| БрМЭЦМі: |
БОЮФжївЊНВНтСЫЗжЮіЪІЕФжАд№ЗЖЮЇЁЂжиЖЈвхЃЈЪ§ОнПЦбЇКЯзїЛяАщЃЉМАЪ§ОнашЧѓЕФБъзМСїГЬЁЃ
БОЮФРДзд DataDancer ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|

БОЦЊЙиМќФкШнЃЈ 2049 зжЃЌдФЖСдМ 15 ЗжжгЃЉЃК
ЗжЮіЪІЕФжАд№ЗЖЮЇ
жиЖЈвхЃКЪ§ОнПЦбЇКЯзїЛяАщ
Ъ§ОнашЧѓЕФБъзМСїГЬ
ЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦї - tapd
ЮЊЪВУДаДетЦЊЮФеТЃПЦ№вђЪЧЗжЮіЪІЭХЖгЕФ leader РыжАСЫЃЌзїЮЊДѓРЯАхЃЌЮвжЛФмбЁдёднДњЙмРэвЛЖЮЪБМфЃЈ
ВхВЅЙуИцЃКеаЦИжа ЃЉЁЃдкАяЭХЖгГЩдБЪсРэЙЄзїФкШнЕФЙ§ГЬЃЌЮвГщЯѓСЫЦфжавЛаЉЙиМќЕФвЊЫиЃЌвдМАашвЊГЮЧхЕФШЯжЊЮѓЧјЁЃетаЉзмНсЮвВЛЯыНіНіЗтБедкздМКЕФЭХЖгФкВПЃЌЛЙЯЃЭћФмАяЕНе§дкжАвЕЩњбФУдУЃЕФЗжЮіЪІУЧЁЃ
Part 1 ЗжЮіЪІЕФжАд№ЗЖЮЇ
ЮЊСЫЫЕЧхГўКѓУцХгДѓЕФТпМЬхЯЕЃЌЮвУЧЯШАбОЕЭЗРЕНдЖДІЃЌЯШДгЗжЮіЪІДІРэЕФжївЊШ§жжРраЭЙЄзїЫЕЦ№ЃК
СйЪБадЪ§ОнашЧѓЃЈЛђзЈЯюЗжЮіБЈИцЃЉ
ПьЫйПЩЪгЛЏБЈБэПЊЗЂЃЈBIЃЉ
зЈвЕНЧЖШЕФЪ§ОнЭкОђШЮЮё
МИКѕЫљгаЗжЮіЪІЖМЯЃЭћГаЕЃЕк 3 жжРраЭЙЄзїЁЃЮЊЪВУДФиЁЊЁЊетИіРраЭЕФЙЄзїЃЌНкзрИќПЩПиЃЌИДдгЖШЯрЖдНЯИпЃЌИќМгеУЯдИіШЫЕФзЈвЕМлжЕЁЃЖјЕк
1 КЭ 2 жжЙЄзїГЃГЃБЛЬљЩЯБЛЖЏЁЂЕЭМлжЕЁЂжиИДРЭЖЏетаЉБъЧЉЁЃЯШБ№МБзХЯТНсТлЃЌетИіЙлЕуБГКѓЪЧвђЮЊВЛЦЅХфЕФШЯжЊКЭСїГЬЖјЕМжТЕФЃЌШчЙћ
