| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЛљгкЁЖАйвкМЖШЋЭјгпЧщЗжЮіЯЕЭГДцДЂЩшМЦЁЗВЂНсКЯTablestoreЕФаТЙІФмзіСЫЯжДњДѓЪ§ОнгпЧщЯЕЭГЕФМмЙЙЩ§МЖЃЌЪЕЯжСЫКЃСПаХЯЂЯТЕФЪЕЪБгпЧщЗжЮіДцДЂЯЕЭГЃЌвВНщЩмСЫПЊдДЗНАИЁЃ
БОЮФРДздsegmentfault ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЛЅСЊЭјЕФЗЩЫйЗЂеЙДйНјСЫКмЖраТУНЬхЕФЗЂеЙЃЌВЛТлЪЧжЊУћЕФДѓVЃЌУїаЧЛЙЪЧЮЇЙлШКжкЖМПЩвдЭЈЙ§ЪжЛњдкЮЂВЉЃЌХѓгбШІЛђепЕуЦРЭјеОЩЯЗЂБэзДЬЌЃЌЗжЯэздМКЕФЫљМћЫљЯыЃЌЪЙЕУЁАШЫШЫЖМгаСЫТѓПЫЗчЁБЁЃВЛТлЪЧШШЕуаТЮХЛЙЪЧгщРжАЫидЃЌДЋВЅЫйЖШдЖГЌЮвУЧЕФЯыЯѓЁЃПЩвддкЖЬЖЬЪ§ЗжжгФкЃЌгаЪ§ЭђМЦзЊЗЂЃЌЪ§АйЭђЕФдФЖСЁЃШчДЫКЃСПЕФаХЯЂПЩвдЕУЕНБЌеЈЪНЕФДЋВЅЃЌШчКЮФмЙЛЪЕЪБЕФАбЮеУёЧщВЂзїГіЖдгІЕФДІРэЖдКмЖрЦѓвЕРДЫЕЖМЪЧжСЙиживЊЕФЁЃДѓЪ§ОнЪБДњЃЌГ§СЫУНЬхаХЯЂвдЭтЃЌЩЬЦЗдкИїРрЕчЩЬЦНЬЈЕФЖЉЕЅСПЃЌгУЛЇЕФЙКТђЦРТлвВЖМЖдКѓајЕФЯћЗбепВњЩњКмДѓЕФгАЯьЁЃЩЬМвЕФВњЦЗЩшМЦепашвЊЛузмЭГМЦКЭЗжЮіИїРрЦНЬЈЕФЪ§ОнзіЮЊвРОнЃЌОіЖЈКѓајЕФВњЦЗЗЂеЙЃЌЙЋЫОЕФЙЋЙиКЭЪаГЁВПУХвВашвЊИљОнгпЧщзїГіЯргІЕФМАЪБДІРэЃЌЖјетвЛЧавВвтЮЖзХДЋЭГЕФгпЧщЯЕЭГЩ§МЖГЩЮЊДѓЪ§ОнгпЧщВЩМЏКЭЗжЮіЯЕЭГЁЃ
ЗжЮіЭъгпЧщГЁОАКѓЃЌЮвУЧдйРДОпЬхЯИЛЏПДЯТДѓЪ§ОнгпЧщЯЕЭГЃЌЖдЮвУЧЕФЪ§ОнДцДЂКЭМЦЫуЯЕЭГЬсГіФФаЉашЧѓЃК
КЃСПдЪМЪ§ОнЕФЪЕЪБШыПтЃКЮЊСЫЪЕЯжвЛећЬзгпЧщЯЕЭГЃЌашвЊгаЩЯгЮдЪМЪфГіЕФВЩМЏЃЌвВОЭЪЧХРГцЯЕЭГЁЃХРГцашвЊВЩМЏИїРрУХЛЇЃЌздУНЬхЕФЭјвГФкШнЁЃдкзЅШЁЧАашвЊШЅжиЃЌзЅШЁКѓЛЙашвЊЗжЮіЬсШЁЃЌР§ШчНјаазгЭјвГЕФзЅШЁЁЃ
дЪМЭјвГЪ§ОнЕФДІРэЃКВЛТлЪЧжїСїУХЛЇЛЙЪЧздУНЬхЕФЭјвГаХЯЂЃЌзЅШЁКѓЮвУЧашвЊзівЛЖЈЕФЪ§ОнЬсШЁЃЌАбдЪМЕФЭјвГФкШнзЊЛЏЮЊНсЙЙЛЏЪ§ОнЃЌР§ШчЮФеТЕФБъЬтЃЌеЊвЊЕШЃЌШчЙћЪЧЩЬЦЗЕуЦРРрЯћЯЂвВашвЊЬсШЁгааЇЕФЕуЦРЁЃ
