| БрМЭЦМі: |
БОЮФДгШчЯТМИИіЗНУцЗжБ№НщЩмЃЌАќКЌЃК
гВМўбЁдёЁЂФкВПбЙЫѕ ЁЂЗжЦЌВпТдЁЂЫїв§гХЛЏЁЂВщбЏаЇТЪЁЂESЕФФкДцЩшжУЁЂЕїећJVMЩшжУЕШФкШнЁЃ
БОЮФРДздФЛЮобЉДњТыВЉПЭЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
гВМўбЁдё
ElasticsearchЃЈКѓЮФМђГЦ ESЃЉЕФЛљДЁЪЧ LuceneЃЌЫљгаЕФЫїв§КЭЮФЕЕЪ§ОнЪЧДцДЂдкБОЕиЕФДХХЬжаЃЌОпЬхЕФТЗОЖПЩдк
ES ЕФХфжУЮФМў../config/elasticsearch.ymlжаХфжУЃЌШчЯТЃК
# Path to directory
where to store the data (separate multiple locations
by comma):
#
path.data: /path/to/data
#
# Path to log files:
#
path.logs: /path/to/logs |
ДХХЬЩцМАЕН IO ЕФЖСаДЫйЖШЮЪЬтЃЌвђДЫШчЙћЬѕМўдЪаэЕФЬѕМўЯТЃЌОЁПЩФмЪЙгУ
SSD гВХЬКЭ ИпХфжУЕФ CPUЁЃIOЕФЬсЩ§ЃЌЛсМЋДѓИФНј ES ЕФЫйЖШКЭадФмЁЃ
ДХХЬБИЗнВЩгУ RAID0ЁЃвђЮЊ Elasticsearch дкздЩэВуУцЭЈЙ§ИББОЃЌвбОЬсЙЉСЫБИЗнЕФЙІФмЃЌЫљвдВЛашвЊРћгУДХХЬЕФБИЗнЙІФмЃЌЕЋЪЧШчЙћЭЌЪБЪЙгУДХХЬБИЗнЙІФмЕФЛАЃЌЖдаДШыЫйЖШгаНЯДѓЕФЬсЩ§ЁЃ
ФкВПбЙЫѕ
гВМўзЪдДБШНЯАКЙѓЃЌвЛАуВЛЛсЛЈДѓГЩБОШЅЙКжУетаЉЃЌПЩПиЕФНтОіЗНАИЛЙЪЧашвЊДгШэМўЗНУцРДЪЕЯжадФмгХЛЏЬсЩ§ЁЃ
ЦфЪЕЃЌЖдгквЛИіЗжВМЪНЁЂПЩРЉеЙЁЂжЇГжPBМЖБ№Ъ§ОнЁЂЪЕЪБЕФЫбЫїгыЪ§ОнЗжЮів§ЧцЃЌES БОЩэЖдгкЫїв§Ъ§ОнКЭЮФЕЕЪ§ОнЕФДцДЂЗНУцФкВПзіСЫКмЖргХЛЏЃЌОпЬхЬхЯждкЖдЪ§ОнЕФбЙЫѕЃЌФЧУДЪЧШчКЮбЙЫѕЕФФиЃПНщЩмЧАЯШвЊЫЕУїЯТ
Postings lists ЕФИХФюЁЃ
Postings lists
ЫбЫїв§ЧцвЛЯюКмживЊЕФЙЄзїОЭЪЧИпаЇЕФбЙЫѕКЭПьЫйЕФНтбЙЫѕвЛЯЕСагаађЕФећЪ§СаБэЁЃЮвУЧЖМжЊЕРЃЌElasticsearch
Лљгк LuceneЃЌвЛИі Lucene Ыїв§ ЮвУЧдк Elasticsearch ГЦзї ЗжЦЌ ЃЌ етИі
java Птв§ШыСЫ АДЖЮЫбЫї ЕФИХФюЁЃаТЕФЮФЕЕЪзЯШБЛЬэМгЕНФкДцЫїв§ЛКДцжаЃЌШЛКѓаДШыЕНвЛИіЛљгкДХХЬЕФЖЮЁЃдкУПИі
segment ФкЮФЕЕЖМЛсгавЛИі 0 ЕНЮФЕЕИіЪ§жЎМфЕФБъЪЖЗћЃЈзюИпжЕ 2^31 -1ЃЉЃЌГЦжЎЮЊ doc
IDЁЃетдкИХФюЩЯРрЫЦгкЪ§зщжаЕФЫїв§ЃКЫќБОЩэВЛзіДцДЂЃЌЕЋзувдЪЖБ№УПИіitem Ъ§ОнЁЃ
Segments АДЫГађДцДЂгаЙиЮФЕЕЕФЪ§ОнЃЌдквЛИіSegments жа doc ID ЪЧ ЮФЕЕЕФЫїв§ЁЃвђДЫЃЌsegment
жаЕФЕквЛИіЮФЕЕЕФ doc ID ЮЊ0ЃЌЕкЖўИіЮЊ1ЃЌЕШЕШЃЌжБЕНзюКѓвЛИіЮФЕЕЃЌЦф doc ID ЕШгк segment
жаЮФЕЕЕФзмЪ§Мѕ1ЁЃ
ФЧУДетаЉ doc ID гаЪВУДгУФиЃПЕЙХХЫїв§ашвЊНЋ terms гГЩфЕНАќКЌИУЕЅДЪ ЃЈtermЃЉ ЕФЮФЕЕСаБэЃЌетбљЕФгГЩфСаБэЮвУЧГЦжЎЮЊЃКЕЙХХСаБэЃЈpostings
listЃЉЁЃОпЬхФГвЛЬѕгГЩфЪ§ОнГЦжЎЮЊЃКЕЙХХЫїв§ЯюЃЈPostingЃЉЁЃ
