| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЖд
Flink зіСЫвЛИіЯъЯИЕФНщЩмЃЌНЋ Flink ЕФИХФюЁЂЬиЕуЕШзіСЫЯъЯИУшЪіЁЃЯЃЭћЖдФугаАяжњЁЃ
БОЮФРДздЫбКќЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЫцзХетаЉФъДѓЪ§ОнЕФЗЩЫйЗЂеЙЃЌвВГіЯжСЫВЛЩйМЦЫуЕФПђМмЃЈHadoopЁЂStormЁЂSparkЁЂFlinkЃЉЁЃдкЭјЩЯгаШЫНЋДѓЪ§ОнМЦЫув§ЧцЕФЗЂеЙЗжЮЊЫФИіНзЖЮЁЃ
ЕквЛДњЃКHadoop ГадиЕФ MapReduce
ЕкЖўДњЃКжЇГж DAGЃЈгаЯђЮоЛЗЭМЃЉПђМмЕФМЦЫув§Чц Tez КЭ OozieЃЌжївЊЛЙЪЧХњДІРэШЮЮё
ЕкШ§ДњЃКжЇГж Job ФкВПЕФ DAGЃЈгаЯђЮоЛЗЭМЃЉЃЌвд Spark ЮЊДњБэ
ЕкЫФДњЃКДѓЪ§ОнЭГвЛМЦЫув§ЧцЃЌАќРЈСїДІРэЁЂХњДІРэЁЂAIЁЂMachine LearningЁЂЭММЦЫуЕШЃЌвд
Flink ЮЊДњБэ
ЛђаэЛсгаШЫВЛЭЌвтвдЩЯЕФЗжРрЃЌЮвОѕЕУЦфЪЕетВЂВЛживЊЕФЃЌживЊЕФЪЧЬхЛсИїИіПђМмЕФВювьЃЌвдМАИќЪЪКЯЕФГЁОАЁЃВЂНјааРэНтЃЌУЛгаФФвЛИіПђМмПЩвдЭъУРЕФжЇГжЫљгаЕФГЁОАЃЌвВОЭВЛПЩФмгаШЮКЮвЛИіПђМмФмЭъШЋШЁДњСэвЛИіЁЃ
БОЮФНЋЖд Flink ЕФећЬхМмЙЙКЭ Flink ЕФЖржжЬиадзіИіЯъЯИЕФНщЩмЃЁдкНВ Flink жЎЧАЕФЛАЃЌЮвУЧЯШРДПДПД
Ъ§ОнМЏРраЭКЭ Ъ§ОндЫЫуФЃаЭЕФжжРрЁЃ
Ъ§ОнМЏРраЭ
ЮоЧюЪ§ОнМЏЃКЮоЧюЕФГжајМЏГЩЕФЪ§ОнМЏКЯ
гаНчЪ§ОнМЏЃКгаЯоВЛЛсИФБфЕФЪ§ОнМЏКЯ
ФЧУДФЧаЉГЃМћЕФЮоЧюЪ§ОнМЏгаФФаЉФиЃП
