| БрМЭЦМі: |
БОЮФжївЊНВНтСЫHDFSЛљДЁЃЌHDFSМмЙЙЫМТЗНтЮіЁЂHDFSзщГЩМмЙЙЁЂHDFSЪ§ОнаДШыЛњжЦЁЂHDFSЪ§ОнЖСШЁЛњжЦЕШФкШнЁЃ
БОЮФРДздЮЂаХеьВщвЛЯпЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
HadoopАќКЌШ§ДѓЛљБОзщМўЃК
HDFSЁЊЁЊЗжВМЪНЮФМўЯЕЭГЃЌгУгкЪ§ОнДцДЂ
YARNЁЊЁЊЭГвЛзЪдДЙмРэКЭЕїЖШЯЕЭГЃЌгУгкЙмРэМЏШКЕФМЦЫузЪдДВЂИљОнМЦЫуПђМмЕФашЧѓНјааЕїЖШЃЌжЇГжАќКЌMapReduceЁЂSparkЁЂFlinkЕШЖржжМЦЫуПђМмЁЃMRv2(Hadoop
2.x)жЎКѓЕФаТЬиадЁЃ
MapReduceЁЊЁЊЗжВМЪНМЦЫуПђМмЃЌдЫаагкYARNжЎЩЯ

етЦЊЮФеТжївЊЪЧЖдHadoopШ§ДѓЛљБОзщМўжЎвЛЕФHDFSНјааЩюШыЕФбЇЯАЁЃ
вЛЁЂHDFSИХЪі
1.1 HDFSВњЩњБГОА
ЫцзХЪ§ОнСПдНРДдНДѓЃЌдквЛвЛИіВйзїЯЕЭГДцВЛЯТЫљгаЕФЪ§ОнЃЌФЧУДОЭЗжХфЕНИќЖрЕФВйзїЯЕЭГЙмРэЕФДХХЬжаЃЌЕЋЪЧВЛЗНБуЙмРэКЭЮЌЛЄЃЌЦШЧаашвЊвЛжжЯЕЭГРДЙмРэЖрЬЈЛњЦїЩЯЕФЮФМўЃЌетОЭЪЧЗжВМЪНЮФМўЙмРэЯЕЭГЁЃHDFSжЛЪЧЗжВМЪНЮФМўЙмРэЯЕЭГжаЕФвЛжжЁЃ
1.2 HDFSЖЈвх
HDFSЃЈHadoop Distributed File SystemЃЉЃКЪЧHadoopЕФЗжВМЪНЮФМўЯЕЭГЕФЪЕЯжЁЃЫќЕФЩшМЦФПБъЪЧДцДЂКЃСПЕФЪ§ОнЃЌВЂЮЊЗжВМдкЭјТчжаЕФДѓСППЭЛЇЖЫЬсЙЉЪ§ОнЗУЮЪЁЃ
HDFSЪЧИпШнДэадЕФЃЌПЩвдВПЪ№дкЕЭГЩБОЕФгВМўжЎЩЯЃЌHDFSЬсЙЉИпЭЬЭТСПЕиЖдгІгУГЬађЪ§ОнЗУЮЪЁЃ
HDFSЕФЪЙгУГЁОАЃКЪЪКЯвЛДЮаДШыЃЌЖрДЮЖСГіЕФГЁОАЃЌЧвВЛжЇГжЮФМўЕФаоИФЁЃЪЪКЯгУРДзіЪ§ОнЗжЮіЃЌВЂВЛЪЪКЯгУРДзіЭјХЬгІгУЁЃ
1.3 HDFSЬиад
ФмЙЛБЃДцPBМЖЕФЪ§ОнСПЃЌНЋЪ§ОнЩЂВМдкДѓСПЕФМЦЫуЛњЃЈНкЕуЃЉЩЯЃЌжЇГжИќДѓЕФЮФМўЁЃ
