| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫKylin
дкБДПЧЕФЪЙгУЧщПіНщЩмвдМАKylin HBase гХЛЏСНДѓЗНУцЁЃ
БОЮФРДздЙЋжкКХ apachekylinЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Kylin дкБДПЧЕФЪЙгУЧщПіНщЩм
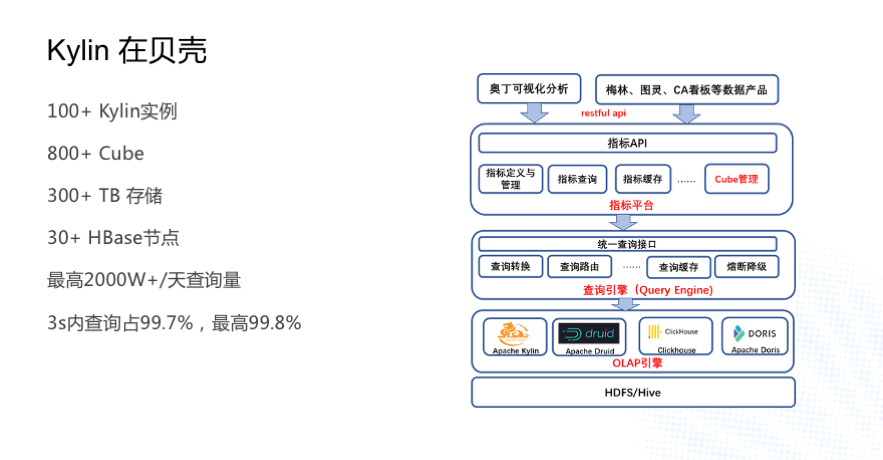
Kylin Дг 2017 ФъПЊЪМзїЮЊБДПЧЙЋЫОМЖ OLAP в§ЧцЖдЭтЬсЙЉЗўЮёЃЌ ФПЧАга 100 ЖрЬЈ
Kylin ЪЕР§ЃЛга 800 ЖрИі CubeЃЛга 300 Жр T ЕФЕЅИББОДцДЂЃЛдкБДПЧ Kylin
гаСНЬз HBase МЏШКЃЌ30 ЖрИіНкЕуЃЌKylin УПЬьЕФВщбЏСПзюИп 2000+Эђ ЁЃ
ЮвУЧИКд№ Kylin ЭЌЪТеХШчЫЩдк 2018 Фъ Kylin Meetup ЩЯЗжЯэЙ§KylinдкБДПЧЕФЪЕМљЃЌЕБЪБУПЬьзюИпЧыЧѓСПЪЧ
100 ЖрЭђЃЌСНФъЕФЪБМфРяЧыЧѓСПдіМгСЫ 19 БЖЃЛЮвУЧЖдгУЛЇЕФВщбЏЯьгІЪБМфГаХЕЪЧ 3 УыФкЕФВщбЏеМБШвЊДяЕН
99.7%ЃЌЮвУЧзюИпЪЧДяЕНСЫ 99.8%ЁЃдкУПЬь 2000+W ВщбЏСПЕФЧщПіЯТЃЌKylin гіЕНКмЖрЕФЬєеНЃЌНгЯТРДЮвНЋЮЊДѓМвНщЩмвЛЯТЮвУЧгіЕНЕФвЛаЉЮЪЬтЃЌЯЃЭћФмИјЩчЧјЕФХѓгбЬсЙЉвЛаЉВЮПМЁЃ
Kylin HBase гХЛЏ
Бэ/Region ВЛПЩЗУЮЪ
1ЃЉЯжЯѓЃК

СшГПЙЙНЈ Cube ЦкМфЃЌЛсГіЯжживЊБэЕФФГИі region ВЛПЩЗУЮЪЕМжТЙЙНЈЪЇАмЕФЧщПіЃЌгвЩЯНЧЕФЭМЪЧ
HBase ЕФ meta БэВЛПЩЗУЮЪЕФШежОЃЛАзЬьВщбЏЪБвВгаВПЗжВщбЏвђЮЊЪ§ОнБэФГИі Region ВЛПЩЗУЮЪЕМжТВщбЏГЌЪБЕФЧщПіЃЌгвЯТНЧЕФЭМЪЧВщбЏЪ§ОнБэ
Region ГЌЪБЕФШежОЃЛСэЭтвЛИіЯжЯѓЪЧРЯЕФ Kylin МЏШК Region Ъ§СПДяЕН 16W+ЃЌЦНОљУПЬЈЛњЦїЩЯ
1W+Иі RegionЃЌетЕМжТ Kylin HBase МЏШКНЈБэКЭЩОБэЖМЗЧГЃТ§ЃЌСшГПЙЙНЈЛсГіЯжНЈБэПЈзЁЕФЯжЯѓЃЌЭЌЪБЧхРэГЬађЩОГ§вЛеХБэашвЊШ§ЫФЗжжгЕФЪБМфЃЌУцЖдетбљЕФЧщПіЃЌЮвУЧзіСЫвЛаЉИФНјЁЃ
2ЃЉНтОіЗНАИЃК

