| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ
Spark StreamingИХЪіКЭЯрЙиЪѕгяЃЌStreamingдЫаадРэЁЂМмЙЙЁЂБрГЬФЃаЭМАШнДэЁЂГжОУЛЏКЭадФмЕїгХЕШЯрЙиФкШнЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1ЁЂSpark StreamingМђНщ
1.1 ИХЪі
Spark Streaming ЪЧSparkКЫаФAPIЕФвЛИіРЉеЙЃЌПЩвдЪЕЯжИпЭЬЭТСПЕФЁЂОпБИШнДэЛњжЦЕФЪЕЪБСїЪ§ОнЕФДІРэЁЃжЇГжДгЖржжЪ§ОндДЛёШЁЪ§ОнЃЌАќРЈKafkЁЂFlumeЁЂTwitterЁЂZeroMQЁЂKinesis
вдМАTCP socketsЃЌДгЪ§ОндДЛёШЁЪ§ОнжЎКѓЃЌПЩвдЪЙгУжюШчmapЁЂreduceЁЂjoinКЭwindowЕШИпМЖКЏЪ§НјааИДдгЫуЗЈЕФДІРэЁЃзюКѓЛЙПЩвдНЋДІРэНсЙћДцДЂЕНЮФМўЯЕЭГЃЌЪ§ОнПтКЭЯжГЁвЧБэХЬЁЃдкЁАOne
Stack rule them allЁБЕФЛљДЁЩЯЃЌЛЙПЩвдЪЙгУSparkЕФЦфЫћзгПђМмЃЌШчМЏШКбЇЯАЁЂЭММЦЫуЕШЃЌЖдСїЪ§ОнНјааДІРэЁЃ
Spark StreamingДІРэЕФЪ§ОнСїЭМЃК

SparkЕФИїИізгПђМмЃЌЖМЪЧЛљгкКЫаФSparkЕФЃЌSpark StreamingдкФкВПЕФДІРэЛњжЦЪЧЃЌНгЪеЪЕЪБСїЕФЪ§ОнЃЌВЂИљОнвЛЖЈЕФЪБМфМфИєВ№ЗжГЩвЛХњХњЕФЪ§ОнЃЌШЛКѓЭЈЙ§Spark
EngineДІРэетаЉХњЪ§ОнЃЌзюжеЕУЕНДІРэКѓЕФвЛХњХњНсЙћЪ§ОнЁЃ
ЖдгІЕФХњЪ§ОнЃЌдкSparkФкКЫЖдгІвЛИіRDDЪЕР§ЃЌвђДЫЃЌЖдгІСїЪ§ОнЕФDStreamПЩвдПДГЩЪЧвЛзщRDDsЃЌМДRDDЕФвЛИіађСаЁЃЭЈЫзЕуРэНтЕФЛАЃЌдкСїЪ§ОнЗжГЩвЛХњвЛХњКѓЃЌЭЈЙ§вЛИіЯШНјЯШГіЕФЖгСаЃЌШЛКѓ
Spark EngineДгИУЖгСажавРДЮШЁГівЛИіИіХњЪ§ОнЃЌАбХњЪ§ОнЗтзАГЩвЛИіRDDЃЌШЛКѓНјааДІРэЃЌетЪЧвЛИіЕфаЭЕФЩњВњепЯћЗбепФЃаЭЃЌЖдгІЕФОЭгаЩњВњепЯћЗбепФЃаЭЕФЮЪЬтЃЌМДШчКЮаЕїЩњВњЫйТЪКЭЯћЗбЫйТЪЁЃ
1.2 ЪѕгяЖЈвх
lРыЩЂСїЃЈdiscretized streamЃЉЛђDStreamЃКетЪЧSpark StreamingЖдФкВПГжајЕФЪЕЪБЪ§ОнСїЕФГщЯѓУшЪіЃЌМДЮвУЧДІРэЕФвЛИіЪЕЪБЪ§ОнСїЃЌдкSpark
StreamingжаЖдгІгквЛИіDStream ЪЕР§ЁЃ
lХњЪ§ОнЃЈbatch dataЃЉЃКетЪЧЛЏећЮЊСуЕФЕквЛВНЃЌНЋЪЕЪБСїЪ§ОнвдЪБМфЦЌЮЊЕЅЮЛНјааЗжХњЃЌНЋСїДІРэзЊЛЏЮЊЪБМфЦЌЪ§ОнЕФХњДІРэЁЃЫцзХГжајЪБМфЕФЭЦвЦЃЌетаЉДІРэНсЙћОЭаЮГЩСЫЖдгІЕФНсЙћЪ§ОнСїСЫЁЃ
lЪБМфЦЌЛђХњДІРэЪБМфМфИєЃЈ batch intervalЃЉЃКетЪЧШЫЮЊЕиЖдСїЪ§ОнНјааЖЈСПЕФБъзМЃЌвдЪБМфЦЌзїЮЊЮвУЧВ№ЗжСїЪ§ОнЕФвРОнЁЃвЛИіЪБМфЦЌЕФЪ§ОнЖдгІвЛИіRDDЪЕР§ЁЃ
lДАПкГЄЖШЃЈwindow lengthЃЉЃКвЛИіДАПкИВИЧЕФСїЪ§ОнЕФЪБМфГЄЖШЁЃБиаыЪЧХњДІРэЪБМфМфИєЕФБЖЪ§ЃЌ
lЛЌЖЏЪБМфМфИєЃКЧАвЛИіДАПкЕНКѓвЛИіДАПкЫљОЙ§ЕФЪБМфГЄЖШЁЃБиаыЪЧХњДІРэЪБМфМфИєЕФБЖЪ§
lInput DStream :вЛИіinput DStreamЪЧвЛИіЬиЪтЕФDStreamЃЌНЋSpark
StreamingСЌНгЕНвЛИіЭтВПЪ§ОндДРДЖСШЁЪ§ОнЁЃ
1.3 StormгыSpark StremingБШНЯ
lДІРэФЃаЭвдМАбгГй
ЫфШЛСНПђМмЖМЬсЙЉСЫПЩРЉеЙад(scalability)КЭПЩШнДэад(fault tolerance)ЃЌЕЋЪЧЫќУЧЕФДІРэФЃаЭДгИљБОЩЯЫЕЪЧВЛвЛбљЕФЁЃStormПЩвдЪЕЯжбЧУыМЖЪБбгЕФДІРэЃЌЖјУПДЮжЛДІРэвЛЬѕeventЃЌЖјSpark
StreamingПЩвддквЛИіЖЬднЕФЪБМфДАПкРяУцДІРэЖрЬѕ(batches)EventЁЃЫљвдЫЕStormПЩвдЪЕЯжбЧУыМЖЪБбгЕФДІРэЃЌЖјSpark
StreamingдђгавЛЖЈЕФЪБбгЁЃ
lШнДэКЭЪ§ОнБЃжЄ
ШЛЖјСНепЕФДњМлЖМЪЧШнДэЪБКђЕФЪ§ОнБЃжЄЃЌSpark StreamingЕФШнДэЮЊгазДЬЌЕФМЦЫуЬсЙЉСЫИќКУЕФжЇГжЁЃдкStormжаЃЌУПЬѕМЧТМдкЯЕЭГЕФвЦЖЏЙ§ГЬжаЖМашвЊБЛБъМЧИњзйЃЌЫљвдStormжЛФмБЃжЄУПЬѕМЧТМзюЩйБЛДІРэвЛДЮЃЌЕЋЪЧдЪаэДгДэЮѓзДЬЌЛжИДЪББЛДІРэЖрДЮЁЃетОЭвтЮЖзХПЩБфИќЕФзДЬЌПЩФмБЛИќаТСНДЮДгЖјЕМжТНсЙћВЛе§ШЗЁЃ
ШЮвЛЗНУцЃЌSpark StreamingНіНіашвЊдкХњДІРэМЖБ№ЖдМЧТМНјаазЗзйЃЌЫљвдЫћФмБЃжЄУПИіХњДІРэМЧТМНіНіБЛДІРэвЛДЮЃЌМДЪЙЪЧnodeНкЕуЙвЕєЁЃЫфШЛЫЕStormЕФ