ЪЙгУЪ§ОнБИЗнЕФЗНЗЈНтОіЮФМўДцДЂЕФПЩППадЃЌШчЙћМЏШКжаЕЅИіНкЕуЙЪеЯдђЦєгУБИЗнЁЃ
КмКУЕФгыMap-ReduceМЏГЩЃЌЮЊМѕаЁМЦЫуЪБЕФЪ§ОнНЛЛЅЃЌHDFSдЪаэЪ§ОндкБОЕиМЦЫуЁЃ
1.4 HDFSОжЯоад
еыЖдИпЫйСїЪНЖСШЁНјаагХЛЏЃЌВщбЏадФмЕЭЯТЃЈПЩРћгУHiveВщбЏЃЉ
вЛДЮаДШыЖрДЮЖСШЁЃЌВЛжЇГжВЂЗЂаДШыЃЌВЂЗЂЖСШЁадФмКмИп
ВЛжЇГжЮФМўаоИФ
ВЛжЇГжЛКДцЃЌУПДЮЖСШЁЮФМўаыДггВХЬЩЯжиаТЖСШЁЃЌЕБШЛЖдгкДѓЮФМўЫГађЖСШЁадФмгАЯьВЛДѓ
ВЛЪЪКЯДцДЂаЁЮФМў
ЖўЁЂHDFSМмЙЙЫМТЗНтЮі
2.1 HDFSМмЙЙЫМТЗНтЮі1
HDFSЪЧвЛжжЗжВМЪНЮФМўЯЕЭГЃЌНЋЮФМўДцДЂЕНВЛЭЌЕФМЦЫуЛњНкЕужаЁЃШчКЮНЋЮФМўБЃДцЕНВЛЭЌНкЕужаЃП

HDFSЪЧЛљгкКЮжжЫМТЗРДЩшМЦФПЧАЕФМмЙЙЃП
2.2 HDFSМмЙЙЫМТЗНтЮі2
НЋЮФМўБЃДцдкВЛЭЌЕФНкЕу(Node)жаЃК

ЮЪЬтЃК ПЩППадВюЃЌНкЕуЫ№ЛЕЛсЕМжТНкЕуФкЪ§ОнЖЊЪЇЁЃ
НтОіЗНАИЃЌНЋвЛЗнЪ§ОнБИЗнЕНЖрИіНкЕуЁЃ

ВЩгУетжжЗНЗЈДцдквдЯТСНжжгХЕуЃК
1ЁЂПЩППадИпЃЌвЛИіНкЕуЛЕЕєЃЌЦєгУБИЗн
2ЁЂЖСШЁЫйЖШПьЃЌЭЌвЛЗнЪ§ОнЖрИіБИЗнЭЌЪБЖС
ФЧгжДцдкЪВУДОжЯоадФиЃП
ДѓЮФМўБЃДцКЭЖСШЁРЇФбЃЈШчЃКЕЅИі100GЮФМўЃЉЁЃ
2.3 HDFSМмЙЙЫМТЗНтЮі3
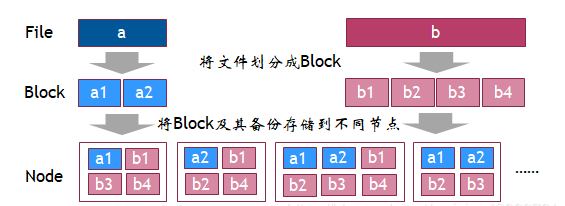
НтОіЗНАИЃК НЋЫљгаЮФМўвдЙЬЖЈДѓаЁЗжИюЮЊПщ(Block)ЃЌНкЕужЛБЃДцЙЬЖЈДѓаЁЕФПщЁЃ
2.4 HDFSМмЙЙЫМТЗНтЮі4
дкЫМТЗНтЮі3жаЛЙДцдкЪ§ОнЖСШЁЕФЮЪЬт
ШчКЮжЊЕРЯЕЭГжагаФФаЉЮФМўЃП
НкЕужажЛДцДЂСЫЮФМўЕФBlockЃЌЮФМўЕФдЪМаХЯЂЖЊЪЇ
ШчКЮжЊЕРФГИідЪМЮФМўЕФBlockЖдгІгкФФаЉНкЕуЃП
