| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫApache
HiveЮШЖЈадВтЪдЕФБГОАЁЂЮШЖЈадВтЪдЗжЮіЁЂЮШЖЈадВтЪдЪЕМљгызмНсМАеЙЭћЃЌЯЃЭћЖдФугаАяжњЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1. БГОА
HiveЪЧApacheПЊдДЕФЪ§ОнВжПтЙЄОпЃЌжївЊЪЧНЋЛљгкHadoopЕФНсЙЙЛЏЪ§ОнЮФМўгГЩфЮЊЪ§ОнПтБэЃЌВЂЬсЙЉРрSQLВщбЏЙІФмЁЃHiveзюГѕЕФФПБъЪЧЮЊСЫНЕЕЭДѓЪ§ОнПЊЗЂЕФУХМїЃЌЫќЦСБЮСЫЕзВуМЦЫуФЃаЭЕФИДдгПЊЗЂТпМЃЌРрSQLЕФВщбЏЙІФмвВБугкЪ§ОнгІгУЕФПЊЗЂЃЌЕЋHiveВЂВЛЪЪКЯФФаЉЕЭбгГйЕФВщбЏЗўЮёЃЌШчСЊЛњЪТЮёДІРэЃЈOLTPЃЉРрВщбЏЃЌжївЊгУгкРыЯпЪ§ОнЗжЮіЃЌЪ§ОнСПвЛАуЖМОоДѓЃЌвЛАуЛсгаЗжжгМЖЕФВщбЏбгГйЁЃ
ЫцзХДѓЪ§ОнЕФЗЂеЙЃЌHiveбмЩњГіСЫЛљгкThriftЕФRPCЗўЮёHiveserver2ЁЂMetastoreЃЌБугкНјааЙцФЃЛЏЕФдЫЮЌМАРЉеЙЁЃЭјвзКМбабаЗЂЕФДѓЪ§ОнЦНЬЈЭјвзУЭсяЕФЪ§ВжНЈЩшМАРыЯпЗжЮіОљЪЧЛљгкHiveЃЌШЈЯоЁЂбЊдЕМАЦфЫћЛљгкHadoopЕФРрSQLМЦЫув§ЧцвВгыHiveУмВЛПЩЗжЁЃУцЖдвЕЮёЪ§ОнЗжЮіашЧѓЕФВЛЖЯдіМгЃЌЪ§ВжМАЪ§ОнПЊЗЂШЮЮёЕФЙцФЃвВдкВЛЖЯРЉДѓЃЌИјHiveДјРДЕФЬєеНвВдНРДдНДѓЃЌвЛЕЉЗўЮёЕФЮШЖЈадГіЯжЮЪЬтЃЌгУЛЇВрЫљгаЕФЪ§ОнгІгУвВЖМПЩФмЯнШыЬБЛОЁЃ
ДгЯпЩЯHiveЕФРњЪЗдЫЮЌМАЗЂеЙРДПДЃЌжївЊДцдквдЯТМИИіЭДЕуЃК
ЩчЧјАцБОвХСєЕФЮЪЬтЃКЯпЩЯЙЪеЯЦЕЗБГіЯжЃЌДѓбЙСІГЁОАЯТЗўЮёFullGCЁЂвьГЃЭЫГіЕШЧщПіЃЛ
вРРЕзщМўДјРДЕФЗчЗчЯеЃКЗўЮёСДТЗНЯГЄЃЌвРРЕЗўЮёЕФвьГЃЭљЭљЛсЕМжТHiveЗўЮёГіЯжВЛПЩЛжИДЕФвьГЃЃЛ
БфИќДјРДЕФЗчЯеЃКЫцзХвЕЮёЕФЗЂеЙЃЌбЊдЕЁЂШЈЯоЁЂUDFЕФРЉеЙдНРДдНЖрЃЌЭљЭљЛсЖдЗўЮёДјРДВЛПЩдЄжЊЕФгАЯьЁЃ
ЭДЖЈЫМЭДжЎЯТЃЌЮвУЧНЋHiveЕФЮШЖЈадБЃеЯзїЮЊЙЄзїЕФжиЕуЃЌФПБъЪЧЬсЩ§HiveЗўЮёЕФПЩгУТЪЃЌвЛЗНУцБЃжЄАцБОЕќДњИќаТКѓЯпЩЯЗўЮёЮШЖЈПЩгУЃЌСэвЛЗНУцЕБЙЪеЯГіЯжЪБгаЖдгІЕФдЄАИЃЌФмЙЛПьЫйЕФЛжИДЃЌМѕЩйЙЪеЯЕФЖЈЮЛМАЛжИДЪБМфЁЃ
2 HiveЮШЖЈадВтЪдЗжЮі
2.1 ЯпЩЯЮЪЬтЗжЮі
дкНјааHiveЕФЮШЖЈадВтЪджЎЧАЃЌЪзЯШашвЊЖдЯпЩЯЕБЧАЕФЮШЖЈадЮЪЬтНјааЗжЮіЃЌзлКЯРњЪЗЫљгаЕФЯпЩЯЙЪеЯЃЌжївЊдвђдквдЯТМИИіЗНУцЃК
ДѓВЂЗЂДѓбЙСІГЁОАЯТЃЌЗўЮёХМЯжвьГЃЃЛ
ДѓЪ§ОнГЁОАЯТЕФЬиЖЈSQLЕМжТЗўЮёФкДцвчГіЁЃ
РЉеЙJARПЩФмЛсЕМжТЗўЮёНјГЬвьГЃЭЫГіЃЛ
вРРЕзщМўЕФвьГЃЕМжТЗўЮёВЛПЩгУЧвЮоЗЈЛжИДЁЃ
ЛљгкЩЯЪіЕФЮЪЬтЃЌжївЊДгбЙСІВтЪдЁЂЙЪеЯзЂШыСНИіЗНУцРДНјааБЃеЯЁЃдкбЙСІВтЪдЗНУцЃЌГ§СЫашвЊСїСПФЃаЭЕФЙЙдьЭтЃЌЛЙашвЊжиЕуЙизЂЧыЧѓSQLЁЂЪ§ОнГЁОАЃЌетОЭашвЊЖдЯпЩЯГЁОАГфЗжЗжЮіКѓНјааФЃФтЃЌдкЙЪеЯзЂШыЗНУцЃЌашвЊЪзЯШЖдМмЙЙМАСДТЗНјааЗжЮіЁЃ
