| БрМЭЦМі: |
| ЙЄзїжаЪЙгУЕНСЫhiveЃЌmysqlЕШЪ§ОнПтЃЌВЛЭЌЕФЪ§ОнПтгаВЛЭЌЕФгІгУГЁОАЃЌИУШчКЮе§ШЗЕФбЁдёЪ§ОнДцДЂгыДІРэЗНЪНЃЌашвЊСЫНтЕзВудРэЃЌВХФмЩйзпЭфТЗЃЌБОЮФжївЊЪЧМЧТМвЛЯТhiveЕФЪЕЯждРэвдМАвЛаЉЖдгІЕФИХФюЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Front
дкПЊЪМСЫНтhiveжЎЧАЃЌашвЊСЫНтвЛаЉжЊЪЖЛђепИХФюЃЌПЩвдИќКУЕФРэНтhiveЪЕЯждРэ
MapReduce
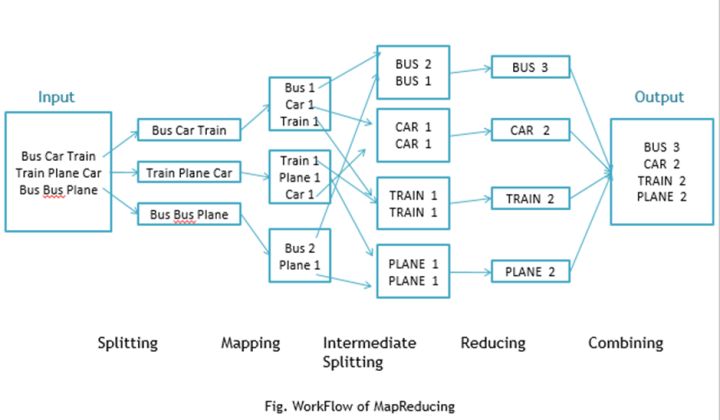
Google MapReduceЪЧGoogleЛљгкКЏЪ§ЪНБрГЬmapЃЈгГЩфЃЉЃЌreduceЃЈЛЏМђЃЉЬсГіЕФвЛжжЗжВМЪНБрГЬФЃаЭЃЌдкФЃаЭжавўВиСЫЗжВМЪНМЏШКЕФЪЕЯжЯИНкЃЌНЛгЩПђМмЕзВуНјааЪЕЯжЃЌФмЙЛЪЙГЬађдБдкВЛСЫНтЗжВМЪНВЂааБрГЬЕФЧщПіЯТЃЌНЋздМКЪщаДЕФГЬађдкЗжВМЪНЯЕЭГЩЯдЫаа
БрГЬФЃаЭ
Map: НЋЪфШыЕФвЛЖдМќжЕЖдзЊЛЛЮЊвЛзщжаМфМќжЕЖд ЃЈk1,v1) -> list(k2,v2)
Reduce: НЋЫљгаМќЯрЭЌЕФжаМфМќжЕЖдКЯВЂЃЌЕУЕНЙигкФЧИіМќЕФНсЙћ (k2,list(v2)) ->
(k2,v3)
ОйИіРѕзг
вдвЛИіКмМђЕЅЕФWordCountЮЊР§згЃЌМйЩшИјЖЈДѓСПЪ§ОнЕФЮФЕЕЃЌМЦЫуЦфжаУПИіЕЅДЪГіЯжЕФДЮЪ§ЃЌЯТУцЪЧЮБДњТы
map(String key,String
value,Context context){
// key: document name
// value: document contents
String[] words = value.split(separator);
for(String word:words){
context.write(word,1);
}
}
reduce(String word,Iterable<Integer>
values,Context context){
int sum = 0;
for(Integer value:values){
sum += value;
}
con.write(word,sum);
} |
ИќЖрЕФРѕзг
МЦЫу URL ЗУЮЪЦЕТЪЃКMap КЏЪ§ДІРэШежОжа web вГУцЧыЧѓЕФМЧТМЃЌШЛКѓЪфГі(URL,1)ЁЃReduce
КЏЪ§АбЯрЭЌURL ЕФ value жЕЖМРлМгЦ№РДЃЌВњЩњ(URL,МЧТМзмЪ§)НсЙћЁЃ
ЕЙзЊЭјТчСДНгЭМЃКMap КЏЪ§дкдДвГУцЃЈsourceЃЉжаЫбЫїЫљгаЕФСДНгФПБъЃЈtargetЃЉВЂЪфГіЮЊ(target,source)ЁЃ
Reduce КЏЪ§АбИјЖЈСДНгФПБъЃЈtargetЃЉЕФСДНгзщКЯГЩвЛИіСаБэЃЌЪфГі(target,list(source))ЁЃ
ЕЙХХЫїв§ЃКMap КЏЪ§ЗжЮіУПИіЮФЕЕЪфГівЛИі(ДЪ,ЮФЕЕКХ)ЕФСаБэЃЌReduce КЏЪ§ЕФЪфШыЪЧвЛИіИјЖЈДЪЕФЫљга
ЃЈДЪЃЌЮФЕЕКХЃЉЃЌХХађЫљгаЕФЮФЕЕКХЃЌЪфГі(ДЪ,listЃЈЮФЕЕКХЃЉ)ЁЃЫљгаЕФЪфГіМЏКЯаЮГЩвЛИіМђЕЅЕФЕЙХХЫїв§ЃЌЫќ
вдвЛжжМђЕЅЕФЫуЗЈИњзйДЪдкЮФЕЕжаЕФЮЛжУЁЃ
