| БрМЭЦМі: |
БОЮФжївЊжївЊДг
Ъ§ОнИёЪНЁЂЪ§ОнБъЧЉМАБрТыДІРэЁЂ ЗжЮіЗНЗЈЪ§ОнИёЪНЁЂЪ§ОнвьГЃЛђЮоаЇДІРэЁЂЪ§ОнЛљБОЬиеїЬНЫїЃЌетМИИіЗНУцЗжЮіСЫЪ§ОнЫМЮЌЁЃЯЃЭћЖдФугаАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЯывЊНјааПЦбЇЕФЪ§ОнЗжЮіЃЌе§ШЗЕФЪ§ОнИёЪНЃЌвдМАе§ГЃЕФЪ§ОнЪЧзюЛљБОЕФЁЃЖјЧвЪ§ОнЕФзМБИКЭЪ§ОнЕФРэНтЃЌе§ЪЧПЦбЇЕФЪ§ОнЗжЮіЫМЮЌБиБИЬѕМўжЎвЛЁЃ
ЯывЊзМБИКУздМКЕФЪ§ОнЃЌашвЊДгвдЯТСљИіЗНУцНјааДІРэЃК
Ек1ЕуЃЌЪЧашвЊзМБИКУе§ШЗЕФЪ§ОнИёЪН
Ек2ЕуЃЌдкгкЖдЪ§ОнЕФЛљБОДІРэЃЌАќРЈЪ§ОнБъЧЉЁЂЪ§ОнБрТыКЭЩњГЩБфСПЕШ
Ек3ЕуЃЌЪЧвЛаЉЗжЮіЗНЗЈашвЊЕФЪ§ОнЬиЪтИёЪНзМБИ
Ек4ЕуЃЌЪЧЪ§ОнвьГЃжЕЃЌЛђепЮоаЇбљБОЪ§ОнЕФДІРэ
Ек5ЕуЃЌЪЧЪ§ОнЛљБОЬиеїЬНЫї
Ек6ЕуЃЌЪЧвЛаЉЦфЫќзЂвтЪТЯюЕШ 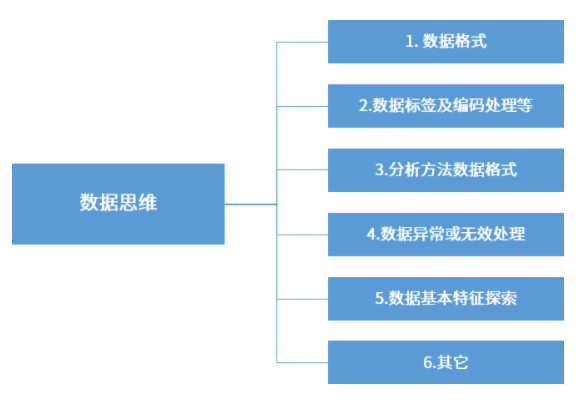
Ек1ЕуЃЌЪ§ОнИёЪН
дкНјааЪ§ОнЗжЮіЧАЃЌЪ§ОнЕФзМБИЪЧЕквЛЕуЃЌВЛТлЪЧЪЙгУЪ§ОнПтЯТдиЕФЪ§ОнЃЌЛђепЪЕбщЪ§ОнЃЌвВЛђепЮЪОэЕїВщЪ§ОнЃЌЪжЙЄТМШыЪ§ОнЕШЁЃВЛТлЪЧжБНгДгЯЕЭГЯТдиЕФдЪМЪ§ОнЃЌЛЙЪЧздМКЪжЙЄТМШыЕФЪ§ОнЃЌОљашвЊАДееЪ§ОнЗжЮіЫМЮЌЕФЙцЗЖИёЪННјааЃЌЗёдђШЮКЮШэМўЖМЮоЗЈЗжЮіЁЃ
ЕЋЭЈГЃЧщПіЯТЃЌКмЖрШЫЖМЛсКіТдДЫВНжшЃЌШЯЪЖгаСЫЪ§ОнТэЩЯОЭПЩвдЗжЮіЃЌЦфЪЕВЛШЛЃЌзМБИЪ§ОнКЭЪ§ОнЕФЛљБОДІРэвВЪєгкЪ§ОнЗжЮіЕФЗЖГыЃЌЖјЧве§ГЃЧщПіЯТЪ§ОнДІРэЛЈЕФЪБМфеМБШЛсГЌЙ§50%ЃЌвВМДЪЧЫЕЯыЭъГЩвЛЯюЗжЮіЃЌЦфЪЕгаГЌЙ§50%ЕФЪБМфЃЈЖрЪ§ЧщПіЯТЛсЪЧ70%зѓгвЃЉЖМЪЧдкзМБИЪ§ОнЩЯЁЃ