2.2 бЙВтЗНАИ
2.2.1 ВтЪдЛЗОГ
Hiveserver2/Metastore ЯпЩЯВПЪ№ОљВЩгУZookeeperРДзіИпПЩгУМАЫцЛњЕФИКдиОљКтЃЌЧвОљЮЊЛьВПЕФЗНЪНЃЈМДHiveserver2ЁЂMetastore
ВПЪ№гкЭЌвЛНкЕуЃЉЃЌвдЯпЩЯФГМЏШКЮЊР§ЃЌДцдк2НкЕуЕФHiveserver2МАMetastoreЁЃ
ЮШЖЈадВтЪдЛЗОГЕФВПЪ№ЭиЦЫашвЊгыЯпЩЯБЃГжвЛжТЃЌЧвЗўЮёЕФКЫаФХфжУашвЊгыЯпЩЯБЃГжвЛжТЛђепАДееЗўЮёЦїЙцИёНјаавЛЖЈБШР§ЕФЫѕаЁЁЃетРяашвЊжиЕуЙизЂЕФЪЧЃЌЯпЩЯЯпЯТзюДѓЕФВювьдкгкЕзВуЕФДцДЂМАМЦЫузЪдДЃЌЯпЩЯHadoopМЏШКЙцФЃЭљЭљдкЪ§АйИіНкЕуЩѕжСЩЯЧЇИіНкЕуЃЌЯпЯТВтЪдЛЗОГЪмЯогкГЩБОЃЌвЛЖЈгыЩњВњЛЗОГДцдкНЯДѓВювьЃЌетОЭашвЊдкЦЬЕиЪ§ОнЁЂСїСПЙЙдьЗНУцеыЖдВтЪдЛЗОГзЪдДНјааеыЖдадЕФЙЙдьЁЃ
2.2.2 SQLГЁОАЙЙНЈ
злКЯЖдгкHQLЕФЗжЮіЃЌПЩвдНЋSQLДѓжТЗжЮЊШ§РрЃЌDDLЁЂDMLМАDQL
DDLжївЊЪЧHiveПтЁЂБэЁЂСаЁЂЗжЧјНјааДДНЈЁЂаоИФЁЂЩОГ§ЯрЙиЕФВйзїЃЌДЫРрВйзївЛАуSQLЯрЖдМђЕЅжДааКФЪБНЯЖЬЃЌжївЊЕФбЙСІдкгкЖдгкMetastoreдЊЪ§ОнЕФдіЩОИФВщЁЃетРяашвЊжиЕузЂвтpartitionЕФЪ§ОнЦЬЕиЃЌдкHiveдЊЪ§ОнжаЭЈГЃРДЫЕжЛгаpartitionsЪ§ОнПЩвдДяЕНАйЭђМЖБ№ЃЈПтБэЪ§ОнЕФСПМЖЭљЭљНЯаЁЃЉЁЃ
DMLЮЊЪ§ОнВйзїгябдЃЌКИЧHiveБэЪ§ОндіИФВйзїЃЌHiveЖдгкUpdateЕФжЇГжвЛАуЃЌДЫРргяЗЈвЛАуУЛШЫгУЃЌЫљвджиЕуЙизЂHiveБэЕФЕМШыВйзїЃЌМАжївЊАќКЌLoadМАInsertгяЗЈЁЃгЩгкПЩФмЩцМАЪ§ОнЕФЧЈвЦМАОлКЯЕШВйзїЃЌДЫРрSQLЭљЭљАщЫцзХMRЕФжДааЃЌгЩгкВтЪдЛЗОГМЦЫузЪдДЁЂДцДЂзЪдДгаЯоЃЌФЃФтЪБашвЊЪЪЕБМѕЩйMRВйзїЕФБШР§ЁЃ
DQLгяОфЃЌжївЊАќКЌВщбЏЁЂМЦЫуРрЕФSQLЃЌгыDMLвЛбљДЫРрSQLЭљЭљвВЛсАщЫцзХMRШЮЮёЕФВњЩњЃЌЙЪДЫРрSQLЕФБШР§вВЛсЪЪЕБНЕЕЭ
РэЯызДЬЌЯТЃЌЯпЯТЮШЖЈадВтЪдЕФЧыЧѓГЁОАгІИУИќМгЬљНќЯпЩЯЃЌЭЈГЃЛсВЩгУЯпЩЯв§СїЕФЗНЪНРДНјааЙЙдьЃЌЕЋЪЧЕЋЪЧЖдгкДѓЪ§ОнГЁОАРДЫЕЃЌЧыЧѓSQLгывЕЮёЪ§ОнЁЂдЊЪ§ОнвЛЭЌЙЙГЩСЫгУЛЇГЁОАЃЌЭбРыЪ§ОнМАдЊЪ§ОнЕФгУЛЇЧыЧѓSQLКСЮовтвхЃЌЖјгЩгкЪ§ОнСПМЖЕФОоДѓЃЌЯпЯТЮоЗЈЖдетВПЗжЪ§ОнНјааФЃФтЃЌвђДЫЮвУЧВЩгУСЫЁАЧњЯпОШЙњЁБЕФЗНЪНРДНјааЙЙНЈЁЃ
ЮШЖЈадВтЪдЕФФПБъжївЊдкгкhiveserver2/metastoreЗўЮёЕФЮШЖЈадЃЌИДдгMRШЮЮёЕФSQLЕФЦПОБдкгкЕзВуМЦЫузЪдДЃЌЧвSQLЕФГЁОАКмФбУЖОйЃЌУЄФПзЗЧѓгыЯпЩЯSQLГЁОАЭъШЋвЛжТЗДЖјЛсЕМжТгЩгкЕзВуМЦЫузЪдДЕФВЛзуЃЌЕМжТЪЕМЪбЙВтЖдЯѓЕФЦЋВюЁЃЪЕМЪдкЮШЖЈадВтЪдЕФСїСПЙЙНЈжаЃЌжївЊвджЎЧАЛ§РлЕФDDLЁЂDMLЁЂDQL
