| БрМЭЦМі: |
дкБОЮФжаЃЌНЋЪзЯШНщЩмSparkЩњЬЌКЭКЫаФИХФюЃЌSparkЩњЬЌЕФСїМЦЫуММЪѕЃКSpark
Streaming,зюКѓЪЙгУЪЕР§РДЫЕУї Spark StremingВЂНјааЕїгХЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1ЁЂБГОАНщЩм
StormвдМАРыЯпЪ§ОнЦНЬЈЕФMapReduceКЭHiveЙЙГЩСЫHadoopЩњЬЌЖдЪЕЪБКЭРыЯпЪ§ОнДІРэЕФвЛЬзЭъећДІРэНтОіЗНАИЁЃГ§СЫДЫЬзНтОіЗНАИжЎЭтЃЌЛЙгавЛжжЗЧГЃСїааЕФЖјЧвЭъећЕФРыЯпКЭ
ЪЕЪБЪ§ОнДІРэЗНАИЁЃетжжЗНАИОЭЪЧSparkЁЃSparkБОжЪЩЯЪЧЖдHadoopЬиБ№ЪЧMapReduceЕФВЙГфЁЂгХЛЏКЭЭъЩЦЃЌгШЦфЪЧЪ§ОнДІРэЫйЖШЁЂвзгУадЁЂЕќДњМЦЫуКЭИДдгЪ§ОнЗжЮіЕШЗНУцЁЃ
Spark Streaming зїЮЊSparkећЬхНтОіЗНАИжаЪЕЪБЪ§ОнДІРэВПЗжЃЌБОжЪЩЯШдШЛЪЧЛљгкSparkЕФЕЏадЗжВМЪНЪ§ОнМЏЃЈResilient
Distributed Datasets ЃКRDDЃЉИХФюЁЃSpark StreamingНЋдДЭЗ
Ъ§ОнЛЎЗжЮЊКмаЁЕФХњЃЌВЂвдРрЫЦгкРыЯпХњЕФЗНЪНРДДІРэетВПЗжЮЂХњЪ§ОнЁЃ
ЯрЖдгкStormетжждЩњЕФЪЕЪБДІРэПђМмЃЌSpark StreamingЛљгкЮЂХњЕФЕФЗНАИДјРДСЫЭЬЭТСПЕФЬсЩ§ЃЌЕЋЪЧвВЕМжТСЫЪ§ОнДІРэбгГйЕФдіМг---ЛљгкSpark
StreamingЪЕЪБЪ§ОнДІРэЗНАИЕФЪ§ОнбгГйЭЈГЃдкУыМЖЩѕжСЗжжгМЖЁЃ
2ЁЂSparkЩњЬЌКЭКЫаФИХФю
2.1ЁЂSparkИХРР
SparkЕЎЩњгкУРЙњВЎПЫРћДѓбЇЕФAMPLab,ЫќзюГѕЪєгкВЎПЫРћДѓбЇЕФбаОПадЯюФПЃЌгы2010Фъе§ЪНПЊдДЃЌгк2013ФъГЩЮЊApacheЛљН№ЯюФПЃЌБљгъ2014ФъГЩЮЊApacheЛљН№ЕФЖЅМЖЯюФПЁЃ
SparkгУСЫВЛЕН5ФъЕФЪБМфОЭГЩСЫApacheЕФЖЅМЖЯюФПЃЌФПЧАвбБЛЙњФкЭтЕФжкЖрЛЅСЊЭјЙЋЫОЪЙгУЃЌАќРЈAmazonЁЂEBayЁЂЬдБІЁЂЬкбЖЕШЁЃSparkЕФСїааКЭЫќНтОіСЫHadoopЕФКмЖрВЛзуУмВЛПЩЗжЁЃ
ДЋЭГHadoopЛљгкMapReduceЕФЗНАИЪЪгУгкДѓЖрЪ§ЕФРыЯпХњДІРэГЁОАЃЌЕЋЪЧЖдгкЪЕЪБВщбЏЁЂЕќДњМЦЫуЕШГЁОАЗЧГЃВЛЪЪКЯЃЌетЪЧгаЦфФкдкОжЯоОіЖЈЕФЁЃ
1ЁЂMapReduceжЛЬсЙЉMapКЭReduceСНИіВйзїЃЌГщЯѓГЬЖШЕЭЃЌЕЋЪЧИДдгЕФМЦЫуЭЈГЃашвЊКмЖрВйзїЃЌЖјЧвВйзїжЎМфгаИДдгЕФвРРЕЙиЯЕЁЃ
2ЁЂMapReduceЕФжаМфДІРэНсЙћЪЧЗХдкHDFSЮФМўЯЕЭГжаЕФЃЌУПДЮЕФТфЕиКЭЖСШЁЖМЯћКФДѓСПЕФЪБМфКЭзЪдДЁЃ
3ЁЂЕБШЛЃЌMapReduceвВВЛжЇГжИпМЖЪ§ОнДІРэAPIЁЂDAGЃЈгаЯђЮхЛЗЭМЃЉМЦЫуЁЂЕќДњМЦЫуЕШЁЃSparkдђНЯКУЕиНтОіСЫЩЯЪіетаЉЮЪЬтЁЃ
1ЁЂSparkЭЈЙ§в§ШыЕЏадЗжВМЪНЪ§ОнМЏЃЈResilient Distributed
DatasetsЃКRDDЃЉвдМАRDDЗсИЛЕФЖЏзїВйзїAPIЃЌЗЧГЃКУЕижЇГжСЫDGAЕФМЦЫуКЭЕќДњМЦЫуЁЃ