УПИіжїЛњЕФМьЫїДЪЯђСПЃКМьЫїДЪЯђСПгУвЛИі(ДЪ,ЦЕТЪ)СаБэРДИХЪіГіЯждкЮФЕЕЛђЮФЕЕМЏжаЕФзюживЊЕФвЛаЉ ДЪЁЃMap
КЏЪ§ЮЊУПвЛИіЪфШыЮФЕЕЪфГі(жїЛњУћ,МьЫїДЪЯђСП)ЃЌЦфжажїЛњУћРДздЮФЕЕЕФ URLЁЃReduce КЏЪ§НгЪеИј
ЖЈжїЛњЕФЫљгаЮФЕЕЕФМьЫїДЪЯђСПЃЌВЂАбетаЉМьЫїДЪЯђСПМгдквЛЦ№ЃЌЖЊЦњЕєЕЭЦЕЕФМьЫїДЪЃЌЪфГівЛИізюжеЕФ(жїЛњУћ,МьЫїДЪЯђСП)ЁЃ
ЯЕЭГЪЕЯж
ЪзЯШЃЌгУЛЇЭЈЙ§ MapReduce ПЭЛЇЖЫжИЖЈ Map КЏЪ§КЭ Reduce КЏЪ§ЃЌвдМАДЫДЮ MapReduce
МЦЫуЕФХфжУЃЌАќРЈжаМфНсЙћМќжЕЖдЕФ Partition Ъ§СП R вдМАгУгкЧаЗжжаМфНсЙћЕФЙўЯЃКЏЪ§ hash
ЁЃ гУЛЇПЊЪМ MapReduce МЦЫуКѓЃЌећИі MapReduce МЦЫуЕФСїГЬПЩзмНсШчЯТЃК
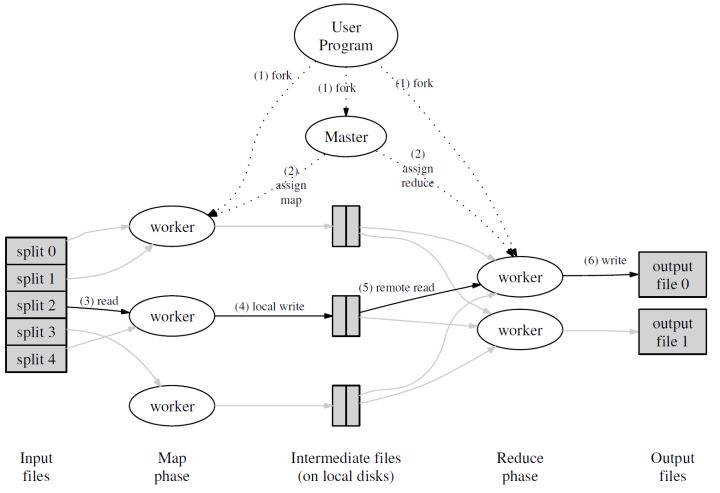
зїЮЊЪфШыЕФЮФМўЛсБЛЗжЮЊ M Иі SplitЃЌУПИі Split ЕФДѓаЁЭЈГЃдк 16~64 MB жЎМф
ШчДЫЃЌећИі MapReduce МЦЫуАќКЌ M ИіMap ШЮЮёКЭ R Иі Reduce ШЮЮёЁЃMaster
НсЕуЛсДгПеЯаЕФ Worker НсЕужаНјаабЁШЁВЂЮЊЦфЗжХф Map ШЮЮёКЭ Reduce ШЮЮё
ЪеЕН Map ШЮЮёЕФ Worker УЧЃЈгжГЦ MapperЃЉПЊЪМЖСШыздМКЖдгІЕФ SplitЃЌНЋЖСШыЕФФкШнНтЮіЮЊЪфШыМќжЕЖдВЂЕїгУгЩгУЛЇЖЈвхЕФ
Map КЏЪ§ЁЃгЩ Map КЏЪ§ВњЩњЕФжаМфНсЙћМќжЕЖдЛсБЛднЪБДцЗХдкЛКГхФкДцЧјжа
дк Map НзЖЮНјааЕФЭЌЪБЃЌMapper УЧжмЦкадЕиНЋЗХжУдкЛКГхЧјжаЕФжаМфНсЙћДцШыЕНздМКЕФБОЕиДХХЬжаЃЌЭЌЪБИљОнгУЛЇжИЖЈЕФ
Partition КЏЪ§ЃЈФЌШЯЮЊ hash(key) mod RЃЉНЋВњЩњЕФжаМфНсЙћЗжЮЊ R ИіВПЗжЁЃШЮЮёЭъГЩЪБЃЌMapper
БуЛсНЋжаМфНсЙћдкЦфБОЕиДХХЬЩЯЕФДцЗХЮЛжУБЈИцИј Master
Mapper ЩЯБЈЕФжаМфНсЙћДцЗХЮЛжУЛсБЛ Master зЊЗЂИј ReducerЁЃЕБ Reducer
НгЪеЕНетаЉаХЯЂКѓБуЛсЭЈЙ§ RPC ЖСШЁДцДЂдк Mapper БОЕиДХХЬЩЯЪєгкЖдгІ Partition
ЕФжаМфНсЙћЁЃдкЖСШЁЭъБЯКѓЃЌReducer ЛсЖдЖСШЁЕНЕФЪ§ОнНјааХХађвдСюгЕгаЯрЭЌМќЕФМќжЕЖдФмЙЛСЌајЗжВМ
жЎКѓЃЌReducer ЛсЮЊУПИіМќЪеМЏгыЦфЙиСЊЕФжЕЕФМЏКЯЃЌВЂвджЎЕїгУгУЛЇЖЈвхЕФ Reduce КЏЪ§ЁЃReduce
КЏЪ§ЕФНсЙћЛсБЛЗХШыЕНЖдгІЕФ Reduce Partition НсЙћЮФМў
ЪЕМЪЩЯЃЌдквЛИі MapReduce МЏШКжаЃЌMaster ЛсМЧТМУПвЛИі Map КЭ Reduce ШЮЮёЕФЕБЧАЭъГЩзДЬЌЃЌвдМАЫљЗжХфЕФ
WorkerЁЃГ§ДЫжЎЭтЃЌMaster ЛЙИКд№НЋ Mapper ВњЩњЕФжаМфНсЙћЮФМўЕФЮЛжУКЭДѓаЁзЊЗЂИј
