| БрМЭЦМі: |
БОЮФжївЊНВНтСЫHiveМмЙЙЁЂHiveЕФМИжжНЈБэЗНЪНЁЂHiveЕФЪ§ОнРраЭЁЂФкВПБэКЭЭтВПБэЁЂHiveЕФбЯИёФЃЪНКЭЗЧбЯИёФЃЪНЁЂHive
JOINЕШЕШЯрЙиФкШнЁЃ
БОЮФРДздгкЮЂаХДѓЪ§ОнбЇЯАгыЗжЯэЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Apache HiveЪЧЛљгкHadoopЕФвЛИіЪ§ОнВжПтЙЄОпЃЌПЩвдНЋНсЙЙЛЏЕФЪ§ОнЮФМўгГЩфЮЊвЛеХЪ§ОнПтБэЃЌВЂЬсЙЉвЛжжHQLгябдНјааВщбЏЃЌОпгаРЉеЙадКУЁЂбгеЙадКУЁЂИпШнДэЕШЬиЕуЃЌЖргІгУгкРыЯпЪ§ВжНЈЩшЁЃ
1. HiveМмЙЙ
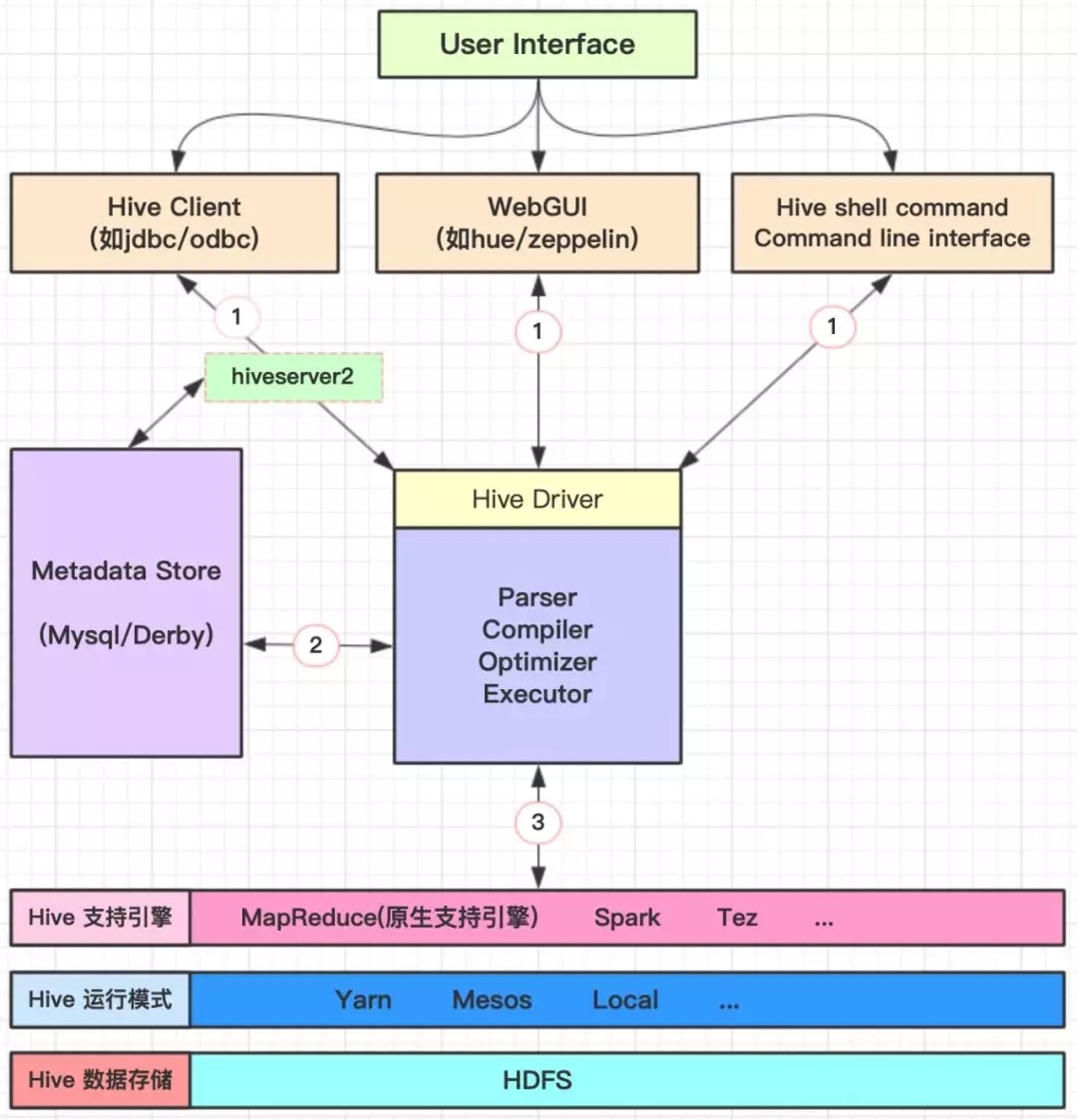
ДцДЂЃКHiveЕзВуДцДЂвРРЕгкhdfsЃЌвђДЫвВжЇГжhdfsЫљжЇГжЕФЪ§ОнДцДЂИёЪНЃЌШчtextЁЂjsonЁЂparquetЕШЁЃЕБЮвУЧНЋвЛИіЮФМўгГЩфЮЊHiveжавЛеХБэЪБЃЌжЛашдкНЈБэЕФЪБИцЫпHiveЃЌЪ§ОнжаЕФСаУћЁЂСаЗжИєЗћЁЂааЗжИєЗћЕШЃЌHiveОЭПЩвд
здЖЏНтЮіЪ§ОнЁЃ
