| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫspark
ЩњЬЌМАдЫаадРэЁЂsparkдЫааМмЙЙЁЂSparkКЫаФИХФюжЎRDDЁЂSparkКЫаФИХФюжЎJobs
/ StageЁЂSpark StreamingдЫаадРэЁЂSpark зЪдДЕїгХЕШФкШн
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЕМгя
spark вбОГЩЮЊЙуИцЁЂБЈБэвдМАЭЦМіЯЕЭГЕШДѓЪ§ОнМЦЫуГЁОАжаЪзбЁЯЕЭГЃЌвђаЇТЪИпЃЌвзгУвдМАЭЈгУаддНРДдНЕУЕНДѓМвЕФЧрэљЃЌЮвздМКзюНќАыФъдкНгДЅsparkвдМАspark
streamingжЎКѓЃЌЖдsparkММЪѕЕФЪЙгУгавЛаЉздМКЕФОбщЛ§РлвдМАаФЕУЬхЛсЃЌдкДЫЗжЯэИјДѓМвЁЃ
БОЮФвРДЮДгsparkЩњЬЌЃЌдРэЃЌЛљБОИХФюЃЌspark streamingдРэМАЪЕМљЃЌЛЙгаsparkЕїгХвдМАЛЗОГДюНЈЕШЗНУцНјааНщЩмЃЌЯЃЭћЖдДѓМвгаЫљАяжњЁЃ
spark ЩњЬЌМАдЫаадРэ
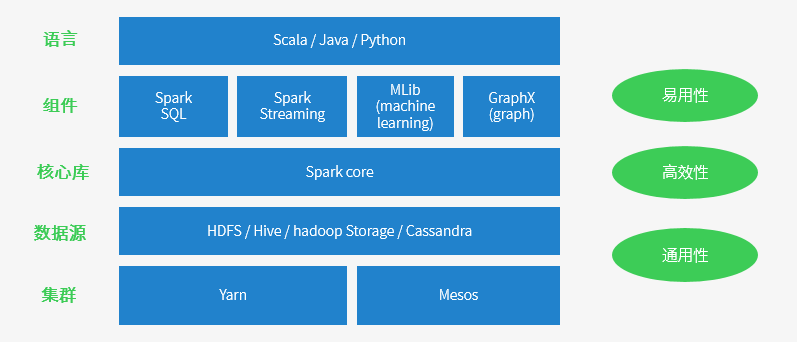
Spark ЬиЕу
дЫааЫйЖШПь SparkгЕгаDAGжДаав§ЧцЃЌжЇГждкФкДцжаЖдЪ§ОнНјааЕќДњМЦЫуЁЃЙйЗНЬсЙЉЕФЪ§ОнБэУїЃЌШчЙћЪ§ОнгЩДХХЬЖСШЁЃЌЫйЖШЪЧHadoop
MapReduceЕФ10БЖвдЩЯЃЌШчЙћЪ§ОнДгФкДцжаЖСШЁЃЌЫйЖШПЩвдИпДя100ЖрБЖЁЃ
ЪЪгУГЁОАЙуЗК ДѓЪ§ОнЗжЮіЭГМЦЃЌЪЕЪБЪ§ОнДІРэЃЌЭММЦЫуМАЛњЦїбЇЯА
взгУад БраДМђЕЅЃЌжЇГж80жжвдЩЯЕФИпМЖЫузгЃЌжЇГжЖржжгябдЃЌЪ§ОндДЗсИЛЃЌПЩВПЪ№дкЖржжМЏШКжа
ШнДэадИпЁЃSparkв§НјСЫЕЏадЗжВМЪНЪ§ОнМЏRDD (Resilient Distributed Dataset)
ЕФГщЯѓЃЌЫќЪЧЗжВМдквЛзщНкЕужаЕФжЛЖСЖдЯѓМЏКЯЃЌетаЉМЏКЯЪЧЕЏадЕФЃЌШчЙћЪ§ОнМЏвЛВПЗжЖЊЪЇЃЌдђПЩвдИљОнЁАбЊЭГЁБЃЈМДГфаэЛљгкЪ§ОнбмЩњЙ§ГЬЃЉЖдЫќУЧНјаажиНЈЁЃСэЭтдкRDDМЦЫуЪБПЩвдЭЈЙ§CheckPointРДЪЕЯжШнДэЃЌЖјCheckPointгаСНжжЗНЪНЃКCheckPoint