ReducerЁЃ
жЕЕУзЂвтЕФЪЧЃЌУПДЮ MapReduce ШЮЮёжДааЪБЃЌ M КЭ R ЕФжЕЖМгІБШМЏШКжаЕФ Worker
Ъ§СПвЊИпЕУЖрЃЌвдДяГЩМЏШКФкИКдиОљКтЕФаЇЙћЁЃ
СаЪНДцДЂ
ЪВУДЪЧСаЪНДцДЂ
ДЋЭГЪТЮёаЭЪ§ОнПтЭЈГЃВЩгУааЪНДцДЂЁЃвдЯТЭМЮЊР§ЃЌЫљгаЕФСавРДЮХХСаЙЙГЩвЛааЃЌвдааЮЊЕЅЮЛДцДЂЃЌдйХфКЯвд B+
ЪїзїЮЊЫїв§ЃЌОЭФмПьЫйЭЈЙ§жїМќевЕНЯргІЕФааЪ§ОнЁЃ
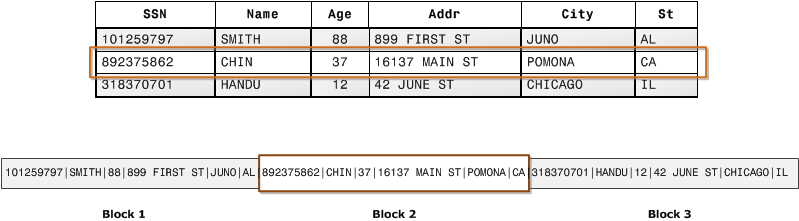
ааЪНДцДЂЖдгк OLTPЃЈСЊЛњЪТЮёДІРэЃЉ ГЁОАЪЧКмздШЛЕФЃКДѓЖрЪ§ВйзїЖМвдЪЕЬхЃЈentityЃЉЮЊЕЅЮЛЃЌМДДѓЖрЮЊдіЩОИФВщвЛећааМЧТМЃЌЯдШЛАбвЛааЪ§ОнДцдкЮяРэЩЯЯрСкЕФЮЛжУЪЧИіКмКУЕФбЁдёЁЃ
ШЛЖјЃЌЖдгк OLAP ЃЈСЊЛњЗжЮіДІРэЃЉГЁОАЃЌвЛИіЕфаЭЕФВщбЏашвЊБщРњећИіБэЃЌНјааЗжзщЁЂХХађЁЂОлКЯЕШВйзїЃЌетбљвЛРДАДааДцДЂЕФгХЪЦОЭВЛИДДцдкСЫЁЃИќдуИтЕФЪЧЃЌЗжЮіаЭ
SQL ГЃГЃВЛЛсгУЕНЫљгаЕФСаЃЌЖјНіНіЖдЦфжаФГаЉИааЫШЄЕФСазідЫЫуЃЌФЧвЛаажаФЧаЉЮоЙиЕФСавВВЛЕУВЛВЮгыЩЈУшЁЃ
СаЪНДцДЂОЭЪЧЮЊетбљЕФашЧѓЩшМЦЕФЁЃШчЯТЭМЫљЪОЃЌЭЌвЛСаЕФЪ§ОнБЛвЛИіНгвЛИіНєАЄзХДцЗХдквЛЦ№ЃЌБэЕФУПСаЙЙГЩвЛИіГЄЪ§зщЁЃ
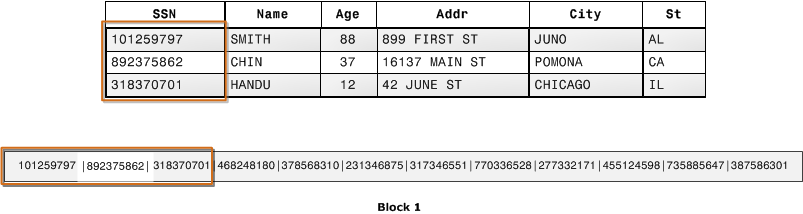
ЯдШЛЃЌСаЪНДцДЂЖдгк OLTP ВЛгбКУЃЌвЛааЪ§ОнЕФаДШыашвЊЭЌЪБаоИФЖрИіСаЁЃЕЋЖд OLAP ГЁОАгазХКмДѓЕФгХЪЦЃК
ЕБВщбЏгяОфжЛЩцМАВПЗжСаЪБЃЌжЛашвЊЩЈУшЯрЙиЕФСа
УПвЛСаЕФЪ§ОнЖМЪЧЯрЭЌРраЭЕФЃЌБЫДЫМфЯрЙиадИќДѓЃЌЖдСаЪ§ОнбЙЫѕЕФаЇТЪНЯИп
СаЪНДцДЂгыЗжВМЪНЮФМўЯЕЭГ
дкЯжДњЕФДѓЪ§ОнМмЙЙжаЃЌGFSЁЂHDFS ЕШЗжВМЪНЮФМўЯЕЭГвбОГЩЮЊДцЗХДѓЙцФЃЪ§ОнМЏЕФжїСїЗНЪНЁЃЗжВМЪНЮФМўЯЕЭГЯрБШЕЅЛњЩЯЕФДХХЬЃЌОпБИЖрИББОИпПЩгУЁЂШнСПДѓЁЂГЩБОЕЭЕШжюЖргХЪЦЃЌЕЋвВДјРДСЫвЛаЉЕЅЛњМмЙЙЫљУЛгаЕФЮЪЬтЃК
ЖСаДОљвЊОЙ§ЭјТчЃЌЭЬЭТСППЩвдзЗЦНЩѕжСГЌЙ§гВХЬЃЌЕЋЪЧбгГйвЊБШгВХЬДѓЕУЖрЃЌЧвЪмЭјТчЛЗОГгАЯьКмДѓЁЃ
ПЩвдНјааДѓЭЬЭТСПЕФЫГађЖСаДЃЌЕЋЫцЛњЗУЮЪадФмКмВюЃЌДѓЖрВЛжЇГжЫцЛњаДШыЁЃЮЊСЫЕжЯћЭјТчЕФ overheadЃЌЭЈГЃаДШыЖМвдМИЪЎ
MB ЮЊЕЅЮЛЁЃ ЩЯЪіШБЕуЖдгкжиЖШвРРЕЫцЛњЖСаДЕФ OLTP ГЁОАРДЫЕЪЧжТУќЕФЁЃЫљвдЮвУЧПДЕНЃЌКмЖрЖЈЮЛгк
OLAP ЕФСаЪНДцДЂбЁдёЗХЦњ OLTP ФмСІЃЌДгЖјФмЙЙНЈдкЗжВМЪНЮФМўЯЕЭГжЎЩЯЁЃ
