| БрМЭЦМі: |
| БОЮФжївЊНВНтСЫHiveЛљБОИХФюЁЂВйзїЁЂВЮЪ§ЁЂКЏЪ§ЕШФкШнЁЃ
БОЮФРДздCSDNЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
1. HiveЛљБОИХФю
1.1 HiveМђНщ
1.1.1 ЪВУДЪЧHive
HiveЪЧЛљгкHadoopЕФвЛИіЪ§ОнВжПтЙЄОпЃЌПЩвдНЋНсЙЙЛЏЕФЪ§ОнЮФМўгГЩфЮЊвЛеХЪ§ОнПтБэЃЌВЂЬсЙЉРрSQLВщбЏЙІФмЁЃ
1.1.2 ЮЊЪВУДЪЙгУHive
1.ЃЉ жБНгЪЙгУhadoopЫљУцСйЕФЮЪЬт
ШЫдБбЇЯАГЩБОЬЋИп
ЯюФПжмЦквЊЧѓЬЋЖЬ
MapReduceЪЕЯжИДдгВщбЏТпМПЊЗЂФбЖШЬЋДѓ
2.ЃЉ
ВйзїНгПкВЩгУРрSQLгяЗЈЃЌЬсЙЉПьЫйПЊЗЂЕФФмСІЁЃ
БмУтСЫШЅаДMapReduceЃЌМѕЩйПЊЗЂШЫдБЕФбЇЯАГЩБОЁЃ
РЉеЙЙІФмКмЗНБуЁЃ
1.1.3 HiveЕФЬиЕу
1.ЃЉПЩРЉеЙ
HiveПЩвдздгЩЕФРЉеЙМЏШКЕФЙцФЃЃЌвЛАуЧщПіЯТВЛашвЊжиЦєЗўЮёЁЃ
2.ЃЉбгеЙад
HiveжЇГжгУЛЇздЖЈвхКЏЪ§ЃЌгУЛЇПЩвдИљОнздМКЕФашЧѓРДЪЕЯжздМКЕФКЏЪ§ЁЃ
3.ЃЉШнДэ
СМКУЕФШнДэадЃЌНкЕуГіЯжЮЪЬтSQLШдПЩЭъГЩжДааЁЃ
1.2 HiveМмЙЙ
1.2.1 МмЙЙЭМ 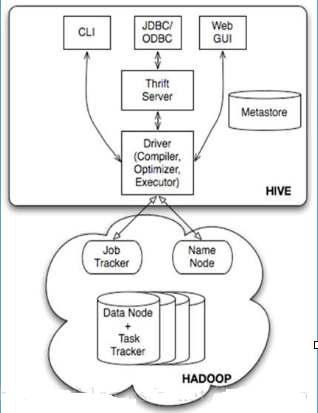
JobtrackerЪЧhadoop1.xжаЕФзщМўЃЌЫќЕФЙІФмЯрЕБгкЃК Resourcemanager+AppMaster
TaskTracker ЯрЕБгкЃК Nodemanager + yarnchild
1.2.2 ЛљБОзщГЩ
1.ЃЉ гУЛЇНгПкЃКАќРЈ CLIЁЂJDBC/ODBCЁЂWebGUIЁЃ
2.ЃЉ дЊЪ§ОнДцДЂЃКЭЈГЃЪЧДцДЂдкЙиЯЕЪ§ОнПтШч mysql , derbyжаЁЃ
3.ЃЉ НтЪЭЦїЁЂБрвыЦїЁЂгХЛЏЦїЁЂжДааЦїЁЃ
1.2.3 ИїзщМўЕФЛљБОЙІФм
1.ЃЉ гУЛЇНгПкжївЊгЩШ§ИіЃКCLIЁЂJDBC/ODBCКЭWebGUIЁЃЦфжаЃЌCLIЮЊshellУќСюааЃЛJDBC/ODBCЪЧHiveЕФJAVAЪЕЯжЃЌгыДЋЭГЪ§ОнПтJDBCРрЫЦЃЛWebGUIЪЧЭЈЙ§фЏРРЦїЗУЮЪHiveЁЃ
2.ЃЉдЊЪ§ОнДцДЂЃКHive НЋдЊЪ§ОнДцДЂдкЪ§ОнПтжаЁЃHive жаЕФдЊЪ§ОнАќРЈБэЕФУћзжЃЌБэЕФСаКЭЗжЧјМАЦфЪєадЃЌБэЕФЪєадЃЈЪЧЗёЮЊЭтВПБэЕШЃЉЃЌБэЕФЪ§ОнЫљдкФПТМЕШЁЃ
3.ЃЉНтЪЭЦїЁЂБрвыЦїЁЂгХЛЏЦїЭъГЩ HQL ВщбЏгяОфДгДЪЗЈЗжЮіЁЂгяЗЈЗжЮіЁЂБрвыЁЂгХЛЏвдМАВщбЏМЦЛЎЕФЩњГЩЁЃЩњГЩЕФВщбЏМЦЛЎДцДЂдк
HDFS жаЃЌВЂдкЫцКѓга MapReduce ЕїгУжДааЁЃ
1.3 HiveгыHadoopЕФЙиЯЕ
HiveРћгУHDFSДцДЂЪ§ОнЃЌРћгУMapReduceВщбЏЪ§Он

1.4 HiveгыДЋЭГЪ§ОнПтЖдБШ
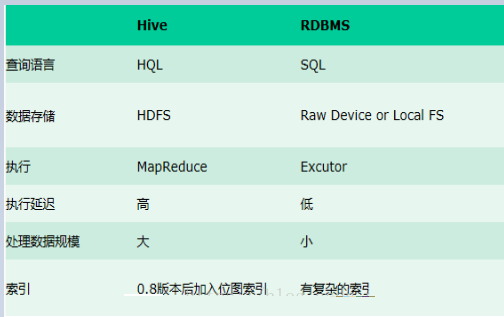
змНсЃКhiveОпгаsqlЪ§ОнПтЕФЭтБэЃЌЕЋгІгУГЁОАЭъШЋВЛЭЌЃЌhiveжЛЪЪКЯгУРДзіХњСПЪ§ОнЭГМЦЗжЮі
1.5 HiveЕФЪ§ОнДцДЂ
1ЁЂHiveжаЫљгаЕФЪ§ОнЖМДцДЂдк HDFS жаЃЌУЛгазЈУХЕФЪ§ОнДцДЂИёЪНЃЈПЩжЇГжTextЃЌSequenceFileЃЌParquetFileЃЌRCFILEЕШЃЉ
2ЁЂжЛашвЊдкДДНЈБэЕФЪБКђИцЫп Hive Ъ§ОнжаЕФСаЗжИєЗћКЭааЗжИєЗћЃЌHive ОЭПЩвдНтЮіЪ§ОнЁЃ
3ЁЂHive жаАќКЌвдЯТЪ§ОнФЃаЭЃКDBЁЂTableЃЌExternal TableЃЌPartitionЃЌBucketЁЃ
dbЃКдкhdfsжаБэЯжЮЊ${hive.metastore.warehouse.dir}ФПТМЯТвЛИіЮФМўМа
tableЃКдкhdfsжаБэЯжЫљЪєdbФПТМЯТвЛИіЮФМўМа
