| БрМЭЦМі: |
БОЮФжиЕуНщЩмzeppelinећЬхМмЙЙЗжЮі,InterpreterзщМўвдМАNoteФЃПщжївЊЙІФмЃЌSparkInterpreterЕФЙЄзїдРэЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздГЬађдБДѓБОгЊЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂZeppelinећЬхМмЙЙЗжЮі
ЪзЯШЩЯвЛеХЙйЗНИјГіЕФZeppelinећЬхМмЙЙЭМ
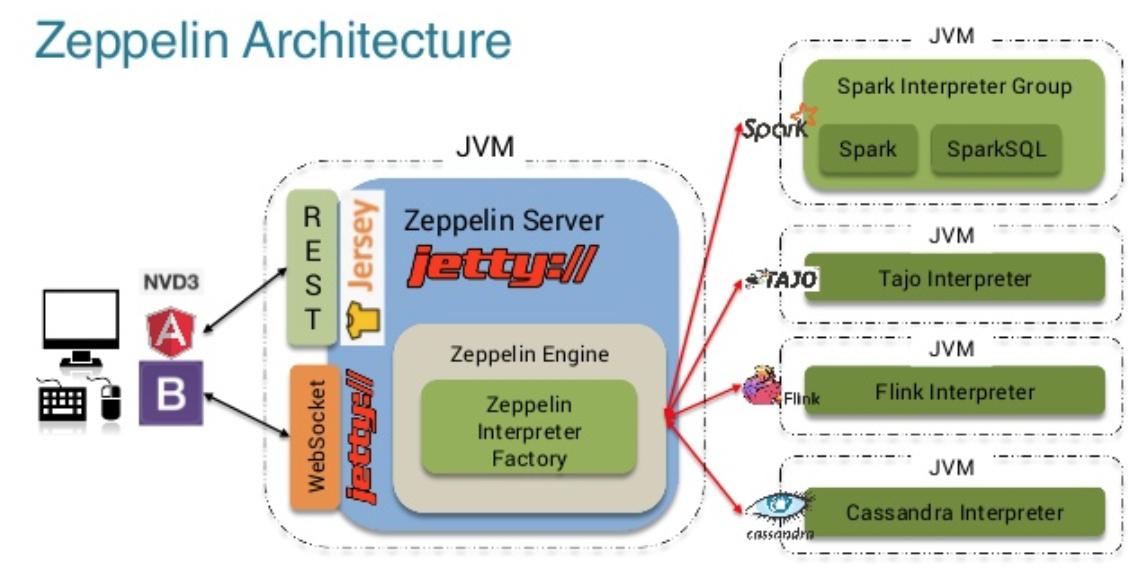
Apache ZeppelinЕФМмЙЙБШНЯМђЕЅжБЙлЃЌзмЙВЗжЮЊ3ВуЃК
1.Zeppelin ЧАЖЫ
2.Zeppelin Server
3.Zeppelin Interpreter
ZeppelinЧАЖЫЪЧЛљгкAngularJSЃЈФПЧАЩчЧје§дкЩ§МЖИФдьЧАЖЫЃЌЕЋЪЧЖдгУЛЇЬхбщВЛЛсгагАЯьЃЉЁЃ
Zeppelin ServerЪЧвЛИіЛљгкJettyЕФЧсСПМЖWeb ServerЃЌжївЊИКд№вдЯТвЛаЉЙІФмЃК
1.ЕЧТНШЈЯоЙмРэ
2.ZeppelinХфжУаХЯЂЙмРэ
3.Interpreter ХфжУаХЯЂКЭЩњУќжмЦкЙмРэ
4.NoteДцДЂЙмРэ
5.ВхМўЛњжЦЙмРэ
ZeppelinЧАЖЫКЭZeppelin ServerжЎМфЕФЭЈаХЛњжЦжївЊгаRest apiКЭWebSocketСНжжЁЃZeppelin
ServerКЭZeppelin InterpreterЪЧЭЈЙ§Thrift RPCРДЭЈаХЃЌЖјЧвЫћУЧБЫДЫжЎМфЪЧЫЋЯђЭЈаХЃЌZeppelin
ServerПЩвдЯђZeppelin InterpreterЗЂЫЭЧыЧѓЃЌZeppelin InterpreterвВПЩвдЯђZeppelin
ServerЗЂЫЭЧыЧѓЁЃ
ЙигкzeppelinВЩгУWebSocketММЪѕЕФБивЊадЮЪЬтЃЌетРявВзівЛЯТМђЕЅЗжЮіЁЃzeppelinЪЧЙВЯэЪНЁЂNotebookЪНЕФДѓЪ§ОнЗжЮіЛЗОГЃЌвдreplЕФЗНЪНжДаавдParagraphЮЊзюаЁСЃЖШЕФДњТыЖЮЁЃ
1. ЪзЯШreplЕФЗНЪНЧПЕїЪЕЪБЗДРЁжДааНсЙћЃЌЬиБ№ЪЧдкДѓЪ§ОнЛЗОГЯТЃЌвЛЖЮДњТыПЩФмашвЊжДааКмГЄЪБМфЃЌдкжДааЕФЙ§ГЬжаЃЌzeppelinЕФгУЛЇЦкЭћПДЕНжДааНјЖШКЭжаМфНсЙћЃЌашвЊдкЧАКѓЖЫжЎМфНЈСЂвЛИіГЄСЌНгЃЌБугкЪЕЪБДЋЕнЪ§ОнЁЃ