DataЃЌКЭLogging The UpdatesЃЌгУЛЇПЩвдПижЦВЩгУФФжжЗНЪНРДЪЕЯжШнДэЁЃ
SparkЕФЪЪгУГЁОА
ФПЧАДѓЪ§ОнДІРэГЁОАгавдЯТМИИіРраЭЃК
ИДдгЕФХњСПДІРэЃЈBatch Data ProcessingЃЉЃЌЦЋжиЕудкгкДІРэКЃСПЪ§ОнЕФФмСІЃЌжСгкДІРэЫйЖШПЩШЬЪмЃЌЭЈГЃЕФЪБМфПЩФмЪЧдкЪ§ЪЎЗжжгЕНЪ§аЁЪБЃЛ
ЛљгкРњЪЗЪ§ОнЕФНЛЛЅЪНВщбЏЃЈInteractive QueryЃЉЃЌЭЈГЃЕФЪБМфдкЪ§ЪЎУыЕНЪ§ЪЎЗжжгжЎМф
ЛљгкЪЕЪБЪ§ОнСїЕФЪ§ОнДІРэЃЈStreaming Data ProcessingЃЉЃЌЭЈГЃдкЪ§АйКСУыЕНЪ§УыжЎМф
SparkГЩЙІАИР§
ФПЧАДѓЪ§ОндкЛЅСЊЭјЙЋЫОжївЊгІгУдкЙуИцЁЂБЈБэЁЂЭЦМіЯЕЭГЕШвЕЮёЩЯЁЃдкЙуИцвЕЮёЗНУцашвЊДѓЪ§ОнзігІгУЗжЮіЁЂаЇЙћЗжЮіЁЂЖЈЯђгХЛЏЕШЃЌдкЭЦМіЯЕЭГЗНУцдђашвЊДѓЪ§ОнгХЛЏЯрЙиХХУћЁЂИіадЛЏЭЦМівдМАШШЕуЕуЛїЗжЮіЕШЁЃетаЉгІгУГЁОАЕФЦеБщЬиЕуЪЧМЦЫуСПДѓЁЂаЇТЪвЊЧѓИпЁЃ
ЬкбЖ / yahoo / ЬдБІ / гХПсЭСЖЙ
sparkдЫааМмЙЙ
sparkЛљДЁдЫааМмЙЙШчЯТЫљЪОЃК
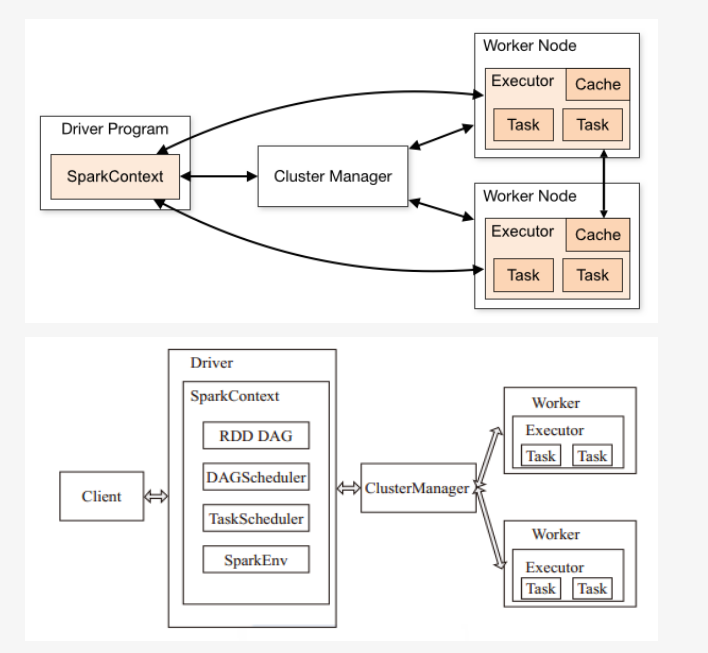
sparkНсКЯyarnМЏШКБГКѓЕФдЫааСїГЬШчЯТЫљЪОЃК
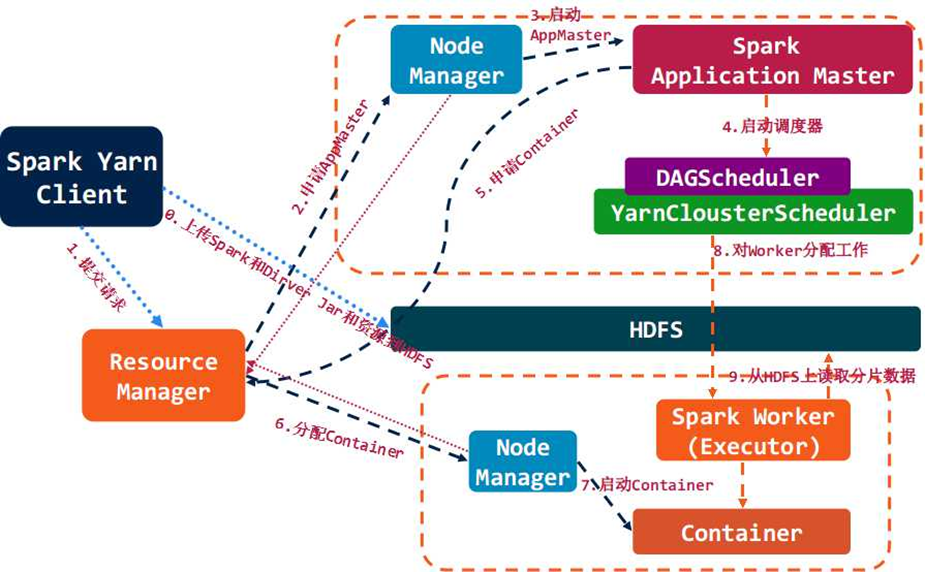
spark дЫааСїГЬЃК
SparkМмЙЙВЩгУСЫЗжВМЪНМЦЫужаЕФMaster-SlaveФЃаЭЁЃMasterЪЧЖдгІМЏШКжаЕФКЌгаMasterНјГЬЕФНкЕуЃЌSlaveЪЧМЏШКжаКЌгаWorkerНјГЬЕФНкЕуЁЃ
MasterзїЮЊећИіМЏШКЕФПижЦЦїЃЌИКд№ећИіМЏШКЕФе§ГЃдЫааЃЛ
WorkerЯрЕБгкМЦЫуНкЕуЃЌНгЪежїНкЕуУќСюгыНјаазДЬЌЛуБЈЃЛ