гУЛЇгыПЭЛЇЖЫЕФЪЕЪБНЛЛЅЪ§Он
гІгУЪЕЪБВњЩњЕФШежО
Н№ШкЪаГЁЕФЪЕЪБНЛвзМЧТМ
Ё
Ъ§ОндЫЫуФЃаЭ
СїЪНЃКжЛвЊЪ§ОнвЛжБдкВњЩњЃЌМЦЫуОЭГжајЕиНјаа
ХњДІРэЃКдкдЄЯШЖЈвхЕФЪБМфФкдЫааМЦЫуЃЌЕБМЦЫуЭъГЩЪБЪЭЗХМЦЫуЛњзЪдД
ФЧУДЮвУЧдйРДПДПД Flink ЫќЪЧЪВУДФиЃП
Flink ЪЧЪВУДЃП
Flink ЪЧвЛИіеыЖдСїЪ§ОнКЭХњЪ§ОнЕФЗжВМЪНДІРэв§ЧцЃЌДњТыжївЊЪЧгЩ Java ЪЕЯжЃЌВПЗжДњТыЪЧ ScalaЁЃЫќПЩвдДІРэгаНчЕФХњСПЪ§ОнМЏЁЂвВПЩвдДІРэЮоНчЕФЪЕЪБЪ§ОнМЏЁЃЖд
Flink ЖјбдЃЌЦфЫљвЊДІРэЕФжївЊГЁОАОЭЪЧСїЪ§ОнЃЌХњЪ§ОнжЛЪЧСїЪ§ОнЕФвЛИіМЋЯоЬиР§ЖјвбЃЌЫљвд Flink
вВЪЧвЛПюеце§ЕФСїХњЭГвЛЕФМЦЫув§ЧцЁЃ
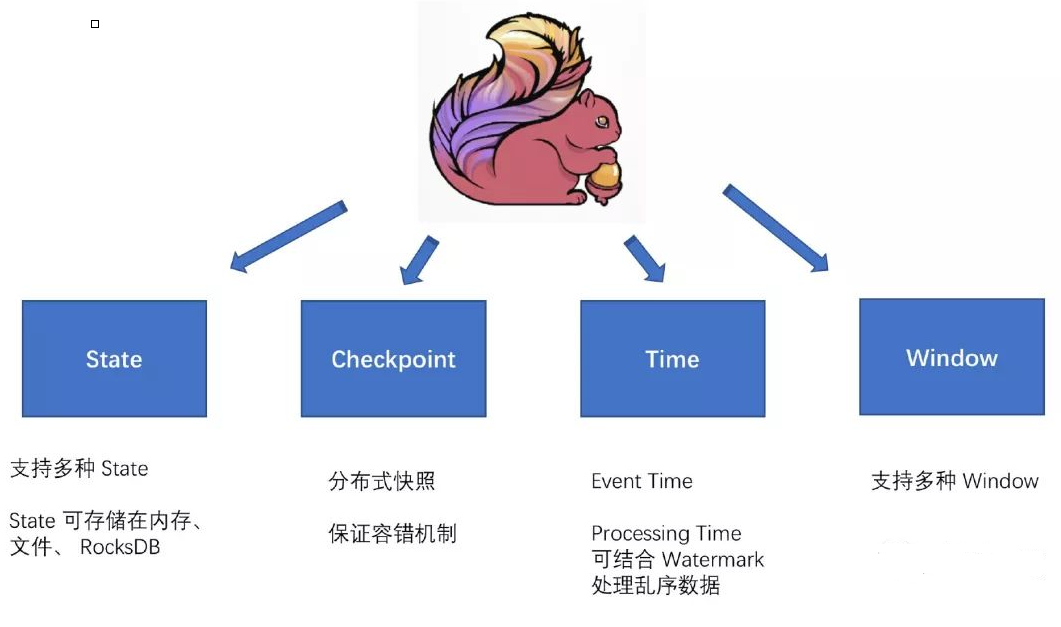
Flink ЬсЙЉСЫ StateЁЂCheckpointЁЂTimeЁЂWindow ЕШЃЌЫќУЧЮЊ Flink
ЬсЙЉСЫЛљЪЏЃЌБОЦЊЮФеТЯТУцЛсЩдзїНВНтЃЌОпЬхЩюЖШЗжЮіКѓУцЛсгазЈУХЕФЮФеТРДНВНтЁЃ
Flink ећЬхНсЙЙ
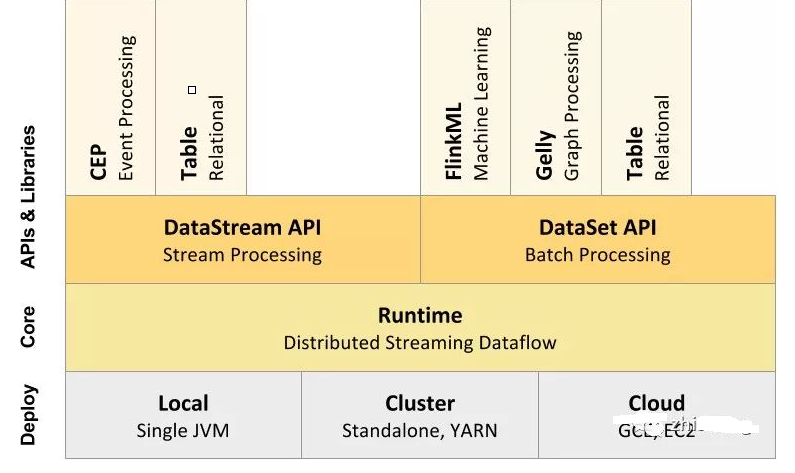
ДгЯТжСЩЯЃК
1ЁЂВПЪ№ЃКFlink жЇГжБОЕидЫааЃЈIDE жажБНгдЫааГЬађЃЉЁЂФмдкЖРСЂМЏШКЃЈStandalone
ФЃЪНЃЉЛђепдкБЛ YARNЁЂMesosЁЂK8s ЙмРэЕФМЏШКЩЯдЫааЃЌвВФмВПЪ№дкдЦЩЯЁЃ
2ЁЂдЫааЃКFlink ЕФКЫаФЪЧЗжВМЪНСїЪНЪ§Онв§ЧцЃЌвтЮЖзХЪ§ОнвдвЛДЮвЛИіЪТМўЕФаЮЪНБЛДІРэЁЃ
3ЁЂAPIЃКDataStreamЁЂDataSetЁЂTableЁЂSQL APIЁЃ