Trident libraryПЩвдБЃжЄвЛЬѕМЧТМБЛДІРэвЛДЮЃЌЕЋЪЧЫќвРРЕгкЪТЮёИќаТзДЬЌЃЌЖјетИіЙ§ГЬЪЧКмТ§ЕФЃЌВЂЧвашвЊгЩгУЛЇШЅЪЕЯжЁЃ
lЪЕЯжКЭБрГЬAPI
StormжївЊЪЧгЩClojureгябдЪЕЯжЃЌSpark StreamingЪЧгЩScalaЪЕЯжЁЃШчЙћФуЯыПДПДетСНИіПђМмЪЧШчКЮЪЕЯжЕФЛђепФуЯыздЖЈвхвЛаЉЖЋЮїФуОЭЕУМЧзЁетвЛЕуЁЃStormЪЧгЩBackTypeКЭ
TwitterПЊЗЂЃЌЖјSpark StreamingЪЧдкUC BerkeleyПЊЗЂЕФЁЃ
StormЬсЙЉСЫJava APIЃЌЭЌЪБвВжЇГжЦфЫћгябдЕФAPIЁЃ Spark StreamingжЇГжScalaКЭJavaгябд(ЦфЪЕвВжЇГжPython)ЁЃ
lХњДІРэПђМмМЏГЩ
Spark StreamingЕФвЛИіКмАєЕФЬиадОЭЪЧЫќЪЧдкSparkПђМмЩЯдЫааЕФЁЃетбљФуОЭПЩвдЯыЪЙгУЦфЫћХњДІРэДњТывЛбљРДаДSpark
StreamingГЬађЃЌЛђепЪЧдкSparkжаНЛЛЅВщбЏЁЃетОЭМѕЩйСЫЕЅЖРБраДСїХњСПДІРэГЬађКЭРњЪЗЪ§ОнДІРэГЬађЁЃ
lЩњВњжЇГж
StormвбОГіЯжКУЖрФъСЫЃЌЖјЧвздДг2011ФъПЊЪМОЭдкTwitterФкВПЩњВњЛЗОГжаЪЙгУЃЌЛЙгаЦфЫћвЛаЉЙЋЫОЁЃЖјSpark
StreamingЪЧвЛИіаТЕФЯюФПЃЌВЂЧвдк2013ФъНіНіБЛSharethroughЪЙгУ(ОнзїепСЫНт)ЁЃ
StormЪЧ Hortonworks HadoopЪ§ОнЦНЬЈжаСїДІРэЕФНтОіЗНАИЃЌЖјSpark StreamingГіЯждк
MapRЕФЗжВМЪНЦНЬЈКЭClouderaЕФЦѓвЕЪ§ОнЦНЬЈжаЁЃГ§ДЫжЎЭтЃЌDatabricksЪЧЮЊSparkЬсЙЉММЪѕжЇГжЕФЙЋЫОЃЌАќРЈСЫSpark
StreamingЁЃ
ЫфШЛЫЕСНепЖМПЩвддкИїздЕФМЏШКПђМмжадЫааЃЌЕЋЪЧStormПЩвддкMesosЩЯдЫаа, ЖјSpark StreamingПЩвддкYARNКЭMesosЩЯдЫааЁЃ
2ЁЂдЫаадРэ
2.1 StreamingМмЙЙ
SparkStreamingЪЧвЛИіЖдЪЕЪБЪ§ОнСїНјааИпЭЈСПЁЂШнДэДІРэЕФСїЪНДІРэЯЕЭГЃЌПЩвдЖдЖржжЪ§ОндДЃЈШчKdfkaЁЂFlumeЁЂTwitterЁЂZeroКЭTCP
ЬзНгзжЃЉНјааРрЫЦMapЁЂReduceКЭJoinЕШИДдгВйзїЃЌВЂНЋНсЙћБЃДцЕНЭтВПЮФМўЯЕЭГЁЂЪ§ОнПтЛђгІгУЕНЪЕЪБвЧБэХЬЁЃ
lМЦЫуСїГЬЃКSpark StreamingЪЧНЋСїЪНМЦЫуЗжНтГЩвЛЯЕСаЖЬаЁЕФХњДІРэзївЕЁЃетРяЕФХњДІРэв§ЧцЪЧSpark
CoreЃЌвВОЭЪЧАбSpark StreamingЕФЪфШыЪ§ОнАДееbatch sizeЃЈШч1УыЃЉЗжГЩвЛЖЮвЛЖЮЕФЪ§ОнЃЈDiscretized
StreamЃЉЃЌУПвЛЖЮЪ§ОнЖМзЊЛЛГЩSparkжаЕФRDDЃЈResilient Distributed
DatasetЃЉЃЌШЛКѓНЋSpark StreamingжаЖдDStreamЕФTransformationВйзїБфЮЊеыЖдSparkжаЖдRDDЕФTransformationВйзїЃЌНЋRDDОЙ§ВйзїБфГЩжаМфНсЙћБЃДцдкФкДцжаЁЃећИіСїЪНМЦЫуИљОнвЕЮёЕФашЧѓПЩвдЖджаМфЕФНсЙћНјааЕўМгЛђепДцДЂЕНЭтВПЩшБИЁЃЯТЭМЯдЪОСЫSpark
StreamingЕФећИіСїГЬЁЃ
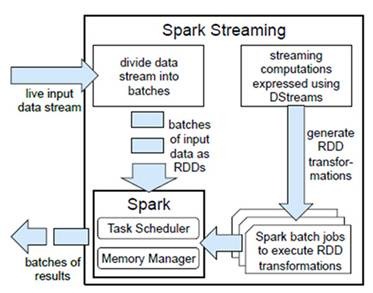
ЭМSpark StreamingЙЙМм
lШнДэадЃКЖдгкСїЪНМЦЫуРДЫЕЃЌШнДэаджСЙиживЊЁЃЪзЯШЮвУЧвЊУїШЗвЛЯТSparkжаRDDЕФШнДэЛњжЦЁЃУПвЛИіRDDЖМЪЧвЛИіВЛПЩБфЕФЗжВМЪНПЩжиЫуЕФЪ§ОнМЏЃЌЦфМЧТМзХШЗЖЈадЕФВйзїМЬГаЙиЯЕЃЈlineageЃЉЃЌЫљвджЛвЊЪфШыЪ§ОнЪЧПЩШнДэЕФЃЌФЧУДШЮвтвЛИіRDDЕФЗжЧјЃЈPartitionЃЉГіДэЛђВЛПЩгУЃЌЖМЪЧПЩвдРћгУдЪМЪфШыЪ§ОнЭЈЙ§зЊЛЛВйзїЖјжиаТЫуГіЕФЁЃ
ЖдгкSpark StreamingРДЫЕЃЌЦфRDDЕФДЋГаЙиЯЕШчЯТЭМЫљЪОЃЌЭМжаЕФУПвЛИіЭждВаЮБэЪОвЛИіRDDЃЌЭждВаЮжаЕФУПИідВаЮДњБэвЛИіRDDжаЕФвЛИіPartitionЃЌЭМжаЕФУПвЛСаЕФЖрИіRDDБэЪОвЛИіDStreamЃЈЭМжагаШ§ИіDStreamЃЉЃЌЖјУПвЛаазюКѓвЛИіRDDдђБэЪОУПвЛИіBatch
SizeЫљВњЩњЕФжаМфНсЙћRDDЁЃЮвУЧПЩвдПДЕНЭМжаЕФУПвЛИіRDDЖМЪЧЭЈЙ§lineageЯрСЌНгЕФЃЌгЩгкSpark
StreamingЪфШыЪ§ОнПЩвдРДздгкДХХЬЃЌР§ШчHDFSЃЈЖрЗнПНБДЃЉЛђЪЧРДздгкЭјТчЕФЪ§ОнСїЃЈSpark