ЩОГ§ЮогУБэМѕЩй RegionЁЃ ЭЈЙ§ИеВХЕФНщЩм HBase МЏШКЦНОљУПЬЈЛњЦїЩЯ 1W+Иі RegionЃЌетЖдгк
HBase РДЫЕЪЧВЛЬЋКЯРэЕФЃЌСэЭтгЩгкЩОГ§вЛеХБэашвЊШ§ЫФЗжжгЕФЪБМфЃЌЧхРэГЬађвВжДааЕФвьГЃЛКТ§ЃЌзюКѓЮвУЧВЛЕУВЛЪЙгУСЫвЛаЉЗЧГЃЙцЪжЖЮЩОГ§СЫ
10W+Иі RegionЁЃ
ЫѕЖЬЧхРэжмЦкЃЌ ДгжЎЧАЕФвЛжмЧхРэвЛДЮ HBase БэЕНУПЬьЧхРэвЛДЮЃЌГ§ДЫжЎЭт Kylin ЛсУПжмКЯВЂвЛДЮ
Cube РДМѕЩй HBase БэЪ§СПДгЖјМѕЩй Region Ъ§СПЃЌзюже 16W+ЕФ Region ЩОЕНСЫВЛЕН
6 ЭђЃЌжСДЫЮвУЧНтОіСЫвЛВПЗжЮЪЬтЃЌЛЙЛсДцдкЙЙНЈЪБжиЕуБэЕФ Region ВЛПЩЗУЮЪЕФЧщПіЁЃ
НЋ HBase Дг 1.2.6 Щ§ЕН 1.4.9ЃЌ жївЊЪЧЯывЊРћгУ RSGroup ЕФФмСІРДзіжиЕуБэКЭЪ§ОнБэЕФМЦЫуИєРыЃЛ
ЙиБе HBase здЖЏ Balance ЕФЙІФмЃЌ НідквЙМфвЕЮёЕЭЗхЦкПЊЦєМИИіаЁЪБЃЛ
ЪЙгУ HBase здДјЕФ Canary ЖЈЦкЕФМьВт Region ЕФПЩФмадЃЌ ШчЙћЗЂЯжФГаЉ Region
ВЛПЩгУТэЩЯЗЂЫЭИцОЏ
ЪЙгУ RSGroup ЕЅЖРИєРыжиЕуБэРДЦСБЮСЫМЦЫуДјРДИЩШХЃЌ етаЉжиЕуБэАќРЈ HBase Meta
БэЁЂAcl БэЁЂNamespace БэЁЂKylin_metadata БэЁЃ
ОЙ§СЫетвЛЯЕСаЕФИФНјжЎКѓБэ/Region ВЛПЩЗУЮЪЕФЮЪЬтЛљБОЩЯНтОіСЫЃЌЯждкЛљБОЩЯУЛгадйГіЯж Region
ВЛПЩЗУЮЪЕФЧщПіЁЃНтОіетИіЮЪЬтЮвУЧЛЈЗбСЫКмГЄЪБМфЃЌОРњСЫЩ§МЖжиЦєКЭЩОСЫДѓСПЕФБэКѓЃЌЮвУЧгіЕНСЫСэЭтвЛИіЮЪЬтЁЃ
RS Ъ§ОнБОЕиадЬсЩ§
1ЃЉЯжЯѓ

Kylin HBase МЏШКЕФ RegionServer Ъ§ОнБОЕиадЗЧГЃЕЭЃЌжЛга 20%ВЛФмКмКУЕФРћгУ
HDFS ЖЬТЗЖСЃЌетбљЖдВщбЏЯьгІЪБМфВњЩњСЫвЛЖЈгАЯь ЃЌЮвУЧШ§УыФкЕФВщбЏеМБШГіЯжСЫЯТНЕЁЃСЫНт HBase
ЕФХѓгбЖМжЊЕРШчЙћ RS ЕФЪ§ОнБОЕиадНЯЕЭЃЌгавЛжжНтОіЗНАИОЭЪЧзі Compact АбЪ§ОнРЕН RegionServer
ЖдгІЕФ Datanode ЩЯЃЌПМТЧЕНДѓЙцФЃЕФзі Compact ЛсЖдВщбЏдьГЩКмДѓгАЯьЃЌЮвУЧУЛгаетУДзіЃЌИњ
