| БрМЭЦМі: |
| БОЮФжївЊНВНтСЫHDFSИХЪіЁЂМмЙЙЁЂЙиМќЬиадЁЂХфжУДцДЂЕШФкШнЁЃ
БОЮФзїепъЧГЦВЫФё-ДЋЦцЃЌРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
ЮФМўЯЕЭГЕФЛљБОИХЪі
ЮФМўЯЕЭГЖЈвхЃКЮФМўЯЕЭГЪЧвЛжжДцДЂКЭзщжЏМЦЫуЛњЪ§ОнЕФЗНЗЈЃЌЫќЪЙЕУЖдЦфЗУЮЪКЭВщевБфЕУШнвзЁЃ
ЮФМўУћЃКдкЮФМўЯЕЭГжаЃЌЮФМўУћЪЧгУгкЖЈЮЛДцДЂЮЛжУЁЃ
дЊЪ§ОнЃЈMetadataЃЉЃКБЃДцЮФМўЪєадЕФЪ§ОнЃЌШчЮФМўУћЃЌЮФМўГЄЖШЃЌЮФМўЫљЪєгУЛЇзщЃЌЮФМўДцДЂЮЛжУЕШЁЃ
Ъ§ОнПщЃЈBlockЃЉЃКДцДЂЮФМўЕФзюаЁЕЅдЊЁЃЖдДцДЂНщжЪЛЎЗжСЫЙЬЖЈЕФЧјгђЃЌЪЙгУЪБАДетаЉЧјгђЗжХфЪЙгУЁЃ
HDFSЕФИХЪі
HDFS(Hadoop Distributed File System)ЛљгкGoogleЗЂВМЕФGFSТлЮФЩшМЦПЊЗЂЁЃ
HDFSЪЧHadoopММЪѕПђМмжаЕФЗжВМЪНЮФМўЯЕЭГЃЌЖдВПЪ№дкЖрЬЈЖРСЂЮяРэЛњЦїЩЯЕФЮФМўНјааЙмРэЁЃ
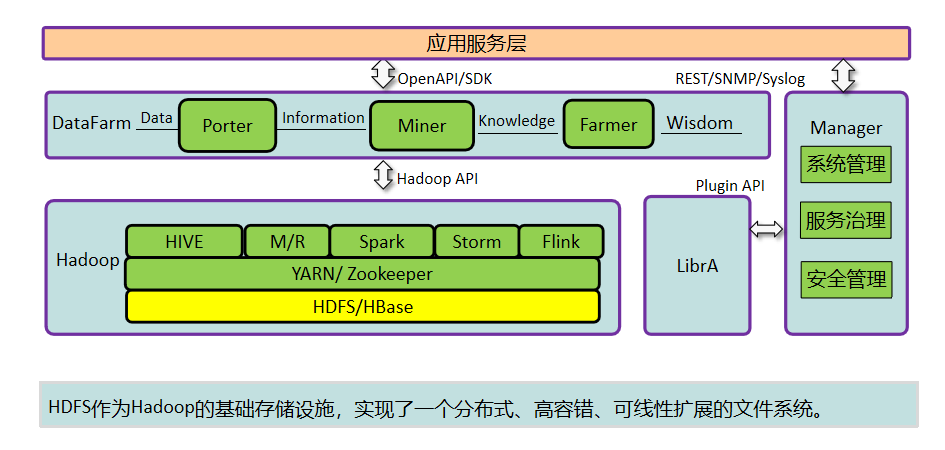
ПЩгУгкЖржжГЁОАЃЌШчЃК ЭјеОгУЛЇааЮЊЪ§ОнДцДЂЁЃ ЩњЬЌЯЕЭГЪ§ОнДцДЂЁЃ ЦјЯѓЪ§ОнДцДЂЁЃ
HDFSЕФгХЕуКЭШБЕу
ЦфГ§ОпБИЦфЫќЗжВМЪНЮФМўЯЕЭГЯрЭЌЬиадЭтЃЌЛЙгаздМКЬигаЕФЬиадЃК
ИпШнДэадЃКШЯЮЊгВМўзмЪЧВЛПЩППЕФЁЃ
ИпЭЬЭТСПЃКЮЊДѓСПЪ§ОнЗУЮЪЕФгІгУЬсЙЉИпЭЬЭТСПжЇГжЁЃ
ДѓЮФМўДцДЂЃКжЇГжДцДЂTB-PBМЖБ№ЕФЪ§ОнЁЃ
ВЛЪЪгУГЁОА
[1] ЕЭЪБМфбгГйЪ§ОнЗУЮЪЕФгІгУЃЌР§ШчМИЪЎКСУыЗЖЮЇЁЃ
двђЃКHDFSЪЧЮЊИпЪ§ОнЭЬЭТСПгІгУгХЛЏЕФЃЌетбљОЭЛсдьГЩвдИпЪБМфбгГйЮЊДњМлЁЃ
[2] ДѓСПаЁЮФМў ЁЃ
двђЃКNameNodeЦєЖЏЪБЃЌНЋЮФМўЯЕЭГЕФдЊЪ§ОнМгдиЕНФкДцЃЌвђДЫЮФМўЯЕЭГЫљФмДцДЂЕФЮФМўзмЪ§ЪмЯогкNameNodeФкДцШнСПЁЃЃЌФЧУДашвЊЕФФкДцПеМфНЋЪЧЗЧГЃДѓЕФЁЃ
[3] ЖргУЛЇаДШыЃЌШЮвтаоИФЮФМўЁЃ
двђЃКЯждкHDFSЮФМўжЛгавЛИіwriterЃЌЖјЧваДВйзїзмЪЧаДдкЮФМўЕФФЉЮВЁЃ
СїЪНЪ§ОнЗУЮЪ