НгЯТРДвдР§згЫЕУїЯТЪВУДЪЧе§ШЗЕФЪ§ОнИёЪНЃЌЪзЯШПДЯТГЃМћЕФДэЮѓЪ§ОнИёЪНР§згШчЯТЭМЃК
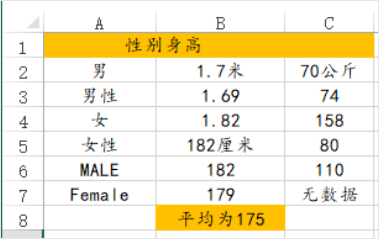
ЩЯЭМЮЊЪЧзюЮЊГЃМћЕФвЛжжДэЮѓЪ§ОнИёЪНЃЌЪжЙЄТМШыЕНEXCELРяУцЕФЪБКђЃЌЗЧГЃЕФЫцвтЃЌЯыШчКЮОЭШчКЮЁЃЕЋвЛЕЉЯыНјааЗжЮіЕФЪБКђОЭЛсГіДэЃЌФЧЪЧгЩгкEXCELЪЧБэИёШэМўЃЌЖјВЛЪЧЪ§ОнЗжЮіШэМўЃЌЫљвдЫцвтЕФИёЪНЖМПЩвдЁЃ
ЩЯЭМжаГіЯжСЫ5ИіГЃМћЕФЮЪЬтЃЌЗжБ№ЪЧЃК
Ек1ЃКГіЯжКЯВЂЕЅдЊИёЃЌA1КЭA2етСНИіЕЅдЊИёКЯВЂЃЌдкЗжЮіЕФЪБКђШэМўОЭВЛжЊЕРУћзжгІИУНаЪВУДЃЌЫљвджБНгЮоЗЈЩЯДЋЕНШэМўжаЃЛ
Ек2ЃКC1етИіЕЅдЊИёБОЩэЪЧБъЪЖЬхжиаХЯЂЃЌЕЋжБНгЮЊПеЃЌЗжЮіШэМўПЩВЛжЊЕРПеОЭЪЧЁЎЬхжиЁЏЕФвтЫМЃЌетЪЧЗЧГЃУїЯдЕФДэЮѓЃЛ
Ек3ЃКAСаРяУцЮЊадБ№ЃЌЕЋЪЧЪ§ОнЗЧГЃВЛЙцЗЖЃЌФаЃЌФаадЃЌMALEетШ§ИіДЪгяЖМЪЧФаЃЌЕЋЪЧЗжЮіШэМўЛсШЯЮЊетЪЧ3ИіВЛЭЌЕФУћДЪЃЌетвВПЩвдКмКУЕФНтЪЭЮЊЪВУДЁЎЬюПеЬтЁЏетжждгТвЮоеТЕФЪ§ОнЭЈГЃЪЧЮоЗЈЗжЮіЕФдвђЃЛ
Ек4ЃКB8етИіИёзгРяУцЮЊЁЎЦНОљЮЊ175ЁЏЃЌетЪЧДэЮѓЕФЁЃдвђдкгкBСаЪЧБъЪЖЩэИпаХЯЂЃЌЖјВЛЪЧЦНОљЩэИпаХЯЂЃЌШчЙћашвЊЕУЕНЦНОљЩэИпЃЌШУЗжЮіШэМўАяФуМЦЫуОЭКУЃЛ
Ек5ЃКC7етИіИёЪНЮЊЁЎЮоЪ§ОнЁЏЃЌЦфЪЕОЭЪЧШБЪЇЪ§ОнЃЌжБНгПезХОЭКУЃЌЗёдђЗжЮіШэМўЛсШЯЮЊЁЎЮоЪ§ОнЁЏЪЧвЛИіЪ§ОнаХЯЂЁЃ
