| БрМЭЦМі: |
БОЮФжївЊНщЩм
HBase КЭ Flink SQL ЕФНсКЯЪЙгУЕФСНжжГЁОАЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкApacheFlinkЃЌгЩAliceБрМЁЂЭЦМіЁЃ
|
|
HBase зїЮЊ Google ЗЂБэ Big Table ТлЮФЕФПЊдДЪЕЯжАцБОЃЌЪЧвЛжжЗжВМЪНСаЪНДцДЂЕФЪ§ОнПтЃЌЙЙНЈдк
HDFS жЎЩЯЕФ NoSQL Ъ§ОнПтЃЌЗЧГЃЪЪКЯДѓЙцФЃЪЕЪБВщбЏЃЌвђДЫ HBase дкЪЕЪБМЦЫуСьгђЪЙгУЗЧГЃЙуЗКЁЃПЩвдЪЕЪБаД
HBaseЃЌвВПЩвдРћгУ buckload вЛАбАбРыЯп Job ЩњГЩ HFile Load ЕНHBase
БэжаЁЃЖјЕБЯТ Flink SQL ЕФЛ№ШШГЬЖШВЛгУЖрЫЕЃЌFlink SQL вВЮЊ HBase ЬсЙЉСЫ
connectorЃЌвђДЫ HBase гы Flink SQL ЕФНсКЯЗЧГЃгаБивЊЪЕМљЪЕМљЁЃ
ЕБШЛЃЌБОЮФМйЩшгУЛЇгавЛЖЈЕФ HBase жЊЪЖЛљДЁЃЌВЛЛсЯъЯИШЅНщЩм HBase ЕФМмЙЙКЭдРэЃЌБОЮФзХжиНщЩм
HBase КЭ Flink дкЪЕМЪГЁОАжаЕФНсКЯЪЙгУЁЃжївЊЗжЮЊСНжжГЁОАЃЌЕквЛжжГЁОАЃКHBase зїЮЊЮЌБэгы
Flink Kafka table зі temporal table join ЕФГЁОАЃЛЕкЖўжжГЁОАЃКFlink
SQL зіМЦЫужЎКѓЕФНсЙћаДЕН HBase БэЃЌЙЉЦфЫћгУЛЇВщбЏЕФГЁОАЁЃвђДЫЃЌБОЮФНщЩмЕФФкШнШчЯТЫљЪОЃК
ЁЄ HBase ЛЗОГзМБИ
ЁЄ Ъ§ОнзМБИ
ЁЄ HBase зїЮЊЮЌЖШБэНјаа temporal table joinЕФГЁОА
ЁЄ Flink SQL зіМЦЫуаД HBase ЕФГЁОА
ЁЄ змНс
вЛЁЂHBase ЛЗОГзМБИ
гЩгкУЛгаВтЪдЕФ HBase ЛЗОГвдМАЮЊСЫБмУтЮлШОЯпЩЯ Hbase ЛЗОГЁЃвђДЫЃЌздМК buildвЛИі
Hbase docker image(ДѓМвПЩвд docker pull guxinglei/myhbase
РЕНБОЕи)ЃЌЪЧЛљгкЙйЗНИЩОЛЕФ ubuntu imgae жЎЩЯАВзАСЫ Hbase 2.2.0 АцБОвдМА
JDK1.8 АцБОЁЃ
ЦєЖЏШнЦїЃЌБЉТЖ Hbase web UI ЖЫПквдМАФкжУ zk ЖЫПкЃЌЗНБуЮвУЧДг web вГУцПДаХЯЂвдМАДДНЈ
Flink Hbase table ашвЊ zk ЕФСДНгаХЯЂЁЃ