СїЪНЪ§ОнЗУЮЪЃКдкЪ§ОнМЏЩњГЩКѓЃЌГЄЪБМфдкДЫЪ§ОнМЏЩЯНјааИїжжЗжЮіЁЃУПДЮЗжЮіЖМНЋЩцМАИУЪ§ОнМЏЕФДѓВПЗжЪ§ОнЩѕжСШЋВПЪ§ОнЃЌвђДЫЖСШЁећИіЪ§ОнМЏЕФЪБМфбгГйБШЖСШЁЕквЛЬѕМЧТМЕФЪБМфбгГйИќживЊЁЃ
гыСїЪ§ОнЗУЮЪЖдгІЕФЪЧЫцЛњЪ§ОнЗУЮЪЃКЫќвЊЧѓЖЈЮЛЁЂВщбЏЛђаоИФЪ§ОнЕФбгГйНЯаЁЃЌБШНЯЪЪКЯгкДДНЈЪ§ОнКѓдйЖрДЮЖСаДЕФЧщПіЃЌДЋЭГЙиЯЕаЭЪ§ОнПтКмЗћКЯетвЛЕуЁЃ
HDFSЕФМмЙЙ
HDFSМмЙЙАќКЌШ§ИіВПЗжЃКNameNodeЃЌDataNodeЃЌClientЁЃ
NameNodeЃКNameNodeгУгкДцДЂЁЂЩњГЩЮФМўЯЕЭГЕФдЊЪ§ОнЁЃдЫаавЛИіЪЕР§ЁЃ
DataNodeЃКDataNodeгУгкДцДЂЪЕМЪЕФЪ§ОнЃЌНЋздМКЙмРэЕФЪ§ОнПщЩЯБЈИјNameNode ЃЌдЫааЖрИіЪЕР§ЁЃ
ClientЃКжЇГжвЕЮёЗУЮЪHDFSЃЌДгNameNode ,DataNodeЛёШЁЪ§ОнЗЕЛиИјвЕЮёЁЃЖрИіЪЕР§ЃЌКЭвЕЮёвЛЦ№дЫааЁЃ
HDFSЪ§ОнЕФаДШыСїГЬ
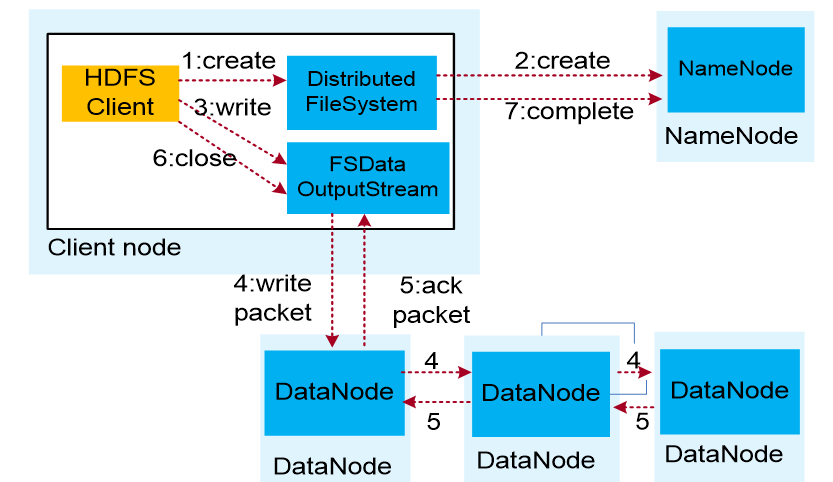
вЕЮёгІгУЕїгУHDFS ClientЬсЙЉЕФAPIЃЌЧыЧѓаДШыЮФМўЁЃ
HDFS ClientСЊЯЕNameNodeЃЌNameNodeдкдЊЪ§ОнжаДДНЈЮФМўНкЕуЁЃ
вЕЮёгІгУЕїгУwrite APIаДШыЮФМўЁЃ
HDFS ClientЪеЕНвЕЮёЪ§ОнКѓЃЌДгNameNodeЛёШЁЕНЪ§ОнПщБрКХЁЂЮЛжУаХЯЂКѓЃЌСЊЯЕDataNodeЃЌВЂНЋашвЊаДШыЪ§ОнЕФDataNodeНЈСЂЦ№СїЫЎЯпЁЃЭъГЩКѓЃЌПЭЛЇЖЫдйЭЈЙ§здгаавщаДШыЪ§ОнЕНDataNode1ЃЌдйгЩDataNode1ИДжЦЕНDataNode2,
DataNode3ЁЃ
аДЭъЕФЪ§ОнЃЌНЋЗЕЛиШЗШЯаХЯЂИјHDFS ClientЁЃ
ЫљгаЪ§ОнШЗШЯЭъГЩКѓЃЌвЕЮёЕїгУHDFS ClientЙиБеЮФМўЁЃ
вЕЮёЕїгУclose, flushКѓHDFSClientСЊЯЕNameNodeЃЌШЗШЯЪ§ОнаДЭъГЩЃЌNameNodeГжОУЛЏдЊЪ§ОнЁЃ
HDFSЪ§ОнЕФЖСШЁСїГЬ
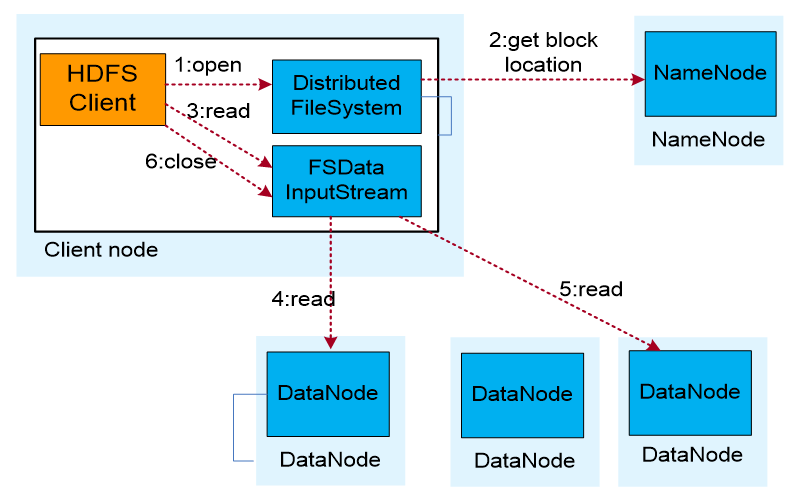
вЕЮёгІгУЕїгУHDFS ClientЬсЙЉЕФAPIДђПЊЮФМўЁЃ
HDFS ClientСЊЯЕNameNodeЃЌЛёШЁЕНЮФМўаХЯЂЃЈЪ§ОнПщЁЂDataNodeЮЛжУаХЯЂЃЉЁЃ
вЕЮёгІгУЕїгУread APIЖСШЁЮФМўЁЃ
HDFS ClientИљОнДгNameNodeЛёШЁЕНЕФаХЯЂЃЌСЊЯЕDataNodeЃЌЛёШЁЯргІЕФЪ§ОнПщЁЃ(ClientВЩгУОЭНќддђЖСШЁЪ§Он)ЁЃ
