| БрМЭЦМі: |
БОЮФЪзЯШНщЩмДЋЭГЯЕЭГЕФЮЪЬтЁЂЪ§ОнЯЕЭГЕФИХФюЁЂLambdaМмЙЙЕФServing
LayerЃЌSpeed LayerЕШЯрЙиФкШнЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Nathan MarzЕФДѓзїBig Data: Principles
and best practices of scalable real-time data systemsНщЩмСЫLabmda
ArchitectureЕФИХФюЃЌгУгкдкДѓЪ§ОнМмЙЙжаЃЌШчКЮШУreal-timeгыbatch jobИќКУЕиНсКЯЦ№РДЃЌвдДяГЩЖдДѓЪ§ОнЕФЪЕЪБДІРэЁЃ
ДЋЭГЯЕЭГЕФЮЪЬт
дкДЋЭГЪ§ОнПтЕФЩшМЦжаЃЌЮоЗЈКмКУЕижЇГжЯЕЭГЕФПЩЩьЫѕадЁЃЕБгУЛЇЗУЮЪСПдіМгЪБЃЌЪ§ОнПтЮоЗЈТњзуШевцдіГЄЕФгУЛЇЧыЧѓИКдиЃЌДгЖјЕМжТЪ§ОнПтЗўЮёЦїЮоЗЈМАЪБЯьгІгУЛЇЧыЧѓЃЌГіЯжГЌЪБДэЮѓЁЃ
НтОіЕФАьЗЈЪЧдкWebЗўЮёЦїгыЪ§ОнПтжЎМфдіМгвЛИівьВНДІРэЕФЖгСаЁЃШчЯТЭМЫљЪОЃК
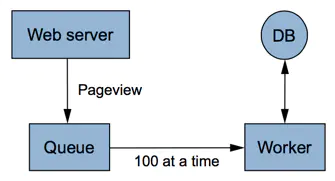
в§ШыЖгСа
ЕБWeb ServerЪеЕНвГУцЧыЧѓЪБЃЌЛсНЋЯћЯЂЬэМгЕНЖгСажаЁЃдкDBЖЫЃЌДДНЈвЛИіWorkerЖЈЦкДгЖгСажаШЁГіЯћЯЂНјааДІРэЃЌР§ШчУПДЮЖСШЁ100ЬѕЯћЯЂЁЃетЯрЕБгкдкСНепжЎМфНЈСЂСЫвЛИіЛКГхЁЃ
ЕЋЪЧЃЌетвЛЗНАИВЂУЛгаДгБОжЪЩЯНтОіЪ§ОнПтoverloadЕФЮЪЬтЃЌЧвЕБworkerЮоЗЈИњЩЯwriterЕФЧыЧѓЪБЃЌОЭашвЊдіМгЖрИіworkerВЂЗЂжДааЃЌЪ§ОнПтгжНЋдйДЮГЩЮЊЯьгІЧыЧѓЕФЦПОБЁЃвЛИіНтОіАьЗЈЪЧЖдЪ§ОнПтНјааЗжЧјЃЈhorizontal
partitioningЛђепshardingЃЉЁЃЗжЧјЕФЗНЪНЭЈГЃвдHashжЕзїЮЊkeyЁЃетбљОЭашвЊгІгУГЬађЖЫжЊЕРШчКЮШЅбАевУПИіkeyЫљдкЕФЗжЧјЁЃ