ж№ИіНкЕуШЅВщевЃП
ЛЙЪЧНЈСЂвЛИіЙмРэНкЕуЃЌзЈУХРДЙмРэИїИіНкЕуЕФаХЯЂЃП
зюжеНтОіЗНАИЃК
ДцДЂЪ§ОнЪБЃЌНЋЮФМўЕФдЪМаХЯЂЃЌвдМАЖдгІЕФBlockаХЯЂДцДЂЕНЁАЙмРэНкЕуЁБжаБЃДцЁЃ
ЖСШЁЪ§ОнЪБЃЌЯШВщбЏдЪМЮФМўМЧТМКЭЖдгІЕФBlockаХЯЂОЭжЊЕРБОЯЕЭГгаФФаЉдЪМЮФМўЃЌетаЉЮФМўгаФФаЉBlockЃЌвдМАетаЉBlockДцДЂдкФФаЉНкЕужаЁЃ
Ш§ЁЂHDFSзщГЩМмЙЙ
жїДгФЃЪН
ећИіHadoopБЛЙЙНЈдкМЏШКЩЯЃЌМЏШКгЩИїИіНкЕуЃЈNodeЃЉЙЙГЩЁЃ
НЋМЏШКжаЕФНкЕуЗжЮЊNameNodeЃЈЙмРэепЃЉКЭDataNodeЃЈЙЄзїепЃЉЁЃ
ЮФМўБЛВ№ЗжЮЊЖрИіBlockЃЈПщЃЉЗХЕНВЛЭЌЕФDataNodeжаЃЌдкHDFS 1.x жаУПИіПщФЌШЯДѓаЁЮЊ64MBЃЌHDFS
2.x жаУПИіПщФЌШЯДѓаЁЮЊ128MBЃЌЭЌвЛИіПщЛсБИЗнЕНЖрИіDataNodeжаДцДЂЁЃ
3.1 HDFSзщГЩМмЙЙНщЩм
HDFSзщГЩМмЙЙШчЯТЫљЪОЃК
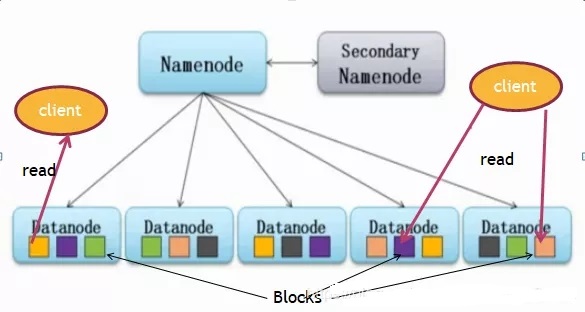
NameNodeЃЈnnЃЉЃКвВОЭЪЧMasterЃЌЫќЪЧвЛИіжїЙмЁЂЙмРэепЁЃЪЙгУNameNodeДцДЂдЊЪ§ОнаХЯЂЃЌБЃДцЮФМўУћвдМАЮФМўЕФПщ(Block)ДцДЂдкФФаЉDataNodeжаЁЃУПИіДцЛюЕФDataNodeЖЈЪБЯђNameNodeЗЂЫЭаФЬјаХЯЂЃЌШчЙћЮДЪеЕНDataNodeЕФаФЬјЃЌNameNodeНЋШЯЖЈЦфвбЪЇаЇЃЌВЛдйЯђЦфХЩЗЂШЮКЮЮФМўЖСЧыЧѓЁЃNameNodeЛсНЋЪЇаЇЕФDataNodeжаЕФПщ(Block)БИЗнЕНЦфЫћДцЛюЕФDataNodeжаЁЃМђЕЅРДЫЕОЭЪЧЃК
ЃЈ1ЃЉЙмРэHDFSЕФУћГЦПеМф;
ЃЈ2ЃЉХфжУИББОВпТд;
ЃЈ3ЃЉЙмРэЪ§ОнПщ(Block) гГЩфаХЯЂ;
ЃЈ4ЃЉДІРэПЭЛЇЖЫЖСаДЧыЧѓЁЃ
DataNodeЃКОЭЪЧSlaveЃЌNameNodeЯТДяУќСюЃЌDataNodeжДааЪЕМЪВйзїЁЃ