HDFS ClientЛсгыЖрИіDataNodeЭЈбЖЛёШЁЪ§ОнПщЁЃ
Ъ§ОнЖСШЁЭъГЩКѓЃЌвЕЮёЕїгУcloseЙиБеСЌНгЁЃ
HDFSЕФЙиМќЬиад
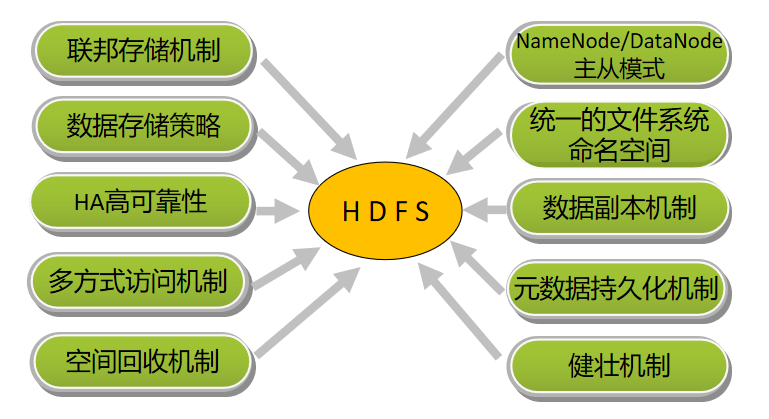
HDFSЕФИпПЩППадЃЈHAЃЉ
HDFSЕФИпПЩППадЃЈHAЃЉжївЊЬхЯждкРћгУzookeeperЪЕЯжжїБИNameNodeЃЌвдНтОіЕЅЕуNameNodeЙЪеЯЮЪЬтЁЃ
ZooKeeperжївЊгУРДДцДЂHAЯТЕФзДЬЌЮФМўЃЌжїБИаХЯЂЁЃZKИіЪ§НЈвщ3ИіМАвдЩЯЧвЮЊЦцЪ§ИіЁЃ
NameNodeжїБИФЃЪНЃЌжїЬсЙЉЗўЮёЃЌБИЭЌВНжїдЊЪ§ОнВЂзїЮЊжїЕФШШБИЁЃ
ZKFC(ZooKeeper Failover Controller)гУгкМрПиNameNodeНкЕуЕФжїБИзДЬЌЁЃ
JN(JournalNode)гУгкДцДЂActive NameNodeЩњГЩЕФEditlogЁЃStandby
NameNodeМгдиJNЩЯEditlogЃЌЭЌВНдЊЪ§ОнЁЃ
ZKFCПижЦNameNodeжїБИжйВУ
ZKFCзїЮЊвЛИіОЋМђЕФжйВУДњРэЃЌЦфРћгУzookeeperЕФЗжВМЪНЫјЙІФмЃЌЪЕЯжжїБИжйВУЃЌдйЭЈЙ§УќСюЭЈЕРЃЌПижЦNameNodeЕФжїБИзДЬЌЁЃZKFCгыNNВПЪ№дквЛЦ№ЃЌСНепИіЪ§ЯрЭЌЁЃ
дЊЪ§ОнЭЌВН
жїNameNodeЖдЭтЬсЙЉЗўЮёЁЃЩњГЩЕФEditlogЭЌЪБаДШыБОЕиКЭJNЃЌЭЌЪБИќаТжїNameNodeФкДцжаЕФдЊЪ§ОнЁЃ
БИNameNodeМрПиЕНJNЩЯEditlogБфЛЏЪБЃЌМгдиEditlogНјФкДцЃЌЩњГЩаТЕФгыжїNameNodeвЛбљЕФдЊЪ§ОнЁЃдЊЪ§ОнЭЌВНЭъГЩЁЃ
жїБИЕФFSImageШдБЃДцдкИїздЕФДХХЬжаЃЌВЛЗЂЩњНЛЛЅЁЃFSImageЪЧФкДцжадЊЪ§ОнЖЈЪБаДЕНБОЕиДХХЬЕФИББОЃЌвВНадЊЪ§ОнОЕЯёЁЃ
дЊЪ§ОнГжОУЛЏ
EditLog:МЧТМгУЛЇЕФВйзїШежОЃЌгУвддкFSImageЕФЛљДЁЩЯЩњГЩаТЕФЮФМўЯЕЭГОЕЯёЁЃ
FSImage:гУвдНзЖЮадБЃДцЮФМўОЕЯёЁЃ
FSImage.ckpt:дкФкДцжаЖдfsimageЮФМўКЭEditLogЮФМўКЯВЂЃЈmergeЃЉКѓВњЩњаТЕФfsimageЃЌаДЕНДХХЬЩЯЃЌетИіЙ§ГЬНаcheckpoint.ЁЃБИгУNameNodeМгдиЭъfsimageКЭEditLogЮФМўКѓЃЌЛсНЋmergeКѓЕФНсЙћЭЌЪБаДЕНБОЕиДХХЬКЭNFSЁЃДЫЪБДХХЬЩЯгавЛЗндЪМЕФfsimageЮФМўКЭвЛЗнаТЩњГЩЕФcheckpointЮФМўЃКfsimage.ckpt.
