| БрМЭЦМі: |
БОЮФНщЩмСЫ
Lambda МмЙЙЕФЛљБОИХФю,Lambda МмЙЙЭЈЙ§ЖдЪ§ОнКЭВщбЏЕФБОжЪШЯЪЖЃЌШкКЯСЫВЛПЩБфадЃЈImmunabilityЃЉЃЌЖСаДЗжРыКЭИДдгадИєРыЕШвЛЯЕСаМмЙЙддђЁЃ
БОЮФРДздЦЗИпдЦЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
етРявЊНВЕФ Lambda ЪЧвЛИіЪЕЪБДѓЪ§ОнДІРэПђМмЃЌЖјВЛЪЧ AWS
ЕФЭЌУћЗўЮёЃЌЕЋЪЧЦфжаЫљЧПЕїЕФШнДэадЁЂКсЯђРЉШнЁЂвзгкЮЌЛЄЕШЭЈгУаджЪЕФИХФюШДЪЧЖўепЖМОпБИЕФЃЌЖдгк AWS
Lambda ИааЫШЄЕФПЩвдПДВЉПЭЕФСэЭтвЛЦЊЮФеТЁЖServerless(ЮоЗўЮёЦї) МмЙЙШыУХ by LambdaЁЗЛђЗУЮЪ
AWS ЙйЗНСЫНтЁЃ
1.Lambda МмЙЙБГОАНщЩм
Lambda МмЙЙЪЧгЩ Storm ЕФзїеп Nathan Marz ЬсГіЕФвЛИіЪЕЪБДѓЪ§ОнДІРэПђМмЁЃMarz
дк Twitter ЙЄзїЦкМфПЊЗЂСЫжјУћЕФЪЕЪБДѓЪ§ОнДІРэПђМм StormЃЌLambda МмЙЙЪЧЦфИљОнЖрФъНјааЗжВМЪНДѓЪ§ОнЯЕЭГЕФОбщзмНсЬсСЖЖјГЩЁЃ
Lambda МмЙЙЕФФПБъЪЧЩшМЦГівЛИіФмТњзуЪЕЪБДѓЪ§ОнЯЕЭГЙиМќЬиадЕФМмЙЙЃЌАќРЈгаЃКИпШнДэЁЂЕЭбгЪБКЭПЩРЉеЙЕШЁЃLambda
МмЙЙећКЯРыЯпМЦЫуКЭЪЕЪБМЦЫуЃЌШкКЯВЛПЩБфадЃЈImmunabilityЃЉЃЌЖСаДЗжРыКЭИДдгадИєРыЕШвЛЯЕСаМмЙЙддђЃЌПЩМЏГЩ
HadoopЃЌKafkaЃЌStormЃЌSparkЃЌHbase ЕШИїРрДѓЪ§ОнзщМўЁЃ
2. ДѓЪ§ОнЯЕЭГЕФЙиМќЬиад
Marz ШЯЮЊДѓЪ§ОнЯЕЭГгІОпгавдЯТЕФЙиМќЬиадЃК
Robust and fault-tolerantЃЈШнДэадКЭТГАєадЃЉЃКЖдДѓЙцФЃЗжВМЪНЯЕЭГРДЫЕЃЌЛњЦїЪЧВЛПЩППЕФЃЌПЩФмЛсЕБЛњЃЌЕЋЪЧЯЕЭГашвЊЪЧНЁзГЁЂааЮЊе§ШЗЕФЃЌМДЪЙЪЧгіЕНЛњЦїДэЮѓЁЃГ§СЫЛњЦїДэЮѓЃЌШЫИќПЩФмЛсЗИДэЮѓЁЃдкШэМўПЊЗЂжаФбУтЛсгавЛаЉ
BugЃЌЯЕЭГБиаыЖдга Bug ЕФГЬађаДШыЕФДэЮѓЪ§ОнгазуЙЛЕФЪЪгІФмСІЃЌЫљвдБШЛњЦїШнДэадИќМгживЊЕФШнДэадЪЧШЫЮЊВйзїШнДэадЁЃЖдгкДѓЙцФЃЕФЗжВМЪНЯЕЭГРДЫЕЃЌШЫКЭЛњЦїЕФДэЮѓУПЬьЖМПЩФмЛсЗЂЩњЃЌШчКЮгІЖдШЫКЭЛњЦїЕФДэЮѓЃЌШУЯЕЭГФмЙЛДгДэЮѓжаПьЫйЛжИДгШЦфживЊЁЃ
Low latency reads and updatesЃЈЕЭбгЪБЃЉЃККмЖргІгУЖдгкЖСКЭаДВйзїЕФбгЪБвЊЧѓЗЧГЃИпЃЌвЊЧѓЖдИќаТКЭВщбЏЕФЯьгІЪЧЕЭбгЪБЕФЁЃ