ExecutorИКд№ШЮЮёЕФжДааЃЛ
ClientзїЮЊгУЛЇЕФПЭЛЇЖЫИКд№ЬсНЛгІгУЃЛ
DriverИКд№ПижЦвЛИігІгУЕФжДааЁЃ
SparkМЏШКВПЪ№КѓЃЌашвЊдкжїНкЕуКЭДгНкЕуЗжБ№ЦєЖЏMasterНјГЬКЭWorkerНјГЬЃЌЖдећИіМЏШКНјааПижЦЁЃдквЛИіSparkгІгУЕФжДааЙ§ГЬжаЃЌDriverКЭWorkerЪЧСНИіживЊНЧЩЋЁЃDriver
ГЬађЪЧгІгУТпМжДааЕФЦ№ЕуЃЌИКд№зївЕЕФЕїЖШЃЌМДTaskШЮЮёЕФЗжЗЂЃЌЖјЖрИіWorkerгУРДЙмРэМЦЫуНкЕуКЭДДНЈExecutorВЂааДІРэШЮЮёЁЃдкжДааНзЖЮЃЌDriverЛсНЋTaskКЭTaskЫљвРРЕЕФfileКЭjarађСаЛЏКѓДЋЕнИјЖдгІЕФWorkerЛњЦїЃЌЭЌЪБExecutorЖдЯргІЪ§ОнЗжЧјЕФШЮЮёНјааДІРэЁЃ
Excecutor /Task УПИіГЬађздгаЃЌВЛЭЌГЬађЛЅЯрИєРыЃЌtaskЖрЯпГЬВЂаа
МЏШКЖдSparkЭИУїЃЌSparkжЛвЊФмЛёШЁЯрЙиНкЕуКЭНјГЬ
Driver гыExecutorБЃГжЭЈаХЃЌазїДІРэ
Ш§жжМЏШКФЃЪНЃК
1.Standalone ЖРСЂМЏШК
2.Mesos, apache mesos
3.Yarn, hadoop yarn
ЛљБОИХФюЃК
Application ⇨SparkЕФгІгУГЬађЃЌАќКЌвЛИіDriver
programКЭШєИЩExecutor
SparkContext⇨ SparkгІгУГЬађЕФШыПкЃЌИКд№ЕїЖШИїИідЫЫузЪдДЃЌаЕїИїИіWorker
NodeЩЯЕФExecutor
Driver Program ⇨дЫааApplicationЕФmain()КЏЪ§ВЂЧвДДНЈSparkContext
Executor ⇨ЪЧЮЊApplicationдЫаадкWorker
nodeЩЯЕФвЛИіНјГЬЃЌИУНјГЬИКд№дЫааTaskЃЌВЂЧвИКд№НЋЪ§ОнДцдкФкДцЛђепДХХЬЩЯЁЃУПИіApplicationЖМЛсЩъЧыИїздЕФExecutorРДДІРэШЮЮё
Cluster Manager ⇨дкМЏШКЩЯЛёШЁзЪдДЕФЭтВПЗўЮё
(Р§ШчЃКStandaloneЁЂMesosЁЂYarn)