ЖјКѓНЋfsimage.ckptИФУћЮЊfsimageЃЈИВИЧдгаЕФfsimageЃЉЁЃ
EditLog.new: NameNodeУПИє1аЁЪБЛђEditlogТњ64MBОЭДЅЗЂКЯВЂ,КЯВЂЪБ,НЋЪ§ОнДЋЕНStandby
NameNodeЪБ,вђЪ§ОнЖСаДВЛФмЭЌВННјаа,ДЫЪБNameNodeВњЩњвЛИіаТЕФШежОЮФМўEditlog.newгУРДДцЗХетЖЮЪБМфЕФВйзїШежОЁЃStandby
NameNodeКЯВЂГЩfsimageКѓЛиДЋИјжїNameNodeЬцЛЛЕєдгаfsimage,ВЂНЋEditlog.new
УќУћЮЊEditlogЁЃ
HDFSСЊАюЃЈFederationЃЉ
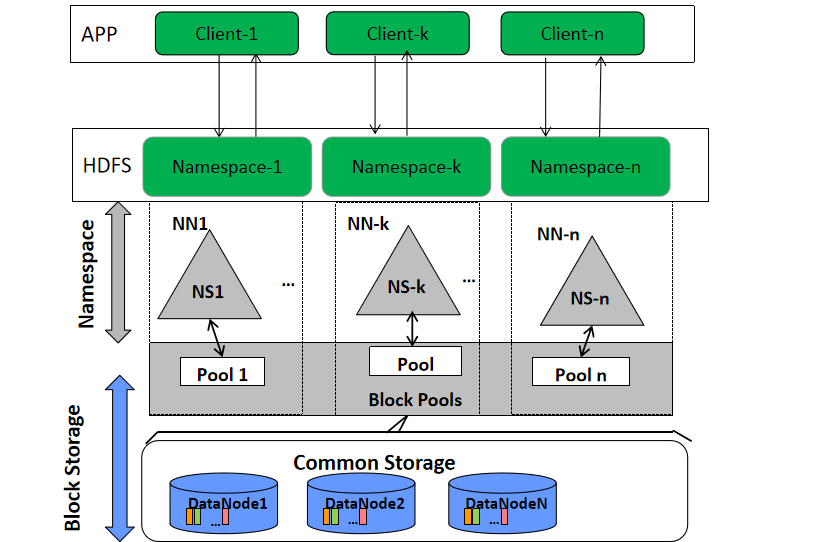
ВњЩњдвђЃКЕЅActive NNЕФМмЙЙЪЙЕУHDFSдкМЏШКРЉеЙадКЭадФмЩЯЖМгаЧБдкЕФЮЪЬтЃЌЕБМЏШКДѓЕНвЛЖЈГЬЖШКѓЃЌNNНјГЬЪЙгУЕФФкДцПЩФмЛсДяЕНЩЯАйGЃЌNNГЩЮЊСЫадФмЕФЦПОБЁЃ
гІгУГЁОАЃКГЌДѓЙцФЃЮФМўДцДЂЁЃШчЛЅСЊЭјЙЋЫОДцДЂгУЛЇааЮЊЪ§ОнЁЂЕчаХРњЪЗЪ§ОнЁЂгявєЪ§ОнЕШГЌДѓЙцФЃЪ§ОнДцДЂЁЃДЫЪБNameNodeЕФФкДцВЛзувджЇГХШчДЫХгДѓЕФМЏШКЁЃГЃгУЕФЙРЫуЙЋЪНЮЊ1GЖдгІ1АйЭђИіПщЃЌАДШБЪЁПщДѓаЁМЦЫуЕФЛАЃЌДѓИХЪЧ128T
(етИіЙРЫуБШР§ЪЧгаБШНЯДѓЕФИЛдЃЕФЃЌЦфЪЕЃЌМДЪЙЪЧУПИіЮФМўжЛгавЛИіПщЃЌЫљгадЊЪ§ОнаХЯЂвВВЛЛсга1KB/block)ЁЃ
FederationМђЕЅРэНтЃКИїNameNodeИКд№здМКЫљЪєЕФФПТМЁЃгыLinuxЙвдиДХХЬЕНФПТМРрЫЦЃЌДЫЪБУПИіNameNodeжЛИКд№ећИіhdfsМЏШКжаВПЗжФПТМЁЃШчNameNode1ИКд№/databaseФПТМЃЌФЧУДдк/databaseФПТМЯТЕФЮФМўдЊЪ§ОнЖМгЩNameNode1ИКд№ЁЃИїNameNodeМфдЊЪ§ОнВЛЙВЯэЃЌУПИіNameNodeЖМгаЖдгІЕФstandbyЁЃ
ПщГиЃЈblock poolЃЉ:ЪєгкФГвЛУќУћПеМф(NS)ЕФвЛзщЮФМўПщЁЃСЊАюЛЗОГЯТЃЌУПИіnamenodeЮЌЛЄвЛИіУќУћПеМфОэЃЈnamespace
volumeЃЉЃЌАќРЈУќУћПеМфЕФдЊЪ§ОнКЭдкИУПеМфЯТЕФЮФМўЕФЫљгаЪ§ОнПщЕФПщГиЁЃ
namenodeжЎМфЪЧЯрЛЅЖРСЂЕФЃЌСНСНжЎМфВЂВЛЛЅЯрЭЈаХЃЌвЛИіЪЇаЇвВВЛЛсгАЯьЦфЫћnamenodeЁЃ