external tableЃКЭтВПБэ, гыtableРрЫЦЃЌВЛЙ§ЦфЪ§ОнДцЗХЮЛжУПЩвддкШЮвтжИЖЈТЗОЖ
ЦеЭЈБэ: ЩОГ§БэКѓ, hdfsЩЯЕФЮФМўЖМЩОСЫ
ExternalЭтВПБэЩОГ§Кѓ, hdfsЩЯЕФЮФМўУЛгаЩОГ§, жЛЪЧАбЮФМўЩОГ§СЫ
partitionЃКдкhdfsжаБэЯжЮЊtableФПТМЯТЕФзгФПТМ
bucketЃКЭА, дкhdfsжаБэЯжЮЊЭЌвЛИіБэФПТМЯТИљОнhashЩЂСажЎКѓЕФЖрИіЮФМў, ЛсИљОнВЛЭЌЕФЮФМўАбЪ§ОнЗХЕНВЛЭЌЕФЮФМўжа
1.6 HIVEЕФАВзАВПЪ№
1.6.1 АВзА
ЕЅЛњАцЃК
дЊЪ§ОнПтmysqlАцЃК
АВзАЙ§ГЬТдЃЌЯТдиКУКѓНтбЙМДПЩЃЌИааЫШЄЕФХѓгбПЩвджБНгЯТдиЮвХфжУКУЕФhiveЃЌдЫаадкcentos7.4ЯТЭъУРдЫааЃЌЯТдивГЃК
https://download.csdn.net/download/l1212xiao/10434728
1.6.2 ЪЙгУЗНЪН
HiveНЛЛЅshell
bin/hive
Hive thriftЗўЮё 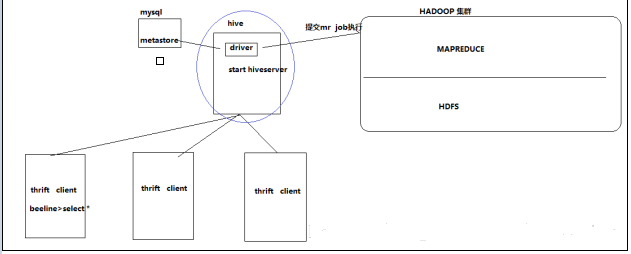
ЦєЖЏЗНЪНЃЌЃЈМйШчЪЧдкhadoop01ЩЯЃЉЃК
ЦєЖЏЮЊЧАЬЈЃКbin/hiveserver2
ЦєЖЏЮЊКѓЬЈЃКnohup bin/hiveserver2 1>/var/log/hiveserver.log
2>/var/log/hiveserver.err &
ЦєЖЏГЩЙІКѓЃЌПЩвддкБ№ЕФНкЕуЩЯгУbeelineШЅСЌНг
v ЗНЪНЃЈ1ЃЉ
hive/bin/beeline ЛиГЕЃЌНјШыbeelineЕФУќСюНчУц
ЪфШыУќСюСЌНгhiveserver2
beeline> !connect jdbc:hive2//mini1:10000
ЃЈhadoop01ЪЧhiveserver2ЫљЦєЖЏЕФФЧЬЈжїЛњУћЃЌЖЫПкФЌШЯЪЧ10000ЃЉ
v ЗНЪНЃЈ2ЃЉ
ЛђепЦєЖЏОЭСЌНгЃК
| bin/beeline
-u jdbc:hive2://hadoop01:10000 -n hadoop |
НгЯТРДОЭПЩвдзіе§ГЃsqlВщбЏСЫ
HiveУќСю
| [hadoop@hdp-node-02
~]$ hive -e ЁЎsqlЁЏ |
2. HiveЛљБОВйзї
2.1 DDLВйзї
2.1.1 ДДНЈБэ
НЈБэгяЗЈ
| CREATE
[EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT
col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type
[COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name,
...)
[SORTED BY (col_name [ASC|DESC],
...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
|
ЫЕУїЃК
1ЁЂ CREATE TABLE ДДНЈвЛИіжИЖЈУћзжЕФБэЁЃШчЙћЯрЭЌУћзжЕФБэвбОДцдкЃЌдђХзГівьГЃЃЛгУЛЇПЩвдгУ
IF NOT EXISTS бЁЯюРДКіТдетИівьГЃЁЃ
2ЁЂ EXTERNALЙиМќзжПЩвдШУгУЛЇДДНЈвЛИіЭтВПБэЃЌдкНЈБэЕФЭЌЪБжИЖЈвЛИіжИЯђЪЕМЪЪ§ОнЕФТЗОЖЃЈLOCATIONЃЉЃЌHive
ДДНЈФкВПБэЪБЃЌЛсНЋЪ§ОнвЦЖЏЕНЪ§ОнВжПтжИЯђЕФТЗОЖЃЛШєДДНЈЭтВПБэЃЌНіМЧТМЪ§ОнЫљдкЕФТЗОЖЃЌВЛЖдЪ§ОнЕФЮЛжУзіШЮКЮИФБфЁЃдкЩОГ§БэЕФЪБКђЃЌФкВПБэЕФдЊЪ§ОнКЭЪ§ОнЛсБЛвЛЦ№ЩОГ§ЃЌЖјЭтВПБэжЛЩОГ§дЊЪ§ОнЃЌВЛЩОГ§Ъ§ОнЁЃ
3ЁЂ LIKE дЪаэгУЛЇИДжЦЯжгаЕФБэНсЙЙЃЌЕЋЪЧВЛИДжЦЪ§ОнЁЃ
4ЁЂ ROW FORMAT
| DELIMITED
[FIELDS TERMINATED BY char] [COLLECTION ITEMS
TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value,
...)]