Worker Node⇨ МЏШКжаШЮКЮПЩвддЫааApplicationДњТыЕФНкЕуЃЌдЫаавЛИіЛђЖрИіExecutorНјГЬ
Task ⇨дЫаадкExecutorЩЯЕФЙЄзїЕЅдЊ
Job ⇨SparkContextЬсНЛЕФОпЬхActionВйзїЃЌГЃКЭActionЖдгІ
Stage ⇨УПИіJobЛсБЛВ№ЗжКмЖрзщtaskЃЌУПзщШЮЮёБЛГЦЮЊStageЃЌвВГЦTaskSet
RDD ⇨ЪЧResilient distributed
datasetsЕФМђГЦЃЌжаЮФЮЊЕЏадЗжВМЪНЪ§ОнМЏ;ЪЧSparkзюКЫаФЕФФЃПщКЭРр
DAGScheduler ⇨ИљОнJobЙЙНЈЛљгкStageЕФDAGЃЌВЂЬсНЛStageИјTaskScheduler
TaskScheduler ⇨НЋTasksetЬсНЛИјWorker
nodeМЏШКдЫааВЂЗЕЛиНсЙћ
Transformations ⇨ЪЧSpark APIЕФвЛжжРраЭЃЌTransformationЗЕЛижЕЛЙЪЧвЛИіRDDЃЌЫљгаЕФTransformationВЩгУЕФЖМЪЧРСВпТдЃЌШчЙћжЛЪЧНЋTransformationЬсНЛЪЧВЛЛсжДааМЦЫуЕФ
Action ⇨ЪЧSpark APIЕФвЛжжРраЭЃЌActionЗЕЛижЕВЛЪЧвЛИіRDDЃЌЖјЪЧвЛИіscalaМЏКЯЃЛМЦЫужЛгадкActionБЛЬсНЛЕФЪБКђМЦЫуВХБЛДЅЗЂЁЃ
SparkКЫаФИХФюжЎRDD
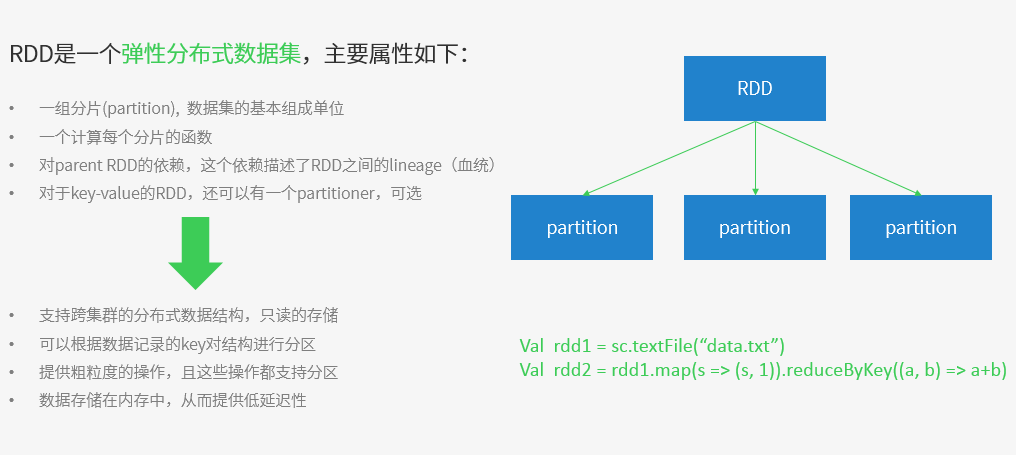
SparkКЫаФИХФюжЎTransformations / Actions
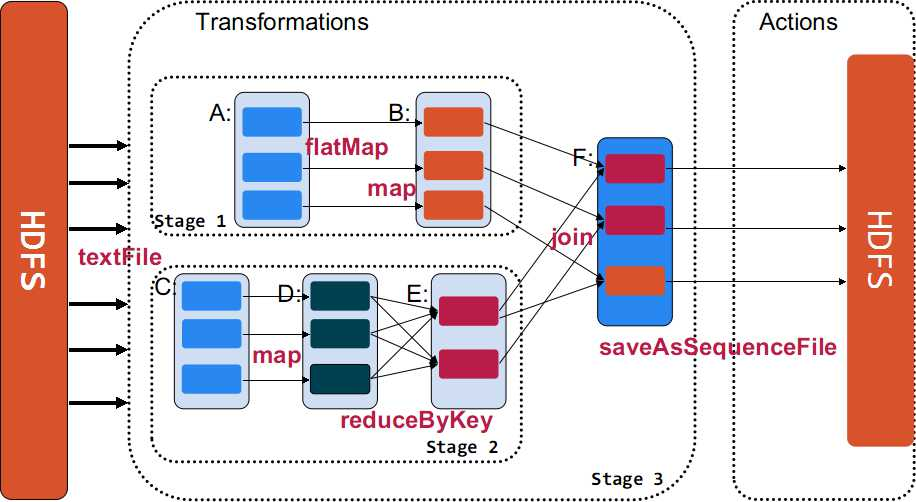
TransformationЗЕЛижЕЛЙЪЧвЛИіRDDЁЃЫќЪЙгУСЫСДЪНЕїгУЕФЩшМЦФЃЪНЃЌЖдвЛИіRDDНјааМЦЫуКѓЃЌБфЛЛГЩСэЭтвЛИіRDDЃЌШЛКѓетИіRDDгжПЩвдНјааСэЭтвЛДЮзЊЛЛЁЃетИіЙ§ГЬЪЧЗжВМЪНЕФЁЃ
ActionЗЕЛижЕВЛЪЧвЛИіRDDЁЃЫќвЊУДЪЧвЛИіScalaЕФЦеЭЈМЏКЯЃЌвЊУДЪЧвЛИіжЕЃЌвЊУДЪЧПеЃЌзюжеЛђЗЕЛиЕНDriverГЬађЃЌЛђАбRDDаДШыЕНЮФМўЯЕЭГжаЁЃ