вЊЯыНЋЗжВМЪНЮФМўЯЕЭГЕФадФмЗЂЛгЕНМЋжТЃЌЮоЗЧгаМИжжЗНЗЈЃКАДПщЃЈЗжЦЌЃЉЖСШЁЪ§ОнЁЂСїЪНЖСШЁЁЂзЗМгаДШыЕШЁЃЮвУЧдкКѓУцЛсПДЕНвЛаЉПЊдДНчСїааЕФСаЪНДцДЂФЃаЭЃЌНЋетаЉгХЛЏЗНЗЈЬхЯждкДцДЂИёЪНЕФЩшМЦжаЁЃ
СаЪНДцЭГДЂЯЕАИР§
Apache ORC
Apache ORC зюГѕЪЧЮЊжЇГж Hive ЩЯЕФ OLAP ВщбЏПЊЗЂЕФвЛжжЮФМўИёЪНЃЌШчНёдк Hadoop
ЩњЬЌЯЕЭГжагаЙуЗКЕФгІгУЁЃORC жЇГжИїжжИёЪНЕФзжЖЮЃЌАќРЈГЃМћЕФ intЁЂstring ЕШЃЌвВАќРЈ structЁЂlistЁЂmap
ЕШзщКЯзжЖЮЃЛзжЖЮЕФ meta аХЯЂОЭЗХдк ORC ЮФМўЕФЮВВПЃЈетБЛГЦЮЊздУшЪіЕФЃЉЁЃ
Ъ§ОнНсЙЙМАЫїв§
ЮЊЗжЧјЙЙдьЫїв§ЪЧвЛжжГЃМћЕФгХЛЏЗНАИЃЌORC ЕФЪ§ОнНсЙЙЗжГЩвдЯТ 3 ИіВуМЖЃЌдкУПИіВуМЖЩЯЖМгаЫїв§аХЯЂРДМгЫйВщбЏ
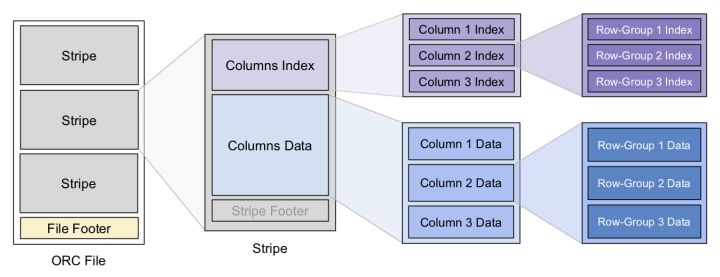
File LevelЃКМДвЛИі ORC ЮФМўЃЌFooter жаБЃДцСЫЪ§ОнЕФ meta аХЯЂЃЌЛЙгаЮФМўЪ§ОнЕФЫїв§аХЯЂЃЌР§ШчИїСаЪ§ОнЕФзюДѓзюаЁжЕЃЈЗЖЮЇЃЉЁЂNULL
жЕЗжВМЁЂВМТЁЙ§ТЫЦїЕШЃЌетаЉаХЯЂПЩгУРДПьЫйШЗЖЈИУЮФМўЪЧЗёАќКЌвЊВщбЏЕФЪ§ОнЁЃУПИі ORC ЮФМўжаАќКЌЖрИі
StripeЁЃ
Stripe Level ЖдгІдБэЕФвЛИіЗЖЮЇЗжЧјЃЌРяУцАќКЌИУЗжЧјФкИїСаЕФжЕЁЃУПИі Stripe вВгаздМКЕФвЛИіЫїв§ЗХдк
footer РяЃЌКЭ file-level Ыїв§РрЫЦЁЃ
Row-Group Level ЃКвЛСажаЕФУП 10000 ааЪ§ОнЙЙГЩвЛИі row-groupЃЌУПИі
row-group гЕгаздМКЕФ row-level Ыїв§ЃЌаХЯЂЭЌЩЯ
ORC РяЕФ Stripe ОЭЯёДЋЭГЪ§ОнПтЕФвГЃЌЫќЪЧ ORC ЮФМўХњСПЖСаДЕФЛљБОЕЅЮЛЁЃетЪЧгЩгкЗжВМЪНДЂДцЯЕЭГЕФЖСаДбгГйНЯДѓЃЌвЛДЮ
IO ВйзїжЛгаХњСПЖСШЁвЛЖЈСПЕФЪ§ОнВХЛЎЫуЁЃетКЭАДвГЖСаДДХХЬЕФЫМТЗвВгаЙВЭЈжЎДІЁЃ
ЯёЦфЫћКмЖрДЂДцИёЪНвЛбљЃЌORC бЁдёНЋЭГМЦЪ§ОнКЭ Metadata ЗХдк File КЭ Stripe
ЕФЮВВПЖјВЛЪЧЭЗВПЁЃЕЋ ORC дк Stripe ЕФЖСаДЩЯЛЙгавЛЕугХЛЏЃЌФЧОЭЪЧАбЗжЧјСЃЖШаЁгк Stripe
ЕФНсЙЙЃЈШч Column КЭ Row-GroupЃЉЕФЫїв§ЭГвЛГщШЁГіРДЗХЕН Stripe ЕФЭЗВПЁЃетЪЧвђЮЊдкХњДІРэМЦЫужавЛАуЪЧАбећИі
Stripe ЖСШыХњСПДІРэЕФЃЌНЋетаЉЫїв§ГщШЁГіРДПЩвдМѕЩйдкХњДІРэГЁОАЯТашвЊЕФ IOЃЈХњДІРэЖСШЁПЩвдЬјЙ§етвЛВПЗжЃЉЁЃ
Dremel (2010) / Apache Parquet
Dremel ЪЧ Google баЗЂЕФгУгкДѓЙцФЃжЛЖСЪ§ОнЕФВщбЏЯЕЭГЃЌгУгкНјааПьЫйЕФ ad-hoc ВщбЏЃЌУжВЙ