Kylin ЕФЭЌбЇЙЕЭЈКѓЗЂЯжОјДѓЖрЪ§ЕФ Cube УПЬьЛсЪЙгУзюаТЙЙНЈЕФБэЃЌВщОЩБэЕФПЩФмЯЕВЛЪЧЬиБ№ДѓЃЌЫљвдЬсЩ§УПЬьаТНЈБэЕФЪ§ОнБОЕиадОЭПЩвдСЫЃЌ
ОпЬхЮвУЧЪЧетбљзіЕФЁЃ
2ЃЉНтОіЗНАИ

ЮвУЧЗЂЯж Kylin гУЕНЕФЪЧ HFileOutputFormat3 Ињ HBase ЕФ HFileOutputFormat2
ЪЧгавЛаЉВюБ№ЕФЃЌЮвУЧдк HFileOutputFormat3 РяУцМгШыСЫ HBASEЁЊ12596 ЕФЬиадЃЌетИіЬиаджївЊЪЧЩњГЩ
HFile ЕФЪБКђЛсаДвЛЗнЪ§ОнЕФИББОЕН Region ЫљдкЕФ RegionServer ЖдгІЕФ Datanode
ЩЯЁЃЯТУцЪЧвЛаЉДњТыЯИНкЃЌГЬађЛсЯШШЁЕНетИі Region ЫљдкЕФЛњЦїЃЌШЛКѓдйЛёШЁ Writer ЪБЃЌАбетЬЈНкЕуЕФаХЯЂДЋЕнЙ§ШЅЃЌзюКѓаДЪ§ОнЕФЪБКђЛсаДвЛИіИББОЕНетИі
Region ЖдгІЕФ Datanode ЩЯЃЌ етбљж№НЅЮвУЧЕФЪ§ОнЮШЖЈадОЭЬсЩЯРДСЫЃЌЯждкПДСЫвЛЯТЛљБОЩЯдк
80%ЖрзѓгвЁЃ
RegionServer IO ЦПОБ
1ЃЉЯжЯѓ
ЮвУЧЗЂЯждкЙЙНЈдчИпЗхЪБЃЌHBase ЯьгІЪБМфЕФ P99 ЛсЫцжЎЩ§ИпЕФЃЌЭЈЙ§МрПиЗЂЯжЪЧгЩгк RegionServer
ЛњЦїЕФ IO Wait ЦЋИпЕМжТЕФЁЃ
ЛЙгавЛжжГЁОАЪЧгУЛЇЙЙНЈЪБМфЗЖЮЇбЁдёЙ§ДѓЃЌЕМжТЭјПЈБЛДђТњЃЌжЎЧАгаИігУЛЇЙЙНЈСЫвЛФъЕФЪ§ОнЃЌЛЙгаЙЙНЈШ§ЫФИідТЪ§ОнЃЌетСНжжЧщПіЖМЛсдьГЩ
RegionServer ЛњЦї IO ГіЯжЦПОБЕМжТ Kylin ВщбЏГЌЪБЁЃ
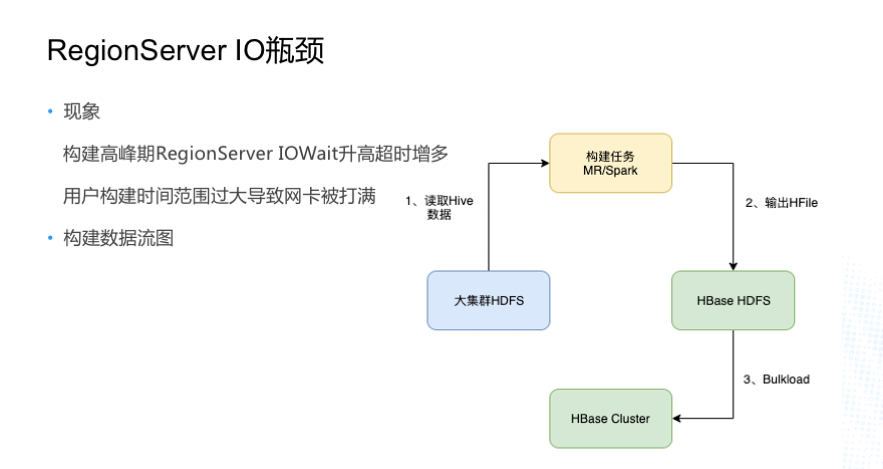
ЩЯЭМЪЧ Cube Ъ§ОнЙЙНЈСїГЬЃЌЪзЯШ HBase МЏШККЭЙЋЫОДѓЕФ Hadoop МЏШКЪЧЖРСЂЕФСНЬз HDFS
МЏШКЃЌУПЬьЙЙНЈЪЧДгДѓМЏШКЕФ HDFS ШЅЖСШЁ Hive ЕФЪ§ОнЃЌЙЙНЈШЮЮёжБНгЪфГі HFile ЕН HBase
ЕФ HDFS МЏШКЃЌзюКѓжДаа Bulkload ВйзїЁЃгЩгк HBase HDFS МЏШКЛњЦїНЯЩйЃЌЙЙНЈШЮЮёаДЪ§ОнЙ§ПьЕМжТ
DataNode/RegionServer ЛњЦї IO Wait Щ§ИпЃЌдѕУДНтОіетИіЮЪЬтФиЃП
2ЃЉНтОіЗНАИ
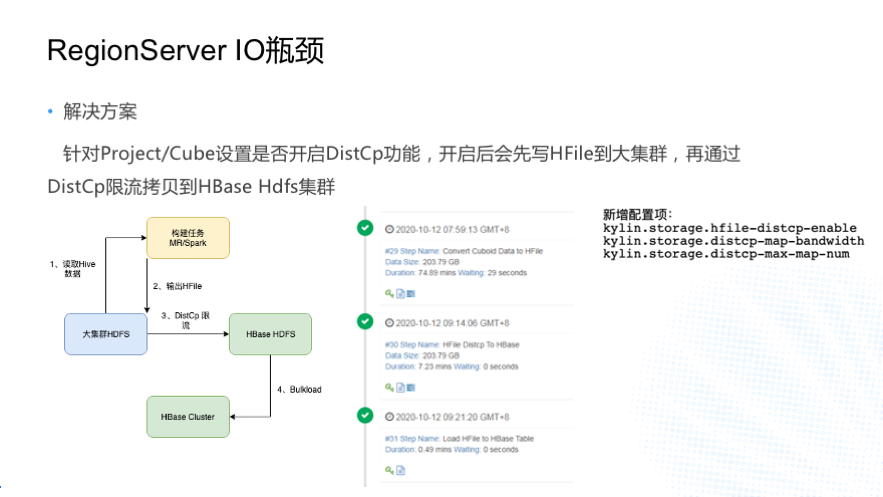