ActionЪЧЗЕЛижЕЗЕЛиИјdriverЛђепДцДЂЕНЮФМўЃЌЪЧRDDЕНresultЕФБфЛЛЃЌTransformationЪЧRDDЕНRDDЕФБфЛЛЁЃ
жЛгаactionжДааЪБЃЌrddВХЛсБЛМЦЫуЩњГЩЃЌетЪЧrddРСЖшжДааЕФИљБОЫљдкЁЃ
SparkКЫаФИХФюжЎJobs / Stage
Job ⇨АќКЌЖрИіtaskЕФВЂааМЦЫуЃЌвЛИіactionДЅЗЂвЛИіjob
stage ⇨вЛИіjobЛсБЛВ№ЮЊЖрзщtaskЃЌУПзщШЮЮёГЦЮЊвЛИіstageЃЌвдshuffleНјааЛЎЗж
SparkКЫаФИХФюжЎShuffle
вдreduceByKeyЮЊР§НтЪЭshuffleЙ§ГЬЁЃ
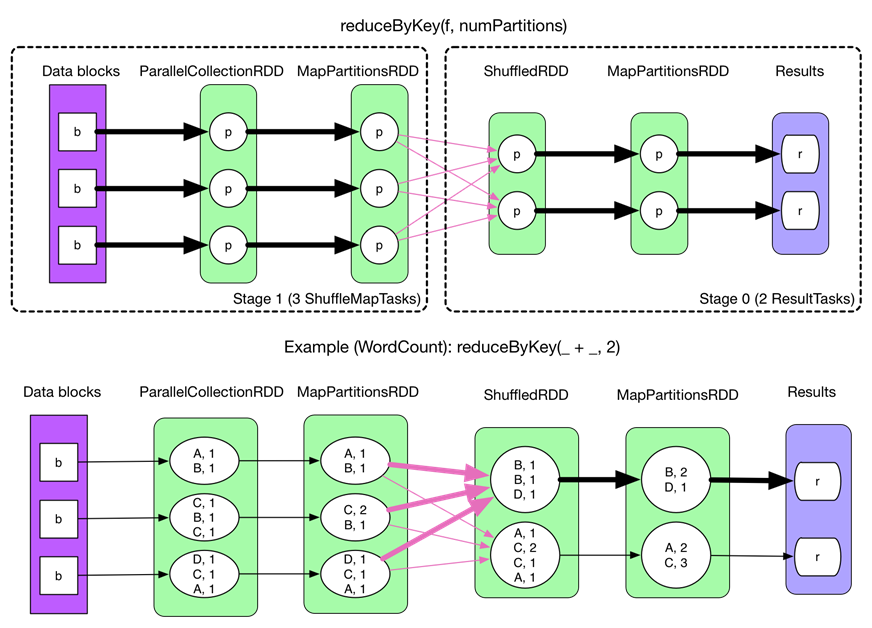
дкУЛгаtaskЕФЮФМўЗжЦЌКЯВЂЯТЕФshuffleЙ§ГЬШчЯТЃКЃЈspark.shuffle.consolidateFiles=falseЃЉ
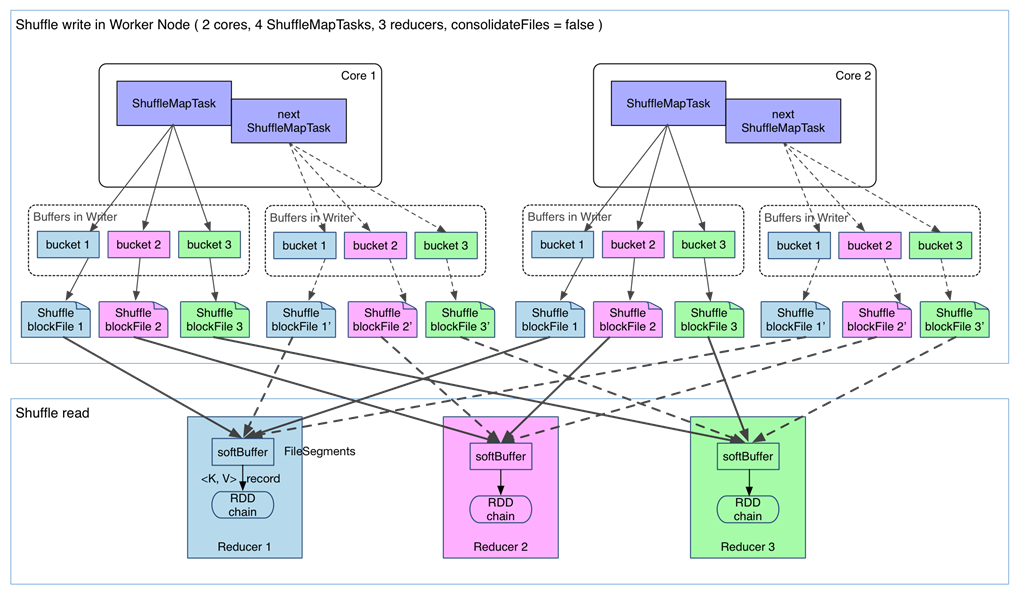
fetch РДЕФЪ§ОнДцЗХЕНФФРяЃП
Ие fetch РДЕФ FileSegment ДцЗХдк softBuffer ЛКГхЧјЃЌОЙ§ДІРэКѓЕФЪ§ОнЗХдкФкДц
+ ДХХЬЩЯЁЃетРяЮвУЧжївЊЬжТлДІРэКѓЕФЪ§ОнЃЌПЩвдСщЛюЩшжУетаЉЪ§ОнЪЧЁАжЛгУФкДцЁБЛЙЪЧЁАФкДцЃЋДХХЬЁБЁЃШчЙћspark.shuffle.spill
= falseОЭжЛгУФкДцЁЃгЩгкВЛвЊЧѓЪ§ОнгаађЃЌshuffle write ЕФШЮЮёКмМђЕЅЃКНЋЪ§Он partition
КУЃЌВЂГжОУЛЏЁЃжЎЫљвдвЊГжОУЛЏЃЌвЛЗНУцЪЧвЊМѕЩйФкДцДцДЂПеМфбЙСІЃЌСэвЛЗНУцвВЪЧЮЊСЫ fault-toleranceЁЃ
shuffleжЎЫљвдашвЊАбжаМфНсЙћЗХЕНДХХЬЮФМўжаЃЌЪЧвђЮЊЫфШЛЩЯвЛХњtaskНсЪјСЫЃЌЯТвЛХњtaskЛЙашвЊЪЙгУФкДцЁЃШчЙћШЋВПЗХдкФкДцжаЃЌФкДцЛсВЛЙЛЁЃСэЭтвЛЗНУцЮЊСЫШнДэЃЌЗРжЙШЮЮёЙвЕєЁЃ
ДцдкЮЪЬтШчЯТЃК
ВњЩњЕФ FileSegment Й§ЖрЁЃУПИі ShuffleMapTask ВњЩњ RЃЈreducer
ИіЪ§ЃЉИі FileSegmentЃЌM Иі ShuffleMapTask ОЭЛсВњЩњ M * R ИіЮФМўЁЃвЛАу