2. СэЭтzeppelinЕФСэвЛИіССЕуЪЧЦфНсЙћПЩЪгЛЏФмСІЃЌашвЊдкЧАКѓЬЈДЋЕнЭМЦЌЃЌВЂЧвжЇГжНЯДѓЪ§ОнСПЕФДЋЪфЕФФмСІЃЈЯрЖдДЋЭГhttpММЪѕЃЉЁЃ
3. дйепЃЌгЩгкЪЧЙВЯэЪНЛЗОГЃЌвЛИіNoteПЩФмБЛЖрИігУЛЇЭЌЪБПДЕНЁЂЩѕжСБрМЃЌашвЊдкИїИівбОДђПЊСЫЭЌвЛИіNoteЕФwebПЭЛЇЖЫжЎМфЭЌВНNoteЕФДњТыЁЂжДааНсЙћКЭНјЖШаХЯЂЁЃ
ЛљгквдЩЯ3ЕуЃЌzeppelinВЩгУWebSocketММЪѕЪЧЫЎЕНЧўГЩЕФЪТЧщЁЃ
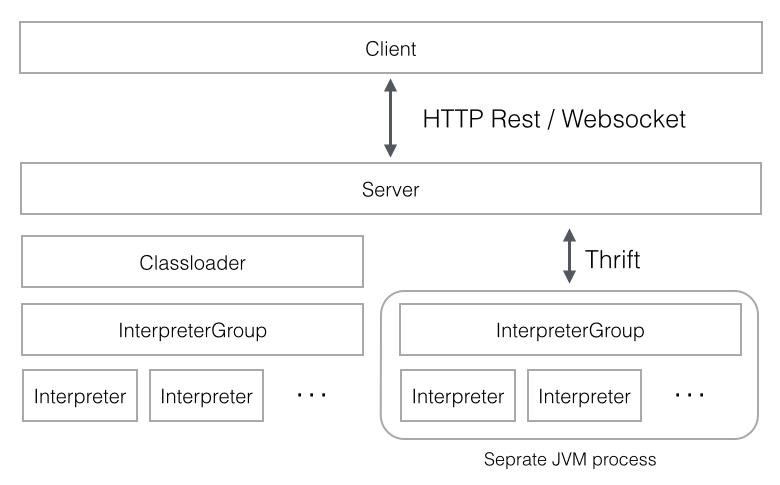
ЩЯЭМЪЧzeppelinЕФЧАКѓЬЈНЛЛЅФЃаЭЃЌzeppelinВЩгУЕЅЖРЕФjvmРДЦєЖЏinterpreterНјГЬЃЌИУInterpreterНјГЬгыzeppelinServerНјГЬжЎМфВЩгУThriftавщЭЈаХЃЌЦфжаRemoteInterpreterProcessЪЧThrift-ClientЖЫЃЌЖјЯргІЕФRemoteInterpreterServerЪЧThrift-ServerЖЫЁЃУПвЛИіInterpreterЖМЪєгкЛЛвЛИіInterpreterGroupЃЌЭЌвЛИіInterpreterGroupЕФInterpretersПЩвдЯрЛЅв§гУЃЌР§ШчSparkSqlInterpreter
ПЩвдв§гУ SparkInterpreter вдЛёШЁ SparkContextЃЌвђЮЊЫћУЧЪєгкЭЌвЛИіInterpreterGroupЁЃЕБЧАвбОЪЕЯжЕФInterpreterгаsparkНтЪЭЦїЃЌpythonНтЪЭЦїЃЌSparkSQLНтЪЭЦї,JDBCЃЌMarkdownКЭshellЕШЁЃ
ЖўЁЂZeppelin-interpreter
2.1ЁЂInterpreterИХФю
InterpreterзщМўЪЧжИИїИіМЦЫув§ЧцдкZeppelinетБпЕФЪЪХфЁЃБШШчPythonЃЌSparkЃЌFlinkЕШЕШЁЃУПИіInterpreterЖМrunдквЛИіJVMНјГЬРяЃЌетИіJVMНјГЬПЩвдЪЧКЭZeppelin