1 КЭ 2 ВЛФме§ШЗЕФИуЖЈЃЌВЛЖЎвЕЮёЕФФувВВЛПЩФмЭцзЊЫљЮНЕФзЈвЕЪ§ОнЭкОђШЮЮёЕФЁЃ
дкСФе§ЪТжЎЧАЯШЗжЯэвЛИіЙЪЪТЃЌЙЪЪТЕФУћзжНазіЁЖЕк 7 ИіТјЭЗЁЗЃЌЧщНкКмМђЕЅЃК
гаИіРЯЭЗЖљЖіЛЕСЫЃЌвЛСЌГдСЫ 6 ИіТјЭЗЛЙУЛГдБЅЃЌЕБЫћГдЯТЕк 7 ИіТјЭЗЪБЃЌжегкГдБЅСЫЁЃ
гкЪЧКУЪТепПЊЪМбаОПЕк 7 ИіТјЭЗЕФзіЗЈКЭгУСЯЃЌЯыДгжаЭкОђГіРЯЭЗГдБЅЕФАТУиЁЁ
етИіЙЪЪТжмКшЕtОГЃЙвдкзьБпЃЌЫфШЛЬ§Ц№РДЯёаІЛАЃЌЕЋЪЕМЪЩЯУПЬьЖМдкжиИДЩЯбнЁЃЯыЯыЮвУЧдкНЬПЦЪщЁЂЭтВПЗжЯэПДЕНЛђЬ§ЕНЕФХФАИНаОјЕФАИР§ЃЌЫќУЧЖМдкНВЕк
7 ИіТјЭЗЁЃЮвУЧЫљгаЕФЗжЮібЕСЗЃЈВЂВЛЪЧЬижИЯСвхЕФЪ§ОнЗжЮіЃЉЖМдкжИЯђбаОПЕк 7 ИіТјЭЗЕФзіЗЈКЭгУСЯЃЌЖјКіЪгСЫЧА
6 ИіТјЭЗЕФЙ§ГЬКЭзїгУЁЃ
ЁАЗВеНепЃЌвде§КЭЃЌвдЦцЪЄЁБЃЌвЛЖЈвЊНїМЧЃКЁАе§КЭЁБЪЧдкЁАЦцЪЄЁБжЎЧАЁЃСйЪБадЪ§ОнЗжЮіашЧѓОЭЪЧЧА 6 ИіТјЭЗЃЌЧЁЧЁПЩвдШУЗжЮіЪІШЋЗНЮЛЁЂЩюШыРэНтвЕЮёЮЪЬтЃЌЪЧМЋМбЕФЦѕЛњЕуЃЁ
КЫаФЕуЫЕЧхГўСЫЃЌФЧШчКЮНтЙЙФиЃПЮвУЧашвЊДгНЧЩЋЖЈЮЛЁЂЙизЂФкШнЁЂЛњжЦЕШЯИНкРДжиЫмСїГЬЁЃ
НЧЩЋЖЈЮЛКЭЛњжЦ
ДЋЭГЩЯЃЌЮвУЧвЛАуЖЈвхСЫЪ§ОнЗжЮіЪІЁЂЪ§ОнЗжЮізЈдБетСНИіНЧЩЋЁЃЕЋзаЯИЯыЯыетСНИіУћДЪЕФзжУцвтвхЃЌЮЪЬтЦфЪЕЗЧГЃДѓЃЌЫћУЧОгШЛШЋЪЧУцЯђЪ§ОнЕФЃЌЖјВЛЪЧУцЯђНтОіЮЪЬтЛђепМлжЕБОЩэЕФЃЁ