Spark job ЕФ M КЭ R ЖМКмДѓЃЌвђДЫДХХЬЩЯЛсДцдкДѓСПЕФЪ§ОнЮФМўЁЃ
ЛКГхЧјеМгУФкДцПеМфДѓЁЃУПИі ShuffleMapTask ашвЊПЊ R Иі bucketЃЌM Иі ShuffleMapTask
ОЭЛсВњЩњ MR Иі bucketЁЃЫфШЛвЛИі ShuffleMapTask НсЪјКѓЃЌЖдгІЕФЛКГхЧјПЩвдБЛЛиЪеЃЌЕЋвЛИі
worker node ЩЯЭЌЪБДцдкЕФ bucket ИіЪ§ПЩвдДяЕН cores R ИіЃЈвЛАу worker
ЭЌЪБПЩвддЫаа cores Иі ShuffleMapTaskЃЉЃЌеМгУЕФФкДцПеМфвВОЭДяЕНСЫcoresЁС
R ЁС 32 KBЁЃЖдгк 8 КЫ 1000 Иі reducer РДЫЕЃЌеМгУФкДцОЭЪЧ 256MBЁЃ
ЮЊСЫНтОіЩЯЪіЮЪЬтЃЌЮвУЧПЩвдЪЙгУЮФМўКЯВЂЕФЙІФмЁЃ
дкНјааtaskЕФЮФМўЗжЦЌКЯВЂЯТЕФshuffleЙ§ГЬШчЯТЃКЃЈspark.shuffle.consolidateFiles=trueЃЉ
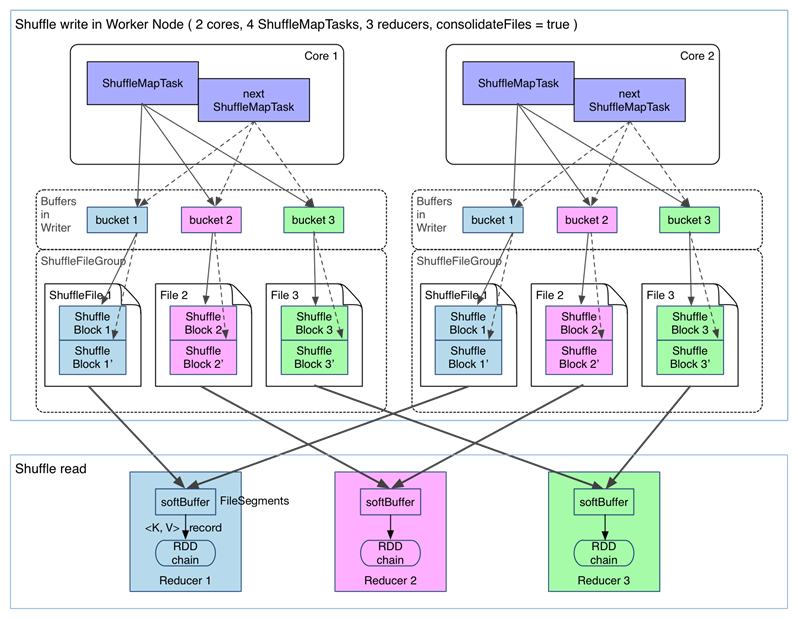
ПЩвдУїЯдПДГіЃЌдквЛИі core ЩЯСЌајжДааЕФ ShuffleMapTasks ПЩвдЙВгУвЛИіЪфГіЮФМў
ShuffleFileЁЃЯШжДааЭъЕФ ShuffleMapTask аЮГЩ ShuffleBlock iЃЌКѓжДааЕФ
ShuffleMapTask ПЩвдНЋЪфГіЪ§ОнжБНгзЗМгЕН ShuffleBlock i КѓУцЃЌаЮГЩ ShuffleBlock
i'ЃЌУПИі ShuffleBlock БЛГЦЮЊ FileSegmentЁЃЯТвЛИі stage ЕФ reducer
жЛашвЊ fetch ећИі ShuffleFile ОЭааСЫЁЃетбљЃЌУПИі worker ГжгаЕФЮФМўЪ§НЕЮЊ
coresЁС RЁЃFileConsolidation ЙІФмПЩвдЭЈЙ§spark.shuffle.consolidateFiles=trueРДПЊЦєЁЃ
SparkКЫаФИХФюжЎCache