гяЗЈSQLЮЊЛљДЁЃЌЮЊСЫНтОіSQLИДдгЖШЩЯЕФЮЪЬтЃЌЮвУЧв§ШыСЫвЕФкКтСПДѓЪ§ОнадФмжИБъЕФЛљзМВтЪдМЏКЯTPC-DSзїЮЊЧыЧѓSQLГЁОАжаЕФвЛВПЗжЁЃГ§ДЫжЎЭтЃЌвЛВПЗжЬиЖЈЕФгУЛЇSQLГЁОАвВЛсДјРДЮШЖЈадЗНУцЕФЮЪЬтЃЌДЫРрЮЪЬтЭљЭљАщЫцзХЬиЖЈЕФЪ§ОнГЁОАЛђепЬиЖЈЕФUDFГЁОАЃЌШчЖдгкЗжЧјЪ§АйЭђМЖЕФБэЃЌНјааВщбЏЛђепJOINВйзїЛсРДЗўЮёФкДцЕФМЋДѓдіМгЃЌвђДЫетРрSQLвВЛсФЩШыЮШЖЈадВтЪдЕФSQLГЁОАжаЁЃ
злКЯЩЯЪіЗжЮіЙ§ГЬЃЌДѓЬхУїШЗSQLГЁОАжївЊвдЛљДЁЕФSQLМЏКЯЁЂTPCDS SQLМЏКЯМАЛ§РлЕФЯпЩЯЮЪЬтSQLГЁОАРДзщГЩЃЌгЩгквЕФкВЂУЛгаЭГвЛЕФКтСПSQLИДдгЖШЕФБъзМЃЌHiveserver2
metrics жаЕФsql_compileЕФКФЪБПЩвддквЛЖЈГЬЖШЩЯЗДгІSQLЕФИДдгГЬЖШЃЌЪЕМЪдкЙЙдьбЙСІФЃаЭЪБЃЌЛсИљОнЯпЩЯМрПиЪ§ОнНсКЯYarnМЦЫузЪдДЃЌЕїећИїРрSQLЕФБШР§ЁЃ
2.2.3 ЦЬЕиЪ§ОнЙЙдь
HiveЦЬЕиЪ§ОнАќКЌСНВПЗжЃЌвЛВПЗжЮЊHDFSЩЯДцДЂЕФвЕЮёЪ§ОнЃЌСэвЛВПЗжЮЊДцДЂдкMySQLжаЕФдЊЪ§ОнаХЯЂЁЃ
ЖдгкHDFSЩЯДцДЂЕФвЕЮёЪ§ОнРДЫЕЃЌзюРэЯыЕФзДПівЛЖЈЪЧдкЪ§ОнИДдгЖШМАЪ§ОнСПМЖЩЯБЃГжИњЯпЩЯвЛжТЃЌHDFSЕФецЪЕЪ§ОнСПМЖЭљЭљдкTBЩѕжСPBМЖБ№ЃЌЪмЯогкЪ§ОнАВШЋадЁЂМЏШКЙцФЃЕФгАЯьЃЌВтЪдЛЗОГЮоЗЈжБНгЪЙгУЯпЩЯЪ§ОнвВЮоЗЈБЃжЄИњЯпЩЯЪ§ОнЙцФЃвЛжТЁЃ
дкецЪЕЪ§ОнЕФИДдгЖШЩЯЃЌTPC-DSЕФЛљзМЪ§ОнвбОФмдквЛЖЈГЬЖШЩЯФЃФтСЫOLAPЕФЪ§ОнЗжЮіГЁОАЁЃЪ§ОнЙцФЃЗНУцЃЌПМТЧЕНЪ§ОнЕФРЉеХДјРДЕФжївЊЕзВуHadoopМЏШКЕФМЦЫуМАДцДЂбЙСІЃЌЖдгкHiveserver2
ДјРДЕФбЙСІгаЯоЃЌвђДЫетРяВЛдйОРНсгкЪ§ОнСПМЖЕФЖрЩйЃЌЖјЧвжБНгВЩгУАйGBМЖБ№ЕФTPC-DSЛљзМЪ§ОнзїЮЊЦЬЕиЁЃ
дкMySQLДцДЂЕФдЊЪ§ОнаХЯЂЗНУцЃЌЮЊСЫЬљНќЯпЩЯецЪЕГЁОАЃЌетРяОЭМђЕЅДжБЉЕФжБНгИДжЦЯпЩЯRDSжаЪ§ОнзїЮЊЦЬЕзЁЃ
2.2.4 СїСПЙЙдь
ЮШЖЈадВтЪдЕФбЙСІФЃаЭЭљЭљЗжЮЊвдЯТМИИіНзЖЮЃК
КуЖЈбЙСІНзЖЮЃКдкКуЖЈДѓбЙСІГЁОАЯТЃЌЯЕЭГПЩФмГіЯжЭЬЭТСПTPSЕФЖЖЖЏЁЂЯьгІЪБМфЕФВЈЖЏЕШЃЛ
ЛљгкЯпЩЯЧыЧѓГЁОАЙЙНЈЕФбЙСІФЃаЭЃКЭЈЙ§ЖдЗўЮёдкЯпЩЯдЫааЧщПіЕФМрПиЃЌВЛФбЛёШЁЕНВЛЭЌЪБМфЕуЃЌЯпЩЯвЕЮёЕФСїСПВЈЖЏЃЌДЫРрСїСПЭљЭљАщЫцзХЗхжЕЗхЙШбЙСІЃЌЧввЛАуРДЫЕУПЬьЕФбЙСІВЈЖЏЧщПіБШНЯЙЬЖЈЃЌР§ШчЖдгкHiveРДЫЕЃЌРыЯпЗжЮіШЮЮёЕФЧыЧѓЭљЭљдкСшГПКѓДяЕНЗхжЕЃЌДЫРрЧыЧѓСПЭЛдіЕФЧщПіЃЌЭљЭљЛсБЉТЖГіЗўЮёжавўВиЕФЮШЖЈадЮЪЬтЃЌШчГіЯжФкДцвьГЃЁЂЗўЮёхДЛњЕШЧщПіЁЃ