ScalableЃЈКсЯђРЉШнЃЉЃКЕБЪ§ОнСП/ИКдидіДѓЪБЃЌПЩРЉеЙадЕФЯЕЭГЭЈЙ§діМгИќЖрЕФЛњЦїзЪдДРДЮЌГжадФмЁЃвВОЭЪЧГЃЫЕЕФЯЕЭГашвЊЯпадПЩРЉеЙЃЌЭЈГЃВЩгУ
scale outЃЈЭЈЙ§діМгЛњЦїЕФИіЪ§ЃЉЖјВЛЪЧ scale upЃЈЭЈЙ§діЧПЛњЦїЕФадФмЃЉЁЃ
GeneralЃЈЭЈгУадЃЉЃКЯЕЭГашвЊФмЙЛЪЪгІЙуЗКЕФгІгУЃЌАќРЈН№ШкСьгђЁЂЩчНЛЭјТчЁЂЕчзгЩЬЮёЪ§ОнЗжЮіЕШЁЃ
ExtensibleЃЈПЩРЉеЙЃЉЃКашвЊдіМгаТЙІФмЁЂаТЬиадЪБЃЌПЩРЉеЙЕФЯЕЭГФмвдзюаЁЕФПЊЗЂДњМлРДдіМгаТЙІФмЁЃ
Allows ad hoc queriesЃЈЗНБуВщбЏЃЉЃКЪ§ОнжадЬКЌгаМлжЕЃЌашвЊФмЙЛЗНБуЁЂПьЫйЕФВщбЏГіЫљашвЊЕФЪ§ОнЁЃ
Minimal maintenanceЃЈвзгкЮЌЛЄЃЉЃКЯЕЭГвЊЯызіЕНвзгкЮЌЛЄЃЌЦфЙиМќЪЧПижЦЦфИДдгадЃЌдНЪЧИДдгЕФЯЕЭГдНШнвзГіДэЁЂдНФбЮЌЛЄЁЃ
DebuggableЃЈвзЕїЪдЃЉЃКЕБГіЮЪЬтЪБЃЌЯЕЭГашвЊгазуЙЛЕФаХЯЂРДЕїЪдДэЮѓЃЌевЕНЮЪЬтЕФИљдДЁЃЦфЙиМќЪЧФмЙЛзЗИљЫндДЕНУПИіЪ§ОнЩњГЩЕуЁЃ
3. Ъ§ОнЯЕЭГЕФБОжЪ
ЮЊСЫЩшМЦГіФмТњзуЧАЪіЕФДѓЪ§ОнЙиМќЬиадЕФЯЕЭГЃЌЮвУЧашвЊЖдЪ§ОнЯЕЭГгаБОжЪадЕФРэНтЁЃЮвУЧПЩНЋЪ§ОнЯЕЭГМђЛЏЮЊЃК
Ъ§ОнЯЕЭГ = Ъ§Он + ВщбЏ
ДгЖјДгЪ§ОнКЭВщбЏСНЗНУцРДШЯЪЖДѓЪ§ОнЯЕЭГЕФБОжЪЁЃ
3.1. Ъ§ОнЕФБОжЪ
3.1.1. Ъ§ОнЕФЬиадЃКWhen & What
ЮвУЧЯШДг ЁАЪ§ОнЁБ ЕФЬиадЬИЦ№ЁЃЪ§ОнЪЧвЛИіВЛПЩЗжИюЕФЕЅЮЛЃЌЪ§ОнгаСНИіЙиМќЕФаджЪЃКWhen КЭ WhatЁЃ
When ЪЧжИЪ§ОнЪЧгыЪБМфЯрЙиЕФЃЌЪ§ОнвЛЖЈЪЧдкФГИіЪБМфЕуВњЩњЕФЁЃБШШч Log ШежООЭвўКЌзХАДееЪБМфЯШКѓЫГађВњЩњЕФЪ§ОнЃЌLog
ЧАУцЕФШежОЪ§ОнвЛЖЈЯШгк Log КѓУцЕФШежОЪ§ОнВњЩњЃЛЯћЯЂЯЕЭГжаЯћЯЂЕФНгЪмепвЛЖЈЪЧдкЯћЯЂЕФЗЂЫЭепЗЂЫЭЯћЯЂКѓНгЪеЕНЕФЯћЯЂЁЃЯрБШгкЪ§ОнПтЃЌЪ§ОнПтжаБэЕФМЧТМОЭЖЊЪЇСЫЪБМфЯШКѓЫГађЕФаХЯЂЃЌжаМфФГЬѕМЧТМПЩФмЪЧдкзюКѓвЛЬѕМЧТМВњЩњКѓЗЂЩњИќаТЕФЁЃЖдгкЗжВМЪНЯЕЭГЃЌЪ§ОнЕФЪБМфЬиадгШЦфживЊЁЃЗжВМЪНЯЕЭГжаЪ§ОнПЩФмВњЩњгкВЛЭЌЕФЯЕЭГжаЃЌЪБМфОіЖЈСЫЪ§ОнЗЂЩњЕФШЋОжЯШКѓЫГађЁЃБШШчЖдвЛИіжЕзіЫуЪѕдЫЫуЃЌЯШ+2ЃЌКѓ*3ЃЌгыЯШ*3ЃЌКѓ+2ЃЌЕУЕНЕФНсЙћЭъШЋВЛЭЌЁЃЪ§ОнЕФЪБМфаджЪОіЖЈСЫЪ§ОнЕФШЋОжЗЂЩњЯШКѓЃЌвВОЭОіЖЈСЫЪ§ОнЕФНсЙћЁЃ