datanodeЯђМЏШКжаЫљгаnamenodeзЂВсЃЌЮЊМЏШКжаЕФЫљгаПщГиДцДЂЪ§ОнЁЃ
NameSpaceЃЈNSЃЉЃКУќУћПеМфЁЃ HDFSЕФУќУћПеМфАќКЌФПТМЁЂЮФМўКЭПщЁЃПЩвдРэНтЮЊNameNodeЫљЪєЕФТпМФПТМЁЃ
Ъ§ОнИББОЛњжЦ
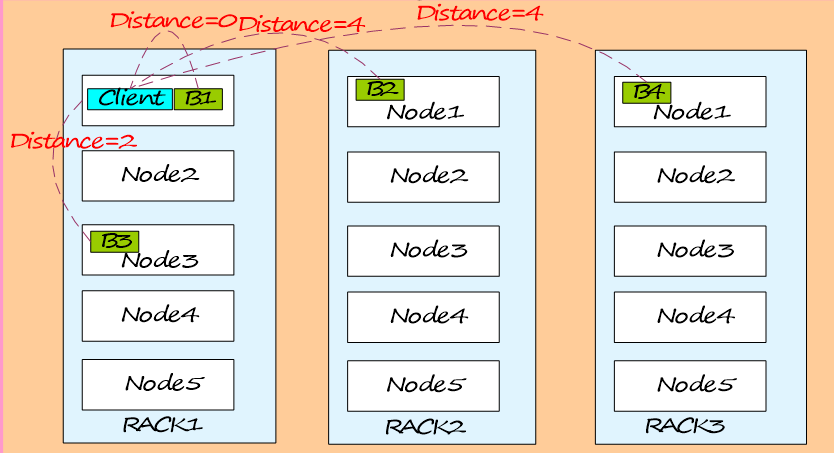
ИББООрРыМЦЫуЙЋЪНЃК
Distance(Rack1/D1, Rack1/D1)=0ЃЌЭЌвЛЬЈЗўЮёЦїЕФОрРыЮЊ0ЁЃ
Distance(Rack1/D1, Rack1/D3)=2ЃЌЭЌвЛЛњМмВЛЭЌЕФЗўЮёЦїОрРыЮЊ2ЁЃ
Distance(Rack1/D1, Rack2/D1)=4ЃЌВЛЭЌЛњМмЕФЗўЮёЦїОрРыЮЊ4ЁЃ
ИББОЗХжУВпТдЃК
ЕквЛИіИББОдкБОНкЕуЁЃ
ЕкЖўИіИББОдкдЖЖЫЛњМмЕФНкЕуЁЃ
ЕкШ§ИіИББОПДжЎЧАЕФСНИіИББОЪЧЗёдкЭЌвЛЛњМмЃЌШчЙћЪЧдђбЁдёЦфЫћЛњМмЃЌЗёдђбЁдёКЭЕквЛИіИББОЯрЭЌЛњМмЕФВЛЭЌНкЕуЃЌЕкЫФИіМАвдЩЯЃЌЫцЛњбЁдёИББОДцЗХЮЛжУЁЃ
ШчЙћаДЧыЧѓЗНЫљдкЛњЦїЪЧЦфжавЛИіDataNode,дђжБНгДцЗХдкБОЕи,ЗёдђЫцЛњдкМЏШКжабЁдёвЛИіDataNodeЁЃ
Rack1ЃКБэЪОЛњМм1ЁЃ
D1ЃКБэЪОDataNodeНкЕу1ЁЃ
B1ЃКБэЪОНкЕуЩЯЕФblockПщ1ЁЃ
ХфжУHDFSЪ§ОнДцДЂВпТд
ФЌШЯЧщПіЯТЃЌHDFS NameNodeздЖЏбЁдёDataNodeБЃДцЪ§ОнЕФИББОЁЃдкЪЕМЪвЕЮёжаЃЌДцдквдЯТГЁОАЃК
DataNodeЩЯДцдкЕФВЛЭЌЕФДцДЂЩшБИЃЌЪ§ОнашвЊбЁдёвЛИіКЯЪЪЕФДцДЂЩшБИЗжМЖДцДЂЪ§ОнЁЃ
DataNodeВЛЭЌФПТМжаЕФЪ§ОнживЊГЬЖШВЛЭЌЃЌЪ§ОнашвЊИљОнФПТМБъЧЉбЁдёвЛИіКЯЪЪЕФDataNodeНкЕуБЃДцЁЃ
DataNodeМЏШКЪЙгУСЫвьЙЙЗўЮёЦїЃЌЙиМќЪ§ОнашвЊБЃДцдкОпгаИпЖШПЩППадЕФНкЕузщжаЁЃ
ХфжУHDFSЪ§ОнДцДЂВпТд--ЗжМЖДцДЂ
ХфжУDataNodeЪЙгУЗжМЖДцДЂ
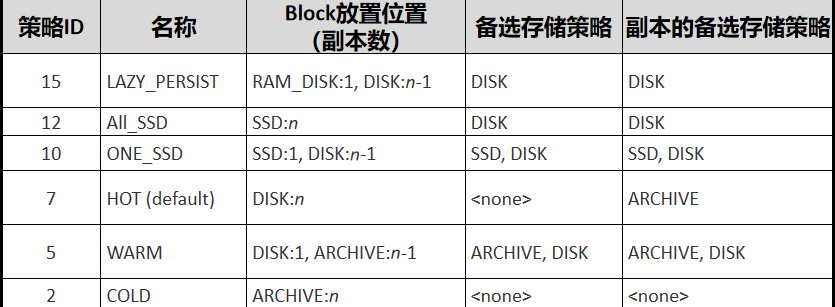
HDFSЕФЗжМЖДцДЂПђМмЬсЙЉСЫRAM_DISKЃЈФкДцХЬЃЉЁЂDISKЃЈЛњаЕгВХЬЃЉЁЂARCHIVEЃЈИпУмЖШЕЭГЩБОДцДЂНщжЪЃЉЁЂSSDЃЈЙЬЬЌгВХЬЃЉЫФжжДцДЂРраЭЕФДцДЂЩшБИЁЃ
ЭЈЙ§ЖдЫФжжДцДЂРраЭНјааКЯРэзщКЯЃЌМДПЩаЮГЩЪЪгУгкВЛЭЌГЁОАЕФДцДЂВпТдЁЃ