дкКуЖЈбЙСІЕФЛљДЁЩЯв§ШывьГЃЕФИЩШХЃЌШчзЂШыCPUВЈЖЏЁЂЭјТчбгГйЛђепвРРЕзщМўГіЯжЗўЮёвьГЃЕШЁЃв§ШывьГЃзЂШыЭљЭљЛсдкКуЖЈЕФбЙСІГЁОАЯТЪЕЯжЃЌЗёдђЮоЗЈЗжЮіжИБъЕФБфЛЏЪЧЗёЪЧвђЮЊСїСПЕФВЈЖЏДјРДЕФгАЯьЁЃ
дкЭЈГЃЕФвЕЮёГЁОАжаЃЌбЙВтжаЕФбЙСІФЃаЭЪ§ОнЭљЭљРДдДгкадФмВтЪджаЕФЦПОБЪ§ОнЃЌвЕФкЭљЭљЛсгУЙеЕуадФмЪ§ОнЕФ80%зїЮЊбЙВтЪБЕФВЂЗЂЪ§ОнЁЃдкHiveЗўЮёжагЩгкЖдЯьгІЪБМфЕФвЊЧѓВЂУЛгаФЧУДПСПЬЃЌРыЯпМЦЫуШЮЮёЕФКФЪБОГЃдкЗжжгЩѕжСаЁЪБМЖБ№ЃЌЧвећИіМЦЫуСДТЗЩЯЕФЦПОБвЛЖЈВЛдкHiveserver2ЁЂMetastoreЩЯЃЌЖјЪЧгыМЏШКЕФМЦЫузЪдДЁЂДцДЂзЪдДЯрЙиЃЌЫљвдЮвУЧдкЮШЖЈадВтЪдЧАЃЌВЂЮДзіЯЕЭГЕФадФмВтЪдРДШЗЖЈЗўЮёЕФЙеЕуадФмЪ§ОнЃЌвђДЫдкбЙСІДѓаЁЗНУцЃЌЮвУЧМДвдЯпЩЯКЫаФМЏШКЕФЗхжЕЧыЧѓСїСПРДНјааЙЙдьЁЃ
ФЧУДШчКЮРДЦРХав§ШыЕФбЙСІвбОжСЩйДяЕНСЫЯпЩЯбЙСІЕФИКдиФиЃПЕУвцгкHiveЗўЮёНЯЮЊЭъЩЦЕФЗўЮёМрПижИБъЃЌЮвУЧжївЊДгвдЯТСНЗНУцРДНјааХаЖЯЃК
ЗўЮёЦїЕФЛљДЁзЪдДеМгУЃЌHiveЗўЮёЖдДХХЬЁЂЭјТчЕФвЊЧѓВЂВЛИпЃЌвђДЫжиЕуЙизЂЮШЖЈадВтЪджаЕФCPUЁЂФкДцЪЧЗёФмДяЕНИњЯпЩЯЕФЗўЮёМрПиЪ§ОнЦЅХфЃЛ
HiveЗўЮёMetricsМрПиЪ§ОнЃЌжївЊЭЈЙ§open_connectionsРДХаЖЯСїСПЪЧЗёДяЕНдЄЦкЃЌвдМАбЙСІФЃаЭЪЧЗёгыЯпЩЯГЁОАвЛжТЃЛ
2.3 вьГЃзЂШы
ЗжЮіHiveЗўЮёашвЊзЂШыЕФвьГЃЧАЃЌЪзЯШРДЖдЗўЮёЕФМмЙЙМАСДТЗНјааЗжЮіЁЃ
HiveЗўЮёАќКЌHiveserver2/MetastoreЃЌетРяКіТдHiveClientЕФжДааЗНЪНЃЌжївЊЙизЂЗўЮёЕФдЫааЮШЖЈадЁЃ
Hiveserver2/Metastore ЭЈЙ§ZookeeperЪЕЯжИпПЩгУЃЌгУЛЇжДааSQLЪБЭЈЙ§ZookeeperЫцЛњбЁдёЦфжавЛИіНкЕуЧыЧѓЁЃ
SQLЬсНЛКѓжївЊЭЈЙ§Hiveserver2ЪЕЯжБрвыЁЂжДааЕШЙ§ГЬЃЌетИіЙ§ГЬжаашвЊгыRMЁЂNNНкЕуНЛЛЅЃЌЭЌЪБашвЊгыMetastoreНЛЛЛдЊЪ§ОнаХЯЂЁЃ
MetastoreЗўЮёжївЊЬсЙЉдЊЪ§ОнЯрЙиЕФAPIЃЌВЂЭЈЙ§hooksВхМўЪЕЯждЊЪ§ОнЭЌВНЁЂШЈЯоПижЦЁЂбЊдЕЩњГЩЁЂlifecycleБэЕШЙІФмЁЃ
MetastoreдЊЪ§ОнДцДЂдкMySQLЩЯЃЈЯпЩЯВЩгУRDSЃЉ,ЪЕМЪЪ§ОнДцДЂдкHDFSЩЯ
НсКЯЩЯЪіЕФМмЙЙЗжЮіЪсРэГіЧыЧѓСДТЗЩЯЕФЧПШѕвРРЕЃЌЮвУЧНЋHive вРРЕЕФЗўЮёЗжЮЊСНРрЃЌвЛРрЮЊЧПвРРЕЃЌМДЭъећжДааСДТЗЩЯБиаывЊНЛЛЅЕФзщМўЃЛвЛРрЮЊШѕвРРЕЃЌМДвьВНЕїгУЛђепЕїгУЪЇАмВЛЛсгАЯьжДаазДЬЌЕФзщМўЁЃ
ЧПвРРЕзщМўАќКЌЃКMySQLЁЂHDFS(NameNode)ЁЂYARN(ResourceManager)ЁЂZookeeper
ШѕвРРЕзщМўАќКЌЃКRangerAdminЁЂKafkaЁЂMongoDB