жЇГжЖржжбЙЫѕИёЪНЃКbzip2ЁЂgzipЁЂlzoЁЂsnappyЕШЁЃЭЈГЃВЩгУparquet+snappyИёЪНДцДЂЁЃ
жЇГжМЦЫув§ЧцЃКдЩњжЇГжв§ЧцЮЊMapReduceЁЃЕЋвВжЇГжЦфЫћМЦЫув§ЧцЃЌШчSparkЁЂTez
дЊЪ§ОнДцДЂЃКderbyЪЧHiveФкжУЕФдЊЪ§ОнДцДЂПтЃЌЕЋЪЧderbyВЂЗЂадФмВюЧвФПЧАВЛжЇГжЖрЛсЛАЁЃЪЕМЪЩњВњжаЃЌИќЖрЕФЪЧВЩгУmysqlЖрЮЊHiveЕФдЊЪ§ОнДцДЂПтЁЃ
HQLгяОфжДааЃКНтЮіЦїЁЂБрвыЦїЁЂгХЛЏЦїЭъГЩHQLВщбЏгяОфДгДЪЗЈЗжЮіЁЂгяЗЈЗжЮіЁЂБрвыЁЂгХЛЏвдМАВщбЏМЦЛЎЕФЩњГЩЁЃЩњГЩЕФВщбЏМЦЛЎДцДЂдкhdfsжаЃЌВЂдкЫцКѓзЊЛЏЮЊMapReduceШЮЮёжДааЁЃ
2.HiveЕФМИжжНЈБэЗНЪН
1ЃЉcreate [external] table ...
create [external]
table [if not exists] table_name
[(col_name data_type[comment col_comment],...)]
[comment table_comment]
[partitioned by (col_name data_type[comment
col_comment],...)]
[clustered by (col_name,col_name,...)