ХфжУHDFSЪ§ОнДцДЂВпТд--БъЧЉДцДЂ
ХфжУDataNodeЪЙгУБъЧЉДцДЂЃК
гУЛЇашвЊЭЈЙ§Ъ§ОнЬиеїСщЛюХфжУHDFSЮФМўЪ§ОнПщЕФДцДЂНкЕуЁЃЭЈЙ§ЩшжУHDFSФП ТМ/ЮФМўЖдгІвЛИіБъЧЉБэДяЪНЃЌЭЌЪБЩшжУУПИіDatanodeЖдгІвЛИіЛђЖрИіБъЧЉЃЌДгЖјИјЮФМўЕФЪ§ОнПщДцДЂжИЖЈСЫЬиЖЈЗЖЮЇЕФDatanodeЁЃ
ЕБЪЙгУЛљгкБъЧЉЕФЪ§ОнПщАкЗХВпТдЃЌЮЊжИЖЈЕФЮФМўбЁдёDataNodeНкЕуНјааДцЗХЪБЃЌЛсИљОнЮФМўЕФБъЧЉБэДяЪНбЁдёГіНЋвЊДцЗХЕФDatanodeНкЕуЗЖЮЇЃЌШЛКѓдкетаЉDatanodeНкЕуЗЖЮЇФкЃЌбЁдёГіКЯЪЪЕФДцЗХНкЕуЁЃ
жЇГжгУЛЇНЋЪ§ОнПщЕФИїИіИББОДцЗХдкжИЖЈОпгаВЛЭЌБъЧЉЕФНкЕуЃЌШчФГИіЮФМўЕФЪ§ОнПщЕФ2ИіИББОЗХжУдкБъЧЉL1ЖдгІНкЕужаЃЌИУЪ§ОнПщЕФЦфЫћИББОЗХжУдкБъЧЉL2ЖдгІЕФНкЕужаЁЃ
жЇГжбЁдёНкЕуЪЇАмЧщПіЯТЕФВпТдЃЌШчЫцЛњДгШЋВПНкЕужабЁвЛИіЁЃ
МђЕЅЕФЫЕЃКИјDataNodeЩшжУБъЧЉЃЌБЛДцДЂЕФЪ§ОнвВгаБъЧЉЁЃЕБДцДЂЪ§ОнЪБЃЌЪ§ОнОЭЛсДцДЂЕНБъЧЉЯрЭЌЕФDataNodeжаЁЃ
ХфжУHDFSЪ§ОнДцДЂВпТд--НкЕузщДцДЂ
ХфжУDataNodeЪЙгУНкЕузщДцДЂЃК
ЙиМќЪ§ОнИљОнЪЕМЪвЕЮёашвЊБЃДцдкОпгаИпЖШПЩППадЕФНкЕужаЃЌЭЈЙ§аоИФDataNodeЕФДцДЂВпТдЃЌЯЕЭГПЩвдНЋЪ§ОнЧПжЦБЃДцдкжИЖЈЕФНкЕузщжаЁЃ
ЪЙгУдМЪјЃК
ЕквЛЗнИББОНЋДгЧПжЦЛњМмзщЃЈЛњМмзщ2ЃЉжабЁГіЃЌШчЙћдкЧПжЦЛњМмзщжаУЛгаПЩгУНкЕуЃЌдђаДШыЪЇАмЁЃ
ЕкЖўЗнИББОНЋДгБОЕиПЭЛЇЖЫЛњЦїЛђЛњМмзщжаЕФЫцЛњНкЕужаЃЈЕБПЭЛЇЖЫЛњЦїЛњМмзщВЛЮЊЧПжЦЛњМмзщЪБЃЉбЁГіЁЃ
ЕкШ§ЗнИББОНЋДгЦфЫћЛњМмзщжабЁГіЁЃ
ИїИББОгІДцЗХдкВЛЭЌЕФЛњМмзщжаЁЃШчЙћЫљашИББОЕФЪ§СПДѓгкПЩгУЕФЛњМмзщЪ§СПЃЌдђЛсНЋЖрГіЕФИББОДцЗХдкЫцЛњЛњМмзщжаЁЃ
гЩгкИББОЪ§СПЕФдіМгЛђЪ§ОнПщЪмЫ№ЕМжТдйДЮБИЗнЪБЃЌШчЙћгавЛЗнвдЩЯЕФИББОШБЪЇЛђЮоЗЈДцЗХжСЧПжЦЛњМмзщЃЌНЋВЛЛсНјаадйДЮБИЗнЁЃЯЕЭГНЋЛсМЬајГЂЪдНјаажиаТБИЗнЃЌжБжСЧПжЦзщжагае§ГЃНкЕуЛжИДПЩгУзДЬЌЁЃ