4ЁЂРЉеЙПтЃКFlink ЛЙАќРЈгУгк CEPЃЈИДдгЪТМўДІРэЃЉЁЂЛњЦїбЇЯАЁЂЭМаЮДІРэЕШГЁОАЁЃ
Flink жЇГжЖржжЗНЪНВПЪ№
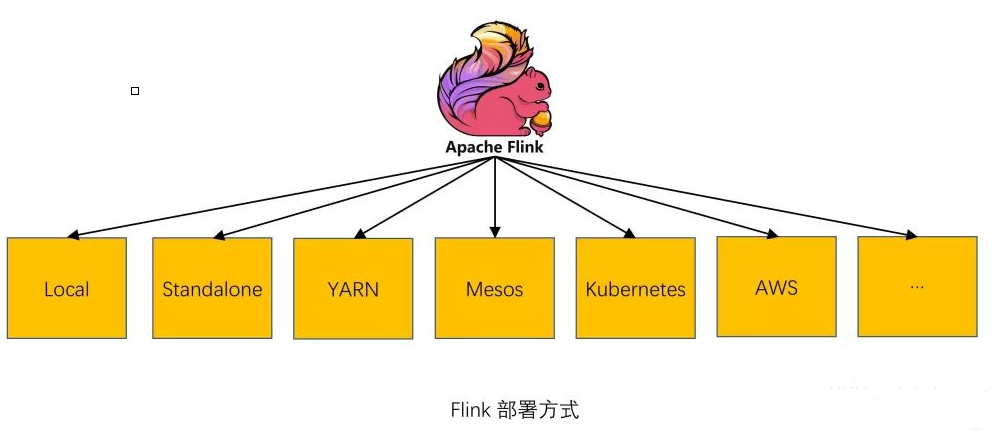
Flink жЇГжЖржжФЃЪНЯТЕФдЫааЁЃ
LocalЃКжБНгдк IDE жадЫаа Flink Job ЪБдђЛсдкБОЕиЦєЖЏвЛИі mini Flink
МЏШК
StandaloneЃКдк Flink ФПТМЯТжДаа bin/start-cluster.sh НХБОдђЛсЦєЖЏвЛИі
Standalone ФЃЪНЕФМЏШК
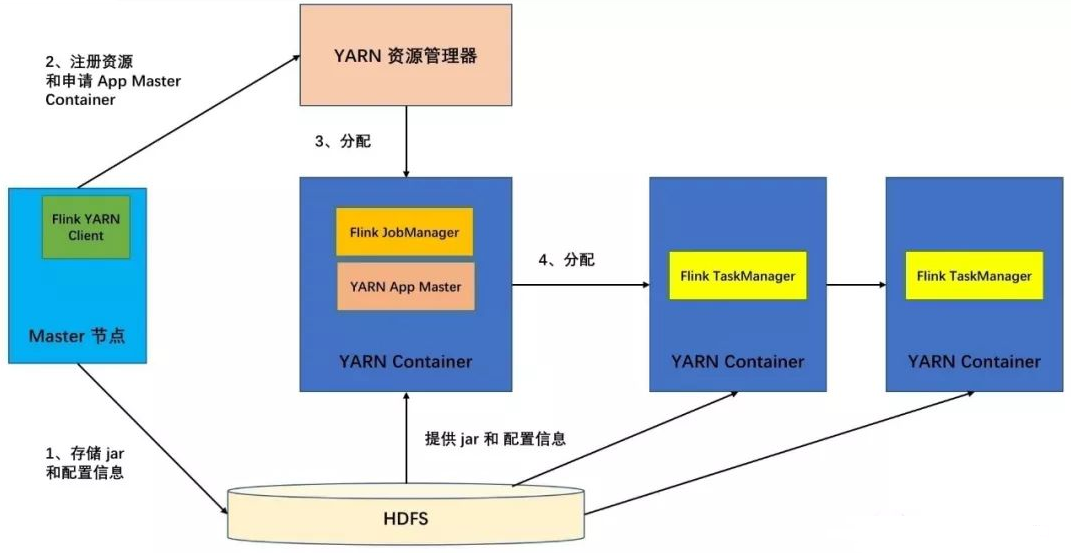
YARNЃКYARN ЪЧ Hadoop МЏШКЕФзЪдДЙмРэЯЕЭГЃЌЫќПЩвддкШКМЏЩЯдЫааИїжжЗжВМЪНгІгУГЬађЃЌFlink
ПЩгыЦфЫћгІгУВЂаагк YARN жаЃЌFlink on YARN ЕФМмЙЙШчЯТЃК
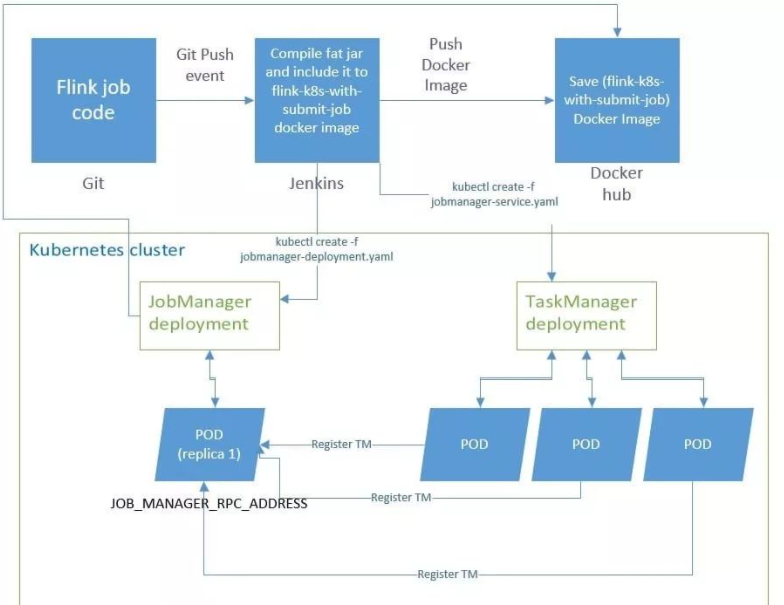
KubernetesЃКKubernetes ЪЧ Google ПЊдДЕФШнЦїМЏШКЙмРэЯЕЭГЃЌдк Docker
ММЪѕЕФЛљДЁЩЯЃЌЮЊШнЦїЛЏЕФгІгУЬсЙЉВПЪ№дЫааЁЂзЪдДЕїЖШЁЂЗўЮёЗЂЯжКЭЖЏЬЌЩьЫѕЕШвЛЯЕСаЭъећЙІФмЃЌЬсИпСЫДѓЙцФЃШнЦїМЏШКЙмРэЕФБуНнадЃЌFlink
вВжЇГжВПЪ№дк Kubernetes ЩЯЃЌдк GitHub ПДЕНгаЯТУцетжждЫааМмЙЙЕФЁЃ
ЭЈГЃЩЯУцЫФжжОгЖрЃЌСэЭтЛЙжЇГж AWSЁЂMapRЁЂAliyun OSS ЕШЁЃ
Flink ЗжВМЪНдЫаа
Flink зївЕЬсНЛМмЙЙСїГЬПЩМћЯТЭМЃК
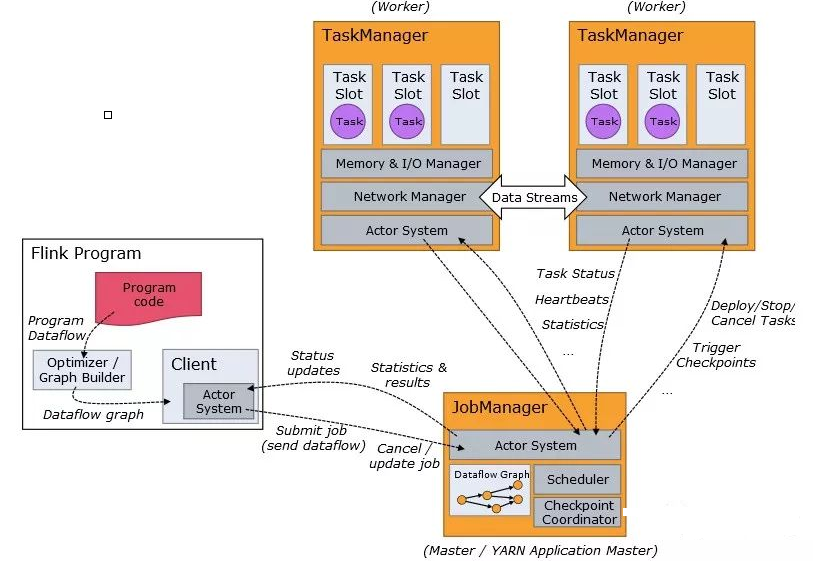
1ЁЂProgram CodeЃКЮвУЧБраДЕФ Flink гІгУГЬађДњТы