НсЙЙЛЏЪ§ОнЕФгпЧщЗжЮіЃКЕБИїРрдЪМЪфГіБфГЩНсЙЙЛЏЕФЪ§ОнКѓЃЌЮвУЧашвЊгавЛИіЪЕЪБЕФМЦЫуВњЦЗАбИїРрЪфГізіКЯРэЕФЗжРрЃЌНјвЛВНЖдЗжРрКѓЕФФкШнНјааЧщИаДђБъЁЃИљОнвЕЮёЕФашЧѓетРяПЩФмЛсВњЩњВЛЭЌЕФЪфГіЃЌР§ШчЦЗХЦЕБЯТЪЧЗёгаШШЕуЛАЬтЃЌгпЧщгАЯьСІЗжЮіЃЌзЊВЅТЗОЖЗжЮіЃЌВЮгыгУЛЇЭГМЦКЭЛЯёЃЌгпТлЧщИаЗжЮіЛђепЪЧЗёгажиДѓдЄОЏЁЃ
гпЧщЗжЮіЯЕЭГжаМфКЭНсЙћЪ§ОнЕФДцДЂЃЌНЛЛЅЗжЮіВщбЏЃКДгЭјвГдЪМЪ§ОнЧхЯДЕНзюжеЕФгпЧщБЈБэетжаМфЛсВњЩњКмЖрРраЭЕФЪ§ОнЁЃетаЉЪ§ОнгаЕФЛсЬсЙЉИјЪ§ОнЗжЮіЭЌбЇНјаагпЧщЗжЮіЯЕЭГЕФЕїгХЃЌгаЕФЪ§ОнЛсЬсЙЉИјвЕЮёВПУХИљОнгпЧщНсЙћНјааОіВпЁЃетаЉВщбЏПЩФмЛсКмСщЛюЃЌашвЊЮвУЧЕФДцДЂЯЕЭГОпБИШЋЮФМьЫїЃЌЖрзжЖЮзщКЯСщЛюЕФНЛЛЅЗжЮіФмСІЁЃ
жиДѓгпЧщЪТМўЕФЪЕЪБдЄОЏЃКЖдгкгпЧщЕФНсЙћГ§СЫе§ГЃЕФЫбЫїКЭеЙЪОашЧѓвдЭтЃЌЕБгажиДѓЪТМўГіЯжЮвУЧашвЊФмзіЕНЪЕЪБЕФдЄОЏЁЃ
ЮвУЧМЦЛЎЗжСНЦЊНщЩмЭъећЕФгпЧщаТМмЙЙЃЌЕквЛЦЊжївЊЪЧЬсЙЉМмЙЙЩшМЦЃЌЛсЯШНщЩмЪБЯТжїСїЕФДѓЪ§ОнМЦЫуМмЙЙЃЌВЂЗжЮівЛаЉгХШБЕуЃЌШЛКѓв§ШыгпЧщДѓЪ§ОнМмЙЙЁЃЕкЖўЦЊЛсгаЭъећЕФЪ§ОнПтБэЩшМЦКЭВПЗжЪОР§ДњТыЁЃДѓМвОДЧыЦкД§ЁЃ
ЯЕЭГЩшМЦ
ашЧѓЗжЮі
НсКЯЮФеТПЊЭЗЖдгпЧщЯЕЭГЕФУшЪіЃЌКЃСПДѓЪ§ОнгпЧщЗжЮіЯЕЭГСїГЬЭМДѓЬхШчЯТЃК
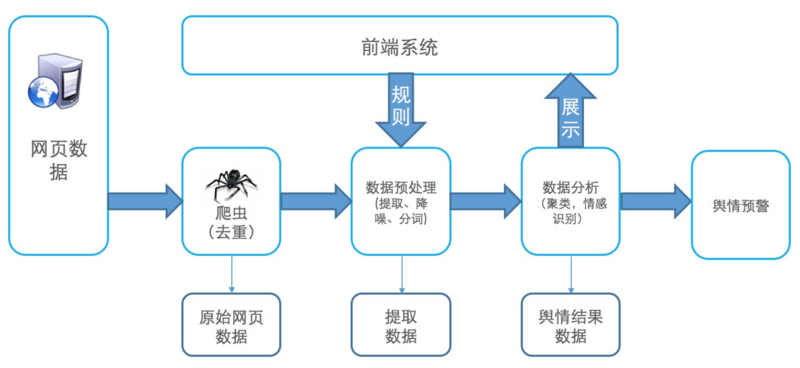
ЭМ1 гпЧщЯЕЭГвЕЮёСїГЬ
дЪМЭјвГДцДЂПтЃЌетИіПташвЊФмжЇГжКЃСПЪ§ОнЃЌЕЭГЩБОЃЌЕЭбгЪБаДШыЁЃЭјвГЪ§ОнаДШыКѓЃЌвЊзіЪЕЪБНсЙЙЛЏЬсШЁЃЌЬсШЁГіРДЕФЪ§ОндйНјааНЕдыЃЌЗжДЪЃЌЭМЦЌocrДІРэЕШЁЃЖдЗжДЪЮФБОЃЌЭМЦЌНјааЧщИаЪЖБ№ВњЩњгпЧщЪ§ОнНсЙћМЏЁЃДЋЭГЕФРыЯпШЋСПМЦЫуКмФбТњзугпЧщЯЕЭГЕФЪБаЇадашЧѓЁЃ
МЦЫув§ЧцдкзіЪ§ОнДІРэЪБЃЌПЩФмЛЙашвЊДгДцДЂПтжаЛёШЁвЛаЉдЊЪ§ОнЃЌР§ШчгУЛЇаХЯЂЃЌЧщИаДЪдЊЪ§ОнаХЯЂЕШЁЃ
Г§СЫЪЕЪБЕФМЦЫуСДТЗЃЌЖдДцСПЪ§ОнЖЈЦквЊзівЛаЉОлРрЃЌгХЛЏЮвУЧЕФЧщИаДЪЪЖБ№ПтЃЌЛђепЩЯгЮИљОнвЕЮёашвЊДЅЗЂЧщИаДІРэЙцдђИќаТЃЌИљОнаТЕФЧщИаДђБъПтЖдДцСПЪ§ОнзівЛДЮгпЧщМЦЫуЁЃ
гпЧщЕФНсЙћЪ§ОнМЏгаВЛЭЌРрЕФЪЙгУашЧѓЁЃЖдгкжиДѓгпЧщЃЌашвЊзіЪЕЪБЕФдЄОЏЁЃЭъећЕФгпЧщНсЙћЪ§ОнеЙЪОВуашвЊжЇГжШЋЮФМьЫїЃЌСщЛюЕФЪєадзжЖЮзщКЯВщбЏЁЃвЕЮёЩЯПЩФмИљОнЪєадзжЖЮжаЕФжУаХЖШЃЌгпЧщЪБМфЃЌЛђепЙиМќДЪзщКЯНјааЗжЮіЁЃ