2ЁЂSparkЭЈЙ§ФкДцМЦЫуКЭЛКДцЪ§ОнЗЧГЃКУЕижЇГжСЫЕќДњМЦЫуКЭDAGМЦЫуЕФЪ§ОнЙВЯэЁЂМѕЩйСЫЪ§ОнЖСШЁЕФIOПЊЯњЁЂДѓДѓЬсИпСЫЪ§ОнДІРэЫйЖШЁЃ
3ЁЂSparkЮЊХњДІРэЃЈSpark CoreЃЉЁЂСїЪНДІРэЃЈSpark
StreamingЃЉЁЂНЛЛЅЗжЮіЃЈSpark SQLЃЉЁЂЛњЦїбЇЯАЃЈMLLibЃЉКЭЭММЦЫуЃЈGraphXЃЉЬсЙЉСЫвЛИіЭЌвЛЕФЦНЬЈКЭAPIЃЌЗЧГЃБугкЪЙгУЁЃ
4ЁЂSparkЗЧГЃШнвзЪЙгУЁЂSparkжЇГжjavaЁЂPythonКЭScalaЕФAPIЃЌЛЙжЇГжГЌЙ§80жжИпМЖЫуЗЈЃЌЪЙЕУгУЛЇПЩвдПьЫйЙЙНЈВЛЭЌЕФгІгУЁЃSparkжЇГжНЛЛЅЪНЕФPythonКЭScalaЕФshellЃЌетвтЮЖзХ
ПЩвдЗЧГЃЗНБуЕидкетаЉshellжаЪЙгУSparkМЏШКРДбщжЄНтОіЮЪЬтЕФЗНЗЈЃЌЖјВЛЪЧЯёвдЧАвЛбљЃЌашвЊДђАќЁЂЩЯДЋМЏШКЁЂбщжЄЕШЁЃетЖдгкдаЭПЊЗЂгШЦфживЊЁЃ
5ЁЂSparkПЩвдЗЧГЃЗНБуЕигыЦфЫћПЊдДВњЦЗНјааШкКЯЃКБШШчЃЌSparkПЩвдЪЙгУHadoopЕФYARNКЭApache
MesosзїЮЊЫќЕФзЪдДЙмРэКЭЕїЖШЦїЃЌВЂЧвПЩвдДІРэЫљгаHadoopжЇГжЕФЪ§ОнЃЌАќРЈHDFSЁЂ
HBaseКЭCassandraЕШЁЃSparkвВПЩвдВЛвРРЕгкЕкШ§ЗНЕФзЪдДЙмРэКЭЕїЖШЦїЃЌЫќЪЕЯжСЫStandaloneзїЮЊЦфФкжУЕФзЪдДЙмРэКЭЕїЖШПђМмЃЌетбљНјвЛВННЕЕЭСЫSparkЕФЪЙгУУХМїЁЃ
6ЁЂExternal Data SourceЖрЪ§ОндДжЇГжЃКSparkПЩвдЖРСЂдЫааЃЌГ§СЫПЩвддЫаадкЕБЯТЕФYarnМЏШКЙмРэжЎЭтЃЌЫќЛЙПЩвдЖСШЁвбгаЕФHadoopЪ§ОнЁЃЫќПЩвддЫааЖржжЪ§ОндДЃЌБШШчParquetЁЂHiveЁЂHBaseЁЂHDFSЕШЁЃ
2.2ЁЂSparkКЫаФИХФю
RDDЪЧSparkжазюЮЊКЫаФКЭживЊЕФИХФюЁЃRDDЃЌШЋГЦЮЊ Resilient
Distributed DatasetЃЌдкSparkЙйЗНЮФЕЕжаБЛГЦЮЊЁАвЛИіПЩВЂааВйзїЕФгаШнДэЛњжЦЕФЪ§ОнМЏКЯЁБЁЃЪЕМЪЩЯRDDОЭЪЧвЛИіЪ§ОнМЏЃЌЖјЧвЪЧЗжВМЪНЕФЁЃЭЌЪБSparkЛЙЖдетИіЗжВМЪНЪ§ОнМЏЬсЙЉСЫЗсИЛЕФЪ§ОнВйзїКЭШнДэадЁЃ
1ЁЂRDDДДНЈ
SparkжаДДНЈRDDзюжБНгЕФЗНЗЈЪЧЕїгУSparkContext(SparkContextЪЧSparkМЏШКЛЗОГЕФЗУЮЪШыПкЃЌSpark
StreamingвВгаздМКЖдгІЕФЖдЯѓStreamContext)ЕФparallelizeЗНЗЈЁЃ
List<Integer> data = Arrays.asList(1,2,3,4,5);
HavaRDD<Integer> distData = sc.parallelize(data);
ЩЯЪіДњТыЛсНЋЪ§ОнМЏКЯ (data)зЊЛЛЮЊетИіЗжВМЪНЪ§ОнМЏЃЈdistDataЃЉ,жЎКѓОЭПЩвдЖдДЫRDDжДааИїжжзЊЛЛЕШЁЃБШШчЕїгУdistData.reduce((a,b)
=> a+b),НЋетИіЪ§зщжаЕФдЊЫиЯюМгЃЌ
ДЫЭтЃЌЛЙПЩвдЭЈЙ§ЩшжУparallelizeЕФЕкЖўИіВЮЪ§ЪжЖЏЩшжУЩњГЩRDDЕФЗжЧјЪ§ЃКsc.parallelize(data,10),ШчЙћВЛЩшЖЈЕФЛАЃЌSparkЛсздЖЏЩшЖЈЁЃ