2ЁЂJob ClientЃКJob Client ВЛЪЧ Flink ГЬађжДааЕФФкВПВПЗжЃЌЕЋЫќЪЧШЮЮёжДааЕФЦ№ЕуЁЃJob
Client ИКд№НгЪмгУЛЇЕФГЬађДњТыЃЌШЛКѓДДНЈЪ§ОнСїЃЌНЋЪ§ОнСїЬсНЛИј Job Manager вдБуНјвЛВНжДааЁЃжДааЭъГЩКѓЃЌJob
Client НЋНсЙћЗЕЛиИјгУЛЇ
3ЁЂJob ManagerЃКжїНјГЬЃЈвВГЦЮЊзївЕЙмРэЦїЃЉаЕїКЭЙмРэГЬађЕФжДааЁЃЫќЕФжївЊжАд№АќРЈАВХХШЮЮёЃЌЙмРэ
checkpoint ЃЌЙЪеЯЛжИДЕШЁЃЛњЦїМЏШКжажСЩйвЊгавЛИі masterЃЌmaster ИКд№ЕїЖШ taskЃЌаЕї
checkpoints КЭШнджЃЌИпПЩгУЩшжУЕФЛАПЩвдгаЖрИі masterЃЌЕЋвЊБЃжЄвЛИіЪЧ leader,
ЦфЫћЪЧ standby; Job Manager АќКЌ Actor systemЁЂSchedulerЁЂCheck
pointing Ш§ИіживЊЕФзщМў
4ЁЂTask ManagerЃКДг Job Manager ДІНгЪеашвЊВПЪ№ЕФ TaskЁЃTask Manager
ЪЧдк JVM жаЕФвЛИіЛђЖрИіЯпГЬжажДааШЮЮёЕФЙЄзїНкЕуЁЃШЮЮёжДааЕФВЂааадгЩУПИі Task Manager
ЩЯПЩгУЕФШЮЮёВлЃЈSlot ИіЪ§ЃЉОіЖЈЁЃУПИіШЮЮёДњБэЗжХфИјШЮЮёВлЕФвЛзщзЪдДЁЃР§ШчЃЌШчЙћ Task Manager
гаЫФИіВхВлЃЌФЧУДЫќНЋЮЊУПИіВхВлЗжХф 25ЃЅ ЕФФкДцЁЃПЩвддкШЮЮёВлжадЫаавЛИіЛђЖрИіЯпГЬЁЃЭЌвЛВхВлжаЕФЯпГЬЙВЯэЯрЭЌЕФ
JVMЁЃ
ЭЌвЛ JVM жаЕФШЮЮёЙВЯэ TCP СЌНгКЭаФЬјЯћЯЂЁЃTask Manager ЕФвЛИі Slot ДњБэвЛИіПЩгУЯпГЬЃЌИУЯпГЬОпгаЙЬЖЈЕФФкДцЃЌзЂвт