ИќЧЁЕБЕФЖЈвхЪЧЪВУДФиЃПдкЮвЕФЭХЖгЃЌЮвАбЫ§жиаТЖЈвхГЩСЫ DSPЃЈData Science PartnerЃЉЃЌЪЧХћзХЪ§ОнПЦбЇЭтвТЕФКЯзїЛяАщЁЃВЛвЊаЁПДетИіНЧЩЋЖЈвхЕФВЛЭЌЃЌетИіНЧЩЋвЊЧѓЪ§ОнЗжЮіЪІДгвЛИіБЛЖЏНгЪмашЧѓЕФЖЈЮЛжБНгЙ§ЖЩЕНКЯзїепФЃЪНЃЈЮЊСЫБЃГжааЮФКЭЙлФюЕФвЛжТадЃЌКѓУцвРШЛЛсЪЙгУЪ§ОнЗжЮіЪІЕФГЦКєЃЉЁЃ
ЪфГіОіЖЈгкЪфШыЁЃНЧЩЋжиаТЖЈвхжЎКѓЃЌЗжЮіЪІШчКЮЛёЕУИќЖрЕФаХЯЂЃПШчЙћВЛФмЙЛЕквЛЪБМфЛёШЁЙЋЫОЕФОіВпаХЯЂЃЌФЧУДЙЄзїЛЙЪЧЛсЗЧГЃБЛЖЏЁЃВЛЭЌЕФЙЋЫОгаВЛЭЌЕФВйзїЗНЗЈЃЌетРяУцИјГіНЈвщЕФВйзїВНжшЃК
РћгУКУСаЯЏЦфЫћВПУХЕФжмР§ЛсЕФЛњЛсЁЃМШШЛЖЈвхЮЊ partnerЃЌФЧУДЛяАщВПУХЕФжмР§ЛсБиаывЊШЋГЬВЮМгЃЌвдЛяАщЪгНЧЙлВьетИіВПУХШеГЃдЫзїЕФЧщПіЃЌВЛГЌЙ§вЛИідТЃЌЗжЮіЪІЛсдкФПБъШЯжЊЩЯгаГЄзуБфЛЏЁЃ
РћгУЗЧЙЄзїЪБМфЃЈШчЮчВЭЃЉЭЌЛяАщВПУХЕФЙиМќШЫЮяНјаавЛЖдвЛЗЧе§ЪНЙЕЭЈЃЌВЂГжајБЃГжЦЕТЪЁЃ
вдЩЯаХЯЂЖЈЦкЭЌЪ§ОнВПУХРЯДѓзіИќаТЃЌЕУЕНЗДРЁЁЃ
вдЩЯЖЏзїЪЭЗХИјСЫЭтВПвЛИіаХКХЃЌЮвУЧПЩвдвЛЦ№ЭЈЙ§Ъ§ОнИуЖЈвЕЮёЮЪЬтЃЌдкгаашвЊЕФЕквЛЪБМфТэЩЯПЩвдевЕНЪ§ОнЗжЮіЪІЁЃдкгааЇаХЯЂЪфШыЮЪЬтЕУЕНИФЩЦжЎКѓЃЌЗжЮіЪІНЋУцСйНгЕНашЧѓжЎКѓШчКЮИќИпаЇТЪЕФећКЯетаЉСуЩЂЁЃећКЯЕФаЇТЪКЭ
1 ФъжЎКѓЕФЗжЮіЪІМлжЕИпЖШЯрЙиЁЃ
зЂЃКЃЈЖдгкЮвЫОРДЫЕЃЉЗжЮіЪІИКд№ЕФЪЎЬѕвЕЮёЯпЗжБ№ЪЧЃКCEOЁЂЪаГЁЁЂдЫгЊЁЂЭтНЬЁЂВњЦЗЁЂбЇЪѕЁЂгУЛЇЬхбщЁЂММЪѕЃЌВЦЮёЃЌШЫСІЁЃ
Part 2 Ъ§ОнЗжЮіЕФЙЄзїСїГЬ
Ъ§ОнЗжЮіЙЄзїзюжежИЯђЕФЪЧЃЌЭЈЙ§вЕЮёЮЪЬтЕФВ№НтКЭКЯВЂЃЌзюжеаЮГЩвЕЮёжЊЪЖЭМЦзЁЃ