|
гУЛЇдкНЈБэЕФЪБКђПЩвдздЖЈвх SerDe ЛђепЪЙгУздДјЕФ SerDeЁЃШчЙћУЛгажИЖЈ
ROW FORMAT Лђеп ROW FORMAT DELIMITEDЃЌНЋЛсЪЙгУздДјЕФ SerDeЁЃдкНЈБэЕФЪБКђЃЌгУЛЇЛЙашвЊЮЊБэжИЖЈСаЃЌгУЛЇдкжИЖЈБэЕФСаЕФЭЌЪБвВЛсжИЖЈздЖЈвхЕФ
SerDeЃЌHiveЭЈЙ§ SerDe ШЗЖЈБэЕФОпЬхЕФСаЕФЪ§ОнЁЃ
5ЁЂ STORED AS
| SEQUENCEFILE|TEXTFILE|RCFILE
|
ШчЙћЮФМўЪ§ОнЪЧДПЮФБОЃЌПЩвдЪЙгУ STORED AS TEXTFILEЁЃШчЙћЪ§ОнашвЊбЙЫѕЃЌЪЙгУ
STORED AS SEQUENCEFILEЁЃ
6ЁЂCLUSTERED BY
ЖдгкУПвЛИіБэЃЈtableЃЉЛђепЗжЧјЃЌ HiveПЩвдНјвЛВНзщжЏГЩЭАЃЌвВОЭЪЧЫЕЭАЪЧИќЮЊЯИСЃЖШЕФЪ§ОнЗЖЮЇЛЎЗжЁЃHiveвВЪЧ
еыЖдФГвЛСаНјааЭАЕФзщжЏЁЃHiveВЩгУЖдСажЕЙўЯЃЃЌШЛКѓГ§вдЭАЕФИіЪ§ЧѓгрЕФЗНЪНОіЖЈИУЬѕМЧТМДцЗХдкФФИіЭАЕБжаЁЃ
АбБэЃЈЛђепЗжЧјЃЉзщжЏГЩЭАЃЈBucketЃЉгаСНИіРэгЩЃК
ЃЈ1ЃЉЛёЕУИќИпЕФВщбЏДІРэаЇТЪЁЃЭАЮЊБэМгЩЯСЫЖюЭтЕФНсЙЙЃЌHive дкДІРэгааЉВщбЏЪБФмРћгУетИіНсЙЙЁЃОпЬхЖјбдЃЌСЌНгСНИідкЃЈАќКЌСЌНгСаЕФЃЉЯрЭЌСаЩЯЛЎЗжСЫЭАЕФБэЃЌПЩвдЪЙгУ
Map ЖЫСЌНг ЃЈMap-side joinЃЉИпаЇЕФЪЕЯжЁЃБШШчJOINВйзїЁЃЖдгкJOINВйзїСНИіБэгавЛИіЯрЭЌЕФСаЃЌШчЙћЖдетСНИіБэЖМНјааСЫЭАВйзїЁЃФЧУДНЋБЃДцЯрЭЌСажЕЕФЭАНјааJOINВйзїОЭПЩвдЃЌПЩвдДѓДѓНЯЩйJOINЕФЪ§ОнСПЁЃ
ЃЈ2ЃЉЪЙШЁбљЃЈsamplingЃЉИќИпаЇЁЃдкДІРэДѓЙцФЃЪ§ОнМЏЪБЃЌдкПЊЗЂКЭаоИФВщбЏЕФНзЖЮЃЌШчЙћФмдкЪ§ОнМЏЕФвЛаЁВПЗжЪ§ОнЩЯЪддЫааВщбЏЃЌЛсДјРДКмЖрЗНБуЁЃ
ОпЬхЪЕР§
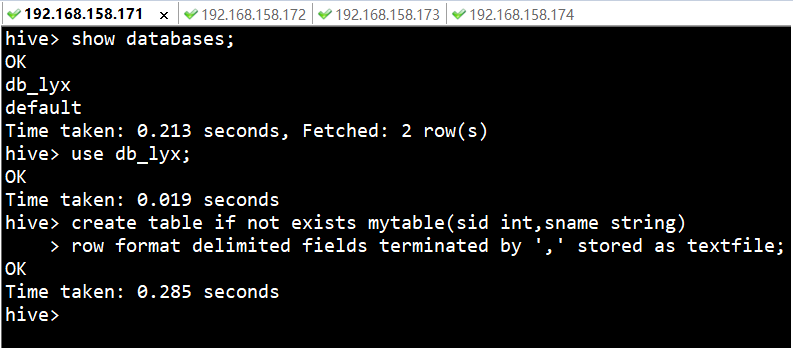
1ЁЂ ДДНЈФкВПБэmytableЁЃ
| hive>
create table if not exists mytable(sid int,sname
string)
> row format delimited fields
terminated by ',' stored as textfile;
|
ЪОР§ЃЌ ЯдЪОШчЯТЃК
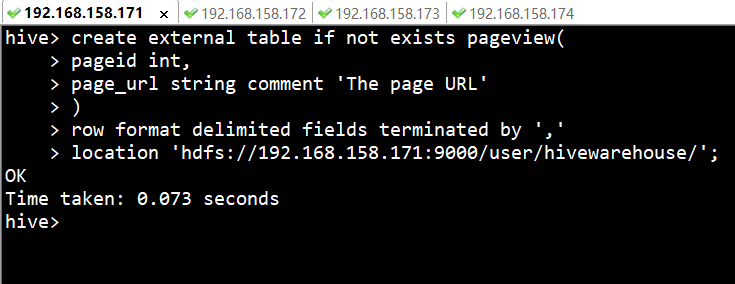
2ЁЂ ДДНЈЭтВПБэpageviewЁЃ
| hive>
create external table if not exists pageview(
> pageid int,
> page_url string comment
'The page URL'
> )
> row format delimited fields
terminated by ','
> location 'hdfs://192.168.158.171:9000/user/hivewarehouse/';
|
3ЁЂ ДДНЈЗжЧјБэinvitesЁЃ
| hive>
create table student_p(
> Sno int,
> Sname string,
> Sex string,
> Sage int,
> Sdept string)
> partitioned by(part string)
> row format delimited fields
terminated by ','stored as textfile;
|
4ЁЂ ДДНЈДјЭАЕФБэstudentЁЃ
| hive>
create table student(id int,age int,name string)
> partitioned by(stat_data
string)
> clustered by(id) sorted
by(age) into 2 buckets
> row format delimited fields
terminated by ',';
|
2.1.2 аоИФБэ
діМг/ЩОГ§ЗжЧј
гяЗЈНсЙЙ
| ALTER
TABLE table_name ADD [IF NOT EXISTS] partition_spec
[ LOCATION 'location1' ] partition_spec [ LOCATION
'location2' ] ...
partition_spec:
: PARTITION (partition_col =
partition_col_value, partition_col = partiton_col_value,
...)
