| БрМЭЦМі: |
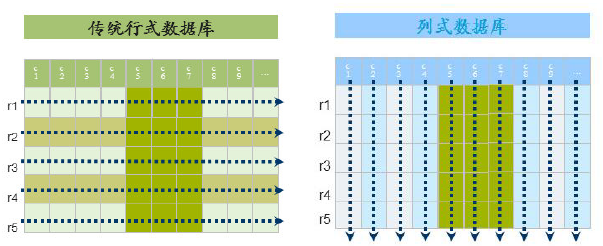
БОЮФЪзЯШЖдHBaseзіГіЛљБОНщЩмЃЌЦфДЮНщЩмСЫHBaseЕФЪ§ОнФЃаЭЁЂЪЕЯждРэЁЂЯЕЭГМмЙЙКЭгІгУЗНАИЃЌзюКѓНщЩмСЫЛЊЮЊЕФдіЧПЬиадЃЌИќЖрСЫНтЧыдФЖСЯТЮФЁЃ
БОЮФРДздИіШЫВЉПЭЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
HBaseЛљБОНщЩм
BigTableМђНщЃК
BigTableЪЧвЛИіЗжВМЪНДцДЂЯЕЭГЃЌBigTableЦ№ГѕгУгкНтОіЕфаЭЕФЛЅСЊЭјЫбЫїЮЪЬтЁЃ
BigTableЪЧвЛИіЗжВМЪНДцДЂЯЕЭГЁЃ
РћгУЙШИшЬсГіЕФMapReduceЗжВМЪНВЂааМЦЫуФЃаЭРДДІРэКЃСПЪ§ОнЁЃ
ЪЙгУЙШИшЗжВМЪНЮФМўЯЕЭГGFSзїЮЊЕзВуЪ§ОнДцДЂЁЃ
ВЩгУChubbyЬсЙЉаЭЌЗўЮёЙмРэЁЃ
ПЩвдРЉеЙЕНPBМЖБ№ЕФЪ§ОнКЭЩЯЧЇЬЈЛњЦїЃЌОпБИЙуЗКгІгУадЁЂПЩРЉеЙадЁЂИпадФмКЭИпПЩгУадЕШЬиЕуЁЃ
ЙШИшЕФаэЖрЯюФПЖМДцДЂдкBigTableжаЃЌАќРЈЫбЫїЁЂЕиЭМЁЂВЦОЁЃ
HBaseМђНщЃК
HBaseЪЧвЛИіИпПЩППЁЂИпадФмЁЂУцЯђСаЁЂПЩЩьЫѕЕФЗжВМЪНЪ§ОнПтЃЌЪЧЙШИшBigTableЕФПЊдДЪЕЯжЃЌжївЊгУРДДцДЂЗЧНсЙЙЛЏКЭАыНсЙЙЛЏЕФЫЩЩЂЪ§ОнЁЃHBaseЕФФПБъЪЧДІРэЗЧГЃХгДѓЕФБэЃЌПЩвдЭЈЙ§ЫЎЦНРЉеЙЕФЗНЪНЃЌРћгУСЎМлМЦЫуЛњМЏШКДІРэгЩГЌЙ§10вкааЪ§ОнКЭЪ§АйЭђСадЊЫизщГЩЕФЪ§ОнБэЁЃ
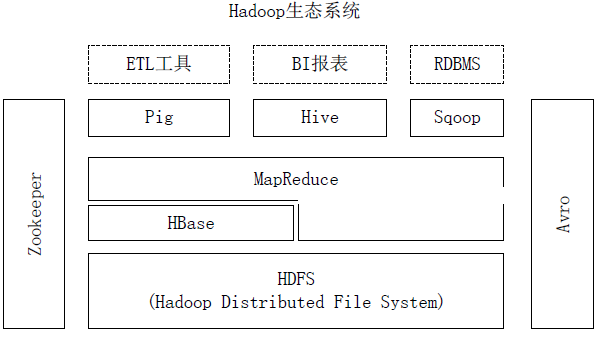
ЭМЃКHadoopЩњЬЌЯЕЭГжаHBaseгыЦфЫћВПЗжЕФЙиЯЕ
ЪЪКЯгУгкДѓБэЪ§ОнЃЈБэЕФЙцФЃПЩвдДяЕНЪ§ЪЎвкаавдМАЪ§АйЭђСаЃЉЃЌВЂЧвЖдДѓБэЪ§ОнЕФЖСаДЗУЮЪПЩвдДяЕНЪЕЪБМЖБ№ЁЃ
РћгУHadoop HDFSзїЮЊЦфЮФМўДцДЂЯЕЭГЃЌЬсЙЉЪЕЪБЖСаДЕФЗжВМЪНЪ§ОнПтЯЕЭГЁЃ
РћгУZooKeeperзїЮЊаЭЌЗўЮёЁЃ
HBaseКЭBigTableЕФЕзВуММЪѕЖдгІЙиЯЕЃК
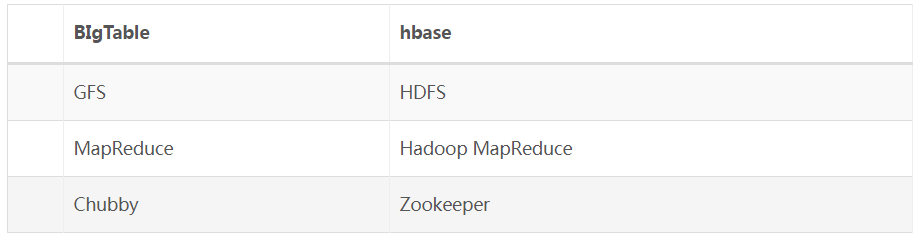
HBaseГіЯжЕФдвђЃК
ЙиЯЕЪ§ОнПтвбОСїааКмЖрФъЃЌВЂЧвHadoopвбОгаСЫHDFSКЭMapReduceЃЌЮЊЪВУДашвЊHBase?
HadoopПЩвдКмКУЕиНтОіДѓЙцФЃЪ§ОнЕФРыЯпХњСПДІРэЮЪЬтЃЌЕЋЪЧЃЌЪмЯогкHadoop MapReduceБрГЬПђМмЕФИпбгГйЪ§ОнДІРэЛњжЦЃЌЪЙЕУHadoopЮоЗЈТњзуДѓЙцФЃЪ§ОнЪЕЪБДІРэгІгУЕФашЧѓЁЃ
HDFSУцЯђХњСПЗУЮЪФЃЪНЃЌВЛЪЧЫцЛњЗУЮЪФЃЪНЁЃ
ДЋЭГЕФЭЈгУЙиЯЕаЭЪ§ОнПтЮоЗЈгІЖддкЪ§ОнЙцФЃОчдіЪБЕМжТЕФЯЕЭГРЉеЙадКЭадФмЮЪЬтЃЈЗжПтЗжБэвВВЛФмКмКУНтОіЃЉЁЃ
ДЋЭГЙиЯЕЪ§ОнПтдкЪ§ОнНсЙЙБфЛЏЪБвЛАуашвЊЭЃЛњЮЌЛЄЃЛПеСаРЫЗбДцДЂПеМфЁЃ
вђДЫЃЌвЕНчГіЯжСЫвЛРрУцЯђАыНсЙЙЛЏЪ§ОнДцДЂКЭДІРэЕФИпПЩРЉеЙЁЂЕЭаДШы/ВщбЏбгГйЕФЯЕЭГЃЌР§ШчЃЌМќжЕЪ§ОнПтЁЂЮФЕЕЪ§ОнПтКЭСазхЪ§ОнПтЃЈШчBigTableКЭHBaseЕШЃЉЁЃ
HBaseвбОГЩЙІгІгУгкЛЅСЊЭјЗўЮёСьгђКЭДЋЭГаавЕЕФжкЖрдкЯпЪНЪ§ОнЗжЮіДІРэЯЕЭГжаЁЃ
HBaseгыДЋЭГЙиЯЕЪ§ОнПтЖдБШЗжЮіЃК
HBaseгыДЋЭГЕФЙиЯЕЪ§ОнПтЕФЧјБ№жївЊЬхЯждквдЯТМИИіЗНУцЃК
Ъ§ОнРраЭЃКЙиЯЕЪ§ОнПтВЩгУЙиЯЕФЃаЭЃЌОпгаЗсИЛЕФЪ§ОнРраЭКЭДцДЂЗНЪНЃЌHBaseдђВЩгУСЫИќМгМђЕЅЕФЪ§ОнФЃаЭЃЌЫќАбЪ§ОнДцДЂЮЊЮДОНтЪЭЕФзжЗћДЎЁЃ
Ъ§ОнВйзїЃКЙиЯЕЪ§ОнПтжаАќКЌСЫЗсИЛЕФВйзїЃЌЦфжаЛсЩцМАИДдгЕФЖрБэСЌНгЁЃHBaseВйзїдђВЛДцдкИДдгЕФБэгыБэжЎМфЕФЙиЯЕЃЌжЛгаМђЕЅЕФВхШыЁЂВщбЏЁЂЩОГ§ЁЂЧхПеЕШЃЌвђЮЊHBaseдкЩшМЦЩЯОЭБмУтСЫИДдгЕФБэКЭБэжЎМфЕФЙиЯЕЁЃ
ДцДЂФЃЪНЃКЙиЯЕЪ§ОнПтЪЧЛљгкааФЃЪНДцДЂЕФЁЃHBaseЪЧЛљгкСаДцДЂЕФЃЌУПИіСазхЖМгЩМИИіЮФМўБЃДцЃЌВЛЭЌСазхЕФЮФМўЪЧЗжРыЕФЁЃ
Ъ§ОнЫїв§ЃКЙиЯЕЪ§ОнПтЭЈГЃПЩвдеыЖдВЛЭЌСаЙЙНЈИДдгЕФЖрИіЫїв§ЃЌвдЬсИпЪ§ОнЗУЮЪадФмЁЃHBaseжЛгавЛИіЫїв§ЁЊЁЊааМќЃЌЭЈЙ§ЧЩУюЕФЩшМЦЃЌHBaseжаЕФЫљгаЗУЮЪЗНЗЈЃЌЛђепЭЈЙ§ааМќЗУЮЪЃЌЛђепЭЈЙ§ааМќЩЈУшЃЌДгЖјЪЙЕУећИіЯЕЭГВЛЛсТ§ЯТРДЁЃ