StreamingЛсНЋЭјТчЪфШыЪ§ОнЕФУПвЛИіЪ§ОнСїПНБДСНЗнЕНЦфЫћЕФЛњЦїЃЉЖМФмБЃжЄШнДэадЃЌЫљвдRDDжаШЮвтЕФPartitionГіДэЃЌЖМПЩвдВЂааЕидкЦфЫћЛњЦїЩЯНЋШБЪЇЕФPartitionМЦЫуГіРДЁЃетИіШнДэЛжИДЗНЪНБШСЌајМЦЫуФЃаЭЃЈШчStormЃЉЕФаЇТЪИќИпЁЃ
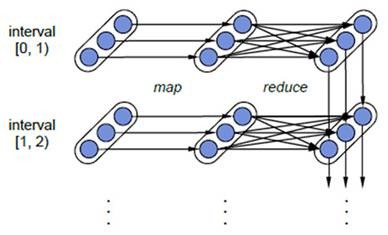
Spark StreamingжаRDDЕФlineageЙиЯЕЭМ
lЪЕЪБадЃКЖдгкЪЕЪБадЕФЬжТлЃЌЛсЧЃЩцЕНСїЪНДІРэПђМмЕФгІгУГЁОАЁЃSpark StreamingНЋСїЪНМЦЫуЗжНтГЩЖрИіSpark
JobЃЌЖдгкУПвЛЖЮЪ§ОнЕФДІРэЖМЛсОЙ§Spark DAGЭМЗжНтвдМАSparkЕФШЮЮёМЏЕФЕїЖШЙ§ГЬЁЃЖдгкФПЧААцБОЕФSpark
StreamingЖјбдЃЌЦфзюаЁЕФBatch SizeЕФбЁШЁдк0.5~2УыжгжЎМфЃЈStormФПЧАзюаЁЕФбгГйЪЧ100msзѓгвЃЉЃЌЫљвдSpark
StreamingФмЙЛТњзуГ§ЖдЪЕЪБадвЊЧѓЗЧГЃИпЃЈШчИпЦЕЪЕЪБНЛвзЃЉжЎЭтЕФЫљгаСїЪНзМЪЕЪБМЦЫуГЁОАЁЃ
lРЉеЙадгыЭЬЭТСПЃКSparkФПЧАдкEC2ЩЯвбФмЙЛЯпадРЉеЙЕН100ИіНкЕуЃЈУПИіНкЕу4CoreЃЉЃЌПЩвдвдЪ§УыЕФбгГйДІРэ6GB/sЕФЪ§ОнСПЃЈ60M
records/sЃЉЃЌЦфЭЬЭТСПвВБШСїааЕФStormИп2ЁЋ5БЖЃЌЭМ4ЪЧBerkeleyРћгУWordCountКЭGrepСНИігУР§ЫљзіЕФВтЪдЃЌдкGrepетИіВтЪджаЃЌSpark
StreamingжаЕФУПИіНкЕуЕФЭЬЭТСПЪЧ670k records/sЃЌЖјStormЪЧ115k records/sЁЃ
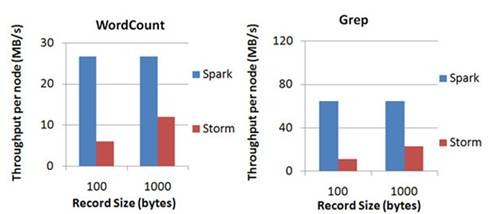
Spark StreamingгыStormЭЬЭТСПБШНЯЭМ
2.2 БрГЬФЃаЭ
DStreamЃЈDiscretized StreamЃЉзїЮЊSpark StreamingЕФЛљДЁГщЯѓЃЌЫќДњБэГжајадЕФЪ§ОнСїЁЃетаЉЪ§ОнСїМШПЩвдЭЈЙ§ЭтВПЪфШыдДРЕЛёШЁЃЌвВПЩвдЭЈЙ§ЯжгаЕФDstreamЕФtransformationВйзїРДЛёЕУЁЃдкФкВПЪЕЯжЩЯЃЌDStreamгЩвЛзщЪБМфађСаЩЯСЌајЕФRDDРДБэЪОЁЃУПИіRDDЖМАќКЌСЫздМКЬиЖЈЪБМфМфИєФкЕФЪ§ОнСїЁЃШчЭМ7-3ЫљЪОЁЃ

ЭМ7-3 DStreamжадкЪБМфжсЯТЩњГЩРыЩЂЕФRDDађСа
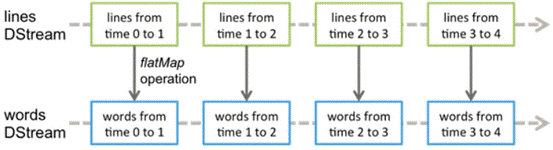
ЖдDStreamжаЪ§ОнЕФИїжжВйзївВЪЧгГЩфЕНФкВПЕФRDDЩЯРДНјааЕФЃЌШчЭМ7-4ЫљЪОЃЌЖдDtreamЕФВйзїПЩвдЭЈЙ§RDDЕФtransformationЩњГЩаТЕФDStreamЁЃетРяЕФжДаав§ЧцЪЧSparkЁЃ
2.2.1 ШчКЮЪЙгУSpark Streaming
зїЮЊЙЙНЈгкSparkжЎЩЯЕФгІгУПђМмЃЌSpark StreamingГаЯЎСЫSparkЕФБрГЬЗчИёЃЌЖдгквбОСЫНтSparkЕФгУЛЇРДЫЕФмЙЛПьЫйЕиЩЯЪжЁЃНгЯТРДвдSpark
StreamingЙйЗНЬсЙЉЕФWordCountДњТыЮЊР§РДНщЩмSpark StreamingЕФЪЙгУЗНЪНЁЃ
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
// Create a local StreamingContext with two working
thread and batch interval of 1 second.
// The master requires 2 cores to prevent from a
starvation scenario.
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream that will connect to hostname:port,
like localhost:9999
val lines = ssc.socketTextStream("localhost",
9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
import org.apache.spark.streaming.StreamingContext._
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated
in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation
to terminate
1.ДДНЈStreamingContextЖдЯѓ ЭЌSparkГѕЪМЛЏашвЊДДНЈSparkContextЖдЯѓвЛбљЃЌЪЙгУSpark
StreamingОЭашвЊДДНЈStreamingContextЖдЯѓЁЃДДНЈStreamingContextЖдЯѓЫљашЕФВЮЪ§гыSparkContextЛљБОвЛжТЃЌАќРЈжИУїMasterЃЌЩшЖЈУћГЦ(ШчNetworkWordCount)ЁЃашвЊзЂвтЕФЪЧВЮЪ§Seconds(1)ЃЌSpark
StreamingашвЊжИЖЈДІРэЪ§ОнЕФЪБМфМфИєЃЌШчЩЯР§ЫљЪОЕФ1sЃЌФЧУДSpark StreamingЛсвд1sЮЊЪБМфДАПкНјааЪ§ОнДІРэЁЃДЫВЮЪ§ашвЊИљОнгУЛЇЕФашЧѓКЭМЏШКЕФДІРэФмСІНјааЪЪЕБЕФЩшжУЃЛ