ОйИіР§згЃЌЮФЕЕКЭДЪЬѕжЎМфЕФЙиЯЕШчЯТЭМЫљЪОЃЌгвБпЕФЙиЯЕБэМДЮЊЕЙХХСаБэЃК
ЕЙХХСаБэ гУРДМЧТМгаФФаЉЮФЕЕАќКЌСЫФГИіЕЅДЪЃЈTermЃЉЁЃвЛАудкЮФЕЕМЏКЯРяЛсгаКмЖрЮФЕЕАќКЌФГИіЕЅДЪЃЌУПИіЮФЕЕЛсМЧТМЮФЕЕБрКХЃЈdoc
IDЃЉЃЌЕЅДЪдкетИіЮФЕЕжаГіЯжЕФДЮЪ§ЃЈTFЃЉМАЕЅДЪдкЮФЕЕжаФФаЉЮЛжУГіЯжЙ§ЕШаХЯЂЃЌетбљгывЛИіЮФЕЕЯрЙиЕФаХЯЂБЛГЦзі
ЕЙХХЫїв§ЯюЃЈPostingЃЉЃЌАќКЌетИіЕЅДЪЕФвЛЯЕСаЕЙХХЫїв§ЯюаЮГЩСЫСаБэНсЙЙЃЌетОЭЪЧФГИіЕЅДЪЖдгІЕФ ЕЙХХСаБэ
Frame Of Reference
СЫНтСЫЗжДЪЃЈTermЃЉКЭЮФЕЕЃЈDocumentЃЉжЎМфЕФгГЩфЙиЯЕКѓЃЌЮЊСЫИпаЇЕФМЦЫуНЛМЏКЭВЂМЏЃЌЮвУЧашвЊЕЙХХСаБэЃЈpostings
listsЃЉЪЧгаађЕФЃЌетбљЗНБуЮвУЧбЙЫѕКЭНтбЙЫѕЁЃ
еыЖдЕЙХХСаБэЃЌLucene ВЩгУвЛжждіСПБрТыЕФЗНЪННЋвЛЯЕСа ID НјаабЙЫѕДцДЂЃЌМДГЦЮЊFrame
Of ReferenceЕФбЙЫѕЗНЪНЃЈFORЃЉЃЌздLucene 4.1вдРДвЛжБдкЪЙгУЁЃ
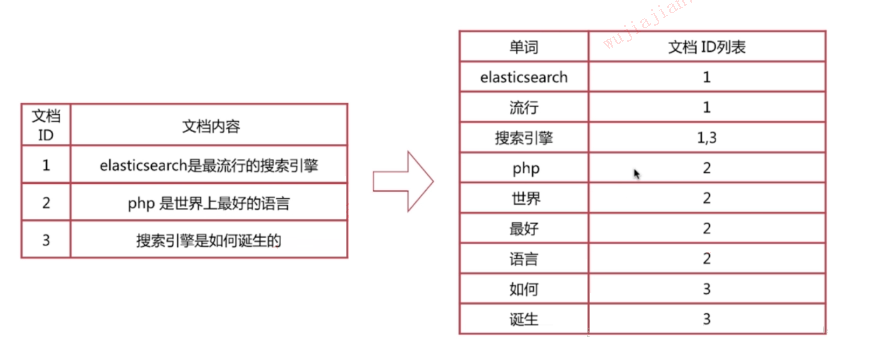
дкЪЕМЪЕФЫбЫїв§ЧцЯЕЭГжаЃЌВЂВЛДцДЂЕЙХХЫїв§ЯюжаЕФЪЕМЪЮФЕЕБрКХЃЈDoc IDЃЉЃЌЖјЪЧДњжЎвдЮФЕЕБрКХВюжЕЃЈD-GapЃЉЁЃЮФЕЕБрКХВюжЕЪЧЕЙХХСаБэжаЯрСкЕФСНИіЕЙХХЫїв§ЯюЮФЕЕБрКХЕФВюжЕЃЌвЛАудкЫїв§ЙЙНЈЙ§ГЬжаЃЌПЩвдБЃжЄЕЙХХСаБэжаКѓУцГіЯжЕФЮФЕЕБрКХДѓгкжЎЧАГіЯжЕФЮФЕЕБрКХЃЌЫљвдЮФЕЕБрКХВюжЕзмЪЧДѓгк0ЕФећЪ§ЁЃШчЭМ2ЫљЪОЕФР§згжаЃЌдЪМЕФ
3ИіЮФЕЕБрКХЗжБ№ЪЧ187ЁЂ196КЭ199ЃЌЭЈЙ§БрКХВюжЕМЦЫуЃЌдкЪЕМЪДцДЂЕФЪБКђОЭзЊЛЏГЩСЫЃК187ЁЂ9ЁЂ3ЁЃ
жЎЫљвдвЊЖдЮФЕЕБрКХНјааВюжЕМЦЫуЃЌжївЊдвђЪЧЮЊСЫИќКУЕиЖдЪ§ОнНјаабЙЫѕЃЌдЪМЮФЕЕБрКХвЛАуЖМЪЧДѓЪ§жЕЃЌЭЈЙ§ВюжЕМЦЫуЃЌОЭгааЇЕиНЋДѓЪ§жЕзЊЛЛЮЊСЫаЁЪ§жЕЃЌЖјетгажњгкдіМгЪ§ОнЕФбЙЫѕТЪЁЃ
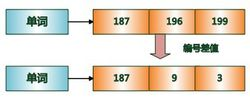
БШШчвЛИіДЪЖдгІЕФЮФЕЕID СаБэ[73, 300, 302, 332,343, 372] ЃЌIDСаБэЪзЯШвЊДгаЁЕНДѓХХКУађЃЛ
ЕквЛВНЃК діСПБрТыОЭЪЧДгЕкЖўИіЪ§ПЊЪМУПИіЪ§ДцДЂгыЧАвЛИіidЕФВюжЕЃЌМД300-73=227ЃЌ302-300=2ЃЌ...ЃЌвЛжБЕНзюКѓвЛИіЪ§ЃЛ
ЕкЖўВНЃК ОЭЪЧНЋетаЉВюжЕЗХЕНВЛЭЌЕФЧјПщЃЌLuceneЪЙгУ256ИіЧјПщЃЌЯТУцЪОР§ЮЊСЫЗНБуеЙЪОЪЙгУСЫ3ИіЧјПщЃЌМДУП3ИіЪ§вЛзщЃЛ
ЕкШ§ВНЃК ЮЛбЙЫѕЃЌМЦЫуУПзщ3ИіЪ§жазюДѓЕФФЧИіЪ§ашвЊеМгУbitЮЛЪ§ЃЌБШШч30ЁЂ11ЁЂ29жазюДѓЪ§30зюаЁашвЊ5ИіbitЮЛДцДЂЃЌетбљ11ЁЂ29вВгУ5ИіbitЮЛДцДЂЃЌетбљВХеМгУ15ИіbitЃЌВЛЕН2ИізжНкЃЌбЙЫѕаЇЙћКмКУЁЃ
ШчЯТУцдРэЭМЫљЪОЃЌетЪЧвЛИіЧјПщДѓаЁЮЊ3ЕФЪОР§ЃЈЪЕМЪЩЯЪЧ256ЃЉЃК
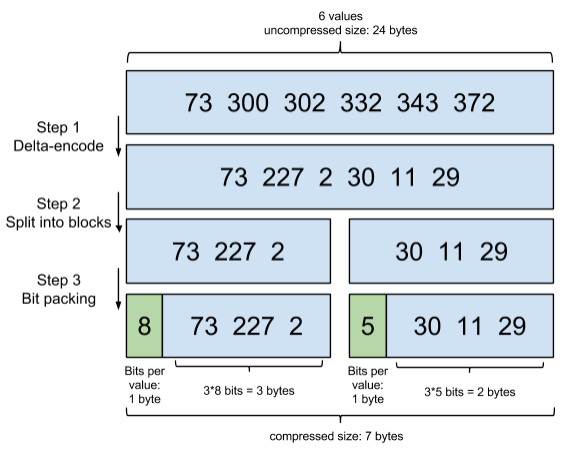