| docker run -it
--network=host -p 2181:2181 -p 60011:60011 docker.io/guxinglei/myhbase:latest
bash |

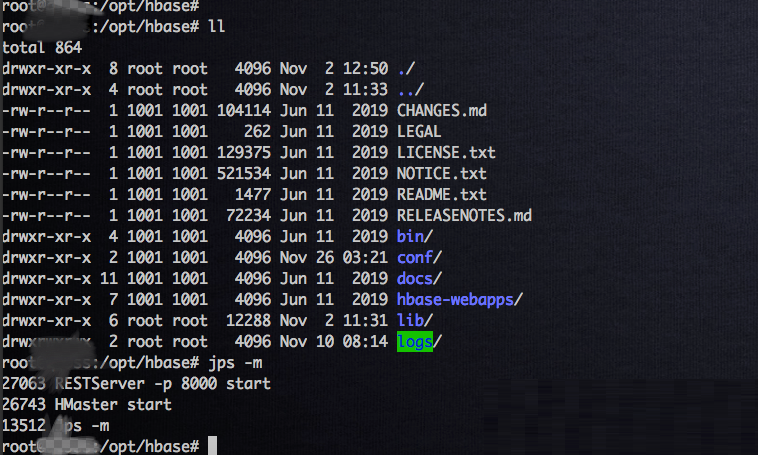
НјШыШнЦїЃЌЦєЖЏ HBase МЏШКЃЌвдМАЦєЖЏ rest serverЃЌКѓајЗНБуЮвУЧгУ
REST API РДЖСШЁ Flink SQL аДНј HBase ЕФЪ§ОнЁЃ
# ЦєЖЏhbase МЏШКbin/start-hbase.sh#
КѓЬЈЦєЖЏ
restServerbin/hbase-daemon.sh start rest -p
8000 |
ЖўЁЂЪ§ОнзМБИ
гЩгк HBase ЛЗОГЪЧздМКСйЪБИуЕФЕЅЛњЗўЮёЃЌРяУцУЛгаЪ§ОнЃЌашвЊЭљРяУцаДЕуЪ§ОнЙЉКѓајЪОР§гУЁЃдк Flink
SQL ЪЕеНЯЕСаЕкЖўЦЊжаНщЩмСЫШчКЮзЂВс Flink Mysql tableЃЌЮвУЧПЩвдНЋЙуИцЮЛБэГщШЁЕН
HBase БэжаЃЌгУРДзіЮЌЖШБэЃЌНјаа temporal table joinЁЃвђДЫЃЌЮвУЧашвЊдк HBase
жаДДНЈвЛеХБэЃЌЭЌЪБЛЙашвЊДДНЈ Flink HBase table, етСНеХБэЭЈЙ§ Flink SQL
ЕФ HBase connector ЙиСЊЦ№РДЁЃ
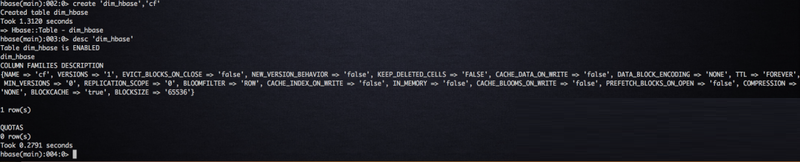
дкШнЦїжаЦєЖЏ HBase shellЃЌДДНЈвЛеХУћЮЊ dim_hbase
ЕФ HBase БэЃЌНЈБэгяОфШчЯТЫљЪОЃК
# дкhbase shellДДНЈ
hbaseБэ
hbase(main):002:0> create 'dim_hbase','cf'
Created table dim_hbase
Took 1.3120 seconds
=> Hbase::Table - dim_hbase |
дк Flink жаДДНЈ Flink HBase tableЃЌНЈБэгяОфШчЯТЫљЪОЃК
# зЂВс Flink Hbase
table
DROP TABLE IF EXISTS flink_rtdw.demo.hbase_dim_table;
CREATE TABLE flink_rtdw.demo.hbase_dim_table (
rowkey STRING,
cf ROW < adspace_name STRING >,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'dim_hbase',
'sink.buffer-flush.max-rows' = '1000',
'zookeeper.quorum' = 'localhost:2181'
); |