2.ДДНЈInputDStreamШчЭЌStormЕФSpoutЃЌSpark StreamingашвЊжИУїЪ§ОндДЁЃШчЩЯР§ЫљЪОЕФsocketTextStreamЃЌSpark
StreamingвдsocketСЌНгзїЮЊЪ§ОндДЖСШЁЪ§ОнЁЃЕБШЛSpark StreamingжЇГжЖржжВЛЭЌЕФЪ§ОндДЃЌАќРЈKafkaЁЂ
FlumeЁЂHDFS/S3ЁЂKinesisКЭTwitterЕШЪ§ОндДЃЛ
3.ВйзїDStreamЖдгкДгЪ§ОндДЕУЕНЕФDStreamЃЌгУЛЇПЩвддкЦфЛљДЁЩЯНјааИїжжВйзїЃЌШчЩЯР§ЫљЪОЕФВйзїОЭЪЧвЛИіЕфаЭЕФWordCountжДааСїГЬЃКЖдгкЕБЧАЪБМфДАПкФкДгЪ§ОндДЕУЕНЕФЪ§ОнЪзЯШНјааЗжИюЃЌШЛКѓРћгУMapКЭReduceByKeyЗНЗЈНјааМЦЫуЃЌЕБШЛзюКѓЛЙгаЪЙгУprint()ЗНЗЈЪфГіНсЙћЃЛ
4.ЦєЖЏSpark StreamingжЎЧАЫљзїЕФЫљгаВНжшжЛЪЧДДНЈСЫжДааСїГЬЃЌГЬађУЛгаеце§СЌНгЩЯЪ§ОндДЃЌвВУЛгаЖдЪ§ОнНјааШЮКЮВйзїЃЌжЛЪЧЩшЖЈКУСЫЫљгаЕФжДааМЦЛЎЃЌЕБssc.start()ЦєЖЏКѓГЬађВХеце§НјааЫљгадЄЦкЕФВйзїЁЃ
жСДЫЖдгкSpark StreamingЕФШчКЮЪЙгУгаСЫвЛИіДѓИХЕФгЁЯѓЃЌдкКѓУцЕФеТНкЮвУЧЛсЭЈЙ§дДДњТыЩюШыЬНОПвЛЯТSpark
StreamingЕФжДааСїГЬЁЃ
2.2.2 DStreamЕФЪфШыдД
дкSpark StreamingжаЫљгаЕФВйзїЖМЪЧЛљгкСїЕФЃЌЖјЪфШыдДЪЧетвЛЯЕСаВйзїЕФЦ№ЕуЁЃЪфШы DStreams
КЭ DStreams НгЪеЕФСїЖМДњБэЪфШыЪ§ОнСїЕФРДдДЃЌдкSpark Streaming ЬсЙЉСНжжФкжУЪ§ОнСїРДдДЃК
l ЛљДЁРДдД дк StreamingContext API жажБНгПЩгУЕФРДдДЁЃР§ШчЃКЮФМўЯЕЭГЁЂSocketЃЈЬзНгзжЃЉСЌНгКЭ
Akka actorsЃЛ
l ИпМЖРДдД Шч KafkaЁЂFlumeЁЂKinesisЁЂTwitter ЕШЃЌПЩвдЭЈЙ§ЖюЭтЕФЪЕгУЙЄОпРрДДНЈЁЃ
2.2.2.1 ЛљДЁРДдД
дкЧАУцЗжЮідѕбљЪЙгУSpark StreamingЕФР§згжаЮвУЧвбПДЕНssc.socketTextStream()ЗНЗЈЃЌПЩвдЭЈЙ§
TCP ЬзНгзжСЌНгЃЌДгДгЮФБОЪ§ОнжаДДНЈСЫвЛИі DStreamЁЃГ§СЫЬзНгзжЃЌStreamingContext
ЕФAPIЛЙЬсЙЉСЫЗНЗЈДгЮФМўКЭ Akka actors жаДДНЈ DStreamsзїЮЊЪфШыдДЁЃ
Spark StreamingЬсЙЉСЫstreamingContext.fileStream(dataDirectory)ЗНЗЈПЩвдДгШЮКЮЮФМўЯЕЭГ(ШчЃКHDFSЁЂS3ЁЂNFS
ЕШЃЉЕФЮФМўжаЖСШЁЪ§ОнЃЌШЛКѓДДНЈвЛИіDStreamЁЃSpark Streaming МрПи dataDirectory
ФПТМКЭдкИУФПТМЯТШЮКЮЮФМўБЛДДНЈДІРэ(ВЛжЇГждкЧЖЬзФПТМЯТаДЮФМў)ЁЃашвЊзЂвтЕФЪЧЃКЖСШЁЕФБиаыЪЧОпгаЯрЭЌЕФЪ§ОнИёЪНЕФЮФМўЃЛДДНЈЕФЮФМўБиаыдк
dataDirectory ФПТМЯТЃЌВЂЭЈЙ§здЖЏвЦЖЏЛђжиУќУћГЩЪ§ОнФПТМЃЛЮФМўвЛЕЉвЦЖЏОЭВЛФмБЛИФБфЃЌШчЙћЮФМўБЛВЛЖЯзЗМг,аТЕФЪ§ОнНЋВЛЛсБЛдФЖСЁЃЖдгкМђЕЅЕФЮФБОЮФЃЌПЩвдЪЙгУвЛИіМђЕЅЕФЗНЗЈstreamingContext.textFileStream(dataDirectory)РДЖСШЁЪ§ОнЁЃ
Spark StreamingвВПЩвдЛљгкздЖЈвх Actors ЕФСїДДНЈDStream ЃЌЭЈЙ§ Akka
actors НгЪмЪ§ОнСїЃЌЪЙгУЗНЗЈstreamingContext.actorStream(actorProps,
actor-name)ЁЃSpark StreamingЪЙгУ streamingContext.queueStream(queueOfRDDs)ЗНЗЈПЩвдДДНЈЛљгк
RDD ЖгСаЕФDStreamЃЌУПИіRDD ЖгСаНЋБЛЪгЮЊ DStream жавЛПщЪ§ОнСїНјааМгЙЄДІРэЁЃ
2.2.2.2 ИпМЖРДдД
етвЛРрЕФРДдДашвЊЭтВП non-Spark ПтЕФНгПкЃЌЦфжавЛаЉгаИДдгЕФвРРЕЙиЯЕ(Шч KafkaЁЂFlume)ЁЃвђДЫЭЈЙ§етаЉРДдДДДНЈ
DStreams ашвЊУїШЗЦфвРРЕЁЃР§ШчЃЌШчЙћЯыДДНЈвЛИіЪЙгУ Twitter tweets ЕФЪ§ОнЕФDStream
СїЃЌБиаыАДвдЯТВНжшРДзіЃК
1ЃЉдк SBT Лђ MavenЙЄГЬРяЬэМг spark-streaming-twitter_2.10
вРРЕЁЃ
2ЃЉПЊЗЂЃКЕМШы TwitterUtils АќЃЌЭЈЙ§ TwitterUtils.createStream
ЗНЗЈДДНЈвЛИіDStreamЁЃ