ЖдгкЧПвРРЕзщМўРДЫЕЃЌашвЊЙизЂЕїгУЪЇАмКѓШЮЮёЕФвьГЃЗДРЁМАЗўЮёвьГЃШежОЪЧЗёЧхЮњЃЌвдМАДѓХњСПЪЇАмЕФЧщПіЯТЖдЗўЮёдЫаазДЬЌЕФгАЯьМАЛжИДКѓШЮЮёжДааЪЧЗёЛжИДЁЃ
ШѕвРРЕзщМўЕФвьГЃвЛАуВЛЛсгАЯьШЮЮёЕФжДаазДЬЌЃЌЕЋЪЧашвЊЙизЂДѓХњСПЁЂГЄЪБМфжДааЕФЧщПіЯТЃЌвьГЃЪЧЗёЛсгАЯьЗўЮёЕФадФмЁЂзЪдДеМгУЃЌБШШчЪЧЗёЛсЕМжТЯпГЬГиТњЃЌЪЧЗёЛсГіЯжФкДцвчГіЕШЧщПіЁЃ
3 HiveЮШЖЈадВтЪдЪЕМљ
3.1 ВтЪдЛЗОГ
ВЮПМЯпЩЯЛЗОГЭиЦЫгыХфжУЃЌВтЪдЛЗОГвВВЩгУHiveserver2/MetastoreНкЕуЛьКЯВПЪ№ЕФЗНЪНЃЌhiveserver2/metastoreЗўЮёВПЪ№ЕФЛњЦїХфжУгыЯпЩЯВювьВЛДѓЃЈCPU
coresДцдкЧјБ№ЃЉЃЌжївЊЧјБ№дкгкЕзВуМЦЫуНкЕуЃЌЯпЩЯЖдНгЕФЮЊ970+ЕФМЦЫуНкЕуЃЌЖјЯпЯТНіга5НкЕуЃЌФмЙЛЪЙгУЕФМЦЫузЪдДЯрВюНЯДѓЃЌЪЕМЪВтЪдЪБашвЊМѕЩйMRРраЭSQLдЫааБШР§ЁЃ
гЩгкHiveserver2/Metastore ВПЪ№ЛњЦїгыЯпЩЯЛљБОвЛжТЃЌЫљвдЗўЮёЕФЯрЙиХфжУвВАДееЯпЩЯНјааСЫаоИФЃЌЙиМќХфжУЯюОљгыЯпЩЯБЃГжвЛжТЁЃ
3.2 бЙСІВтЪд
ВтЪдSQLГЁОА
гЩЩЯЪіЕФВтЪдЗжЮіПЩвдЕУЕНЃЌЮШЖЈадВтЪджаSQLГЁОАжївЊВЩгУвдЯТМИРрЃК
ЛљДЁSQLгяОфЃКАќКЌГЃЙцDDLЁЂDMLЁЂDQLгяОф
ВПЗжTPC-DS SQLГЁОА
РДдДгкЯпЩЯЬиЖЈгУЛЇГЁОАЕФSQLЃЌШчгУЛЇUDFЁЂИДдгЗжЧјЬѕМўЯТЕФБэВщбЏВйзїЁЃ
ЫљгаЕФSQLжДааОљзёбаТНЈБэЁЊЁЊ>жДааВтЪдSQLВйзїЁЊЁЊ>ЩОГ§БэВйзїЃЌвдБЃжЄбЙВтЙ§ГЬжаВЛЛсЛЅЯрИЩШХЁЃSQLГЁОАЙЙдьЙ§ГЬжаВЂУЛгаЭъШЋАДееЯпЩЯецЪЕSQLФЃФтЃЌЙЪЯпЯТбЙВтЪЙгУЕФSQLИДдгЖШПЩФмЛсаЁгкЯпЩЯЃЈгЩгкИДдгРрБ№ЕФSQLОљАщЫцзХMRШЮЮёЕФжДааЃЌВЂЧвМЦЫуНкЕуЕФзЪдДВЛзуЃЌВЛПЩФмЭъШЋгыЯпЩЯБЃГжвЛжТЃЉЃЌЮЊСЫЦНКтДЫРрЮЪЬтЃЌSQLГЁОАжаЪЕМЪМгШыСЫВПЗжTPC-DS
SQLЃЌЭЈЙ§ЕїећДЫРрИДдгSQLЕФБШР§РДДяЕНПижЦећЬхSQLИДдгЖШЕФФПБъЁЃ
ЭЈЙ§hiveserver2ЕФmetricsЕФcompile_apiЕФжИБъПЩвдПДЕНЕБЧАЛЈЗбдкБрвыЩЯЕФЦНОљКФЪБЃЌДЫжИБъЪЕМЪгыSQLЕФИДдгЖШЙвЙГЃЌПЩвдДѓжТПДГіSQLИДдгЖШЧщПіЃЌЭЈЙ§ЯТЭММрПиЪ§ОнЖдБШПЩвдПДЕНдкБрвыЦНОљКФЪБЩЯЃЌЯпЩЯгыЯпЯТЛљБОФмЙЛДяЕНвЛжТЁЃ
ЦЬЕзЪ§Он
гЩжЎЧАЕФЗжЮіЙ§ГЬПЩвдПДЕНЃЌетРяЕФЦЬЕзЪ§ОнАќКЌЃК
ЙиЯЕаЭЪ§ОнПтЃЈRDSЃЉЕФдЊЪ§Он
HDFSЩЯДцДЂЕФецЪЕЪ§Он
дЊЪ§ОнЕФЪ§ОнПтСПжївЊгАЯьMetastore APIЕФадФмЃЌетРяВЩгУСЫБШНЯМђЕЅДжБЉЕФЗНЪНЃЌжБНгНЋЯпЩЯМЏШКЕФдЊЪ§ОнЕМШыЮШЖЈадВтЪдЛЗОГзїЮЊЦЬЕзЁЃГ§СЫЦЬЕиЕФдЊЪ§ОнЭтЃЌашвЊИљОнбЙВтГЁОАжаЕФSQLЙЙдьЖдгІЕФдЊЪ§ОнЃЌетРяАќКЌШєИЩraw_tableМАtpcds-dsБэЁЃ