What ЪЧжИЪ§ОнЕФБОЩэЁЃгЩгкЪ§ОнИњФГИіЪБМфЕуЯрЙиЃЌЫљвдЪ§ОнЕФБОЩэЪЧВЛПЩБфЕФ (immutable)ЃЌЙ§ЭљЕФЪ§ОнвбОГЩЮЊЪТЪЕЃЈFactЃЉЃЌФуВЛПЩФмЛиЕНЙ§ШЅЕФФГИіЪБМфЕуШЅИФБфЪ§ОнЪТЪЕЁЃетвВОЭвтЮЖзХЖдЪ§ОнЕФВйзїЦфЪЕжЛгаСНжжЃКЖСШЁвбДцдкЕФЪ§ОнКЭЬэМгИќЖрЕФаТЪ§ОнЁЃВЩгУЪ§ОнПтЕФМЧЗЈЃЌCRUD
ОЭБфГЩСЫ CRЃЌUpdate КЭ Delete БОжЪЩЯЦфЪЕЪЧаТВњЩњЕФЪ§ОнаХЯЂЃЌгУ C РДМЧТМЁЃ
3.1.2. Ъ§ОнЕФДцДЂЃКStore Everything Rawly and Immutably
ИљОнЩЯЪіЖдЪ§ОнБОжЪЬиадЕФЗжЮіЃЌLamba МмЙЙжаЖдЪ§ОнЕФДцДЂВЩгУЕФЗНЪНЪЧЃКЪ§ОнВЛПЩБфЃЌДцДЂЫљгаЪ§ОнЁЃ
ЭЈЙ§ВЩгУВЛПЩБфЗНЪНДцДЂЫљгаЕФЪ§ОнЃЌПЩвдгаШчЯТКУДІЃК
МђЕЅЁЃВЩгУВЛПЩБфЕФЪ§ОнФЃаЭЃЌДцДЂЪ§ОнЪБжЛашвЊМђЕЅЕФЭљжїЪ§ОнМЏКѓзЗМгЪ§ОнМДПЩЁЃЯрБШгкВЩгУПЩБфЕФЪ§ОнФЃаЭЃЌЮЊСЫ
Update ВйзїЃЌЪ§ОнЭЈГЃашвЊБЛЫїв§ЃЌДгЖјФмПьЫйевЕНвЊИќаТЕФЪ§ОнШЅзіИќаТВйзїЁЃ
ДгШнгІЖдШЫЮЊКЭЛњЦїЕФДэЮѓЁЃЧАЪіжаЬсЕНШЫКЭЛњЦїУПЬьЖМПЩФмЛсГіДэЃЌШчКЮгІЖдШЫКЭЛњЦїЕФДэЮѓЃЌШУЯЕЭГФмЙЛДгДэЮѓжаПьЫйЛжИДМЋЦфживЊЁЃВЛПЩБфадЃЈImmutabilityЃЉКЭжиаТМЦЫуЃЈRecomputationЃЉдђЪЧгІЖдШЫЮЊКЭЛњЦїДэЮѓЕФГЃгУЗНЗЈЁЃВЩгУПЩБфЪ§ОнФЃаЭЃЌв§ЗЂДэЮѓЕФЪ§ОнгаПЩФмБЛИВИЧЖјЖЊЪЇЁЃЯрБШгкВЩгУВЛПЩБфЕФЪ§ОнФЃаЭЃЌвђЮЊЫљгаЕФЪ§ОнЖМдкЃЌв§ЗЂДэЮѓЕФЪ§ОнвВдкЁЃаоИДЕФЗНЗЈОЭПЩвдМђЕЅЕФЪЧБщРњЪ§ОнМЏЩЯДцДЂЕФЫљгаЕФЪ§ОнЃЌЖЊЦњДэЮѓЕФЪ§ОнЃЌжиаТМЦЫуЕУЕН
ViewsЃЈView ЕФИХФюВЮПМ 4.1.2ЃЉЁЃжиаТМЦЫуЕФЙиМќЕудкгкРћгУЪ§ОнЕФЪБМфЬиадОіЖЈЕФШЋОжДЮађЃЌвРДЮЫГађжиаТжДааЃЌБиШЛФмЕУЕНе§ШЗЕФНсЙћЁЃ
ЕБЧАвЕНчгаКмЖрВЩгУВЛПЩБфЪ§ОнФЃаЭРДДцДЂЫљгаЪ§ОнЕФР§згЁЃБШШчЗжВМЪНЪ§ОнПт DatomicЃЌЛљгкВЛПЩБфЪ§ОнФЃаЭРДДцДЂЪ§ОнЃЌДгЖјМђЛЏСЫЩшМЦЁЃЗжВМЪНЯћЯЂжаМфМў
KafkaЃЌЛљгк Log ШежОЃЌвдзЗМг append-only ЕФЗНЪНРДДцДЂЯћЯЂЁЃ