MapReduce НЛЛЅЪНВщбЏФмСІЕФВЛзуЁЃЮЊСЫБмУтЖдЪ§ОнЕФЖўДЮПНБДЃЌDremel ЕФЪ§ОнОЭЗХдкдДІЃЌЭЈГЃЪЧ
GFS етбљЕФЗжВМЪНЮФМўЯЕЭГЃЌЮЊДЫашвЊЩшМЦвЛжжЭЈгУЕФЮФМўИёЪНЁЃ
Dremel ЕФЯЕЭГЩшМЦКЭДѓЖр OLAP ЕФСаЪНЪ§ОнПтВЂЮоЬЋЖрДДаТЕуЃЌЕЋЪЧЦфОЋЧЩЕФДцДЂИёЪНШДБфЕУСїааЦ№РДЃЌApache
Parquet ОЭЪЧЫќЕФПЊдДИДПЬАцЁЃзЂвт Parquet КЭ ORC вЛбљЖМЪЧвЛжжДцДЂИёЪНЃЌЖјЗЧЭъећЕФЯЕЭГЁЃ
ЧЖЬзЪ§ОнФЃаЭ
Google ФкВПДѓСПЪЙгУ Protobuf зїЮЊПчЦНЬЈЁЂПчгябдЕФЪ§ОнађСаЛЏИёЪНЃЌЯрБШ JSON вЊИќНєДеВЂОпгаИќЧПЕФБэДяФмСІЁЃProtobuf
ВЛНідЪаэгУЛЇЖЈвхБиаыЃЈrequiredЃЉКЭПЩбЁЃЈoptinalЃЉзжЖЮЃЌЛЙдЪаэгУЛЇЖЈвх repeated
зжЖЮЃЌвтЮЖзХИУзжЖЮПЩвдГіЯж 0ЁЋN ДЮЃЌРрЫЦБфГЄЪ§зщЁЃ
Dremel ИёЪНЕФЩшМЦФПЕФОЭЪЧАДСаРДДцДЂ Protobuf ЕФЪ§ОнЁЃгЩгк repeated зжЖЮЕФДцдкЃЌетвЊБШАДСаДцДЂЙиЯЕаЭЕФЪ§ОнРЇФбвЛаЉЁЃвЛАуЕФЫМТЗПЩФмЪЧгУжежЙЗћБэЪОУПИі
repeat НсЪјЃЌЕЋЪЧПМТЧЕНЪ§ОнПЩФмКмЯЁЪшЃЌDremel в§ШыСЫвЛжжИќЮЊНєДеЕФИёЪНЁЃ
зїЮЊР§згЃЌЯТЭМзѓАыБпеЙЪОСЫЪ§ОнЕФ schema КЭ 2 Иі Document ЕФЪЕР§ЃЌгвАыБпЪЧађСаЛЏжЎКѓЕФИїИіСаЁЃађСаЛЏжЎКѓЕФСаЖрГіСЫ
RЁЂD СНСаЃЌЗжБ№ДњБэ Repetition Level КЭ Definition LevelЃЌЭЈЙ§етСНИіжЕОЭФмШЗБЃЮЈвЛЕиЗДађСаЛЏГідБОЕФЪ§ОнЁЃ
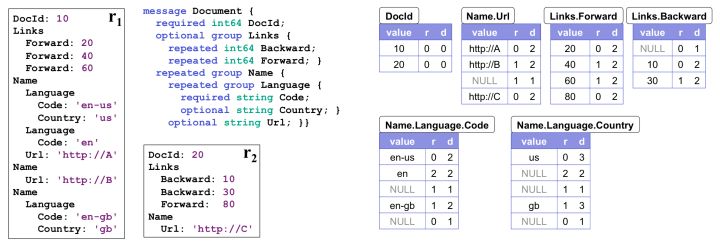
Repetition Level БэЪОЕБЧАжЕдкФФвЛИіМЖБ№ЩЯжиИДЁЃЖдгкЗЧ repeated зжЖЮжЛвЊЬюЩЯ
trivial жЕ 0 МДПЩЃЛЗёдђЃЌжЛвЊетИізжЖЮПЩФмГіЯжжиИДЃЈЮоТлБОЩэЪЧ repeated ЛЙЪЧЭтВуНсЙЙЪЧ
repeatedЃЉЃЌгІЕБЮЊ R ЬюЩЯЕБЧАжЕдкФФвЛВуЩЯ repeatЁЃ
ОйИіР§згЫЕУїЃКЖдгк Name.Language.Code ЮвУЧвЛЙВгаШ§ЬѕЗЧ NULL ЕФМЧТМЁЃ
ЕквЛИіЪЧ en-usЃЌГіЯждкЕквЛИі Name ЕФЕквЛИі Lanuage ЕФЕквЛИі Code РяУцЁЃдкДЫжЎЧАЃЌетШ§ИідЊЫиЪЧУЛгажиИДЙ§ЕФЃЌЖМЪЧЕквЛДЮГіЯжЁЃЫљвдЦф
R=0
ЕкЖўИіЪЧ enЃЌГіЯждкЯТвЛИі Language РяУцЁЃвВОЭЪЧЫЕ Language ЪЧжиИДЕФдЊЫиЁЃName.Language.Code
жаLanguage ХХЕкЖўИіЃЌЫљвдЦф R=2
ЕкШ§ИіЪЧ en-gbЃЌГіЯждкЯТвЛИі Name жаЃЌName ЪЧжиИДдЊЫиЃЌХХЕквЛИіЃЌЫљвдЦф R=1
зЂвтЕН en-gbЪЧЪєгкЕк3Иі Name ЕФЖјЗЧЕк2ИіNameЃЌЮЊСЫБэДяетИіЪТЪЕЃЌЮвУЧдк en КЭ
en-gbжаМфЗХСЫвЛИі R=1 ЕФ NULLЁЃ