[sorted by (col_name[asc|desc],...)] into num_buckets
buckets]
[row formatrow_format]
[stored as file_format]
[location hdfs_path];
|
createЁЂif not existsЕШИњДЋЭГЕФЙиЯЕаЭЪ§ОнПтКЌвхРрЫЦЃЌОЭВЛзИЪіСЫЁЃБЪепетРяжївЊЫЕвЛЯТhiveНЈБэЪБЕФМИИіЬиЪтЙиМќзжЃК
externalЃКДДНЈЭтВПБэЪБашвЊжИЖЈИУЙиМќзжЃЌВЂЭЈЙ§locationжИЖЈЪ§ОнДцДЂЕФТЗОЖ
partitioned byЃКДДНЈЗжЧјБэЪБЃЌжИЖЈЗжЧјСаЁЃ
clustered byКЭsort byЃКЭЈГЃСЌгУЃЌгУРДДДНЈЗжЭАБэЃЌЯТЮФЛсОпЬхВћЪіЁЃ
row format delimited [fields terminated by char]
[collection items terminated by char] [map keys terminated
by char] [lines terminated by char] serde serde_name
[with serdeproperties (property_name=property_value,
property_name=property_value, ...)]ЃКжИЖЈааЁЂзжЖЮЁЂМЏКЯРраЭЪ§ОнЗжИюЗћЁЂmapРраЭЪ§ОнkeyЕФЗжИєЗћЕШЁЃгУЛЇдкНЈБэЕФЪБКђПЩвдЪЙгУHiveздДјЕФserdeЛђепздЖЈвхserdeЃЌHiveЭЈЙ§serdeШЗЖЈБэОпЬхСаЕФЪ§ОнЁЃ
stored as file_formatЃКжИЖЈБэЪ§ОнДцДЂИёЪНЃЌШчTextFileЃЌSequenceFileЃЌRCFileЁЃФЌШЯtextfileМДЮФБОИёЪНЃЌИУЗНЪНжЇГжЭЈЙ§loadЗНЪНМгдиЪ§ОнЁЃШчЙћЪ§ОнашвЊбЙЫѕЃЌдђВЩгУsequencefileЗНЪНЃЌЕЋетжжДцДЂЗНЪНВЛФмЭЈЙ§loadЗНЪНМгдиЪ§ОнЃЌБиаыДгвЛИіБэжаВщбЏГіЪ§ОндйаДШыЕНвЛИіБэжаinsert
overwrite table t1 select * from t1;
2ЃЉ create table t_x as select ...
МДctasгяОфЃЌИДжЦЪ§ОнЕЋВЛИДжЦБэНсЙЙЃЌДДНЈЕФЮЊЦеЭЈБэЁЃШчЙћИДжЦЕФЪЧЗжЧјБэдђаТДДНЈЕФВЛЪЧЗжЧјБэЕЋгаЗжЧјзжЖЮЁЃ
ctasгяОфЪЧдзгадЕФЃЌШчЙћselectЪЇАмЃЌНЋВЛдйжДааcreateВйзїЁЃ
3ЃЉ create table t_x like t_y
likeдЪаэгУЛЇИДжЦдДБэНсЙЙЃЌЕЋВЛИДжЦЪ§ОнЁЃШчЃЌcreate table t2 like t1;
3.HiveЕФЪ§ОнРраЭ