ServerдкЭЌвЛЬЈЛњЦїЩЯЃЈФЌШЯЗНЪНЃЉЃЌвВПЩвдrunдкZeppelinМЏШКРяЕФЦфЫћШЮКЮЛњЦїЩЯЛђепK8sМЏШКЕФвЛИіPodРяЃЌетИігЩZeppelinЕФВЛЭЌInterpreterLauncherВхМўРДЪЕЯжЁЃInterpreterLauncherЪЧZeppelinЕФвЛжжВхМўРраЭЁЃ
InterpreterжЇГжЖЏЬЌМгдиmavenИёЪНвРРЕАќЕФФмСІЃЌЖрJVMИєРыruntimeвРРЕЁЃThrift-BasedПчгябдIPC(Inter-Process-Communication)ЛњжЦЃЈЙцЖЈreplНтЪЭЦїМЏГЩКЭЦНЬЈжЎМфЕФЪ§ОнНЛЛЛЕФИёЪНКЭЪБађЃЉЁЃГщЯѓГіreplНтЪЭЦїЩњУќжмЦкЙмРэНгПкЃЌИїreplНтЪЭЦїЪмzeppelinServerЖЫПижЦЁЃ
УПвЛИіInterpreterЖМгавЛИіЖдгІЕФSchedulerЪЕР§ЃЌSchedulerНЋJobЕФЬсНЛгыжДааБфГЩСЫвЛИівьВНЕФЙ§ГЬЃЌМДJobдкSchedulerДІНјШыЖгСаЕШД§ЬсНЛЃЌгУЛЇПЩвдЖЈЦкЪеЕНJobжДааЯрЙиЕФаХЯЂЁЃZeppelinФкВПгаШ§жжSchedulerЃК
1.FIFOScheduler: ЪЪгУгкParagraphжЛФмЫГађжДааЕФInterpreterЃЌШчSparkInterpreter,
ShellInterpreterЕШЁЃ
2.ParallelScheduler: ЪЪгУгкParagraphПЩВЂаажДааЕФInterpreterЃЌШчSparkSqlInterpreter,
MarkdownInterpreterЕШЁЃ
3.RemoteScheduler: гыRemoteInterpreterProcessХфКЯЪЙгУЕФЃЌRemoteInterpreterProcessвдЖРСЂЕФНјГЬЦєЖЏInterpreterЃЌЦфФкВПЭЌбљдЫааСЫЕїЖШЦїЃЌгЩгкzeppelinServerдЫаадкжїНјГЬжаЃЌгыдЖГЬInterpreterНјГЬЃЈЭЈЙ§RemoteInterpreterServerЦєЖЏЕФjvmЃЌзЂвтЃКВЛЪЧдЫааInterpreterProcessРрЫљдкЕФНјГЬЃЌInterpreterProcessШдШЛдЫаадкгыZeppelinServerЯрЭЌЕФжїНјГЬжаЃЉВЛдкЭЌвЛИіНјГЬЁЃRemoteSchedulerЕФзїгУОЭзїЮЊдЫаадкдЖГЬInterpreterНјГЬЕФдЖГЬДњРэЃЌRemoteSchedulerгыZeppelinServerдЫаадкЭЌвЛИіJVMНјГЬжаЃЌИКд№ЯђZeppelinServerЬсЙЉдЖГЬInterpreterНјГЬжаЕїЖШЦїЕФФкВПдЫааЧщПіЁЃ