ЯШеыЖдгкЕЅвЛЗжЮіШЮЮёЃЌЮвАбетИіЪ§ОнЗжЮіЪІЕФЙЄзїСїГЬЛЎЗжГЩСЫАЫИізДЬЌЃЌетаЉзДЬЌЃЈЛЗНкЃЉЕФМђвЊНщЩмШчЯТЃК
аТЃКМЧТМвЕЮёЗНЗЂЦ№ЕФдЪМашЧѓ
вЕЮёШЗШЯЃККЭвЕЮёЗНЬжТлКЫаФФПЕФ
Ъ§ОндДШЗШЯЃКШЗШЯЗжЮіашвЊЕФЪ§ОндДЃЌвдМАДцДЂЪЧЗёКЯРэ
ЪЕЯжжаЃКДњТыЪЕЯжЙ§ГЬМЧТМЃЌашвЊМЧТМ gitlab дДТыЕижЗ
НЛИЖЃКТд
вбОмОјЃКТд
МлжЕЛиЙЫКЭИДХЬЃКИУЯюФПЙБЯзЕФМлжЕЃЌжиаТзівЛБщгІИУзіЪВУД
ЙвЦ№ЃКТд
"аТ" етИізДЬЌЪЧЦ№ЪМзДЬЌЃЌ"вбОмОј" КЭ "МлжЕЛиЙЫКЭИДХЬ"
етСНИізДЬЌЪЧНсЪјзДЬЌЁЃЮвУЧж№ИіЗжЮіЮЊЪВУДдкЪ§ОнЗжЮіЕФЙ§ГЬжаБиаывЊетаЉЛЗНкЃП
ЛЗНкЃКаТ
етИізДЬЌЪЧВЛзіШЮКЮЦРХаЃЌДПДтДгашЧѓЗННЧЖШЃЌжвЪЕЕФМЧТМдЪМашЧѓЁЃетРяжЛЪЧДПДтЕФМЧТМЃЌЖјВЛНјаа judgementЃЌетРяНшМјСЫORID
НЙЕуЬжТлЗЈЕФЕквЛИіВНжшЃЌЦфжаЕФАТУюЧыЖСепздааЫМПМЁЃ
ЛЗНкЃКвЕЮёШЗШЯ
етИіЛЗНкЪЧЗжЮіЪІЯдЪОздЩэЕФзЈвЕФмСІЕФЙиМќЛЗНкЃЌвВЪЧЗжЮіШЮЮёГЩАмЕФЪзвЊЙиМќВНжшЁЃгЩгкашЧѓЗНБГОАВЛЭЌЃЌЖдгкЪ§ОнШЯжЊФмСІвВВЮВюВЛЦыЁЃетРяУцЛсДцдкМИжжПЩФмЃК
вЕЮёЗНЮоЗЈУшЪіЮЪЬт
вЕЮёЗННЋКмЖрЮЪЬтЛьдгдквЛЦ№
вЕЮёЗНЧхГўУцСйЮЪЬтЃЌЕЋЮоЗЈКЭЪ§ОнНјаагГЩф
вЕЮёЗНЧхГўУцСйЮЪЬтЃЌЬсГіСЫДэЮѓЕФЪ§ОнашЧѓ
вЕЮёЗНЮоЗЈдЄХаПЩФмЕФЗжЮіНсЙћ
Ждгк 1 РрашЧѓЗНЃЌзЈвЕММФмВЛКЯИёЃЌЛсЛіКІЩЯЯТгЮЃЌfire ЕєОЭПЩвдСЫЃЌОјЖдВЛПЩвдЪжШэЁЃЃЈШчЙћФуЪЧЮвЕФЗжЮіЪІЃЌЧыИцЫпЮветИівЕЮёЪЧЫЃЉ