ALTER TABLE table_name DROP
partition_spec, partition_spec,...
|
ОпЬхЪЕР§
| alter table
student_p add partition(part='a') partition(part='b'); |
жиУќУћБэ
гяЗЈНсЙЙ
| ALTER TABLE
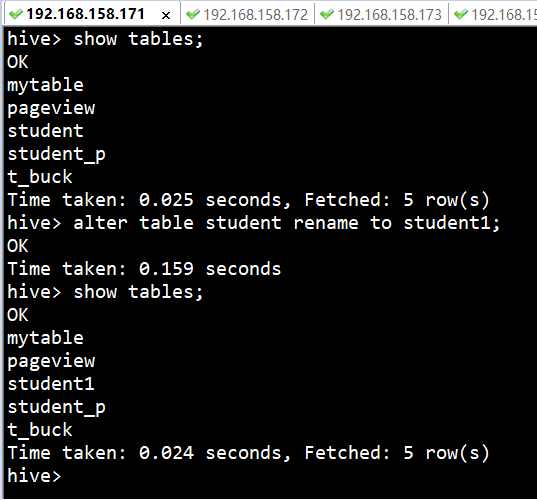
table_name RENAME TO new_table_name |
ОпЬхЪЕР§
| hive> alter
table student rename to student1; |
діМг/ИќаТСа
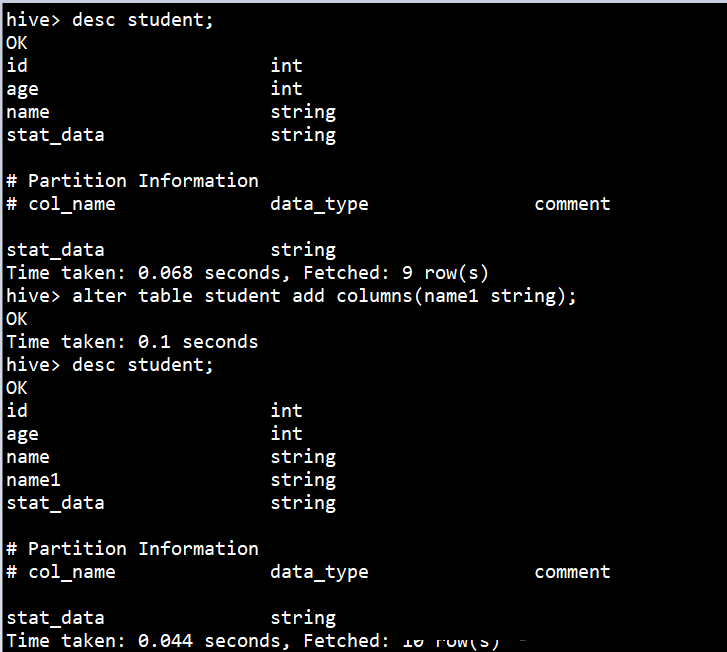
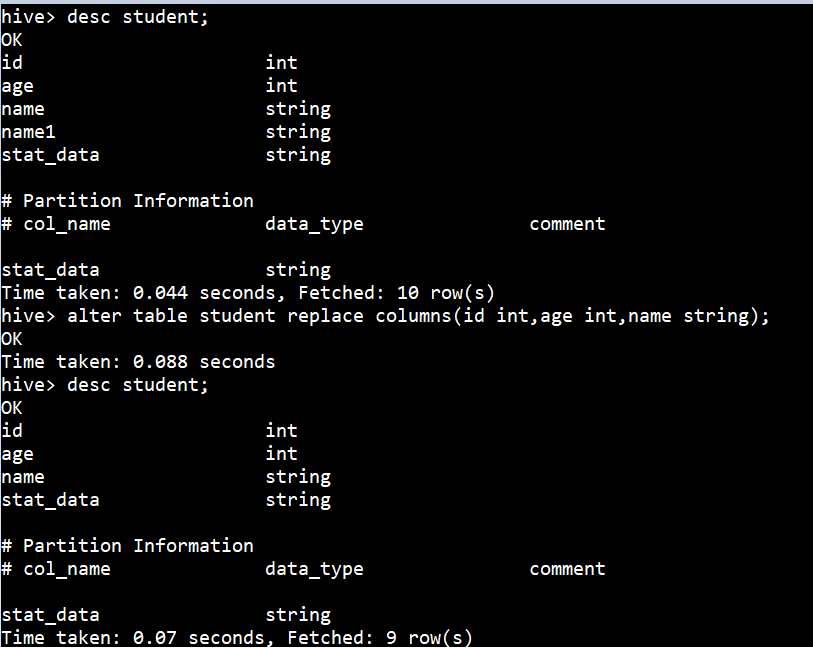
гяЗЈНсЙЙ
| ALTER TABLE
table_name ADD|REPLACE COLUMNS (col_name data_type
[COMMENT col_comment], ...) |
зЂЃКADDЪЧДњБэаТдівЛзжЖЮЃЌзжЖЮЮЛжУдкЫљгаСаКѓУц(partitionСаЧА)ЃЌREPLACEдђЪЧБэЪОЬцЛЛБэжаЫљгазжЖЮЁЃ
| ALTER TABLE
table_name CHANGE [COLUMN] col_old_name col_new_name
column_type [COMMENT col_comment] [FIRST|AFTER
column_name] |
ОпЬхЪЕР§
2.1.3 ЯдЪОУќСю
| show
tables
show databases
show partitions
show functions
desc extended t_name;
desc formatted table_name;
|
2.2 DMLВйзї
2.2.1 Load
гяЗЈНсЙЙ
| LOAD
DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1,
partcol2=val2 ...)]
|
ЫЕУїЃК
1ЁЂ Load ВйзїжЛЪЧЕЅДПЕФИДжЦ/вЦЖЏВйзїЃЌНЋЪ§ОнЮФМўвЦЖЏЕН Hive БэЖдгІЕФЮЛжУЁЃ
2ЁЂ filepathЃК
ЯрЖдТЗОЖЃЌР§ШчЃКproject/data1
ОјЖдТЗОЖЃЌР§ШчЃК/user/hive/project/data1
АќКЌФЃЪНЕФЭъећ URIЃЌСаШчЃК
| hdfs://namenode:9000/user/hive/project/data1 |
3ЁЂ LOCALЙиМќзж
ШчЙћжИЖЈСЫ LOCALЃЌ load УќСюЛсШЅВщевБОЕиЮФМўЯЕЭГжаЕФ filepathЁЃ
ШчЙћУЛгажИЖЈ LOCAL ЙиМќзжЃЌдђИљОнinpathжаЕФuriВщевЮФМў
4ЁЂ OVERWRITE ЙиМќзж
ШчЙћЪЙгУСЫ OVERWRITE ЙиМќзжЃЌдђФПБъБэЃЈЛђепЗжЧјЃЉжаЕФФкШнЛсБЛЩОГ§ЃЌШЛКѓдйНЋ filepath
жИЯђЕФЮФМў/ФПТМжаЕФФкШнЬэМгЕНБэ/ЗжЧјжаЁЃ
ШчЙћФПБъБэЃЈЗжЧјЃЉвбОгавЛИіЮФМўЃЌВЂЧвЮФМўУћКЭ filepath жаЕФЮФМўУћГхЭЛЃЌФЧУДЯжгаЕФЮФМўЛсБЛаТЮФМўЫљЬцДњЁЃ
ОпЬхЪЕР§
| 1ЁЂ
МгдиЯрЖдТЗОЖЪ§ОнЁЃ
hive> load data local inpath
'sc.txt' overwrite into table sc;
2ЁЂ МгдиОјЖдТЗОЖЪ§ОнЁЃ
hive> load data local inpath
'/home/hadoop/hivedata/students.txt' overwrite
into table student;
3ЁЂ МгдиАќКЌФЃЪНЪ§ОнЁЃ
hive> load data inpath 'hdfs://mini1:9000/hivedata/course.txt'
overwrite into table course;
4ЁЂ OVERWRITEЙиМќзжЪЙгУЁЃ
|
ШчЩЯ
2.2.2 Insert
НЋВщбЏНсЙћВхШыHiveБэ
гяЗЈНсЙЙ
| INSERT
OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1,
partcol2=val2 ...)] select_statement1 FROM from_statement
Multiple inserts:
FROM from_statement
INSERT OVERWRITE TABLE tablename1
[PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1
[INSERT OVERWRITE TABLE tablename2
[PARTITION ...] select_statement2] ...