ИљОнЧАУцЕФНщЩмЃЌгпЧщДѓЪ§ОнЗжЮіЯЕЭГашвЊСНРрМЦЫуЃЌвЛРрЪЧЪЕЪБМЦЫуАќРЈКЃСПЭјвГФкШнЪЕЪБГщШЁЃЌЧщИаДЪЗжЮіВЂНјааЭјвГгпЧщНсЙћДцДЂЁЃСэвЛРрЪЧРыЯпМЦЫуЃЌЯЕЭГашвЊЖдРњЪЗЪ§ОнНјааЛиЫнЃЌНсКЯШЫЙЄБъзЂЕШЗНЪНгХЛЏЧщИаДЪПтЃЌЖдвЛаЉЪЕЪБМЦЫуЕФНсЙћНјааНУе§ЕШЁЃЫљвддкЯЕЭГЩшМЦЩЯЃЌашвЊбЁдёвЛЬзМШПЩвдзіЪЕЪБМЦЫугжФмзіХњСПРыЯпМЦЫуЕФЯЕЭГЁЃдкПЊдДДѓЪ§ОнНтОіЗНАИжаЃЌLambdaМмЙЙЧЁКУПЩвдТњзуетаЉашЧѓЃЌЯТУцЮвУЧРДНщЩмЯТLambdaЕФМмЙЙЁЃ
LambdaМмЙЙ ЃЈwikiЃЉ
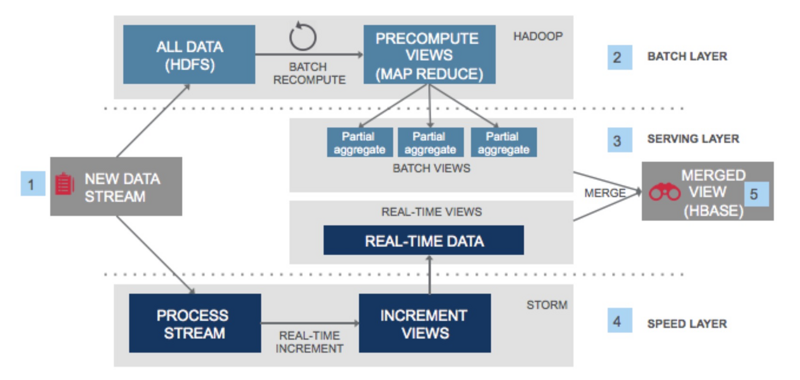
ЭМ2 LambdaМмЙЙЭМ
LambdaМмЙЙПЩвдЫЕЪЧHadoopЃЌSparkЬхЯЕЯТзюЛ№ЕФДѓЪ§ОнМмЙЙЁЃетЬзМмЙЙЕФзюДѓгХЪЦОЭЪЧдкжЇГжКЃСПЪ§ОнХњСПМЦЫуДІРэЃЈвВОЭЪЧРыЯпДІРэЃЉЭЌЪБвВжЇГжСїЪНЕФЪЕЪБДІРэЃЈМДШШЪ§ОнДІРэЃЉЁЃ
ОпЬхЪЧШчКЮЪЕЯжЕФФиЃЌЪзЯШЩЯгЮвЛАуЪЧвЛИіЖгСаЗўЮёР§ШчkafkaЃЌЪЕЪБДцДЂЪ§ОнЕФаДШыЁЃkafkaЖгСаЛсгаСНИіЖЉдФепЃЌвЛИіЪЧШЋСПЪ§ОнМДЭМЦЌжаЩЯАыВПЗжЃЌШЋСПЪ§ОнЛсБЛДцДЂдкРрЫЦHDFSетбљЕФДцДЂНщжЪЩЯЁЃЕБгаРыЯпМЦЫуШЮЮёЕНРДЃЌМЦЫузЪдДЃЈР§ШчHadoopЃЉЛсЗУЮЪДцДЂЯЕЭГЩЯЕФШЋСПЪ§ОнЃЌНјааШЋСПХњМЦЫуЕФДІРэТпМЁЃОЙ§map/reduceЛЗНкКѓШЋСПЕФНсЙћЛсБЛаДШывЛИіНсЙЙЛЏЕФДцДЂв§ЧцР§ШчHbaseжаЃЌЬсЙЉИјвЕЮёЗНВщбЏЁЃЖгСаЕФСэвЛИіЯћЗбЖЉдФЗНЪЧСїМЦЫув§ЧцЃЌСїМЦЫув§ЧцЭљЭљЛсЪЕЪБЕФЯћЗбЖгСажаЕФЪ§ОнНјааМЦЫуДІРэЃЌР§ШчSpark
StreamingЪЕЪБЖЉдФKafkaЕФЪ§ОнЃЌСїМЦЫуНсЙћвВЛсаДШывЛИіНсЙЙЛЏЪ§Онв§ЧцЁЃХњСПМЦЫуКЭСїМЦЫуЕФНсЙћаДШыЕФНсЙЙЛЏДцДЂв§ЧцМДЩЯЭМБъзЂ3ЕФ"Serving
Layer"ЃЌетвЛВужївЊЬсЙЉНсЙћЪ§ОнЕФеЙЪОКЭВщбЏЁЃ