ПМТЧЕНЦЕЗБГіЯжЕФtermЃЈЫљЮНlow cardinalityЕФжЕЃЉЃЌБШШчgenderРяЕФФаЛђепХЎЁЃШчЙћга1АйЭђИіЮФЕЕЃЌФЧУДадБ№ЮЊФаЕФ
posting list РяОЭЛсга50ЭђИіintжЕЁЃгУ Frame of Reference БрТыНјаабЙЫѕПЩвдМЋДѓМѕЩйДХХЬеМгУЁЃетИігХЛЏЖдгкМѕЩйЫїв§ГпДчгаЗЧГЃживЊЕФвтвхЁЃ
вђЮЊетИі FOR ЕФБрТыЪЧгаНтбЙЫѕГЩБОЕФЁЃРћгУskip listЃЌГ§СЫЬјЙ§СЫБщРњЕФГЩБОЃЌвВЬјЙ§СЫНтбЙЫѕетаЉбЙЫѕЙ§ЕФblockЕФЙ§ГЬЃЌДгЖјНкЪЁСЫcpuЁЃ
Roaring bitmaps
Frame Of Reference бЙЫѕЫуЗЈЖдгкЕЙХХБэРДЫЕаЇЙћКмКУЃЌЕЋЖдгкашвЊДцДЂдкФкДцжаЕФFilterЛКДцЕШВЛЬЋКЯЪЪЃЌСНепжЎМфгаКмЖрВЛЭЌжЎДІЃКЕЙХХБэДцДЂдкДХХЬЃЌеыЖдУПИіДЪЖМашвЊНјааБрТыЃЌЖјFilterЕШФкДцЛКДцжЛЛсДцДЂФЧаЉОГЃЪЙгУЕФЪ§ОнЃЌЖјЧвеыЖдFilterЪ§ОнЕФЛКДцОЭЪЧЮЊСЫМгЫйДІРэаЇТЪЃЌЖдбЙЫѕЫуЗЈвЊЧѓИќИпЃЛетОЭВњЩњСЫЯТУцеыЖдФкДцЛКДцЪ§ОнПЩвдНјааИпаЇбЙЫѕНтбЙКЭТпМдЫЫуЕФroaring
bitmapsЫуЗЈЁЃ
ЫЕЕНRoaring bitmapsЃЌОЭБиаыЯШДгbitmapЫЕЦ№ЁЃBitmapЪЧвЛжжЪ§ОнНсЙЙЃЌМйЩшгаФГИіposting
listЃК
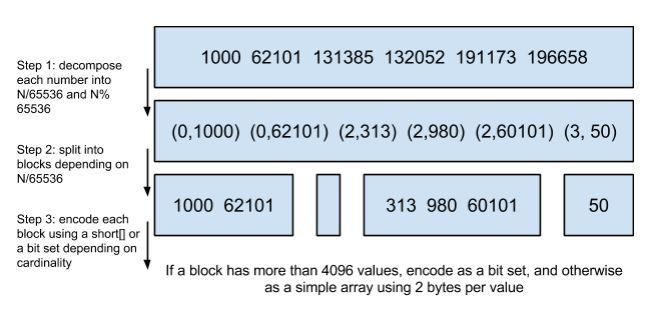
ЖдгІЕФBitmapОЭЪЧЃК
ЗЧГЃжБЙлЃЌгУ0/1БэЪОФГИіжЕЪЧЗёДцдкЃЌБШШч8етИіжЕОЭЖдгІЕк8ЮЛЃЌЖдгІЕФbitжЕЪЧ1ЃЌетбљгУвЛИізжНкОЭПЩвдДњБэ8ИіЮФЕЕidЃЈ1B
= 8bitЃЉЃЌОЩАцБО(5.0жЎЧА)ЕФLuceneОЭЪЧгУетбљЕФЗНЪНРДбЙЫѕЕФЁЃЕЋетбљЕФбЙЫѕЗНЪНШдШЛВЛЙЛИпаЇЃЌBitmapздЩэОЭгабЙЫѕЕФЬиЕуЃЌЦфгУвЛИіbyteОЭПЩвдДњБэ8ИіЮФЕЕЃЌЫљвд100ЭђИіЮФЕЕжЛашвЊ12.5ЭђИіbyteЁЃЕЋЪЧПМТЧЕНЮФЕЕПЩФмгаЪ§ЪЎвкжЎЖрЃЌдкФкДцРяБЃДцBitmapШдШЛЪЧКмЩнГоЕФЪТЧщЁЃЖјЧвЖдгкИіУПвЛИіfilterЖМвЊЯћКФвЛИіBitmapЃЌБШШчage=18ЛКДцЦ№РДЕФЛАЪЧвЛИіBitmapЃЌ18<=age<25ЪЧСэЭтвЛИіfilterЛКДцЦ№РДвВвЊвЛИіBitmapЁЃ
BitmapЕФШБЕуЪЧДцДЂПеМфЫцзХЮФЕЕИіЪ§ЯпаддіГЄЃЌЫљвдУиОїОЭдкгкашвЊгавЛИіЪ§ОнНсЙЙДђЦЦетИіФЇжфЃЌФЧУДОЭвЛЖЈвЊгУЕНФГаЉжИЪ§ЬиадЃК
ПЩвдКмбЙЫѕЕиБЃДцЩЯвкИіbitДњБэЖдгІЕФЮФЕЕЪЧЗёЦЅХфfilterЃЛ
етИібЙЫѕЕФBitmapШдШЛПЩвдКмПьЕиНјааANDКЭ ORЕФТпМВйзїЁЃ
LuceneЪЙгУЕФетИіЪ§ОнНсЙЙНазі Roaring BitmapЁЃ
ЦфбЙЫѕЕФЫМТЗЦфЪЕКмМђЕЅЁЃгыЦфБЃДц100Иі0ЃЌеМгУ100ИіbitЁЃЛЙВЛШчБЃДц0вЛДЮЃЌШЛКѓЩљУїетИі0жиИДСЫ100БщЁЃ
етСНжжКЯВЂЪЙгУЫїв§ЕФЗНЪНЖМгаЦфгУЭОЁЃElasticsearch ЖдЦфадФмгаЯъЯИЕФЖдБШЃЌПЩдФЖС Frame
of Reference and Roaring BitmapsЁЃ
ЗжЦЌВпТд
ДДНЈЫїв§ЕФЪБКђЃЌЮвУЧашвЊдЄЗжХф ES МЏШКЕФЗжЦЌЪ§КЭИББОЪ§ЃЌМДЪЙЪЧЕЅЛњЧщПіЯТЁЃШчЙћУЛгадк mapping
