| БрМЭЦМі: |
БОЮФжиЕуНщЩмШчКЮЪЕЯжApache
ZeppelinдкTrafodionЩЯЕФПЩЪгЛЏ,ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
НщЩм
Apache TrafodionКЭEsgynDBЃЈEsgynЕФЩЬвЕАцЃЉжЇГжЪ§ОнПЩЪгЛЏЙЄОпЃЈР§ШчЃЌApache
ZeppelinКЭTableauЃЉЃЌОпгаБъзМJDBC/ODBCСЌНгЁЃБОЮФжиЕуНщЩмШчКЮЪЕЯжApache
ZeppelinдкTrafodionЩЯЕФПЩЪгЛЏЁЃ
Apache ZeppelinЛљгкwebЃЌЪ§ОнзЈМвПЩвдЭЈЙ§ИУЙЄОпНјааДѓЙцФЃЪ§ОнЭкОђКЭПЩЪгЛЏЕФазїЁЃДѓЙцФЃЪ§ОнЗжЮіЕФЙЄзїСїАќРЈЖрИіВНжшЃЌР§ШчЪ§ОнЛёШЁЁЂдЄДІРэЁЂПЩЪгЛЏЁЁЁЃЭЈЙ§ZeppelinЃЌгУЛЇПЩвддкВЛЭЌЕФжДааПщ/ЖЮжаДДНЈетаЉВНжшЁЃетвЛЬзВНжш/ЙЄзїСїГЦЮЊNotebookЁЃИїЖЮгЩНтЪЭЦїНјааДІРэЁЃZeppelinОпгаМИИіФЌШЯЕФНтЪЭЦїЁЃЮвУЧПЩвдЪЙгУshellНтЪЭЦїЁЂPostgreSQLНтЪЭЦїЛђJDBCНтЪЭЦїЪЕЯжTrafodionЛђEsgynDBгыZepplinЕФМЏГЩЁЃ
МмЙЙ
Zeppelin UIЃЈПЭЛЇЖЫЃЉСЌНгЕНZeppelin ServerЃЌШЛКѓгывЛИіЛђЖрИіНтЪЭЦїНјааНЛЛЅЃЌвджДааЖЮТфжаЕФУќСюЁЃ
ЖдгкTrafodion/EsgynDBМЏГЩЃЌЮвУЧПЩвдЪЙгУJDBCНтЪЭЦїЛђPostgresНтЪЭЦїдЫааSQLУќСюЃЌЪЙгУshellНтЪЭЦїдкTrafodion/EsgynDBЪЕР§ЩЯдЫааshellУќСюЁЃ
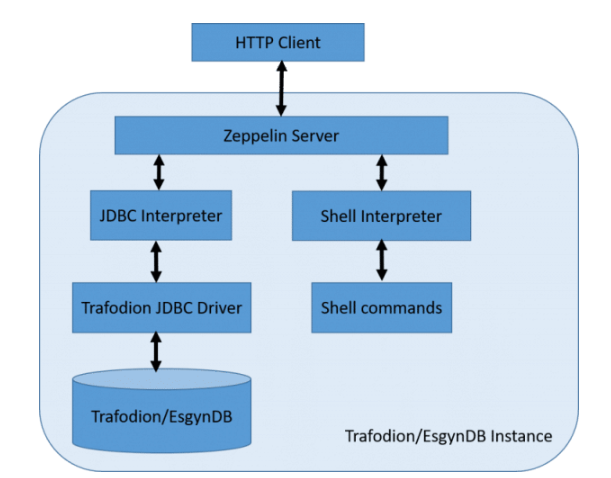
ЮЊTrafodion/EsgynDBХфжУZeppelin