ЮЪЬтШдШЛЛсЫцзХгУЛЇЧыЧѓЕФдіМгНгѕрЖјРДЁЃЕБжЎЧАЕФЗжЧјЮоЗЈТњзуИКдиЪБЃЌОЭашвЊдіМгИќЖрЗжЧјЃЌетЪБОЭашвЊЖдЪ§ОнПтНјааreshardЁЃreshardingЕФЙЄзїЗЧГЃКФЪБЖјЭДПрЃЌвђЮЊашвЊаЕїКмЖрЙЄзїЃЌР§ШчЪ§ОнЕФЧЈвЦЁЂИќаТПЭЛЇЖЫЗУЮЪЕФЗжЧјЕижЗЃЌИќаТгІгУГЬађДњТыЁЃШчЙћЯЕЭГБОЩэЛЙЬсЙЉСЫдкЯпЗУЮЪЗўЮёЃЌЖддЫЮЌЕФвЊЧѓОЭИќИпЁЃЩдгаВЛЩїЃЌОЭПЩФмЕМжТЪ§ОнаДЕНДэЮѓЕФЗжЧјЃЌвђДЫБиаывЊБраДНХБОРДздЖЏЭъГЩЃЌЧвашвЊГфЗжЕФВтЪдЁЃ
МДЪЙЗжЧјФмЙЛНтОіЪ§ОнПтИКдиЮЪЬтЃЌШДЛЙДцдкШнДэадЃЈFault-ToleranceЃЉЕФЮЪЬтЁЃНтОіАьЗЈЃК
ИФБфqueue/workerЕФЪЕЯжЁЃЕБЯћЯЂЗЂЫЭИјВЛПЩгУЕФЗжЧјЪБЃЌНЋЯћЯЂЗХЕНЁАpendingЁБЖгСаЃЌШЛКѓУПИєвЛЖЮЪБМфЖдpendingЖгСажаЕФЯћЯЂНјааДІРэЁЃ
ЪЙгУЪ§ОнПтЕФreplicationЙІФмЃЌЮЊУПИіЗжЧјдіМгslaveЁЃ
ЮЪЬтВЂУЛгаЕУЕНЭъУРЕиНтОіЁЃМйЩшЯЕЭГГіЯжЮЪЬтЃЌР§ШчдкгІгУЯЕЭГДњТыЖЫВЛаЁаФв§ШыСЫвЛИіbugЃЌЪЙЕУЖдвГУцЕФЧыЧѓжиИДЬсНЛСЫвЛДЮЃЌетОЭЕМжТСЫжиИДЕФЧыЧѓЪ§ОнЁЃдуИтЕФЪЧЃЌжБЕН24аЁЪБжЎКѓВХЗЂЯжСЫИУЮЪЬтЃЌДЫЪБЖдЪ§ОнЕФЦЦЛЕвбОдьГЩСЫЁЃМДЪЙУПжмЕФЪ§ОнБИЗнвВЮоЗЈНтОіДЫЮЪЬтЃЌвђЮЊЫќВЛжЊЕРЕНЕзЪЧФФаЉЪ§ОнЪмЕНСЫЦЦЛЕЃЈcorrupitonЃЉЁЃгЩгкШЫЮЊДэЮѓзмЪЧВЛПЩБмУтЕФЃЌЮвУЧдкМмЙЙЪБгІИУШчКЮЙцБмДЫЮЪЬтЃП
ЯждкЃЌМмЙЙБфЕУдНРДдНИДдгЃЌдіМгСЫЖгСаЁЂЗжЧјЁЂИДжЦЁЂжиЗжЧјНХБОЃЈresharding scriptsЃЉЁЃгІгУГЬађЛЙашвЊСЫНтЪ§ОнПтЕФschemaЃЌВЂФмЗУЮЪЕНе§ШЗЕФЗжЧјЁЃЮЪЬтдкгкЃКЪ§ОнПтЖдгкЗжЧјЪЧВЛСЫНтЕФЃЌЮоЗЈАяжњФугІЖдЗжЧјЁЂИДжЦгыЗжВМЪНВщбЏЁЃзюдуИтЕФЮЪЬтЪЧЯЕЭГВЂУЛгаЮЊШЫЮЊДэЮѓНјааЙЄГЬЩшМЦЃЌНіППБИЗнЪЧВЛФмжЮБОЕФЁЃЙщИљНсЕзЃЌЯЕЭГЛЙашвЊЯожЦвђЮЊШЫЮЊДэЮѓЕМжТЕФЦЦЛЕЁЃ
Ъ§ОнЯЕЭГЕФИХФю