Definition Level ЪЧЮЊСЫЫЕУї NULL БЛЖЈвхдкФФвЛВуЃЌвВОЭаћИцФЧвЛВуЕФ repeat
ЕНДЫЮЊжЙЁЃЖдгкЗЧ NULL зжЖЮжЛвЊЬюЩЯ trivial жЕЃЌМДЪ§ОнБОЩэЫљдкЕФ level МДПЩЁЃ
ЭЌбљОйИіР§згЃЌЖдгк Name.Language.Country Са
us ЗЧ NULL жЕЬюЩЯ Country зжЖЮЕФ level МД D=3
NULL дк R1 ФкВПЃЌБэЪОЕБЧА Name жЎФкЁЂКѓајЫљга Language ЖМВЛКЌга Country
зжЖЮЁЃЫљвдDЮЊ2ЁЃ
NULL дк R1 ФкВПЃЌБэЪОЕБЧА Document жЎФкЁЂКѓајЫљга Name ЖМВЛКЌга Country
зжЖЮЁЃЫљвдDЮЊ1ЁЃ
gb ЗЧ NULL жЕЬюЩЯ Country зжЖЮЕФ level МД D=3
NULL дк R2 ФкВПЃЌБэЪОКѓајЫљга Document ЖМВЛКЌга Country зжЖЮЁЃЫљвдDЮЊ0ЁЃ
ПЩвджЄУїЃЌНсКЯ RЁЂD СНИіЪ§жЕвЛЖЈФмЮЈвЛЙЙНЈГідЪМЪ§ОнЁЃЮЊСЫИпаЇБрНтТыЃЌDremel дкжДааЪБЪзЯШЙЙНЈГізДЬЌЛњЃЌжЎКѓРћгУзДЬЌЛњДІРэСаЪ§ОнЁЃВЛНіШчДЫЃЌзДЬЌЛњЛЙЛсНсКЯВщбЏашЧѓКЭЪ§ОнЕФ
structure жБНгЬјЙ§ЮоЙиЕФЪ§ОнЁЃ
Hive
hiveЪЕМЪЩЯЪЧвдHDFSзїЮЊДцДЂЃЌMapReduceзїЮЊМЦЫув§ЧцЃЌYARNзїЮЊзЪдДЗжХфМАШнДэЛњжЦЃЌвРЭагкhadoopЩњЬЌЯЕЭГЪЕЯжЕФвЛжжOLAPЪ§ОнВжПтЃЌОпЬхУшЪіШчЯТ
HiveЪЧвЛИіSQLНтЮів§ЧцЃЌНЋSQLгяОфзЊвыГЩMapReduce JobЃЌШЛКѓдйHadoopЦНЬЈЩЯдЫааЃЌДяЕНПьЫйПЊЗЂЕФФПЕФЁЃ
HiveжаЕФБэЪЧДПТпМБэЃЌОЭжЛЪЧБэЕФЖЈвхЕШЃЌМДБэЕФдЊЪ§ОнЁЃБОжЪОЭЪЧHadoopЕФФПТМ/ЮФМўЃЌДяЕНСЫдЊЪ§ОнгыЪ§ОнДцДЂЗжРыЕФФПЕФ
HiveБОЩэВЛДцДЂЪ§ОнЃЌЫќЭъШЋвРРЕHDFSКЭMapReduceЁЃ
HiveЕФФкШнЪЧЖСЖраДЩйЃЌФЌШЯВЛжЇГжЖдЪ§ОнЕФupdateКЭdelete
HiveМмЙЙ
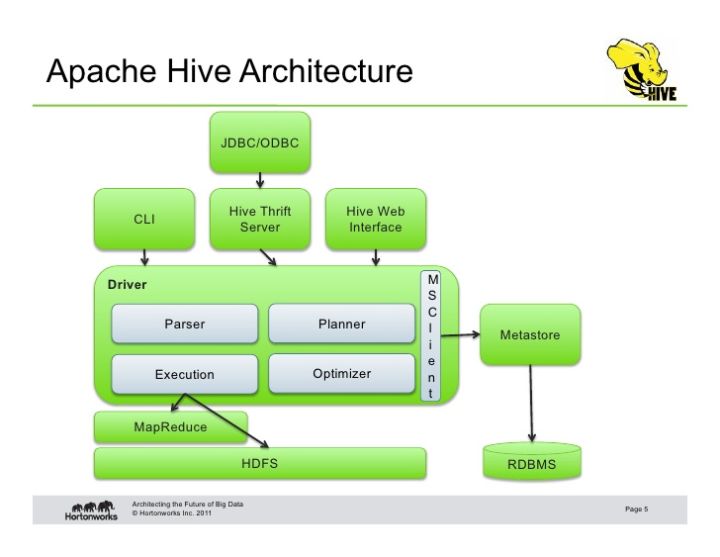
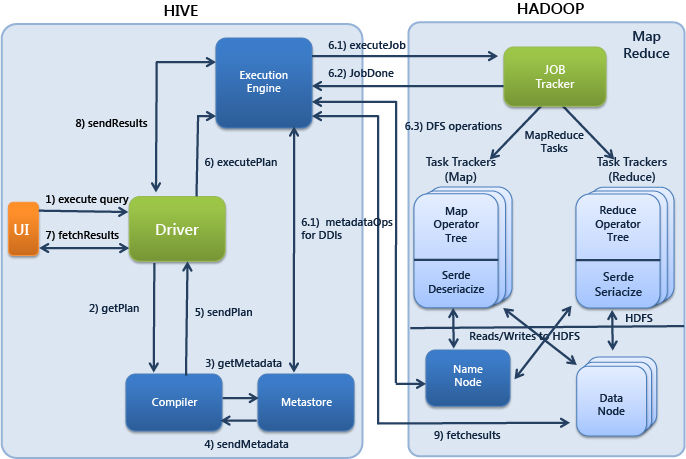
Hive гЩЭтВПCLIЃЌHive Thrift ServerЛђепWeb UIЬсНЛSQLЃЌЬсНЛжСDriverжаЃЌDriverНЋsqlНтЮіГЩMapReduceжДааМЦЛЎЃЌВЂНјааТпМгХЛЏМАЮяРэгХЛЏКѓЬсНЛжСMapReduceНјаажДааЃЌШчЙћгаашвЊаДШыЕФЪ§ОнОЭаДШыHDFSЮФМўжаЃЌВЂЧвМЧТМЯТMetadataжСMetastoreжа
HiveЕФДцДЂЮФМўИёЪН
HiveЫљгаДцДЂЖМЪЧвдЮФМўИёЪНЧјЗжФПТМДцЗХдкhdfsЩЯЕФЃЌДЂДцИёЪНЕФВЛЭЌМАЬиЕуЧјЗжгкИїИіЮФМўИёЪНЕФЬиЕуЃЌHiveжЇГждкНЈБэЪБЪЙгУSTORED
AS (TextFile|RCFile|SequenceFile|AVRO|ORC|Parquet)РДжИЖЈДцДЂИёЪН
вдЯТЪЧУПжжИёЪНЕФЬиЕу