ЕЋдкЪЕМЪЕФЯюФПжаЃЌRDDвЛАуЪЧДгдДЭЗЪ§ОнДДНЈЕФЁЃSparkжЇГжДгШЮКЮвЛИіHadoopжЇГжЕФДцДЂЪ§ОнДДНЈRDDЃЌАќРЈБОЕиЮФМўЯЕЭГЁЂHDFSЁЂCassandnaЁЂHBaseКЭAmazon
S3ЕШЁЃ
СэЭтЃЌSparkвВжЇГжДгЮФБОЮФМўЃЌSequenceFilesКЭЦфЫќHadoop InputFormatЕФИёЪНЮФМўжаДДНЈRDDЁЃДДНЈЕФЗНЗЈвВКмМђЕЅЃЌжЛашвЊжИЖЈдДЭЗЮФМўВЂЕїгУЖдгІЕФЗНЗЈМДПЩЃК
JavaRDD<String> distFile = sc.textFile("data.txt");
Spark жазЊЛЛSequenceFileЕФSparkContextЗНЗЈЪЧ
sequenceFileЃЌзЊЛЛHadoop InputFormatsЕФSparkContextЗНЗЈЪЧHadoopRDDЁЃ
2ЁЂRDDВйзї
RDDВйзїЗжЮЊзЊЛЛ(transformation)КЭааЖЏ(action)ЃЌtransformationЪЧИљОндгаЕФRDDДДНЈвЛИіаТЕФRDDЃЌactionдђАЩRDDВйзїКѓЕФНсЙћЗЕЛиИјdriverЁЃР§Шчmap
ЪЧвЛИізЊЛЛЃЌ
ЫќАбЪ§ОнМЏжаЕФУПИідЊЫиОЙ§вЛИіЗНЗЈДІРэЕФНсЙћЗЕЛивЛИіаТЕФRDDЃЌreduceЪЧвЛИіaction,ЫќЪеМЏRDDЕФЫљгаЪ§ОнОЙ§вЛаЉЗНЗЈЕФДІРэЃЌзюКѓАбНсЙћЗЕЛиИјdriverЁЃ
SparkЖдtransformationЕФГщЯѓПЩвдДѓДѓЬсИпадФмЃЌетЪЧвђЮЊдкSparkжаЃЌЫљгаtransformationВйзїЖМЪЧlazyФЃЪНЃЌМДSparkВЛЛсСЂМДМЦЫуНсЙћЃЌЖјжЛЪЧМђЕЅЕиМЧзЁЫљгаЖдЪ§ОнМЏЕФ
зЊЛЛВйзїТпЁЃетаЉзЊЛЛжЛгагіЕНactionВйзїЕФЪБКђВХЛсПЊЪММЦЫуЁЃетбљЕФЩшМЦЪЙЕУSparkИќМгИпаЇЃЌР§ШчПЩвдЭЈЙ§mapДДНЈвЛИіаТЪ§ОнМЏдкreduceжаЪЙгУЃЌВЂНіНіЗЕЛиreduceЕФ
НсЙћИјdriverЃЌЖјВЛЪЧећИіДѓДѓЕФmapЙ§ЕФЪ§ОнМЏЁЃ
3ЁЂRDDГжОУЛЏ
SparkзюживЊЕФвЛИіЙІФмЪЧЫќПЩвдЭЈЙ§ИїжжВйзїГжОУЛЏЃЈЛђЛКДцЃЉвЛИіМЏКЯЕНФкДцжаЁЃЕБГжОУЛЏвЛИіRDDЕФЪБКђЃЌУПвЛИіНкЕуЖМНЋВЮгыМЦЫуЕФЫљгаЗжЧјЪ§ОнДцДЂЕНФкДцжаЃЌ
ВЂЧветаЉЪ§ОнПЩвдБЛетИіМЏКЯЃЈвдМАетИіМЏКЯбмЩњЕФЦфЫћМЏКЯЃЉЕФЖЏзїжиИДРћгУЁЃетИіФмСІЪЙКѓајЕФЖЏзїЫйЖШИќПьЃЈЭЈГЃПь10БЖвдЩЯЃЉЁЃЖдгІЕќДњЫуЗЈКЭПьЫйЕФНЛЛЅгІгУРДЫЕЃЌ
ЛКДцЪЧвЛИіЙиМќЕФЙЄОпЁЃ
ПЩвдЭЈЙ§ persist()Лђепcache()ЗНЗЈГжОУЛЏвЛИіRDDЁЃЯШдкactionжаМЦЫуЕУЕНRDD,ШЛКѓНЋЦфБЃДцдкУПИіНкЕуЕФФкДцжаЁЃSparkЕФЛКДцЪЧвЛИіШнДэЕФММЪѕЃЌвВОЭЪЧЫЕЃЌШчЙћRDDЕФ
ШЮКЮвЛИіЗжЧјЖЊЪЇЃЌЫќПЩвдЭЈЙ§дгаЕФзЊЛЛВйзїздЖЏжиИДМЦЫуВЂЧвДДНЈГіетИіЗжЧјЁЃ
ДЫЭтЃЌЛЙПЩвдРћгУВЛЭЌЕФДцДЂМЖБ№ДцДЂУПвЛИіБЛГжОУЛЏЕФRDDЃЌЁЃР§ШчЃЌЫќдЪаэГжОУЛЏМЏКЯЕНДХХЬЩЯЁЂНЋМЏКЯзїЮЊађСаЛЏЕФJavaЖдЯѓГжОУЛЏЕНФкДцжаЁЂдкНкЕуМфИДжЦМЏКЯЛђДцДЂМЏКЯ
ЕНTachyonжаЁЃПЩвдЭЈЙ§ДЋЕнвЛИіStorageLevelЖдЯѓИјpersist()ЗНЪНЩшжУетаЉДцДЂМЖБ№ЁЃcache()ЪЙгУСЫФЌШЯЕФДцДЂМЖБ№-----StorageLevel.MEMORY_ONLYЁЃ