Ъ§ОнЮЌЛЄЃКдкЙиЯЕЪ§ОнПтжаЃЌИќаТВйзїЛсгУзюаТЕФЕБЧАжЕШЅЬцЛЛМЧТМжадРДЕФОЩжЕЃЌОЩжЕБЛИВИЧКѓОЭВЛЛсДцдкЁЃЖјдкHBaseжажДааИќаТВйзїЪБЃЌВЂВЛЛсЩОГ§Ъ§ОнОЩЕФАцБОЃЌЖјЪЧЩњГЩвЛИіаТЕФАцБОЃЌОЩгаЕФАцБОШдШЛБЃСєЁЃ
ПЩЩьЫѕадЃКЙиЯЕЪ§ОнПтКмФбЪЕЯжКсЯђРЉеЙЃЌзнЯђРЉеЙЕФПеМфвВБШНЯгаЯоЁЃЯрЗДЃЌHBaseКЭBigTableетаЉЗжВМЪНЪ§ОнПтОЭЪЧЮЊСЫЪЕЯжСщЛюЕФЫЎЦНРЉеЙЖјПЊЗЂЕФЃЌФмЙЛЧсвзЕиЭЈЙ§дкМЏШКжадіМгЛђепМѕЩйгВМўЪ§СПРДЪЕЯжадФмЕФЩьЫѕ
HBaseгІгУГЁОАЃК
HBaseЪЪКЯОпгаШчЯТашЧѓЕФгІгУЃК
КЃСПЪ§ОнЃЈTBЃЌPBЃЉЁЃ
ВЛашвЊЭъШЋгЕгаДЋЭГЙиЯЕаЭЪ§ОнПтЫљОпБИЕФACIDЬиадЁЃ
ИпЭЬЭТСПЁЃ
ашвЊдкКЃСПЪ§ОнжаЪЕЯжИпаЇЕФЫцЛњЖСШЁЁЃ
ашвЊКмКУЕФадФмЩьЫѕадЁЃ
ФмЙЛЭЌЪБДІРэНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
HBaseЗУЮЪНгПкЃК
HBaseдкFusionInsightжаЕФЮЛжУЃК
HBaseзїЮЊвЛИіИпПЩППадЁЂИпадФмЁЂУцЯђСаЁЂПЩЩьЫѕЕФЗжВМЪНЪ§ОнПтЃЌЬсЙЉКЃСПЪ§ОнДцДЂЙІФмЃЌгУРДНтОіЙиЯЕаЭЪ§ОнПтдкКЃСПЪ§ОнЪБЕФОжЯоадЁЃ
ЭМЃК HBaseдкFusionInsightжаЕФЮЛжУ
HBaseЪ§ОнФЃаЭ
Ъ§ОнФЃаЭИХЪіЃК
HBaseЪЧвЛИіЯЁЪшЁЂЖрЮЌЖШЁЂХХађЕФгГЩфБэЃЌетеХБэЕФЫїв§ЪЧааМќЁЂСазхЁЂСаЯоЖЈЗћКЭЪБМфДСЁЃ
УПИіжЕЪЧвЛИіЮДОНтЪЭЕФзжЗћДЎЃЌУЛгаЪ§ОнРраЭЁЃ
гУЛЇдкБэжаДцДЂЪ§ОнЃЌУПвЛааЖМгавЛИіПЩХХађЕФааМќКЭШЮвтЖрЕФСаЁЃ
БэдкЫЎЦНЗНЯђгЩвЛИіЛђепЖрИіСазхзщГЩЃЌвЛИіСазхжаПЩвдАќКЌШЮвтЖрИіСаЃЌЭЌвЛИіСазхРяУцЕФЪ§ОнДцДЂдквЛЦ№ЁЃ
СазхжЇГжЖЏЬЌРЉеЙЃЌПЩвдКмЧсЫЩЕиЬэМгвЛИіСазхЛђСаЃЌЮоашдЄЯШЖЈвхСаЕФЪ§СПвдМАРраЭЃЌЫљгаСаОљвдзжЗћДЎаЮЪНДцДЂЃЌгУЛЇашвЊздааНјааЪ§ОнРраЭзЊЛЛЁЃ
HBaseжажДааИќаТВйзїЪБЃЌВЂВЛЛсЩОГ§Ъ§ОнОЩЕФАцБОЃЌЖјЪЧЩњГЩвЛИіаТЕФАцБОЃЌОЩгаЕФАцБОШдШЛБЃСєЃЈетЪЧКЭHDFSжЛдЪаэзЗМгВЛдЪаэаоИФЕФЬиадЯрЙиЕФЃЉЁЃ
Ъ§ОнФЃаЭЯрЙиИХФюЃК
БэЃКHBaseВЩгУБэРДзщжЏЪ§ОнЃЌБэгЩааКЭСазщГЩЃЌСаЛЎЗжЮЊШєИЩИіСазхЁЃ
ааЃКУПИіHBaseБэЖМгЩШєИЩаазщГЩЃЌУПИіаагЩааМќЃЈrow keyЃЉРДБъЪЖЁЃ
СазхЃКвЛИіHBaseБэБЛЗжзщГЩаэЖрЁАСазхЁБЃЈColumn FamilyЃЉЕФМЏКЯЃЌЫќЪЧЛљБОЕФЗУЮЪПижЦЕЅдЊЁЃ
СаЯоЖЈЗћЃКСазхРяЕФЪ§ОнЭЈЙ§СаЯоЖЈЗћЃЈЛђСаЃЉРДЖЈЮЛЁЃ
ЕЅдЊИёЃКдкHBaseБэжаЃЌЭЈЙ§ааЁЂСазхКЭСаЯоЖЈЗћШЗЖЈвЛИіЁАЕЅдЊИёЁБЃЈcellЃЉЃЌЕЅдЊИёжаДцДЂЕФЪ§ОнУЛгаЪ§ОнРраЭЃЌзмБЛЪгЮЊзжНкЪ§зщbyte[]ЁЃ
ЪБМфДСЃКУПИіЕЅдЊИёЖМБЃДцзХЭЌвЛЗнЪ§ОнЕФЖрИіАцБОЃЌетаЉАцБОВЩгУЪБМфДСНјааЫїв§ЁЃ
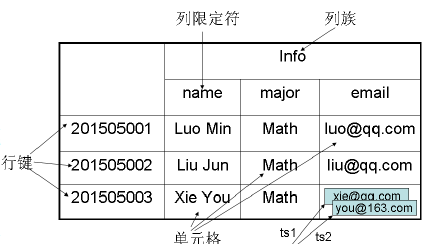
ЭМЃКБэЪОР§
ШчЩЯЭМЃКИУЕЅдЊИёга2ИіЪБМфДСts1КЭts2ЃЌУПИіЪБМфДСЖдгІвЛИіЪ§ОнАцБОЁЃ
Ъ§ОнзјБъЃК
HBaseжаашвЊИљОнааМќЁЂСазхЁЂСаЯоЖЈЗћКЭЪБМфДСРДШЗЖЈвЛИіЕЅдЊИёЃЌвђДЫЃЌПЩвдЪгЮЊвЛИіЁАЫФЮЌзјБъЁБЃЌМД[ааМќ,
Сазх, СаЯоЖЈЗћ, ЪБМфДС]ЁЃ
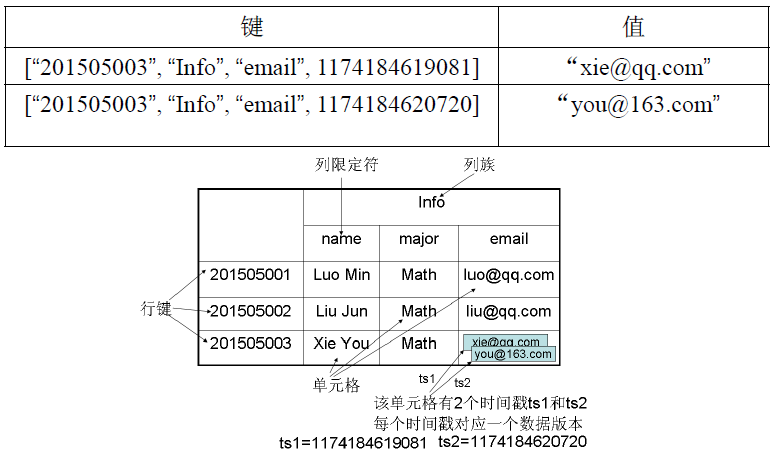
ЭМЃКЪ§ОнБэЪОЗЈЪОР§
ИХФюЪгЭМЃК
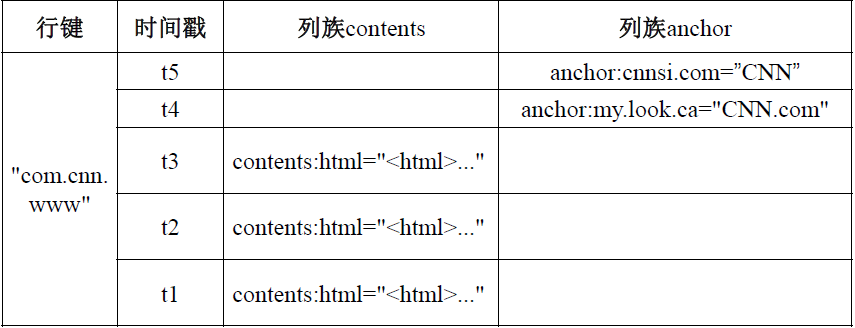
ЭМЃКHBaseЪ§ОнЕФИХФюЪгЭМ
ЮяРэЪгЭМ:
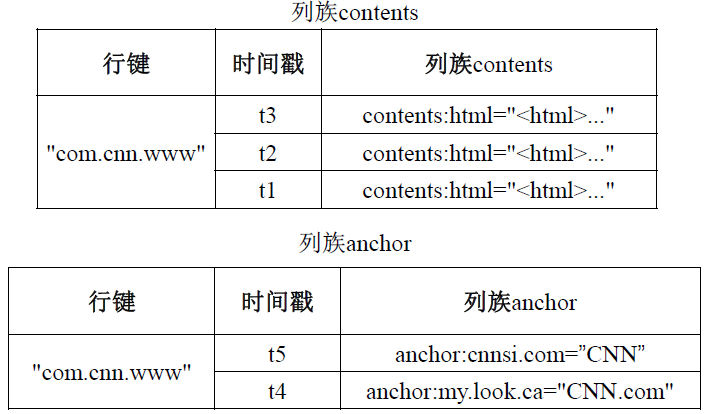
ЭМЃКHBaseЪ§ОнЕФЮяРэЪгЭМ
УцЯђСаЕФДцДЂЃК
ЭМЃККЛЪЕЪ§ОнПтКЭСаЪНЪ§ОнПтЪОвтЭМ
ааДцДЂЃКЪ§ОнАДааДцДЂдкЕзВуЮФМўЯЕЭГжаЁЃЭЈГЃЃЌУПвЛааЛсБЛЗжХфЙЬЖЈЕФПеМфЁЃ
гХЕуЃКгаРћгкдіМгЁЂаоИФећааМЧТМЕШВйзїЃЛгаРэгЩЪ§ОнЕФЖСШЁВйзїЁЃ
ШБЕуЃКЕЅСаВщбЏЪБЃЌЛсЖСШЁвЛаЉВЛБивЊЕФЪ§ОнЁЃ
СаДцДЂЃКЪ§ОнвдСаЮЊЕЅЮЛЃЌДцДЂдкЕзВуЮФМўЯЕЭГжаЁЃ
гХЕуЃКгаРћгкУцЯђЕЅСаЪ§ОнЕФЖСШЁЁЂЭГМЦЕШВйзїЁЃ
ШБЕуЃКећааЖСШЁЪБЃЌПЩФмашвЊЖрДЮI/OВйзїЁЃ
KeyValueДцДЂФЃаЭЃК
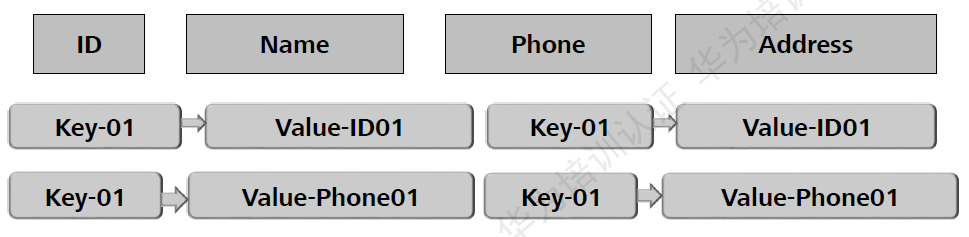