HiveФкжУЪ§ОнРраЭжївЊЗжЮЊСНРрЃКЛљДЁЪ§ОнРраЭКЭИДдгЪ§ОнРраЭЁЃЛљДЁЪ§ОнРраЭЮоЭтКѕОЭЪЧtinyintЁЂsmallintЁЂintЁЂbigintЁЂbooleanЁЂfloatЁЂdoubleЁЂstringЁЂtimestampЁЂdecimalЕШЃЌБЪепетРяжївЊНщЩмHiveЕФИДдгЪ§ОнРраЭЃЌЛђепГЦжЎЮЊМЏКЯРраЭЁЃ
HiveЕФИДдгЪ§ОнРраЭжївЊЗжШ§жжЃКmapЁЂarrayЁЂstructЃЌВЂЧвжЇГжИДдгРраЭЧЖЬзЃЌРћгУКУетаЉЪ§ОнРраЭЃЌНЋгааЇЬсИпЪ§ОнВщбЏаЇТЪЁЃФПЧАЮЊжЙЖдгкЙиЯЕаЭЪ§ОнПтВЛжЇГжетаЉИДдгРраЭЁЃ
1.ЪзЯШДДНЈвЛеХБэ
create table
t_complex(id int,
hobby1 map<string,string>,
hobby2 array<string>,
address struct<country:string,city:string>)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;
|
2.зМБИЪ§ОнЮФМў
1,ГЊИш:вЛАу-ЬјЮш:ЯВЛЖ-гЮгО:ВЛЯВЛЖ,ГЊИш-ЬјЮш-гЮгО,USA-New York
2,ДђгЮЯЗ:ВЛЯВЛЖ-бЇЯА:ЗЧГЃЯВЛЖ,ДђгЮЯЗ-РКЧђ,CHINA-BeiJing
3.НЋЪ§ОнЮФМўloadЕНДДНЈЕФБэжа
load data local inpath '/root/complex.txt' into table
t_complex;
4.ВщбЏmapЁЂarrayЁЂstructРраЭЪ§Он
ВщбЏmapКЭarrayИњjavaжаЪЧРрЫЦЕФЃЌЖМЪЧЭЈЙ§keyВщевmapЕФvalueЛђепИљОнЫїв§ВщевarrayжаЕФдЊЫиЃЌЖјstructдђЭЈЙ§СаУћ.БъЪЖРДЗУЮЪдЊЫиЁЃ
ВщбЏmapЪОР§ЃКselect hobby1['ГЊИш'] from t_complex;
ВщбЏarrayЪОР§ЃКselect hobby2[0], hobby2[1] from t_complex;
ВщбЏstructЪОР§ЃКselect address.country, address.city from
t_complex;
4.ФкВПБэКЭЭтВПБэ
HiveдкДДНЈБэЪБФЌШЯДДНЈЕФЪЧФкВПБэЃЈгжГЦЭаЙмБэЃЉЁЃЕБжИЖЈexternalЙиМќзжЪБЃЌдђДДНЈЕФЮЊЭтВПБэЁЃВЂПЩвдЭЈЙ§locationжИЖЈНЈБэЕФЪ§ОнДцДЂЕФhdfsТЗОЖЁЃ
HiveДДНЈФкВПБэЪБЃЌЛсНЋЪ§ОнИДжЦ/вЦЖЏЕНЪ§ОнВжПтжИЯђЕФТЗОЖЃЛШєДДНЈЭтВПБэЃЌНіМЧТМЪ§ОнЫљдкТЗОЖЃЌВЛЖдЪ§ОнЮЛжУзіШЮКЮИФБфЁЃдкЩОГ§БэЪБЃЌФкВПБэЕФдЊЪ§ОнКЭБэЪ§ОнЖМЛсБЛЩОГ§ЃЌЖјЭтВПБэжЛЩОГ§дЊЪ§ОнЃЌВЛЩОГ§БэЪ§ОнЁЃ