ЩЯЪівбОСаГіГЃМћЕФДэЮѓЬиеїЃЌНгЯТРДЫЕУїе§ШЗЕФЪ§ОнИёЪНШчЯТЃК
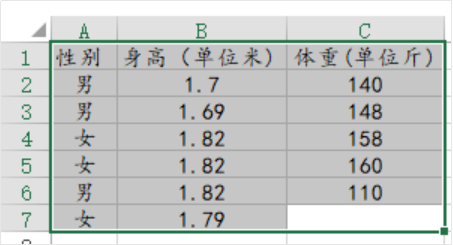
ЙцЗЖЕФЪ§ОнИёЪНЃЈПЩгУгкЪ§ОнЗжЮіЃЉгІИУЪЧетбљЃЌЕк1ааЮЊЁЎБъЬтЁЏМДОпЬхУћзжЃЌЕк2ааЦ№ЮЊОпЬхЕФЪ§ОнЃЌЧвВЛФмгаКЯВЂЕЅдЊИёЕФЧщПіЃЌШчЙћЮЊПежЕМДШБЪЇжЕЃЌжБНгВЛТМШыОЭКУЁЃВЂЧвЪ§ОнаХЯЂашвЊЙцЗЖЃЌБШШчФаЃЌФаадЃЌMALEетШ§ИіДЪгяЖМгІИУЙцЗЖГЩЁЎФаЁЏЁЃ
ШЮКЮЕФЗжЮіШэМўЖМгІИУЬсЙЉЙцЗЖЕФЪ§ОнИёЪНВХФмЗжЮіЃЌвдSPSSAUЮЊР§ЃЌЦфжЇГжЕФЪ§ОнИёЪНЫЕУїШчЯТЃЌЧвSPSSAUжЇГжEXCELИёЪНЃЈАќРЈCSVЃЌxlsКЭxlsxШ§жжРраЭЃЉЃЌSAV(SPSSИёЪНЕШ)ЃЌЪЙгУSPSSAUгвЩЯНЧЁЎЮвЕФЪ§ОнЁЏЩЯДЋЪ§ОнКѓМДГЩЙІЕМШыСЫЪ§ОнЁЃ
ашвЊЬиБ№ЫЕУїЕФвЛЕуЪЧЃКЪ§ОнЗжЮіШэМўЪТЪЕЩЯжЛШЯЪЖЪ§зжЃЌБШШчЩЯР§жаЕФЁЎФаЁЏЃЌЁЎХЎЁЏЃЌШэМўЪЧВЛШЯЪЖЕФЃЌФЧУДШэМўШчКЮДІРэФиЁЃЫќЛсздЖЏАбЁЎФаЁЏЛђЁЎХЎЁЏгУЪ§зж1Лђ2НјааБэЪОЃЌШЛКѓДђЩЯЪ§зжЕФБъЧЉЃЌЗжЮіГіРДКѓЪ§зж1ЕФЪБКђОЭЛсЯдЪОГЩЁЎФаЁЏЃЌЪ§зж2ОЭЛсЯдЪОГЩЁЎХЎЁЏЁЃШЮКЮЕФЛњЦїдРэЩЯЖМжЛШЯЪЖЪ§зжЖјВЛШЯЪЖЮФзжЃЌШЋВПЖМЪЧНЋЮФзжЁЎЪ§зжЛЏЁЏДІРэЁЃвђДЫНгЯТРДЛсНјаавЛаЉЪ§зжБъЧЉЃЌвдМАЪ§ОнЛљБОДІРэЕФЫЕУїЁЃ
Г§ДЫжЎЭтЛЙашвЊЫЕУївЛЕуЪЧЃКШчЙћгаЖрЗнЪ§ОнЃЌетЪЧашвЊздМККЯВЂећРэдквЛИіEXCELЙЄзїБэРяУцВХПЩвдЃЌЗжЮіШэМўЪЧЮоЗЈжЊЕРЖрЗнЪ§ОнЗжБ№ДњБэЪВУДвтЫМЃЌашвЊздМКЪжЙЄНЋЪ§ОнКЯВЂећРэдквЛИіЙЄзїБэРяУцКѓВХФмНјвЛВНЗжЮіЁЃ