МђЕЅЕФЫЕЃКОЭЪЧЧПжЦФГаЉЙиМќЪ§ОнДцДЂЕНжИЖЈЗўЮёЦїжаЁЃ
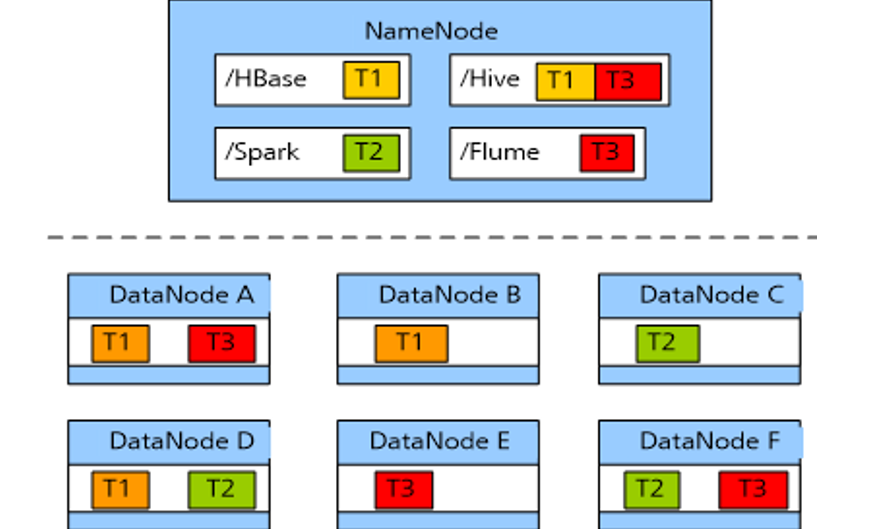
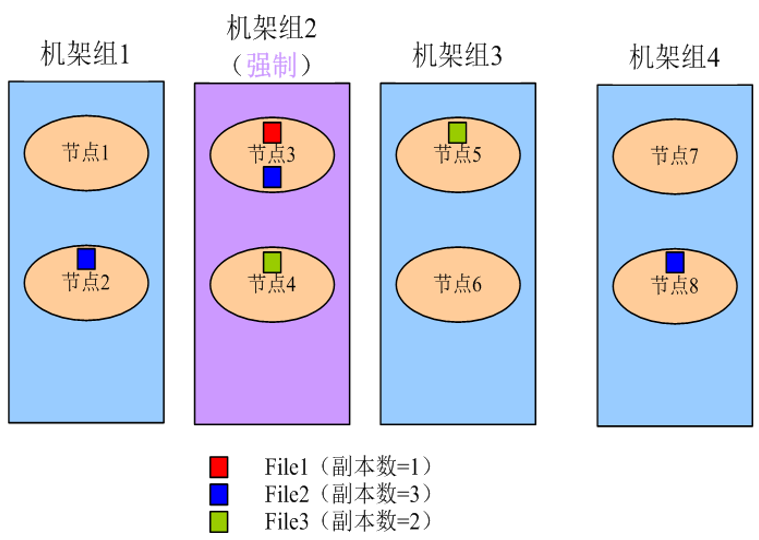
ColocationЭЌЗжВМ
ЭЌЗжВМ(Colocation)ЕФЖЈвхЃКНЋДцдкЙиСЊЙиЯЕЕФЪ§ОнЛђПЩФмвЊНјааЙиСЊВйзїЕФЪ§ОнДцДЂдкЯрЭЌЕФДцДЂНкЕуЩЯЁЃ
АДееЯТЭМДцЗХЃЌМйЩшвЊНЋЮФМўAКЭЮФМўDНјааЙиСЊВйзїЃЌДЫЪБВЛПЩБмУтЕивЊНјааДѓСПЕФЪ§ОнАсЧЈЃЌећИіМЏШКНЋгЩгкЪ§ОнДЋЪфеМОнДѓСПЭјТчДјПэЃЌбЯжигАЯьДѓЪ§ОнЕФДІРэЫйЖШгыЯЕЭГадФмЁЃ
HDFSЮФМўЭЌЗжВМЕФЬиадЃЌНЋФЧаЉашНјааЙиСЊВйзїЕФЮФМўДцЗХдкЯрЭЌЪ§ОнНкЕуЩЯЃЌдкНјааЙиСЊВйзїМЦЫуЪББмУтСЫЕНЦфЫћЕФЪ§ОнНкЕуЩЯЛёШЁЪ§ОнЃЌДѓДѓНЕЕЭЭјТчДјПэЕФеМгУЁЃ
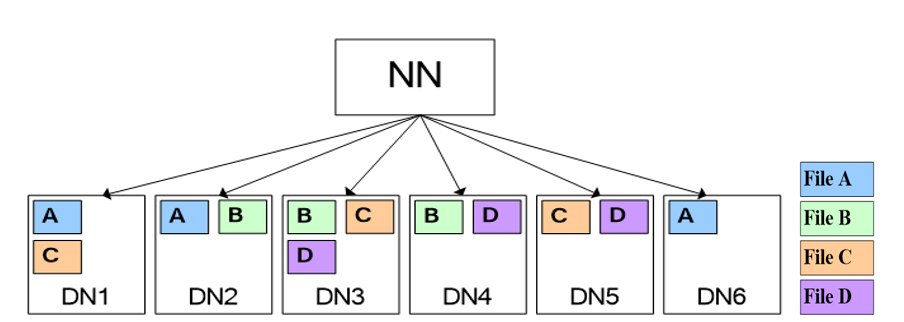
ЪЙгУЭЌЗжВМЬиадЃЌЮФМўAЁЂDНјааjoinЪБЃЌгЩгкЦфЖдгІЕФblockЖМдкЯрЭЌНкЕуЃЌвђДЫДѓДѓНЕЕЭзЪдДЯћКФЁЃ
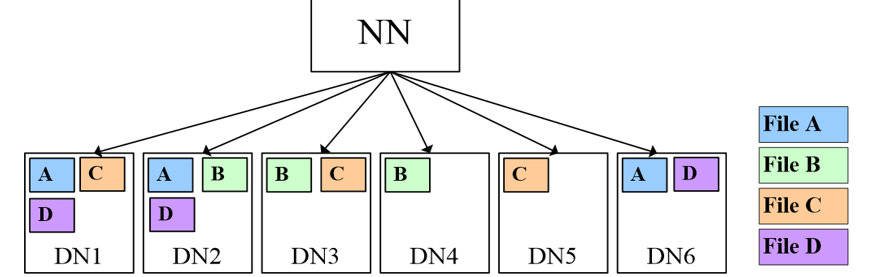
HadoopЪЕЯжЮФМўЭЌЗжВМЃЌМДДцдкЯрЙиСЊЕФЖрИіЮФМўЕФЫљгаПщЖМЗжВМдкЭЌвЛДцДЂНкЕуЩЯЁЃЮФМўМЖЭЌЗжВМЪЕЯжЮФМўЕФПьЫйЗУЮЪЃЌБмУтСЫвђЪ§ОнАсЧЈДјРДЕФДѓСПЭјТчПЊЯњЁЃ
HDFSЪ§ОнЭъећадБЃеЯ
HDFSжївЊФПЕФЪЧБЃжЄДцДЂЪ§ОнЭъећадЃЌЖдгкИїзщМўЕФЪЇаЇЃЌзіСЫПЩППадДІРэЁЃ
жиНЈЪЇаЇЪ§ОнХЬЕФИББОЪ§Он
DataNodeЯђNameNodeжмЦкЩЯБЈЪЇАмЪБЃЌNameNodeЗЂЦ№ИББОжиНЈЖЏзївдЛжИДЖЊЪЇИББОЁЃ
МЏШКЪ§ОнОљКт
HDFSМмЙЙЩшМЦСЫЪ§ОнОљКтЛњжЦЃЌДЫЛњжЦБЃжЄЪ§ОндкИїИіDataNodeЩЯЗжВМЪЧЦНОљЕФЁЃ
дЊЪ§ОнПЩППадБЃжЄ
ВЩгУШежОЛњжЦВйзїдЊЪ§ОнЃЌЭЌЪБдЊЪ§ОнДцЗХдкжїБИNameNodeЩЯЁЃ
ПьееЛњжЦЪЕЯжСЫЮФМўЯЕЭГГЃМћЕФПьееЛњжЦЃЌБЃжЄЪ§ОнЮѓВйзїЪБЃЌФмМАЪБЛжИДЁЃ
АВШЋФЃЪН