ДѓЪ§ОнДІРэММЪѕашвЊНтОіетжжПЩЩьЫѕадгыИДдгадЁЃЪзЯШвЊШЯЪЖЕНетжжЗжВМЪНЕФБОжЪЃЌвЊКмКУЕиДІРэЗжЧјгыИДжЦЃЌВЛЛсЕМжТДэЮѓЗжЧјв§Ц№ВщбЏЪЇАмЃЌЖјЪЧвЊНЋетаЉТпМФкЛЏЕНЪ§ОнПтжаЁЃЕБашвЊРЉеЙЯЕЭГЪБЃЌПЩвдЗЧГЃЗНБуЕидіМгНкЕуЃЌЯЕЭГвВФмЙЛеыЖдаТНкЕуНјааrebalanceЁЃ
ЦфДЮЪЧвЊШУЪ§ОнГЩЮЊВЛПЩБфЕФЁЃдЪМЪ§ОнгРдЖЖМВЛФмБЛаоИФЃЌетбљМДЪЙЗИСЫДэЮѓЃЌаДСЫДэЮѓЪ§ОнЃЌдРДКУЕФЪ§ОнВЂВЛЛсЪмЕНЦЦЛЕЁЃ
КЮЮНЁАЪ§ОнЯЕЭГЁБЃПNathan MarzШЯЮЊЃК
ШчЙћЪ§ОнЯЕЭГЭЈЙ§ВщевЙ§ШЅЕФЪ§ОнШЅЛиД№ЮЪЬтЃЌдђЭЈГЃашвЊЗУЮЪећИіЪ§ОнМЏЁЃ
вђДЫПЩвдИјdata systemЕФзюЭЈгУЕФЖЈвхЃК
| Query = function(all
data) |
НгЯТРДЃЌБОЪщзїепНщЩмСЫBig Data SystemЫљашОпБИЕФЪєадЃК
НЁзГадКЭШнДэадЃЈRobustnessКЭFault ToleranceЃЉ
ЕЭбгГйЕФЖСгыИќаТЃЈLow Latency reads and updatesЃЉ
ПЩЩьЫѕадЃЈScalabilityЃЉ
ЭЈгУадЃЈGeneralizationЃЉ
ПЩРЉеЙадЃЈExtensibilityЃЉ
ФкжУВщбЏЃЈAd hoc queriesЃЉ
ЮЌЛЄзюаЁЃЈMinimal maintenanceЃЉ
ПЩЕїЪдадЃЈDebuggabilityЃЉ
LambdaМмЙЙ
LambdaМмЙЙЕФжївЊЫМЯыОЭЪЧНЋДѓЪ§ОнЯЕЭГЙЙНЈЮЊЖрИіВуДЮЃЌШчЯТЭМЫљЪОЃК
lambda layer
РэЯызДЬЌЯТЃЌШЮКЮЪ§ОнЗУЮЪЖМПЩвдДгБэДяЪНQuery = function(all data)ПЊЪМЃЌЕЋЪЧЃЌШєЪ§ОнДяЕНЯрЕБДѓЕФвЛИіМЖБ№ЃЈР§ШчPBЃЉЃЌЧвЛЙашвЊжЇГжЪЕЪБВщбЏЪБЃЌОЭашвЊКФЗбЗЧГЃХгДѓЕФзЪдДЁЃ
вЛИіНтОіЗНЪНЪЧдЄдЫЫуВщбЏКЏЪ§ЃЈprecomputed query
funcitonЃЉЁЃЪщжаНЋетжждЄдЫЫуВщбЏКЏЪ§ГЦжЎЮЊBatch ViewЃЌетбљЕБашвЊжДааВщбЏЪБЃЌПЩвдДгBatch
ViewжаЖСШЁНсЙћЁЃетбљвЛИідЄЯШдЫЫуКУЕФViewЪЧПЩвдНЈСЂЫїв§ЕФЃЌвђЖјПЩвджЇГжЫцЛњЖСШЁЁЃгкЪЧЯЕЭГОЭБфГЩЃК
batch view =
function(all data)
query = function(batch view) |
Batch Layer