Ек2ЕуЃЌЪ§ОнБъЧЉМАБрТыДІРэЕШ
ЩЯвЛЕувбОЫЕУїе§ШЗЕФЪ§ОнжЎКѓЃЌНгЯТРДЫЕУїЯТЪ§ОнЕФЛљБОДІРэЃЌАќРЈЪ§ОнБъЧЉЁЂЪ§ОнБрТыКЭЩњГЩБфСПЁЃЙигкЪ§ОнДІРэЯрЙиЕФВйзїЃЌSPSSAUНиЭМШчЯТЃК
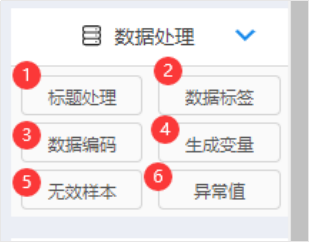
ЭъГЩе§ШЗЕФЪ§ОнЩЯДЋКѓЃЌФЧУДЪ§зжДњБэЕФвтвхЪЧЪВУДФиЃПБШШчЪ§зж1БэЪОФаЃЌЪ§зж2БэЪОХЎЃЌеташвЊИцЫпШэМўВХПЩвдЃЌетМДЪЧЪ§ОнБъЧЉЕФЙІФмЃЌSPSSAUВйзїШчЯТЃК
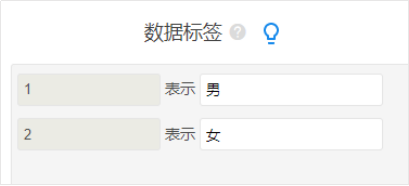
Г§СЫЪ§ОнБъЧЉЭтЃЌгаЪБКђЛЙПЩФмашвЊНјааЪ§ОнБрТыДІРэЃЌБШШчЯЃЭћЖдФъСфЗжГЩ3ИізщБ№ЃЌЗжБ№ЪЧ20вдЯТЃЌ20~30ЃЌ30вдЩЯЁЃДЫЪБОЭашвЊЪЙгУЪ§ОнБрТыДІРэЃЌШчЯТЭМЃК
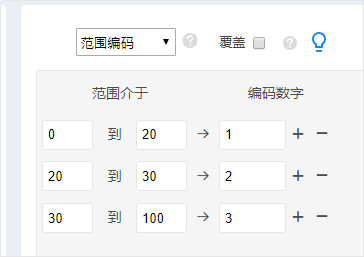
ЩЯЭМжаЯдЪОЃЌНЋ0~20ЫъБрТыГЩЪ§зж1ЃЛ20~30БрТыГЩЪ§зж2ЃЛ30ЕН100БрТыГЩЪ§зж3ЃЛЕБШЛжСгкЪ§зж1ЃЌ2ЃЌ3ЗжБ№ДњБэЕФвтвхЃЌжЛгаЗжЮіШЫдБздМКВХжЊЕРЃЌЫљвдвЛАуЛЙашвЊЪЙгУЪ§ОнБъЧЉЙІФмШЅБъЪЖГіЪ§зж1ЃЌ2ЃЌ3ДњБэЕФвтвхЁЃ
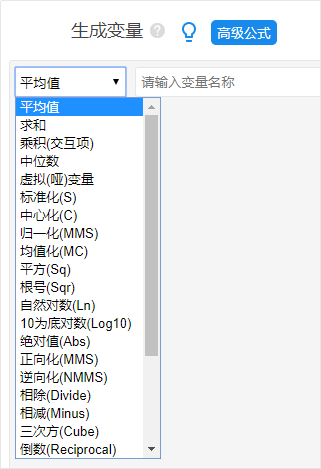
КмЖрЪБКђЛЙашвЊЖдЪ§ОнЩњГЩБфСПДІРэЃЌБШШчЫЕЖдЬхжиЛђепЩэИпЧѓЖдЪ§ДІРэЃЌЛђепЖдЪ§ОнПЊИљКХЃЌШЁОјЖджЕЃЌЧѓКЭЃЌЧѓЦНОљжЕДІРэЕШЃЌФЧУДПЩЪЙгУSPSSAUЩњГЩБфСПЙІФмЃЌSPSSAUЬсЙЉДѓдМ30РрЪ§ОнДІРэЕФЙІФмЛљБОЩЯПЩвдТњзуЫљгаШЫЕФашЧѓЁЃЕБШЛгаЪБКђЛЙашвЊИќЖрЕФДІРэЃЌПЩЪЙгУЁЎИпМЖЙЋЪНЁЏздМКЪфШыЙЋЪНДІРэМДПЩЁЃ