ЭМЃКKeyValueДцДЂФЃаЭ
KeyValueОпгаЬиадЕФНсЙЙЁЃKeyВПЗжБЛгУРДПьЫйМьЫївЛЬѕЪ§ОнМЧТМЃЌValueВПЗжгУРДДцДЂЪЕМЪЕФгУЛЇЪ§ОнаХЯЂЁЃ
KeyValueзїЮЊГадигУЛЇЪ§ОнЕФЛљБОЕЅдЊЃЌашвЊБЃДцвЛаЉЖдздЩэЕФУшЪіаХЯЂЁЃР§ШчЃЌЪБМфДСЃЌРраЭЕШЕШЁЃФЧУДЪЦБиЛсгавЛЖЈЕФНсЙЙЛЏПеМфПЊЯњЁЃ
жЇГжЖЏЬЌдіМгСаЃЌШнвзЪЪгІЪ§ОнРраЭКЭНсЙЙЕФБфЛЏЁЃвдПщЮЊЕЅдЊВйзїЪ§ОнЃЌСаМфЁЂБэМфВЂЮоЙиСЊЙиЯЕЁЃ
KeyValueаЭЪ§ОнПтЪ§ОнЗжЧјЗНЪНЈCАДKeyжЕСЌајЗЖЮЇЗжЧјЁЃШчЯТЭМЃК
Ъ§ОнАДееRowKeyЕФЗЖЮЇЃЈАДRowKeyЕФзжЕфЫГађЃЉЃЌЛЎЗжЮЊвЛИіИіЕФзгЧјМфЁЃУПвЛИізгЧјМфЖМЪЧвЛИіЗжВМЪНДцДЂЕФЛљБОЕЅдЊЁЃ
HBaseЕФЕзВуЪ§ОнвдKeyValueЕФаЮЪНДцдкЃЌKeyValueОпгаЬиЖЈЕФИёЪНЁЃ
KeyValueжагЕгаЪБМфДСЁЂРраЭЕШЙиМќаХЯЂЁЃ
ЭЌвЛИіKeyжЕПЩвдЙиСЊЖрИіValueЃЌУПвЛИіKeyValueЖМгЕгавЛИіQualifierБъЪЖЁЃ
МДЪЙЪЧKeyжЕЯрЭЌЃЌQualifierвВЯрЭЌЕФЖрИіKeyValueЃЌвВПЩФмгаЖрИіЃЌДЫЪБЪЙгУЪБМфДСРДЧјЗжЃЌетОЭЪЧЭЌвЛЬѕЪ§ОнМЧТМЕФЖрАцБОЁЃ
HBaseЪЕЯждРэ
HBaseЙІФмзщМўЃК
HBaseЕФЪЕЯжАќРЈШ§ИіжївЊЕФЙІФмзщМўЃК
ПтКЏЪ§ЃКСДНгЕНУПИіПЭЛЇЖЫ
вЛИіMasterжїЗўЮёЦї
аэЖрИіRegionЗўЮёЦї
жїЗўЮёЦїMasterИКд№ЙмРэКЭЮЌЛЄHBaseБэЕФЗжЧјаХЯЂЃЌЮЌЛЄRegionЗўЮёЦїСаБэЃЌЗжХфRegionЃЌИКдиОљКтЁЃ
RegionЗўЮёЦїИКд№ДцДЂКЭЮЌЛЄЗжХфИјздМКЕФRegionЃЌДІРэРДздПЭЛЇЖЫЕФЖСаДЧыЧѓЁЃ
ПЭЛЇЖЫВЂВЛЪЧжБНгДгMasterжїЗўЮёЦїЩЯЖСШЁЪ§ОнЃЌЖјЪЧдкЛёЕУRegionЕФДцДЂЮЛжУаХЯЂКѓЃЌжБНгДгRegionЗўЮёЦїЩЯЖСШЁЪ§ОнЁЃ
ПЭЛЇЖЫВЂВЛвРРЕMasterЃЌЖјЪЧЭЈЙ§ZookeeperРДЛёЕУRegionЮЛжУаХЯЂЃЌДѓЖрЪ§ПЭЛЇЖЫЩѕжСДгРДВЛКЭMasterЭЈаХЃЌетжжЩшМЦЗНЪНЪЙЕУMasterИКдиКмаЁЁЃ
RegionЛљБОИХФюЃК
Region
ЭМЃКRegionЕФРДдД
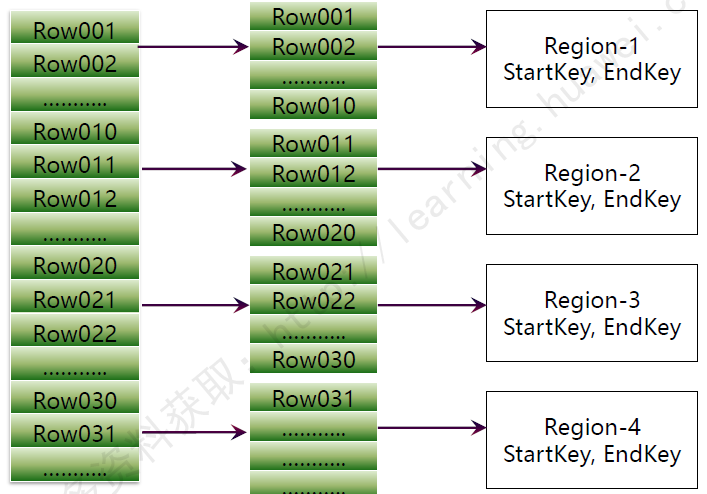
НЋвЛИіЪ§ОнБэАДKeyжЕЗЖЮЇКсЯђЛЎЗжЮЊвЛИіИіЕФзгБэЃЌЪЕЯжЗжВМЪНДцДЂЁЃ
етИізгБэЃЌдкHBaseжаБЛГЦзїЁАRegionЁБЁЃ
УПвЛИіRegionЖМЙиСЊвЛИіKeyжЕЗЖЮЇЃЌМДвЛИіЪЙгУStartKeyКЭEndKeyУшЪіЕФЧјМфЃЌЪТЪЕЩЯЃЌУПвЛИіRegionНіНіМЧТМStartKeyОЭПЩвдЃЌвђЮЊЫќЕФEndKeyОЭЪЧЯТвЛИіRegionЕФStartKeyЁЃ
RegionЪЧHBaseЗжВМЪНДцДЂЕФзюЛљБОЕЅдЊЁЃ
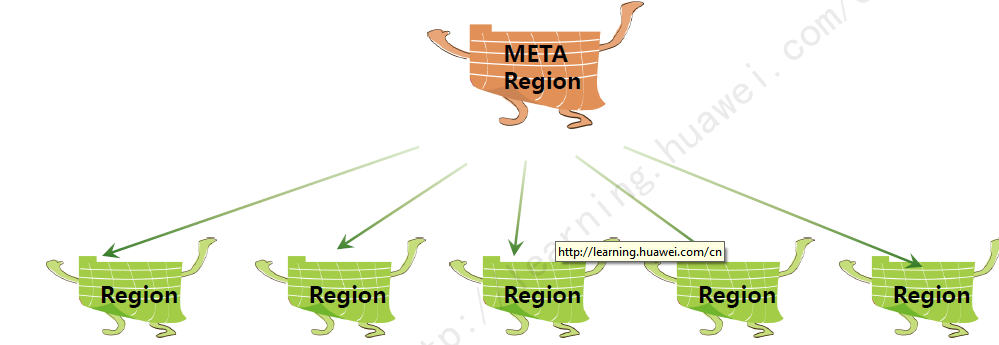
ЭМЃКRegionЗжРр
RegionЗжЮЊдЊЪ§ОнRegionвдМАгУЛЇRegionСНРрЁЃ
Meta RegionМЧТМСЫУПвЛИіUser RegionЕФТЗгЩаХЯЂЁЃ
ЖСаДRegionЪ§ОнЕФТЗгЩЃЌАќРЈШчЯТМИВНЃК
бАевMeta RegionЕижЗЁЃ
дйгЩMeta RegionбАевUser RegionЕижЗЁЃ
Column Family(Сазх)ЃК
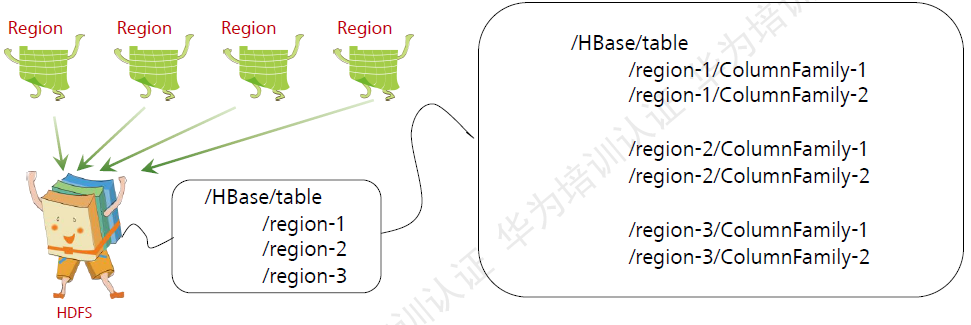
ЭМЃКСазх
ColumnFamilyЪЧRegionЕФвЛИіЮяРэДцДЂЕЅдЊЁЃЭЌвЛИіRegionЯТУцЕФЖрИіColumnFamilyЃЌЮЛгкВЛЭЌЕФТЗОЖЯТУцЁЃ
ColumnFamilyаХЯЂЪЧБэМЖБ№ЕФХфжУЁЃвВОЭЪЧЫЕЃЌЭЌвЛИіБэЕФЖрИіRegionЃЌЖМгЕгаЯрЭЌЕФColumnFamilyаХЯЂЁЃЃЈР§ШчЃЌЖМгаСНИіColumnFamilyЃЌЧвВЛЭЌRegionЕФЭЌвЛИіColumnFamilyХфжУаХЯЂЯрЭЌЃЉЁЃ
БэКЭRegionЃК
ПЊЪМжЛгавЛИіRegionЃЌКѓРДВЛЖЯЗжСбRegionВ№ЗжВйзїЗЧГЃПьЃЌНгНќЫВМфЃЌвђЮЊВ№ЗжжЎКѓЕФRegionЖСШЁЕФШдШЛЪЧдДцДЂЮФМўЃЌжБЕНЁАКЯВЂЁБЙ§ГЬАбДцДЂЮФМўвьВНЕиаДЕНЖРСЂЕФЮФМўжЎКѓЃЌВХЛсЖСШЁаТЮФМўЁЃ
УПИіRegionФЌШЯДѓаЁЪЧ100MBЕН200MBЃЈ2006ФъвдЧАЕФгВМўХфжУЃЉ
УПИіRegionЕФзюМбДѓаЁШЁОігкЕЅЬЈЗўЮёЦїЕФгааЇДІРэФмСІЁЃ
ФПЧАУПИіRegionзюМбДѓаЁНЈвщ1GB-2GBЃЈ2013ФъвдКѓЕФгВМўХфжУЃЉЁЃ
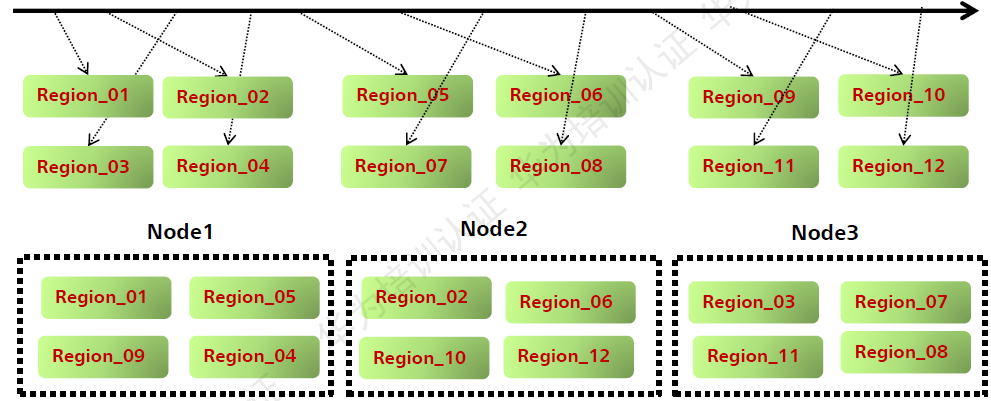
ЭЌвЛИіRegionВЛЛсБЛЗжВ№ЕНЖрИіRegionЗўЮёЦї.