4ЁЂSparkЩњЬЌШІ
SparkНЈСЂдкЭГвЛГщЯѓЕФRDDжЎЩЯЃЌЪЙЕУЫќПЩвдвдЛљБОвЛжТЕФЗНЪНгІЖдВЛЭЌЕФДѓЪ§ОнДІРэГЁОАЃЌАќРЈХњДІРэЃЌСїДІРэЁЂSQLЁЂMachine
LearningвдМАGraphXЕШЁЃетОЭЪЧSparkЩшМЦЕФЁА
ЭЈгУЕФБрГЬГщЯѓЁБЃЈ Unified Programming AbstractionЃЉ,вВе§ЪЧSparkЖРЬиЕФЕиЗНЁЃ
SparkЩњЬЌШІАќКЌСЫSpark CoreЁЂSpark SQLЁЂSpark StreamingЁЂMLLibКЭGraphXЕШзщМўЃЌЦфжаSpark
CoreЬсЙЉФкДцМЦЫуПђМмЁЂSparkStreamingЬсЙЉЪЕЪБДІРэгІгУЁЂSpark SQLЬсЙЉ
МДЯЏВщбЏЃЌдйМгЩЯMLlibЕФЛњЦїбЇЯАКЭGraphXЕФЭМДІРэЃЌЫќУЧФмЮоЗьМЏГЩВЂЬсЙЉSparkвЛеОЪНЕФДѓЪ§ОнНтОіЦНЬЈКЭЩњЬЌШІЁЃ
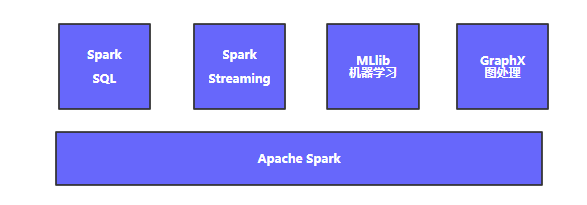
Spark CoreЃКSpark CoreЪЕЯжСЫSparkЕФЛљБОЙІФмЃЌАќРЈШЮЮёЕїЖШЁЂФкДцЙмРэЁЂДэЮѓЛжИДЁЂгыДцДЂЯЕЭГНЛЛЅЕШФЃПщЁЃSpark
CoreЛЙАќРЈСЫRDDЕФAPIЖЈвхЃЌВЂЬсЙЉСЫДДНЈКЭВйзїRDDЕФ
ЗсИЛAPIЁЃSpark CoreЪЧSparkЦфЫќзщМўЕФЛљДЁКЭИљБОЁЃ
Spark StreamingЃКЫћЪЧSparkЬсЙЉЕФЖдЪЕЪБЪ§ОнНјааСїМЦЫуЕФзщМўЃЌЬсЙЉСЫгУРДВйзїЪ§ОнСїЕФAPIЃЌВЂЧвгыSpark
CoreжаЕФRDD APIИпЖШЖдгІЁЃSpark StreamingжЇГжгыSpark Core
ЭЌМЖБ№ЕФШнДэадЁЂЭЬЭТСПКЭЩьЫѕадЁЃ
Spark SQLЃКЫќЪЧSparkгУРДВйзїНсЙЙЛЏЪ§ОнЕФГЬађАќЃЌЭЈЙ§Spark SQLЃЌПЩвдЪЙгУSQLЛђРрSQLгябдРДВщбЏЪ§ОнЃЛЭЌЪБSpark
SQLжЇГжЖржжЪ§ОндДЃЌБШШчHiveБэЁЂParquetвдМА
JSONЕШЃЌГ§СЫЮЊSparkЬсЙЉвЛИіSQLНгПкЃЌSpark SQLЛЙжЇГжПЊЗЂепНЋSQLКЭДЋЭГЕФRDDБрГЬЕФЪ§ОнВйзїЗНЪНЯђНсКЯЃЌВЛТлЪЧЪЙгУPythonЁЂJavaЛЙЪЧScalaЃЌПЊЗЂепЖМПЩвддк
ЕЅИігІгУжаЭЌЪБЪЙгУSQLКЭИДдгЕФЪ§ОнЗжЮіЁЃ
MLLibЃКSparkЬсЙЉСЫГЃМћЕФЛњЦїбЇЯАЙІФмЕФГЬађПтЃЌНазіMLlib,MLlibЬсЙЉСЫЖржжЛњЦїбЇЯАЫуЗЈЃЌАќРЈЗжРрЁЂЛиЙщЁЂОлРрЁЂаЭЌЙ§ТЫЕШЃЌЛЙЬсЙЉСЫФЃаЭЦРЙРЁЂЪ§ОнЕМШыЕШЖюЭтЕФ
жЇГжЙІФмЁЃДЫЭтЃЌMLLibЛЙЬсЙЉСЫвЛаЉИќЕзВуЕФЛњЦїбЇЯАдгяЃЌАќРЈвЛИіЭЈгУЕФЬнЖШЯТНЕгХЛЏЫуЗЈЃЌЫљгаетаЉЗНЗЈЖМБЛЩшМЦЮЊПЩвддкМЏШКЩЯЧсЫЩЩьЫѕЕФМмЙЙЁЃ
GraphXЃКGraphXЪЧгУРДВйзїЭМЃЈШчЩчНЛЭјТчЕФХѓгбШІЃЉЕФГЬађПтЃЌПЩвдНјааВЂааЕФЭММЦЫуЁЃгыSpark
StreamingКЭSpark SQLРрЫЦЃЌGraphXвВРЉеЙСЫSparkЕФRDD APIЃЌ
ФмгУРДДДНЈвЛИіЖЅЕуКЭБпЖМАќКЌШЮвтЪєадЕФгаЯђЭМЁЃGraphXЛЙжЇГжеыЖдЭМЕФИїжжВйзїЃЈШчНјааЭМЗжИюЕФsubgraphКЭВйзїЫљгаЖЅЕуЕФmapVerticesЃЉ,вдМАвЛаЉГЃгУЕФЭМЫуЗЈ
