиДцДЂдк
KafkaЃЌElasticSearch КЭ Long Term Storage жаЃЌетПЩвдМЋДѓМѕЩйСЫЦѓвЕгУЛЇЪ§ОнДцДЂЕФГЩБОЁЃ
Pravega ФмЙЛЬсЙЉздЖЏЕФ Tier DownЃЌЮоашв§Шы Flume ЕШзщМўРДНјааЖюЭтЕФ ETL
ПЊЗЂЁЃ
зщМўЕУЕНОЋМђЃЌДгдРДЕФ Kafka+Flume+HDFS+ElasticSearch+Kibana+Spark+SparkStreaming
ОЋМђЕН Pravega+Flink+Kibana+HDFS ,МѕЧсдЫЮЌШЫдБЕФдЫЮЌбЙСІЁЃ
Flink ФмЙЛЬсЙЉСїХњДІРэЭГвЛЕФЙІФмЃЌЮоашЮЊЯрЭЌЕФЪ§ОнЬсЙЉСНЬзЖРСЂЕФДІРэДњТыЁЃ
зм Нс
Flink йВШЛвбОГЩЮЊСїЪНМЦЫув§ЧцжаЕФвЛПХЩСССЕФУїаЧЃЌШЛЖјСїЪНДцДЂСьгђЩаЪЧвЛЦЌПеАзЁЃЖј Pravega
ЕФЩшМЦГѕждОЭЪЧЮЊСЫЬюЩЯДѓЪ§ОнДІРэМмЙЙетвЛЦДЭМзюКѓЕФПеАзЁЃЁАЫљгаМЦЫуЛњСьгђЕФЮЪЬтЃЌЖМПЩвдЭЈЙ§діМгвЛИіЖюЭтЕФжаМфВуГщЯѓНтОіЁБЃЌЖј
Pravega БОжЪОЭЪЧдкМЦЫув§ЧцКЭЕзВуДцДЂжЎМфГфЕБНтёюВуЃЌжМдкНтОіаТвЛДњДѓЪ§ОнЦНЬЈдкЪ§ОнДцДЂВуЩЯЕФЬєеНЁЃ
|