ЮФМўжажИЖЈЃЌФЧУДЫїв§дкФЌШЯЧщПіЯТЛсБЛЗжХф5ИіжїЗжЦЌКЭУПИіжїЗжЦЌЕФ1ИіИББОЁЃ
ЗжЦЌКЭИББОЕФЩшМЦЮЊ ES ЬсЙЉСЫжЇГжЗжВМЪНКЭЙЪеЯзЊвЦЕФЬиадЃЌЕЋВЂВЛвтЮЖзХЗжЦЌКЭИББОЪЧПЩвдЮоЯоЗжХфЕФЁЃЖјЧвЫїв§ЕФЗжЦЌЭъГЩЗжХфКѓгЩгкЫїв§ЕФТЗгЩЛњжЦЃЌЮвУЧЪЧВЛФмжиаТаоИФЗжЦЌЪ§ЕФЁЃР§ШчФГИіДДвЕЙЋЫОГѕЪМгУЛЇЕФЫїв§
t_user ЗжЦЌЪ§ЮЊ2ЃЌЕЋЪЧЫцзХвЕЮёЕФЗЂеЙгУЛЇЕФЪ§ОнСПбИЫйдіГЄЃЌетЪБЮвУЧЪЧВЛФмжиаТНЋЫїв§ t_user
ЕФЗжЦЌЪ§діМгЮЊ3ЛђепИќДѓЕФЪ§ЁЃ
ПЩФмгаШЫЛсЫЕЃЌЮвВЛжЊЕРетИіЫїв§НЋРДЛсБфЕУЖрДѓЃЌВЂЧвЙ§КѓЮввВВЛФмИќИФЫїв§ЕФДѓаЁЃЌЫљвдЮЊСЫБЃЯеЦ№МћЃЌЛЙЪЧИјЫќЩшЮЊ
1000 ИіЗжЦЌАЩЁ
вЛИіЗжЦЌВЂВЛЪЧУЛгаДњМлЕФЁЃашвЊСЫНтЃК
вЛИіЗжЦЌЕФЕзВуМДЮЊвЛИі Lucene Ыїв§ЃЌЛсЯћКФвЛЖЈЮФМўОфБњЁЂФкДцЁЂвдМА CPU дЫзЊЁЃ
УПвЛИіЫбЫїЧыЧѓЖМашвЊУќжаЫїв§жаЕФУПвЛИіЗжЦЌЃЌШчЙћУПвЛИіЗжЦЌЖМДІгкВЛЭЌЕФНкЕуЛЙКУЃЌ ЕЋШчЙћЖрИіЗжЦЌЖМашвЊдкЭЌвЛИіНкЕуЩЯОКељЪЙгУЯрЭЌЕФзЪдДОЭгааЉдуИтСЫЁЃ
гУгкМЦЫуЯрЙиЖШЕФДЪЯюЭГМЦаХЯЂЪЧЛљгкЗжЦЌЕФЁЃШчЙћгааэЖрЗжЦЌЃЌУПвЛИіЖМжЛгаКмЩйЕФЪ§ОнЛсЕМжТКмЕЭЕФЯрЙиЖШЁЃ
ЪЪЕБЕФдЄЗжХфЪЧКУЕФЁЃЕЋЩЯЧЇИіЗжЦЌОЭгааЉдуИтЁЃЮвУЧКмФбШЅЖЈвхЗжЦЌЪЧЗёЙ§ЖрСЫЃЌетШЁОігкЫќУЧЕФДѓаЁвдМАШчКЮШЅЪЙгУЫќУЧЁЃ
вЛАйИіЗжЦЌЕЋКмЩйЪЙгУЛЙКУЃЌСНИіЗжЦЌЕЋЗЧГЃЦЕЗБЕиЪЙгУгаПЩФмОЭгаЕуЖрСЫЁЃ МрПиФуЕФНкЕуБЃжЄЫќУЧСєгазуЙЛЕФПеЯазЪдДРДДІРэвЛаЉЬиЪтЧщПіЁЃ
вЛИівЕЮёЫїв§ОпЬхашвЊЗжХфЖрЩйЗжЦЌПЩФмашвЊМмЙЙЪІКЭММЪѕШЫдБЖдвЕЮёЕФдіГЄгаИідЄЯШЕФХаЖЯЃЌКсЯђРЉеЙгІЕБЗжНзЖЮНјааЁЃЮЊЯТвЛНзЖЮзМБИКУзуЙЛЕФзЪдДЁЃ
жЛгаЕБФуНјШыЕНЯТвЛИіНзЖЮЃЌФуВХгаЪБМфЫМПМашвЊзїГіФФаЉИФБфРДДяЕНетИіНзЖЮЁЃ
вЛАуРДЫЕЃЌЮвУЧзёбвЛаЉддђЃК
ПижЦУПИіЗжЦЌеМгУЕФгВХЬШнСПВЛГЌЙ§ESЕФзюДѓJVMЕФЖбПеМфЩшжУЃЈвЛАуЩшжУВЛГЌЙ§32GЃЌВЮМгЯТЮФЕФJVMЩшжУддђЃЉЃЌвђДЫЃЌШчЙћЫїв§ЕФзмШнСПдк500GзѓгвЃЌФЧЗжЦЌДѓаЁдк16ИізѓгвМДПЩЃЛЕБШЛЃЌзюКУЭЌЪБПМТЧддђ2ЁЃ
ПМТЧвЛЯТnodeЪ§СПЃЌвЛАувЛИіНкЕугаЪБКђОЭЪЧвЛЬЈЮяРэЛњЃЌШчЙћЗжЦЌЪ§Й§ЖрЃЌДѓДѓГЌЙ§СЫНкЕуЪ§ЃЌКмПЩФмЛсЕМжТвЛИіНкЕуЩЯДцдкЖрИіЗжЦЌЃЌвЛЕЉИУНкЕуЙЪеЯЃЌМДЪЙБЃГжСЫ1ИівдЩЯЕФИББОЃЌЭЌбљгаПЩФмЛсЕМжТЪ§ОнЖЊЪЇЃЌМЏШКЮоЗЈЛжИДЁЃЫљвдЃЌ
вЛАуЖМЩшжУЗжЦЌЪ§ВЛГЌЙ§НкЕуЪ§ЕФ3БЖЁЃ
жїЗжЦЌЃЌИББОКЭНкЕузюДѓЪ§жЎМфЪ§СПЃЌЮвУЧЗжХфЕФЪБКђПЩвдВЮПМвдЯТЙиЯЕЃК
НкЕуЪ§<=жїЗжЦЌЪ§*ЃЈИББОЪ§+1ЃЉ