Slot жЛЖдФкДцИєРыЃЌУЛгаЖд CPU ИєРыЁЃФЌШЯЧщПіЯТЃЌFlink дЪаэзгШЮЮёЙВЯэ SlotЃЌМДЪЙЫќУЧЪЧВЛЭЌ
task ЕФ subtaskЃЌжЛвЊЫќУЧРДздЯрЭЌЕФ jobЁЃетжжЙВЯэПЩвдгаИќКУЕФзЪдДРћгУТЪЁЃ
Flink API
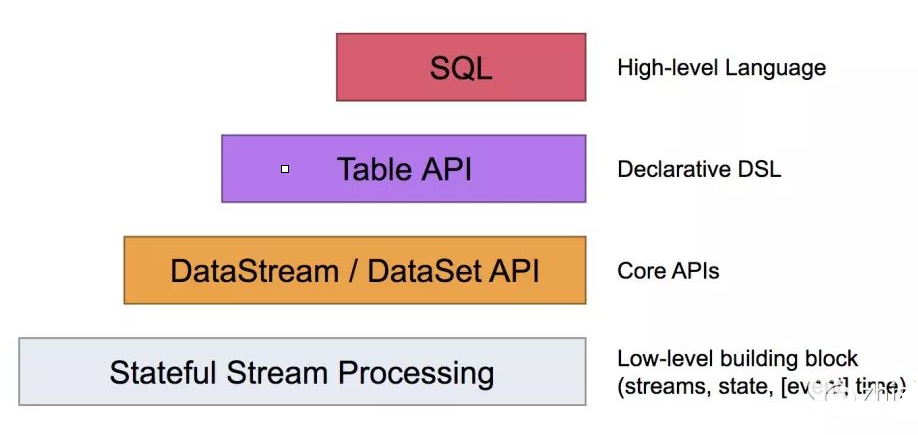
Flink ЬсЙЉСЫВЛЭЌЕФГщЯѓМЖБ№ЕФ API вдПЊЗЂСїЪНЛђХњДІРэгІгУЁЃ
зюЕзВуЬсЙЉСЫгазДЬЌСїЁЃЫќНЋЭЈЙ§ Process Function ЧЖШыЕН DataStream API
жаЁЃЫќдЪаэгУЛЇПЩвдздгЩЕиДІРэРДздвЛИіЛђЖрИіСїЪ§ОнЕФЪТМўЃЌВЂЪЙгУвЛжТадЁЂШнДэЕФзДЬЌЁЃГ§ДЫжЎЭтЃЌгУЛЇПЩвдзЂВсЪТМўЪБМфКЭДІРэЪТМўЛиЕїЃЌДгЖјЪЙГЬађПЩвдЪЕЯжИДдгЕФМЦЫуЁЃ
DataStream / DataSet API ЪЧ Flink ЬсЙЉЕФКЫаФ API ЃЌDataSet
ДІРэгаНчЕФЪ§ОнМЏЃЌDataStream ДІРэгаНчЛђепЮоНчЕФЪ§ОнСїЁЃгУЛЇПЩвдЭЈЙ§ИїжжЗНЗЈЃЈmap /
flatmap / window / keyby / sum / max / min / avg /
join ЕШЃЉНЋЪ§ОнНјаазЊЛЛЛђепМЦЫуЁЃ
Table API ЪЧвдБэЮЊжааФЕФЩљУїЪН DSLЃЌЦфжаБэПЩФмЛсЖЏЬЌБфЛЏЃЈдкБэДяСїЪ§ОнЪБЃЉЁЃTable
API ЬсЙЉСЫР§Шч selectЁЂprojectЁЂjoinЁЂgroup-byЁЂaggregate ЕШВйзїЃЌЪЙгУЦ№РДШДИќМгМђНрЃЈДњТыСПИќЩйЃЉЁЃ
ФуПЩвддкБэгы DataStream/DataSet жЎМфЮоЗьЧаЛЛЃЌвВдЪаэГЬађНЋ Table API
гы DataStream вдМА DataSet ЛьКЯЪЙгУЁЃ