УПИіRegionЗўЮёЦїДцДЂ10-1000ИіRegion.
RegionЕФЖЈЮЛ:
дЊЪ§ОнБэ
гжУћ.META.БэЃЌДцДЂСЫRegionКЭRegionЗўЮёЦїЕФгГЩфЙиЯЕ.гУРДАяжњClientЖЈЮЛЕНОпЬхЕФRegionЁЃ
ЕБHBaseБэКмДѓЪБЃЌдЊЪ§ОнвВЛсБЛЧаЗжЮЊЖрИіReginaЃЌRegionЕФдЊЪ§ОнаХЯЂБЃДцдкZookeeperжаЁЃ
ИљЪ§ОнБэЃЌгжУћ-ROOT-БэЃЌМЧТМЫљгадЊЪ§ОнЕФОпЬхЮЛжУЁЃ
-ROOT-БэжЛгаЮЈвЛвЛИіRegionЃЌУћзжЪЧдкГЬађжаБЛаДЫРЕФЁЃ
ZookeeperЮФМўМЧТМСЫ-ROOT-БэЕФЮЛжУЁЃ
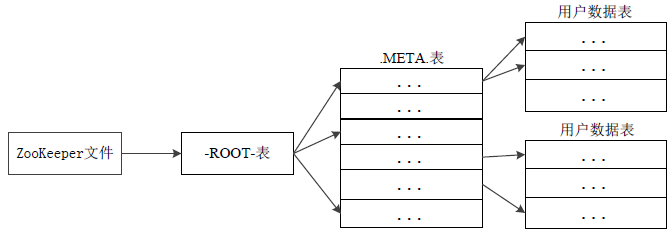
ЭМЃКHBaseЕФШ§ВуНсЙЙ
HBaseЕФШ§ВуНсЙЙжаИїВуДЮЕФУћГЦКЭзїгУЃК
ЕквЛВуЃКZookeeperЮФМўЃЌМЧТМвд-ROOt-БэЕФЮЛжУаХЯЂЁЃ
ЕкЖўВуЃК-ROOT-БэЃЌМЧТМСЫ.META.БэЕФRegionЮЛжУаХЯЂЁЃ-ROOT-БэжЛФмвЛИіRegionЁЃЭЈЙ§-ROOT-БэЃЌОЭПЩвдЗУЮЪ.METAЁЃБэжаЕФЪ§ОнЁЃ
ЕкШ§ВуЃК.META.БэЃЌМЧТМСЫгУЛЇЪ§ОнБэЕФRegionЮЛжУЯЂЃЌ.META.БэПЩвдгаЖрИіRegionЃЌБЃДцСЫHBaseжаЫљгагУЛЇЪ§ОнБэЕФRegionЮЛжУаХЯЂЁЃ
ЮЊСЫМгПьЗУЮЪЫйЖШЃЌ.META.БэЕФШЋВПRegionЖМЛсБЛБЃДцдкФкДцжаЁЃ
МйЩш.META.БэЕФУПааЃЈвЛИігГЩфЬѕФПЃЉдкФкДцжаДѓдМеМгУ1KBЃЌВЂЧвУПИіRegionЯожЦЮЊ128MBЃЌФЧУДЃЌЩЯУцЕФШ§ВуНсЙЙПЩвдБЃДцЕФгУЛЇЪ§ОнБэЕФRegionЪ§ФПЕФМЦЫуЗНЗЈЪЧЃК
-ROOT-БэФмЙЛбАжЗЕФ.META.БэЕФRegionИіЪ§ЃЉЁСЃЈУПИі.META.БэЕФ RegionПЩвдбАжЗЕФгУЛЇЪ§ОнБэЕФRegionИіЪ§ЃЉ
вЛИі-ROOT-БэзюЖржЛФмгавЛИіRegionЃЌвВОЭЪЧзюЖржЛФмга128MBЃЌАДееУПааЃЈвЛИігГЩфЬѕФПЃЉеМгУ1KBФкДцМЦЫуЃЌ128MBПеМфПЩвдШнФЩ128MB/1KB=2ЕФ17ДЮЗН
ааЁЃ
ааЃЌвВОЭЪЧЫЕЃЌвЛИі-ROOT-БэПЩвдбАжЗ2ЕФ17ДЮЗНИі.META.БэЕФRegionЁЃ
ЭЌРэЃЌУПИі.META.БэЕФ RegionПЩвдбАжЗЕФгУЛЇЪ§ОнБэЕФRegionИіЪ§ЪЧ128MB/1KB=2ЕФ17ДЮЗНЁЃ
зюжеЃЌШ§ВуНсЙЙПЩвдБЃДцЕФRegionЪ§ФПЪЧ(128MB/1KB) ЁС (128MB/1KB) =
2ЕФ34ДЮЗНИіRegionЁЃ
ПЭЛЇЖЫЗУЮЪЪ§ОнЪБЕФЁАШ§МЖбАжЗЁБ:
ЮЊСЫМгЫйбАжЗЃЌПЭЛЇЖЫЛсЛКДцЮЛжУаХЯЂЃЌЭЌЪБЃЌашвЊНтОіЛКДцЪЇаЇЮЪЬт.
бАжЗЙ§ГЬПЭЛЇЖЫжЛашвЊбЏЮЪZookeeperЗўЮёЦїЃЌВЛашвЊСЌНгMasterЗўЮёЦї.
ZookeeperЮЊHBaseЬсЙЉЃК
ЗжВМЪНЫјЕФЗўЮёЃК
ЖрИіHMasterНјГЬЖМЛсГЂЪдзХШЅZookeeperжааДШывЛИіЖдгІЕФНкЕуЃЌИУНсЕужЛФмБЛвЛИіHMasterНјГЬДДНЈГЩЙІЃЌДДНЈГЩЙІЕФHMasterНјГЬОЭЪЧActiveЁЃ
ЪТМўМрЬ§ЛњжЦЃК
жїHMasterНјГЬхДЕєжЎКѓЃЌБИHMasterдкМрЬ§ЖдгІЕФZookeeperНкЕуЁЃжїHMasterНјГЬхДЕєжЎКѓЃЌИУНкЕуЛсБЛЩОГ§ЃЌЦфЫћЕФБИHMasteОЭПЩвдЪеЕНЯьгІЕФЯћЯЂЁЃ
ЮЂаЭЪ§ОнПтНЧЩЋЃК
ZookeeperжаДцЗХСЫRegion ServerЕФЕижЗЃЌДЫЪБЃЌПЩвдНЋЫќРэНтГЩвЛИіЮЂаЭЪ§ОнПтЁЃ
HBaseЯЕЭГМмЙЙ
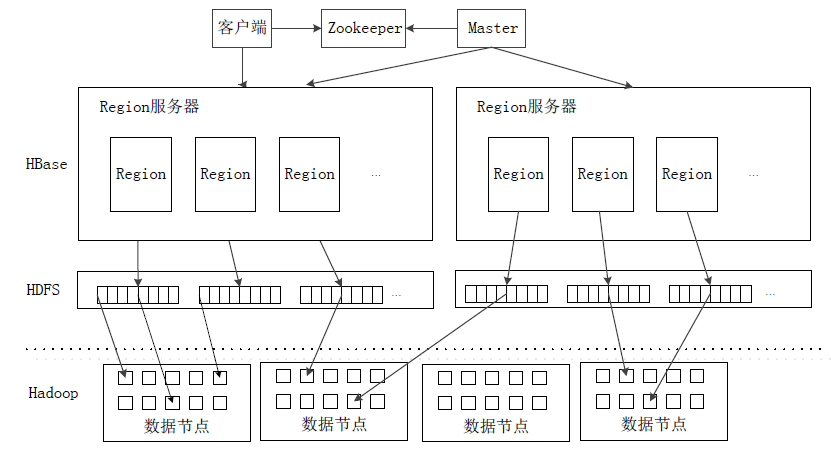
HBaseЯЕЭГМмЙЙЃК
ЭМЃКHBaseЯЕЭГМмЙЙЭМ
ИїзщМўЙІФмЃК
ПЭЛЇЖЫ
ПЭЛЇЖЫАќКЌЗУЮЪHBaseЕФНгПкЃЌЭЌЪБдкЛКДцжаЮЌЛЄзХвбОЗУЮЪЙ§ЕФRegionЮЛжУаХЯЂЃЌгУРДМгПьКѓајЪ§ОнЗУЮЪЙ§ГЬЁЃ
ZookeeperЗўЮёЦї
ZookeeperПЩвдАяжњбЁОйГівЛИіMasterзїЮЊМЏШКЕФзмЙмЃЌВЂБЃжЄдкШЮКЮЪБПЬзмгаЮЈвЛвЛИіMasterдкдЫааЃЌетОЭБмУтСЫMasterЕФЁАЕЅЕуЪЇаЇЁБЮЪЬт
ЁЃ
ZookeeperЪЧвЛИіКмКУЕФМЏШКЙмРэЙЄОпЃЌБЛДѓСПгУгкЗжВМЪНМЦЫуЃЌЬсЙЉХфжУЮЌЛЄЁЂгђУћЗўЮёЁЂЗжВМЪНЭЌВНЁЂзщЗўЮёЕШЁЃ
MasterЃЈHMasterЃЉ
жїЗўЮёЦїMasterжївЊИКд№БэКЭRegionЕФЙмРэЙЄзїЃК
ЈC ЙмРэгУЛЇЖдБэЕФдіМгЁЂЩОГ§ЁЂаоИФЁЂВщбЏЕШВйзїЁЃ
ЈC ЪЕЯжВЛЭЌRegionЗўЮёЦїжЎМфЕФИКдиОљКтЁЃ
ЈC дкRegionЗжСбЛђКЯВЂКѓЃЌИКд№жиаТЕїећRegionЕФЗжВМЁЃ
ЈC ЖдЗЂЩњЙЪеЯЪЇаЇЕФRegionЗўЮёЦїЩЯЕФRegionНјааЧЈвЦЁЃ
-HMasterНјГЬИКд№ЫљгаRegionЕФзЊвЦВйзїЃК
аТБэДДНЈЪБЕФRegionЗжХфЁЃ
дЫааЦкМфЕФИКдиОљКтБЃжЄЁЃ
RegionServer FailoverКѓЕФRegionНгЙмЁЃ