гЩгкHDFSМЏШКгыЯпЩЯЬхСПвРШЛВюОрОоДѓЃЌетРяКіТдСЫNNгЩгкЪ§ОнСПМЖВювьЕМжТЕФадФмВювьЃЌУЛгаеыЖдадЙЙдьHDFSЦЬЕиЪ§ОнЃЌЪЕМЪВтЪджаЪЙгУЕФЪ§ОнОљРДздгкTPC-DSЁЃ
СїСПЙЙдь
бЙВтЙЄОп
гЩгкВЂУЛгаСМКУМцШнДѓЪ§ОнШЯжЄЬхЯЕЕФадФмВтЪдЙЄОпЃЌетРявРШЛВЩгУJmeterРДЪЉбЙЃЌЭЈЙ§ПЊЗЂjmeterВхМўЕФЗНЪНЃЌЗтзАkerboresШЯжЄМАJDBCЧыЧѓЃЌВЂЭЈЙ§Jmeter
BashShell SamplerРДжДааЁЃ
ЭЈЙ§ЮЌЛЄЖрИіЯпГЬзщВЂЩшжУВЛЭЌВЂЗЂЯпГЬЪ§РДЩшжУВЛЭЌРраЭSQLЕФжДааБШР§ЁЃ
дкЗЧКуЖЈСїСПЕФЙЙдьЩЯЃЌВЩгУСЫJmeterЬсЙЉЕФUltimate Thread GroupВхМўРДЪЕЯжЃЌЭЈЙ§ЯпЩЯбЙСІФЃаЭЕФЗжЮіЃЌРДЙЙдьЮШЖЈадВтЪджаЪЙгУЕФСїСПЧњЯпЁЃ
бЙВтСїСП
ЭЈЙ§ЧАЮФЗжЮіЃЌHiveЮШЖЈадВтЪджаЕФСїСПОљашвЊРДдДгкЯпЩЯЃЌЪЕМЪдкВйзїЙ§ГЬжаЃЌдкКуЖЈСїСПГЁОАжаЃЌЮвУЧВЩгУЕФЮЊЯпЩЯЗхжЕСїСПЃЌЖјдкЗЧКуЖЈСїСПГЁОАжаЃЌЮвУЧЖдЯпЩЯ24аЁЪБЕФСїСПЪ§ОнЗжЮіКѓЃЌНјааНЈФЃЃЌВЂЭЈЙ§ЩЯЮФНщЩмЕФjmeterВхМўUltimate
Thread GroupРДНјааФЃФтЁЃ
ЪЕМЪВтЪдЙ§ГЬжаЃЌвВЗжБ№ЭЈЙ§МрПиЪ§ОнгыЯпЩЯНјааБШЖдЃЌжївЊДгЗўЮёЦїзЪдДЪЙгУТЪЁЂЗўЮёmetricsЪ§ОнжИБъЕШЗНУцРДХаЖЯЪЧЗёДяЕНЛђепНгНќЮШЖЈадВтЪдЕФбЙСІИКдиЁЃвдКуЖЈСїСПГЁОАжаЕФСЌНгЪ§жИБъРДОйР§ЃЌШчЯТЭМЫљЪОЁЃетРяПЩвдПДЕНЮШЖЈадВтЪджаСЌНгЪ§жИБъгыЯпЩЯЗхжЕСїСПЛљБОвЛжТЃЌНсКЯЗўЮёЦїФкДцзЪдДеМгУЧщПіДѓжТПЩвдПДГіСїСПЕФзЂШыЗћКЯдЄЦкЁЃ
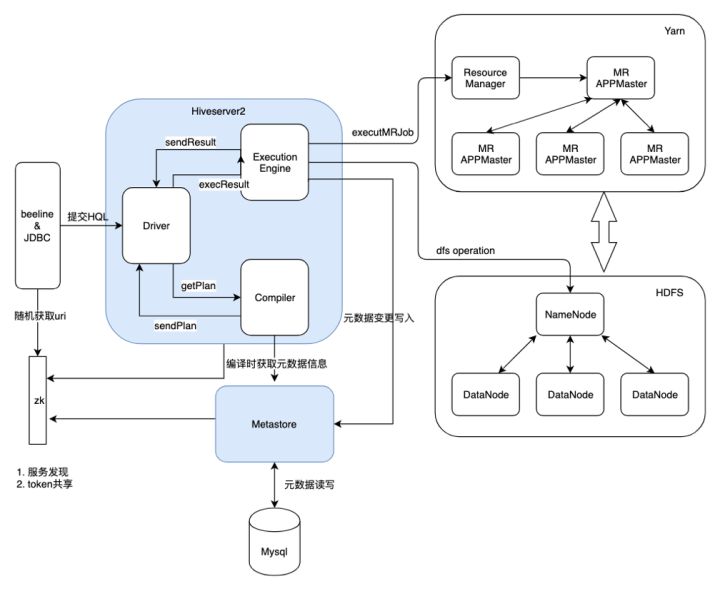
ЕБШЛДгКуЖЈСїСПЁЂЗЧКуЖЈСїСПГЁОАЯТЮвУЧОљПДЕНВПЗжМрПиЪ§ОнгыЯпЩЯДцдкВЛвЛжТЕФЧщПіЃЌШчCPU ЪЙгУТЪЯпЯТЭљЭљФмДяЕН70~80%зѓгвЃЌЕЋЯпЩЯжЛга15~25%зѓгвЃЌжївЊЮЪЬтвВдкгкЯпЯТВтЪдгЩгкПМТЧЕНМЏШКзЪдДЕФЮЪЬтЃЌМѕЩйСЫИДдгSQLЃЈАщЫцзХДѓСПМЦЫузЪдДЕФЯћКФЃЉЕФБШР§ЃЌДЫРрSQLдкЬсНЛMRжДааКѓМДДІгкЕШД§ШЮЮёНсЪј/ЕїЖШЬсНЛMRШЮЮёЕФНзЖЮЃЌвђДЫЛсгазХНЯЕЭЕФCPUЯћКФЁЃ
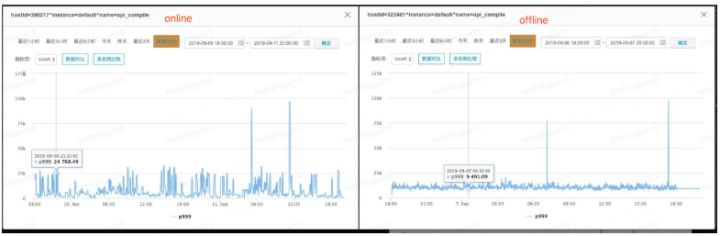
ашвЊЫЕУїЕФвЛЕуЪЧЃЌMetastoreЕФЗўЮёбЙСІЭљЭљБШHiveserver2вЊДѓЃЌВтЪдЛЗОГдкФЃФтЪБЃЌЫљгаЕФСїСПШыПкОљЪЧHiveserver2ЃЌвђДЫЮЊСЫБЃжЄMetastoreЕФбЙСІИКдиЃЌетРяЕФСїСПЪ§ОнВЩгУЕФОљЮЊMetastoreЗўЮёЕФЯпЩЯЗхжЕЪ§ОнЁЃ
3.3 вьГЃзЂШы
ЧАЮФЕФЗжЮіЙ§ГЬжаЃЌЮвУЧвбОИљОнHiveЕФПђМмМАСДТЗДѓжТЪсРэСЫЗўЮёЕФЧПШѕвРРЕЃЌдкЮШЖЈадВтЪдЕФКѓајНзЖЮЃЌЮвУЧвВНЋетВПЗжвьГЃИЩШХМгШыЕНЮШЖЈВтЪджДаажаЁЃ