Ждгк 2 РрашЧѓЗНЃЌЗЧГЃЦеБщЃЌвђЮЊКмЖрШЫВЂУЛгаОЪмЙ§бЯИёЕФЯЕЭГЛЏЫМЮЌЃЌЗжЮіЪІашвЊЪЙгУ MECE ддђАяжњвЕЮёЗНЪсРэвЕЮёЃЌдкЦкМфевЕНЛњЛсЕуЁЃЭЌЪБдкЪсРэЮЪЬтЕФЭЌЪБЃЌашвЊСЫНтЧхГўЪВУДЪЧжївЊЮЪЬтЃЌЪВУДЪЧДЮвЊЮЪЬтЃПЪВУДЪЧЮЪЬтБГКѓЕФЮЪЬтЃП
ЖдгкЕк 3 РрашЧѓЗНЃЌвВЯрЖдЦеБщЃЌвЛАуЦѓвЕЪЧЭЈЙ§НЧЩЋЧАжУРДЛКНтетИіЮЪЬтЃЌЭЈГЃетИіЧАжУЕФНЧЩЋЪЧВњЦЗОРэЃЌВЛЙ§БЏОчЕФЪЧЧАжУНЧЩЋПЩФмВЛКЯИёЃЌетЪБгжашвЊЗжЮіЪІдк~Ъ§ОндДШЗШЯ~ЛЗНкИјГізЈвЕНЈвщЁЃ
Ек 4 РрвЕЮёЗНЕФЮЪЬтКЭЕк 3 жжКмЯёЃЌЕЋашвЊЕЅЖРЬсГіРДЃЌЯыЯывЛЯТЃЌЖдЗНЬсСЫвЛИіДэЮѓЕФЪ§ОнашЧѓЃЌЕЋзїЮЊЗжЮіЪІЕФФуОгШЛЦЏССЕижДааЭъГЩСЫЁЁШЛКѓвЕЮёЗНВЛТњвтЃЌгжЬсСЫвЛБщЃЌПЩФмЛЙгаЕкШ§БщЁЁаТЪжЗжЮіЪІгІИУУЛЩйГдЙ§етИібЦАЭПїЁЃ
ЖдгкЕк 5 РрЃЌЮвУЧЪЕМЪЩЯЖдвЕЮёЗНЬсГіСЫИќИпЕФвЊЧѓЃЌетБГКѓЕФТпМгаСНВуЃК
вЕЮёЗНЪЧЗёгЮШагагрЕФеЦПивЕЮёКЭЪ§ОнжЎМфЕФЫљгаПЩФмЙиЯЕЃЛ
ШчЙћгаКЭдЄЦквЛжТЕФЪ§ОнЗжЮіНсЙћЃЌФЧУДНгЯТРДЕФааЖЏЗНАИЪЧЗёжЕЕУжДааЁЃ
ШчЙћвдЩЯСНЕувЕЮёЗНАбПиЕФЗЧГЃЭъУРЃЌВЛТлФуЪЧЗёЪЧзЪЩюЪ§ОнЗжЮіЪІЃЌИЯНєБЇДѓЭШЃЁШчЙћДѓЭШВЛжЊЕРдѕУДБЇЃЌЫНаХЮвЁЃ
ЛЗНкЃКЪ§ОндДШЗШЯ
етИіЛЗНкПЩФмЛсгавдЯТМИИіЮЪЬтЃК
ЦкЭћЕФЪ§ОндкММЪѕВуУЛгаДцДЂ
гаЪ§ОнЃЌЕЋЪ§ОнЗжЩЂдкЪ§ОнВжПтЕФВЛЭЌЮЛжУ