HMasterНјГЬгажїБИНЧЩЋЁЃМЏШКПЩвдХфжУСНИіHMasterНЧЩЋЃЌМЏШКЦєЖЏЪБЃЌетаЉHMasterНЧЩЋЭЈЙ§ОКељЛёЕУжїHMasterНЧЩЋЁЃжїHMasterжЛФмгавЛИіЃЌБИHMasterНјГЬдкМЏШКдЫааЦкМфДІгканУпзДЬЌЃЌВЛИЩЩцШЮКЮМЏШКЪТЮёЁЃ
RegionServerЃК
RegionЗўЮёЦїЪЧHBaseжазюКЫаФЕФФЃПщЃЌЪЧHBaseЕФЪ§ОнЗўЮёНјГЬИКд№ДІРэгУЛЇЕФЪ§ОнЕФЖСаДЧыЧѓЁЃ
RegionгЩRegionServerЙмРэЁЃЫљгагУЛЇЪ§ОнЕФЖСаДЧыЧѓЃЌЖМЪЧКЭRegionServerЩЯЕФRegionНјааНЛЛЅЁЃ
RegionПЩвддкRegionServerжЎМфЧЈвЦЁЃ
RegionServerЙЄзїдРэЃК
###RegionServerЕФМмЙЙЃК
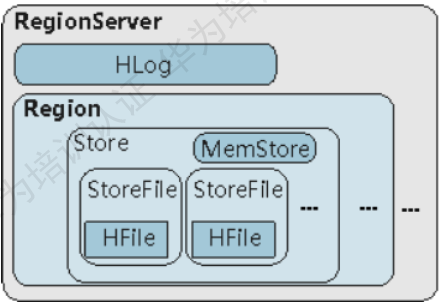
ЭМЃКHBaseЕФRegionServerМмЙЙ
Store:вЛИіRegionгЩвЛИіЛђЖрИіStoreзщГЩЁЃУПИіStoreЖдгІЭМжаЕФвЛИіColumn FamilyЁЃ
MemStoreЃКвЛИіStoreАќКЌвЛИіMemStoreЃЌMemStoreЛКДцПЭЛЇЖЫЯђRegionВхШыЕФЪ§ОнЁЃ
StoreFileЃКMemStoreЕФЪ§ОнFlushЕНHDFSКѓГЩЮЊStoreFileЁЃ
HfileЃКHfileЖЈвхСЫStoreFileдкЮФМўЯЕЭГжаЕФДцДЂИёЪНЃЌЫќЪЧЕБЧАHBaseЯЕЭГЛузмStoreFileЕФОпЬхЪЕЯжЁЃ
HlogЃКHLogШежОБЃжЄСЫЕБRegionServerЙЪеЯЕФЧщПіЯТгУЛЇаДШыЕФЪ§ОнВЛЖЊЪЇЁЃ
RegionServerЕФЖрИіRegionЙВЯэвЛИіЯрЭЌЕФHlogЁЃ
RegionЗўЮёЦїRegionЗўЮёЦїЯђHDFSЮФМўЯЕЭГжаЖСаДЪ§ОнЃК
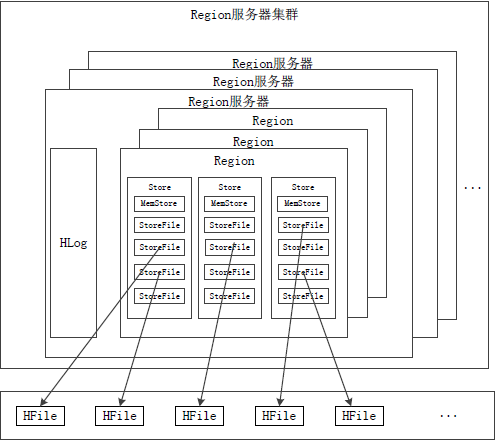
ЭМЃКRegionЗўЮёЦїЯђHDFSЮФМўЯЕЭГжаЖСаДЪ§Он
(1)гУЛЇЖСаДЪ§ОнЙ§ГЬЃК
гУЛЇаДШыЪ§ОнЪБЃЌБЛЗжХфЕНЯргІRegionЗўЮёЦїШЅжДааЁЃ
гУЛЇЪ§ОнЪзЯШБЛаДШыЕНMemStoreКЭHlogжаЁЃ
жЛгаЕБВйзїаДШыHlogжЎКѓЃЌcommit()ЕїгУВХЛсНЋЦфЗЕЛиИјПЭЛЇЖЫЁЃ
ЕБгУЛЇЖСШЁЪ§ОнЪБЃЌRegionЗўЮёЦїЛсЪзЯШЗУЮЪMemStoreЛКДцЃЌШчЙћевВЛЕНЃЌдйШЅДХХЬЩЯУцЕФStoreFileжабАевЁЃ
ЃЈ2ЃЉЛКДцЕФЫЂаТЃК
ЯЕЭГЛсжмЦкадЕиАбMemStoreЛКДцРяЕФФкШнЫЂаДЕНДХХЬЕФStoreFileЮФМўжаЃЌЧхПеЛКДцЃЌВЂдкHlogРяУцаДШывЛИіБъМЧЁЃ
УПДЮЫЂаДЖМЩњГЩвЛИіаТЕФStoreFileЮФМўЃЌвђДЫЃЌУПИіStoreАќКЌЖрИіStoreFileЮФМўЁЃ
УПИіRegionЗўЮёЦїЖМгавЛИіздМКЕФHLog ЮФМўЃЌУПДЮЦєЖЏЖММьВщИУЮФМўЃЌШЗШЯзюНќвЛДЮжДааЛКДцЫЂаТВйзїжЎКѓЪЧЗёЗЂЩњаТЕФаДШыВйзїЃЛШчЙћЗЂЯжИќаТЃЌдђЯШаДШыMemStoreЃЌдйЫЂаДЕНStoreFileЃЌзюКѓЩОГ§ОЩЕФHlogЮФМўЃЌПЊЪМЮЊгУЛЇЬсЙЉЗўЮёЁЃЁЄ
ЃЈ3ЃЉStoreFileЕФКЯВЂЃЈCompactionЃЉЃК
HfileЮФМўЪ§ФПдНРДдНЖрЃЌЖСШЁЪБбгвВдНРДдНДѓЁЃ
УПДЮЫЂаДЖМЩњГЩвЛИіаТЕФStoreFileЃЌЪ§СПЬЋЖрЃЌгАЯьВщевЫйЖШЁЃ
ЕїгУStore.compact()АбЖрИіКЯВЂГЩвЛИіЁЃ
КЯВЂВйзїБШНЯКФЗбзЪдДЃЌжЛгаЪ§СПДяЕНвЛИіуажЕВХЦєЖЏКЯВЂЁЃ
StoreЙЄзїдРэЃК
StoreЪЧRegionЗўЮёЦїЕФКЫаФЁЃ
ЖрИіStoreFileКЯВЂГЩвЛИіЁЃ
ЕЅИіStoreFileЙ§ДѓЪБЃЌгжДЅЗЂЗжСбВйзїЃЌ1ИіИИRegionБЛЗжСбГЩСНИізгRegionЁЃ
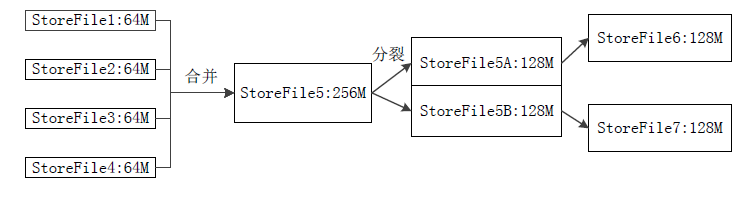
ЭМЃКStoreFileЕФКЯВЂКЭЗжСбЙ§ГЬ
##HLogЙЄзїдРэЃК
ЗжВМЪНЛЗОГБиаывЊПМТЧЯЕЭГГіДэЁЃHBaseВЩгУHLogБЃжЄЯЕЭГЛжИДЁЃ
HBaseЯЕЭГЮЊУПИіRegionЗўЮёЦїХфжУСЫвЛИіHLogЮФМўЃЌЫќЪЧвЛжждЄаДЪНШежОЃЈWrite Ahead
LogЃЉЁЃ
гУЛЇИќаТЪ§ОнБиаыЪзЯШаДШыШежОКѓЃЌВХФмаДШыMemStoreЛКДцЃЌВЂЧвЃЌжБЕНMemStoreЛКДцФкШнЖдгІЕФШежОвбОаДШыДХХЬЃЌИУЛКДцФкШнВХФмБЛЫЂаДЕНДХХЬЁЃ
ZookeeperЛсЪЕЪБМрВтУПИіRegionЗўЮёЦїЕФзДЬЌЃЌЕБФГИіRegionЗўЮёЦїЗЂЩњЙЪеЯЪБЃЌZookeeperЛсЭЈжЊMasterЁЃ
MasterЪзЯШЛсДІРэИУЙЪеЯRegionЗўЮёЦїЩЯУцвХСєЕФHLogЮФМўЃЌетИівХСєЕФHLogЮФМўжаАќКЌСЫРДздЖрИіRegionЖдЯѓЕФШежОМЧТМЁЃ
ЯЕЭГЛсИљОнУПЬѕШежОМЧТМЫљЪєЕФRegionЖдЯѓЖдHLogЪ§ОнНјааВ№ЗжЃЌЗжБ№ЗХЕНЯргІRegionЖдЯѓЕФФПТМЯТЃЌШЛКѓЃЌдйНЋЪЇаЇЕФRegionжиаТЗжХфЕНПЩгУЕФRegionЗўЮёЦїжаЃЌВЂАбгыИУRegionЖдЯѓЯрЙиЕФHLogШежОМЧТМвВЗЂЫЭИјЯргІЕФRegionЗўЮёЦїЁЃ