ЃЈШчPageRankКЭШ§НЧМЦЫуЃЉЁЃ
3ЁЂSparkЩњЬЌЕФСїМЦЫуММЪѕЃКSpark Streaming Spark StreamingзїЮЊSparkЕФКЫаФзщМўжЎвЛЃЌЭЈStormвЛбљЃЌжївЊЖдЪ§ОнНјааЪЕЪБЕФСїДІРэЃЌЕЋЪЧВЛЭЌгкApache
StormЃЈетРяжИЕФЪЧдЩњStormЃЌЗЧTridentЃЉЃЌдкSpark Streaming
жаЪ§ОнДІРэЕФЕЅЮЛЪЧЪЧвЛХњЖјВЛЪЧвЛЬѕЃЌSparkЛсЕШВЩМЏЕФдДЭЗЪ§ОнРлЛ§ЕНЩшжУЕФМфИєЬѕМўКѓЃЌЖдЪ§ОнНјааЭГвЛЕФЮЂХњДІРэЁЃетИіМфИєЪЧSpark
StreamingжаЕФКЫаФИХФюКЭЙиМќВЮЪ§ЃЌ
жБНгОіЖЈСЫSpark StreamingзївЕЕФЪ§ОнДІРэбгГйЃЌЕБШЛвВОіЖЈзХЪ§ОнДІРэЕФЭЬЭТСПКЭадФмЁЃ
ЯрЖдгкStormЕФКСУыМЖбгГйРДЫЕЃЌSpark StreamingЕФбгГйзюЖржЛФмЕНМИАйКСУыЃЌвЛАуЪЧУыМЖЩѕжСЗжжгМЖЃЌвђДЫЖдгкЪЕЪБЪ§ОнДІРэбгГйвЊЗЧГЃИпЕФГЁКЯЃЌSpark
StreamingВЂВЛКЯЪЪЁЃ
СэЭтЃЌSpark StreamingЕзВувРРЕгкSpark Core ЕФRDDЪЕЯжЃЌМДЫќКЭSparkПђМмећЬхЪЧАѓЖЈдквЛЦ№ЕФЃЌетЪЧгХЕувВЪЧШБЕуЁЃ
ЖдгквбОВЩгУSpark зїЮЊДѓЪ§ОнДІРэПђМмЃЌЭЌЪБЖдЪ§ОнбгГйадвЊЧѓВЛЪЧКмИпЕФГЁКЯЃЌSpark
StreamingЗЧГЃЪЪКЯзїЮЊЪТЪЕСїДІРэЕФЙЄОпКЭЗНАИЃЌдвђШчЯТЃК
1ЁЂSpark StreamingФкВПЕФЪЕЯжКЭЕїЖШЗНЪНИпЖШвРРЕгкSparkЕФDAGЕїЖШЦїКЭRDDЃЌSpark
StreamingЕФРыЩЂСїЃЈDStreamЃЉБОжЪЩЯЪЧRDDдкСїЪНЪ§ОнЩЯЕФГщЯѓЃЌвђДЫЪьЯЄSparkКЭ
КЭRDDИХФюЕФгУЛЇЗЧГЃШнвзРэНтSpark StreamingвбОЦфDSreamЁЃ
2ЁЂSparkЩЯИїИізщМўБрГЬФЃаЭЖМЪЧРрЫЦЕФЃЌЫљвдШчЙћЪьЯЄSparkЕФAPIЃЌФЧУДЖдSpark
StreamingЕФAPIвВЗЧГЃШнвзЩЯЪжКЭеЦЮеЁЃ
ЕЋЪЧЃЌШчЙћвбОВЩгУСЫЦфЫћжюШчHadoopКЭStormЕФЪ§ОнДІРэЗНАИЃЌФЧУДШчЙћЪЙгУSpark
StreamingЃЌдђУцСйзХSparkвдМАSpark StreamingЕФИХФюМАдРэЕФбЇЯАГЩБОЁЃ
змЬхРДЫЕЃЌSpark StreamingзїЮЊSparkКЫаФAPIЕФвЛИіРЉеЙЃЌЫќЖдЪЕЪБСїЪНЪ§ОнЕФДІРэОпгаПЩРЉеЙадЁЂИпЭЬЭТСПЁЂКЭПЩвдШнДэадЕШЬиЕуЁЃ
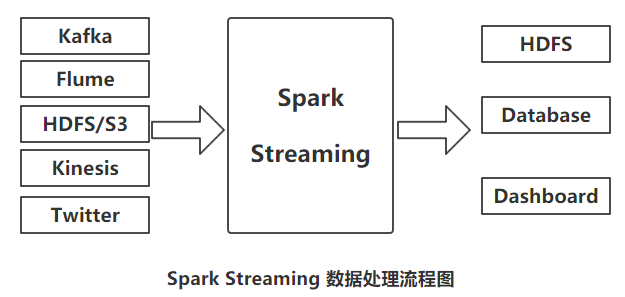
ЭЌЦфЫћСїДІРэПђМмвЛбљЃЌSpark StreamingДгKafkaЁЂFlumeЁЂTwitterЁЂZeroMQЁЂKinesisЕШдДЭЗЛёШЁЪ§ОнЃЌВЂmapЁЂreduceЁЂjoinЁЂwindowЕШзщГЩЕФИДдгЫуЗЈМЦЫуГіЦкЭћЕФНсЙћЃЌДІРэ
КѓЕФНсЙћЪ§ОнПЩБЛЭЦЫЭЕНЮФМўЯЕЭГЃЌЪ§ОнПтЁЂЪЕЪБвЧБэХЬжаЃЌЕБШЛЃЌвВПЩвдНЋДІРэКѓЕФЪ§ОнгІгУЕНSparkЕФЛњЦїбЇЯАЫуЗЈЁЂЭМДІРэЫуЗЈжаЁЃећИіЕФЪ§ОнДІРэСїГЬШчЯТЃК
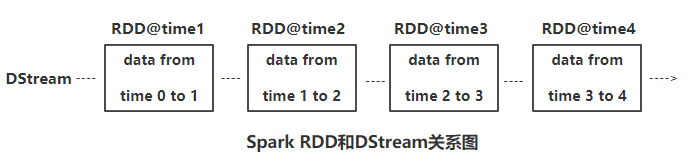