НЈвщдкЩњВњжаДДНЈHiveБэЪБВЩгУЭтВПБэЕФЗНЪНЃЌетбљдкЗЂЩњЮѓЩОБэЕФЪБЃЌВЛжСгкАбБэЪ§ОнвВЩОГ§ЃЌРћгкЪ§ОнЛжИДКЭАВШЋЁЃЕБШЛвВПЩвдАДееЯТЪіЧщПізіЯИЗжДІРэЃК
1ЃЉЫљгаЪ§ОнДІРэЃЌШЋВПгЩhiveЭъГЩЃЌЪЪКЯгУФкВПБэ
2ЃЉгаhiveКЭЦфЫћЙЄОпЙВЭЌДІРэвЛИіЪ§ОнМЏМДЭЌвЛЪ§ОнМЏгаЖрИігІгУвЊДІРэЃЌЪЪКЯгУЭтВПБэ
3ЃЉДгhiveжаЕМГіЪ§ОнЃЌЙЉЦфЫћгІгУЪЙгУЃЌЪЪКЯгУЭтВПБэ
4ЃЉЦеБщгУЗЈЃКГѕЪМЪ§ОнМЏгЩЭтВПБэВйзїЃЌЪ§ОнЗжЮіжаМфБэЪЙгУФкВПБэ
5.order/sort/distribute/cluster by
order byЃКЛсНЋЫљгаЕФЪ§ОнЛуОлЕНвЛИіreduceЩЯШЅжДааЃЌШЛКѓФмБЃжЄШЋОжгаађЁЃЕЋЪЧаЇТЪЕЭЃЌвђЮЊВЛФмВЂаажДаа
sort byЃКЕБЩшжУmapred.reduce.tasks>1ЃЌдђsort byжЛБЃжЄУПИіreducerЕФЪфГігаађЃЌВЛБЃжЄШЋОжгаађЁЃКУДІЪЧЃКжДааСЫОжВПХХађжЎКѓПЩвдЮЊНгЯТШЅЕФШЋОжХХађЬсИпВЛЩйЕФаЇТЪЃЈЦфЪЕОЭЪЧзівЛДЮЙщВЂХХађОЭПЩвдзіЕНШЋОжХХађЁЃ
distribute byЃКИљОнжИЖЈЕФзжЖЮНЋЪ§ОнЗжЕНВЛЭЌЕФreduceЃЌЧвЗжЗЂЫуЗЈЪЧhashЩЂСаЁЃФмБЃжЄУПвЛИіreduceИКд№ЕФЪ§ОнЗЖЮЇВЛжиЕўСЫЃЌЕЋЪЧВЛБЃжЄХХађЕФЮЪЬтЁЃ
cluster byЃКГ§СЫОпгаdistribute byЕФЙІФмЭтЃЌЛЙЛсЖдИУзжЖЮНјааХХађЁЃ
жЛгавЛИіreduceЪБЃЌcluster byаЇЙћВЛУїЯдЃЌПЩвджДааset mapred.reduce.tasks>1РДЪЙаЇЙћУїЯдЁЃ
ЕБзжЖЮЯрЭЌЪБЃЌcluster byаЇЙћЕШЭЌгкdistribute by+sort byЁЃ
зЂвтЃКcluster КЭ sort дкВщбЏ(select)ЪБВЛФмЙВДцЃЌНЈБэЪБПЩвдЙВДц
6. HiveжаЕФЗжЧјЁЂЗжЭАвдМАЪ§ОнГщбљ
ЖдHiveБэНјааЗжЧјЁЂЗжЭАЃЌПЩвдЬсИпВщбЏаЇТЪЃЌГщбљаЇТЪ
6.1ЗжЧј
ЗжЧјЃЌдкhdfsжаБэЯжЮЊtableФПТМЯТЕФзгФПТМ
6.2ЗжЭА
ЖдгІНЈБэЪБbucketЙиМќзжЃЌдкhdfsжаБэЯжЮЊЭЌвЛИіБэФПТМЯТИљОнhashЩЂСажЎКѓЕФЖрИіЮФМўЃЌЛсИљОнВЛЭЌЕФЮФМўАбЪ§ОнЗХЕНВЛЭЌЕФЭАжаЁЃ
ШчЙћЗжЭАБэЕМШыЪ§ОнУЛгаЩњГЩЖдгІЪ§СПЕФЮФМўЃЌПЩЭЈЙ§ШчЯТЗНЪННтОіЃК