ДДНЈЫїв§ЕФЪБКђашвЊПижЦЗжЦЌЗжХфааЮЊЃЌКЯРэЗжХфЗжЦЌЃЌШчЙћКѓЦкЫїв§ЫљЖдгІЕФЪ§ОндНРДдНЖрЃЌЮвУЧЛЙПЩвдЭЈЙ§Ыїв§Б№УћЕШЦфЫћЗНЪННтОіЁЃ
вдЩЯЪЧдкДДНЈУПИіЫїв§ЕФЪБКђашвЊПМТЧЕФгХЛЏЗНЗЈЃЌШЛЖјдкЫїв§вбДДНЈКУЕФЧАЬсЯТЃЌЪЧЗёОЭЪЧУЛгаАьЗЈДгЗжЦЌЕФНЧЖШЬсИпСЫадФмСЫФиЃПЕБШЛВЛЪЧЃЌЪзЯШФмзіЕФЪЧЕїећЗжЦЌЗжХфЦїЕФРраЭЃЌОпЬхЪЧдк
elasticsearch.yml жаЩшжУcluster.routing.allocation.type
ЪєадЃЌЙВгаСНжжЗжЦЌЦїeven_shardЃЌbalancedЃЈФЌШЯЃЉЁЃ
even_shard ЪЧОЁСПБЃжЄУПИіНкЕуЖМОпгаЯрЭЌЪ§СПЕФЗжЦЌЃЌbalanced ЪЧЛљгкПЩПижЦЕФШЈжиНјааЗжХфЃЌЯрЖдгкЧАвЛИіЗжХфЦїЃЌЫќИќБЉТЉСЫвЛаЉВЮЪ§Жјв§ШыЕїећЗжХфЙ§ГЬЕФФмСІЁЃ
УПДЮESЕФЗжЦЌЕїећЖМЪЧдкESЩЯЕФЪ§ОнЗжВМЗЂЩњСЫБфЛЏЕФЪБКђНјааЕФЃЌзюгаДњБэадЕФОЭЪЧгааТЕФЪ§ОнНкЕуМгШыСЫМЏШКЕФЪБКђЁЃЕБШЛЕїећЗжЦЌЕФЪБЛњВЂВЛЪЧгЩФГИіуажЕДЅЗЂЕФЃЌESФкжУЪЎвЛИіВУОіепРДОіЖЈЪЧЗёДЅЗЂЗжЦЌЕїећЃЌетРяднВЛзИЪіЁЃСэЭтЃЌетаЉЗжХфВПЪ№ВпТдЖМЪЧПЩвддкдЫааЪБИќаТЕФЃЌИќЖрХфжУЗжЦЌЕФЪєадвВЧыДѓМвздааВщдФЭјЩЯзЪСЯЁЃ
Ыїв§гХЛЏ
MappingНЈФЃ
ОЁСПБмУтЪЙгУnestedЛђ parent/childЃЌФмВЛгУОЭВЛгУЃЛnested queryТ§ЃЌ parent/child
query ИќТ§ЃЌБШnested queryТ§ЩЯАйБЖЃЛвђДЫФмдкmappingЩшМЦНзЖЮИуЖЈЕФЃЈДѓПэБэЩшМЦЛђВЩгУБШНЯsmartЕФЪ§ОнНсЙЙЃЉЃЌОЭВЛвЊгУИИзгЙиЯЕЕФmappingЁЃ
ШчЙћвЛЖЈвЊЪЙгУnested fieldsЃЌБЃжЄnested fieldsзжЖЮВЛФмЙ§ЖрЃЌФПЧАESФЌШЯЯожЦЪЧ50ЁЃВЮПМЃК
index.mapping.nested_fields.limit ЃК50
вђЮЊеыЖд1Иіdocument, УПвЛИіnested field, ЖМЛсЩњГЩвЛИіЖРСЂЕФdocument,
етНЋЪЙDocЪ§СПОчдіЃЌгАЯьВщбЏаЇТЪЃЌгШЦфЪЧJOINЕФаЇТЪЁЃ
БмУтЪЙгУЖЏЬЌжЕзїзжЖЮ(key), ЖЏЬЌЕндіЕФmappingЃЌЛсЕМжТМЏШКБРРЃЃЛЭЌбљЃЌвВашвЊПижЦзжЖЮЕФЪ§СПЃЌвЕЮёжаВЛЪЙгУЕФзжЖЮЃЌОЭВЛвЊЫїв§ЁЃПижЦЫїв§ЕФзжЖЮЪ§СПЁЂmappingЩюЖШЁЂЫїв§зжЖЮЕФРраЭЃЌЖдгкESЕФадФмгХЛЏЪЧжижажЎжиЁЃвдЯТЪЧESЙигкзжЖЮЪ§ЁЂmappingЩюЖШЕФвЛаЉФЌШЯЩшжУЃК
index.mapping.nested_objects.limit :10000 index.mapping.total_fields.limit:1000
index.mapping.depth.limit: 20
ВЛашвЊзіФЃК§МьЫїЕФзжЖЮЪЙгУ keywordРраЭДњЬц text РраЭЁЃ
Ыїв§ЩшжУ
ШчЙћФуЕФЫбЫїНсЙћВЛашвЊНќЪЕЪБЕФзМШЗЖШЃЌПМТЧАбУПИіЫїв§ЕФ index.refresh_interval
ИФЕН 30sЛђепИќДѓЁЃ ШчЙћФуЪЧдкзіДѓХњСПЕМШыЃЌЩшжУ refresh_interval ЮЊ-1ЃЌЭЌЪБЩшжУnumber_of_replicas
ЮЊ0ЃЌЭЈЙ§ЙиБе refresh МфИєжмЦкЃЌЭЌЪБВЛЩшжУИББОРДЬсИпаДадФмЁЃ