3.1ЁЂSpark StreamingЛљБОдРэ Spark Streaming жаЛљБОЕФГщЯѓЪЧРыЩЂСїЃЈМДDStreamЃЉ.DStreamДњБэвЛИіСЌајЕФЪ§ОнСїЁЃдкSpark
StreamingФкВПжаЃЌDStreamЪЕМЪЩЯЪЧгЩвЛЯЕСаСЌајRDDзщГЩЁЃУПИіRDDАќКЌШЗЖЈ
ЪБМфМфИєФкЕФЪ§ОнЃЌетаЉРыЩЂЕФRDDСЌдквЛЦ№ЃЌЙВЭЌзщГЩСЫЖдгІЕФDStreamЁЃ
ЪЕМЪЩЯШЮКЮЃЌШЮКЮЖдDStreamЕФВйзїЖМзЊЛЛГЩСЫЖдDStreamвўКЌЕФвЛЯЕСаЖдгІRDDЕФВйзїЃЌШчЩЯЭМжаЖдlines
DStreamЪЧЕФflatMapВйзїЃЌЪЕМЪЩЯгІгУгкlinesЖдгІУПИіRDDЕФВйзїЃЌВЂЩњГЩСЫ
ЖдгІЕФwork DStreamЕФRDDЁЃ
вВОЭЪЧЩЯУцЫљЫЕЕФЃЌSpark StreamingЕзВувРРЕгкSpark CoreЕФRDDЪЕЯжЁЃДгБОжЪЩЯРДЫЕЃЌSpark
StreamingжЛВЛЙ§ЪЧНЋСїЪНЕФЪ§ОнСїИљОнЩшЖЈЕФМфИєЗжГЩСЫвЛЯЕСаЕФRDDЃЌШЛКѓдкУПИіRDDЩЯ
гІгУЯргІЕФИїжжВйзїКЭазїЃЌЫљвдSpark StreamingЕзВуЕФдЫаав§ЧцЪЕМЪЩЯЪЧSpark
CoreЁЃ
3.2ЁЂSpark StreamingКЫаФAPI
SparkStreamingЭъећЕФAPIАќРЈ StreamingContextЁЂDStream
ЪфШыЁЂDStream ЩЯЕФИїжжВйзїКЭЖЏзїЁЂDStreamЪфГіЕШЁЃ
1ЁЂStreamingContext
ЮЊСЫГѕЪМЛЏSpark StreamingГЬађЃЌБиаыДДНЈвЛИіStreamingContextЖдЯѓЃЌИУЖдЯѓЪЧSpark
StreamingЫљгаСїВйзїЕФжївЊШыПкЁЃвЛИіStreamingContext ЖдЯѓПЩвдгУSparkConfЖдЯѓДДНЈЃК
import
org.apache.spark.*;
import org.apache.spark.streaming.api.Java.*;
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaStreamingContext ssc = new JavaStreamingContext(conf,
new Duration(1000)); |
2ЁЂDStreamЪфШы
DStreamЪфШыБэЪОДгЪ§ОндДЛёШЁЕФдЪМЪ§ОнСїЁЃУПИіЪфШыСїDStreamКЭвЛИіНгЪеЦї(receiver)ЖдЯѓЯрЙиСЊЃЌетИіReceiverДгдДжаЛёШЁЪ§ОнЃЌВЂНЋЪ§ОнДцШыФкДцжагУгкДІРэЁЃ
Spark StreamingгаСНРрЪ§ОндДЃК
ЛљБОдД(basic source)ЃКдкStreamingContext APIжажБНгПЩгУЕФдДЭЗЃЌР§ШчЮФМўЯЕЭГЁЂЬзНгзжСЌНгЁЂAkkaЕФactorЕШЁЃ
ИпМЖдД(advanced source)ЃКАќРЈ KafkaЁЂFlumeЁЂKinesisЁЂTiwtterЕШЃЌЫћУЧашвЊЭЈЙ§ЖюЭтЕФРрРДЪЙгУЁЃ
3ЁЂDStreamЕФзЊЛЛ
КЭRDDРрЫЦЃЌtransformationгУРДЖдЪфШыDStreamsЕФЪ§ОнНјаазЊЛЛЁЂаоИФЕШИїжжВйзїЃЌЕБШЛЃЌDStreamвВжЇГжКмЖрдкSpark
RDDЕФtransformationЫузгЁЃ
4ЁЂDStreamЕФЪфГі
КЭRDDРрЫЦЃЌSpark StreamingдЪаэНЋDStreamзЊЛЛКѓЕФНсЙћЗЂЫЭЕНЪ§ОнПтЁЂЮФМўЯЕЭГЕШЭтВПЯЕЭГжаЁЃФПЧАЃЌЖЈвхСЫSpark
StreamingЕФЪфГіВйзїЃК