val rdd1 = ... // ЖСШЁhdfsЪ§ОнЃЌМгдиГЩRDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cacheКЭunpersisitСНИіВйзїБШНЯЬиЪтЃЌЫћУЧМШВЛЪЧactionвВВЛЪЧtransformationЁЃcacheЛсНЋБъМЧашвЊЛКДцЕФrddЃЌеце§ЛКДцЪЧдкЕквЛДЮБЛЯрЙиactionЕїгУКѓВХЛКДцЃЛunpersisitЪЧФЈЕєИУБъМЧЃЌВЂЧвСЂПЬЪЭЗХФкДцЁЃжЛгаactionжДааЪБЃЌrdd1ВХЛсПЊЪМДДНЈВЂНјааКѓајЕФrddБфЛЛМЦЫуЁЃ
cacheЦфЪЕвВЪЧЕїгУЕФpersistГжОУЛЏКЏЪ§ЃЌжЛЪЧбЁдёЕФГжОУЛЏМЖБ№ЮЊMEMORY_ONLYЁЃ
persistжЇГжЕФRDDГжОУЛЏМЖБ№ШчЯТЃК

ашвЊзЂвтЕФЮЪЬтЃК
CacheЛђshuffleГЁОАађСаЛЏЪБЃЌ sparkађСаЛЏВЛжЇГжprotobuf messageЃЌашвЊjava
ПЩвдserializableЕФЖдЯѓЁЃвЛЕЉдкађСаЛЏгУЕНВЛжЇГжjava serializableЕФЖдЯѓОЭЛсГіЯжЩЯЪіДэЮѓЁЃ
SparkжЛвЊаДДХХЬЃЌОЭЛсгУЕНађСаЛЏЁЃГ§СЫshuffleНзЖЮКЭpersistЛсађСаЛЏЃЌЦфЫћЪБКђRDDДІРэЖМдкФкДцжаЃЌВЛЛсгУЕНађСаЛЏЁЃ
Spark StreamingдЫаадРэ
sparkГЬађЪЧЪЙгУвЛИіsparkгІгУЪЕР§вЛДЮадЖдвЛХњРњЪЗЪ§ОнНјааДІРэЃЌspark streamingЪЧНЋГжајВЛЖЯЪфШыЕФЪ§ОнСїзЊЛЛГЩЖрИіbatchЗжЦЌЃЌЪЙгУвЛХњsparkгІгУЪЕР§НјааДІРэЁЃ
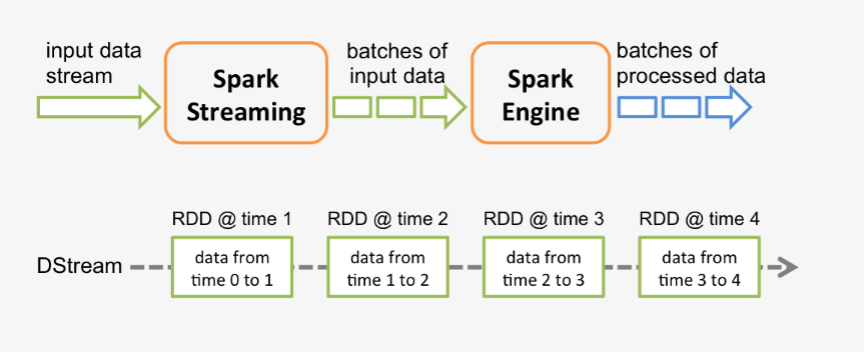
ДгдРэЩЯПДЃЌАбДЋЭГЕФsparkХњДІРэГЬађБфГЩstreamingГЬађЃЌsparkашвЊЙЙНЈЪВУДЃП
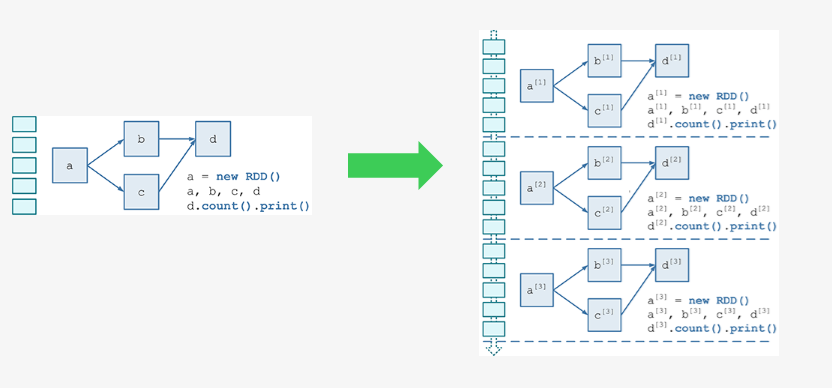
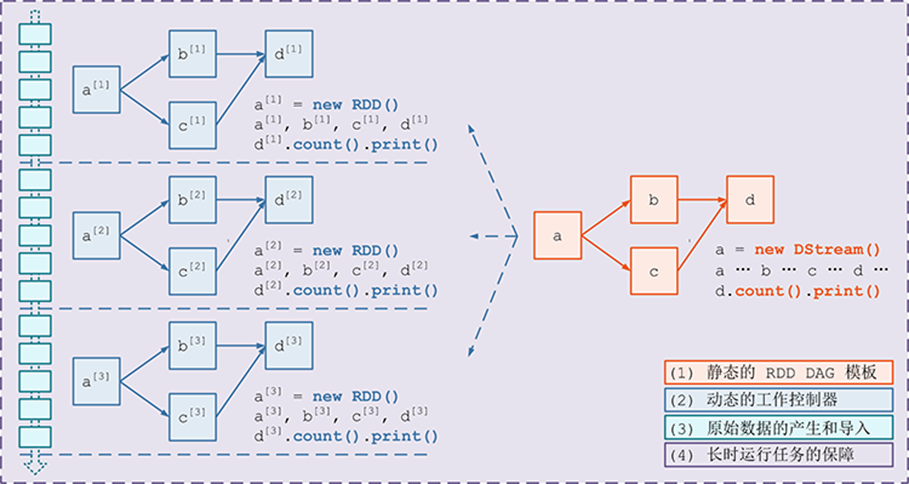
ашвЊЙЙНЈ4ИіЖЋЮїЃК
вЛИіОВЬЌЕФ RDD DAG ЕФФЃАхЃЌРДБэЪОДІРэТпМЃЛ
вЛИіЖЏЬЌЕФЙЄзїПижЦЦїЃЌНЋСЌајЕФ streaming data ЧаЗжЪ§ОнЦЌЖЮЃЌВЂАДееФЃАхИДжЦГіаТЕФ
RDD ЃЛ
DAG ЕФЪЕР§ЃЌЖдЪ§ОнЦЌЖЮНјааДІРэЃЛ