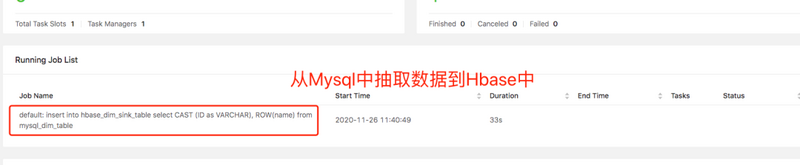
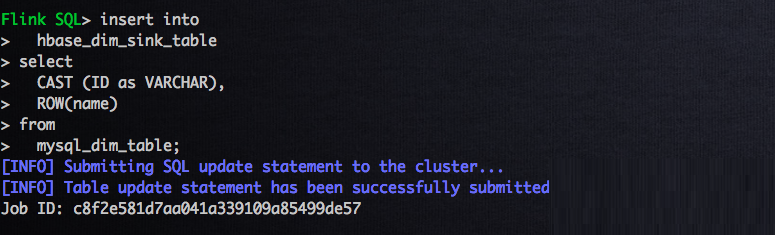
Flink MySQL table КЭ Flink HBase table
вбОДДНЈКУСЫЃЌОЭПЩвдаДГщШЁЪ§ОнЕНHBase ЕФ SQL job СЫЃЌSQL гяОфвдМА job зДЬЌШчЯТЫљЪОЃК
| # ГщШЁMysqlЪ§ОнЕНHbaseБэжа
insert into
hbase_dim_table
select
CAST (ID as VARCHAR),
ROW(name)
from
mysql_dim_table; |


03 HBase зїЮЊЮЌБэгы Kafka зі temporal join ЕФГЁОА
дк Flink SQL join жаЃЌЮЌЖШБэЕФ join вЛЖЈШЦВЛПЊЕФЃЌБШШчЖЉЕЅН№Жю join ЛуТЪБэЃЌЕуЛїСї
join ЙуИцЮЛЕФУїЯИБэЕШЕШЃЌЪЙгУГЁОАЗЧГЃЙуЗКЁЃФЧУДзїЮЊЗжВМЪНЪ§ОнПтЕФ HBase БШ MySQL
зїЮЊЮЌЖШБэгУзїЮЌЖШБэ join ИќгагХЪЦЁЃдк Flink SQL ЪЕеНЯЕСаЕкЖўЦЊжаЃЌЮвУЧзЂВсСЫЙуИцЕФЕуЛїСїЃЌНЋ
Kafka topic зЂВс Flink Kafka TableЃЌЭЌЪБвВНщЩмСЫ temporal table
join дк Flink SQL жаЕФЪЙгУЃЛФЧУДБОНкжаНЋЛсНщЩм HBase зїЮЊЮЌЖШБэРДЪЙгУЃЌЩЯУцаЁНкжавбОНЋЪ§ОнГщШЁЕН
Hbase жаСЫЃЌЮвУЧжБНгаД temporal table join МЦЫуТпММДПЩЁЃ
зїЮЊЙуИцЕуЛїСїЕФ Flink Kafa table гы зїЮЊЙуИцЮЛЕФ
Flink HBase table ЭЈЙ§ЙуИцЮЛ Id Нјаа temporal table joinЃЌЪфГіЙуИцЮЛ
ID КЭЙуИцЮЛжаЮФУћзжЃЌSQL join ТпМШчЯТЫљЪОЃК
select adsdw_dwd_max_click_mobileapp.publisher_
adspace _ adspaceId as publisher_adspace_adspaceId,
hbase_dim_table.cf.adspace_name as publisher_adspace_name
from adsdw_dwd_max_click_mobileapp
left join hbase_dim_table FOR SYSTEM_TIME AS OF
adsdw_dwd_max_click_mobileapp.procTime
on cast(adsdw_dwd_max_click_mobileapp.publisher_
adspace _ adspaceId as string) = hbase_dim_table.rowkey;