RegionЗўЮёЦїСьШЁЕНЗжХфИјздМКЕФRegionЖдЯѓвдМАгыжЎЯрЙиЕФHLogШежОМЧТМвдКѓЃЌЛсжиаТзівЛБщШежОМЧТМжаЕФИїжжВйзїЃЌАбШежОМЧТМжаЕФЪ§ОнаДШыЕНMemStoreЛКДцжаЃЌШЛКѓЃЌЫЂаТЕНДХХЬЕФStoreFileЮФМўжаЃЌЭъГЩЪ§ОнЛжИДЁЃ
ЙВгУШежОгХЕуЃКЬсИпЖдБэЕФаДВйзїадФмЃЛ
ШБЕуЃКЛжИДЪБашвЊЗжВ№ШежОЁЃ
аДСїГЬЃК
ЃЈ1ЃЉПЭЛЇЖЫЗЂЦ№аДЪ§ОнЧыЧѓЁЃ
ЃЈ2ЃЉЖЈЮЛRegoinЁЃЖЈЮЛЕНашвЊаДЕНЕФRegionServerЃЌRegionЃЌRowkeyЁЃ
ЃЈ3ЃЉЪ§ОнЗжзщЃКећИіЪ§ОнЗжзщЃЌЩцМАЕНСНВНЁЃ
ЁАЗжРКзгЁБВйзїЃК
ИљОнmeteБэевЕНБъЕФRegionаХЯЂЃЌДЫЪБвВЕУЕНСЫЖдгІЕФRegionServerаХЯЂЁЃ
ИљОнrowkeyЃЌНЋЪ§ОнаДЕНжИЖЈЕФregionжаЁЃ
УПИіRegionServerЩЯЕФЪ§ОнЛсвЛЦ№ЗЂЫЭЁЃЗЂЫЭЪ§ОнжаЃЌЖМЪЧвбОАДееRegionЗжКУзщСЫЁЃ
ЃЈ4ЃЉЭљRegionServerЗЂЫЭЧыЧѓЁЃ
РћгУHBaseздЩэЗтзАЕФRPCПђМмЃЌРДЭъГЩЪ§ОнЗЂЫЭВйзїЁЃ
ЭљЖрИіRegionServerЗЂЫЭЧыЧѓЪЧВЂааЕФЁЃ
ПЭЛЇЖЫЗЂЫЭЭъаДЪ§ОнЧыЧѓКѓЃЌЛсздЖЏЕШД§ЧыЧѓДІРэНсЙћЁЃ
ШчЙћПЭЛЇЖЫУЛгаВЖЛёЕНШЮКЮЕФвьГЃЃЌдђШЯЮЊЫљгаЪ§ОнЖМвбОБЛаДШыГЩЙІЁЃШчЙћШЋВПаДШыЪЇАмЃЌЛђепВПЗжаДШыЪЇАмЃЌПЭЛЇЖЫФмЙ§ЛёжЊЯъЯИЕФЪЇАмkeyжЕСаБэЁЃ
ЃЈ5ЃЉRegionаДЪ§ОнСїГЬЁЃ
ЛёШЁRegionВйзїЫјЁЃЃЈЖСаДЫјЃЉ
вЛДЮЛёШЁИїааааЫјЁЃ
аДШыЕНMemStoreжаЁЃЃЈвЛИіФкДцХХађМЏКЯЃЉ
ЪЭЗХвдЛёШЁЕФааЫјЁЃ
аДЪ§ОнЕНWALжаЁЃЃЈWrite-Ahead-LogЃЉ
ЪЭЗХRegionЫјЁЃ
МШШЛЪЧWrite-Ahead-LogЃЌЮЊКЮЯШаДФкДцдйаДWALЃП
ЯШаДФкДцЕФдвђЃКHBaseЬсЙЉСЫвЛИіMVCCЛњжЦЃЌРДБЃеЯаЉЪ§ОнНзЖЮЕФЪ§ОнПЩМћадЁЃаДаДMemStoreдйаДWALЃЌЪЧЮЊСЫвЛаЉЬиЪтГЁОАЯТЃЌФкДцжаЕФЪ§ОнФмЙЛИќМАЪБЕФПЩНЋЁЃШчЙћЯШаДWALЪЇАмЕФЛАЃЌMemStoreжњЙЅЕФЪ§ОнЛсБЛЛиЙіЁЃ
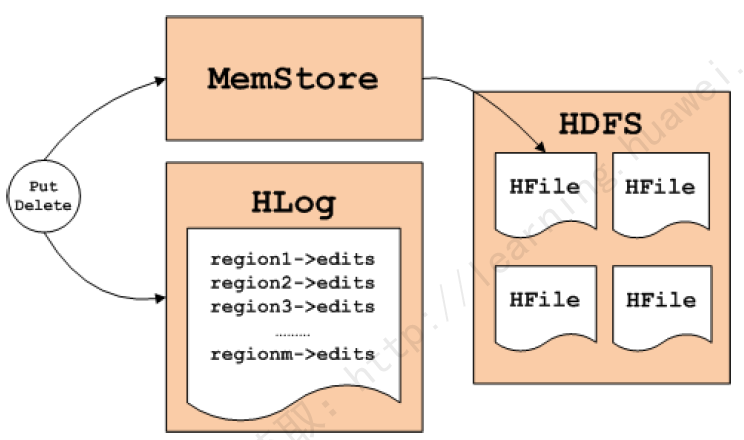
аДСїГЬ
НЋашвЊаДШыЛђЩОГ§ЕФЪ§ОнднЪББЃДцдкУПИіRegionЕФФкДцжаЃЌМДMemStoreжаЁЃ
аДФкДцЃЌБмУтЖрRegionЧщаЮЯТДјРДЕФЙ§ЖрЕФЗжЩЂIOВйзїЁЃ
Ъ§ОндкаДШыЕНMemStoreжЎКѓЃЌвВЛсЫГађаДЕНHLogжаЃЌвдБЃеЯЪ§ОнЕФАВШЋЁЃ
ЃЈ6ЃЉFlushЁЃ
вдЯТЖрИіГЁОАЃЌЛсДЅЗЂMemstoreЕФFlushВйзїЃК
RegionжаЕФMemStoreЕФзмДѓаЁЃЌДяЕНСЫдЄЩшЕФFlush SizeуажЕЁЃ
MemStoreеМгУФкДцЕФзмСПКЭRegionServerзмФкДцЕФБШжЕГЌГіРДСЫдЄЩшЕФуажЕДѓаЁЁЃ
ЕБWALsжаЮФМўЪ§СПДяЕНуажЕЪБЁЃ
HBaseЖЈЦкЫЂаТMemStoreЃЌФЌШЯжмЦкЮЊ1аЁЪБЁЃ
гУЛЇПЩвдЭЈЙ§shellУќСюЗжБ№ЖдвЛИіБэЛђепвЛИіRegionНјааFlushЁЃ
ЃЈ7ЃЉCompactionЁЃ
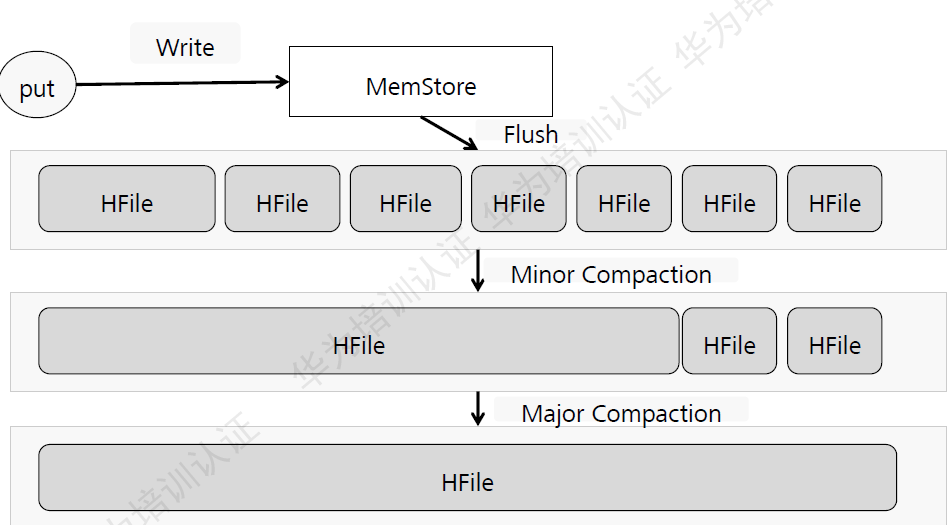
CompactionЕФФПЕФЃЌЪЧЮЊСЫМѕЩйЭЌвЛИіRegionжаЕФЭЌвЛИіColumnFamilyЯТУцЕФаЁЮФМўЃЈHFileЃЉЪ§ФПЃЌДгЖјЬсЩ§ЖСШЁЕФадФмЁЃ
CompactionЗжЮЊMinorЁЂMajorСНРрЃК
MinorЃКаЁЗЖЮЇЕФCompactionЁЃгазюЩйКЭзюДѓЮФМўЪ§ФПЕФЯожЦЁЃЭЈГЃЛсбЁдёвЛаЉСЌајЪБМфЗЖЮЇЕФаЁЮФМўНјааКЯВЂЁЃ
MajorЃКЩцМАИУRegionИУColumnFamilyЯТУцЕФЫљгаHFileЮФМўЁЃ
Minor CompactionбЁШЁЮФМўЪБЃЌзёбвЛЖЈЕФЫуЗЈЁЃ
ЭМЃКCompactionВйзїЪОР§
ЃЈ8ЃЉRegion SplitЁЃ
Region SplitЪЧжИМЏШКЦкМфЃЌФГвЛИіRegionЕФДѓаЁГЌГіСЫдЄЩшЕФуажЕЃЌдђашвЊНЋИУRegionздЖЏЗжСбГЩЮЊСНИіREgionЁЃ
ЗжСбЙ§ГЬжаЃЌБЛЗжСбЕФRegionЛсднЭЃЖСаДЗўЮёЁЃгЩгкЗжСбЙ§ГЬжаЃЌИИRegionЕФЪ§ОнЮФМўВЂВЛЛсеце§ЕФЗжСбЃЌЖјЪЧНіНіЭЈЙ§дкаТЕФRegionжаДДНЈв§гУЮФМўЕФЗНЪНЃЌРДЪЕЯжПьЫйЗжСбЁЃвђДЫЃЌRegionднЭЃЗўЮёЕФЪБМфБШНЯЖЬднЁЃ
ПЭЛЇЖЫВсЫљЛКДцЕФИИRegionЕФТЗгЩаХЯЂашвЊБЛИќаТЁЃ
ЖССїГЬЃК
ЃЈ1ЃЉПЭЛЇЖЫЗЂЦ№ЖСЪ§ОнЧыЧѓЃК
GetВйзїдкОЋзМЕФKeyжЕЕФЧщаЮЯТЃЌЖСШЁЕЅаагУЛЇЪ§ОнЁЃ
SacnВйзїЪБЮЊСЫХњСПЩЈУшЯоЖЈKEyжЕЗЖЮЇЕФгУЛЇЪ§ОнЁЃ