Ек 1 ИіЮЪЬтдкГѕДДЙЋЫОБШНЯГЃМћЃЌЕквЛд№ШЮШЫЪЧбаЗЂЃЌЫГДЮЪЧВњЦЗОРэЃЌдйДЮЪЧвЕЮёЗНЁЃШчЙћзїЮЊЗжЮіЪІИуЖЈСЫетИіЪ§ОндДЮЪЬтЃЌФуЪЕМЪдкБфЯрАяжњВњЦЗОРэКЭвЕЮёЗНЃЌЩѕжСЪЧбаЗЂЁЃОУЖјОУжЎЃЌФуЕФММЪѕВуУцгАЯьСІЛсЕУЕНГжајЧПЛЏЁЃ
Ек 2 ИіЮЪЬтЬхЯжСЫЪ§ОнВжПтЩшМЦЕФВЛЭъБИЁЃетжжЧщПіЯТЃЌЪзЯШХаЖЯЪЧЗёЪЧОГЃадЮЪЬтЃЌШчЙћВЛЪЧЃЌСйЪБНтОіМДПЩЃЛШчЙћЪЧЃЌгаСНжжВпТдЃК
ИцжЊЪ§ОнВжПтПЊЗЂЖдгІИКд№ШЫЃЌЕШД§дЄЦкЪ§ОнНсЙћЕФНЛИЖЃЛ
жїЖЏСЫНтЕзВуЕФЪ§ОнТпМЃЌдк ODS ВузіЖўДЮДІРэЃЌдкСйЪБЪ§ОнВуаЮГЩНсЙћМЏЃЌзюжеНЋЙЄГЬЛЏЕФДњТыНЛИЖЪ§ОнВжПтЭХЖгЁЃ
ПМТЧЕНЗжЮіЪІЭХЖгвЛАуЭЌВжПтЭХЖгСЅЪєгкЭЌвЛИіДѓВПУХЃЌГжајБЃГжетИіЯАЙпЃЌвВЛсдіЧПЗжЮіЪІЕФФкВПгАЯьСІЁЃ
ЛЗНкЃКЪЕЯжжа
етИіВНжшашвЊЧПЕїЕФЕуЪЧШчКЮРћгУ git ЙмРэКУздМКЕФЗжЮіДњТыЃЌвд R ЮЊР§ЃЌОЁСПЪЙгУ magrittrЁЂ
dplyrЁЂ dtplyr етРрЕФАќЃЌБЃжЄЪ§ОнДІРэЕФУПИіВНжшЕФПЩЖСадЁЃЭЌЪББЃжЄДњТыФкЕФзЂЪЭвдМА git
commit ЕФаХЯЂЭъећадЁЃ
ЗжЮіЪІЛсЭЈЙ§ HIVE SQL ЬсШЁЪ§ОнЃЌдйЭЈЙ§ R НјааДІРэЃЌШчКЮЩшМЦШЁЪ§ТпМЃЌРћгУКУ HIVE
SQL КЭ R СНжжЙЄОпЕФИїздгХЕуЃЌЬсИпЪ§ОнДІРэЕФПЩРэНтадКЭЫйЖШЃЌПМбщЕФОЭЪЧЛљБОЙІСЫЁЃ
етРяЖрНВвЛЯТЙЄОпЕФЪЙгУЃЌШчЙћДѓСПЪЙгУ R Notebook етРрЙЄОпЃЌЛсШУФуЕФаЇТЪДѓДѓЬсИпЁЃ
ЛЗНкЃКНЛИЖ
ЧПЕїЮоЪ§ДЮЃК
ДгЪ§ОнЕННсТлЃЁ