Dynamic partition inserts:
INSERT OVERWRITE TABLE tablename
PARTITION (partcol1[=val1], partcol2[=val2]
...) select_statement FROM from_statement
|
ОпЬхЪЕР§
1ЁЂЛљБОФЃЪНВхШыЁЃ
2ЁЂЖрВхШыФЃЪНЁЃ
3ЁЂздЖЏЗжЧјФЃЪНЁЃ
ЕМГіБэЪ§Он
гяЗЈНсЙЙ
| INSERT
OVERWRITE [LOCAL] DIRECTORY directory1 SELECT
... FROM ...
multiple inserts:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY
directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY
directory2 select_statement2] ...
|
ОпЬхЪЕР§
1ЁЂЕМГіЮФМўЕНБОЕиЁЃ
| hive>
insert overwrite local directory '/home/hadoop/hivedata/outdata'
> select * from student;
|
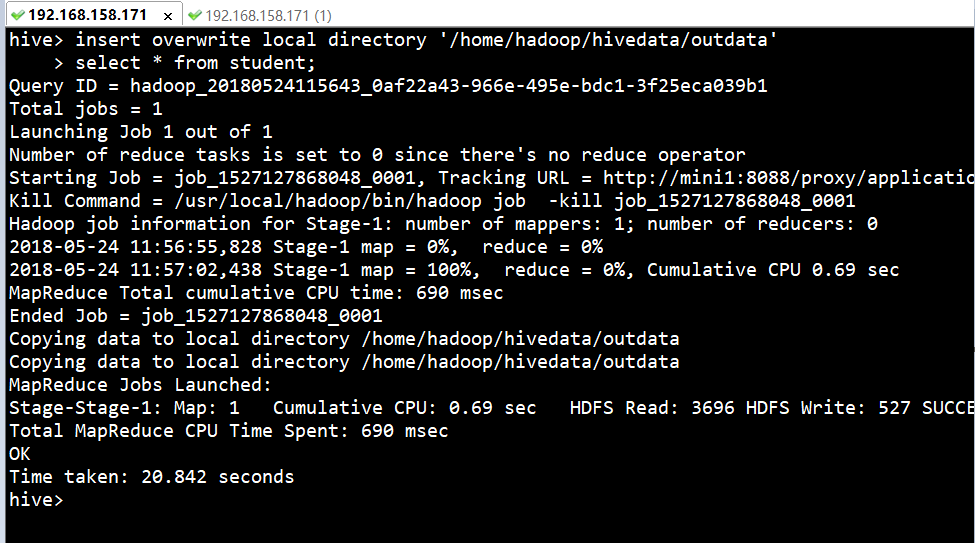
ЫЕУїЃК
Ъ§ОнаДШыЕНЮФМўЯЕЭГЪБНјааЮФБОађСаЛЏЃЌЧвУПСагУ^AРДЧјЗжЃЌ\nЮЊЛЛааЗћЁЃгУmoreУќСюВщПДЪБВЛШнвзПДГіЗжИюЗћЃЌ
ПЩвдЪЙгУ: sed -e 's/\x01/|/g' filenameРДВщПДЁЃ
ШчЃКsed -e 's/\x01/,/g' 000000_0
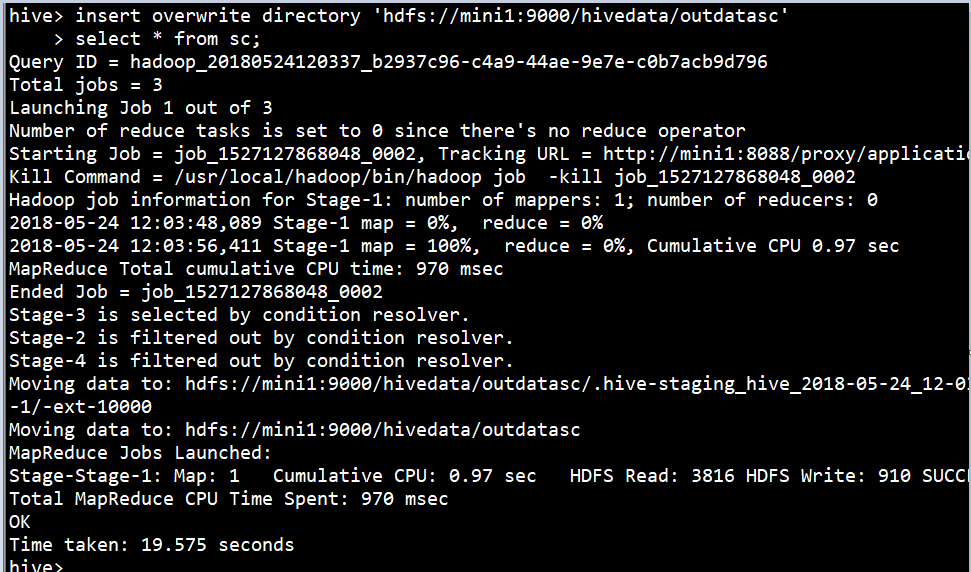
2ЁЂЕМГіЪ§ОнЕНHDFSЁЃ
| hive>
insert overwrite directory 'hdfs://mini1:9000/hivedata/outdatasc'
> select * from sc;
|
2.2.3 SELECT
ЛљБОЕФSelectВйзї
гяЗЈНсЙЙ
| SELECT
[ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list]
[SORT BY| ORDER BY col_list]
]
[LIMIT number]
|
зЂЃК1ЁЂorder by ЛсЖдЪфШызіШЋОжХХађЃЌвђДЫжЛгавЛИіreducerЃЌЛсЕМжТЕБЪфШыЙцФЃНЯДѓЪБЃЌашвЊНЯГЄЕФМЦЫуЪБМфЁЃ
2ЁЂsort byВЛЪЧШЋОжХХађЃЌЦфдкЪ§ОнНјШыreducerЧАЭъГЩХХађЁЃвђДЫЃЌШчЙћгУsort byНјааХХађЃЌВЂЧвЩшжУmapred.reduce.tasks>1ЃЌдђsort
byжЛБЃжЄУПИіreducerЕФЪфГігаађЃЌВЛБЃжЄШЋОжгаађЁЃ
3ЁЂdistribute byИљОнdistribute byжИЖЈЕФФкШнНЋЪ§ОнЗжЕНЭЌвЛИіreducerЁЃ
4ЁЂCluster by Г§СЫОпгаDistribute byЕФЙІФмЭтЃЌЛЙЛсЖдИУзжЖЮНјааХХађЁЃвђДЫЃЌГЃГЃШЯЮЊcluster
by = distribute by + sort by
ОпЬхЪЕР§
1ЁЂЛёШЁФъСфДѓЕФ3ИібЇЩњЁЃ
| hive> select
sno,sname,sage from student order by sage desc
limit 3; |
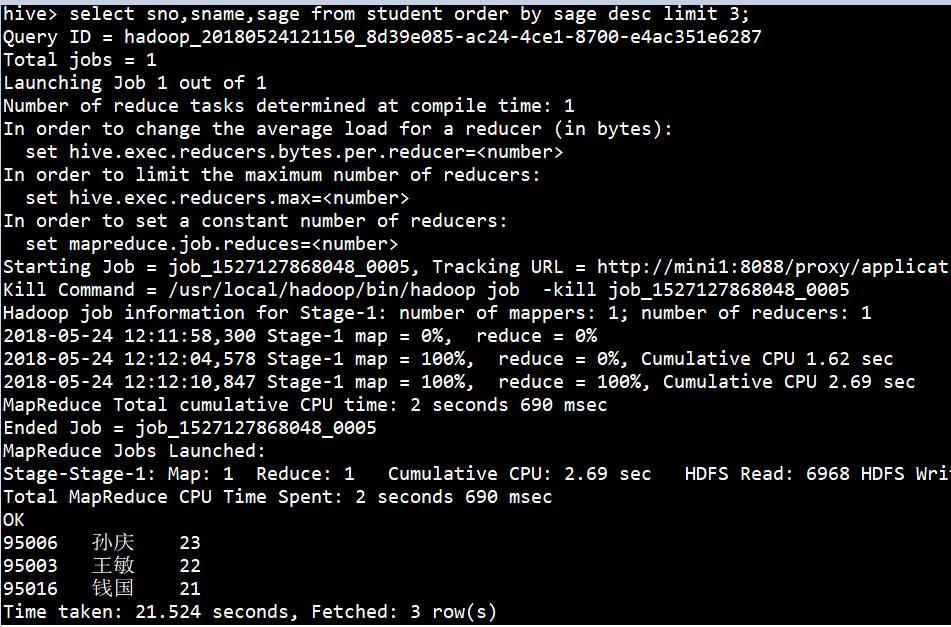
2ЁЂВщбЏбЇЩњаХЯЂАДФъСфЃЌНЕађХХађЁЃ
hive> select sno,sname,sage from student sort
by sage desc;
hive> select sno,sname,sage from student order
by sage desc;
hive> select sno,sname,sage from student distribute
by sage;
3ЁЂАДбЇЩњУћГЦЛузмбЇЩњФъСфЁЃ