4ЁЂSpark StreamingЪЕЪБПЊЗЂЪЕР§ ЯТУцгУзжЗћМЦЪ§етИіР§згРДЫЕУї Spark Streming
ЪзЯШЃЌЕМШы Spark StreamingЕФЯрЙиРрЕНЛЗОГжаЃЌетаЉРрЃЈШчDStreamЃЉЬсЙЉСЫСїВйзїКмЖргагУЕФЗНЗЈЃЌStreamingContextЪЧSparkЫљгаСїВйзїЕФжївЊШыПкЁЃ
ЦфДЮЃЌДДНЈвЛИіОпгаСНИіжДааЯпГЬвдМА1УыХњМфИєЪБМфЃЈМДвдУыЮЊЕЅЮЛЗжИєЪ§ОнСїЃЉЕФБОЕиStreamingContext.
import org.apache.spark.{*,
SparkConf}
import org.apache.spark.api.java.function.*
import org.apache.spark.streaming.{*, Duration,
Durations}
import org.apache.spark.streaming.api.java.{*,
JavaDStream, JavaStreamingContext}
import scala.Tuple2;
object streaming_test {
def main(args: Array[String]): Unit = {
//ДДНЈвЛИіБОЕиЕФStreamingContextЩЯЯТЮФЖдЯѓЃЌИУЖдЯѓАќКЌСНИіЙЄзїЯпГЬЃЌХњДІРэМфИєЮЊ1Уы
val conf = new SparkConf().setMaster("local[2]").setAppName("Network-WordCount");
val jssc = new JavaStreamingContext(conf,Durations.seconds(1));
//РћгУетИіЩЯЯТЮФЃЌФмЙЛДДНЈвЛИіDStream,ЫќБэЪОДгTCPдДЃЈжїЛњЮЊlocalhost,ЖЫПкЮЊ9999ЃЉЛёШЁЕФСїЪНЪ§Он
//ДДНЈвЛИіСЌНгЕНhostname:portЕФDStreamЖдЯѓЃЌРрЫЦlocalhost:9999
val lines =jssc.socketTextStream("localhost",9999);
//етИіlinesБфСПЪЧвЛИіDStream,БэЪОМДНЋДгЪ§ОнЗўЮёЦїЛђЕФЪ§ОнСїЃЌетИіDStreamЕФУПЬѕМЧТМЖМДњБэвЛааЮФБОЃЌ
// НгЯТРДашвЊНЋDStreamжаЕФУПааЮФБОЖМЧаЗжЮЊЕЅДЪ
val words =lines.flatMap(x:String => util.Arrays.asList(x.split("
")).iterator());
val pairs =words.mapToPair<s=>new Tuple2<>(s,1));
val wordCounts =pairs.reduceByKey((i1,i2)=>
i1+i2);
wordCounts.print();
}
} |
5ЁЂSpark StreamingЕїгХЪЕМљ
Spark StreamingзївЕЕФЕїгХЭЈГЃЖМЩцМАзївЕПЊЗЂЕФгХЛЏЁЂВЂааЖШЕФгХЛЏКЭХњДѓаЁвдМАФкДцЕШзЪдДЕФгХЛЏЁЃ
5.1ЁЂзївЕПЊЗЂгХЛЏ
RDDИДгУЃКЖдгкЪЕЪБзївЕЃЌгШЦфЪЧСДТЗНЯГЄЕФзївЕЃЌвЊОЁСПжиИДЪЙгУRDDЃЌЖјВЛЪЧжиИДДДНЈЖрИіRDDЁЃСэЭташвЊЖрДЮЪЙгУЕФжаМфRDDЃЌПЩвдНЋЦфГжОУЛЏЃЌвдНЕЕЭУПДЮЖМашвЊжиИДМЦЫуЕФПЊЯњЁЃ
ЪЙгУаЇТЪНЯИпЕФshuffleЫузгЃКШчЭЌHadoopжаЕФзївЕвЛбљЃЌЪЕЪБзївЕЕФshuffleВйзїЛсЩцМАЪ§ОнжиаТЗжВМЃЌвђДЫЛсКФЗбДѓСПЕФФкДцЁЂЭјТчКЭМЦЫуЕШзЪдДЃЌашвЊОЁСПНЕЕЭашвЊshuffleЕФЪ§ОнСПЃЌ