ЃЈ1ЃЉДцДЂЪЕМЪЕФЪ§ОнПщ
ЃЈ2ЃЉжДааЪ§ОнПщЕФЖС/аДВйзї
ClientЃКОЭЪЧПЭЛЇЖЫЁЃ
ЃЈ1ЃЉЮФМўЧаЗжЁЃЮФМўЩЯДЋHDFSЕФЪБКђЃЌ ClientНЋЮФМўЧаЗжГЩвЛ ИіИіЕФBlockЃЌ ШЛКѓНјааЩЯДЋ
ЃЈ2ЃЉгыNameNodeНЛЛЅЃЌЛёШЁЮФМўЕФЮЛжУаХЯЂ
ЃЈ3ЃЉгыDataNodeНЛЛЅЃЌЖСШЁЛђепаДШыЪ§Он
ЃЈ4ЃЉClientЬсЙЉвЛ аЉУќ СюРДЙмРэHDFS,БШШчNameNodeИёЪНЛЏ
ЃЈ5ЃЉClientПЩвдЭЈЙ§вЛаЉУќСюРДЗУЮЪHDFS,БШШчЖдHDFSдіЩОВщИФВйзї
Secondany NameNodeЃКВЂЗЧNameNodeЕФШШБИЁЃЕБNameNodeЙвЕєЕФЪБКђЃЌ
ЫќВЂВЛФмТэЩЯЬцЛЛNameNodeВЂЬсЙЉЗўЮёЁЃ
ЃЈ1ЃЉИЈжњNameNode,ЗжЕЃЦфЙЄзїСПЃЌБШШчЖЈЦкЬЈВЂfsimageКЭedits,ВЂЭЦЫЭИјNameNode
;
ЃЈ2ЃЉдкНєМБЧщПіЯТЃЌПЩИЈжњЛжИДNameNodeЁЃ
3.2 NamenodeЕФдЊЪ§ОнЙмРэЛњжЦ
ећИіЯЕЭГЕФдЊЪ§ОнЖМБЃДцдкNameNodeжа
ФкДцдЊЪ§ОнЃКmeta dataЃЌгУгкдЊЪ§ОнВщбЏ
гВХЬдЊЪ§ОнОЕЯёЮФМўЃКfsimageЃЌГжОУЛЏДцДЂдЊЪ§Он
Ъ§ОнВйзїШежОЃКeditsЃЌHDFSЮФМўдіЩОЛсдьГЩдЊЪ§ОнИќИФЃЌНЋИќИФМЧТМЕНeditsЃЌПЩдЫЫуГідЊЪ§Он
NameNodeдЊЪ§ОнЙмРэЙ§ГЬ
ЯЕЭГЦєЖЏЪБЃЌЖСШЁfsimageКЭeditsжСФкДцЃЌаЮГЩФкДцдЊЪ§Онmeta dataЁЃ
clientЯђNameNodeЗЂЦ№Ъ§ОндіЩОВщЧыЧѓ
NameNodeНгЪеЕНЧыЧѓКѓЃЌдкФкДцдЊЪ§ОнжажДаадіЩОВщВйзїЃЌВЂЯђclientЗЕЛиВйзїНсЙћЁЃ
ШчЙћЪЧдіЩОВйзїЃЌдђЭЌЪБМЧТМЪ§ОнВйзїШежОeditsЁЃ
ЪЙгУSecondary NameNodeЃЌдкЪЪЕБЕФЪБЛњНЋВйзїШежОКЯВЂЕНfsimageжаЃЈCheckPointЙ§ГЬЃЉ
3.3 Ш§ИіЮЪЬт
ЮЊЪВУДПщЕФДѓаЁВЛФмЩшжУЬЋаЁЃЌвВВЛФмЩшжУЬЋДѓ?