Flink ЬсЙЉЕФзюИпВуМЖЕФГщЯѓЪЧ SQL ЁЃетвЛВуГщЯѓдкгяЗЈгыБэДяФмСІЩЯгы Table API РрЫЦЃЌЕЋЪЧЪЧвд
SQLВщбЏБэДяЪНЕФаЮЪНБэЯжГЬађЁЃSQL ГщЯѓгы Table API НЛЛЅУмЧаЃЌЭЌЪБ SQL ВщбЏПЩвджБНгдк
Table API ЖЈвхЕФБэЩЯжДааЁЃ
Flink ГЬађгыЪ§ОнСїНсЙЙ
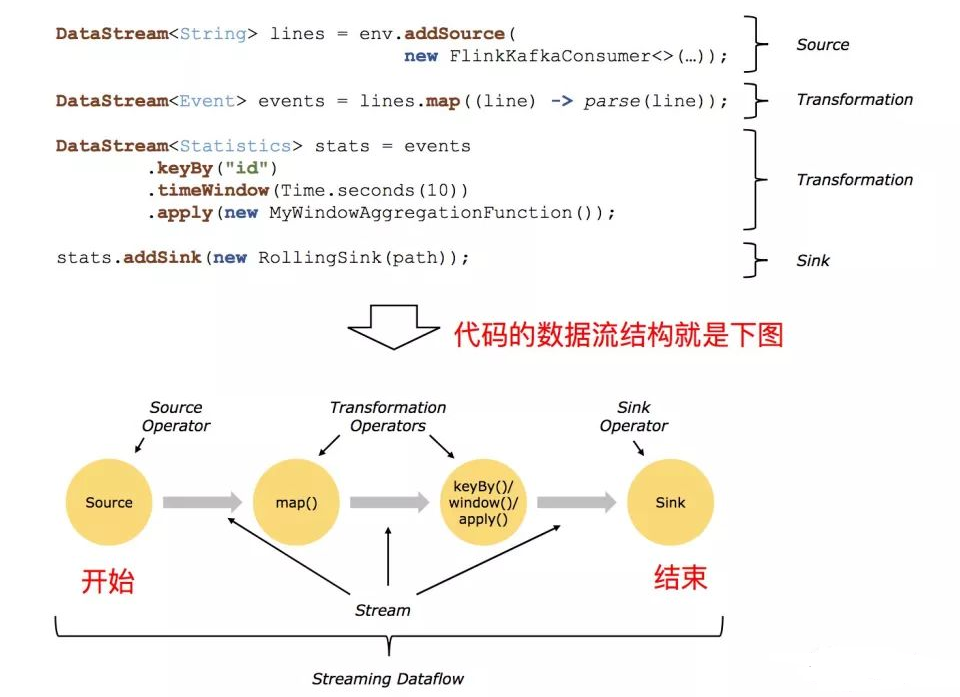
вЛИіЭъећЕФ Flink гІгУГЬађНсЙЙОЭЪЧШчЩЯСНЭМЫљЪОЃК
1ЁЂSourceЃКЪ§ОнЪфШыЃЌFlink дкСїДІРэКЭХњДІРэЩЯЕФ source ДѓИХга 4 РрЃКЛљгкБОЕиМЏКЯЕФ
sourceЁЂЛљгкЮФМўЕФ sourceЁЂЛљгкЭјТчЬзНгзжЕФ sourceЁЂздЖЈвхЕФ sourceЁЃздЖЈвхЕФ
source ГЃМћЕФга Apache kafkaЁЂAmazon Kinesis StreamsЁЂRabbitMQЁЂTwitter
Streaming APIЁЂApache NiFi ЕШЃЌЕБШЛФувВПЩвдЖЈвхздМКЕФ sourceЁЃ
2ЁЂTransformationЃКЪ§ОнзЊЛЛЕФИїжжВйзїЃЌга Map / FlatMap / Filter
/ KeyBy / Reduce / Fold / Aggregations / Window /
WindowAll / Union / Window join / Split / Select /
Project ЕШЃЌВйзїКмЖрЃЌПЩвдНЋЪ§ОнзЊЛЛМЦЫуГЩФуЯывЊЕФЪ§ОнЁЃ
3ЁЂSinkЃКЪ§ОнЪфГіЃЌFlink НЋзЊЛЛМЦЫуКѓЕФЪ§ОнЗЂЫЭЕФЕиЕу ЃЌФуПЩФмашвЊДцДЂЯТРДЃЌFlink
ГЃМћЕФ Sink ДѓИХгаШчЯТМИРрЃКаДШыЮФМўЁЂДђгЁГіРДЁЂаДШы socket ЁЂздЖЈвхЕФ sink ЁЃздЖЈвхЕФ
sink ГЃМћЕФга Apache kafkaЁЂRabbitMQЁЂMySQLЁЂElasticSearchЁЂApache