3.2. ВщбЏ
ВщбЏЪЧИіЪВУДИХФюЃПMarz ИјВщбЏШчЯТвЛИіМђЕЅЕФЖЈвхЃК
Query = Function(All Data)
ИУЕШЪНЕФКЌвхЪЧЃКВщбЏЪЧгІгУгкЪ§ОнМЏЩЯЕФКЏЪ§ЁЃИУЖЈвхПДЫЦМђЕЅЃЌШДМИКѕФвРЈСЫЪ§ОнПтКЭЪ§ОнЯЕЭГЕФЫљгаСьгђЃКRDBMSЁЂЫїв§ЁЂOLAPЁЂOLTPЁЂMapReduceЁЂEFLЁЂЗжВМЪНЮФМўЯЕЭГЁЂNoSQL
ЕШЖМПЩвдгУетИіЕШЪНРДБэЪОЁЃ
ШУЮвУЧНјвЛВНЩюШыПДвЛЯТКЏЪ§ЕФЬиадЃЌДгЖјЭкОђКЏЪ§здЩэЕФЬиЕуРДжДааВщбЏЁЃ
гавЛРрГЦЮЊ Monoid ЬиадЕФКЏЪ§гІгУЗЧГЃЙуЗКЁЃMonoid ЕФИХФюРДдДгкЗЖГыбЇЃЈCategory
TheoryЃЉЃЌЦфвЛИіживЊЬиадЪЧТњзуНсКЯТЩЁЃШчећЪ§ЕФМгЗЈОЭТњзу Monoid ЬиадЃК
(a+b)+c=a+(b+c)
ВЛТњзу Monoid ЬиадЕФКЏЪ§КмЖрЪБКђПЩвдзЊЛЏГЩЖрИіТњзу Monoid ЬиадЕФКЏЪ§ЕФдЫЫуЁЃШчЖрИіЪ§ЕФЦНОљжЕ
Avg КЏЪ§ЃЌЖрИіЦНОљжЕУЛЗЈжБНгЭЈЙ§НсКЯРДЕУЕНзюжеЕФЦНОљжЕЃЌЕЋЪЧПЩвдВ№ГЩЗжФИГ§вдЗжзгЃЌЗжФИКЭЗжзгЖМЪЧећЪ§ЕФМгЗЈЃЌДгЖјТњзу
Monoid ЬиадЁЃ
Monoid ЕФНсКЯТЩЬиаддкЗжВМЪНМЦЫужаМЋЦфживЊЃЌТњзу Monoid ЬиадвтЮЖзХЮвУЧПЩвдНЋМЦЫуЗжНтЕНЖрЬЈЛњЦїВЂаадЫЫуЃЌШЛКѓдйНсКЯИїздЕФВПЗждЫЫуНсЙћЕУЕНзюжеНсЙћЁЃЭЌЪБвВвтЮЖзХВПЗждЫЫуНсЙћПЩвдДЂДцЯТРДБЛБ№ЕФдЫЫуЙВЯэРћгУЃЈШчЙћИУдЫЫувВАќКЌЯрЭЌЕФВПЗжзгдЫЫуЃЉЃЌДгЖјМѕЩйжиИДдЫЫуЕФЙЄзїСПЁЃ
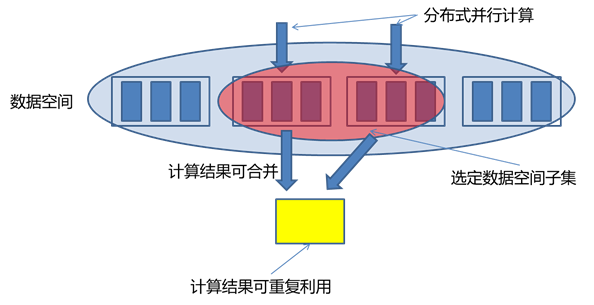
4.Lambda МмЙЙ
гаСЫЩЯУцЖдЪ§ОнЯЕЭГБОжЪЕФЬНЬжЃЌЯТУцЮвУЧРДЬжТлДѓЪ§ОнЯЕЭГЕФЙиМќЮЪЬтЃКШчКЮЪЕЪБЕидкШЮвтДѓЪ§ОнМЏЩЯНјааВщбЏЃПДѓЪ§ОндйМгЩЯЪЕЪБМЦЫуЃЌЮЪЬтЕФФбЖШБШНЯДѓЁЃ
зюМђЕЅЕФЗНЗЈЪЧЃЌИљОнЧАЪіЕФВщбЏЕШЪН Query = Function(All Data)ЃЌдкШЋЬхЪ§ОнМЏЩЯдкЯпдЫааВщбЏКЏЪ§ЕУЕННсЙћЁЃЕЋШчЙћЪ§ОнСПБШНЯДѓЃЌИУЗНЗЈЕФМЦЫуДњМлЬЋДѓСЫЃЌЫљвдВЛЯжЪЕЁЃ
Lambda МмЙЙЭЈЙ§ЗжНтЕФШ§ВуМмЙЙРДНтОіИУЮЪЬтЃКBatch LayerЃЌSpeed Layer
КЭ Serving LayerЁЃ

4.1.Batch Layer
Batch Layer ЕФЙІФмжївЊгаСНЕуЃК
ДцДЂЪ§ОнМЏ
дкЪ§ОнМЏЩЯдЄЯШМЦЫуВщбЏКЏЪ§ЃЌЙЙНЈВщбЏЫљЖдгІЕФ View