дкетЬзМмЙЙжаЃЌХњСПМЦЫуЕФЬиЕуЪЧашвЊжЇГжДІРэКЃСПЕФЪ§ОнЃЌВЂИљОнвЕЮёЕФашЧѓЃЌЙиСЊвЛаЉЦфЫћвЕЮёжИБъНјааМЦЫуЁЃХњСПМЦЫуЕФКУДІЪЧМЦЫуТпМПЩвдИљОнвЕЮёашЧѓСщЛюЕїећЃЌЭЌЪБМЦЫуНсЙћПЩвдЗДИДжиЫуЃЌЭЌбљЕФМЦЫуТпМЖрДЮМЦЫуНсЙћВЛЛсИФБфЁЃХњСПМЦЫуЕФШБЕуЪЧМЦЫужмЦкЯрЖдНЯГЄЃЌКмФбТњзуЪЕЪБГіНсЙћЕФашЧѓЃЌЫљвдЫцзХДѓЪ§ОнМЦЫуЕФбнНјЃЌЬсГіСЫЪЕЪБМЦЫуЕФашЧѓЁЃЪЕЪБМЦЫудкLambdaМмЙЙжаЪЧЭЈЙ§ЪЕЪБЪ§ОнСїРДЪЕЯжЃЌЯрБШХњДІРэЃЌЪ§ОндіСПСїЕФДІРэЗНЪНОіЖЈСЫЪ§ОнЭљЭљЪЧзюНќаТВњЩњЕФЪ§ОнЃЌвВОЭЪЧШШЪ§ОнЁЃе§вђЮЊШШЪ§ОнетвЛЬиЕуЃЌСїМЦЫуПЩвдТњзувЕЮёЖдМЦЫуЕФЕЭбгЪБашЧѓЃЌР§ШчдкгпЧщЗжЮіЯЕЭГжаЃЌЮвУЧЭљЭљЯЃЭћгпЧщаХЯЂПЩвддкЭјвГзЅШЁЯТРДКѓЃЌЗжжгМЖБ№ФУЕНМЦЫуНсЙћЃЌИјвЕЮёЗНГфзуЕФЪБМфНјаагпЧщЗДРЁЁЃЯТУцЮвУЧОЭРДОпЬхПДвЛЯТЃЌЛљгкLambdaМмЙЙЕФЫМЯыШчКЮЪЕЯжвЛЬзЭъећЕФгпЧщДѓЪ§ОнМмЙЙЁЃ
ПЊдДгпЧщДѓЪ§ОнЗНАИ
ЭЈЙ§етИіСїГЬЭМЃЌШУЮвУЧСЫНтСЫећИігпЧщЯЕЭГЕФНЈЩшЙ§ГЬжаЃЌашвЊОЙ§ВЛЭЌЕФДцДЂКЭМЦЫуЯЕЭГЁЃЖдЪ§ОнЕФзщжЏКЭВщбЏгаВЛЭЌЕФашЧѓЁЃдквЕНчЛљгкПЊдДЕФДѓЪ§ОнЯЕЭГВЂНсКЯLambdaМмЙЙЃЌећЬзЯЕЭГПЩвдЩшМЦШчЯТЃК
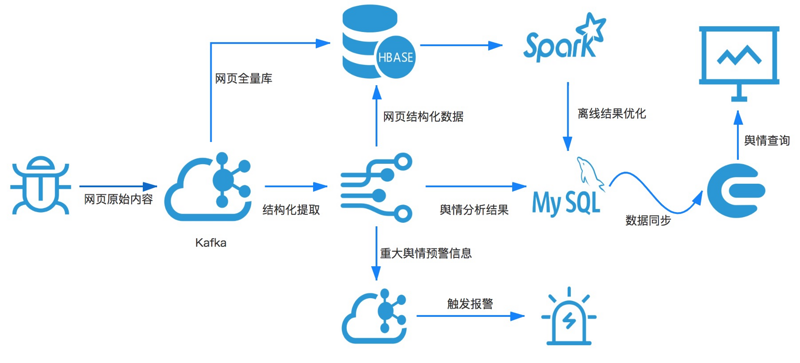
ЭМ3 ПЊдДгпЧщМмЙЙЭМ
ЯЕЭГЕФзюЩЯгЮЪЧЗжВМЪНЕФХРГцв§ЧцЃЌИљОнзЅШЁШЮЮёзЅШЁЖЉдФЕФЭјвГдЮФФкШнЁЃХРГцЛсАбзЅШЁЕНЕФЭјвГФкШнЪЕЪБаДШыKafkaЖгСаЃЌНјШыKafkaЖгСаЕФЪ§ОнИљОнЧАУцУшЪіЕФМЦЫуашЧѓЃЌЛсЪЕЪБСїШыСїМЦЫув§ЧцЃЈР§ШчSparkЛђепFlinkЃЉЃЌвВЛсГжОУЛЏДцДЂдкHbaseЃЌНјааШЋСПЪ§ОнЕФДцДЂЁЃШЋСПЭјвГЕФДцДЂПЩвдТњзуЭјвГХРШЁШЅжиЃЌХњСПРыЯпМЦЫуЕФашЧѓЁЃ
СїМЦЫуЛсЖддЪМЭјвГНјааНсЙЙЛЏЬсШЁЃЌНЋЗЧНсЙЙЛЏЭјвГФкШнзЊЛЏЮЊНсЙЙЪ§ОнВЂНјааЗжДЪЃЌР§ШчЬсШЁГіЭјвГЕФБъЬтЃЌзїепЃЌеЊвЊЕШЃЌЖде§ЮФКЭеЊвЊФкШнНјааЗжДЪЁЃЬсШЁКЭЗжДЪНсЙћЛсаДЛиHbaseЁЃНсЙЙЛЏЬсШЁКЭЗжДЪКѓЃЌСїМЦЫув§ЧцЛсНсКЯЧщИаДЪПтНјааЭјвГЧщИаЗжЮіЃЌХаЖЯЪЧЗёгагпЧщВњЩњЁЃ
СїМЦЫув§ЧцЗжЮіЕФгпЧщНсЙћДцДЂMysqlЛђепHbaseЪ§ОнПтжаЃЌЮЊСЫЗНБуНсЙћМЏЕФЫбЫїВщПДЃЌашвЊАбЪ§ОнЭЌВНЕНвЛИіЫбЫїв§ЧцР§ШчElasticsearchЃЌЗНБуНјааЪєадзжЖЮЕФзщКЯВщбЏЁЃШчЙћЪЧжиДѓЕФгпЧщЪБМфЃЌашвЊаДШыKafkaЖгСаДЅЗЂгпЧщБЈОЏЁЃ