HDFSЬсЙЉЖРгаАВШЋФЃЪНЛњжЦЃЌдкЪ§ОнНкЕуЙЪеЯЃЌгВХЬЙЪеЯЪБЃЌФмЗРжЙЙЪеЯРЉЩЂЁЃ
жиНЈЪЇаЇЪ§ОнХЬЕФИББОЪ§Он
DataNodeгыNameNodeжЎМфЭЈЙ§аФЬјжмЦкЛуБЈЪ§ОнзДЬЌЃЌNameNodeЙмРэЪ§ОнПщЪЧЗёЩЯБЈЭъећЃЌШчЙћDataNodeвђгВХЬЫ№ЛЕЮДЩЯБЈЪ§ОнПщЃЌ
NameNodeНЋЗЂЦ№ИББОжиНЈЖЏзївдЛжИДЖЊЪЇЕФИББОЁЃ
АВШЋФЃЪНЗРжЙЙЪеЯРЉЩЂ
ЕБНкЕугВХЬЙЪеЯЪБЃЌНјШыАВШЋФЃЪНЃЌHDFSжЛжЇГжЗУЮЪдЊЪ§ОнЃЌДЫЪБHDFS ЩЯЕФЪ§ОнЪЧжЛЖСЕФЃЌЦфЫћЕФВйзїШчДДНЈЁЂЩОГ§ЮФМўЕШВйзїЖМЛсЕМжТЪЇАмЁЃД§гВХЬЮЪЬтНтОіЁЂЪ§ОнЛжИДКѓЃЌдйЭЫГіАВШЋФЃЪНЁЃ
HDFSМмЙЙЦфЫћЙиМќЩшМЦвЊЕуЫЕУї
ЭГвЛЕФЮФМўЯЕЭГЃК
HDFSЖдЭтНіГЪЯжвЛИіЭГвЛЕФЮФМўЯЕЭГЁЃ
ПеМфЛиЪеЛњжЦЃК
жЇГжЛиЪееОЛњжЦЃЌвдМАИББОЪ§ЕФЖЏЬЌЩшжУЛњжЦЁЃ
Ъ§ОнзщжЏЃК
Ъ§ОнДцДЂвдЪ§ОнПщЮЊЕЅЮЛЃЌДцДЂдкВйзїЯЕЭГЕФHDFSЮФМўЯЕЭГЩЯЁЃ
ЗУЮЪЗНЪНЃК
ЬсЙЉJAVA APIЃЌHTTPЗНЪНЃЌSHELLЗНЪНЗУЮЪHDFSЪ§ОнЁЃ
ДХХЬЪЙгУТЪЃК
БШШчДХХЬ100GЃЌгУСЫ30GЃЌЪЙгУТЪ30%ЁЃ
ИКдиОљКтБмУтСЫНкЕуМфЪ§ОнЗжВМВЛОљдШЃЌЕМжТШШЕуНкЕуЮЪЬтЁЃ
ЫМПМЬт
ЃБHDFSЪЧЪВУДЃЌЪЪКЯгкзіЪВУДЃП
дЫаадкЭЈгУгВМўЩЯЕФЗжВМЪНЮФМўЯЕЭГЁЃЪЪКЯгкДѓЮФМўДцДЂгыЗУЮЪЁЂСїЪНЪ§ОнЗУЮЪЁЃ
ЃВHDFSАќКЌФЧаЉНЧЩЋЃП
NameNodeЁЂDataNodeЁЂClientЁЃ
3 ЧыМђЪіHDFSЕФЖСаДСїЁЃ
ЖСШЁЃКClientСЊЯЕNameNodeЃЌЛёШЁЮФМўаХЯЂЁЃClientИљОнДгNameNodeЛёШЁЕНЕФаХЯЂЃЌСЊЯЕDataNodeЃЌЛёШЁЯргІЕФЪ§ОнПщЃЛЪ§ОнЖСШЁЭъГЩКѓЃЌвЕЮёЕїгУcloseЙиБеСЌНгЁЃ
аДШыЃКClientСЊЯЕNameNodeЃЌNameNodeдкдЊЪ§ОнжаДДНЈЮФМўНкЕуЃЛClientСЊЯЕDataNodeВЂНЈСЂСїЫЎЯпЃЌЭъГЩКѓЃЌПЭЛЇЖЫдйЭЈЙ§здгаавщаДШыЪ§ОнЕН
DataNode1ЃЌдйгЩDataNode1ИДжЦЕНDataNode2,DataNode3ЃЛвЕЮёЕїгУcloseЙи
БеСЌНгЃЛClientСЊЯЕNameNodeЃЌШЗШЯЪ§ОнаДЭъГЩЁЃ
|