ЮвУЧЯыгУ HBase БШНЯГЃгУЕФЗНЪНОЭЪЧ DistCp РДНтОіетИіЮЪЬтЃЌзѓЯТНЧетеХЭМЪЧЮвУЧЕФИФНјЗНАИЃЌОЭЪЧЮвУЧЩшжУЙЙНЈШЮЮёЕФЪфГіТЗОЖЕН
Hadoop ЕФДѓМЏШКЃЌЖјВЛЪЧЕН HBase ЕФ HDFSB МАШКЃЌдйЭЈЙ§ DistCp ЯоСїЕФПНБД
HFile ЕН HBase ЕФ HDFS МЏШКЃЌзюКѓзі Bulkload ВйзїЁЃжЎЧАЬсЕНЮвУЧга 800
ЖрИі CubeЃЌВЂВЛЪЧЫљгаЕФ Cube ЖМашвЊзпетЬзСїГЬЃЌ вђЮЊЯоСїПНБДЕФЛАПЯЖЈЛсгАЯьЪ§ОнЕФВњГіЪБМфЃЌЮвУЧЩшМЦСЫеыЖд
Project ЛђепЪЧ Cube ЩшжУПЊЦєетИіЙІФмЃЌ ЮвУЧЭЈГЃЛсЖдЪ§ОнСПБШНЯДѓЕФ Cube ПЊЦє DistCp
ЯоСїПНБДЃЌЦфЫћ Cube ЛЙЪЧЪЙгУжЎЧАЕФЪ§ОнСїГЬЁЃ
жаМфетИіЭМЪЧвЛИіЙЙНЈШЮЮёЕФНиЭМЃЌЕквЛВНЪЧЩњГЩ HFileЃЌЕкЖўВНЪЧ DistCpЃЌзюКѓдй BulkloadЃЌетИіЙІФмЮвУЧаТдіСЫвЛаЉХфжУЯюЃЌБШШчЫЕЕквЛИіЪЧЗёПЊЦє
DictCpЃЌЕкЖўИіЪЧУПИі Map ДјПэЪЧЖрЩйЃЌдйгаОЭЪЧзюДѓгаЖрЩй MapЁЃЭЈЙ§етИіЙІФмЮвУЧЛљБОЩЯНтОіСЫЙЙНЈИпЗх
IOWait ЛсБфИпЕФЧщПіЁЃ
Т§ВщбЏжЮРэЈCГЌЪБЖЈЮЛСДТЗгХЛЏ
1ЃЉЯжЯѓ
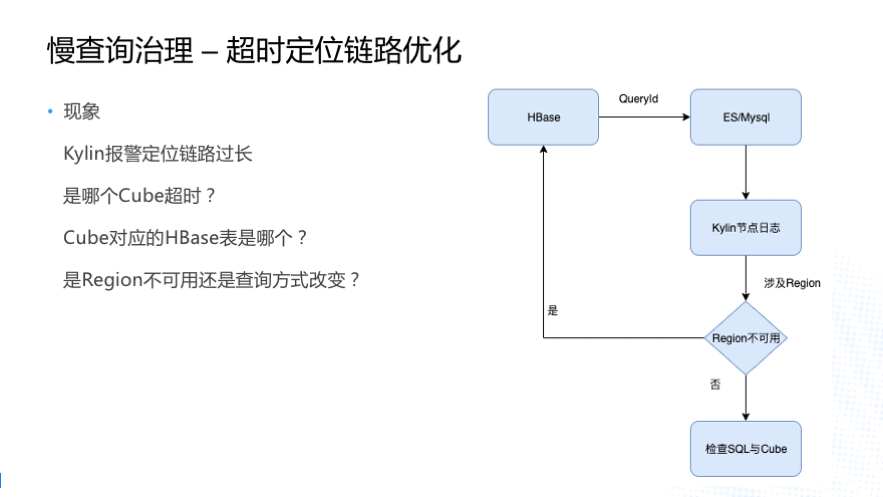
Т§ВщбЏжЮРэгіЕНЕФЕквЛИіЮЪЬтОЭЪЧГЌЪБЖЈЮЛСДТЗЬиБ№ГЄЁЃЮвУЧЪеЕН Kylin БЈОЏЪБЪзЯШЛсЯыжЊЕРЃК
ЪЧФФИіCubeГЌЪБСЫЃП
CubeЖдгІЕФHBaseБэЪЧФФИіЃП
ЪЧRegionВЛПЩгУЛЙЪЧВщбЏЗНЪНБфСЫЃП
жЎЧАЬсЕНгавЛЖЮЪБМфОГЃГіЯж Region ВЛПЩгУЕФЧщПіЃЌвЛЕЉГіЯжГЌЪБЮвУЧВщбЏСДТЗЪЧЪВУДбљЕФФиЃП ПЩФмЮвУЧЯШШЅПД
HBase ШежОРяПДгаУЛга Deadline has passed ЕФОЏИцШежОЃЌгаетжжБЈОЏЕФЛАЮвУЧЛсФУЕНЫќЕФ
QueryIDЃЌШЛКѓШЅ ES ЛђепЪЧ Mysql РяУцШЅВщбЏетИі QureyID ЖдгІЕФ Cube
аХЯЂКЭ SQLЃЌжЊЕРетаЉаХЯЂжЎКѓЃЌЛЙашвЊШЅЕНГЌЪБЕФ Kylin НкЕуЩЯШЅВщбЏШежОЃЌДгШежОРяУцВХФмевЕНЪЧВщбЏФФИі