ЙигкЮЊЪВУДвЊВЩгУЕЅЖРЕФJVMНјГЬРДЦєЖЏreplНтЪЭЦїЃЌдвђгавдЯТСНЕуЃК
1.zeppelinжМдкЬсЙЉвЛИіПЊЗХЕФПђМмЃЌжЇГжЖржжгябдКЭВњЦЗЃЌгЩгкУПжжгябдКЭВњЦЗЖМЪЧИїздЖРСЂбнНјЕФЃЌИїздЕФдЫааЪБвРРЕвВИїВЛЯрЭЌЃЌЩѕжСЪЧЯрЛЅГхЭЛЕФЃЌШчЙћЗХдкЭЌвЛJVMжаЃЌНіНтОіГхЭЛЃЌЮЌЛЄИїИіВњЦЗжЎМфЕФМцШнадЖМЪЧвЛЯюМшОоЕФШЮЮёЃЌФГаЉВњЦЗАцБОЩѕжСЪЧЭъШЋВЛФмМцШнЕФЁЃ
2.ДѓЪ§ОнЗжЮіЃЌЪЧЗёОпгаКсЯђРЉеЙФмСІЪЧproduction-readyвЛЯюживЊЕФКтСПжИБъЃЌШчЙћНЋreplНјГЬгыжїНјГЬКЯдквЛЦ№ЃЌЛсбщжЄгАЯьЯЕЭГадФмЁЃ
вђДЫЃЌдкгаБивЊЕФЪБКђЃЌzeppelinВЩгУЖРСЂJVMЕФЗНЪНРДЦєЖЏreplНјГЬЃЌВЂЧвВЩгУThriftавщЖЈвхСЫжїНјГЬZeppelinServiceгыRemoteInterpreterServiceНјГЬЃЈНтЪЭЦїНјГЬЃЉжЎМфЕФЭЈаХавщЁЃ
2.2ЁЂInterpreterФЃПщЦфЫћВПЗжИХФю
InterpreterFactoryЃКЮЌЛЄЫљгаInterpreterЕФХфжУаХЯЂВЂДцДЂдкinterpreter.jsonЮФМўжаЃЌВЂЙмРэЫљгаЕФInterpreter
InterpreterGroupЃКвЛИіInterpreterGroupжаАќКЌЖрИіInterpreterЃЌЭЌзщФкЕФInterperterЙВЯэЯрЭЌЕФХфжУаХЯЂЃЌР§ШчSparkКЭSparkSQL
interpreterдквЛИіInterpreterGroupФкЁЃ
InterpreterSettingЃКвЛИіInterpreterGroupЛсгавЛИіInterpreterSettingЃЌЦфжаАќКЌзХЯргІЕФХфжУаХЯЂЃЌР§ШчSpark
MasterЁЃ
ЫљгаЕФInterpreterSettingЖМБЛГжОУЛЏдкInterpreter.jsonЮФМўРяЁЃгУгкЮЌЛЄNoteгыInterpreterGroupжБНгЕФАѓЖЈЙиЯЕЃЌМДУПЦЊNoteПЩвдАѓЖЈВЛЭЌЕФInterpreterGroup.