hive> select sname,sum(sage) from student group
by sname;
2.3 Hive Join
гяЗЈНсЙЙ
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN
table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference
join_condition
Hive жЇГжЕШжЕСЌНгЃЈequality joinsЃЉЁЂЭтСЌНгЃЈouter joinsЃЉКЭЃЈleft/right
joinsЃЉЁЃHive ВЛжЇГжЗЧЕШжЕЕФСЌНгЃЈКѓајАцБОвбОжЇГжЃЉЃЌвђЮЊЗЧЕШжЕСЌНгЗЧГЃФбзЊЛЏЕН map/reduce
ШЮЮёЁЃ
СэЭтЃЌHive жЇГжЖргк 2 ИіБэЕФСЌНгЁЃ
аД join ВщбЏЪБЃЌашвЊзЂвтМИИіЙиМќЕуЃК
1. жЛжЇГжЕШжЕjoin
Р§ШчЃК
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
ЪЧе§ШЗЕФЃЌШЛЖј:
SELECT a.* FROM a JOIN b ON (a.id>b.id)
ЪЧДэЮѓЕФЁЃ
tips:КѓајАцБОвбОПЩвджЇГжВЛЕШжЕ
2. ПЩвд join Жргк 2 ИіБэЁЃ
Р§Шч
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
ШчЙћjoinжаЖрИіБэЕФ join key ЪЧЭЌвЛИіЃЌдђ join ЛсБЛзЊЛЏЮЊЕЅИі map/reduce
ШЮЮёЃЌР§ШчЃК
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c
ON (c.key = b.key1)
БЛзЊЛЏЮЊЕЅИі map/reduce ШЮЮёЃЌвђЮЊ join жажЛЪЙгУСЫ b.key1 зїЮЊ join
keyЁЃ
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key
= b.key1)
JOIN c ON (c.key = b.key2)
ЖјетвЛ join БЛзЊЛЏЮЊ 2 Иі map/reduce ШЮЮёЁЃвђЮЊ b.key1 гУгкЕквЛДЮ join
ЬѕМўЃЌЖј b.key2 гУгкЕкЖўДЮ joinЁЃ
3ЃЎjoin ЪБЃЌУПДЮ map/reduce ШЮЮёЕФТпМЃК
reducer ЛсЛКДц join ађСажаГ§СЫзюКѓвЛИіБэЕФЫљгаБэЕФМЧТМЃЌдйЭЈЙ§зюКѓвЛИіБэНЋНсЙћађСаЛЏЕНЮФМўЯЕЭГЁЃетвЛЪЕЯжгажњгкдк
reduce ЖЫМѕЩйФкДцЕФЪЙгУСПЁЃЪЕМљжаЃЌгІИУАбзюДѓЕФФЧИіБэаДдкзюКѓЃЈЗёдђЛсвђЮЊЛКДцРЫЗбДѓСПФкДцЃЉЁЃР§ШчЃК
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
ЫљгаБэЖМЪЙгУЭЌвЛИі join keyЃЈЪЙгУ 1 ДЮ map/reduce ШЮЮёМЦЫуЃЉЁЃReduce
ЖЫЛсЛКДц a БэКЭ b БэЕФМЧТМЃЌШЛКѓУПДЮШЁЕУвЛИі c БэЕФМЧТМОЭМЦЫувЛДЮ join НсЙћЃЌРрЫЦЕФЛЙгаЃК
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
етРягУСЫ 2 ДЮ map/reduce ШЮЮёЁЃЕквЛДЮЛКДц a БэЃЌгУ b БэађСаЛЏЃЛЕкЖўДЮЛКДцЕквЛДЮ
map/reduce ШЮЮёЕФНсЙћЃЌШЛКѓгУ c БэађСаЛЏЁЃ
4ЃЎLEFTЃЌRIGHT КЭ FULL OUTER ЙиМќзжгУгкДІРэ join жаПеМЧТМЕФЧщПі
Р§ШчЃК
SELECT a.val, b.val FROM
a LEFT OUTER JOIN b ON (a.key=b.key)
ЖдгІЫљга a БэжаЕФМЧТМЖМгавЛЬѕМЧТМЪфГіЁЃЪфГіЕФНсЙћгІИУЪЧ a.val, b.valЃЌЕБ a.key=b.key