HBase БэЕФФФИі Region ГЌЪБЃЌШЛКѓдйШЅХаЖЯЪЧВЛЪЧ Region ВЛПЩгУСЫЃЌЛђепЪЧВщбЏЗНЪНИФБфЁЃ
етИіСДТЗЗЧГЃГЄЃЌУПДЮЖМашвЊ HBase КЭ Kylin ЕФЭЌбЇвЛПщЖљРДВщЁЃ
2ЃЉНтОіЗНАИ
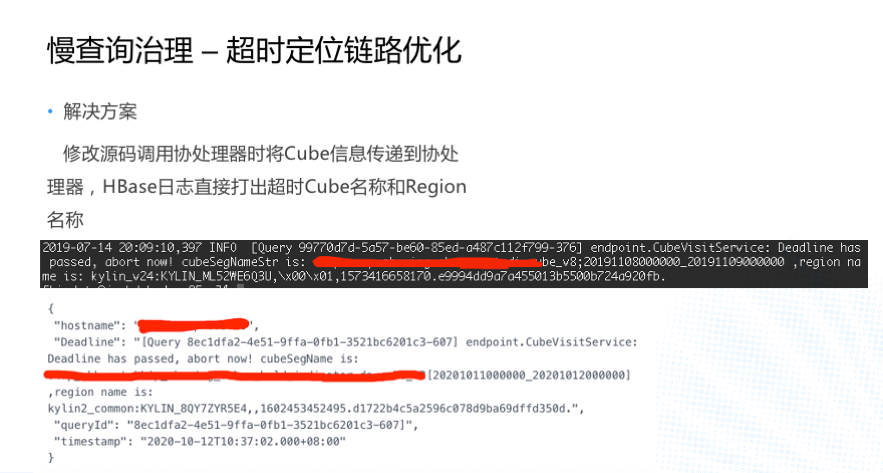
еыЖдетИіЭДЕуИјЮвУЧзіСЫШчЯТИФНјЃКЮвУЧжБНгАб Cube аХЯЂКЭ Region ЕФаХЯЂДђдк HBase
ЕФШежОРяЁЃ жаМфетИіКкЩЋЕФВПЗжОЭЪЧ HBase ЕФШежОЃЌЮвУЧПЩвдПДЕНетИіВщбЏвбОжежЙСЫЃЌCube ЕФУћзжЪЧЪВУДЃЌRegion
ЕФУћзжЪЧЪВУДЃЌЯТУцЕФАзЩЋВПЗжЪЧЭЈЙ§ЬьблЯЕЭГХфжУЕФБЈОЏаХЯЂЃЌетИіБЈОЏЪЧжБНгБЈЕНЦѓвЕЮЂаХЕФЃЌЮвУЧФмТэЩЯжЊЕРетИі
Deadline ЩцМАЕФ Cube КЭ RegionЃЌФмТэЩЯзівЛИіМьВтЪЧетИіБэВЛПЩгУСЫЛЙЪЧВщбЏЗНЪНИФБфСЫЃЌДѓДѓНкЪЁСЫЖЈЮЛЮЪЬтЕФЪБМфЁЃ
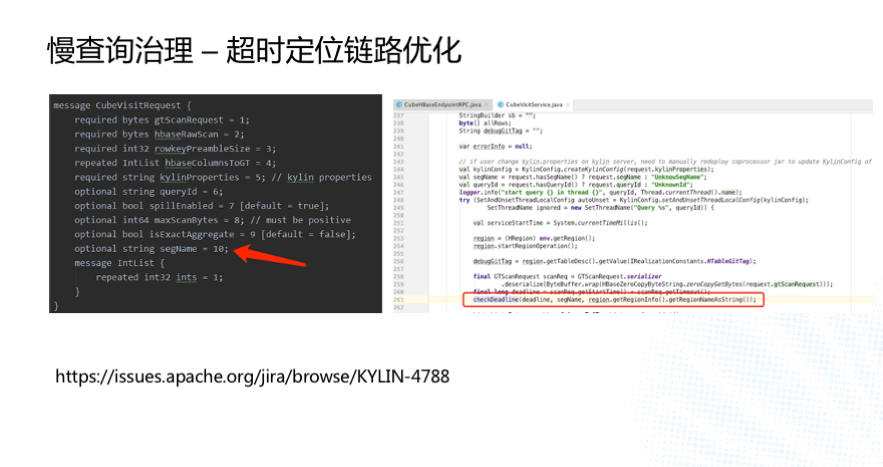
етИіЪЧЮЊСЫНтОіГЌЪБСДТЗЙ§ГЄЮвУЧЖд Kylin зіЕФвЛаЉДњТыИФЖЏЃЌЪзЯШЮвУЧдк
Protobuf ЮФМўжаМгСЫвЛИі segmentName зжЖЮЃЌШЛКѓдкаДІРэЦїРржаЛёШЁСЫ Region
УћзжЃЌдкаДІРэЦїЕїгУ checkDeadLine ЗНЗЈМьВщЪБДЋШы segmentName КЭ regionNameЃЌзюКѓШежОЛсДђгЁГіРД
segment УћГЦКЭ Region ЕФаХЯЂЁЃ етИіЙІФмвбОЗДРЁИјЩчЧјСЫЃЌМћЁЃ
Т§ВщбЏжЮРэ-ЖгСаЖбЛ§ЖЈЮЛ
1ЃЉЯжЯѓ
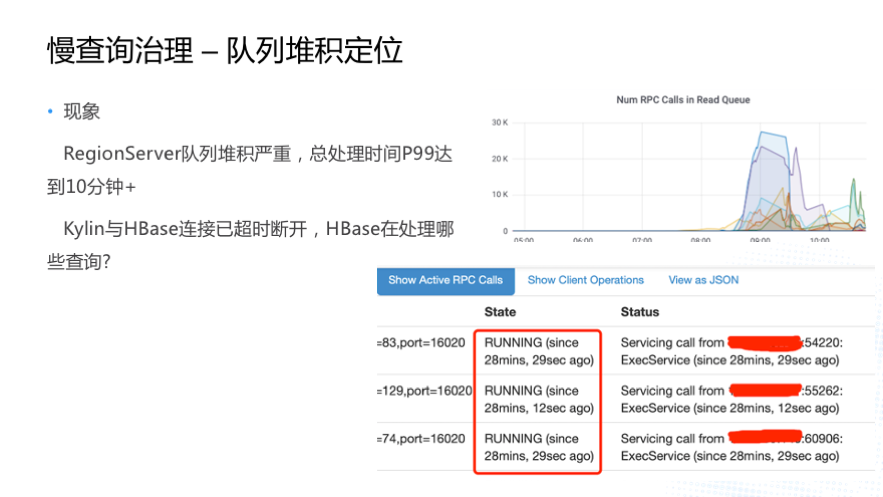
гавЛЬьЮвУЧЗЂЯж Kylin HBase RegionServer ЖгСаЖбЛ§ЗЧГЃбЯжиЃЌRegionServer
ЕФ P99 ЕФЯьгІЪБМфвбОДяЕНСЫ 10 ЖрЗжжгЕФМЖБ№ЃЌДѓМвПДгвЩЯНЧЪЧ HBase ЙигкЖгСаЕФМрПиЧщПіЃЌвЛаЉЛњЦїЕФЖбЛ§вбНЋНќ
3WЁЃЮвУЧЕБЪБЗЧГЃвЩЛѓЃЌвђЮЊ Kylin КЭ HBase жЎМф RPC ЕФГЌЪБЪБМфЪЧ 10 УыЃЌдк
10 УыжЎКѓ Kylin КЭ HBase ЕФСЌНгЖМвбОЖЯПЊСЫЃЌHBase ЕНЕзДІРэЪВУДВщбЏЃЌгвЯТНЧЪЧ
HBase RegionServer UI вГУцЕФНиЭМЃЌдкетИіНиЭМРяЮвУЧЗЂЯжвЛаЉВщбЏЦфЪЕвбОжДааСЫПьАыИіаЁЪБСЫЃЌетАыИіаЁЪБЪЧдкжДааЪВУДФиЃП