InterpreterContextЃКгУгкДцДЂParagraphЯрЙиЕФаХЯЂЃЌInterpreterдкОпЬхНтЮіжДааParagraphЪБЛсгУЕНInterpreterContextЁЃ
InterpreterResultЃКгУгкДцДЂJobЕФзДЬЌаХЯЂвдМАжДааНсЙћЃЌОпЬхАќРЈЃК
зДЬЌТыЃКSUCCESSЃЌINCOMPLETEЃЌERRORЃЌKEEP_PREVIOUS_RESULT
РраЭЃКTextЃЈDefaultЃЉЃЌTableЃЌHtmlЃЌAngularЕШ
ФкШнЃКзжЗћДЎЪ§зщ
Ш§ЁЂZeppelin-Note
3.1ЁЂNoteФЃПщИХФю
NotebookВПЗжгавЛаЉживЊЕФИХФюЪЧашвЊРэНтЕФЃК
Notebook ServerЃКгУгкНЈСЂВЂЮЌЛЄЧАЖЫЭјвГгыКѓЖЫЗўЮёЦїжЎМфЕФWebsocketСЌНгЃЛЫќЦфЪЕЪЧвЛИіjob
listenerЃЌНгЪеВЂДІРэЧАЖЫЭјвГЗЂРДЕФNoteжДааЧыЧѓЃЌдкКѓЖЫЩњГЩВЂжДааЯргІЕФjobЃЌВЂНЋjobжДааЕФзДЬЌаХЯЂЙуВЅЕНЫљгаЕФЧАЖЫвГУцЁЃ
MessageЃКMessageРрЪЧЧАЖЫЭјвГгыКѓЖЫNotebook ServerжЎМфЕФЭЈаХавщЃЌДЋЪфдкWebsocketЩЯЃЌжївЊгУгкУшЪіNoteжДааЯрЙиЕФаХЯЂЁЃ
NotebookЃЌNoteЃЌParagraphЃЌJobЃК
NotebookЃКZeppelinШЯЮЊећИідЫааЪЕР§ЪЧвЛИіNotebookЃЌЦфжаПЩвдгУКмЖрЦЊNoteЁЃ
NoteЃКУПвЛЦЊNoteОЭЪЧвЛИіОпЬхЕФвГУцЃЌЦфжаПЩвдгаКмЖрИіParagraphЃЌОЭЪЧДњТыЖЮТфЁЃ
ParagraphЃКУПвЛИіParagraphОЭЪЧвЛИіДњТыЖЮТфЃЌвђДЫParagraphЪЧвЛИіПЩжДааЕЅдЊЃЌЕШЭЌгквЛИіJobЁЃ
JobЃКJobЪЧZeppelinКѓЖЫЕїЖШКЭжДааЕФЕЅЮЛЃЌЛсдкОпЬхЕФInterpreterЩЯдЫааЁЃ
3.2ЁЂNoteФЃПщжївЊЙІФм
NoteЪЧЕЅИіЁЏМЧЪТБОЁЏЕФФкДцЖдЯѓЃЌЪЧzeppelinЙмРэЕФзюаЁЕЅЮЛЃЌЮоТлЪЧзіШЈЯоПижЦЁЂЙВЯэЁЂЛЙЪЧГжОУЛЏЃЌЖМЪЧвдNoteЮЊСЃЖШЕФЁЃДгРрЙиЯЕЩЯПДЃЌNoteЪЧгЩвЛаЉСаЕФгаађParagraphзщГЩЃЌвђДЫЦфОјДѓВПЗжжАд№ЖМЪЧгыЙмРэParagraphгаЙиЃК
1. ParagraphЕФCRUDЁЂЯрЖдЫГађПижЦ