|
temporal table join job ЬсНЛ Flink
МЏШКЩЯЕФзДЬЌвдМА join НсЙћШчЯТЫљЪОЃК
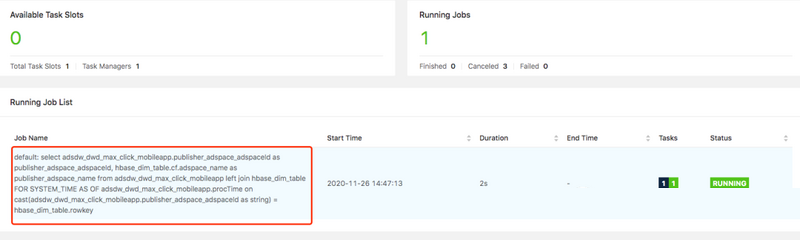

ЫФЁЂМЦЫуНсЙћ sink ЕН HBase зїЮЊНсЙћЕФГЁОА
ЩЯУцаЁНкжаЃЌHBase зїЮЊЮЌЖШБэгУзї temporal table join ЪЧЗЧГЃГЃМћЕФГЁОАЃЌЪЕМЪЩЯ
HBase зїЮЊДцДЂМЦЫуНсЙћвВЪЧЗЧГЃГЃМћЕФГЁОАЃЌБЯОЙ Hbase зїЮЊЗжВМЪНЪ§ОнПтЃЌЕзВуДцДЂЪЧгЕгаЖрИББОЛњжЦЕФ
HDFSЃЌЮЌЛЄМђЕЅЃЌРЉШнЗНБуЃЌ ЪЕЪБВщбЏПьЃЌЖјЧвЬсЙЉИїжжПЭЛЇЖЫЗНБуЯТгЮЪЙгУДцДЂдк HBase жаЕФЪ§ОнЁЃФЧУДБОаЁНкОЭНщЩм
Flink SQL НЋМЦЫуНсЙћаДЕН HBaseЃЌВЂЧвЭЈЙ§ REST API ВщбЏМЦЫуНсЙћЕФГЁОАЁЃ
НјШыШнЦїжаЃЌдк HBase жааТНЈвЛеХ HBase БэЃЌвЛИі column
family ОЭТњзуашЧѓЃЌНЈБэгяОфШчЯТЫљЪОЃК
# зЂВсhbase sink
table
create 'dwa_hbase_click_report','cf' |

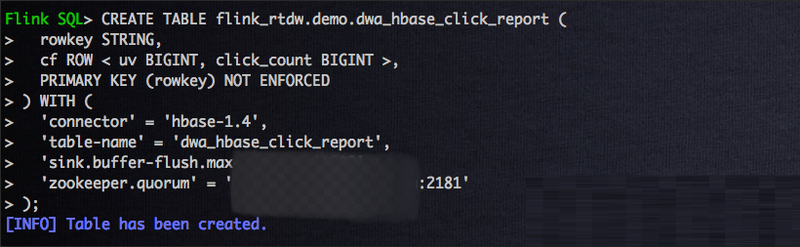
НЈСЂКУ HBase БэжЎКѓЃЌЮвУЧашвЊдк Flink SQL ДДНЈвЛеХ
Flink HBase tableЃЌетИіЪБКђЮвУЧашвЊУїШЗ cf етИі column famaly ЯТУц
column зжЖЮЃЌдк Flink SQLЪЕеНЕкЖўЦЊжаЃЌвбОзЂВсКУСЫзїЮЊЕуЛїСїЕФ Flink Kafka
tableЃЌвђДЫБОНкжаЃЌНЋЛсМЦЫуЕуЛїСїЕФ uv КЭЕуЛїЪ§ЃЌвђДЫСНИі column ЗжБ№ЮЊ uv КЭ
click_countЃЌНЈБэгяОфШчЯТЫљЪОЃК
# зЂВс Flink Hbase
table
DROP TABLE IF EXISTS flink_rtdw.demo.dwa_hbase_click_report;
CREATE TABLE flink_rtdw.demo.dwa_hbase_click_report
(
rowkey STRING,
cf ROW < uv BIGINT, click_count BIGINT >,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'dwa_hbase_click_report',
'sink.buffer-flush.max-rows' = '1000',