ШчЙћЗжЮіЪІУЛгаНсТлдђВЛФмГЦжЎЮЊНЛИЖЁЃНЛИЖЕФаЮЪНгаЮФЕЕЁЂЛУЕЦЦЌЁЂгЪМўЃЌВЛЭЌНЛИЖаЮЪНЛсгавЛаЉВЛвЛбљЕФвЊЧѓЃЌЖдгкЗжЮіЪІРДЫЕЛУЕЦЦЌНЛИЖвЊЧѓзюИпЁЃЮДРДПЩФмЛсзЈУХаДЦЊЮФеТРДНВЪіШчКЮзіЛУЕЦЦЌЃЈзЂвт
slides ВЛЕШгк PPTЃЉЁЃ
НЛИЖЕФФкШнДгвЊЫиЩЯРДЫЕАќКЌЮФзжЁЂБэИёЁЂЭМаЮЁЃЮФзжФкШнВПЗжЪЧдквЕЮёШЗШЯЛЗНкжаЪсРэЕФТпМЩюЖШЃЌБэИёвВВЛЯъЯИзИЪіЃЌдкЗжЮіЕФЙ§ГЬШчКЮШЗЖЈвЛеХКЯРэЕФЭМаЮФиЃПетРяУцгавЛаЉЬзТЗЃЌЭЕРССЫЃЌжБНгИјГівЛИіЧАШЫзмНсЕФОбщЃК
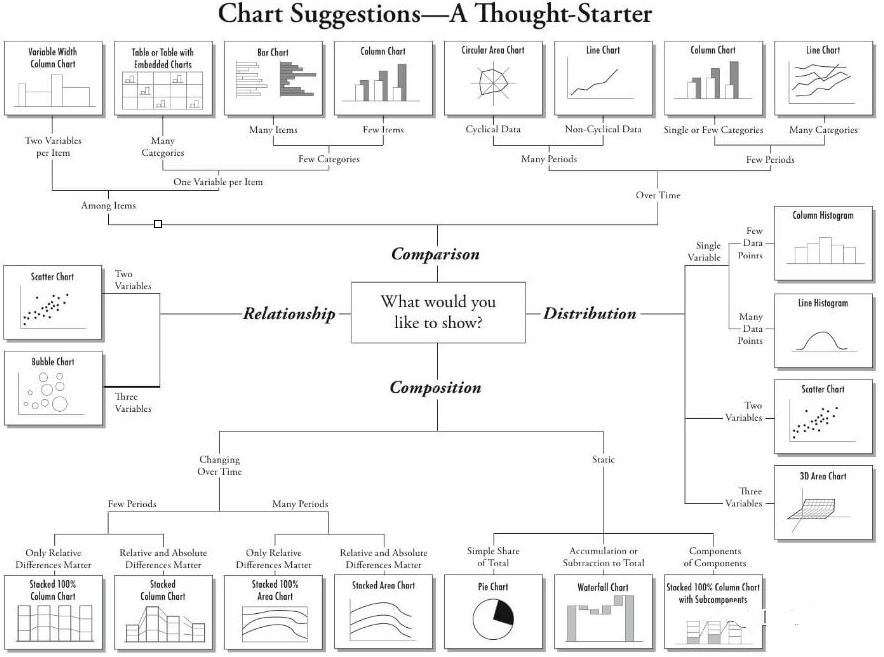
ЛЗНкЃКМлжЕЛиЙЫКЭИДХЬ
ГѕМЖЗжЮіЪІОГЃЛсдкетИіЛЗНкГіЯжЪЇЮѓЃЌЮвОГЃдк review ИїЮЛЗжЮіЪІЯюФПЪБЛсЗЂЯжЃЌКмЖрЯюФПЛсЭЃжЭдк~НЛИЖ~етИіЛЗНкЃЌЯАЙпЕФСІСПЬЋПЩХТЁЃетИіЛЗНкЕФСНИіЙиМќЕуЃКМлжЕЕФХаЖЯКЭИДХЬЁЃ
МлжЕХаЖЯжСЩйДцдкСНЗНУцПМСПЃК
ЭЈЙ§ЗжЮіЕУЕНЕФЙиМќе§ШЗОіВпЃЌгАЯьЙЋЫОФГЯюНјГЬЕФжБНгМлжЕЁЃЖЭСЖЕФЪЧЗжЮіЪІвЕЮё sense ФмСІЃЛ
ИіШЫгаЯоЕФЪБМфДјРДЕФЪевцЃЌЭЖШыВњГіБШЁЃЖЭСЖЕФЪЧЗжЮіЪІЪБМфЙцЛЎФмСІКЭХаЖЯСІЁЃ
ИДХЬЃЈAfter Action ReviewЃЉетИіЛАЬтКмДѓЃЌдкетИіНкЕуЮвУЧЩдЩдОлНЙвЛЯТЃК
ЮЊЪВУДКЭГѕЪМЕФФПБъЯрВюКмдЖЃПЙиМќЕФЪТМўЪЧЪВУДЃП
жиаТзівЛБщетИіашЧѓЃЌФФаЉааЮЊашвЊПЊЪМзіЃПФФаЉЪТЧщашвЊЭЃжЙзіЃПФФаЉЪТЧщашвЊГжајзіЃП
вдЩЯВЛЯогкММЪѕЁЂСїГЬЁЂЛЗОГЁЂзщжЏЁЂШЫдБЕФвЛЧавђЫиЁЃ
зДЬЌЕФСїзЊ