CassandraЁЂHadoop FileSystem ЕШЃЌЭЌРэФувВПЩвдЖЈвхздМКЕФ sinkЁЃ
Flink жЇГжЖржжРЉеЙПт
Flink гЕгаЗсИЛЕФПтРДНјааЛњЦїбЇЯАЃЌЭМаЮДІРэЃЌЙиЯЕЪ§ОнДІРэЕШЁЃгЩгкЦфМмЙЙЃЌКмШнвзжДааИДдгЕФЪТМўДІРэКЭОЏБЈЁЃ
Flink ЬсЙЉЖржж Time гявх
Flink жЇГжЖржж TimeЃЌБШШч Event timeЁЂIngestion TimeЁЂProcessing
TimeЃЌКѓУцЕФЮФеТ [Flink жа Processing TimeЁЂEvent TimeЁЂIngestion
Time ЖдБШМАЦфЪЙгУГЁОАЗжЮі] жаЛсКмЯъЯИЕФНВНт Flink жа Time ЕФИХФюЁЃ

Flink ЬсЙЉСщЛюЕФДАПкЛњжЦ
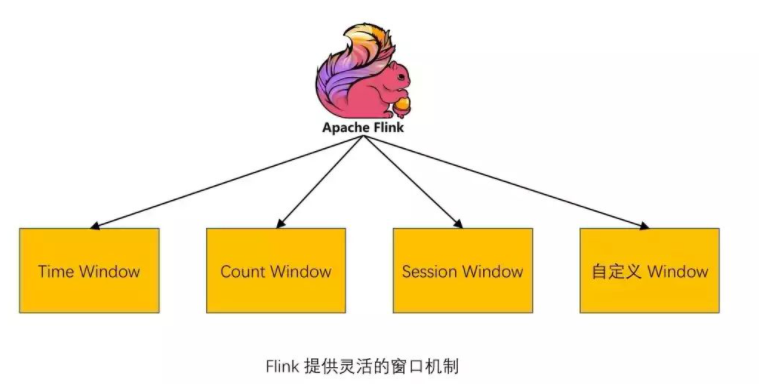
Flink жЇГжЖржж WindowЃЌБШШч Time WindowЁЂCount WindowЁЂSession
WindowЃЌЛЙжЇГжздЖЈвх WindowЁЃКѓУцЕФЮФеТ [ШчКЮЪЙгУ Flink Window МА Window
ЛљБОИХФюгыЪЕЯждРэ] жаЛсКмЯъЯИЕФНВНт Flink жа Window ЕФИХФюЁЃ
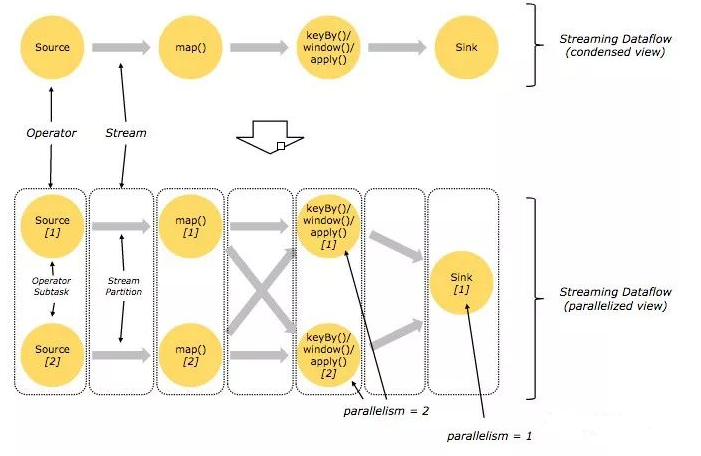
Flink ВЂааЕФжДааШЮЮё
Flink ЕФГЬађФкдкЪЧВЂааКЭЗжВМЪНЕФЃЌЪ§ОнСїПЩвдБЛЗжЧјГЩ stream partitionsЃЌoperators
БЛЛЎЗжЮЊ operator subtasks; етаЉ subtasks дкВЛЭЌЕФЛњЦїЛђШнЦїжаЗжВЛЭЌЕФЯпГЬЖРСЂдЫааЃЛ
operator subtasks ЕФЪ§СПдкОпЬхЕФ operator ОЭЪЧВЂааМЦЫуЪ§ЃЌГЬађВЛЭЌЕФ