2ЃЉНтОіЗНАИ

ЮвУЧЕБЪБЕФНтОіЗНАИЪЧШЅШЮЮёЖбЛ§ЕФгаЖгСаЭЦЛ§ЕФ RegionServer ЩЯШЅПДШежОЃЌЭЈЙ§ВщбЏПЊЪМЪБМфНсЪјЪБМфзіВюжЕЃЌевГіВщбЏЪБМфзюГЄЕФ
Top10 ЕФВщбЏЃЌЭЈЙ§ QureyID ЦЅХфГі Cube КЭОпЬхЕФ SQLЃЌзюжеЮвУЧЗЂЯжвЛАуетжжВщбЏЪБМфЬиБ№ГЄЖМЪЧвђЮЊВщбЏЗНЪНЕФБфЛЏгыдРД
Cube ЩшжУЕФ Rowkey ВЛЯрЗћЕМжТСЫШЋБэЩЈУшЁЃзюжеЕФЗНАИЦфЪЕВщГіРДжЎКѓ Kylin ЕФЭЌбЇЛсШЅЕїећ
Cube ЕФ Rowkey ЩшжУЃЌШЛКѓжиаТЙЙНЈЁЃ
етжжРыЯпЕФЖЈЮЛЕФЗНЪНЦфЪЕВЛЪЧЬиБ№КУЃЌвЛПЊЪМЮвУЧЯыЛљгкШежОзіЪЕЪББЈОЏЃЌетбљФмАяжњЮвУЧИќПьЕФЗЂЯжКЭЖЈЮЛЮЪЬтЃЌЕЋЪЧКѓРДЯыЯыетвВЪЧБШНЯБЛЖЏЕФвЛжжЗНЪНЃЌетжЛЪЧЗЂЯжЮЪЬтЃЌВЛФмГЙЕзНтОіетИіЮЪЬтЁЃ
ЮвУЧКѓРДЯыЕФвЛИіЗНАИЪЧ SQL зїжДаажЎЧАПЩвдЮЊ SQL ДђЗжЃЌЦРЗжЙ§ЕЭЕФОЭОмОјжДааЃЌетИіЙІФмЛЙУЛгаЪЕЯжЁЃгаетИіЯыЗЈЪЧвђЮЊЕБЮвУЧевЕН
SQL аХЯЂКѓЃЌ Kylin ЕФЭЌбЇЪЧПЩвдПДГіРДВщбЏЪЧВЛЪЧВЛКЯРэЃЌЪЧВЛЪЧИњ Rowkey ЩшжУВЛЗћЃЌЮвУЧЯывдКѓзіетбљвЛИіЙІФмЃЌАбШЫЮЊХаЖЯЕФОбщГЬађЛЏЃЌдк
SQL УЛгажДаажЎЧАОЭАбЧБдкЕФЗчЯеЛЏНтЕєЁЃ
Т§ВщбЏжЮРэ ЈC жїЖЏЗРгљ
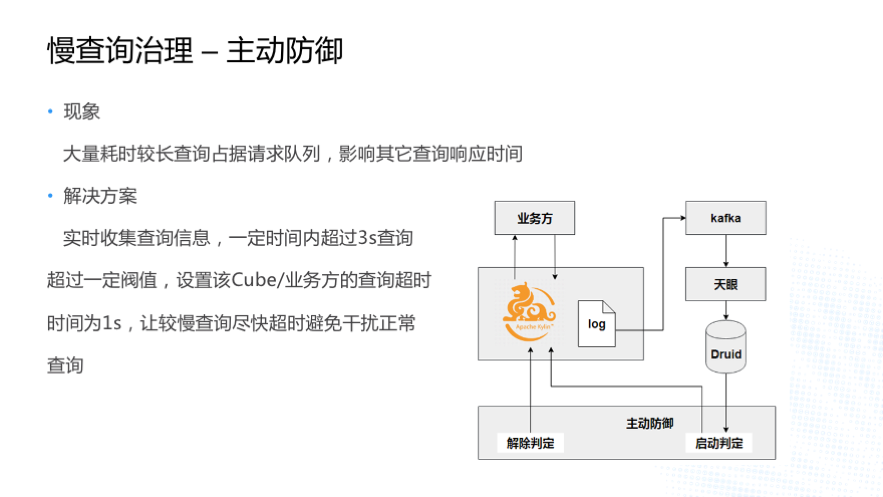
Т§ВщбЏжЮРэЛЙгавЛИіОйДыЪЧ Kylin ЕФжїЖЏЗРгљЁЃЮвУЧЗЂЯжгаДѓСПЕФКФЪБНЯГЄЕФВщбЏЛсеМОнЧыЧѓЖгСаЃЌгАЯьЦфЫћВщбЏЕФЯьгІЪБМфЁЃ
НтОіЗНАИЪЧЭЈЙ§ Kafka ЪеМЏ Kylin ЕФШежОЃЌОЙ§ЬьблЯЕЭГЪЕЪБЧхЯДКѓаДШы DruidЃЌЭЈЙ§
Druid зіЭГМЦЗжЮіЃЌШчЙћФГИівЕЮёЗН/Cube дквЛЖЈЪБМфФкГЌЙ§ 3 УыЕФВщбЏЕНДявЛЖЈЕФЗЇжЕЃЌжїЖЏЗРгљЯЕЭГЛсАбетИівЕЮёЗН/Cube
ЕФВщбЏГЌЪБЪБМфЩшжУЮЊ 1sЃЌШУНЯТ§ЕФВщбЏОЁПьГЌЪБЃЌБмУтЖде§ГЃВщбЏЕФИЩШХЁЃгвБпОЭЪЧЮвУЧећИіСїГЬЕФвЛИіМмЙЙЭМЃЌжїЖЏЗРгљЖдТ§ВщбЏжЮРэгавЛЖЈЕФзїгУЃЌЕЋШЋБэЩЈУшЕФЧщПіЛЙЪЧУЛгаАьЗЈЭъШЋБмУтЁЃ