ReceiverНјаадЪМЪ§ОнЕФВњЩњКЭЕМШыЃЛReceiverНЋНгЪеЕНЕФЪ§ОнКЯВЂЮЊЪ§ОнПщВЂДцЕНФкДцЛђгВХЬжаЃЌЙЉКѓајbatch
RDDНјааЯћЗбЃЛ
ЖдГЄЪБдЫааШЮЮёЕФБЃеЯЃЌАќРЈЪфШыЪ§ОнЕФЪЇаЇКѓЕФжиЙЙЃЌДІРэШЮЮёЕФЪЇАмКѓЕФжиЕїЁЃ
ОпЬхstreamingЕФЯъЯИдРэПЩвдВЮПМЙуЕуЭЈГіЦЗЕФдДТыНтЮіЮФеТЃК
Ждгкspark streamingашвЊзЂвтвдЯТШ§ЕуЃК
ОЁСПБЃжЄУПИіworkНкЕужаЕФЪ§ОнВЛвЊТфХЬЃЌвдЬсЩ§жДаааЇТЪЁЃ
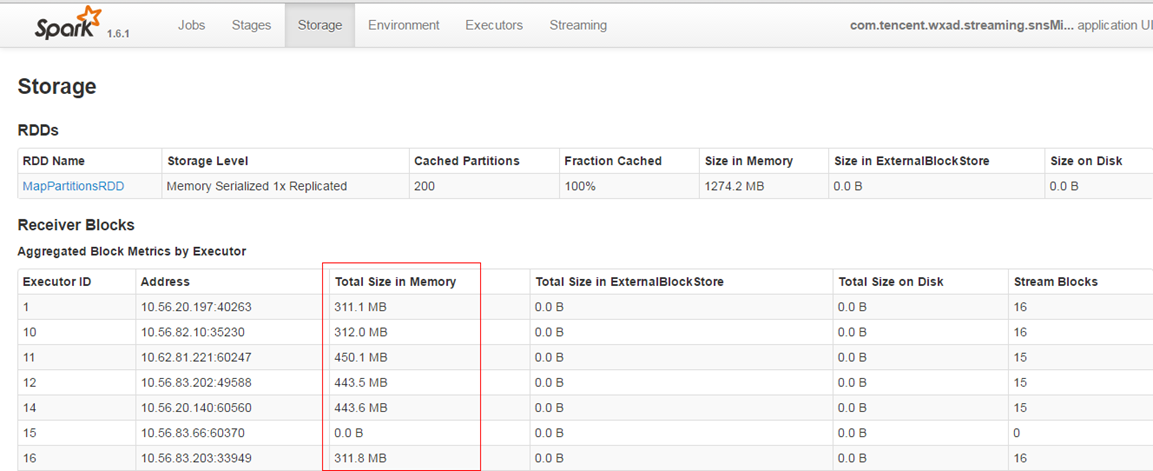
БЃжЄУПИіbatchЕФЪ§ОнФмЙЛдкbatch intervalЪБМфФкДІРэЭъБЯЃЌвдУтдьГЩЪ§ОнЖбЛ§ЁЃ
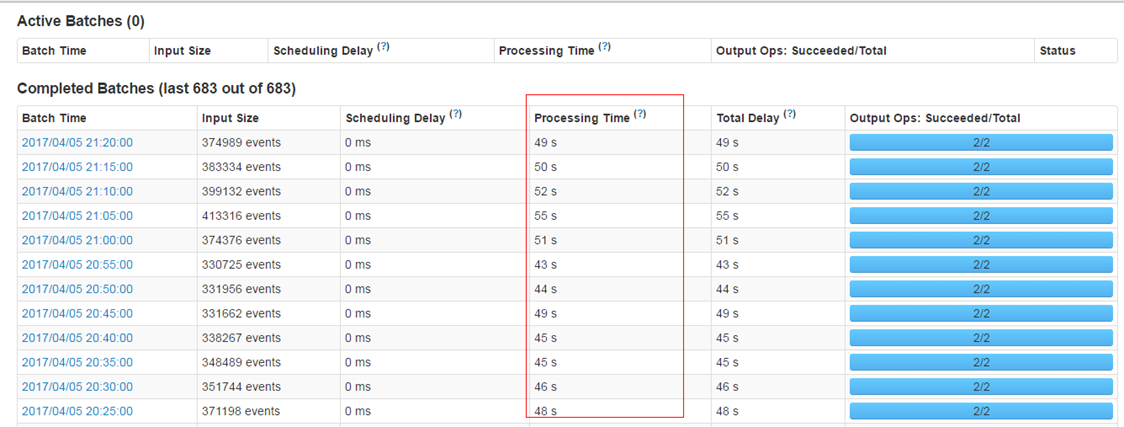
ЪЙгУstevenЬсЙЉЕФПђМмНјааЪ§ОнНгЪеЪБЕФдЄДІРэЃЌМѕЩйВЛБивЊЪ§ОнЕФДцДЂКЭДЋЪфЁЃДгtdbankжаНгЪеКѓзЊДЂЧАНјааЙ§ТЫЃЌЖјВЛЪЧдкtaskОпЬхДІРэЪБВХНјааЙ§ТЫЁЃ
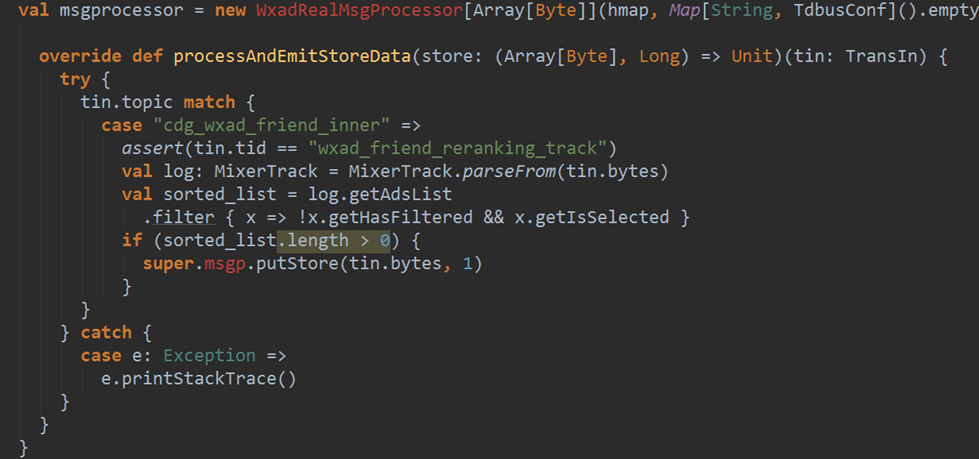
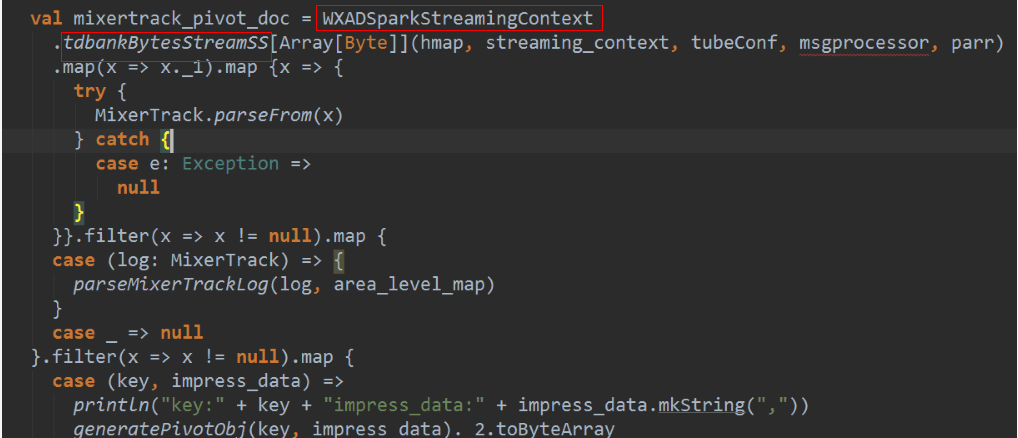
Spark зЪдДЕїгХ
ФкДцЙмРэЃК
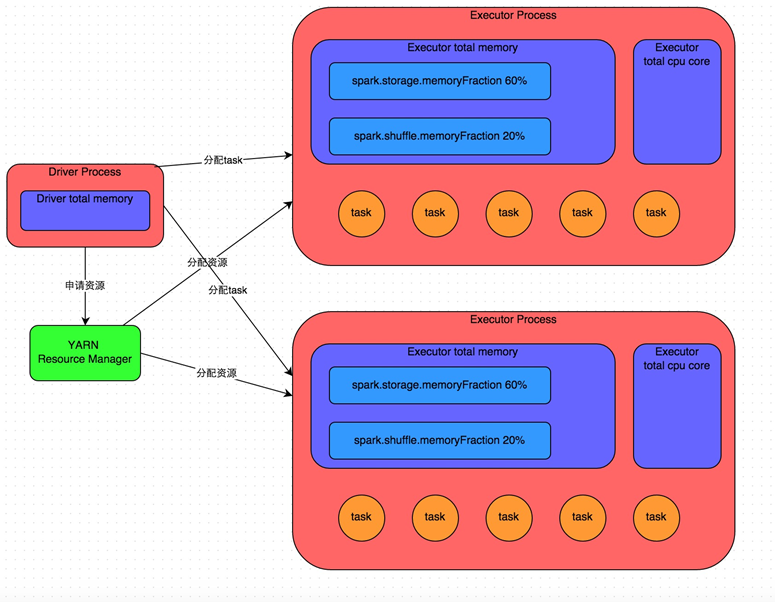
ExecutorЕФФкДцжївЊЗжЮЊШ§ПщЃК
ЕквЛПщЪЧШУtaskжДааЮвУЧздМКБраДЕФДњТыЪБЪЙгУЃЌФЌШЯЪЧеМExecutorзмФкДцЕФ20%ЃЛ
ЕкЖўПщЪЧШУtaskЭЈЙ§shuffleЙ§ГЬРШЁСЫЩЯвЛИіstageЕФtaskЕФЪфГіКѓЃЌНјааОлКЯЕШВйзїЪБЪЙгУЃЌФЌШЯвВЪЧеМExecutorзмФкДцЕФ20%ЃЛ
ЕкШ§ПщЪЧШУRDDГжОУЛЏЪБЪЙгУЃЌФЌШЯеМExecutorзмФкДцЕФ60%ЁЃ
УПИіtaskвдМАУПИіexecutorеМгУЕФФкДцашвЊЗжЮівЛЯТЁЃУПИіtaskДІРэвЛИіpartiitonЕФЪ§ОнЃЌЗжЦЌЬЋЩйЃЌЛсдьГЩФкДцВЛЙЛЁЃ
ЦфЫћзЪдДХфжУЃК

|