HDFSЕФПщЩшжУЬЋаЁЃЌЛсдіМгбАжЗЪБМфЃЌГЬађвЛжБдкевПщЕФПЊЪМЮЛжУ;
ШчЙћПщЩшжУЕФЬЋДѓЃЌДгДХХЬДЋЪфЪ§ОнЕФЪБМфЛсУїЯдДѓгкЖЈЮЛетИіПщПЊЪМЮЛжУЫљашЕФЪБМфЁЃЕМжТГЬађдкДІРэетПщЪ§ОнЪБЃЌЛсЗЧГЃТ§ЁЃ
змНс: HDFSПщЕФДѓаЁЩшжУжївЊШЁОігкДХХЬДЋЪфЫйТЪЁЃ
ЮЊЪВУДЮФМўВйзїВЛжБНгаДШыfsimageЃЌЖјвЊаДШыЕЅЖРЕФeditsЮФМўЃП
fsimageМЧТМСЫећИіДѓЪ§ОнЯЕЭГЕФдЊЪ§ОнЃЌЗЧГЃХгДѓ
fsimageЪЧвЛИіСїЪНЕФЮФБОЮФМўЃЌаТдіМЧТМжЛашдкЮФМўФЉЮВаТдіЪ§ОнЃЌЫйЖШПьЃЛЩОГ§МЧТМЪБЃЌашвЊЩОГ§ЮФМўжаМфЕФФГаЉМЧТМЃЌЮФМўдНДѓжДаааЇТЪдНЕЭ
editsЮФМўвЛАуКмаЁЃЌЭЈГЃГЌЙ§64mbОЭЛсБЛжДааКЯВЂЃЌХњСПКЯВЂЕФВйзїаЇТЪБШЦЕЗБаоИФИпЖрСЫ
ЮЊЪВУДвЊЪЙгУSecondary NameNodeКЯВЂВйзїШежОЃП
ЬсИпадФмЃКNameNodeЪЧЮЈвЛУцЯђClientЕФЙмРэНкЕуЃЌГаЪмClientЕФВЂЗЂЗУЮЪЃЌадФмЗЧГЃживЊЃЌЖјКЯВЂeditsКЭfsimageашвЊНЯДѓМЦЫуСП
ЬсИпПЩППадЃКSecondary NameNodeдкКЯВЂedits КЭfsimageЪБЃЌЛсзіЪ§ОнБИЗнЃЌШчЙћNameNodeжаЕФfsimageЖЊЪЇЃЌПЩДгSecondary
NameNodeЛжИД
3.4 CheckpointЙ§ГЬ
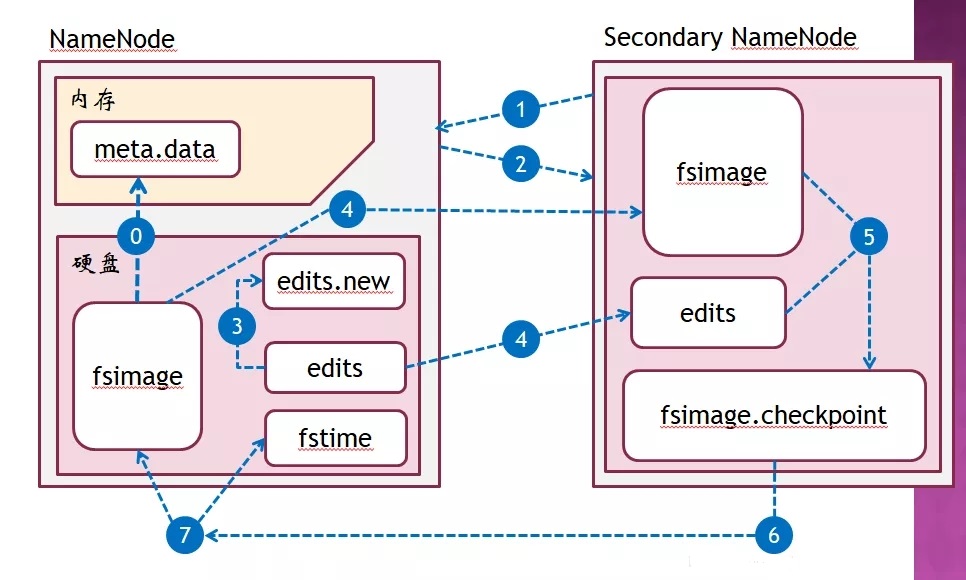
SN(Secondary NameNode)ЯђNameNode(NN)ЗЂЦ№бЏЮЪЃЌЪЧЗёашвЊcheckpoint
NNЖСШЁfstimeжаЕФЩЯДЮcheckpointЪБМфЃЌНсКЯeditsЮФМўДѓаЁЕШвђЫиЃЌОіЖЈПЊЪМcheckpoint
NNаТНЈвЛИіeditsЮФМў(ШчЃКedits.new)ЃЌШУаТВйзїаДШыЕНedits.newжа(БмУтдкcheckpointЙ§ГЬжаЃЌeditsЗЂЩњИФБф)
SNЯђNNЧыЧѓ(httpавщ)ЛёШЁfsimageКЭeditsЮФМў
SNНЋeditsгыfsimageКЯВЂЃЌЩњГЩаТЕФfsimage.checkpointЮФМў
SNНЋfsimage.checkpointЗЂЫЭИјNN