3ЃЉВПЪ№ЃКЬэМгЫљгавРРЕЕФ jar Аќ(АќРЈвРРЕЕФspark-streaming-twitter_2.10
МАЦфвРРЕ)ЃЌШЛКѓВПЪ№гІгУГЬађЁЃ
ашвЊзЂвтЕФЪЧЃЌетаЉИпМЖЕФРДдДвЛАудкSpark ShellжаВЛПЩгУЃЌвђДЫЛљгкетаЉИпМЖРДдДЕФгІгУВЛФмдкSpark
ShellжаНјааВтЪдЁЃШчЙћФуБиаыдкSpark shellжаЪЙгУЫќУЧЃЌФуашвЊЯТдиЯргІЕФMavenЙЄГЬЕФJarвРРЕВЂЬэМгЕНРрТЗОЖжаЁЃ
ЦфжавЛаЉИпМЖРДдДШчЯТЃК
lTwitter Spark StreamingЕФTwitterUtilsЙЄОпРрЪЙгУTwitter4jЃЌTwitter4J
ПтжЇГжЭЈЙ§ШЮКЮЗНЗЈЬсЙЉЩэЗнбщжЄаХЯЂЃЌФуПЩвдЕУЕНЙЋжкЕФСїЃЌЛђЕУЕНЛљгкЙиМќДЪЙ§ТЫСїЁЃ
lFlume Spark StreamingПЩвдДгFlumeжаНгЪмЪ§ОнЁЃ
lKafka Spark StreamingПЩвдДгKafkaжаНгЪмЪ§ОнЁЃ
lKinesis Spark StreamingПЩвдДгKinesisжаНгЪмЪ§ОнЁЃ
ашвЊжиЩъЕФвЛЕуЪЧдкПЊЪМБраДздМКЕФ SparkStreaming ГЬађжЎЧАЃЌвЛЖЈвЊНЋИпМЖРДдДвРРЕЕФJarЬэМгЕНSBT
Лђ Maven ЯюФПЯргІЕФartifactжаЁЃГЃМћЕФЪфШыдДКЭЦфЖдгІЕФJarАќШчЯТЭМЫљЪОЁЃ

СэЭтЃЌЪфШыDStreamвВПЩвдДДНЈздЖЈвхЕФЪ§ОндДЃЌашвЊзіЕФОЭЪЧЪЕЯжвЛИігУЛЇЖЈвхЕФНгЪеЦїЁЃ
2.2.3 DStreamЕФВйзї
гыRDDРрЫЦЃЌDStreamвВЬсЙЉСЫздМКЕФвЛЯЕСаВйзїЗНЗЈЃЌетаЉВйзїПЩвдЗжГЩШ§РрЃКЦеЭЈЕФзЊЛЛВйзїЁЂДАПкзЊЛЛВйзїКЭЪфГіВйзїЁЃ
2.2.3.1 ЦеЭЈЕФзЊЛЛВйзї
ЦеЭЈЕФзЊЛЛВйзїШчЯТБэЫљЪОЃК
дкЩЯУцСаГіЕФетаЉВйзїжаЃЌtransform()ЗНЗЈКЭupdateStateByKey()ЗНЗЈжЕЕУЮвУЧЩюШыЕФЬНЬжвЛЯТЃК
l transform(func)Вйзї
ИУtransformВйзїЃЈзЊЛЛВйзїЃЉСЌЭЌЦфЦфРрЫЦЕФ transformWithВйзїдЪаэDStream
ЩЯгІгУШЮвтRDD-to-RDDКЏЪ§ЁЃЫќПЩвдБЛгІгУгкЮДдк DStream API жаБЉТЖШЮКЮЕФRDDВйзїЁЃР§ШчЃЌдкУПХњДЮЕФЪ§ОнСїгыСэвЛЪ§ОнМЏЕФСЌНгЙІФмВЛжБНгБЉТЖдкDStream
API жаЃЌЕЋПЩвдЧсЫЩЕиЪЙгУtransformВйзїРДзіЕНетвЛЕуЃЌетЪЙЕУDStreamЕФЙІФмЗЧГЃЧПДѓЁЃР§ШчЃЌФуПЩвдЭЈЙ§СЌНгдЄЯШМЦЫуЕФРЌЛјгЪМўаХЯЂЕФЪфШыЪ§ОнСїЃЈПЩФмвВгаSparkЩњГЩЕФЃЉЃЌШЛКѓЛљгкДЫзіЪЕЪБЪ§ОнЧхРэЕФЩИбЁЃЌШчЯТУцЙйЗНЬсЙЉЕФЮБДњТыЫљЪОЁЃЪТЪЕЩЯЃЌвВПЩвддкtransformЗНЗЈжаЪЙгУЛњЦїбЇЯАКЭЭМаЮМЦЫуЕФЫуЗЈЁЃ
l updateStateByKeyВйзї
ИУ updateStateByKey ВйзїПЩвдШУФуБЃГжШЮвтзДЬЌЃЌЭЌЪБВЛЖЯгааТЕФаХЯЂНјааИќаТЁЃвЊЪЙгУДЫЙІФмЃЌБиаыНјааСНИіВНжш
ЃК
ЃЈ1ЃЉ ЖЈвхзДЬЌ - зДЬЌПЩвдЪЧШЮвтЕФЪ§ОнРраЭЁЃ
ЃЈ2ЃЉ ЖЈвхзДЬЌИќаТКЏЪ§ - гУвЛИіКЏЪ§жИЖЈШчКЮЪЙгУЯШЧАЕФзДЬЌКЭДгЪфШыСїжаЛёШЁЕФаТжЕ ИќаТзДЬЌЁЃ
ШУЮвУЧгУвЛИіР§згРДЫЕУїЃЌМйЩшФувЊНјааЮФБОЪ§ОнСїжаЕЅДЪМЦЪ§ЁЃдкетРяЃЌе§дкдЫааЕФМЦЪ§ЪЧзДЬЌЖјЧвЫќЪЧвЛИіећЪ§ЁЃЮвУЧЖЈвхСЫИќаТЙІФмШчЯТЃК

ДЫКЏЪ§гІгУгкКЌгаМќжЕЖдЕФDStreamжаЃЈШчЧАУцЕФЪОР§жаЃЌдкDStreamжаКЌгаЃЈwordЃЌ1ЃЉМќжЕЖдЃЉЁЃЫќЛсеыЖдРяУцЕФУПИідЊЫиЃЈШчwordCountжаЕФwordЃЉЕїгУвЛЯТИќаТКЏЪ§ЃЌnewValuesЪЧзюаТЕФжЕЃЌrunningCountЪЧжЎЧАЕФжЕЁЃ

2.2.3.2 ДАПкзЊЛЛВйзї
Spark Streaming ЛЙЬсЙЉСЫДАПкЕФМЦЫуЃЌЫќдЪаэФуЭЈЙ§ЛЌЖЏДАПкЖдЪ§ОнНјаазЊЛЛЃЌДАПкзЊЛЛВйзїШчЯТЃК
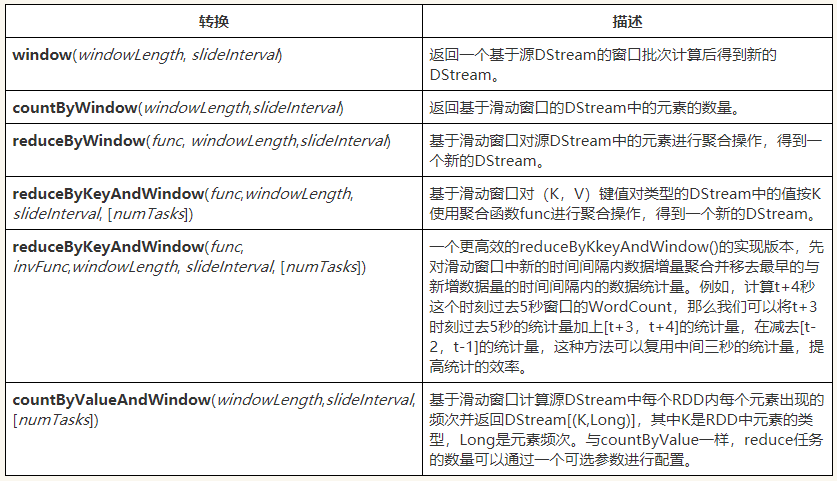
ХњДІРэМфИєЪОвтЭМ
дкSpark StreamingжаЃЌЪ§ОнДІРэЪЧАДХњНјааЕФЃЌЖјЪ§ОнВЩМЏЪЧж№ЬѕНјааЕФЃЌвђДЫдкSpark
StreamingжаЛсЯШЩшжУКУХњДІРэМфИєЃЈbatch durationЃЉЃЌЕБГЌЙ§ХњДІРэМфИєЕФЪБКђОЭЛсАбВЩМЏЕНЕФЪ§ОнЛузмЦ№РДГЩЮЊвЛХњЪ§ОнНЛИјЯЕЭГШЅДІРэЁЃ
ЖдгкДАПкВйзїЖјбдЃЌдкЦфДАПкФкВПЛсгаNИіХњДІРэЪ§ОнЃЌХњДІРэЪ§ОнЕФДѓаЁгЩДАПкМфИєЃЈwindow durationЃЉОіЖЈЃЌЖјДАПкМфИєжИЕФОЭЪЧДАПкЕФГжајЪБМфЃЌдкДАПкВйзїжаЃЌжЛгаДАПкЕФГЄЖШТњзуСЫВХЛсДЅЗЂХњЪ§ОнЕФДІРэЁЃГ§СЫДАПкЕФГЄЖШЃЌДАПкВйзїЛЙгаСэвЛИіживЊЕФВЮЪ§ОЭЪЧЛЌЖЏМфИєЃЈslide