ШЋСПЕФНсЙЙЛЏЪ§ОнЛсЖЈЦкЭЈЙ§SparkЯЕЭГНјааРыЯпМЦЫуЃЌИќаТЧщИаДЪПтЛђепНгЪмаТЕФМЦЫуВпТджиаТМЦЫуРњЪЗЪ§Онаое§ЪЕЪБМЦЫуЕФНсЙћЁЃ
ПЊдДМмЙЙЗжЮі
ЩЯУцЕФгпЧщДѓЪ§ОнМмЙЙЃЌЭЈЙ§KafkaЖдНгСїМЦЫуЃЌHbaseЖдНгХњМЦЫуРДЪЕЯжLambdaМмЙЙжаЕФЁАbatch
viewЁБКЭЁАreal-time viewЁБЃЌећЬзМмЙЙЛЙЪЧБШНЯЧхЮњЕФЃЌПЩвдКмКУЕФТњзудкЯпКЭРыЯпСНРрМЦЫуашЧѓЁЃЕЋЪЧАбетвЛЬзЯЕЭГгІгУдкЩњВњВЂВЛЪЧвЛМўШнвзЕФЪТЧщЃЌжївЊгаЯТУцвЛаЉдвђЁЃ
ећЬзМмЙЙЩцМАЕНЗЧГЃЖрЕФДцДЂКЭМЦЫуЯЕЭГАќРЈЃКKafkaЃЌHbaseЃЌSparkЃЌFlinkЃЌElasticsearchЁЃЪ§ОнЛсдкВЛЭЌЕФДцДЂКЭМЦЫуЯЕЭГжаСїЖЏЃЌдЫЮЌКУећЬзМмЙЙжаЕФУПвЛИіПЊдДВњЦЗЖМЪЧвЛИіКмДѓЕФЬєеНЁЃШЮКЮвЛИіВњЦЗЛђепЪЧВњЦЗМфЕФЭЈЕРГіЯжЙЪеЯЃЌЖдећИігпЧщЗжЮіНсЙћЕФЪБаЇадЖМЛсВњЩњгАЯьЁЃ
ЮЊСЫЪЕЯжХњМЦЫуКЭСїМЦЫуЃЌдЪМЕФЭјвГашвЊЗжБ№ДцДЂдкKafkaКЭHbaseжаЃЌРыЯпМЦЫуЪЧЯћЗбhbaseжаЕФЪ§ОнЃЌСїМЦЫуЯћЗбKafkaЕФЪ§ОнЃЌетбљЛсДјРДДцДЂзЪдДЕФШпгрЃЌЭЌЪБвВЕМжТашвЊЮЌЛЄСНЬзМЦЫуТпМЃЌМЦЫуДњТыПЊЗЂКЭЮЌЛЄГЩБОвВЛсЩЯЩ§ЁЃ
гпЧщЕФМЦЫуНсЙћДцДЂдкMysqlЛђепHbaseЃЌЮЊСЫЗсИЛзщКЯВщбЏгяОфЃЌашвЊАбЪ§ОнЭЌВНЙЙНЈЕНElasticsearchжаЁЃВщбЏЕФЪБКђПЩФмашвЊзщКЯMysqlКЭElasticsearchЕФВщбЏНсЙћЁЃетРяУЛгаЬјЙ§Ъ§ОнПтЃЌжБНгАбНсЙћЪ§ОнаДШыElasticsearchетРрЫбЫїЯЕЭГЃЌЪЧвђЮЊЫбЫїЯЕЭГЕФЪ§ОнЪЕЪБаДШыФмСІКЭЪ§ОнПЩППадВЛШчЪ§ОнПтЃЌвЕНчЭЈГЃЪЧАбЪ§ОнПтКЭЫбЫїЯЕЭГећКЯЃЌећКЯЯТЕФЯЕЭГМцБИСЫЪ§ОнПтКЭЫбЫїЯЕЭГЕФгХЪЦЃЌЕЋЪЧСНИів§ЧцжЎМфЪ§ОнЕФЭЌВНКЭПчЯЕЭГВщбЏЖддЫЮЌКЭПЊЗЂДјРДКмЖрЖюЭтЕФГЩБОЁЃ
аТЕФДѓЪ§ОнМмЙЙLambda plus
ЭЈЙ§ЧАУцЕФЗжЮіЃЌЯраХДѓМвЖМЛсгавЛИівЩЮЪЃЌгаУЛгаМђЛЏЕФЕФДѓЪ§ОнМмЙЙЃЌдкПЩвдТњзуLambdaЖдМЦЫуашЧѓЕФМйЩшЃЌгжФмМѕЩйДцДЂМЦЫувдМАФЃПщЕФИіЪ§ФиЁЃLinkedinЕФJay