reduceByKey/aggregateByKeyЯрБШgroupByKey,ЛсдкmapЖЫЯШНјаадЄОлКЯЃЌвђДЫаЇТЪНЯИпЁЃ
РрЫЦгкHiveЕФMapJoinЃКЖдгкЪЕЪБзївЕЃЌjoinвВЛсЩцМАЪ§ОнЕФжиаТЗжВМЃЌвђДЫШчЙћЪЧДѓЪ§ОнСПЕФRDDКЭаЁЪ§ОнСПЕФRDDНјааjoinЃЌПЩвдЭЈЙ§broadcastгыmapВйзїЪЕЯжРрЫЦгкHiveЕФMapJoinЃЌ
ЕЋЪЧашвЊзЂвтаЁЪ§СПЕФRDDВЛФмЙ§ДѓЃЌВЛШЛЙуВЅЪ§ОнЕФПЊЯњвВКмДѓЁЃ
ЦфЫќИпаЇЕФР§згЃКШчЪЙгУmapPartitionsЬцДњЦеЭЈmap,ЪЙгУforeachPartitions
ЬцДњforeachЃЌЪЙгУ repartitionAndSortWithinPartitions ЬцДњ
repartition гы sortРрВйзїЕШЁЃ
5.2ЁЂВЂааЖШКЭХњДѓаЁ
ЖдгкSpark StreamingетжжЛљгкЮЂХњДІРэКЭЪЕЪБДІРэПђМмРДЫЕЃЌЦфЕїгХВЛЭтКѕСНЕуЃК
вЛЪЧОЁСПЫѕЖЬУПвЛХњДЮЕФДІРэЪБМф
ЖўЪЧЩшжУКЯЪЪЕФbatch size(МДУПХњДІРэЕФЪ§ОнСП)ЃЌЪЙЕУЪ§ОнДІРэЕФЫйЖШФмЙЛЪЪХфЪ§ОнСїШыЕФЫйЖШЁЃ
ЕквЛЕуЭЈГЃвдЩшжУдДЭЗЁЂДІРэЁЂЪфГіЕФВЂЗЂЖШРДЪЕЯжЁЃ
дДЭЗВЂЗЂЃКШчЙћдДЭЗЕФЪфШыШЮЮёЪЧЪЕЪБзївЕЕФЦПОБЃЌФЧУДПЩвдЭЈЙ§МгДѓдДЭЗЕФВЂЗЂЖШЬсЙЉадФмЃЌРДБЃжЄЪ§ОнФмЙЛСїШыКѓајЕФДІРэСДТЗЁЃдкSpark
StreamingЃЌПЩвдЭЈЙ§ШчЯТДњТыРДЪЕЯжЃЈвЛKafkaдДЭЗЮЊР§ЃЉЃК
int numStreams
= 5;
List<JavaPairDStream<String,String>>
kafkaStreams = new ArrayList<JavaPairDStream<String,String>>(numStreams
);
for(int i=0;i<numStreams ;i++){
kafkaStreams.add(KafkaUtils.createStream(...))ЃЛ
}
JavaPairDStream<String,String>
unifiedStream = streamingContext.union( kafkaStreams.get(0),
kafkaStreams.subList(1, kafkaStreams.size())); |
ДІРэВЂЗЂЃКДІРэШЮЮёЕФВЂЗЂОіЖЈСЫЪЕМЪзївЕжДааЕФЮяРэЪгЭМЁЃSpark StreamingзївЕЕФФЌШЯВЂЗЂЖШПЩвдЭЈЙ§spark.default.parllelismРДЩшжУЃЌЕЋЪЧЪЕМЪжаВЛЭЦМіЃЌНЈвщеыЖдУПИіШЮЮёЕЅЖРЩшжУЗЂЖШНјааОЋЯИПижЦЁЃ
ЪфГіВЂЗЂЃКШчЭМHadoopзївЕвЛбљЃЌЪЕЪБзївЕЕФshuffleВйзїЛсЩцМАЪ§ОнжиаТЗжВМЃЌвђДЫЛсКФЗбДѓСПЕФФкДцЁЂЭјТчКЭМЦЫуЕШзЪдДЃЌвђДЫашвЊОЁСПМѕЩйshuffleВйзїЁЃ
batch sizeЃКbatch sizeжївЊгАЯьЯЕЭГЕФЭЬЭТСПКЭбгГйЁЃbatch size
ЬЋаЁЃЌвЛАуДІРэбгГйЛсНЕЕЭЃЌЕЋЪЧЯЕЭГЭЬЭТСПЛсЯТНЕЃЛbatch sizeЬЋДѓЃЌЭЬЭТСПЩЯШЅСЫЃЌЕЋЪЧДІРэбгГйЛсЬсИпЃЌЭЌЪБвЊЧѓЕФ
ФкДцвВЛсдіМгЃЌвђДЫЪЕМЪжаашвЊевЕНвЛИіЦНКтЕуЃЌМШФмТњзуЭЬЭТСПвВФмТњзубгГйЕФвЊЧѓЃЌФЧУДЪЕМЪжаШчКЮЩшжУbatchДѓаЁФиЃП
|