NNЪеЕНfsimage.checkpointКѓЃЌНЋЦфгыОЩЕФfsimageЬцЛЛЃЌИќаТfstimeЮФМўМЧТМБОДЮcheckpointВйзї
3.5 NameNodeЕЅЕуЙЪеЯЛжИД
NameNodeЕЅЕуЙЪеЯЛсЕМжТећИіHadoopБРРЃ
РћгУSN(Secondary NameNode)ЕФБИЗнЛжИДNN (NameNode)дЊЪ§Он
SNгыNNВЂВЛЪЧЪБПЬЭЌВНЕФЃЌcheckpointгаЪБМфМфИєЃЌетЛсЕМжТЛжИДКѓгаЪ§ОнЖЊЪЇ
NFSЗНАИ(NFSджБИ)ЃЌЖдNNжадЊЪ§ОнНјааМДЪББИЗнЃЌБмУтдЊЪ§ОнЖЊЪЇ
NSF(Network File SystemЃЌЭјТчЮФМўЯЕЭГ)ПЩгыЭјТчжаЕФжїЛњЯрЛЅДЋЪфЮФМў
NNПЩХфжУNFSджБИЗўЮёЦїЃЌдкаДШыfsimageЁЂfstimeЁЂeditsЁЂedits.newЕШЮФМўЪБЃЌЭЌВНаДШыЕНNSFЗўЮёЦїжаЃЌНјЖјБмУтNNЪ§ОнЖЊЪЇ
HDFSИпПЩгУад
дЪаэХфжУСНИіЯрЭЌЕФNameNodeвЛИіЮЊactive modeДІгкЛюЖЏФЃЪНЃЌСэвЛИіЮЊstandby
modeДІгкД§ЛњФЃЪН
СНИіNameNodeЪ§ОнБЃГжвЛжТЃЌвЛЕЉЛюЖЏНкЕуЪЇаЇЃЌдђгЩД§ЛњНкЕуЧаЛЛЮЊЛюЖЏНкЕуЃЌБЃжЄHadoopЕФе§ГЃдЫаа
СНИіNameNodeЕФЙВЯэЭЌвЛИіNFSвдНјааЪ§ОнЭЌВН
ЫФЁЂHDFSЪ§ОнаДШыЛњжЦ

0ЃКNameNodeашвЊЭЈЙ§аФЬјЛњжЦЪеМЏDataNodeЕФЩњДцзДЬЌКЭДцДЂзДЬЌЃЛгУвддкЕк3ВНЪБЃЌЗжХфзюМбЕФblockДцДЂЮЛжУЁЃ
гУЛЇПЭЛЇЖЫЧыЧѓHadoopПЭЛЇЖЫЃЌВЂжДааЮФМўЩЯДЋ
ЩЯДЋЕФЮФМўаДШыЕНHadoopПЭЛЇЖЫЕФСйЪБФПТМжаЃЌУПЕБаДШыЕФЪ§ОнСПдНЙ§Пщ(block)БпНчЪБ(hadoop
1.xШБЪЁ64mbЃЌhadoop2.xШБЪЁ128mb)ЃЌЧыЧѓNameNodeЩъЧыЪ§ОнПщ
NameNodeЯђHadoopПЭЛЇЖЫЗЕЛиblockЕФЮЛжУ
HadoopПЭЛЇЖЫжБНгНЋblockаДШыжИЖЈЕФDataNode
ЮхЁЂHDFSЪ§ОнЖСШЁЛњжЦ

0ЃКNameNodeашвЊЭЈЙ§аФЬјЛњжЦЪеМЏDataNodeЕФЩњДцзДЬЌЃЛдкЕк3ВНЪБЃЌВЛЛсНЋЪЇаЇЕФDataNodeЮЛжУЗЕЛиИјПЭЛЇЖЫ