KrepsЬсГіСЫKappaМмЙЙЃЌЙигкLambdaКЭKappaЕФЖдБШПЩвдВЮПМ"дЦЩЯДѓЪ§ОнЗНАИ"етЦЊЃЌетРяВЛеЙПЊЯъЯИЖдБШЃЌМђЕЅЫЕЯТЃЌKappaЮЊСЫМђЛЏСНЗнДцДЂЃЌШЁЯћСЫШЋСПЕФЪ§ОнДцДЂПтЃЌЭЈЙ§дкKafkaБЃСєИќГЄШежОЃЌЕБгаЛиЫнжиаТМЦЫуашЧѓЕНРДЪБЃЌжиаТДгЖгСаЕФЭЗВППЊЪМЖЉдФЪ§ОнЃЌдйвЛДЮгУСїЕФЗНЪНДІРэKafkaЖгСажаБЃДцЕФЫљгаЪ§ОнЁЃетбљЩшМЦЕФКУДІЪЧНтОіСЫашвЊЮЌЛЄСНЗнДцДЂКЭСНЬзМЦЫуТпМЕФЭДЕуЃЌУРжаВЛзуЕФЕиЗНЪЧЖгСаПЩвдБЃСєЕФРњЪЗЪ§ОнБЯОЙгаЯоЃЌФбвдзіЕНЮоЪБМфЯожЦЕФЛиЫнЁЃЗжЮіЕНетРяЃЌЮвУЧбизХKappaеыЖдLambdaЕФИФНјЫМТЗЃЌЯђЧАЖрЫМПМвЛаЉЃКМйШчгавЛИіДцДЂв§ЧцЃЌМШТњзуЪ§ОнПтПЩвдИпаЇЕФаДШыКЭЫцЛњВщбЏЃЌгжФмЯёЖгСаЗўЮёЃЌТњзуЯШНјЯШГіЃЌЪЧВЛЪЧОЭПЩвдАбLambdaКЭKappaМмЙЙШрКЯдквЛЦ№ЃЌДђдьвЛИіLambda
plusМмЙЙФиЃП
аТМмЙЙдкLambdaЕФЛљДЁЩЯПЩвдЬсЩ§вдЯТМИЕуЃК
дкжЇГжСїМЦЫуКЭХњМЦЫуЕФЭЌЪБЃЌШУМЦЫуТпМПЩвдИДгУЃЌЪЕЯжЁАвЛЬзДњТыСНРрашЧѓЁБЁЃ
ЭГвЛРњЪЗЪ§ОнШЋСПКЭдкЯпЪЕЪБдіСПЪ§ОнЕФДцДЂЃЌЪЕЯжЁАвЛЗнДцДЂСНРрМЦЫуЁБЁЃ
ЮЊСЫЗНБугпЧщНсЙћВщбЏашЧѓЃЌЁАbatch viewЁБКЭЁАreal-time viewЁБДцДЂдкМШПЩвджЇГжИпЭЬЭТЕФЪЕЪБаДШыЃЌвВПЩвджЇГжЖрзжЖЮзщКЯЫбЫїКЭШЋЮФМьЫїЁЃ
змНсЦ№РДОЭЪЧећЬзаТМмЙЙЕФКЫаФЪЧНтОіДцДЂЕФЮЪЬтЃЌвдМАШчКЮСщЛюЕФЖдНгМЦЫуЁЃЮвУЧЯЃЭћећЬзЗНАИЪЧРрЫЦЯТУцЕФМмЙЙЃК
ЭМ4 Lambda PlusМмЙЙ
Ъ§ОнСїЪЕЪБаДШывЛИіЗжВМЪНЕФЪ§ОнПтЃЌНшжњгкЪ§ОнПтВщбЏФмСІЃЌШЋСПЪ§ОнПЩвдЧсЫЩЕФЖдНгХњСПМЦЫуЯЕЭГНјааРыЯпДІРэЁЃ
Ъ§ОнПтЭЈЙ§Ъ§ОнПтШежОНгПкЃЌжЇГждіСПЖСШЁЃЌЪЕЯжЖдНгСїМЦЫув§ЧцНјааЪЕЪБМЦЫуЁЃ
ХњМЦЫуКЭСїМЦЫуЕФНсЙћаДЛиЗжВМЪНЪ§ОнПтЃЌЗжВМЪНЪ§ОнПтЬсЙЉЗсИЛЕФВщбЏгявтЃЌЪЕЯжМЦЫуНсЙћЕФНЛЛЅЪНВщбЏЁЃ
ећЬзМмЙЙжаЃЌДцДЂВуУцЭЈЙ§НсКЯЪ§ОнПтжїБэЪ§ОнКЭЪ§ОнПтШежОРДШЁДњДѓЪ§ОнМмЙЙжаЕФЖгСаЗўЮёЃЌМЦЫуЯЕЭГбЁШЁЬьШЛжЇГжХњКЭСїЕФМЦЫув§ЧцР§ШчFlinkЛђепSparkЁЃетбљвЛРДЃЌЮвУЧМШПЩвдЯёLambdaНјааЮоЯожЦЕФРњЪЗЪ§ОнЛиЫнЃЌгжПЩвдЯёKappaМмЙЙвЛбљвЛЬзТпМЃЌДцДЂДІРэСНРрМЦЫуШЮЮёЁЃетбљЕФвЛЬзМмЙЙЮвУЧШЁУћЮЊЁАLambda
plusЁБЃЌЯТУцОЭЯъЯИеЙПЊШчКЮдкАЂРядЦЩЯДђдьетбљЕФвЛЬзДѓЪ§ОнМмЙЙЁЃ
дЦЩЯгпЧщЯЕЭГМмЙЙ