operator НзЖЮПЩФмгаВЛЭЌЕФВЂааЪ§ЃЛШчЯТЭМЫљЪОЃЌsource operator ЕФВЂааЪ§ЮЊ 2ЃЌЕЋзюКѓЕФ
sink operator ЮЊ 1ЃК
Flink жЇГжзДЬЌДцДЂ
Flink ЪЧвЛПюгазДЬЌЕФСїДІРэПђМмЃЌЫќЬсЙЉСЫЗсИЛЕФзДЬЌЗУЮЪНгПкЃЌАДееЪ§ОнЕФЛЎЗжЗНЪНЃЌПЩвдЗжЮЊ Keyed
State КЭ Operator StateЃЌдк Keyed State жагжЬсЙЉСЫЖржжЪ§ОнНсЙЙЃК
ValueState
MapState
ListState
ReducingState
AggregatingState
СэЭтзДЬЌДцДЂвВжЇГжЖржжЗНЪНЃК
MemoryStateBackendЃКДцДЂдкФкДцжа
FsStateBackendЃКДцДЂдкЮФМўжа
RocksDBStateBackendЃКДцДЂдк RocksDB жа
Flink жЇГжШнДэЛњжЦ
Flink жажЇГжЪЙгУ Checkpoint РДЬсИпГЬађЕФПЩППадЃЌПЊЦєСЫ Checkpoint жЎКѓЃЌFlink
ЛсАДеевЛЖЈЕФЪБМфМфИєЖдГЬађЕФдЫаазДЬЌНјааБИЗнЃЌЕБЗЂЩњЙЪеЯЪБЃЌFlink ЛсНЋЫљгаШЮЮёЕФзДЬЌЛжИДжСзюКѓвЛДЮЗЂЩњ
Checkpoint жаЕФзДЬЌЃЌВЂДгФЧРяПЊЪМжиаТПЊЪМжДааЁЃ
СэЭт Flink ЛЙжЇГжИљОн Savepoint ДгвбЭЃжЙзївЕЕФдЫаазДЬЌНјааЛжИДЃЌетжжЗНЪНашвЊЭЈЙ§УќСюНјааДЅЗЂЁЃ
Flink ЪЕЯжСЫздМКЕФФкДцЙмРэЛњжЦ
Flink дк JVM жаЬсЙЉСЫздМКЕФФкДцЙмРэЃЌЪЙЦфЖРСЂгк Java ЕФФЌШЯРЌЛјЪеМЏЦїЁЃЫќЭЈЙ§ЪЙгУЩЂСаЃЌЫїв§ЃЌЛКДцКЭХХађгааЇЕиНјааФкДцЙмРэЁЃЮвУЧдкКѓУцЕФЮФеТ
ЁЖЩюШыЬНЫї Flink ФкДцЙмРэЛњжЦЁЗ ЛсЩюШыНВНт Flink РяУцЕФФкДцЙмРэЛњжЦЁЃ |