1.НЋTrafodion T4 JDBCЧ§ЖЏЦїЃЈjdbcT4.jarЃЉИДжЦЕНZeppelinАВзАЮФМўМаЯТЕФlibФПТМЁЃ
2.НЋjdbcT4.jarЕФЫљгаШЈИќИФЮЊzeppelinЕФгУЛЇidЁЃЪЙгУHDP/AmbariЪБЃЌЛсЕЅЖРДДНЈвЛИіZeppelinгУЛЇidЁЃдкФњЕФЯЕЭГЩЯЃЌМьВщzeppelin
libЮФМўМажаЦфЫћjarЮФМўЕФЫљгаШЈЃЌНЋетаЉЫљгаШЈЩшжУЮЊгыjdbcT4.jarЯрЭЌЁЃ
3.жиЦєZeppelinЁЃШчЙћФњЪЙгУAmbariАВзАZeppelinЃЌдђПЩвдЪЙгУAmbari WebПижЦЬЈНјаажиЦєЁЃ
4.ДђПЊфЏРРЦїЃЌЕЧТМhttp://myhost:9995ЁЃдкФЌШЯЧщПіЯТЃЌZeppelinдк9995ЖЫПкЩЯдЫааЁЃВщПДФњЕФAmbariХфжУЃЌСЫНтЯъЯИаХЯЂЁЃ
5.ФњгІИУПЩвдПДЕНЛЖгвГУцЃЌзДЬЌгІЯдЪОЮЊвбСЌНгЁЃ

6.ЪзЯШЃЌХфжУJDBCНтЪЭЦїЃЌСЌНгЕНTrafodion/EsgynDBЁЃЕЅЛїВЫЕЅжаЕФInterpreterЁЃ
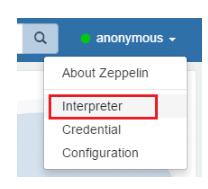
7.ЕЅЛїCreateЁЃ
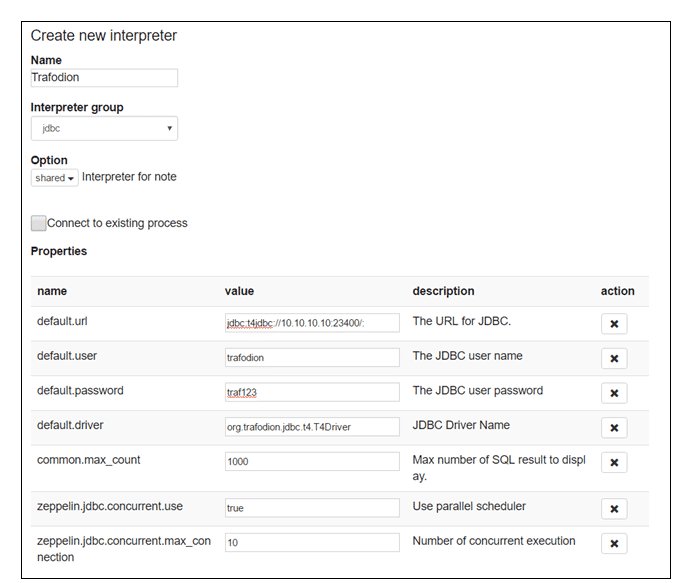
8.ИљОнЯдЪОЕФФкШнЃЌЬюаДЯъЯИаХЯЂЁЃЕЅЛїSaveЃЌДДНЈНтЪЭЦїЁЃ
1) ЪфШыФњНтЪЭЦїЕФУћГЦЁЃ
2) дкНтЪЭЦїЕФЯТРВЫЕЅжаЃЌбЁдёJDBCЁЃ
3) ЬюаДTrafodion JDBCЧ§ЖЏЦїЕФЯъЯИаХЯЂЃЌжИЖЈгыФњTrafodionЪЕР§ЦЅХфЕФJDBC
URLЁЃ
default.driver org.trafodion.jdbc.t4.T4Driver
default.url jdbc:t4jdbc://myhost:23400/:
default.user trafodion
default.password traf123