1.ПЊЦєздЖЏЗжЭАЃЌЩшжУВЮЪ§ЃКset hive.enforce.bucketing= true
2.ЪжЖЏЩшжУreduceЪ§СПЃЌБШШчset mapreduce.job.reduces=4ЁЃНЈвщЖдгкЩшМЦБэгаЗжЭАашЧѓЪБЃЌПЊЦєздЖЏЗжЭАЁЃвђЮЊвЛЕЉreduceЪ§СПЩшжУДэСЫЃЌЙцЛЎЕФЗжЭАЪ§ЛсЮоаЇЁЃ
зЂвтЃКвЊгУinsertгяОфЛђепctasгяОфНЋЪ§ОнДцШыЗжЭАБэЁЃloadгяОфжЛЪЧЮФМўЕФвЦЖЏЛђИДжЦЁЃ
6.3 ГщбљЃЈsamplingЃЉ
6.3.1 АДПщГщбљ
1ЃЉАйЗжБШ
| select * from
some_table tablesample(40 percent);
|
2ЃЉАДДѓаЁ
| select * from
some_table tablesample(20M); |
3ЃЉАДееааЪ§ШЁбљ
| select * from
some_table tablesample(1000 rows); |
6.3.2 АДЭАГщбљ
ЦфЪЕОЭЪЧЖдЗжЭАБэНјааГщбљЃЌаЇТЪИпЁЃ
ГщбљЪ§ОнСП=змЪ§ОнСП/ГщбљЗжЭАЪ§ЁЃ
ЪОР§ЃКselect count(1) from tableA Tablesample(bucket
2 out of 8 on user_id)ЃЛМДTablesample(bucket ПЊЪМШЁбљЕФЭА
out of ЗжГЩЖрЩйИіЭА)ЁЃ
ШчЙћвЊНјааГщбљЃЌНЈвщЃК
1.ШчЙћЬсЧАЗжЭАСЫЃЌБэЗжЭАЪ§гыГщбљЗжЭАЪ§вЛжТЃЌФЧУДжЛЛсЩЈУшФЧИіжИЖЈЭАЕФЪ§Он
2.ШчЙћдЄЯШЗжЭАКЭГщбљЗжЭАЪ§ВЛвЛжТЃКжиаТЗжЭА
3.ШчЙћУЛЗжЭАЃКЯШЗжЭАЃЌдкГщбљ
7.HiveЕФбЯИёФЃЪНКЭЗЧбЯИёФЃЪН
ЭЈЙ§ЩшжУВЮЪ§hive.mapred.modeРДЩшжУЪЧЗёПЊЦєбЯИёФЃЪНЁЃФПЧАВЮЪ§жЕгаСНИіЃКstrictЃЈбЯИёФЃЪНЃЉКЭnostrictЃЈЗЧбЯИёФЃЪНЃЌФЌШЯЃЉЁЃЭЈЙ§ПЊЦєбЯИёФЃЪНЃЌжївЊЪЧЮЊСЫНћжЙФГаЉВщбЏЃЈетаЉВщбЏПЩФмдьГЩвтЯыВЛЕНЕФЛЕЕФНсЙћЃЉЃЌФПЧАжївЊНћжЙ3жжРраЭЕФВщбЏЃК
1ЃЉЗжЧјБэВщбЏ
дкВщбЏвЛИіЗжЧјБэЪБЃЌБиаыдкwhereгяОфКѓжИЖЈЗжЧјзжЖЮЃЌЗёдђВЛдЪаэжДааЁЃ
вђЮЊдкВщбЏЗжЧјБэЪБЃЌШчЙћВЛжИЖЈЗжЧјВщбЏЃЌЛсНјааШЋБэЩЈУшЁЃЖјЗжЧјБэЭЈГЃгаЗЧГЃДѓЕФЪ§ОнСПЃЌШЋБэЩЈУшЗЧГЃЯћКФзЪдДЁЃ
2ЃЉorder by ВщбЏ
order byгяОфБиаыДјгаlimit гяОфЃЌЗёдђВЛдЪаэжДааЁЃ
вђЮЊorder byЛсНјааШЋОжХХађЃЌетИіЙ§ГЬЛсНЋДІРэЕФНсЙћЗжХфЕНвЛИіreduceжаНјааДІРэЃЌДІРэЪБМфГЄЧвгАЯьадФмЁЃ