'zookeeper.quorum' = 'hostname:2181'
); |
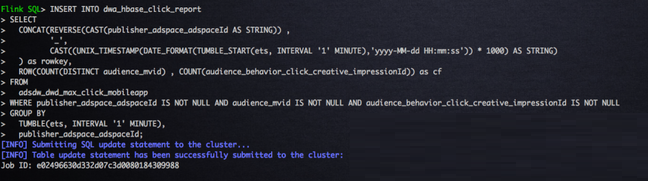
ЧАУцЕуЛїСїЕФ Flink Kafka table КЭДцДЂМЦЫуНсЙћЕФ
HBase table КЭ Flink HBase table вбОзМБИСЫЃЌЮвУЧНЋзівЛИі1ЗжжгЕФЗзЊДАПкМЦЫу
uv КЭЕуЛїЪ§ЃЌВЂЧвНЋМЦЫуНсЙћаДЕН HBase жаЁЃЖд HBase СЫНтЕФШЫгІИУжЊЕРЃЌrowkey
ЕФЩшМЦЖд hbase regoin ЕФЗжВМгазХЗЧГЃживЊЕФгАЯьЃЌЛљгкДЫЮвУЧЕФ rowkey ЪЧЪЙгУ Flink
SQL ФкжУЕФ reverse КЏЪ§НјааЙуИцЮЛ Id НјааЗДзЊКЭДАПкЦєЪМЪБМфзі concatЃЌвђДЫЃЌSQL
ТпМгяОфШчЯТЫљЪОЃК
INSERT INTO dwa_hbase_click_report
SELECT
CONCAT(REVERSE(CAST(publisher_adspace_adspaceId
AS STRING)) ,
'_',
CAST((UNIX_TIMESTAMP(DATE_FORMAT(TUMBLE_START(ets,
INTERVAL '1' MINUTE),'yyyy-MM-dd HH:mm:ss')) *
1000) AS STRING)
) as rowkey,
ROW(COUNT(DISTINCT audience_mvid) , COUNT(audience_behavior_click_creative_impressionId))
as cf
FROM
adsdw_dwd_max_click_mobileapp
WHERE publisher_adspace_adspaceId IS NOT NULL
AND audience _ mvid IS NOT NULL AND audience_behavior_click_creative_impressionId
IS NOT NULL
GROUP BY
TUMBLE(ets, INTERVAL '1' MINUTE),
publisher_adspace_adspaceId; |
SQL job ЬсНЛжЎКѓЕФзДЬЌвдМАНсЙћ check ШчЯТЫљЪОЃК
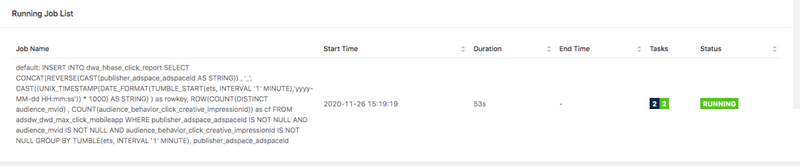
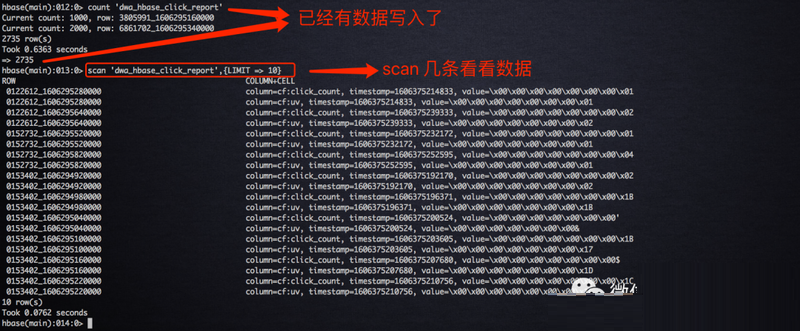
ЩЯЪі SQL job вбОГЩЙІЕФНЋНсЫуНсЙћаДЕН HBase жаСЫЁЃЖдгкЯпЩЯЕФ HBase ЗўЮёРДНВЃЌКмЖрЭЌЪТВЛвЛЖЈга
HBase ПЭЛЇЖЫЕФШЈЯоЃЌДгЖјвВВЛФмЭЈЙ§ HBase shell ЖСШЁЪ§ОнЃЛСэЭтзїЮЊЯпЩЯБЈБэЗўЮёЯдШЛВЛПЩФмЭЈЙ§