4.1.1. ДЂДцЪ§ОнМЏ
ИљОнЧАЪіЖдЪ§Он When&What ЬиадЕФЬжТлЃЌBatch Layer ВЩгУВЛПЩБфФЃаЭДцДЂЫљгаЕФЪ§ОнЁЃвђЮЊЪ§ОнСПБШНЯДѓЃЌПЩвдВЩгУ
HDFS жЎРрЕФДѓЪ§ОнДЂДцЗНАИЁЃШчЙћашвЊАДееЪ§ОнВњЩњЕФЪБМфЯШКѓЫГађДцЗХЪ§ОнЃЌПЩвдПМТЧШч InfluxDB
жЎРрЕФЪБМфађСаЪ§ОнПтЃЈTSDBЃЉДцДЂЗНАИЁЃ
4.1.2. ЙЙНЈВщбЏ View
ЩЯУцЫЕЕНИљОнЕШЪН Query = Function(All Data)ЃЌдкШЋЬхЪ§ОнМЏЩЯдкЯпдЫааВщбЏКЏЪ§ЕУЕННсЙћЕФДњМлЬЋДѓЁЃЕЋШчЙћЮвУЧдЄЯШдкЪ§ОнМЏЩЯМЦЫуВЂБЃДцВщбЏКЏЪ§ЕФНсЙћЃЌВщбЏЕФЪБКђОЭПЩвджБНгЗЕЛиНсЙћЃЈЛђЭЈЙ§МђЕЅЕФМгЙЄдЫЫуОЭПЩЕУЕННсЙћЃЉЖјЮоашжиаТНјааЭъећЗбЪБЕФМЦЫуСЫЁЃетЖљПЩвдАб
Batch Layer ПДГЩЪЧвЛИіЪ§ОндЄДІРэЕФЙ§ГЬЁЃЮвУЧАбеыЖдВщбЏдЄЯШМЦЫуВЂБЃДцЕФНсЙћГЦЮЊ ViewЃЌView
ЪЧ Lamba МмЙЙЕФвЛИіКЫаФИХФюЃЌЫќЪЧеыЖдВщбЏЕФгХЛЏЃЌЭЈЙ§ View МДПЩвдПьЫйЕУЕНВщбЏНсЙћЁЃ
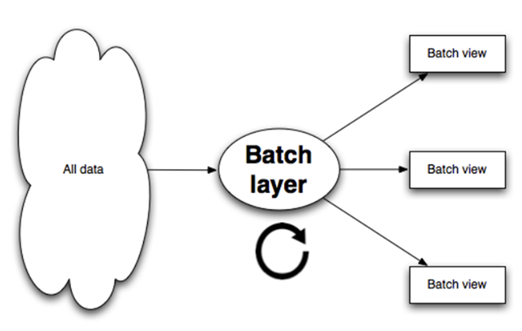
ШчЙћВЩгУ HDFS РДДЂДцЪ§ОнЃЌЮвУЧОЭПЩвдЪЙгУ MapReduce РДдкЪ§ОнМЏЩЯЙЙНЈВщбЏЕФ ViewЁЃBatch
Layer ЕФЙЄзїПЩвдМђЕЅЕФгУШчЯТЮБТыБэЪОЃК

ИУЙЄзїПДЫЦМђЕЅЃЌЪЕжЪЗЧГЃЧПДѓЁЃШЮКЮШЫЮЊЛђЛњЦїЗЂЩњЕФДэЮѓЃЌЖМПЩвдЭЈЙ§аое§ДэЮѓКѓжиаТМЦЫуРДЛжИДЕУЕНе§ШЗНсЙћЁЃ
PSЃКЖд View ЕФРэНт
View ЪЧвЛИіКЭвЕЮёЙиСЊадБШНЯДѓЕФИХФюЃЌView ЕФДДНЈашвЊДгвЕЮёздЩэЕФашЧѓГіЗЂЁЃвЛИіЭЈгУЕФЪ§ОнПтВщбЏЯЕЭГЃЌВщбЏЖдгІЕФКЏЪ§ЧЇБфЭђЛЏЃЌВЛПЩФмЧюОйЁЃЕЋЪЧШчЙћДгвЕЮёздЩэЕФашЧѓГіЗЂЃЌПЩвдЗЂЯжвЕЮёЫљашвЊЕФВщбЏГЃГЃЪЧгаЯоЕФЁЃBatch
Layer ашвЊзіЕФвЛМўживЊЕФЙЄзїОЭЪЧИљОнвЕЮёЕФашЧѓЃЌПМВьПЩФмашвЊЕФИїжжВщбЏЃЌИљОнВщбЏЖЈвхЦфдкЪ§ОнМЏЩЯЖдгІЕФ
ViewsЁЃ
4.2.Speed Layer
Batch Layer ПЩвдКмКУЕФДІРэРыЯпЪ§ОнЃЌЕЋгаКмЖрГЁОАЪ§ОнВЛЖЯЪЕЪБЩњГЩЃЌВЂЧвашвЊЪЕЪБВщбЏДІРэЁЃSpeed
Layer е§ЪЧгУРДДІРэдіСПЕФЪЕЪБЪ§ОнЁЃ
Speed Layer КЭ Batch Layer БШНЯРрЫЦЃЌЖдЪ§ОнНјааМЦЫуВЂЩњГЩ Realtime
ViewЃЌЦфжївЊЧјБ№дкгкЃК