ЃЈ2ЃЉЖЈЮЛRegionЁЃЖЈЮЛЕНИУЪ§ОнЫљдкЕФRegionServerЃЌRegionЃЌRowkeyЁЃ
ЃЈ3ЃЉOpenScannerЃКOpenScannerЙ§ГЬжаЃЌЛсДДНЈСНжжВЛЭЌЕФScannerРДЖСШЁHfileЁЂMemStoreЕФЪ§ОнЁЃ
HFile ЖдгІЕФScannerЮЊStoreFileScannerЁЃ
MemStoreЖдгІЕФScannerЮЊЖдгІЕФMemStoreScannerЁЃ
ЃЈ4ЃЉNextЃК
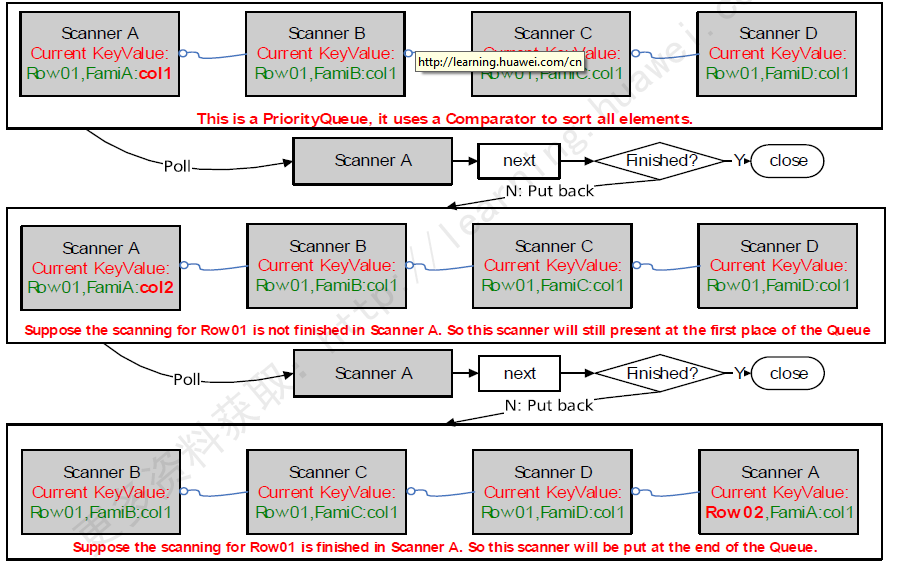
УПвЛИіScannerжаЃЌЖМгавЛИіжИеыЃЌжИЯђНгЯТРДвЊЖСШЁЕФгУЛЇЪ§ОнKeyValueЪЧФФвЛИіЁЃ
ЭЌвЛМЖЕФScannerЃЌБЛЗХдкЭЌвЛИігХЯШМЖЖгСажаЁЃЭЈЙ§ВЛЖЯЕФЖдБШУПвЛИіScannerЕФжИеыЫљжИЯђЕФKeyValueЃЌНЋетаЉScannerНјааХХађЁЃ
УПвЛДЮnextЧыЧѓЃЌЖМЪЧДгИУгХЯШМЖЖгСажаЃЌPollГівЛИіScannerЃЌШЛКѓЃЌЖСШЁИУScannerЕФЕБЧАжИеыЫљжИЯђЕФKeyValueМДПЩЁЃ
УПЖСвЛИіScannerЃЌжИеыЖМЛсЮвФЧИіЯТвЦвЛИіKeyValueЁЃЖјКѓЃЌИУScannerБЛЗЕЛЙЕНЖгСажаЁЃШчЙћвбОЖСЭъЃЌдђжБНгЙиБеЁЃ
ЃЈ5ЃЉFilterдЪаэдкScanЙ§ГЬЛђжЛФмЙжЃЌЩшЖЈвЛЖЈЕФЙ§ТЫЬѕМўЁЃЗћКЯЬѕМўЕФгУЛЇЪ§ОнВХЗЕЛиЁЃЕБЧААќКЌЕФвЛаЉЕфаЭЕФFilterгаЃК
RowFilter
SingleColumnValueFilter
KeyOnlyFilter
FilterList
ЪЙгУFilterЪБЃЌПЩФмЛсЩЈУшДѓСПЕФгУЛЇЪ§ОнЃЌВХПЩвдевЕНЫљЦкЭћЕФТњзуЬѕМўЕФЪ§ОнЁЃвђДЫЃЌвЛаЉГЁОАЯТадФмЪЧВЛПЩдЄЙРЕФЁЃ
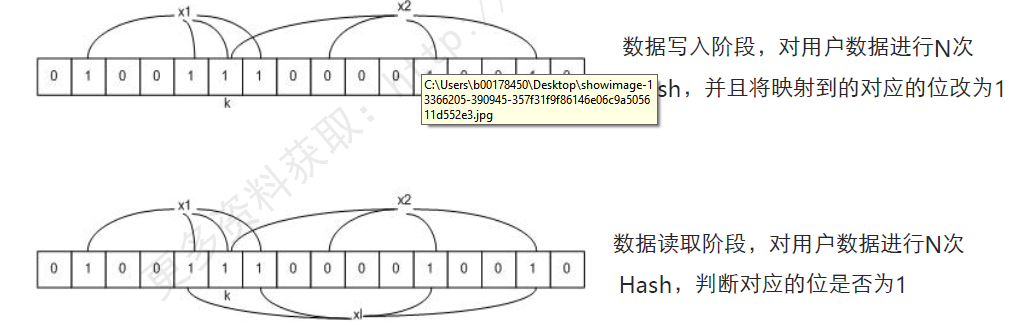
ЃЈ6ЃЉBloomFilterЃК
BloomFilterгУРДгХЛЏвЛаЉЫцЛњЖСШЁЕФГЁОАЃЌМДGetГЁОАЁЃЫќПЩвдБЛгУРДПьЫйЕФХаЖЯвЛЬѕгУЛЇЪ§ОндквЛИіДѓЕФЪ§ОнМЏКЯЃЈИУЪ§ОнМЏКЯЕФДѓВПЗжЪ§ОнЖМУЛЗЈМгдиЕНФкДцжаЃЉжаЪЧЗёДцдкЁЃ
BloomFilterдкХаЖЯвЛИіЪ§ОнЪЧЗёДцдкЪБЃЌгЕгавЛЖЈЕФЮѓХаТЪЁЃЕЋЖдгкЁАгУЛЇЪ§ОнXXXВЛДцдкЁБЕФХаЖЯНсЙћЪЧПЩаХЕФЁЃ
HBaseЕФBLoomFilterЕФЯрЙиЪ§ОнЃЌБЛБЃДцдкHFileжаЁЃ
HBaseгІгУЗНАИ
HBaseЪЕМЪгІгУжаЕФадФмгХЛЏЗНЗЈЃК
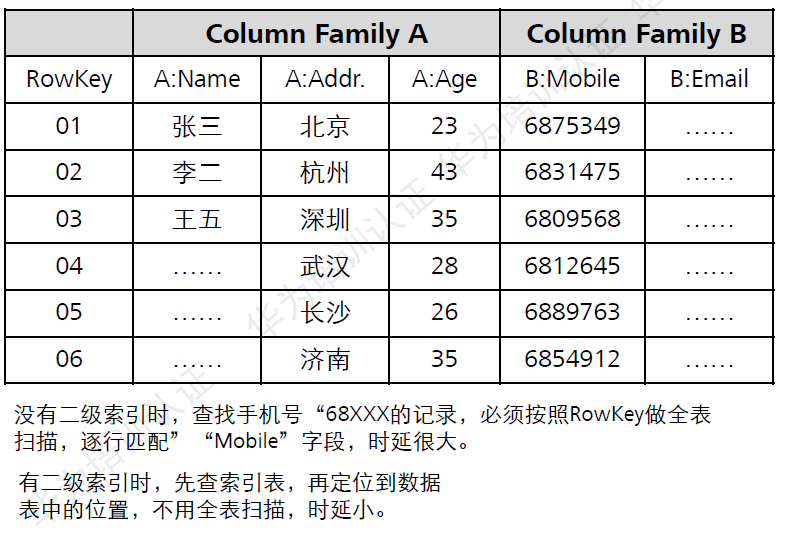
ааМќЃЈRow KeyЃЉ
ааМќЪЧАДеезжЕфађДцДЂЃЌвђДЫЃЌЩшМЦааМќЪБЃЌвЊГфЗжРћгУетИіХХађЬиЕуЃЌНЋОГЃвЛЦ№ЖСШЁЕФЪ§ОнДцДЂЕНвЛПщЃЌНЋзюНќПЩФмЛсБЛЗУЮЪЕФЪ§ОнЗХдквЛПщЁЃ
ОйИіР§згЃКШчЙћзюНќаДШыHBaseБэжаЕФЪ§ОнЪЧзюПЩФмБЛЗУЮЪЕФЃЌПЩвдПМТЧНЋЪБМфДСзїЮЊааМќЕФвЛВПЗжЃЌгЩгкЪЧзжЕфађХХађЃЌЫљвдПЩвдЪЙгУLong.MAX_VALUE
- timestampзїЮЊааМќЃЌетбљФмБЃжЄаТаДШыЕФЪ§ОндкЖСШЁЪБПЩвдБЛПьЫйУќжаЁЃ
InMemory
ДДНЈБэЕФЪБКђЃЌПЩвдЭЈЙ§HColumnDescriptor.setInMemory(true)НЋБэЗХЕНRegionЗўЮёЦїЕФЛКДцжаЃЌБЃжЄдкЖСШЁЕФЪБКђБЛcacheУќжаЁЃ
Max Version
ДДНЈБэЕФЪБКђЃЌПЩвдЭЈЙ§HColumnDescriptor.setMaxVersions(int maxVersions)ЩшжУБэжаЪ§ОнЕФзюДѓАцБОЃЌШчЙћжЛашвЊБЃДцзюаТАцБОЕФЪ§ОнЃЌФЧУДПЩвдЩшжУsetMaxVersions(1)ЁЃ
Time TO LiveЃК
ДДНЈБэЕФЪБКђЃЌПЩвдЭЈЙ§HColumnDescriptor.setTimeToLive(int timeToLive)ЩшжУБэжаЪ§ОнЕФДцДЂЩњУќЦкЃЌЙ§ЦкЪ§ОнНЋздЖЏБЛЩОГ§ЃЌР§ШчШчЙћжЛашвЊДцДЂзюНќСНЬьЕФЪ§ОнЃЌФЧУДПЩвдЩшжУsetTimeToLive(2
24 60 * 60)ЁЃ
HBaseадФмМрЪгЃК
Master-status(здДј)ЃК
HBase MasterФЌШЯЛљгкWebЕФUIЗўЮёЖЫПкЮЊ60010ЃЌHBase regionЗўЮёЦїФЌШЯЛљгкWebЕФUIЗўЮёЖЫПкЮЊ60030.ШчЙћmasterдЫаадкУћЮЊmaster.foo.comЕФжїЛњжаЃЌmaterЕФжївГЕижЗОЭЪЧhttp://master.foo.com:60010ЃЌгУЛЇПЩвдЭЈЙ§WebфЏРРЦїЪфШыетИіЕижЗВщПДИУвГУцПЩвдВщПДHBaseМЏШКЕФЕБЧАзДЬЌЁЃ
GangliaЃК
GangliaЪЧUC BerkeleyЗЂЦ№ЕФвЛИіПЊдДМЏШКМрЪгЯюФПЃЌгУгкМрПиЯЕЭГадФмЁЃ
OpenTSDBЃК
OpenTSDBПЩвдДгДѓЙцФЃЕФМЏШКЃЈАќРЈМЏШКжаЕФЭјТчЩшБИЁЂВйзїЯЕЭГЁЂгІгУГЬађЃЉжаЛёШЁЯргІЕФmetricsВЂНјааДцДЂЁЂЫїв§вдМАЗўЮёЃЌДгЖјЪЙЕУетаЉЪ§ОнИќШнвзШУШЫРэНтЃЌШчwebЛЏЃЌЭМаЮЛЏЕШЁЃ
AmbariЃК
Ambari ЕФзїгУОЭЪЧДДНЈЁЂЙмРэЁЂМрЪг Hadoop ЕФМЏШКЁЃ