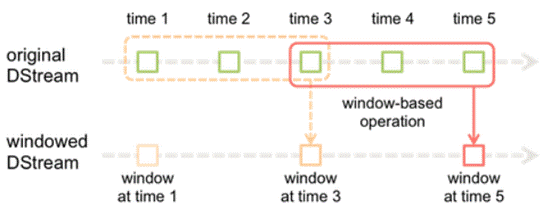
durationЃЉЃЌЫќжИЕФЪЧОЙ§ЖрГЄЪБМфДАПкЛЌЖЏвЛДЮаЮГЩаТЕФДАПкЃЌЛЌЖЏДАПкФЌШЯЧщПіЯТКЭХњДЮМфИєЕФЯрЭЌЃЌЖјДАПкМфИєвЛАуЩшжУЕФвЊБШЫќУЧСНИіДѓЁЃдкетРяБиаызЂвтЕФвЛЕуЪЧЛЌЖЏМфИєКЭДАПкМфИєЕФДѓаЁвЛЖЈЕУЩшжУЮЊХњДІРэМфИєЕФећЪ§БЖЁЃ
ШчХњДІРэМфИєЪОвтЭМЫљЪОЃЌХњДІРэМфИєЪЧ1ИіЪБМфЕЅЮЛЃЌДАПкМфИєЪЧ3ИіЪБМфЕЅЮЛЃЌЛЌЖЏМфИєЪЧ2ИіЪБМфЕЅЮЛЁЃЖдгкГѕЪМЕФДАПкtime
1-time 3ЃЌжЛгаДАПкМфИєТњзуСЫВХДЅЗЂЪ§ОнЕФДІРэЁЃетРяашвЊзЂвтЕФвЛЕуЪЧЃЌГѕЪМЕФДАПкгаПЩФмСїШыЕФЪ§ОнУЛгаГХТњЃЌЕЋЪЧЫцзХЪБМфЕФЭЦНјЃЌДАПкзюжеЛсБЛГХТњЁЃЕБУПИі2ИіЪБМфЕЅЮЛЃЌДАПкЛЌЖЏвЛДЮКѓЃЌЛсгааТЕФЪ§ОнСїШыДАПкЃЌетЪБДАПкЛсвЦШЅзюдчЕФСНИіЪБМфЕЅЮЛЕФЪ§ОнЃЌЖјгызюаТЕФСНИіЪБМфЕЅЮЛЕФЪ§ОнНјааЛузмаЮГЩаТЕФДАПкЃЈtime3-time5ЃЉЁЃ
ЖдгкДАПкВйзїЃЌХњДІРэМфИєЁЂДАПкМфИєКЭЛЌЖЏМфИєЪЧЗЧГЃживЊЕФШ§ИіЪБМфИХФюЃЌЪЧРэНтДАПкВйзїЕФЙиМќЫљдкЁЃ
2.2.3.3 ЪфГіВйзї
Spark StreamingдЪаэDStreamЕФЪ§ОнБЛЪфГіЕНЭтВПЯЕЭГЃЌШчЪ§ОнПтЛђЮФМўЯЕЭГЁЃгЩгкЪфГіВйзїЪЕМЪЩЯЪЙtransformationВйзїКѓЕФЪ§ОнПЩвдЭЈЙ§ЭтВПЯЕЭГБЛЪЙгУЃЌЭЌЪБЪфГіВйзїДЅЗЂЫљгаDStreamЕФtransformationВйзїЕФЪЕМЪжДааЃЈРрЫЦгкRDDВйзїЃЉЁЃвдЯТБэСаГіСЫФПЧАжївЊЕФЪфГіВйзїЃК
dstream.foreachRDDЪЧвЛИіЗЧГЃЧПДѓЕФЪфГіВйзїЃЌЫќдЪНЋаэЪ§ОнЪфГіЕНЭтВПЯЕЭГЁЃЕЋЪЧ ЃЌШчКЮе§ШЗИпаЇЕиЪЙгУетИіВйзїЪЧКмживЊЕФЃЌЯТУцеЙЪОСЫШчКЮШЅБмУтвЛаЉГЃМћЕФДэЮѓЁЃ
ЭЈГЃНЋЪ§ОнаДШыЕНЭтВПЯЕЭГашвЊДДНЈвЛИіСЌНгЖдЯѓЃЈШч TCPСЌНгЕНдЖГЬЗўЮёЦїЃЉЃЌВЂгУЫќРДЗЂЫЭЪ§ОнЕНдЖГЬЯЕЭГЁЃГігкетИіФПЕФЃЌПЊЗЂепПЩФмдкВЛОвтМфдкSpark
driverЖЫДДНЈСЫСЌНгЖдЯѓЃЌВЂГЂЪдЪЙгУЫќБЃДцRDDжаЕФМЧТМЕНSpark workerЩЯЃЌШчЯТУцДњТыЃК
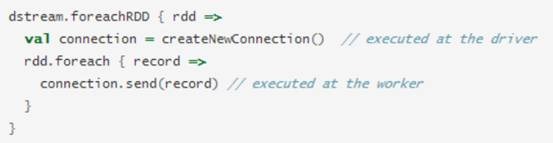
етЪЧВЛе§ШЗЕФЃЌеташвЊСЌНгЖдЯѓНјааађСаЛЏВЂДгDriverЖЫЗЂЫЭЕНWorkerЩЯЁЃСЌНгЖдЯѓКмЩйдкВЛЭЌЛњЦїМфНјааетжжВйзїЃЌДЫДэЮѓПЩФмБэЯжЮЊађСаЛЏДэЮѓЃЈСЌНгЖдВЛПЩађСаЛЏЃЉЃЌГѕЪМЛЏДэЮѓЃЈСЌНгЖдЯѓдкашвЊдкWorker
ЩЯНјааашвЊГѕЪМЛЏЃЉ ЕШЕШЃЌе§ШЗЕФНтОіАьЗЈЪЧдк workerЩЯДДНЈЕФСЌНгЖдЯѓЁЃ
ЭЈГЃЧщПіЯТЃЌДДНЈвЛИіСЌНгЖдЯѓгаЪБМфКЭзЪдДПЊЯњЁЃвђДЫЃЌДДНЈКЭЯњЛйЕФУПЬѕМЧТМЕФСЌНгЖдЯѓПЩФмеажТВЛБивЊЕФзЪдДПЊЯњЃЌВЂЯджјНЕЕЭЯЕЭГећЬхЕФЭЬЭТСП
ЁЃвЛИіИќКУЕФНтОіЗНАИЪЧЪЙгУrdd.foreachPartitionЗНЗЈДДНЈвЛИіЕЅЖРЕФСЌНгЖдЯѓЃЌШЛКѓЪЙгУИУСЌНгЖдЯѓЪфГіЕФЫљгаRDDЗжЧјжаЕФЪ§ОнЕНЭтВПЯЕЭГЁЃ
етЛКНтСЫДДНЈЖрЬѕМЧТМСЌНгЕФПЊЯњЁЃзюКѓЃЌЛЙПЩвдНјвЛВНЭЈЙ§дкЖрИіRDDs/ batchesЩЯжигУСЌНгЖдЯѓНјаагХЛЏЁЃвЛИіБЃГжСЌНгЖдЯѓЕФОВЬЌГиПЩвджигУдкЖрИіХњДІРэЕФRDDЩЯНЋЦфЪфГіЕНЭтВПЯЕЭГЃЌДгЖјНјвЛВННЕЕЭСЫПЊЯњЁЃ
ашвЊзЂвтЕФЪЧЃЌдкОВЬЌГижаЕФСЌНггІИУАДашбгГйДДНЈЃЌетбљПЩвдИќгааЇЕиАбЪ§ОнЗЂЫЭЕНЭтВПЯЕЭГЁЃСэЭташвЊвЊзЂвтЕФЪЧЃКDStreamsбгГйжДааЕФЃЌОЭЯёRDDЕФВйзїЪЧгЩactionsДЅЗЂвЛбљЁЃФЌШЯЧщПіЯТЃЌЪфГіВйзїЛсАДееЫќУЧдкStreamingгІгУГЬађжаЖЈвхЕФЫГађвЛИіИіжДааЁЃ
2.3 ШнДэЁЂГжОУЛЏКЭадФмЕїгХ
2.3.1 ШнДэ
DStreamЛљгкRDDзщГЩЃЌRDDЕФШнДэадвРОЩгааЇЃЌЮвУЧЪзЯШЛивфвЛЯТSparkRDDЕФЛљБОЬиадЁЃ
lRDDЪЧвЛИіВЛПЩБфЕФЁЂШЗЖЈадЕФПЩжиИДМЦЫуЕФЗжВМЪНЪ§ОнМЏЁЃRDDЕФФГаЉpartitionЖЊЪЇСЫЃЌПЩвдЭЈЙ§бЊЭГЃЈlineageЃЉаХЯЂжиаТМЦЫуЛжИДЃЛ