ЮФЕЕдкИДжЦЕФЪБКђЃЌећИіЮФЕЕФкШнЖМБЛЗЂЭљИББОНкЕуЃЌШЛКѓж№зжЕФАбЫїв§Й§ГЬжиИДвЛБщЁЃетвтЮЖзХУПИіИББОвВЛсжДааЗжЮіЁЂЫїв§вдМАПЩФмЕФКЯВЂЙ§ГЬЁЃЯрЗДЃЌШчЙћФуЕФЫїв§ЪЧСуИББОЃЌШЛКѓдкаДШыЭъГЩКѓдйПЊЦєИББОЃЌЛжИДЙ§ГЬБОжЪЩЯжЛЪЧвЛИізжНкЕНзжНкЕФЭјТчДЋЪфЁЃЯрБШжиИДЫїв§Й§ГЬЃЌетИіЫуЪЧЯрЕБИпаЇЕФСЫЁЃ
аоИФ index_buffer_size ЕФЩшжУЃЌПЩвдЩшжУГЩАйЗжЪ§ЃЌвВПЩЩшжУГЩОпЬхЕФДѓаЁЃЌзюЖрИј512MЃЌДѓгкетИіжЕЛсДЅЗЂrefreshЁЃФЌШЯжЕЪЧJVMЕФФкДц10%ЃЌЕЋЪЧЪЧЫљгаЧаЦЌЙВЯэДѓаЁЁЃПЩИљОнМЏШКЕФЙцФЃзіВЛЭЌЕФЩшжУВтЪдЁЃ
indices.memory.index_buffer_sizeЃК10%ЃЈФЌШЯЃЉ indices.memory.min_index_buffer_sizeЃК
48mbЃЈФЌШЯЃЉ indices.memory.max_index_buffer_size
аоИФ translog ЯрЙиЕФЩшжУЃК
a. ПижЦЪ§ОнДгФкДцЕНгВХЬЕФВйзїЦЕТЪЃЌвдМѕЩйгВХЬIOЁЃПЩНЋ sync_interval ЕФЪБМфЩшжУДѓвЛаЉЁЃ
index.translog.sync_intervalЃК5s(ФЌШЯ)ЁЃ
b. ПижЦ tranlog Ъ§ОнПщЕФДѓаЁЃЌДяЕН threshold ДѓаЁЪБЃЌВХЛс flush ЕН lucene
Ыїв§ЮФМўЁЃ
index.translog.flush_threshold_sizeЃК512mb(ФЌШЯ)
_idзжЖЮЕФЪЙгУЃЌгІОЁПЩФмБмУтздЖЈвх_id, вдБмУтеыЖдIDЕФАцБОЙмРэЃЛНЈвщЪЙгУESЕФФЌШЯIDЩњГЩВпТдЛђЪЙгУЪ§зжРраЭIDзіЮЊжїМќЃЌАќРЈСуЬюГфађСа
IDЁЂUUID-1 КЭФЩУыЃЛетаЉ ID ЖМЪЧгавЛжТЕФЃЌбЙЫѕСМКУЕФађСаФЃЪНЁЃЯрЗДЕФЃЌЯё UUID-4
етбљЕФ IDЃЌБОжЪЩЯЪЧЫцЛњЕФЃЌбЙЫѕБШКмЕЭЃЌЛсУїЯдЭЯТ§ LuceneЁЃ
_all зжЖЮМА_source зжЖЮЕФЪЙгУЃЌгІИУзЂвтГЁОАКЭашвЊЃЌ_allзжЖЮАќКЌСЫЫљгаЕФЫїв§зжЖЮЃЌЗНБузіШЋЮФМьЫїЃЌШчЙћЮоДЫашЧѓЃЌПЩвдНћгУЃЛ_sourceДцДЂСЫдЪМЕФdocumentФкШнЃЌШчЙћУЛгаЛёШЁдЪМЮФЕЕЪ§ОнЕФашЧѓЃЌПЩЭЈЙ§ЩшжУincludesЁЂexcludes
ЪєадРДЖЈвхЗХШы_sourceЕФзжЖЮЁЃ
КЯРэЕФХфжУЪЙгУindexЪєадЃЌanalyzed КЭnot_analyzedЃЌИљОнвЕЮёашЧѓРДПижЦзжЖЮЪЧЗёЗжДЪЛђВЛЗжДЪЁЃжЛга
groupbyашЧѓЕФзжЖЮЃЌХфжУЪБОЭЩшжУГЩnot_analyzed, вдЬсИпВщбЏЛђОлРрЕФаЇТЪЁЃ
ВщбЏаЇТЪ
ЪЙгУХњСПЧыЧѓЃЌХњСПЫїв§ЕФаЇТЪПЯЖЈБШЕЅЬѕЫїв§ЕФаЇТЪвЊИпЁЃ
query_string Лђ multi_match ЕФВщбЏзжЖЮдНЖрЃЌ ВщбЏдНТ§ЁЃПЩвддк mapping
НзЖЮЃЌРћгУ copy_to ЪєадНЋЖрзжЖЮЕФжЕЫїв§ЕНвЛИіаТзжЖЮЃЌmulti_matchЪБЃЌгУаТЕФзжЖЮВщбЏЁЃ
ШеЦкзжЖЮЕФВщбЏЃЌ гШЦфЪЧгУnow ЕФВщбЏЪЕМЪЩЯЪЧВЛДцдкЛКДцЕФЃЌвђДЫЃЌ ПЩвдДгвЕЮёЕФНЧЖШРДПМТЧЪЧЗёвЛЖЈвЊгУnow,
БЯОЙРћгУ query cache ЪЧФмЙЛДѓДѓЬсИпВщбЏаЇТЪЕФЁЃ
ВщбЏНсЙћМЏЕФДѓаЁВЛФмЫцвтЩшжУГЩДѓЕУРыЦзЕФжЕЃЌ Шчquery.setSizeВЛФмЩшжУГЩ Integer.MAX_VALUEЃЌ