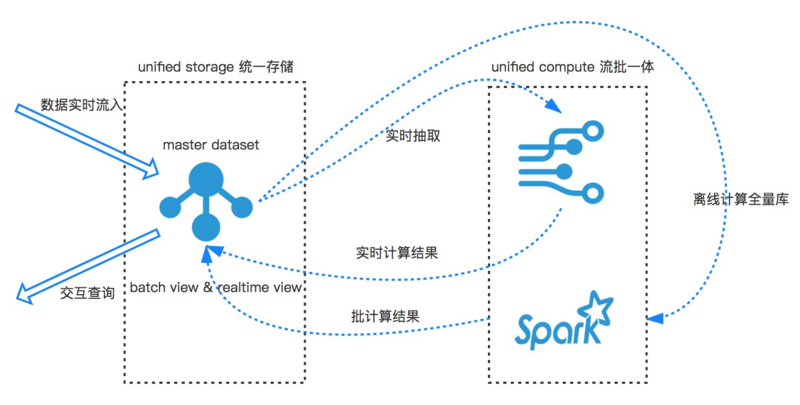
дкАЂРядЦжкЖрДцДЂКЭМЦЫуВњЦЗжаЃЌЬљКЯЩЯЪіДѓЪ§ОнМмЙЙЕФашЧѓЃЌЮвУЧбЁгУСНПюВњЦЗРДЪЕЯжећЬзгпЧщДѓЪ§ОнЯЕЭГЁЃДцДЂВуУцЪЙгУАЂРядЦздбаЕФЗжВМЪНЖрФЃаЭЪ§ОнПтTablestoreЃЌМЦЫуВубЁгУBlinkРДЪЕЯжСїХњвЛЬхМЦЫуЁЃ
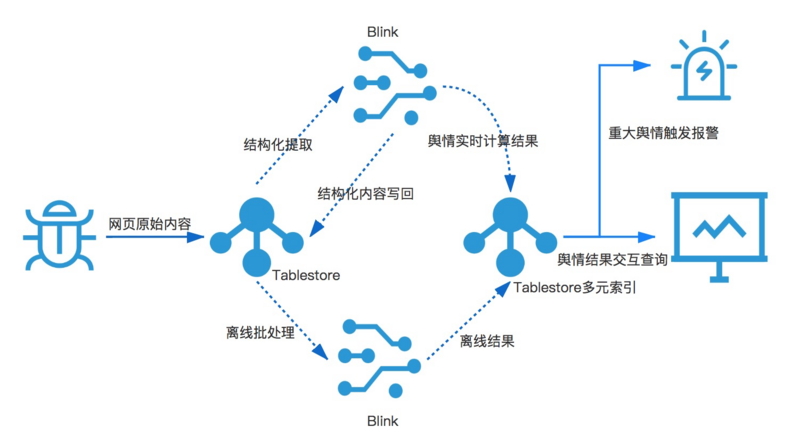
ЭМ5 дЦЩЯгпЧщДѓЪ§ОнМмЙЙ
етЬзМмЙЙдкДцДЂВуУцЃЌШЋВПЛљгкTablestoreЃЌвЛИіЪ§ОнПтНтОіВЛЭЌДцДЂашЧѓЃЌИљОнжЎЧАгпЧщЯЕЭГЕФНщЩмЃЌЭјвГХРГцЪ§ОндкЯЕЭГСїЖЏжаЛсгаЫФИіНзЖЮЗжБ№ЪЧдЪМЭјвГФкШнЃЌЭјвГНсЙЙЛЏЪ§ОнЃЌЗжЮіЙцдђдЊЪ§ОнКЭгпЧщНсЙћЃЌгпЧщНсЙћЫїв§ЁЃЮвУЧРћгУTablestoreПэааКЭschema
freeЕФЬиадЃЌКЯВЂдЪМЭјвГКЭЭјвГНсЙЙЛЏЪ§ОнГЩвЛеХЭјвГЪ§ОнЁЃЭјвГЪ§ОнБэКЭМЦЫуЯЕЭГЭЈЙ§TablestoreаТЙІФмЭЈЕРЗўЮёНјааЖдНгЁЃЭЈЕРЗўЮёЛљгкЪ§ОнПтШежОЃЌЪ§ОнЕФзщжЏНсЙЙАДееЪ§ОнЕФаДШыЫГађНјааДцДЂЃЌе§ЪЧетвЛЬиадЃЌИГФмЪ§ОнПтОпБИСЫЖгСаСїЪНЯћЗбФмСІЁЃЪЙЕУДцДЂв§ЧцМШПЩвдОпБИЪ§ОнПтЕФЫцЛњЗУЮЪЃЌвВПЩвдОпБИЖгСаЕФАДееаДШыЫГађЗУЮЪЃЌетвВОЭТњзуЮвУЧЩЯУцЬсЕНећКЯLambdaКЭkappaМмЙЙЕФашЧѓЁЃЗжЮіЙцдђдЊЪ§ОнБэгЩЗжЮіЙцдђЃЌЧщИаДЪПтзщВуЃЌЖдгІЪЕЪБМЦЫужаЕФЮЌБэЁЃ
МЦЫуЯЕЭГетРябЁгУАЂРядЦЪЕЪБСїМЦЫуВњЦЗBlinkЃЌBlinkЪЧвЛПюжЇГжСїМЦЫуКЭХњМЦЫувЛЬхЕФЪЕЪБМЦЫуВњЦЗЁЃВЂЧвРрЫЦTablestoreПЩвдКмШнвзЕФзіЕНЗжВМЪНЫЎЦНРЉеЙЃЌШУМЦЫузЪдДЫцзХвЕЮёЪ§ОндіГЄЕЏадРЉШнЁЃЪЙгУTablestore
+ BlinkЕФгХЪЦгавдЯТМИЕуЃК
TablestoreвбОЩюЖШКЭBlinkНјааећКЯЃЌжЇГждДБэЃЌЮЌБэКЭФПЕФБэЃЌвЕЮёЮоашЮЊЪ§ОнСїЖЏПЊЗЂДњТыЁЃ
ећЬзМмЙЙДѓЗљНЕЕЭзщНЈИіЪ§ЃЌДгПЊдДВњЦЗЕФ6ЁЋ7ИізщНЈМѕЩйЕН2ИіЃЌTablestoreКЭBlinkЖМЪЧШЋЭаЙм0дЫЮЌЕФВњЦЗЃЌВЂЧвЖМФмзіЕНКмКУЕФЫЎЦНЕЏадЃЌвЕЮёЗхжЕРЉеЙЮобЙСІЃЌЪЙЕУДѓЪ§ОнМмЙЙЕФдЫЮЌГЩБОДѓЗљНЕЕЭЁЃ
вЕЮёЗНжЛашвЊЙизЂЪ§ОнЕФДІРэВПЗжТпМЃЌКЭTablestoreЕФНЛЛЅТпМЖМвбОМЏГЩдкBlinkжаЁЃ