TextFile: ааЪНДцДЂЃЌУПвЛааЖМЪЧвЛЬѕМЧТМЃЌУПааЖМвдЛЛааЗћЃЈ\ nЃЉНсЮВЁЃЪ§ОнВЛзібЙЫѕЃЌДХХЬПЊЯњДѓЃЌЪ§ОнНтЮіПЊЯњДѓЁЃПЩНсКЯGzipЁЂBzip2ЪЙгУЃЈЯЕЭГздЖЏМьВщЃЌжДааВщбЏЪБздЖЏНтбЙЃЉЃЌЕЋЪЙгУетжжЗНЪНЃЌhiveВЛЛсЖдЪ§ОнНјааЧаЗжЃЌДгЖјЮоЗЈЖдЪ§ОнНјааВЂааВйзїЁЃ
SequenceFile: ааЪНДцДЂЃЌЪЧHadoop APIЬсЙЉЕФвЛжжЖўНјжЦЮФМўжЇГжЃЌЦфОпгаЪЙгУЗНБуЁЂПЩЗжИюЁЂПЩбЙЫѕЕФЬиЕуЁЃжЇГжШ§жжбЙЫѕбЁдёЃКNONE,
RECORD, BLOCKЁЃ RecordбЙЫѕТЪЕЭЃЌвЛАуНЈвщЪЙгУBLOCKбЙЫѕЁЃ
RCFileЃКааСаДцДЂЯрНсКЯЃЌЪзЯШЃЌЦфНЋЪ§ОнАДааЗжПщЃЌБЃжЄЭЌвЛИіrecordдквЛИіПщЩЯЃЌБмУтЖСвЛИіМЧТМашвЊЖСШЁЖрИіblockЁЃЦфДЮЃЌПщЪ§ОнСаЪНДцДЂЃЌгаРћгкЪ§ОнбЙЫѕКЭПьЫйЕФСаДцШЁЁЃ
AVROЃКПЊдДЯюФПЃЌЮЊHadoopЬсЙЉЪ§ОнађСаЛЏКЭЪ§ОнНЛЛЛЗўЮёЁЃФњПЩвддкHadoopЩњЬЌЯЕЭГКЭвдШЮКЮБрГЬгябдБраДЕФГЬађжЎМфНЛЛЛЪ§ОнЁЃAvroЪЧЛљгкДѓЪ§ОнHadoopЕФгІгУГЬађжаСїааЕФЮФМўИёЪНжЎвЛЁЃ
ORC: СаЪНДцДЂЃЌHiveДгДѓаЭБэЖСШЁЃЌаДШыКЭДІРэЪ§ОнЪБЃЌЪЙгУORCЮФМўПЩвдЬсИпадФмЁЃ
Parquet: СаЪНДцДЂЃЌУцЯђСаЕФЖўНјжЦЮФМўИёЪНЃЌВЛПЩвджБНгЖСШЁ
ЮвУЧдкЖСЖраДЩйВЂЧвжЛЪЙгУhiveЕФЧщПіЯТЃЌгІИУОЁСПЪЙгУorcвдЬсИпадФм
hqlНтЮіСїГЬ
HiveЛсНЋHive sqlНтЮіЮЊMapReduceЃЌдкСЫНтSQLШчКЮБрвыЮЊMapReduceжЎЧАЃЌЯШПДПДMapReduceПђМмЪЕЯжSQLВйзїЕФЛљДЁдРэ
MapReduceЪЕЯжЛљБОSQLВйзїЕФдРэ
JoinЕФЪЕЯждРэ
| select u.name,
o.orderid from order o join user u on o.uid =
u.uid;
|
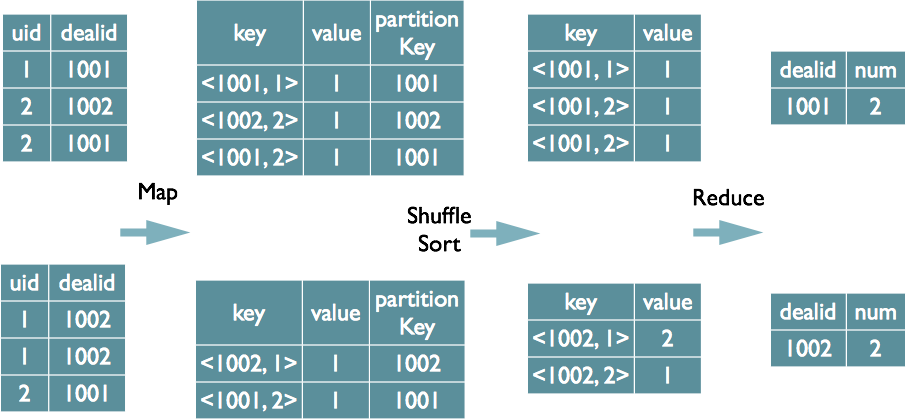
дкmapЕФЪфГіvalueжаЮЊВЛЭЌБэЕФЪ§ОнДђЩЯtagБъМЧЃЌдкreduceНзЖЮИљОнtagХаЖЯЪ§ОнРДдДЁЃMapReduceЕФЙ§ГЬШчЯТЃЈетРяжЛЪЧЫЕУїзюЛљБОЕФJoinЕФЪЕЯжЃЌЛЙгаЦфЫћЕФЪЕЯжЗНЪНЃЉ
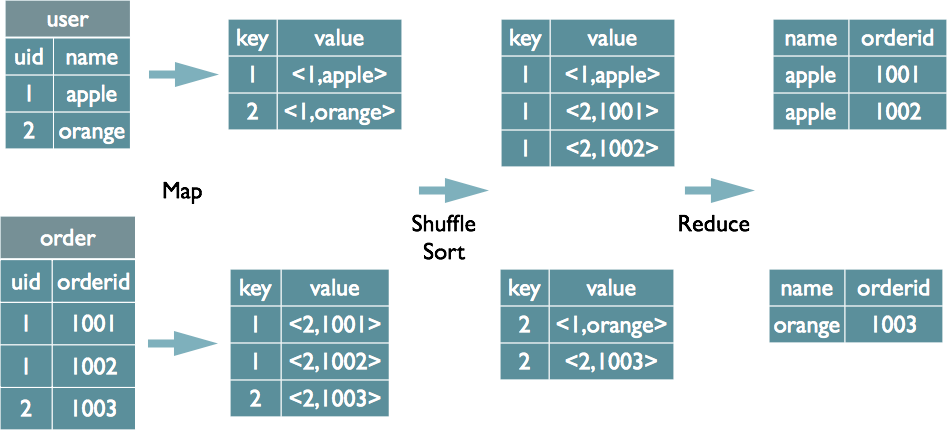
Group ByЕФЪЕЯждРэ
| select rank,
isonline, count(*) from city group by rank, isonline; |
НЋGroupByЕФзжЖЮзщКЯЮЊmapЕФЪфГіkeyжЕЃЌРћгУMapReduceЕФХХађЃЌдкreduceНзЖЮБЃДцLastKeyЧјЗжВЛЭЌЕФkeyЁЃMapReduceЕФЙ§ГЬШчЯТЃЈЕБШЛетРяжЛЪЧЫЕУїReduceЖЫЕФЗЧHashОлКЯЙ§ГЬЃЉ
.png)
DistinctЕФЪЕЯждРэ
| select dealid,
count(distinct uid) num from order group by dealid; |