дкLambdaМмЙЙжаЃЌЪЕЯжbatch view = function(all data)ЕФВПЗжБЛГЦжЎЮЊbatch
layerЁЃЫќГаЕЃСЫСНИіжАд№ЃК
ДцДЂMaster DatasetЃЌетЪЧвЛИіВЛБфЕФГжајдіГЄЕФЪ§ОнМЏ
еыЖдетИіMaster DatasetНјаадЄдЫЫу
ЯдШЛЃЌBatch LayerжДааЕФЪЧХњСПДІРэЃЌР§ШчHadoopЛђепSparkжЇГжЕФMap-ReduceЗНЪНЁЃ
ЫќЕФжДааЗНЪНПЩвдгУвЛЖЮЮБДњТыРДБэЪОЃК
function runBatchLayer():
while (true):
recomputeBatchViews() |
Р§ШчетбљвЛЖЮДњТыЃК
Api.execute(Api.hfsSeqfile ("/tmp/pageview-counts"),
new Subquery ("?url", "?count")
.predicate (Api.hfsSeqfile("/data/pageviews"),
"?url", "?user", "?timestamp")
.predicate(new Count(), "?count"); |
ДњТыВЂааЕиЖдhdfsЮФМўМаЯТЕФpage viewsНјааЭГМЦЃЈcountЃЉЃЌКЯВЂНсЙћЃЌВЂНЋзюжеНсЙћБЃДцдкpageview-countsЮФМўМаЯТЁЃ
РћгУBatch LayerНјаадЄдЫЫуЕФзїгУЪЕМЪЩЯОЭЪЧНЋДѓЪ§ОнБфаЁЃЌДгЖјгааЇЕиРћгУзЪдДЃЌИФЩЦЪЕЪБВщбЏЕФадФмЁЃЕЋетРягавЛИіЧАЬсЃЌОЭЪЧЮвУЧашвЊдЄЯШжЊЕРВщбЏашвЊЕФЪ§ОнЃЌШчДЫВХФмдкBatch
LayerжаАВХХжДааМЦЛЎЃЌЖЈЦкЖдЪ§ОнНјааХњСПДІРэЁЃДЫЭтЃЌЛЙвЊЧѓетаЉдЄдЫЫуЕФЭГМЦЪ§ОнЪЧжЇГжКЯВЂЃЈmergeЃЉЕФЁЃ
Serving Layer
Batch LayerЭЈЙ§Ждmaster datasetжДааВщбЏЛёЕУСЫbatch viewЃЌЖјServing
LayerОЭвЊИКд№Ждbatch viewНјааВйзїЃЌДгЖјЮЊзюжеЕФЪЕЪБВщбЏЬсЙЉжЇГХЁЃвђДЫServing
LayerЕФжАд№АќКЌЃК
Ждbatch viewЕФЫцЛњЗУЮЪ
ИќаТbatch view
Serving LayerгІИУЪЧвЛИізЈгУЕФЗжВМЪНЪ§ОнПтЃЌР§ШчElephant DBЃЌвджЇГжЖдbatch