дкHBaseжЎЩЯЙЙНЈSQLв§ЧцЃК
NoSQLЧјБ№гкЙиЯЕаЭЪ§ОнПтЕФвЛЕуОЭЪЧNoSQLВЛЪЙгУSQLзїЮЊВщбЏгябдЃЌжСгкЮЊКЮдкNoSQLЪ§ОнДцДЂHBaseЩЯЬсЙЉSQLНгПкЃЌгаШчЯТдвђЃК
взЪЙгУЁЃЪЙгУжюШчSQLетбљвзгкРэНтЕФгябдЃЌЪЙШЫУЧФмЙЛИќМгЧсЫЩЕиЪЙгУHBaseЁЃ
МѕЩйБрТыЁЃЪЙгУжюШчSQLетбљИќИпВуДЮЕФгябдРДБраДЃЌМѕЩйСЫБраДЕФДњТыСПЁЃ
ЗНАИЃК 1.HiveећКЯHBase 2.Phoenix
1.HiveећКЯHBase
HiveгыHBaseЕФећКЯЙІФмДгHive0.6.0АцБОвбОПЊЪМГіЯжЃЌРћгУСНепЖдЭтЕФAPIНгПкЛЅЯрЭЈаХЃЌЭЈаХжївЊвРППhive_hbase-handler.jarЙЄОпАќ(Hive
Storage Handlers)ЁЃгЩгкHBaseгавЛДЮБШНЯДѓЕФАцБОБфЖЏЃЌЫљвдВЂВЛЪЧУПИіАцБОЕФHiveЖМФмКЭЯжгаЕФHBaseАцБОНјааећКЯЃЌЫљвддкЪЙгУЙ§ГЬжаЬиБ№зЂвтЕФОЭЪЧСНепАцБОЕФвЛжТадЁЃ
2.Phoenix
PhoenixгЩSalesforce.comПЊдДЃЌЪЧЙЙНЈдкApache HBaseжЎЩЯЕФвЛИіSQLжаМфВуЃЌПЩвдШУПЊЗЂепдкHBaseЩЯжДааSQLВщбЏЁЃ
ЙЙНЈHBaseЖўМЖЫїв§ЃК
HBaseжЛгавЛИіеыЖдааНЁЕФЫїв§ ЗУЮЪHBaseБэжаЕФааЃЌжЛгаШ§жжЗНЪНЃК
ЭЈЙ§ЕЅИіааНЁЗУЮЪ
ЭЈЙ§вЛИіааНЁЕФЧјМфРДЗУЮЪ
ШЋБэЩЈУш
ЪЙгУЦфЫћВњЦЗЮЊHBaseааНЁЬсЙЉЫїв§ЙІФмЃК
HindexЖўМЖЫїв§
HBase+Redis
HBase+solr
дРэЃКВЩгУHBase0.92АцБОжЎКѓв§ШыЕФCoprocessorЬиадЁЃ
CoprocessorЙЙНЈЖўМЖЫїв§ЃК
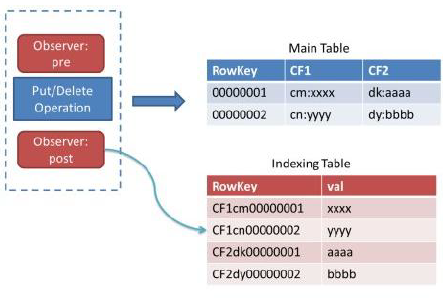
CoprocessorЃЈаДІРэЦїЃЉЬсЙЉСЫСНИіЪЕЯжЃКendpointКЭobserverЃЌendpointЯрЕБгкЙиЯЕаЭЪ§ОнПтЕФДцДЂЙ§ГЬЃЌЖјobserverдђЯрЕБгкДЅЗЂЦїЁЃ
observerдЪаэЮвУЧдкМЧТМputЧАКѓзівЛаЉДІРэЃЌвђДЫЃЌЖјЮвУЧПЩвддкВхШыЪ§ОнЪБЭЌВНаДШыЫїв§БэЁЃ
гХЕуЃК ЗЧЧжШыадЃКв§ЧцЙЙНЈдкHBaseжЎЩЯЃЌМШУЛгаЖдHBaseНјааШЮКЮИФЖЏЃЌвВВЛашвЊЩЯВугІгУзіШЮКЮЭзаЁЃ
ШБЕуЃКУПВхШывЛЬѕЪ§ОнашвЊЯђЫїв§БэВхШыЪ§ОнЃЌМДКФЪБЪЧЫЋБЖЕФЃЌЖдHBaseЕФМЏШКЕФбЙСІвВЪЧЫЋБЖЕФЁЃ
ЭМЃКЖўМЖЫїв§ЪОвтЭМ
###Hindex:
Hindex ЪЧЛЊЮЊЙЋЫОПЊЗЂЕФДП Java БраДЕФHBaseЖўМЖЫїв§ЃЌМцШн Apache HBase
0.94.8ЁЃЕБЧАЕФЬиадШчЯТЃК
ЖрИіБэЫїв§
ЖрИіСаЫїв§
ЛљгкВПЗжСажЕЕФЫїв§
HBase+Redis:
Redis+HBaseЗНАИ
CoprocessorЙЙНЈЖўМЖЫїв§
RedisзіПЭЛЇЖЫЛКДц
НЋЫїв§ЪЕЪБИќаТЕНRedisЕШKVЯЕЭГжаЃЌЖЈЪБДгKVИќаТЫїв§ЕНHBaseЕФЫїв§Бэжа.
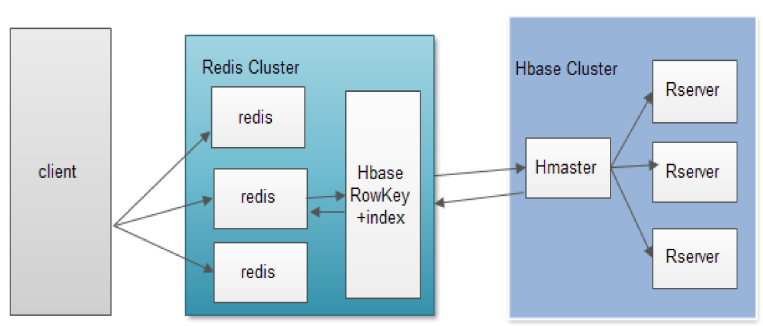
ЭМЃКHBase+RedisЖўМЖЫїв§
HBase+solr:
SolrЪЧвЛИіИпадФмЃЌВЩгУJava5ПЊЗЂЃЌЛљгкLuceneЕФШЋЮФЫбЫїЗўЮёЦїЁЃЭЌЪБЖдЦфНјааСЫРЉеЙЃЌЬсЙЉСЫБШLuceneИќЮЊЗсИЛЕФВщбЏгябдЃЌЭЌЪБЪЕЯжСЫПЩХфжУЁЂПЩРЉеЙВЂЖдВщбЏадФмНјааСЫгХЛЏЃЌВЂЧвЬсЙЉСЫвЛИіЭъЩЦЕФЙІФмЙмРэНчУцЃЌЪЧвЛПюЗЧГЃгХауЕФШЋЮФЫбЫїв§ЧцЁЃ
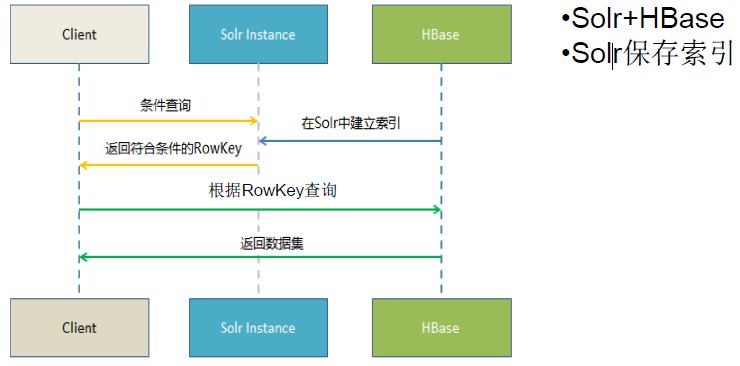
ЭМЃКHBase+Solr
HBaseЛЊЮЊдіЧПЬиад
жЇГжЖўМЖЫїв§ЃК
ЖўМЖЫїв§ЮЊHBaseЬсЙЉСЫАДееФГаЉСаЕФжЕНјааЫїв§ЕФФмСІЁЃ
HFSЃЈHBase FileStreamЃЉЃК
HBaseЮФМўДцДЂФЃПщЃЈHBase FileStreamЃЌМђГЦHFSЃЉЪЧHBaseЕФЖРСЂФЃПщЃЌЫќзїЮЊЖдHBaseгыHDFSНгПкЕФЗтзАЃЌгІгУдкFusionInsightЕФЩЯВугІгУЃЌЮЊЩЯВугІгУЬсЙЉЮФМўЕФДцДЂЁЂЖСШЁЁЂЩОГ§ЕШЙІФмЁЃ
HFSЕФГіЯжНтОіСЫашвЊдкHDFSжаДцДЂКЃСПаЁЮФМўЃЌЭЌЪБвВвЊДцДЂвЛаЉДѓЮФМўЕФЛьКЯЕФГЁОАЁЃМђЕЅРДЫЕЃЌОЭЪЧдкHBaseБэжаЃЌашвЊДцЗХДѓСПЕФаЁЮФМўЃЈ10MBвдЯТЃЉЃЌЭЌЪБгжашвЊДцЗХвЛаЉБШНЯДѓЕФЮФМўЃЈ10MBвдЩЯЁЃЃЉ
HBase MOBЃК
MOBЪ§ОнЃЈМД100KBЕН10MBДѓаЁЕФЪ§ОнЃЉжБНгвдHFileЕФИёЪНДцДЂдкЮФМўЯЕЭГЩЯЃЈР§ШчHDFSЮФМўЯЕЭГЃЉЃЌШЛКѓАбетИіЮФМўЕФЕижЗаХЯЂМАДѓаЁаХЯЂзїЮЊvalueДцДЂдкЦеЭЈHBaseЕФstoreЩЯЃЌЭЈЙ§ЙЅЛїМЏжаЙмРэетаЉЮФМўЁЃетбљОЭПЩвдДѓДѓНЕЕЭHBaseЕФcompationКЭsplitЦЕТЪЃЌЬсЩ§адФмЁЃ
|