Speed Layer ДІРэЕФЪ§ОнЪЧзюНќЕФдіСПЪ§ОнСїЃЌBatch Layer ДІРэЕФШЋЬхЪ§ОнМЏ
Speed Layer ЮЊСЫаЇТЪЃЌНгЪеЕНаТЪ§ОнЪБВЛЖЯИќаТ Realtime ViewЃЌЖј Batch
Layer ИљОнШЋЬхРыЯпЪ§ОнМЏжБНгЕУЕН Batch ViewЁЃ
Lambda МмЙЙНЋЪ§ОнДІРэЗжНтЮЊ Batch Layer КЭ Speed Layer гаШчЯТгХЕуЃК
ШнДэадЁЃSpeed Layer жаДІРэЕФЪ§ОнвВВЛЖЯаДШы Batch LayerЃЌЕБ Batch Layer
жажиаТМЦЫуЕФЪ§ОнМЏАќКЌ Speed Layer ДІРэЕФЪ§ОнМЏКѓЃЌЕБЧАЕФ Realtime View
ОЭПЩвдЖЊЦњЃЌетвВОЭвтЮЖзХ Speed Layer ДІРэжав§ШыЕФДэЮѓЃЌдк Batch Layer жиаТМЦЫуЪБЖМПЩвдЕУЕНаое§ЁЃетЕувВПЩвдПДГЩЪЧ
CAP РэТлжаЕФзюжевЛжТадЃЈEventual ConsistencyЃЉЕФЬхЯжЁЃ 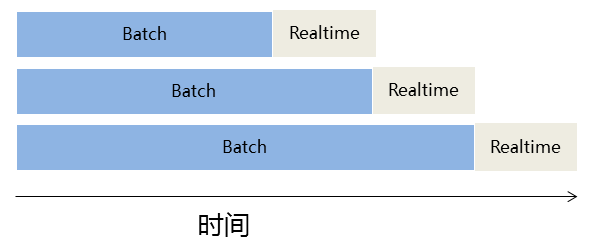
ИДдгадИєРыЁЃBatch Layer ДІРэЕФЪЧРыЯпЪ§ОнЃЌПЩвдКмКУЕФеЦПиЁЃSpeed Layer ВЩгУдіСПЫуЗЈДІРэЪЕЪБЪ§ОнЃЌИДдгадБШ
Batch Layer вЊИпКмЖрЁЃЭЈЙ§ЗжПЊ Batch Layer КЭ Speed LayerЃЌАбИДдгадИєРыЕН
Speed LayerЃЌПЩвдКмКУЕФЬсИпећИіЯЕЭГЕФТГАєадКЭПЩППадЁЃ
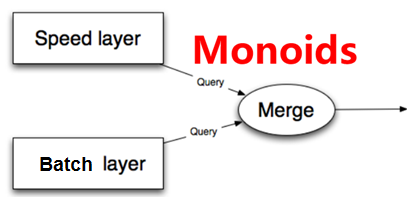
4.3.Serving Layer
Lambda МмЙЙЕФ Serving Layer гУгкЯьгІгУЛЇЕФВщбЏЧыЧѓЃЌКЯВЂ Batch View
КЭ Realtime View жаЕФНсЙћЪ§ОнМЏЕНзюжеЕФЪ§ОнМЏЁЃ
етЖљЩцМАЕНЪ§ОнШчКЮКЯВЂЕФЮЪЬтЁЃЧАУцЮвУЧЬжТлСЫВщбЏКЏЪ§ЕФ Monoid аджЪЃЌШчЙћВщбЏКЏЪ§Тњзу Monoid
аджЪЃЌМДТњзуНсКЯТЪЃЌжЛашвЊМђЕЅЕФКЯВЂ Batch View КЭ Realtime View жаЕФНсЙћЪ§ОнМЏМДПЩЁЃЗёдђЕФЛАЃЌПЩвдАбВщбЏКЏЪ§зЊЛЛГЩЖрИіТњзу
Monoid аджЪЕФВщбЏКЏЪ§ЕФдЫЫуЃЌЕЅЖРЖдУПИіТњзу Monoid аджЪЕФВщбЏКЏЪ§Нјаа Batch View
КЭ Realtime View жаЕФНсЙћЪ§ОнМЏКЯВЂЃЌШЛКѓдйМЦЫуЕУЕНзюжеЕФНсЙћЪ§ОнМЏЁЃСэЭтвВПЩвдИљОнвЕЮёздЩэЕФЬиадЃЌдЫгУвЕЮёздЩэЕФЙцдђРДЖд
Batch View КЭ Realtime View жаЕФНсЙћЪ§ОнМЏКЯВЂЁЃ
5.Big Picture
ЩЯУцЗжБ№ЬжТлСЫ Lambda МмЙЙЕФШ§ВуЃКBatch LayerЃЌSpeed Layer КЭ Serving