HBase shell РДЭЈЙ§ВщбЏЪ§ОнЁЃвђДЫЃЌдкЪЕЪББЈБэГЁОАжаЃЌЪ§ОнПЊЗЂЙЄГЬЪІНЋЪ§ОнаДШы HBase,
ЧАЖЫЙЄГЬЪІЭЈЙ§ REST API РДЖСШЁЪ§ОнЁЃЧАУцЮвУЧвбОЦєЖЏСЫ HBase rest server
НјГЬЃЌЮвУЧПЩвдЭЈ rest ЗўЮёЬсЙЉЖСШЁ HBase РяУцЕФЪ§ОнЁЃ
ЮвУЧЯШ get вЛЬѕИеИеаДЕН HBase жаЕФЪ§ОнПДПДЃЌШчЯТЫљЪОЃК

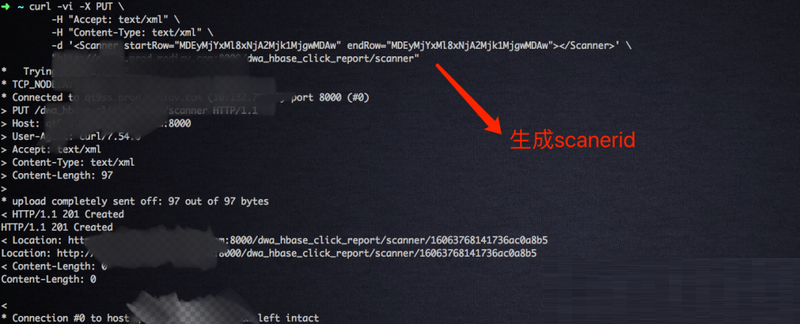
ЯТУцЮвУЧПЊЪМЭЈЙ§ REST API РДВщбЏ HBase жаЕФЪ§ОнЃЌЕквЛВНЃЌжДааШчЯТгяОфФУЕН
scannerIdЃЛЪзЯШашвЊНЋвЊВщбЏЕФ rowkey Нјаа base64 БрТыВХФмЪЙгУЃЌКѓУцашвЊНЋНсЙћНјаа
base64 НтТы
curl -vi -X PUT
\
-H "Accept: text/xml" \
-H "Content-Type: text/xml" \
-d '<Scanner startRow="MDEyMjYxMl8xNjA2Mjk1MjgwMDAw"
endRow="MDEyMjYxMl8xNjA2Mjk1MjgwMDAw"></Scanner>'
\
"http://hostname:8000/dwa_hbase_click_report/scanner"
|
ЕкЖўВНЃЌжДааШчЯТгяОфИљОнЩЯЬѕгяОфЗЕЛиЕФ scannerID ВщбЏЪ§ОнЃЌПЩвдПДЕНЗЕЛиЕФНсЙћЃК
curl -vi -X GET
\
-H "Accept: application/json" \
"http://hostname:8000/dwa_hbase_click_report/
scanner /16063768141736ac0a8b5" |

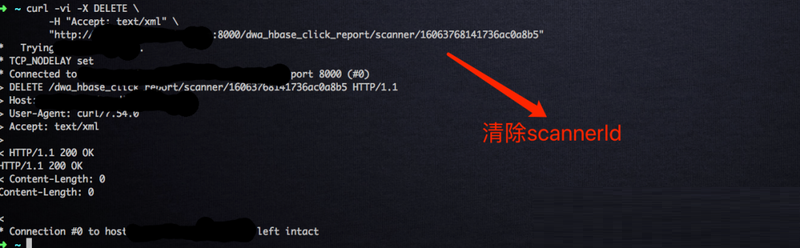
ЕкШ§ВНЃЌВщбЏЭъБЯжЎКѓЃЌжДааШчЯТгяОфЩОГ§ИУscannerId:
curl -vi -X DELETE
\
-H "Accept: text/xml" \
"http://hostname:8000/dwa_hbase_click_
report/scanner/16063768141736ac0a8b5"
|
ЮхЁЂзмНс
дкБОЦЊЮФеТжаЃЌЮвУЧНщЩмСЫ HBase КЭ Flink SQL ЕФНсКЯЪЙгУБШНЯЙуЗКСНжжЕФГЁОАЃКзїЮЊЮЌЖШБэгУвдМАДцДЂМЦЫуНсЙћЃЛЭЌЪБЪЙгУ
REST API Жд HBase жаЕФЪ§ОнНјааВщбЏЃЌЖдгкВщбЏгУЛЇРДЫЕЃЌБмУтжБНгБЉТЖ HBase ЕФ
zkЃЌЭЌЪБНЋ rest server КЭ HBase МЏШКНтёюЁЃ |