ЕБжЛгавЛИіdistinctзжЖЮЪБЃЌШчЙћВЛПМТЧMapНзЖЮЕФHash GroupByЃЌжЛашвЊНЋGroupByзжЖЮКЭDistinctзжЖЮзщКЯЮЊmapЪфГіkeyЃЌРћгУmapreduceЕФХХађЃЌЭЌЪБНЋGroupByзжЖЮзїЮЊreduceЕФkeyЃЌдкreduceНзЖЮБЃДцLastKeyМДПЩЭъГЩШЅжи
HQLзЊЛЏЮЊMapReduceЕФЙ§ГЬ
НЋHQLзЊЮЊMapReduceжДааЕФжївЊСїГЬШчЯТ
гяЗЈНтЮі НЋHQLНтЮіЮЊASTЃЈAbstractSyntaxTreeЃЌГщЯѓгяЗЈЪїЃЉЃЌШыПкЮЊParseDriver.run()ЗНЗЈЁЃИУВНжшжївЊНшжњгкAntlr3ЪЕЯжSQLЕФДЪЗЈКЭгяЗЈНтЮіЃЌетРяВЛЯъЯИНщЩмAntlrЃЌжЛашвЊСЫНтЪЙгУAntlrЙЙдьЬиЖЈЕФгябджЛашвЊБраДвЛИігяЗЈЮФМўЃЌЖЈвхДЪЗЈКЭгяЗЈЬцЛЛЙцдђМДПЩЃЌAntlrЭъГЩСЫДЪЗЈЗжЮіЁЂгяЗЈЗжЮіЁЂгявхЗжЮіЁЂжаМфДњТыЩњГЩЕФЙ§ГЬЁЃ
гявхЗжЮіЕквЛНзЖЮ AST TreeШдШЛЗЧГЃИДдгЃЌВЛЙЛНсЙЙЛЏЃЌВЛЗНБужБНгЗвыЮЊMapReduceГЬађЃЌAST
TreeзЊЛЏЮЊQueryBlockОЭЪЧНЋSQLНјвЛВПГщЯѓКЭНсЙЙЛЏЁЃQueryBlockЪЧвЛЬѕSQLзюЛљБОЕФзщГЩЕЅдЊЃЌАќРЈШ§ИіВПЗжЃКЪфШыдДЃЌМЦЫуЙ§ГЬЃЌЪфГіЁЃМђЕЅРДНВвЛИіQueryBlockОЭЪЧвЛИізгВщбЏЁЃ
ЩњГЩВщбЏМЦЛЎ НЋQueryBlockНтЮіГЩOperatorЪїЃЌHiveзюжеЩњГЩЕФMapReduceШЮЮёЃЌMapНзЖЮКЭReduceНзЖЮОљгЩOperatorTreeзщГЩЁЃOperatorЃЌОЭЪЧдкMapНзЖЮЛђепReduceНзЖЮЭъГЩЕЅвЛЬиЖЈЕФВйзїЁЃ
ТпМгХЛЏ гХЛЏвбЩњГЩЕФOperatorЪїЃЌКЯВЂВйзїЗћЃЌДяЕНМѕЩйMapReduce JobЃЌМѕЩйshuffleЪ§ОнСПЕФФПЕФ
ЩњГЩMRШЮЮё НЋOperatorЪїНтЮіЮЊTaskгаЯђЮоЛЗЭМ
ЮяРэгХЛЏ ИФаДTaskгаЯђЮоЛЗЭМЃЌНЋФГаЉНсЕуЕФЦеЭЈTaskИФаДЮЊПЩдкдЫааЪБНјааЗжжІбЁдёЕФConditionalTask
жДаа НЋTaskгаЯђЮоЛЗЭМНЛгЩПђМмНјаажДаа
змНс
HiveЪЧЪєгкOLAPаЭЕФЪ§ОнВжПтЃЌЪЪгУГЁОАЮЊжДааЪБаЇадВЛИпЕФЃЌЪ§ОнСПДѓЕФРыЯпЗжЮіаЭМЦЫуЃЌР§ШчБЈБэЗжЮіЃЌШчЙћгаДѓСПЪТЮёадВйзїЃЌЧыЪЙгУOLTPаЭЪ§ОнПтЃЌШчmysqlЕШ
HiveДцДЂЮФМўИёЪНгаЖржжЃЌФЌШЯЮЊааЪНДцДЂЕФTextFileЃЌеМгУПеМфНЯДѓЃЌВЂЧвМЦЫуЖСШЁадФмВЛИпЃЌдкЪЙгУhiveЪБЃЌОЁСПбЁгУorcИёЪНДцДЂЃЌбЙЫѕБШР§НЯДѓЃЌЧаЖСШЁадФмКмИп
Hive SQLЕзВуЮЊMapReduceЃЌашЬсНЛжСyarnЩЯжДааЃЌyarnЗжХфзЪдДИјMapReduceШЮЮёЃЌДѓСПhive
sqlЭЌЪБЬсНЛПЩФмЛсЗЧГЃЫ№КФmasterНсЕуЗжХфШЮЮёЕФзЪдДЃЌШчЙћашвЊдкГЬађжаЕїгУhive sql insertЪБЃЌЧыЪЙгУХњСПВхШыЕФsqlЛђепЭЈЙ§ЦфЫќЗНЪН(ШчБраДгУЛЇздЖЈвхКЏЪ§ЖСШЁmysql)НјааЪЕЯж
|