3ЃЉЕбПЈЖћЛ§ВщбЏ
Ъ§ОнСПЗЧГЃДѓЪБЃЌЕбПЈЖћЛ§ВщбЏЛсГіЯжВЛПЩПиЕФЧщПіЃЌвђДЫбЯИёФЃЪНЯТвВВЛдЪаэжДааЁЃ
дкПЊЦєбЯИёФЃЪНЯТЃЌНјааЩЯЪіШ§жжВЛЗћКЯвЊЧѓЕФВщбЏЃЌЭЈГЃЛсБЈРрЫЦFAILED: Error in semantic
analysis: In strict mode, XXX is not allowed. If you
really want to perform the operation,+set hive.mapred.mode=nonstrict+
8.Hive JOIN
аДjoinВщбЏЪБЃЌашвЊзЂвтМИИіЙиМќЕуЃК
1ЃЉжЛжЇГжЕШжЕjoinЃЌвђЮЊЗЧЕШжЕСЌНгЗЧГЃФбзЊЛЏЮЊMapReduceШЮЮё
ЪОР§ЃКselect a.* from a join b on a.id = b.idЪЧе§ШЗЕФЃЌШЛЖј:select
a.* from a join b on a.id>b.idЪЧДэЮѓЕФЁЃ
2ЃЉПЩвдjoinЖрИіБэЃЌШчЙћjoinжаЖрИіБэЕФjoinЕФСаЪЧЭЌвЛИіЃЌдђjoinЛсБЛзЊЛЏЮЊЕЅИіMapReduceШЮЮё
ЪОР§ЃКselect a.*, b.*, c.* from a join b on a.col= b.col1
join c on c.col= b.col1БЛзЊЛЏЮЊЕЅИіMapReduceШЮЮёЃЌвђЮЊjoinжажЛЪЙгУСЫb.col1зїЮЊjoinСаЁЃ
ЕЋЪЧШчЯТаДЗЈЛсБЛзЊЛЏЮЊ2ИіMapReduceШЮЮёЁЃвђЮЊ b.col1гУгкЕквЛДЮjoinЬѕМўЃЌЖј b.col2гУгкЕкЖўДЮ
join
select a.*, b.*, c.* from a join b on a.col= b.col1
join c on c.col= b.col2;
3ЃЉjoinЪБЃЌзЊЛЛЮЊMapReduceШЮЮёЕФТпМ
reduceЛсЛКДцjoinађСажаГ§СЫзюКѓвЛИіБэЕФЫљгаБэЕФМЧТМЃЈОпЬхПДЦєЖЏСЫМИИіmap/reduceШЮЮёЃЉЃЌдйЭЈЙ§зюКѓвЛИіБэНЋНсЙћађСаЛЏЕНЮФМўЯЕЭГЁЃетвЛЪЕЯжгажњгкдкreduceЖЫМѕЩйФкДцЕФЪЙгУСПЁЃЪЕМљжаЃЌгІИУАбзюДѓЕФФЧИіБэаДдкзюКѓЃЈЗёдђЛсвђЮЊЛКДцРЫЗбДѓСПФкДцЃЉЁЃ
ЪОР§ЃК
a.ЕЅИіmap/reduceШЮЮё
select a.*, b.*, c.* from a join b on a.col= b.col1
join c on c.col= b.col1жаЫљгаБэЖМЪЙгУЭЌвЛИіjoinСаЁЃreduceЖЫЛсЛКДцaБэКЭbБэЕФМЧТМЃЌШЛКѓУПДЮШЁЕУвЛИіcБэЕФМЧТМОЭМЦЫувЛДЮjoinНсЙћЃЛ
b.ЖрИіmap/reduceШЮЮё