гУЛЇПЭЛЇЖЫЧыЧѓHadoopПЭЛЇЖЫЃЌЧыЧѓЗЕЛижИЖЈЮФМў
HadoopПЭЛЇЖЫЯђNameNodeЗЂЦ№ЖСЮФМўЧыЧѓ
NameNodeВщбЏmeta dataВЂЗЕЛиЮФМўЖдгІЕФblockЮЛжУ
HadoopПЭЛЇЖЫжБНгЯђDataNodeЧыЧѓblockЪ§ОнЃЌЛёШЁЕНЫљгаblockКѓКЯВЂГЩЮФМў
СљЁЂЩцМАИХФюЃЈзмНсЃЉ
Block
ЫљгаЕФЮФМўНЋБЛВ№ЗжЮЊШєИЩblock(ШБЪЁУПИіblockДѓаЁЮЊ64mb)ЃЌвдДцЗХдкВЛЭЌЕФDataNodeжа(УПИіblockНЋга3ИіБИЗнБЃДцЕНВЛЭЌDataNode)
DataNode
гУгкДцДЂblockЃЌ blockвдЮФМўЕФаЮЪНЫцЛњДцДЂдкМЏШКЕФИїИіDataNodeЩЯ
DataNodeВЛжЊЕРЪ§ОнЕФФкШнЃЌЬсШЁЪ§ОнЪБЮоЗЈжЊЕРУПИіBlockИУФФИіDataNodeЩЯЬсШЁЃЌгкЪЧашвЊМЧТМУПИіBlockДцДЂдкКЮДІЃЈNameNodeЩЯЕФдЊЪ§ОнЃЉЁЃ
NameNode
МЧТМЮФМўЕФдЊЪ§ОнЃЌNameNodeжЊЕРЫљгаЕФЮФМўЖдгІФФаЉBlockвдМАетаЉBlockЖМДцЗХдкКЮДІ
гыИїИіDataNodeЭЈаХВЂЙмРэDataNode
дЊЪ§ОнЃЈ Metadata ЃЉ
УшЪіЪ§ОнЕФЪ§ОнЃЈdata about dataЃЉ
АќКЌСЫЃКУПИіЮФМўЕФЮФМўУћЁЂЮФМўЮЛжУЁЂЗУЮЪШЈЯоКЭИїИіПщЕФУћГЦКЭЮЛжУ
ДѓСПаЁЮФМўЛсЩњГЩЙ§ЖрдЊЪ§ОнМЧТМЃЌНЕЕЭNameNodeВщбЏаЇТЪ(аЁЮФМўЖЈвхЃКдЖдЖаЁгкblockБпНчДѓаЁЕФЮФМў)ЁЃ
Р§ЃК64MbЕФЮФМўЗжХф1ИіblockЃЌеМгУ1ЬѕдЊЪ§ОнМЧТМЃЛЖјЭЌбљДѓаЁЕФ1024Иі64KbЕФЮФМўЃЌаыЗжХф1024ИіblockЃЌеМгУ1024ЬѕдЊЪ§ОнМЧТМ
аФЬј
NameNodeМЧТМСЫЫљгаЕФDataNodeЃЌЕЋШчЙћDataNodeЭЛШЛЪЇаЇЃЌNameNodeашвЊбИЫйЕФжЊЕРЃЛгкЪЧашвЊУПИіDataNodeЖЈЦкЃЈФЌШЯУП3УыЃЉЯђNameNodeЗЂЫЭаФЬјаХЯЂ
ПЭЛЇЖЫ(Client)
ДњБэгУЛЇЭЈЙ§гыNameNodeКЭDataNodeНЛЛЅРДЗУЮЪећИіЮФМўЯЕЭГ.
|