жиЕужИБъВщбЏадФмБЃеЯ
1ЃЉЯжЯѓ

СэЭтвЛИіОйДыЪЧЖджиЕужИБъЕФВщбЏадФмБЃеЯЁЃдчЦк HBase МЏШКжЛга HDD вЛжжДцДЂНщжЪЃЌжиЕужИБъКЭЦеЭЈжИБъЖМДцДЂдк
HDD ЩЯЃЌЗЧГЃШнвзЪмЕНЦфЫћВщбЏКЭ HDD адФмЕФгАЯьЃЌжиЕужИБъЯьгІЪБМфЮоЗЈБЃеЯЁЃ
2ЃЉНтОіЗНАИ
ЮвУЧЕФНтОіЗНАИЪЧРћгУСЫ HDFS ЕФвьЙЙДцДЂЃЌИјвЛВПЗж DataNode ВхЩЯ SSDЃЌНЋжиЕу Cube
ЕФЪ§ОнДцДЂдк SSD ЩЯЃЌЬсЩ§ЭЬЭТЕФЭЌЪБгыЦеЭЈжИБъЪ§ОнзіДцДЂИєРыЃЌетбљОЭМШБмУтСЫЪмЕНЦфЫћВщбЏЕФгАЯьЃЌвВПЩвдЭЈЙ§
SSD ЕФадФмРДЬсЩ§ЭЬЭТЁЃв§Шы SSD жЛЪЧзіСЫДцДЂЕФИєРыЃЌЛЙПЩвдЭЈЙ§ RSGroup зіМЦЫуИєРыЃЌЕЋгЩгкжиЕужИБъЕФЧыЧѓСПеМЕНСЫМЏШКзмЧыЧѓСПЕФ
90%вдЩЯЃЌЕЅЖРИєРыГіМИЬЈЛњЦїЪЧВЛзувджЇГХетУДДѓЧыЧѓСПЕФЃЌЫљвдзюжеЮвУЧВЂУЛгаетУДзіЁЃ
зюКѓЪЧЮвУЧЕУГіЕФвЛаЉОбщЃЌ SSD ЖдЪЎЭђвдЩЯЩЈУшСПВщбЏадФмЬсЩ§ 40%зѓгвЃЌЖдАйЭђвдЩЯЩЈУшСПадФмЬсЩ§
20%зѓгвЁЃ
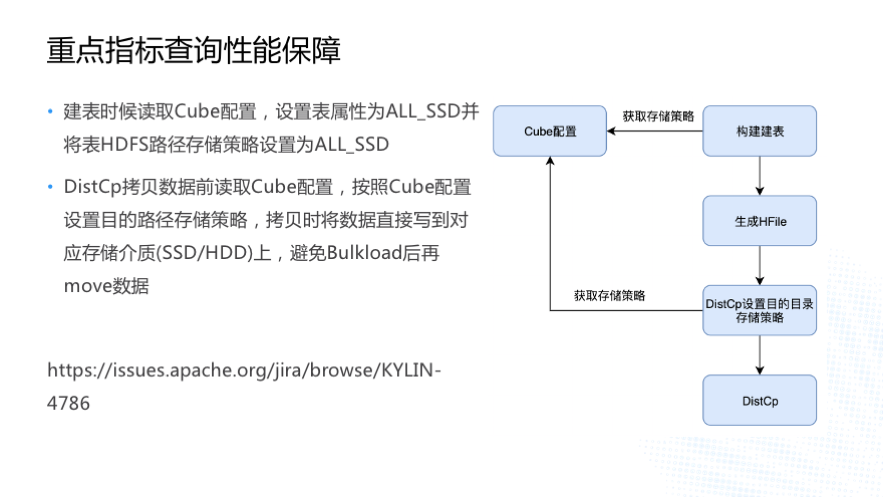
етЪЧЮвУЧгУ SSD зіЕФвЛаЉИФЖЏЃЌЪ§ОнДцДЂдк SSD ЪЧПЩеыЖд Cube ЩшжУЕФЁЃЮвУЧПЩвджИЖЈФФаЉ
Cube Дцдк SSD ЩЯЃЌЙЙНЈШЮЮёНЈБэЪБЛсЖСШЁ Cube ЕФХфжУЃЌАДее Cube ХфжУРДЩшжУ HBase
БэЕФЪєадКЭИУБэЕФ HDFS ТЗОЖДцДЂВпТдЁЃдк DistCp ПНБДжЎЧАвВвЊЯШЖСШЁ Cube ЕФХфжУЃЌШчЙћ
Cube ЕФХфжУЪЧ ALL_SSDЃЌГЬађашвЊЩшжУ DistCp ЕФФПЕФТЗОЖДцДЂВпТдЮЊ ALL_SSDЃЌЩшжУЭъГЩКѓдйНјааЪ§ОнПНБДЁЃ
етбљзіЕФФПЕФЪЧЮЊСЫБмУт Bulkload КѓЪ§ОнЛЙашвЊДг HDD вЦЖЏЕН SSDЃЌвЦЖЏЪ§ОнЛсДјРДЪВУДгАЯьФиЃП
ЮвУЧЗЂЯжШчЙћВЛЯШЩшжУ DistCp ФПЕФТЗОЖДцДЂВпТдЕФЛАЃЌЪ§ОнЛсБЛЯШаДЕН HDD ЩЯЃЌBulkload
КѓгЩгкБэЕФ HDFS ДцДЂТЗОЖДцДЂВпТдЪЧ ALL_SSDЃЌHadoop ЕФ Mover ГЬађЛсАбЪ§ОнДг