LayerЁЃЯТЭМИјГіСЫ Lambda МмЙЙЕФвЛИіЭъећЪгЭМКЭСїГЬЁЃ
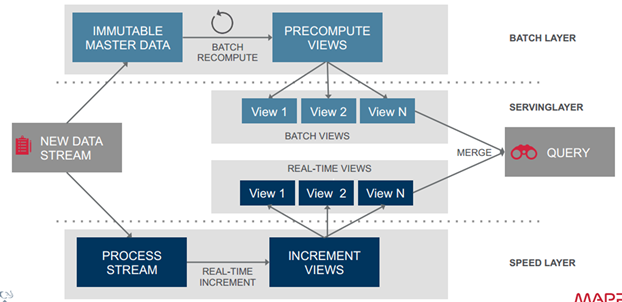
Ъ§ОнСїНјШыЯЕЭГКѓЃЌЭЌЪБЗЂЭљ Batch Layer КЭ Speed Layer ДІРэЁЃ
Batch Layer вдВЛПЩБфФЃаЭРыЯпДцДЂЫљгаЪ§ОнМЏЃЌЭЈЙ§дкШЋЬхЪ§ОнМЏЩЯВЛЖЯжиаТМЦЫуЙЙНЈВщбЏЫљЖдгІЕФ
Batch ViewsЁЃ
Speed Layer ДІРэдіСПЕФЪЕЪБЪ§ОнСїЃЌВЛЖЯИќаТВщбЏЫљЖдгІЕФ Realtime ViewsЁЃ
Serving Layer ЯьгІгУЛЇЕФВщбЏЧыЧѓЃЌКЯВЂ Batch View КЭ Realtime View
жаЕФНсЙћЪ§ОнМЏЕНзюжеЕФЪ§ОнМЏЁЃ
5.1.Lambda МмЙЙзщМўбЁаЭ
ЯТЭМИјГіСЫ Lambda МмЙЙжаИїИіВуГЃгУЕФзщМўЁЃ
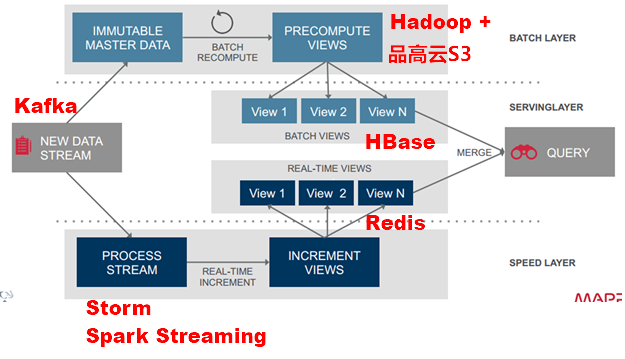
Ъ§ОнСїДцДЂПЩбЁгУЛљгкВЛПЩБфШежОЕФЗжВМЪНЯћЯЂЯЕЭГ KafkaЃЛ
Batch Layer Ъ§ОнМЏЕФДІРэПЩбЁгУ hadoop вдМАЪЙгУЦЗИпдЦ S3 НјааДцДЂЃЈвЛИігЩ
BingoCloudOSЃЈЦЗИпдЦВйзїЯЕЭГЃЉЬсЙЉЕФМцШн AWS S3 ЕФдЦЗўЮёЙВФиИјФуЃЉ
Batch View ЕФдЄМЦЫуПЩвдбЁгУ MapReduce Лђ SparkЃЛBatch View
здЩэНсЙћЪ§ОнЕФДцДЂПЩЪЙгУ MySQLЃЈВщбЏЩйСПЕФзюНќНсЙћЪ§ОнЃЉЃЌЛђ hbaseЃЈВщбЏДѓСПЕФРњЪЗНсЙћЪ§ОнЃЉЁЃ
Speed Layer діСПЪ§ОнЕФДІРэПЩбЁгУ Storm Лђ Spark StreamingЃЛRealtime
View діСПНсЙћЪ§ОнМЏЮЊСЫТњзуЪЕЪБИќаТЕФаЇТЪЃЌПЩбЁгУ Redis ЕШФкДц NoSQLЁЃ
5.2.Lambda МмЙЙзщМўбЁаЭддђ
Lambda МмЙЙЪЧИіЭЈгУПђМмЃЌИїИіВубЁаЭЪБВЛвЊОжЯоЪБЩЯУцИјГіЕФзщМўЃЌЬиБ№ЪЧЖдгк View ЕФбЁаЭЁЃДгЮвЖд
Lambda МмЙЙЕФЪЕМљРДПДЃЌвђЮЊ View ЪЧИіКЭвЕЮёЙиСЊадЗЧГЃДѓЕФИХФюЃЌView бЁдёзщМўЪБЙиМќЪЧвЊИљОнвЕЮёЕФашЧѓЃЌРДбЁдёзюЪЪКЯВщбЏЕФзщМўЁЃВЛЭЌЕФ
View зщМўЕФбЁдёвЊЩюШыЭкОђЪ§ОнКЭМЦЫуздЩэЕФЬиЕуЃЌДгЖјбЁдёГізюЪЪКЯЪ§ОнКЭМЦЫуздЩэЬиЕуЕФзщМўЃЌЭЌЪБВЛЭЌЕФ
View ПЩвдбЁдёВЛЭЌЕФзщМўЁЃ
6.Lambda МмЙЙ vs. Event Sourcing vs. CQRS
дк Lambda МмЙЙЩэЩЯПЩвдПДЕНКмЖрЯжгаЩшМЦЫМЯыКЭМмЙЙЕФгАзгЃЌШч Event Sourcing КЭ