дкЭъГЩЪ§ОнБрТыЃЌЩњГЩБфСПжЎКѓЃЌгаПЩФмЛсЯыЖдЁЎБъЬтУћГЦЁЏаоИФЛђепЩОГ§ЕєЖргрЯюЃЌДЫЪБПЩЪЙгУSPSSAUЁЎБъЬтДІРэЁЏЙІФмМДПЩЁЃ
Ек3ЕуЃЌЗжЮіЗНЗЈЪ§ОнИёЪН
дкЭъГЩе§ШЗЕФЪ§ОнЩЯДЋМАЪ§ОнДІРэКѓЃЌЭЈГЃОЭПЩвдПЊЪМНјаае§ГЃЕФЗжЮіСЫЃЌОјДѓЖрЪ§ЕФЗжЮіЖМПЩвдЭъГЩЁЃЕЋгаЕФЪБКђЃЌИіБ№баОПЗНЗЈЖдгкЪ§ОнИёЪНЪЧгаЬиЪтвЊЧѓЕФЃЌЫљвдЛЙашвЊАДееЦфЬиеїЕФЪ§ОнИёЪНвЊЧѓНјаазМБИЪ§ОнЃЌБШШчПЈЗНМьбщЪБгаЪБЬсЙЉЕФЪЧЁЎМгШЈЁЏЪ§ОнИёЪНЃЌkappaвЛжТадМьбщЃЌФЃК§злКЯЦРМлЗжЮіЗНЗЈЕШЬиБ№ЗжЮіЗНЗЈЪБЃЌЖдгкЪ§ОнЕФИёЪНгаЬиЪтЕФвЊЧѓЃЌНЈвщПЩжБНгВщПДSPSSAUАяжњЪжВсРяУцЕФАИР§Ъ§ОнИёЪНЃЌЕБШЛвВПЩвджБНгЪЙгУSPSSAUЕФАИР§Ъ§ОнРяУцЕФИёЪНФЃЗТВЮПМНјааМДПЩЁЃ
ОпЬхПЩдкДЫвГУцВщПДSPSSAUЕФАИР§Ъ§ОнИёЪНЃК
https://spssau.com/front/spssau/helps/otherdocuments/spssaucasedata.html
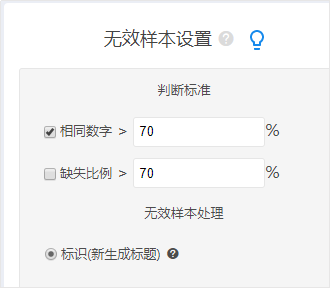
Ек4ЕуЃЌЪ§ОнвьГЃЛђЮоаЇДІРэ
ЖдгкЩЯДЋКѓЕФЪ§ОнЃЌгаЪБКђЛсГіЯжвьГЃЧщПіЃЌБШШче§ГЃФаадГЩФъШЫЕФЩэИпЪЧНщгк1.5~2УзжЎМфЃЌЕЋЪЧШчЙћГіЯжвЛИіЪ§ОнЮЊ1.2УзЃЌФЧетжжвьГЃЪ§ОндкЗжЮіжЎЧАЪЧашвЊНјааДІРэВХПЩвдЃЌвЛАуЧщПіЯТЪЧАбИУжЕжБНгЩшжУГЩnullжЕЁЃSPSSAUВйзїШчЯТЃК