viewЕФМгдиЁЂЫцЛњЖСШЁвдМАИќаТЁЃзЂвтЃЌЫќВЂВЛжЇГжЖдbatch viewЕФЫцЛњаДЃЌвђЮЊЫцЛњаДЛсЮЊЪ§ОнПтв§РДаэЖрИДдгадЁЃМђЕЅЕФЬиадВХФмЪЙЯЕЭГБфЕУИќНЁзГЁЂПЩдЄВтЁЂвзХфжУЃЌвВвзгкдЫЮЌЁЃ
Speed Layer
жЛвЊbatch layerЭъГЩЖдbatch viewЕФдЄМЦЫуЃЌserving layerОЭЛсЖдЦфНјааИќаТЁЃетвтЮЖзХдкдЫаадЄМЦЫуЪБНјШыЕФЪ§ОнВЛЛсТэЩЯГЪЯжЕНbatch
viewжаЁЃетЖдгквЊЧѓЭъШЋЪЕЪБЕФЪ§ОнЯЕЭГЖјбдЪЧВЛФмНгЪмЕФЁЃвЊНтОіетИіЮЪЬтЃЌОЭвЊЭЈЙ§speed layerЁЃДгЖдЪ§ОнЕФДІРэРДПДЃЌspeed
layerгыbatch layerЗЧГЃЯрЫЦЃЌЫќУЧжЎМфзюДѓЕФЧјБ№ЪЧЧАепжЛДІРэзюНќЕФЪ§ОнЃЌКѓепдђвЊДІРэЫљгаЕФЪ§ОнЁЃСэвЛИіЧјБ№ЪЧЮЊСЫТњзузюаЁЕФбгГйЃЌspeed
layerВЂВЛЛсдкЭЌвЛЪБМфЖСШЁЫљгаЕФаТЪ§ОнЃЌЯрЗДЃЌЫќЛсдкНгЪеЕНаТЪ§ОнЪБЃЌИќаТrealtime viewЃЌЖјВЛЛсЯёbatch
layerФЧбљжиаТдЫЫуећИіviewЁЃspeed layerЪЧвЛжждіСПЕФМЦЫуЃЌЖјЗЧжиаТдЫЫуЃЈrecomputationЃЉЁЃ
вђЖјЃЌSpeed LayerЕФзїгУАќРЈЃК
ЖдИќаТЕНserving layerДјРДЕФИпбгГйЕФвЛжжВЙГф
ПьЫйЁЂдіСПЕФЫуЗЈ
зюжеBatch LayerЛсИВИЧspeed layer
Speed LayerЕФЕШЪНБэДяШчЯТЫљЪОЃК
| realtime view
= function(realtime view, new data) |
зЂвтЃЌrealtime viewЪЧЛљгкаТЪ§ОнКЭвбгаЕФrealtime viewЁЃ
змНсЯТРДЃЌLambdaМмЙЙОЭЪЧШчЯТЕФШ§ИіЕШЪНЃК
batch view =
function(all data)
realtime view = function(realtime view, new data)
query = function(batch view . realtime view) |
ећИіLambdaМмЙЙШчЯТЭМЫљЪОЃК
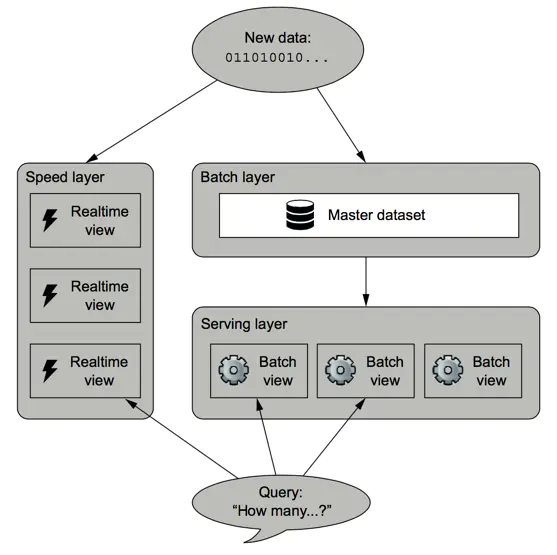
lambda architecture
ЛљгкLambdaМмЙЙЃЌвЛЕЉЪ§ОнЭЈЙ§batch layerНјШыЕНserving layerЃЌдкrealtime
viewжаЕФЯргІНсЙћОЭВЛдйашвЊСЫЁЃ
|