ПЊдДЗНАИжаЃЌШчЙћЪ§ОнПтдДЯЃЭћЖдНгЪЕЪБМЦЫуЃЌЛЙашвЊЫЋаДвЛИіЖгСаЃЌШУСїМЦЫув§ЧцЯћЗбЖгСажаЕФЪ§ОнЁЃЮвУЧЕФМмЙЙжаЪ§ОнПтМШзїЮЊЪ§ОнБэЃЌгжЪЧЖгСаЭЈЕРПЩвдЪЕЪБдіСПЪ§ОнЯћЗбЁЃДѓДѓМђЛЏСЫМмЙЙЕФПЊЗЂКЭЪЙгУГЩБОЁЃ
СїХњвЛЬхЃЌдкгпЧщЯЕЭГжаЪЕЪБадЪЧжСЙиживЊЕФЃЌЫљвдЮвУЧашвЊвЛИіЪЕЪБМЦЫув§ЧцЃЌЖјBlinkГ§СЫЪЕЪБМЦЫувдЭтЃЌвВжЇГжХњДІРэTablestoreЕФЪ§ОнЃЌ
дквЕЮёЕЭЗхЦкЃЌЭљЭљвВашвЊХњСПДІРэвЛаЉЪ§ОнВЂзїЮЊЗДРЁНсЙћаДЛиTablestoreЃЌР§ШчЧщИаЗжЮіЗДРЁЕШЁЃФЧУДвЛЬзМмЙЙМШПЩвджЇГжСїДІРэгжПЩвджЇГжХњДІРэЪЧдйКУВЛЙ§ЁЃетРяЮвУЧПЩвдВЮПМжЎЧАЕФвЛЦЊЮФеТЁЖЪЕЪБМЦЫузюМбЪЕМљЃКЛљгкБэИёДцДЂКЭBlinkЕФДѓЪ§ОнЪЕЪБМЦЫуЁЗЁЃвЛЬзМмЙЙДјРДЕФгХЪЦЪЧЃЌвЛЬзЗжЮіДњТыМШПЩвдзіЪЕЪБСїМЦЫугжПЩвдРыЯпХњДІРэЁЃ
ећИіМЦЫуСїГЬЛсВњЩњЪЕЪБЕФгпЧщМЦЫуНсЙћЁЃжиДѓгпЧщЪТМўЕФдЄОЏЃЌЭЈЙ§TablestoreКЭКЏЪ§МЦЫуДЅЗЂЦїЖдНгРДЪЕЯжЁЃTablestoreКЭКЏЪ§МЦЫузіСЫдіСПЪ§ОнЕФЮоЗьЖдНгЃЌЭЈЙ§НсЙћБэаДШыЪТМўЃЌПЩвдЧсЫЩЕФЭЈЙ§КЏЪ§МЦЫуДЅЗЂЖЬаХЛђепгЪМўЭЈжЊЁЃЭъећЕФгпЧщЗжЮіНсЙћКЭеЙЪОЫбЫїРћгУСЫTablestoreЕФаТЙІФмЖрдЊЫїв§ЃЌГЙЕзНтОіСЫПЊдДHbase+SolrЖрв§ЧцЕФЭДЕуЃК
дЫЮЌИДдгЃЌашвЊгадЫЮЌhbaseКЭsolrСНЬзЯЕЭГЕФФмСІЃЌЭЌЪБЛЙашвЊЮЌЛЄЪ§ОнЭЌВНЕФСДТЗЁЃ
SolrЪ§ОнвЛжТадВЛШчHbaseЃЌдкHbaseКЭSolrЪ§ОнгявтВЂВЛЪЧЭъШЋвЛжТЃЌМгЩЯSolr/ElasticsearchдкЪ§ОнвЛжТадКмФбзіЕНЯёЪ§ОнПтФЧУДбЯИёЁЃдквЛаЉМЋЖЫЧщПіЯТЛсГіЯжЪ§ОнВЛвЛжТЕФЮЪЬтЃЌПЊдДЗНАИвВКмФбзіЕНПчЯЕЭГЕФвЛжТадБШЖдЁЃ
ВщбЏНгПкашвЊЮЌЛЄСНЬзAPIЃЌашвЊЭЌЪБЪЙгУHbase clientКЭSolr clientЃЌЫїв§жаУЛгаЕФзжЖЮашвЊжїЖЏЗДВщHbaseЃЌвзгУадНЯВюЁЃ
ВЮПМЮФЯз
LambdaДѓЪ§ОнМмЙЙ
KappaДѓЪ§ОнМмЙЙ
LambdaКЭKappaМмЙЙЖдБШ
змНс
БОЮФЛљгкЁЖАйвкМЖШЋЭјгпЧщЗжЮіЯЕЭГДцДЂЩшМЦЁЗВЂНсКЯTablestoreЕФаТЙІФмзіСЫЯжДњДѓЪ§ОнгпЧщЯЕЭГЕФМмЙЙЩ§МЖЃЌЪЕЯжСЫКЃСПаХЯЂЯТЕФЪЕЪБгпЧщЗжЮіДцДЂЯЕЭГЁЃвВНщЩмСЫПЊдДЗНАИЃЌВЂКЭЮвУЧЕФЗНАИзіСЫЯъЯИЕФЖдБШЁЃ
|