lШчЙћRDDШЮКЮЗжЧјвђworkerНкЕуЙЪеЯЖјЖЊЪЇЃЌФЧУДетИіЗжЧјПЩвдДгдРДвРРЕЕФШнДэЪ§ОнМЏжаЛжИДЃЛ
lгЩгкSparkжаЫљгаЕФЪ§ОнЕФзЊЛЛВйзїЖМЪЧЛљгкRDDЕФЃЌМДЪЙМЏШКГіЯжЙЪеЯЃЌжЛвЊЪфШыЪ§ОнМЏДцдкЃЌЫљгаЕФжаМфНсЙћЖМЪЧПЩвдБЛМЦЫуЕФЁЃ
Spark StreamingЪЧПЩвдДгHDFSКЭS3етбљЕФЮФМўЯЕЭГЖСШЁЪ§ОнЕФЃЌетжжЧщПіЯТЫљгаЕФЪ§ОнЖМПЩвдБЛжиаТМЦЫуЃЌВЛгУЕЃаФЪ§ОнЕФЖЊЪЇЁЃЕЋЪЧдкДѓЖрЪ§ЧщПіЯТЃЌSpark
StreamingЪЧЛљгкЭјТчРДНгЪмЪ§ОнЕФЃЌДЫЪБЮЊСЫЪЕЯжЯрЭЌЕФШнДэДІРэЃЌдкНгЪмЭјТчЕФЪ§ОнЪБЛсдкМЏШКЕФЖрИіWorkerНкЕуМфНјааЪ§ОнЕФИДжЦЃЈФЌШЯЕФИДжЦЪ§ЪЧ2ЃЉЃЌетЕМжТВњЩњдкГіЯжЙЪеЯЪББЛДІРэЕФСНжжРраЭЕФЪ§ОнЃК
1ЃЉData received and replicated ЃКвЛЕЉвЛИіWorkerНкЕуЪЇаЇЃЌЯЕЭГЛсДгСэвЛЗнЛЙДцдкЕФЪ§ОнжажиаТМЦЫуЁЃ
2ЃЉData received but buffered for replication ЃКвЛЕЉЪ§ОнЖЊЪЇЃЌПЩвдЭЈЙ§RDDжЎМфЕФвРРЕЙиЯЕЃЌДгHDFSетбљЕФЭтВПЮФМўЯЕЭГЖСШЁЪ§ОнЁЃ
ДЫЭтЃЌгаСНжжЙЪеЯЃЌЮвУЧгІИУЙиаФЃК
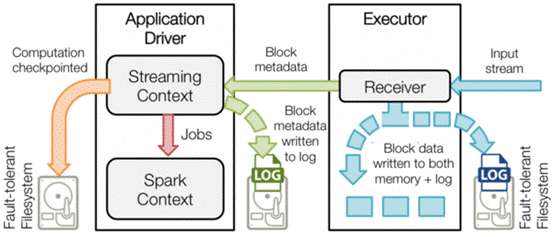
ЃЈ1ЃЉWorkerНкЕуЪЇаЇЃКЭЈЙ§ЩЯУцЕФНВНтЮвУЧжЊЕРЃЌетЪБЯЕЭГЛсИљОнГіЯжЙЪеЯЕФЪ§ОнЕФРраЭЃЌбЁдёЪЧДгСэвЛИігаИДжЦЙ§Ъ§ОнЕФЙЄзїНкЕуЩЯжиаТМЦЫуЃЌЛЙЪЧжБНгДгДгЭтВПЮФМўЯЕЭГЖСШЁЪ§ОнЁЃ
ЃЈ2ЃЉDriverЃЈЧ§ЖЏНкЕуЃЉЪЇаЇ ЃКШчЙћдЫаа Spark StreamingгІгУЪБЧ§ЖЏНкЕуГіЯжЙЪеЯЃЌФЧУДКмУїЯдЕФStreamingContextвбОЖЊЪЇЃЌЭЌЪБдкФкДцжаЕФЪ§ОнШЋВПЖЊЪЇЁЃЖдгкетжжЧщПіЃЌSpark
StreamingгІгУГЬађдкМЦЫуЩЯгавЛИіФкдкЕФНсЙЙЁЊЁЊдкУПЖЮmicro-batchЪ§ОнжмЦкадЕижДааЭЌбљЕФSparkМЦЫуЁЃетжжНсЙЙдЪаэАбгІгУЕФзДЬЌЃЈврГЦcheckpointЃЉжмЦкадЕиБЃДцЕНПЩППЕФДцДЂПеМфжаЃЌВЂдкdriverжиаТЦєЖЏЪБЛжИДИУзДЬЌЁЃОпЬхзіЗЈЪЧдкssc.checkpoint(<checkpoint
directory>)КЏЪ§жаНјааЩшжУЃЌSpark StreamingОЭЛсЖЈЦкАбDStreamЕФдЊаХЯЂаДШыЕНHDFSжаЃЌвЛЕЉЧ§ЖЏНкЕуЪЇаЇЃЌЖЊЪЇЕФStreamingContextЛсЭЈЙ§вбОБЃДцЕФМьВщЕуаХЯЂНјааЛжИДЁЃ
зюКѓЮвУЧЬИвЛЯТSpark StreamЕФШнДэдкSpark 1.2АцБОЕФвЛаЉИФНјЃК
ЪЕЪБСїДІРэЯЕЭГБиаывЊФмдк24/7ЪБМфФкЙЄзїЃЌвђДЫЫќашвЊОпБИДгИїжжЯЕЭГЙЪеЯжаЛжИДЙ§РДЕФФмСІЁЃзюПЊЪМЃЌSparkStreamingОЭжЇГжДгdriverКЭworkerЙЪеЯЛжИДЕФФмСІЁЃШЛЖјгааЉЪ§ОндДЕФЪфШыПЩФмдкЙЪеЯЛжИДвдКѓЖЊЪЇЪ§ОнЁЃдкSpark1.2АцБОжаЃЌSparkвбОдкSparkStreamingжаЖддЄаДШежОЃЈвВБЛГЦЮЊjournalingЃЉзїСЫГѕВНжЇГжЃЌИФНјСЫЛжИДЛњжЦЃЌВЂЪЙИќЖрЪ§ОндДЕФСуЪ§ОнЖЊЪЇгаСЫПЩППЁЃ
ЖдгкЮФМўетбљЕФдДЪ§ОнЃЌdriverЛжИДЛњжЦзувдзіЕНСуЪ§ОнЖЊЪЇЃЌвђЮЊЫљгаЕФЪ§ОнЖМБЃДцдкСЫЯёHDFSЛђS3етбљЕФШнДэЮФМўЯЕЭГжаСЫЁЃЕЋЖдгкЯёKafkaКЭFlumeЕШЦфЫќЪ§ОндДЃЌгааЉНгЪеЕНЕФЪ§ОнЛЙжЛЛКДцдкФкДцжаЃЌЩаЮДБЛДІРэЃЌЫќУЧОЭгаПЩФмЛсЖЊЪЇЁЃетЪЧгЩгкSparkгІгУЕФЗжВМВйзїЗНЪНв§Ц№ЕФЁЃЕБdriverНјГЬЪЇАмЪБЃЌЫљгадкstandalone/yarn/mesosМЏШКдЫааЕФexecutorЃЌСЌЭЌЫќУЧдкФкДцжаЕФЫљгаЪ§ОнЃЌвВЭЌЪББЛжежЙЁЃЖдгкSpark
StreamingРДЫЕЃЌДгжюШчKafkaКЭFlumeЕФЪ§ОндДНгЪеЕНЕФЫљгаЪ§ОнЃЌдкЫќУЧДІРэЭъГЩжЎЧАЃЌвЛжБЖМЛКДцдкexecutorЕФФкДцжаЁЃзнШЛdriverжиаТЦєЖЏЃЌетаЉЛКДцЕФЪ§ОнвВВЛФмБЛЛжИДЁЃЮЊСЫБмУтетжжЪ§ОнЫ№ЪЇЃЌдкSpark1.2ЗЂВМАцБОжав§НјСЫдЄаДШежОЃЈWriteAheadLogsЃЉЙІФмЁЃ
дЄаДШежОЙІФмЕФСїГЬЪЧЃК1ЃЉвЛИіSparkStreamingгІгУПЊЪМЪБЃЈвВОЭЪЧdriverПЊЪМЪБЃЉЃЌЯрЙиЕФStreamingContextЪЙгУSparkContextЦєЖЏНгЪеЦїГЩЮЊГЄзЄдЫааШЮЮёЁЃетаЉНгЪеЦїНгЪеВЂБЃДцСїЪ§ОнЕНSparkФкДцжавдЙЉДІРэЁЃ2ЃЉНгЪеЦїЭЈжЊdriverЁЃ3ЃЉНгЪеПщжаЕФдЊЪ§ОнЃЈmetadataЃЉБЛЗЂЫЭЕНdriverЕФStreamingContextЁЃетИідЊЪ§ОнАќРЈЃКЃЈaЃЉЖЈЮЛЦфдкexecutorФкДцжаЪ§ОнЕФПщreferenceidЃЌЃЈbЃЉПщЪ§ОндкШежОжаЕФЦЋвЦаХЯЂЃЈШчЙћЦєгУСЫЃЉЁЃ