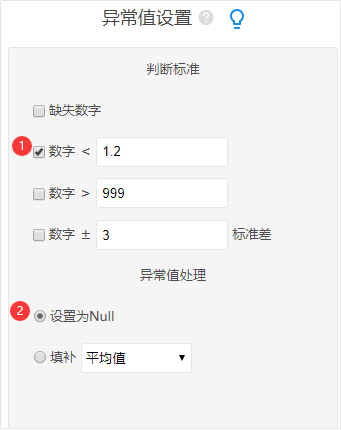
вВгаЕФЪБКђЛсЖдЪ§ОнБъЪЖЮЊЮоаЇбљБОЃЌБШШчвЛЗнЙигкЬдБІЙКЮяТњвтЖШЕФЮЪОэЃЌЬюаДепШЋВПЖМЬюаДЭъШЋЯрЭЌЕФД№АИЃЌЫЕУїИУбљБОУЛгаШЯецЬюаДЃЌДЫЪБПЩНЋИУбљБОЩшжУЮЊЮоаЇбљБОЃЌSPSSAUВйзїШчЯТЭМЃЈНЋЯрЭЌЪ§зжДѓгк70%ЩшжУГЩЮоаЇбљБОЃЉЃК
Ек5ЕуЃЌЪ§ОнЛљБОЬиеїЬНЫї
ЭЈГЃдкЗжЮіЧАЃЌЛЙашвЊЪзЯШЬНЫїЯТЪ§ОнЕФЬиеїЃЌПДЯТЪ§ОнЪЧЗёгавьГЃЧщПіЃЌДѓИХПДЯТЪ§ОнЕФЬиеїЧщПіЕШЃЌБугкзіЕНаФжагаЪ§ЃЌБШШче§ГЃФаадГЩФъШЫЩэИпЪЧНщгк1.5~2УзжЎМфЃЌЕЋЪ§ОнжагаУЛгавьГЃжЕФиЃЌЭЈГЃПЩЪЙгУУшЪіЗжЮіДѓИХПДЯТОЭКУЁЃШчЯТЭМжазюаЁжЕЪЧ1.69УзЃЌзюДѓЪЧ1.82УзЃЌЖМЪЧе§ГЃЪ§ОнЁЃ

ЕБШЛЛЙПЩвдВщПДвЛаЉИќЩюШыЕФЪ§ОнжИБъЃЌБШШчАйЗжЮЛЪ§ЕШЃЌШчЯТЭМЃК

СэЭтвВПЩвдЪЙгУЯфЯпЭМЁЂЛђепЩЂЕуЭМЕШПДЯТЪЧЗёгавьГЃЪ§ОнЃЌSPSSAUПЩЪгЛЏРяУцОљгаЬсЙЉЁЃ
Ек6ЕуЃЌЦфЫќ
Ъ§ОнЕФзМБИКЭЧхРэЪЧНјааЪ§ОнЗжЮіЕФЕквЛВНЃЌЖјЧве§ГЃЧщПіЯТЃЌДЫВНжшеМгУСЫЪ§ОнЗжЮіГЌЙ§50%ЃЈДѓВПЗжЧщПіЯТЪЧ70%ЃЉЕФЪБМфЃЌЕЋДЫВНжшЗЧГЃШнвзБЛЦеЭЈгУЛЇКіТдЁЃ
ЭъГЩЪ§ОнзМБИКЭЛљБОЕФЧхРэЃЌЪ§ОнвьГЃЃЌЪ§ОнЮоаЇЃЌвдМАЪ§ОнЬиеїЬНЫїжЎКѓЃЌВХФмПЊЪМНјШыЯТвЛВНЃЌМДе§ГЃЕФЪ§ОнЗжЮіЁЃЗёдђКѓУцЗжЮіЗЂЯжгазХвьГЃЪ§ОнЛђепЮоаЇЪ§ОнЃЌвВЛђепДэЮѓЕФЪ§ОнЃЌФЧУДжаМфЫљгаЕФЗжЮіЖМЛсАзЗбЁЃ |