HDD вЦЖЏЕН SSDЃЌЕБвЛИіЪ§ОнПщЕФШ§ИіИББОЖМвЦЖЏЕН SSD ЛњЦїЩЯКѓЃЌRegionServer
ВЛФмДгЦфЛКДцИУЪ§ОнПщЕФШ§ЬЈ DataNode ЩЯЖСШЁЕНЪ§ОнЃЌетЪБ RegionServer ЛсЫцЛњЕШД§МИУыжгКѓШЅЯђ
NameNode ЛёШЁИУЪ§ОнПщзюаТЕФ DataNode аХЯЂЃЌетЛсЕМжТВщбЏЯьгІЪБМфБфГЄЃЌЫљвдашвЊдк
DistCp ПНБДЪ§ОнжЎЧАЯШЩшжУФПЕФТЗОЖЕФДцДЂВпТдЁЃ
JVM GC ЦПОБ
1ЃЉЯжЯѓ
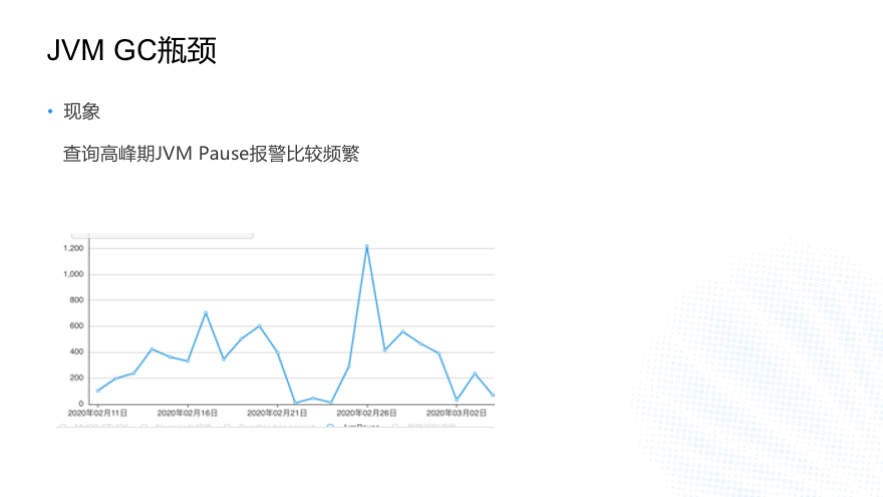
ЮвУЧгіЕНЕФЯТвЛИіЮЪЬтОЭЪЧ RegionServer ЕФ JVM GC ЦПОБЁЃдкВщбЏИпЗхЦк Kylin
HBase JVM Pause БЈОЏЬиБ№ЦЕЗБЃЌДгетеХЭМРяУцПЩвдПДЕНгавЛЬьвбОГЌЙ§ 1200 ИіЁЃKylin
ЖдгУЛЇЕФГаХЕЪЧШ§УыФкВщбЏеМБШдк 99.7%ЃЌЕБЪБвбОДяЕНСЫ 99.8%ЃЌгкЪЧЮвУЧОЭЯыЛЙашвЊгХЛЏФФвЛПщФмШУ
3 УыФкВщбЏеМБШДяЕН 99.9%ЃЌетИі JVM Pause УїЯдГЩЮЊЮвУЧашвЊИФНјЕФвЛИіЕуЃЌДѓМвзі JAVA
ЛљБОЖМжЊЕР JVM дѕУДШЅгХЛЏФиЃП
2ЃЉНтОіЗНАИ
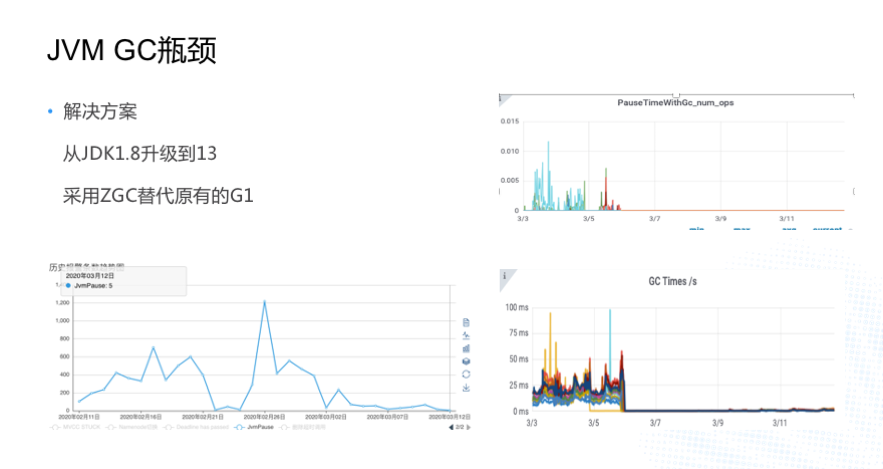
ЪзЯШПЩФмЛсЯыЕНЕїећВЮЪ§ЃЌЦфДЮОЭЪЧЛЛвЛжж GC ЫуЗЈЃЌЮвУЧВЩгУСЫКѓепЁЃ жЎЧАЮвУЧгУЕФЪЧ JDK1.8ЃЌGC
ЫуЗЈЪЧ G1ЃЌКѓРДЮвУЧСЫНтЕН JDK11 ЭЦГіСЫвЛИіаТЕФЫуЗЈНа ZGCЁЃзюже,ЮвУЧАб JDK Дг 1.8
Щ§МЖЕН JDK13ЃЌВЩгУ ZGC ЬцДњСЫдгаЕФ G1ЁЃгвЩЯНЧЕФЭМЪЧ ZGC ЩЯЯпКѓЃЌетЬзМЏШК RegionServer
ЕФ JVM Pause ЕФДЮЪ§МИКѕЮЊ 0ЃЌгвЯТНЧЕФ GC ЪБМфвВЪЧЯрБШжЎЧАНЕЕЭЬиБ№ЖрЁЃZGC гавЛИіЩшМЦФПБъЪЧ
Max JVM Pause ЕФЪБМфдкМИКСУыЃЌетИіаЇЙћЕБЪБПДзХЪЧБШНЯУїЯдЕФЃЌзѓБпЕФЭМЪЧЬьблЯЕЭГЕФБЈОЏЕФЧїЪЦЭМЃЌZGC
ЩЯЯпКѓ JVM Pause БЈОЏЪ§СПУїЯдНЕЕЭЁЃЙигк ZGC ЮвБОдТЛсЗЂвЛЦЊЮФеТНщЩм ZGC ЫуЗЈКЭЮвУЧзіСЫФФаЉИФЖЏРДЪЪХф
JDK13ЃЌетРяОЭВЛЯъЯИНщЩмСЫЁЃ |