2. гыДІРэЧАКѓЖЫЪ§ОнЫЋЯђЭЦЫЭЕФAngularObjectЕФЙмРэ
3. ећЬхКЭЕЅИіParagraph жДааЃЌвдМАжДааЙ§ГЬЕФЛљгкObserverФЃЪНЕФжДааЙ§ГЬHook
4. NoteЛљБОЕФбљЪНЭтЙлПижЦ
ЮЊСЫЁАЗжРыЙизЂЕуЁБЃЌЦфЫћЕФЙІФмЃЌШчЃК
1. NoteЯрЙиЕФInterpreterМгдиКЭГѕЪМЛЏ
2. ГжОУЛЏгыЗДГжОУЛЏЃЌАќРЈбгГйГжОУЛЏ
3. ШЈЯоПижЦ
ЫФЁЂZeppelin-paragraph
ParagraphДњБэзХвЛЖЮДњТывдМАжЇГХЦфжДааЫљашвЊЕФЁАЛЗОГаХЯЂЁБЃЌЪЧДњТыжДааЕФзюаЁЕЅЮЛЁЃParagraphЕФжАд№ШчЯТЃК
1. ЛёШЁДњТыЮФБОЃЌВЂНтЮіЗжРыРрЫЦ%sparkЕФinterpreterЩљУїЖЮКЭПЩжДааДњТыЖЮЁЃ
2. ДњТыжДааЃЌвдМАжДааЙ§ГЬПижЦЃЈНјЖШКЭжежЙЃЉ
3. ДњТыжДааНсЙћЛёШЁ
4. ДњТыжаБфСПВщеввдМАЬцЛЛ
ЮхЁЂвЛДЮQueryЕФжДааЙ§ГЬ
вдSparkInterpreterОйР§
SparkInterpreterЕФЙЄзїдРэШчЯТЃК
1.ФкВПЛљгкSparkILoopвдМАSparkIMainЪЕЯжЃЌЙІФмРрЫЦгкSpark-ShellЃЌМДж№ааЕФНтЮіДњТыЁЃ
2.гУzeppelin-<Interpreter hash
code>-<Paragraph Id>зїЮЊSparkжаЕФJob Group IdЃЌНјЖјгУJob
Group IdРДДгSparkContextжаЛёШЁжДааНјЖШаХЯЂЁЃ
3.НЋSparkInterpreterНјГЬФкДДНЈЕФSparkContextАѓЖЈЕНSparkIMainРяУцЃЌНјЖјдЄЖЈвхвЛаЉЛЗОГХфжУвдМАгяЗЈЬЧЃЌР§ШчZepplinContextЁЃ
4.гУByteArrayOutputStreamРДВЖЛёSparkIMainЕФЪфГіЃЌВЂзЊЛЏЮЊПЩЯдЪОЕФЪфГіНсЙћЁЃ
SparkSqlInterpreterЕФЙЄзїдРэШчЯТЃК
1.дЫаадкSparkInterpreterжЎЩЯЃЌМДдкSparkInterpreterжадЫааSqlContextЛђепHiveContest
2.SparkSqlInterpreterЕФжДааНсЙћЖМЛсвдTableЕФРраЭЗЕЛиИјЧАЖЫЃЌвђДЫЧАЖЫвГУцЛсгУЯргІЕФAngular
JSДњТыНЋНсЙћГЪЯжЮЊЭМБэЁЃ |