вђЮЊESФкВПашвЊНЈСЂвЛИіЪ§ОнНсЙЙРДЗХжИЖЈДѓаЁЕФНсЙћМЏЪ§ОнЁЃ
ОЁСПБмУтЪЙгУ scriptЃЌЭђВЛЕУвбашвЊЪЙгУЕФЛАЃЌбЁдёpainless & experssions
в§ЧцЁЃвЛЕЉЪЙгУ script ВщбЏЃЌвЛЖЈвЊзЂвтПижЦЗЕЛиЃЌЧЇЭђВЛвЊгаЫРбЛЗЃЈШчЯТДэЮѓЕФР§згЃЉЃЌвђЮЊESУЛгаНХБОдЫааЕФГЌЪБПижЦЃЌжЛвЊЕБЧАЕФНХБОУЛжДааЭъЃЌИУВщбЏЛсвЛжБзшШћЁЃШчЃК
{ ЁАscript_fieldsЁБЃК{ ЁАtest1ЁБЃК{ ЁАlangЁБЃКЁАgroovyЁБЃЌ ЁАscriptЁБЃКЁАwhileЃЈtrueЃЉ{print
'donЁЏt use script'}ЁБ } } }
БмУтВуМЖЙ§ЩюЕФОлКЯВщбЏЃЌ ВуМЖЙ§ЩюЕФgroup by , ЛсЕМжТФкДцЁЂCPUЯћКФЃЌНЈвщдкЗўЮёВуЭЈЙ§ГЬађРДзщзАвЕЮёЃЌвВПЩвдЭЈЙ§pipeline
ЕФЗНЪНРДгХЛЏЁЃ
ИДгУдЄЫїв§Ъ§ОнЗНЪНРДЬсИп AGG адФмЃК
ШчЭЈЙ§ terms aggregations ЬцДњ range aggregationsЃЌ ШчвЊИљОнФъСфРДЗжзщЃЌЗжзщФПБъЪЧ:
ЩйФъЃЈ14ЫъвдЯТЃЉ ЧрФъЃЈ14-28ЃЉ жаФъЃЈ29-50ЃЉ РЯФъЃЈ51вдЩЯЃЉЃЌ ПЩвддкЫїв§ЕФЪБКђЩшжУвЛИіage_groupзжЖЮЃЌдЄЯШНЋЪ§ОнНјааЗжРрЁЃДгЖјВЛгУАДageРДзіrange
aggregations, ЭЈЙ§age_groupзжЖЮОЭПЩвдСЫЁЃ
CacheЕФЩшжУМАЪЙгУЃК
a) QueryCache: ESВщбЏЕФЪБКђЃЌЪЙгУfilterВщбЏЛсЪЙгУquery cache,
ШчЙћвЕЮёГЁОАжаЕФЙ§ТЫВщбЏБШНЯЖрЃЌНЈвщНЋquerycacheЩшжУДѓвЛаЉЃЌвдЬсИпВщбЏЫйЖШЁЃ
indices.queries.cache.sizeЃК 10%ЃЈФЌШЯЃЉЃЌ//ПЩЩшжУГЩАйЗжБШЃЌвВПЩЩшжУГЩОпЬхжЕЃЌШч256mbЁЃ
ЕБШЛвВПЩвдНћгУВщбЏЛКДцЃЈФЌШЯЪЧПЊЦєЃЉЃЌ ЭЈЙ§index.queries.cache.enabledЃКfalseЩшжУЁЃ
b) FieldDataCache: дкОлРрЛђХХађЪБЃЌfield data cacheЛсЪЙгУЦЕЗБЃЌвђДЫЃЌЩшжУзжЖЮЪ§ОнЛКДцЕФДѓаЁЃЌдкОлРрЛђХХађГЁОАНЯЖрЕФЧщаЮЯТКмгаБивЊЃЌПЩЭЈЙ§indices.fielddata.cache.sizeЃК30%
ЛђОпЬхжЕ10GBРДЩшжУЁЃЕЋЪЧШчЙћГЁОАЛђЪ§ОнБфИќБШНЯЦЕЗБЃЌЩшжУcacheВЂВЛЪЧКУЕФзіЗЈЃЌвђЮЊЛКДцМгдиЕФПЊЯњвВЪЧЬиБ№ДѓЕФЁЃ
c) ShardRequestCache: ВщбЏЧыЧѓЗЂЦ№КѓЃЌУПИіЗжЦЌЛсНЋНсЙћЗЕЛиИјаЕїНкЕу(Coordinating
Node), гЩаЕїНкЕуНЋНсЙћећКЯЁЃ
ШчЙћгаашЧѓЃЌПЩвдЩшжУПЊЦє; ЭЈЙ§ЩшжУindex.requests.cache.enable: trueРДПЊЦєЁЃ
ВЛЙ§ЃЌshard request cache жЛЛКДц hits.total, aggregations,
suggestions РраЭЕФЪ§ОнЃЌВЂВЛЛсЛКДцhitsЕФФкШнЁЃвВПЩвдЭЈЙ§ЩшжУindices.requests.cache.size:
1%ЃЈФЌШЯЃЉРДПижЦЛКДцПеМфДѓаЁЁЃ
ESЕФФкДцЩшжУ