ЙЪеЯзЂШыЕФЪжЖЮетРяВЛдйзИЪіЃЌЮвУЧВЩгУЕФЮЊЭјвзКМбаQAзщПЊЗЂЕФХЭЪЏЙЪеЯбнСЗЦНЬЈЃЌвЛМќЛЏЕФЙЪеЯзЂШыМАадФмжИБъЪеМЏвВБугкКѓајЕФЗжЮіМАИДгУЁЃ
дкзЂШыЙЪеЯЕФРрБ№ЩЯЃЌвРРЕзщМўжївЊДгЗўЮёЭъШЋВЛПЩгУЁЂЗўЮёЧыЧѓбгЪБСНИіЗНУцРДНјааФЃФтЃЌЗўЮёВЛПЩгУПЩвдДгвРРЕзщМўЕФНјГЬвьГЃРДНјааФЃФтЃЌШчНјГЬЧПЩБЁЂНјГЬМйЫРЁЃЗўЮёЧыЧѓбгГйЕФдвђПЩФмгаСНЕуЃЌвЛЪЧвРРЕзщМўЕФадФмвьГЃЛђепДцдкадФмЦПОБЃЈПЩвдЭЈЙ§JVMзЂШывьГЃРДФЃФтЃЉЃЌЖўЪЧГіЯжЭјТчбгГйЕФЧщПіЃЌвдЩЯвьГЃГЁОАОљПЩвдЭЈЙ§ХЭЪЏЦНЬЈРДНјаазЂШыЁЃ
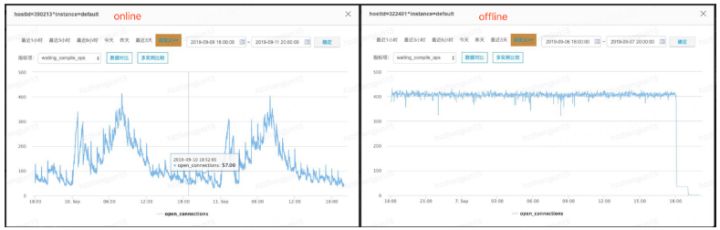
вдвРРЕзщМўNameNodeЮЊР§ЃЌзЂШыЯьгІбгГйвьГЃЃЈЭЈЙ§ЭјТчбгГйРДФЃФтЃЉЃЌЩшжУбгГйЪБМфЮЊ3sЃЈСЌНгГЌЪБЪБМфФЌШЯЮЊ150sЃЉЃЌЕБзЂШывьГЃКѓЃЌHiveSQLЯьгІЪБМфЮДГіЯжУїЯдЯТНЕЃЌЕЋЪЧЫцзХЖјРДЕФЪЧMetastoreСЌНгЪ§ЕФЭЛдіЃЌЕБвьГЃЛжИДКѓЃЌСЌНгЪ§вРШЛЮоЗЈЪЭЗХЃЌвЛЕЉДяЕНMetastoreЩшжУЕФmax
connectionЪ§ЃЌдђЛсв§ЗЂгУЛЇЧыЧѓжБНгБЛХзЦњЃЌгУЛЇШЮЮёЪЇАмЁЃ
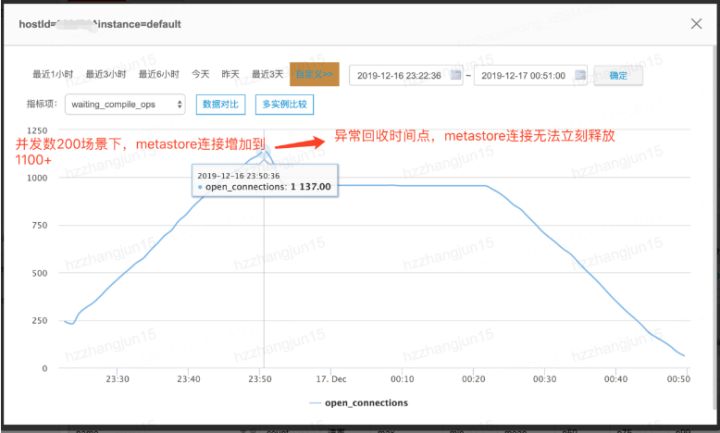
ЭЈЙ§ЖдДЫЪТЕФЖбеЛНјааНјааЗжЮіКѓЗЂЯжЃЌСЌНгЙиБеЪБОљашвЊЕїгУNN apiШЅЩОГ§ДцдкгкHDFSЩЯЕФСйЪБЪ§ОнЃЌЕБЭјТчГіЯжбгГйЛђепNNадФмЦПОБЪБЃЌдђЛсГіЯжЖТШћЃЌЕМжТСЌНгЮоЗЈЪЭЗХЁЃгЩгкHiveЩчЧјМмЙЙЮЪЬтЃЌДЫРрЮЪЬтЭљЭљВЛЛсжБНгаоИДЃЌЖјЧвВЩгУдЄАИЕФЗНЪННјааДІРэЃЌМДЕБNNадФмЛжИДКѓЃЌШчдк30sФкСЌНгЪ§вРШЛЮоЗЈЯТНЕжСдЄЦкжЕЃЌдђжиЦєMetastoreЗўЮёЃЌДгЖјПижЦгЩгкДЫРрЮШЖЈадЮЪЬтДјРДЕФSLA
Ы№ЪЇЁЃ
3.4 ЮШЖЈадВтЪдНсЙћЕФЦРЙР
ЩЯЮФжавбОЬИЕНСЫHiveЮШЖЈадВтЪдЕФЗжЮіМАДѓжТЕФЪЕМљЙ§ГЬЃЌФЧУДШчКЮШЅЦРЙРЮШЖЈадВтЪдЪЧЗёЭЈЙ§ФиЃП
ЖдгкHiveЗўЮёРДЫЕжївЊДгвдЯТМИИіЗНУцРДХаЖЯЃК
TPCЁЂЯьгІЪБМфЕФВЈЖЏЧщПіЃЌдкКуЖЈбЙСІВтЪдНзЖЮЃЌРэТлЩЯРДЫЕбЙВтЕФTPCМАЯьгІЪБМфЕФВЈЖЏЗЖЮЇгІИУНЯаЁЃЌШчГіЯжВЈЖЏНЯДѓЕФЧщПіЃЌМДашвЊНсКЯЦфЫћЗўЮёжИБъНјааЗжЮіШЗШЯЃЛ
ЗўЮёзЪдДеМгУЃКетРяжївЊЭЈЙ§ФкДцзЪдДРДНјааХаЖЯЃЌашвЊМьВщЪЧЗёДцдкФкДцаЙТЖЕФЧщПіЃЌСэЭтЭЈЙ§ЩкБјЕФGCМрПивВФмЙЛПДЕНGCМАФкДцЪЙгУТЪЗНУцЪ§ОнЪЧЗёДцдквьГЃЃЌШчГіЯжЦЕЗБFullGCЛђепFullGCКѓзЪдДЮоЗЈЪЭЗХЃЌдђвВашвЊХаЖЯЪЧЗёДцдкФкДцаЙТЖЮЪЬтЁЃ
ЗўЮёMetricsжИБъЃЌЕУвцгыHiveбгајЖрФъЕФЩчЧјПЊЗЂЛюдОЖШЃЌHiveЕФMetricsЪ§ОнвВНЯЮЊНЁШЋЃЌПЩвдЭЈЙ§ЗўЮёжИБъЕФВЈЖЏРДбщжЄЪЧЗёДцдкЮШЖЈадЮЪЬтЃЌШчhiveserver2/metastoreЗўЮёЕФopen_connectionЪ§ЃЌНсКЯЕБЧАЕФВЂЗЂЪ§ЃЌПЩвдХаЖЯЪЧЗёДцдкСЌНгаЙТЖЕШЮЪЬтЁЃ