вбОмОјКЭЙвЦ№СНжжзДЬЌВЛзіИќЖрЕФзИЪіЁЃзюКѓЮвУЧдйПДПДет 8 ИізДЬЌЕФСїзЊЙиЯЕЃК
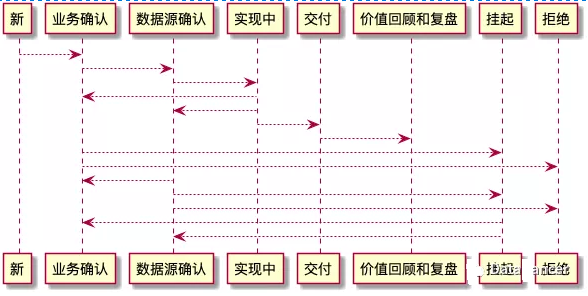
вдЩЯУшЪіЕФЪЧвЛИіЪ§ОнашЧѓЕФзДЬЌЖЈвхКЭСїзЊЙ§ГЬЁЃЗДИДЖрТжжЎКѓЃЌЗжЮіЪІБиаыЭЈЙ§ЮЪЬтЕФЗжНтКЭКЯВЂЃЌвдМАМлжЕХХађХаЖЯЕШММЧЩЃЌаЮГЩздМКЕФвЕЮёжЊЪЖЭМЦзЁЃетЯюФмСІЪЧВЛПЩИДжЦЕФЃЌЧаМЧЃЁ
Part 3 РћЦфЦї
КУМЧадВЛШчРУБЪЭЗЃЌЩЯЪіЕРРэДѓМвЫЦКѕЖМУїАзЃЌЕЋеце§дкжДааЕФЪБКђЃЌКмЖрШЫЛЙЪЧЛсЗИДэЮѓЁЃЧПСвЗжЮіЪІЭХЖгРћгУКУЙЋЫОМЖЕФЯюФПЙмРэЃЈУєНнПЊЗЂЃЉЙЄОпЃЌБШШчЮвУЧе§дкЪЙгУЕФ
tapdЃЌЛђеп jira етаЉЖМПЩвдЁЃ
ФУ tapd РДЫЕЃЌПЩвдздЖЈвх workflowЃЌБъЧЉЃЌАќРЈЯћЯЂЕШЃЌЪЕдкЬЋЗНБуЁЃГ§СЫМЧТМЪ§ОнЗжЮіашЧѓЃЌtapd
ЛЙПЩвдАяЮвУЧМЧТМЦНЪБЗжЮіЪІФкВПздааЗЂЦ№ЕФашЧѓЃЌБШШчЧАЮФвЛБЪДјЙ§ЕФЪ§ОнЭкОђШЮЮёЛђзЈЯюЗжЮіЁЃ
вдМА R ЪЧзіЪ§ОнЗжЮізюКУЕФЙЄОпЃЌУЛгажЎвЛЃЌВЛНгЪмЗДВЕЭМЦЌ
зюКѓЮвУЧдйзмНсвЛЯТЧАУцЕФФкШнЃКЪ§ОнЗжЮіЪІШчЙћЯЃЭћдкжАГЁЩњДцЕФЪцЪЪЃЌНЧЩЋдНРДдНЙиМќЃЌвЛЖЈвЊзЂвтДДдьКУгаРћЕФаХЯЂЪфШыЛЗОГЃЌвЊУДздМКааЖЏЃЌвЊУДЖдРЯАхЬсвЊЧѓЃЛдкЙЄзїжАд№ЗЖЮЇЃЌзіКУздМКЕФдЄЦкЙмРэЃЌЗжЮіЪІЕФЙЄзїВЛЪЧвЛДИзгТђТєЃЌашвЊЭГГяКУЙЄзїЕФВуДЮКЭЯШКѓЫГађЃЛдкУПИіЗжЮіашЧѓЕФЭъГЩЖМвЊЭЈЙ§ЧАУцЬсЕНЕФ
8 ВНЗЈЃЌЗДИДЖЭСЖздМКГщЯѓКЭНсЙЙЮЪЬтЕФФмСІЁЃ
ЯраХЃЌИїЮЛЗжЮіЪІЛсЭцЕФдНРДдНПЊаФЁЃ
|