гУЛЇДЋЫЭЪ§ОнЕФЩњУќжмЦкШчЯТЭМЫљЪОЁЃ
РрЫЦKafkaетбљЕФЯЕЭГПЩвдЭЈЙ§ИДжЦЪ§ОнБЃГжПЩППадЁЃдЪаэдЄаДШежОСНДЮИпаЇЕиИДжЦЭЌбљЕФЪ§ОнЃКвЛДЮгЩKafkaЃЌЖјСэвЛДЮгЩSparkStreamingЁЃSparkЮДРДАцБОНЋАќКЌKafkaШнДэЛњжЦЕФдЩњжЇГжЃЌДгЖјБмУтЕкЖўИіШежОЁЃ
2.3.2 ГжОУЛЏ
гыRDDвЛбљЃЌDStreamЭЌбљвВФмЭЈЙ§persist()ЗНЗЈНЋЪ§ОнСїДцЗХдкФкДцжаЃЌФЌШЯЕФГжОУЛЏЗНЪНЪЧMEMORY_ONLY_SERЃЌвВОЭЪЧдкФкДцжаДцЗХЪ§ОнЭЌЪБађСаЛЏЕФЗНЪНЃЌетбљзіЕФКУДІЪЧгіЕНашвЊЖрДЮЕќДњМЦЫуЕФГЬађЪБЃЌЫйЖШгХЪЦЪЎЗжЕФУїЯдЁЃЖјЖдгквЛаЉЛљгкДАПкЕФВйзїЃЌШчreduceByWindowЁЂreduceByKeyAndWindowЃЌвдМАЛљгкзДЬЌЕФВйзїЃЌШчupdateStateBykeyЃЌЦфФЌШЯЕФГжОУЛЏВпТдОЭЪЧБЃДцдкФкДцжаЁЃ
ЖдгкРДздЭјТчЕФЪ§ОндДЃЈKafkaЁЂFlumeЁЂsocketsЕШЃЉЃЌФЌШЯЕФГжОУЛЏВпТдЪЧНЋЪ§ОнБЃДцдкСНЬЈЛњЦїЩЯЃЌетвВЪЧЮЊСЫШнДэадЖјЩшМЦЕФЁЃ
СэЭтЃЌЖдгкДАПкКЭгазДЬЌЕФВйзїБиаыcheckpointЃЌЭЈЙ§StreamingContextЕФcheckpointРДжИЖЈФПТМЃЌЭЈЙ§
DtreamЕФcheckpointжИЖЈМфИєЪБМфЃЌМфИєБиаыЪЧЛЌЖЏМфИєЃЈslide intervalЃЉЕФБЖЪ§ЁЃ
2.3.3 адФмЕїгХ
1. гХЛЏдЫааЪБМф
l діМгВЂааЖШ ШЗБЃЪЙгУећИіМЏШКЕФзЪдДЃЌЖјВЛЪЧАбШЮЮёМЏжадкМИИіЬиЖЈЕФНкЕуЩЯЁЃЖдгкАќКЌshuffleЕФВйзїЃЌдіМгЦфВЂааЖШвдШЗБЃИќЮЊГфЗжЕиЪЙгУМЏШКзЪдДЃЛ
l МѕЩйЪ§ОнађСаЛЏЃЌЗДађСаЛЏЕФИКЕЃ Spark StreamingФЌШЯНЋНгЪмЕНЕФЪ§ОнађСаЛЏКѓДцДЂЃЌвдМѕЩйФкДцЕФЪЙгУЁЃЕЋЪЧађСаЛЏКЭЗДађСаЛАашвЊИќЖрЕФCPUЪБМфЃЌвђДЫИќМгИпаЇЕФађСаЛЏЗНЪНЃЈKryoЃЉКЭздЖЈвхЕФЯЕСаЛЏНгПкПЩвдИќИпаЇЕиЪЙгУCPUЃЛ
l ЩшжУКЯРэЕФbatch durationЃЈХњДІРэЪБМфМфЃЉ дкSpark StreamingжаЃЌJobжЎМфгаПЩФмДцдквРРЕЙиЯЕЃЌКѓУцЕФJobБиаыШЗБЃЧАУцЕФзївЕжДааНсЪјКѓВХФмЬсНЛЁЃШєЧАУцЕФJobжДааЕФЪБМфГЌГіСЫХњДІРэЪБМфМфИєЃЌФЧУДКѓУцЕФJobОЭЮоЗЈАДЪБЬсНЛЃЌетбљОЭЛсНјвЛВНЭЯбгНгЯТРДЕФJobЃЌдьГЩКѓајJobЕФзшШћЁЃвђДЫЩшжУвЛИіКЯРэЕФХњДІРэМфИєвдШЗБЃзївЕФмЙЛдкетИіХњДІРэМфИєФкНсЪјЪББиаыЕФЃЛ
l МѕЩйвђШЮЮёЬсНЛКЭЗжЗЂЫљДјРДЕФИКЕЃ ЭЈГЃЧщПіЯТЃЌAkkaПђМмФмЙЛИпаЇЕиШЗБЃШЮЮёМАЪБЗжЗЂЃЌЕЋЪЧЕБХњДІРэМфИєЗЧГЃаЁЃЈ500msЃЉЪБЃЌЬсНЛКЭЗжЗЂШЮЮёЕФбгГйОЭБфЕУВЛПЩНгЪмСЫЁЃЪЙгУStandaloneКЭCoarse-grained
MesosФЃЪНЭЈГЃЛсБШЪЙгУFine-grained MesosФЃЪНгаИќаЁЕФбгГйЁЃ
2. гХЛЏФкДцЪЙгУ
lПижЦbatch sizeЃЈХњДІРэМфИєФкЕФЪ§ОнСПЃЉ Spark StreamingЛсАбХњДІРэМфИєФкНгЪеЕНЕФЫљгаЪ§ОнДцЗХдкSparkФкВПЕФПЩгУФкДцЧјгђжаЃЌвђДЫБиаыШЗБЃЕБЧАНкЕуSparkЕФПЩгУФкДцжаЩйФмШнФЩетИіХњДІРэЪБМфМфИєФкЕФЫљгаЪ§ОнЃЌЗёдђБиаыдіМгаТЕФзЪдДвдЬсИпМЏШКЕФДІРэФмСІЃЛ
lМАЪБЧхРэВЛдйЪЙгУЕФЪ§Он ЧАУцНВЕНSpark StreamingЛсНЋНгЪмЕФЪ§ОнШЋВПДцДЂЕНФкВППЩгУФкДцЧјгђжаЃЌвђДЫЖдгкДІРэЙ§ЕФВЛдйашвЊЕФЪ§ОнгІМАЪБЧхРэЃЌвдШЗБЃSpark
StreamingгаИЛгрЕФПЩгУФкДцПеМфЁЃЭЈЙ§ЩшжУКЯРэЕФspark.cleaner.ttlЪБГЄРДМАЪБЧхРэГЌЪБЕФЮогУЪ§ОнЃЌетИіВЮЪ§ашвЊаЁаФЩшжУвдУтКѓајВйзїжаЫљашвЊЕФЪ§ОнБЛГЌЪБДэЮѓДІРэЃЛ
lЙлВьМАЪЪЕБЕїећGCВпТд GCЛсгАЯьJobЕФе§ГЃдЫааЃЌПЩФмбгГЄJobЕФжДааЪБМфЃЌв§Ц№вЛЯЕСаВЛПЩдЄСЯЕФЮЪЬтЁЃЙлВьGCЕФдЫааЧщПіЃЌВЩгУВЛЭЌЕФGCВпТдвдНјвЛВНМѕаЁФкДцЛиЪеЖдJobдЫааЕФгАЯьЁЃ |