гЩгкESЙЙНЈЛљгкlucene, ЖјluceneЩшМЦЧПДѓжЎДІдкгкluceneФмЙЛКмКУЕФРћгУВйзїЯЕЭГФкДцРДЛКДцЫїв§Ъ§ОнЃЌвдЬсЙЉПьЫйЕФВщбЏадФмЁЃluceneЕФЫїв§ЮФМўsegementsЪЧДцДЂдкЕЅЮФМўжаЕФЃЌВЂЧвВЛПЩБфЃЌЖдгкOSРДЫЕЃЌФмЙЛКмгбКУЕиНЋЫїв§ЮФМўБЃГждкcacheжаЃЌвдБуПьЫйЗУЮЪЃЛвђДЫЃЌЮвУЧКмгаБивЊНЋвЛАыЕФЮяРэФкДцСєИјlucene
; СэвЛАыЕФЮяРэФкДцСєИјESЃЈJVM heap )ЁЃЫљвдЃЌ дкESФкДцЩшжУЗНУцЃЌПЩвдзёбвдЯТддђЃК
ЕБЛњЦїФкДцаЁгк64GЪБЃЌзёбЭЈгУЕФддђЃЌ50%ИјESЃЌ50%СєИјluceneЁЃ
ЕБЛњЦїФкДцДѓгк64GЪБЃЌзёбвдЯТддђЃК
a. ШчЙћжївЊЕФЪЙгУГЁОАЪЧШЋЮФМьЫї, ФЧУДНЈвщИјES HeapЗжХф 4~32GЕФФкДцМДПЩЃЛЦфЫќФкДцСєИјВйзїЯЕЭГ,
ЙЉluceneЪЙгУЃЈsegments cache), вдЬсЙЉИќПьЕФВщбЏадФмЁЃ
b. ШчЙћжївЊЕФЪЙгУГЁОАЪЧОлКЯЛђХХађЃЌ ВЂЧвДѓЖрЪ§ЪЧnumerics, dates, geo_points
вдМАnot_analyzedЕФзжЗћРраЭЃЌ НЈвщЗжХфИјES HeapЗжХф 4~32GЕФФкДцМДПЩЃЌЦфЫќФкДцСєИјВйзїЯЕЭГЃЌЙЉluceneЪЙгУ(doc
values cache)ЃЌЬсЙЉПьЫйЕФЛљгкЮФЕЕЕФОлРрЁЂХХађадФмЁЃ
c. ШчЙћЪЙгУГЁОАЪЧОлКЯЛђХХађЃЌВЂЧвЖМЪЧЛљгкanalyzed зжЗћЪ§ОнЃЌетЪБашвЊИќЖрЕФ heap size,
НЈвщЛњЦїЩЯдЫааЖрESЪЕР§ЃЌУПИіЪЕР§БЃГжВЛГЌЙ§50%ЕФES heapЩшжУ(ЕЋВЛГЌЙ§32GЃЌЖбФкДцЩшжУ32GвдЯТЪБЃЌJVMЪЙгУЖдЯѓжИБъбЙЫѕММЧЩНкЪЁПеМф)ЃЌ50%вдЩЯСєИјluceneЁЃ
НћжЙswapЃЌвЛЕЉдЪаэФкДцгыДХХЬЕФНЛЛЛЃЌЛсв§Ц№жТУќЕФадФмЮЪЬтЁЃ ЭЈЙ§ЃК дкelasticsearch.yml
жа bootstrap.memory_lock: trueЃЌ вдБЃГжJVMЫјЖЈФкДцЃЌБЃжЄESЕФадФмЁЃ
ЕїећJVMЩшжУ
ES ЪЧдк lucene ЕФЛљДЁЩЯНјаабаЗЂЕФЃЌвўВиСЫ lucene ЕФИДдгадЃЌЬсЙЉМђЕЅвзгУЕФ RESTful
ApiНгПкЁЃES ЕФЗжЦЌЯрЕБгк lucene ЕФЫїв§ЁЃгЩгк lucene ЪЧ Java гябдПЊЗЂЕФЃЌЪЧ
Java гябдОЭЩцМАЕН JVMЃЌЫљвд ES Дцдк JVMЕФЕїгХЮЪЬтЁЃ
ЕїећФкДцДѓаЁЁЃЕБЦЕЗБГіЯжfull gcКѓПМТЧдіМгФкДцДѓаЁЃЌЕЋЪЧЖбФкДцКЭЖбЭтФкДцВЛвЊГЌЙ§32GЁЃ
ЕїећаДШыЕФЯпГЬЪ§КЭЖгСаДѓаЁЁЃВЛЙ§ЯпГЬЪ§зюДѓВЛФмГЌЙ§33ИіЃЈesПижЦЫРЃЉЁЃ
ESЗЧГЃвРРЕЮФМўЯЕЭГЛКДцЃЌвдБуПьЫйЫбЫїЁЃвЛАуРДЫЕЃЌгІИУжСЩйШЗБЃЮяРэЩЯгавЛАыЕФПЩгУФкДцЗжХфЕНЮФМўЯЕЭГЛКДцЁЃ
GCЩшжУддђЃК
a. БЃГжGCЕФЯжгаЩшжУЃЌФЌШЯЩшжУЮЊЃКConcurrent-Mark and Sweep (CMS)ЃЌБ№ЛЛГЩG1GCЃЌвђЮЊФПЧАG1ЛЙгаКмЖрBUGЁЃ
b. БЃГжЯпГЬГиЕФЯжгаЩшжУЃЌФПЧАESЕФЯпГЬГиНЯ1.XгаСЫНЯЖргХЛЏЩшжУЃЌБЃГжЯжзДМДПЩЃЛФЌШЯЯпГЬГиДѓаЁЕШгкCPUКЫаФЪ§ЁЃШчЙћвЛЖЈвЊИФЃЌАДЙЋЪНЃЈЃЈCPUКЫаФЪ§*
3ЃЉ/ 2ЃЉ+ 1ЩшжУЃЛВЛФмГЌЙ§CPUКЫаФЪ§ЕФ2БЖЃЛЕЋЪЧВЛНЈвщаоИФФЌШЯХфжУЃЌЗёдђЛсЖдCPUдьГЩгВЩЫЁЃ |