ЪБЃЌЖјЕБ b.key жаевВЛЕНЕШжЕЕФ a.key МЧТМЪБвВЛсЪфГі:
a.val, NULL
Ыљвд a БэжаЕФЫљгаМЧТМЖМБЛБЃСєСЫЃЛ
ЁАa RIGHT OUTER JOIN bЁБЛсБЃСєЫљга b БэЕФМЧТМЁЃ
Join ЗЂЩњдк WHERE згОфжЎЧАЁЃШчЙћФуЯыЯожЦ join ЕФЪфГіЃЌгІИУдк WHERE згОфжааДЙ§ТЫЬѕМўЁЊЁЊЛђЪЧдк
join згОфжааДЁЃетРяУцвЛИіШнвзЛьЯ§ЕФЮЪЬтЪЧБэЗжЧјЕФЧщПіЃК
SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
Лс join a БэЕН b БэЃЈOUTER JOINЃЉЃЌСаГі a.val КЭ b.val ЕФМЧТМЁЃWHERE
ДгОфжаПЩвдЪЙгУЦфЫћСазїЮЊЙ§ТЫЬѕМўЁЃЕЋЪЧЃЌШчЧАЫљЪіЃЌШчЙћ b БэжаевВЛЕНЖдгІ a БэЕФМЧТМЃЌb БэЕФЫљгаСаЖМЛсСаГі
NULLЃЌАќРЈ ds СаЁЃвВОЭЪЧЫЕЃЌjoin ЛсЙ§ТЫ b БэжаВЛФмевЕНЦЅХф a Бэ join key
ЕФЫљгаМЧТМЁЃетбљЕФЛАЃЌLEFT OUTER ОЭЪЙЕУВщбЏНсЙћгы WHERE згОфЮоЙиСЫЁЃНтОіЕФАьЗЈЪЧдк
OUTER JOIN ЪБЪЙгУвдЯТгяЗЈЃК
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND
b.ds='2009-07-07' AND
a.ds='2009-07-07')
етвЛВщбЏЕФНсЙћЪЧдЄЯШдк join НзЖЮЙ§ТЫЙ§ЕФЃЌЫљвдВЛЛсДцдкЩЯЪіЮЪЬтЁЃетвЛТпМвВПЩвдгІгУгк RIGHT
КЭ FULL РраЭЕФ join жаЁЃ
Join ЪЧВЛФмНЛЛЛЮЛжУЕФЁЃЮоТлЪЧ LEFT ЛЙЪЧ RIGHT joinЃЌЖМЪЧзѓСЌНгЕФЁЃ
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
ЯШ join a БэЕН b БэЃЌЖЊЦњЕєЫљга join key жаВЛЦЅХфЕФМЧТМЃЌШЛКѓгУетвЛжаМфНсЙћКЭ
c Бэзі joinЁЃетвЛБэЪігавЛИіВЛЬЋУїЯдЕФЮЪЬтЃЌОЭЪЧЕБвЛИі key дк a БэКЭ c БэЖМДцдкЃЌЕЋЪЧ
b БэжаВЛДцдкЕФЪБКђЃКећИіМЧТМдкЕквЛДЮ joinЃЌМД a JOIN b ЕФЪБКђЖМБЛЖЊЕєСЫЃЈАќРЈa.val1ЃЌa.val2КЭa.keyЃЉЃЌШЛКѓЮвУЧдйКЭ
c Бэ join ЕФЪБКђЃЌШчЙћ c.key гы a.key Лђ b.key ЯрЕШЃЌОЭЛсЕУЕНетбљЕФНсЙћЃКNULL,
NULL, NULL, c.val
ОпЬхЪЕР§
1ЁЂ ВщбЏбЁаоСЫПЮГЬЕФбЇЩњаеУћ
hive> select distinct Sname from student inner
join sc on student.Sno=Sc.Sno;
2.ВщбЏбЁаоСЫ3УХвдЩЯЕФПЮГЬЕФбЇЩњбЇКХ
hive> select Sno from (select Sno,count(Cno) CountCno
from sc group by Sno)a where a.CountCno>3;
3 Hive ShellВЮЪ§
3.1 HiveУќСюаа
гяЗЈНсЙЙ
hive [-hiveconf x=y]* [<-i filename>]* [<-f
filename>|<-e query-string>] [-S]
ЫЕУїЃК
1ЁЂ -i ДгЮФМўГѕЪМЛЏHQLЁЃ
2ЁЂ -eДгУќСюаажДаажИЖЈЕФHQL
3ЁЂ -f жДааHQLНХБО
4ЁЂ -v ЪфГіжДааЕФHQLгяОфЕНПижЦЬЈ
5ЁЂ -p <port> connect to Hive Server on port
number
6ЁЂ -hiveconf x=y Use this to set hive/hadoop configuration
variables.