CQRSЃЌетЖљЮвУЧАбЫќУЧКЭ Lambda МмЙЙзівЛНсКЯЖдБШЃЌДгЖјШЅИќЩюШыЕФРэНт Lambda МмЙЙЁЃ
6.1. ЪТМўЫндДЃЈEvent SourcingЃЉvs. Lambda МмЙЙ
ЪТМўЫндДЃЈEvent SourcingЃЉЪЧгЩДѓУћЖІЖІЕФ Martin Flower ДѓЪхЬсГіРДЕФМмЙЙФЃЪНЁЃEvent
Sourcing БОжЪЩЯЪЧвЛжжЪ§ОнГжОУЛЏЕФЗНЪНЃЌЫќНЋв§ЗЂБфЛЏЕФЪТМўЃЈEventЃЉБОЩэДцДЂЯТРДЁЃЯрБШгкДЋЭГЪ§ОнЪЧГжОУЛЏЗНЪНЃЌДцДЂЕФЪЧЪТМўв§ЗЂЕФНсЙћЃЌЖјЗЧЪТМўБОЩэЃЌетбљЮвУЧдкБЃДцНсЙћЕФЭЌЪБЃЌЪЕМЪЩЯЪЇШЅСЫзЗЫнЕМжТНсЙћдвђЕФЛњЛсЁЃ
етЖљПЩвдПДЕН Lambda МмЙЙжаЪ§ОнМЏЕФДцДЂКЭ Event Sourcing жаЕФЫМЯыЪЧЭъШЋвЛжТЕФЃЌБОжЪЖМЪЧВЩгУВЛПЩБфЕФЪ§ОнФЃаЭДцДЂв§ЗЂБфЛЏЕФЪТМўЖјЗЧБфЛЏВњЩњЕФНсЙћЁЃДгЖјдкЗЂЩњДэЮѓЕФЪБКђЃЌФмЙЛзЗБОЫндДЃЌевЕНЗЂЩњДэЮѓЕФИљдДЃЌЭЈЙ§жиаТМЦЫуЖЊЦњДэЮѓЕФаХЯЂРДЛжИДЯЕЭГЃЌДяЕНЯЕЭГЕФШнДэадЁЃ
6.2.CQRS vs. Lambda МмЙЙ
CQRS (Command Query Responsibility Segregation) НЋЖдЪ§ОнЕФаоИФВйзїКЭВщбЏВйзїЗжРыЃЌЦфБОжЪКЭ
Lambda МмЙЙвЛбљЃЌвВЪЧвЛжжаЮЪНЕФЖСаДЗжРыЁЃдк Lambda МмЙЙжаЃЌЪ§ОнвдВЛПЩБфЕФЗНЪНДцДЂЯТРДЃЈаДВйзїЃЉЃЌзЊЛЛГЩВщбЏЫљЖдгІЕФ
ViewsЃЌВщбЏДг View жажБНгЕУЕННсЙћЪ§ОнЃЈЖСВйзїЃЉЁЃ
ЖСаДЗжРыНЋЖСКЭаДСНИіЪгНЧНјааЗжРыЃЌДјРДЕФКУДІЪЧИДдгадЕФИєРыЃЌДгЖјМђЛЏЯЕЭГЕФЩшМЦЁЃЯрБШгкДЋЭГзіЗЈжаЕФНЋЖСКЭаДВйзїЗХдквЛЦ№ЕФДІРэЗНЪНЃЌЖдгкЖСаДВйзївЕЮёЗЧГЃИДдгЕФЯЕЭГЃЌжЛЛсЪЙЯЕЭГБфЕУвьГЃИДдгЃЌФбвдЮЌЛЄЁЃ

7. змНс
БОЮФНщЩмСЫ Lambda МмЙЙЕФЛљБОИХФюЁЃ
Lambda МмЙЙЭЈЙ§ЖдЪ§ОнКЭВщбЏЕФБОжЪШЯЪЖЃЌШкКЯСЫВЛПЩБфадЃЈImmunabilityЃЉЃЌЖСаДЗжРыКЭИДдгадИєРыЕШвЛЯЕСаМмЙЙддђЃЌ
НЋДѓЪ§ОнДІРэЯЕЭГЛЎЗжЮЊ Batch Layer, Speed Layer КЭ Serving Layer
Ш§ВуЃЌ
ДгЖјЩшМЦГівЛИіФмТњзуЪЕЪБДѓЪ§ОнЯЕЭГЙиМќЬиадЃЈШчИпШнДэЁЂЕЭбгЪБКЭПЩРЉеЙЕШЃЉЕФМмЙЙЁЃ
Lambda МмЙЙзїЮЊвЛИіЭЈгУЕФДѓЪ§ОнДІРэПђМмЃЌПЩвдКмЗНБуЕФМЏГЩ HadoopЃЌKafkaЃЌStormЃЌSparkЃЌHbase
ЕШИїРрДѓЪ§ОнзщМўЁЃ
|