Г§ДЫжЎЭтЃЌДѓЪ§ОндЫЮЌМрПиЦНЬЈ(smilodone)вВЬсЙЉСЫзМЪЕЪБЕФHiveSQLЗжЮіЯЕЭГЃЌПЩвдЭЈЙ§ЖдвьГЃSQLжДааЕФШежОНјааЗжЮіЃЌМЬЖјХаЖЯЪЧЗёгыЗўЮёЕФЮШЖЈадЯрЙиЁЃ
ЮвУЧФПЧАвбОНЋЮШЖЈадВтЪдФЩШыHiveАцБОЕќДњЕФзМГіБъзМжЎжаЃЌЕЋВЂЗЧдкУПИіАцБОжаОљОРњЩЯЮФЬИЕНЕФЮШЖЈВтЪдЕФМИИіНзЖЮЃЈКуЖЈСїСПНзЖЮЁЂЗЧКуЖЈСїСПНзЖЮЁЂМАвьГЃИЩШХзЂШыНзЖЮЃЉЁЃдкШеГЃЮЌЛЄАцБОПМТЧЕНИќаТгАЯьМАЕќДњЪБМфЃЌЭљЭљжЛЛсНјаа3*24аЁЪБЕФКуЖЈСїСПбЙСІВтЪдЃЌЕБГіЯжКЫаФБрвыЦїИќаТЛђЩчЧјДѓАцБОИќаТЪБЃЌдђЛсдкЪБМфГфдЃЕФЧАЬсЯТЃЌНЋЩЯЪіШ§ИіНзЖЮОЁЪ§ЭъГЩЃЌвбИќМгГфЗжЕФЦРХаЗўЮёЕФЮШЖЈадЪЧЗёДяБъЁЃ
4. ЮШЖЈадВтЪдзмНсМАеЙЭћ
НсКЯHiveЕФЮШЖЈадВтЪдЪЕМљЃЌЗЂЯжЕФЮЪЬтжиЕуМЏжадквдЯТМИИіЗНУцЃК
ЯЕЭГЮЪЬтЃКЯЕЭГХфжУв§ЗЂЕФЗўЮёЮШЖЈадЮЪЬтЃЌШчВйзїЯЕЭГЕФзюДѓНјГЬЪ§ЁЂзюДѓОфБњЪ§ЕШ
вРРЕЗўЮёЮЪЬтЃКвРРЕЗўЮёЕФадФмЮЪЬтв§ЗЂHiveЗўЮёадФмНЕЕЭЃЌШчNNадФмЦПОБДјРДЕФHiveЯьгІЪБМфдіМгЁЂСЌНгЮоЗЈЪЭЗХЃЛ
ЗўЮёРЉеЙДјРДЕФВЛПЩПиЮЪЬтЃКШчбЊдЕВхМўДјРДЕФФкДцаЙТЖЮЪЬтЁЂUDFв§ЗЂЕФЗўЮёхДЛњЮЪЬтЁЃ
ЬиЖЈSQLГЁОАв§ЗЂЕФФкДцаЙТЖЮЪЬтЃКШчАйЭђМЖЗжЧјГЁОАЯТЕФВщбЏВйзїв§ЗЂЗўЮёФкДцаЙТЖЮЪЬтЁЃ
ЖдгкЮШЖЈадВтЪджаЗЂЯжЕФЮЪЬтВЂВЛвЛЖЈФмЙЛЭЈЙ§ДњТыЪжЖЮРДНјаааоИДЃЌР§ШчЖдгкПЊдДАцБОвХСєЕФМмЙЙЮЪЬтЃЌвђЮЊДЫРрЮЪЬтЩцМАЕФИФЖЏЭљЭљНЯДѓЃЌЧЃвЛЗЂЖјЖЏШЋЩэЃЌаоИДЮЪЬтДјРДЕФВЛПЩдЄжЊадКѓајЮЌЛЄЕФГЩБОПЩФмИќИпЁЃ
ФЧУДШчКЮРДгІЖдЯпЩЯПЩФмДцдкЕФДЫРрвбжЊЗчЯеФиЃПЮвУЧЭЈЙ§СЊКЯSREЁЂПЊЗЂвЛЦ№ЭЦЖЏдЄАИЁЂМрПиЪжЖЮЕФЭъЩЦЃЌдкhiveзщМўВуУцзіЕНЫљгаЕФЯпЩЯвбжЊЗчЯеОљгагІЖддЄАИЃЌВЂЧвСЊКЯПЊЗЂЃЈЯпЩЯЙЪеЯЕФДІРэШЫЃЉдкЯпЯТНјааЖЈЦкЕФдЄАИбнСЗЃЌВЛЖЯЭъЩЦМрПиЗНАИМАПЊЗЂгІЖдЙЪеЯДІРэЕФаЇТЪЁЃ
ДгГЄдЖРДПДЃЌЯпЯТЕФбнСЗбщжЄжЛЪЧЕквЛВНЃЌЯпЩЯбнСЗВХЪЧзюжеФПБъЃЌКѓајЮвУЧЛсж№ВНЭЦНјЯпЩЯбнСЗЃЌж№ВНЭъЩЦВЙГфПЩФмДцдкЕФЙЪеЯдЄАИЃЌВЂЭЈЙ§ЯпЩЯбнСЗЕФЗНЪНРДНјвЛВНЭЦЙудЄАИЕФгааЇадЁЃ
ДгЯпЯТЮШЖЈадВтЪдЕФНЧЖШГіЗЂЃЌКѓајЕФИФНјжївЊДгвдЯТШ§ИіЗНЯђЃЌвЛЪЧВтЪдгааЇадЕФЬсЩ§ЃЌГжајЕФРЉГфгУЛЇГЁОАЁЂЙЪеЯбљБОЃЌвдЦкФмЙЛИќМгЬљНќЯпЩЯецЪЕГЁОАЃЛЖўЪЧВтЪдаЇТЪЕФЬсИпЃЌгХЛЏбЙВтНХБОМАЙЪеЯзЂШыЙЄОпЃЌвдМѕЩйШЫЙЄИЩдЄЕФГЩБОЃЛШ§ЪЧДгВтЪдЗжЮіЮЌЖШЃЌШчКЮИќМгжЧФмЛЏЕФЦРЙРЯЕЭГЕФЮШЖЈадЁЂШчКЮИќОЋзМЖШЕФЗжЮіЖЈЮЛЮЪЬтЃЌНЋЪЧКѓајКмГЄвЛЖЮЪБМфЕФбаОПФПБъЁЃ
|