select a.*, b.*, c.* from a join b on (a.col= b.col1)
join c on (c.col= b.col2)ЁЃЕквЛДЮЛКДцaБэЃЌгУbБэађСаЛЏЃЛЕкЖўДЮЛКДцЕквЛДЮMapReduceШЮЮёЕФНсЙћЃЌШЛКѓгУcБэађСаЛЏЁЃ
4ЃЉleft semi join
ОГЃгУРДЬцЛЛ inКЭexistsЁЃ
ШчЃЌselect * from a left semi join b on a.id = b.id;
ЯрЕБгкselect * from a where a.id exists(select b.id from
b);ЕЋетжжЗНЪНдкhiveжааЇТЪМЋЕЭЁЃ
9.HiveжаЕФ3жжащФтСа
ЕБHiveВњЩњЗЧдЄЦкЕФЪ§ОнЛђnullЪБЃЌПЩвдЭЈЙ§ащФтСаНјааеяЖЯЃЌХаЖЯФФааЪ§ОнГіЯжЮЪЬтЃЌжївЊЗж3жжЃК
1.INPUT__FILE__NAME
УПИіmapШЮЮёЪфШыЮФМўУћ
2.BLOCK__OFFSET__INSIDE__FILE
mapШЮЮёДІРэЕФЪ§ОнЫљЖдгІЮФМўЕФПщФкЦЋвЦСПЃЌЕБЧАШЋОжЮФМўЕФЦЋвЦСПЁЃЖдгкПщбЙЫѕЮФМўЃЌОЭЪЧЕБЧАПщЕФЮФМўЦЋвЦСПЃЌМДЕБЧАПщЕФЕквЛИізжНкдкЮФМўжаЕФЦЋвЦСП
3.ROW__OFFSET__INSIDE__BLOCK
ааЦЋвЦСПЃЌФЌШЯВЛПЩгУЁЃашвЊЩшжУhive.exec.rowoffset=trueРДЦєгУ
10.HiveЬѕМўХаЖЯ
HiveжаПЩФмЛсгіЕНИљОнХаЖЯВЛЭЌжЕЃЌВњЩњЖдгІНсЙћЕФГЁОАЃЌгаШ§жжЪЕЯжЗНЪНЃКifЁЂcoalesceЁЂcase
whenЁЃ
1.if( condition, true value, false value)
жЛФмгУРДХаЖЯЕЅИіЬѕМўЁЃ
ЪОР§ЃКselect if(col_name='еХШ§',1,0) as xfrom tab;
2.coalesce( value1,value2,Ё )
ЛёШЁВЮЪ§СаБэжаЕФЪзИіЗЧПежЕЃЌШєОљЮЊnullЃЌдђЗЕЛиnullЁЃ
ЪОР§select coalesce(null,null,5,null,1,0) as x; ЗЕЛи5
3.case when
ПЩвдгыФГзжЖЮЖрИіБШНЯжЕЕФХаЖЯЃЌВЂЗжБ№ВњЩњВЛЭЌНсЙћЃЌгыЦфЫћгябджаcaseгяЗЈЯрЫЦЁЃ
select
case col_name
when "еХШ§" then 1
when "РюЫФ" then 0
else 2
end as x
from tab; |
ЛђЃК
select
case
when col_nameЃН"еХШ§" then 1
when col_nameЃН"РюЫФ" then 0
else 2
end as x
from tab; |
11.HiveгыДЋЭГЕФЙиЯЕаЭЪ§ОнПтЖдБШ
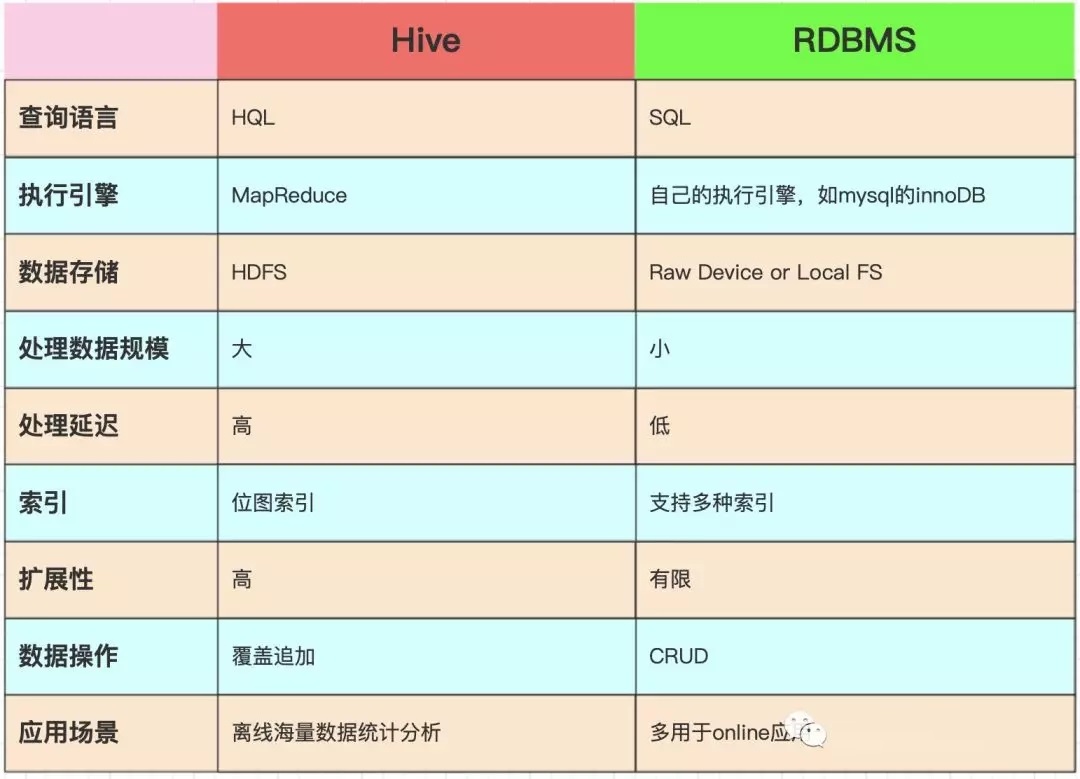 |