ОпЬхЪЕР§
1ЁЂдЫаавЛИіВщбЏЁЃ
hive -e 'select count(*) from student'
2ЁЂдЫаавЛИіЮФМўЁЃ
hive -f hql.hql
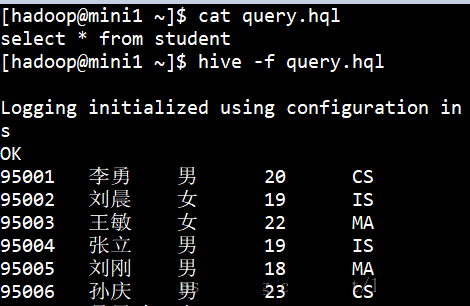
3ЁЂдЫааВЮЪ§ЮФМўЁЃ
hive -i initHQL.conf
3.2 HiveВЮЪ§ХфжУЗНЪН
HiveВЮЪ§ДѓШЋЃК
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
ПЊЗЂHiveгІгУЪБЃЌВЛПЩБмУтЕиашвЊЩшЖЈHiveЕФВЮЪ§ЁЃЩшЖЈHiveЕФВЮЪ§ПЩвдЕїгХHQLДњТыЕФжДаааЇТЪЃЌЛђАяжњЖЈЮЛЮЪЬтЁЃШЛЖјЪЕМљжаОГЃгіЕНЕФвЛИіЮЪЬтЪЧЃЌЮЊЪВУДЩшЖЈЕФВЮЪ§УЛгаЦ№зїгУЃПетЭЈГЃЪЧДэЮѓЕФЩшЖЈЗНЪНЕМжТЕФЁЃ
ЖдгквЛАуВЮЪ§ЃЌгавдЯТШ§жжЩшЖЈЗНЪНЃК
1.)ХфжУЮФМў
2.)УќСюааВЮЪ§
3.)ВЮЪ§ЩљУї
ХфжУЮФМўЃКHiveЕФХфжУЮФМўАќРЈ
1.)гУЛЇздЖЈвхХфжУЮФМўЃК$HIVE_CONF_DIR/hive-site.xml
2.)ФЌШЯХфжУЮФМўЃК$HIVE_CONF_DIR/hive-default.xml
гУЛЇздЖЈвхХфжУЛсИВИЧФЌШЯХфжУЁЃ
СэЭтЃЌHiveвВЛсЖСШыHadoopЕФХфжУЃЌвђЮЊHiveЪЧзїЮЊHadoopЕФПЭЛЇЖЫЦєЖЏЕФЃЌHiveЕФХфжУЛсИВИЧHadoopЕФХфжУЁЃ
ХфжУЮФМўЕФЩшЖЈЖдБОЛњЦєЖЏЕФЫљгаHiveНјГЬЖМгааЇЁЃ
УќСюааВЮЪ§ЃКЦєЖЏHiveЃЈПЭЛЇЖЫЛђServerЗНЪНЃЉЪБЃЌПЩвддкУќСюааЬэМг-hiveconf param=valueРДЩшЖЈВЮЪ§ЃЌР§ШчЃК
bin/hive -hiveconf hive.root.logger=INFO,console
етвЛЩшЖЈЖдБОДЮЦєЖЏЕФSessionЃЈЖдгкServerЗНЪНЦєЖЏЃЌдђЪЧЫљгаЧыЧѓЕФSessionsЃЉгааЇЁЃ
ВЮЪ§ЩљУїЃКПЩвддкHQLжаЪЙгУSETЙиМќзжЩшЖЈВЮЪ§ЃЌР§ШчЃК
set mapred.reduce.tasks=100;
етвЛЩшЖЈЕФзїгУгђвВЪЧsessionМЖЕФЁЃ
ЩЯЪіШ§жжЩшЖЈЗНЪНЕФгХЯШМЖвРДЮЕндіЁЃМДВЮЪ§ЩљУїИВИЧУќСюааВЮЪ§ЃЌУќСюааВЮЪ§ИВИЧХфжУЮФМўЩшЖЈЁЃзЂвтФГаЉЯЕЭГМЖЕФВЮЪ§ЃЌР§Шчlog4jЯрЙиЕФЩшЖЈЃЌБиаыгУЧАСНжжЗНЪНЩшЖЈЃЌвђЮЊФЧаЉВЮЪ§ЕФЖСШЁдкSessionНЈСЂвдЧАвбОЭъГЩСЫЁЃ
4. HiveКЏЪ§
4.1 ФкжУдЫЫуЗћ
ФкШнНЯЖрЃЌМћЁЖHiveЙйЗНЮФЕЕЁЗ
http://hive.apache.org/
4.2 ФкжУКЏЪ§
ФкШнНЯЖрЃЌМћЁЖHiveЙйЗНЮФЕЕЁЗ
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
4.3 HiveздЖЈвхКЏЪ§КЭTransform
ЕБHiveЬсЙЉЕФФкжУКЏЪ§ЮоЗЈТњзуФуЕФвЕЮёДІРэашвЊЪБЃЌДЫЪБОЭПЩвдПМТЧЪЙгУгУЛЇздЖЈвхКЏЪ§ЃЈUDFЃКuser-defined
functionЃЉЁЃ
4.3.1 здЖЈвхКЏЪ§РрБ№
UDF зїгУгкЕЅИіЪ§ОнааЃЌВњЩњвЛИіЪ§ОнаазїЮЊЪфГіЁЃЃЈЪ§бЇКЏЪ§ЃЌзжЗћДЎКЏЪ§ЃЉ
UDAFЃЈгУЛЇЖЈвхОлМЏКЏЪ§ЃЉЃКНгЪеЖрИіЪфШыЪ§ОнааЃЌВЂВњЩњвЛИіЪфГіЪ§ОнааЁЃЃЈcountЃЌmaxЃЉ
4.3.2 UDFПЊЗЂЪЕР§
1ЁЂЯШПЊЗЂвЛИіjavaРрЃЌМЬГаUDFЃЌВЂжидиevaluateЗНЗЈ
| package cn.lyx.bigdata.udf
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public final class Lower extends UDF{
public Text evaluate(final Text s){
if(s==null){return null;}
return new Text(s.toString().toLowerCase());
}
} |
2ЁЂДђГЩjarАќЩЯДЋЕНЗўЮёЦї
3ЁЂНЋjarАќЬэМгЕНhiveЕФclasspath
| hive>add
JAR /home/hadoop/udf.jar; |
4ЁЂДДНЈСйЪБКЏЪ§гыПЊЗЂКУЕФjava classЙиСЊ
| Hive>create
temporary function toprovince as 'cn.lyx.bigdata.udf.ToProvince'; |
5ЁЂМДПЩдкhqlжаЪЙгУздЖЈвхЕФКЏЪ§strip
| Select strip(name),age
from t_test; |
4.3.3 TransformЪЕЯж
HiveЕФ TRANSFORM ЙиМќзжЬсЙЉСЫдкSQLжаЕїгУздаДНХБОЕФЙІФм
ЪЪКЯЪЕЯжHiveжаУЛгаЕФЙІФмгжВЛЯыаДUDFЕФЧщПі
ЪЙгУЪОР§1ЃКЯТУцетОфsqlОЭЪЧНшгУСЫweekday_mapper.pyЖдЪ§ОнНјааСЫДІРэ.
| CREATE TABLE
u_data_new (
movieid INT,
rating INT,
weekday INT,
userid INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
add FILE weekday_mapper.py;
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (movieid, rating, unixtime,userid)
USING 'python weekday_mapper.py'
AS (movieid, rating, weekday,userid)
FROM u_data; |
Цфжаweekday_mapper.pyФкШнШчЯТ
<table width="70%"
border="0" align="center"
id="ccc" cellpadding="7" cellspacing="1"
bgcolor="#CCCCCC" class="content"
style="text-indent: 0em;">
<tr
bgcolor="#FFFFFF">
<td height="25"
bgcolor="#f5f5f5"> 1</td>
</tr>
</table>
|
ЪЙгУЪОР§2ЃКЯТУцЕФР§згдђЪЧЪЙгУСЫshellЕФcatУќСюРДДІРэЪ§Он
| FROM invites
a INSERT OVERWRITE TABLE events SELECT TRANSFORM(a.foo,
a.bar) AS (oof, rab) USING '/bin/cat' WHERE a.ds
> '2008-08-08'; |
|