9.ЭЈЙ§Notebook -> Create new noteВЫЕЅЃЌДДНЈвЛИіаТЕФnotebookЁЃ
10.бЁдёаТДДНЈЕФnotebookЁЃ
11.ЕЅЛїnotebookгвЩЯНЧЕФInterpreter BindingЭМБъЁЃ
12.бЁдёФњЬэМгЕФаТTrafodionНтЪЭЦїЃЌЭЯЖЏЕННтЪЭЦїСаБэЕФЖЅВПЃЌЕЅЛїSaveЁЃ
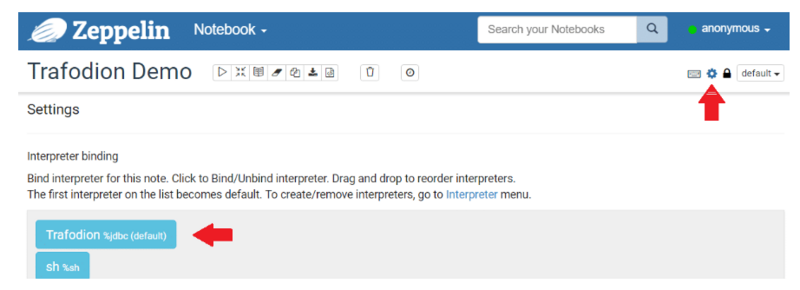
13.ЪфШывЛИіsqlУќСюЃЈР§ШчЃЌget schemasЃЉЃЌЕЅЛїRunЁЃФњгІИУПЩвдПДМћФњЕФTrafodion/EsgynDBЪ§ОнПтЫљгаПЩгУЕФschemaСаБэЁЃ
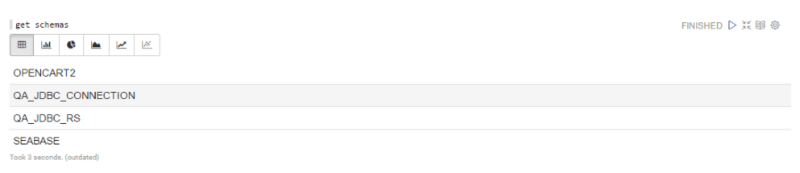
14.ШчЙћжДааЪЇАмЃЌГіЯжСЌНгДэЮѓЛђЬзНгзжДэЮѓЃК
ВщПДHBaseКЭTrafodion/EsgynDBЪЧЗёе§ГЃЦєЖЏВЂдЫааЁЃ
ВщПДгУЛЇУћКЭУмТыЪЧЗёе§ШЗЁЃ
ШчЙћНтЪЭЦїГЌЪБвЛЖЮЪБМфЃЌПЩФмГіЯжЬзНгзжСЌНгДэЮѓЁЃжиЦєНтЪЭЦїЃЌаоИДИУДэЮѓЁЃ
15.ШчЙћвРШЛДцдквьГЃЃЌФњПЩвдМьВщzeppelilnЕФlogЮФМўМажаЕФzeppelin serverКЭjdbcНтЪЭЦїЕФШежОЯћЯЂЁЃ
зЂвтЃК
дкФЌШЯЧщПіЯТЃЌШчЙћУЛгажДааВщбЏЃЈЛђZeppelin UIЯажУЃЉЃЌНтЪЭЦїЛсЙиБегыЪ§ОнПтЕФСЌНгЁЃдйДЮдЫ
ааВщбЏжЎЧАЃЌЧыжиЦєНтЪЭЦїЁЃ
ЪОР§DDL/ЛёШЁ/БЈИцЙЄзїСї
ФњПЩвдЪЙгУвЛЯЕСаЖЮТфЃЌдкZeppelinжаДДНЈЙЄзїСїЃЌУПИіЖЮТфЗжБ№ИКд№жДааФњЙЄзїСїжаЕФвЛИіВНжшЁЃЯТР§ЪЙгУSQL
DDLгяОфДДНЈвЛИіаТБэЃЌШЛКѓМгдиЪ§ОнЃЌзюКѓдЫаавЛИівбМгдиЪ§ОнЕФБЈИцЁЃетаЉВНжшЗжБ№ЪЙгУnotebookжаЕФВЛЭЌЖЮТфЁЃ
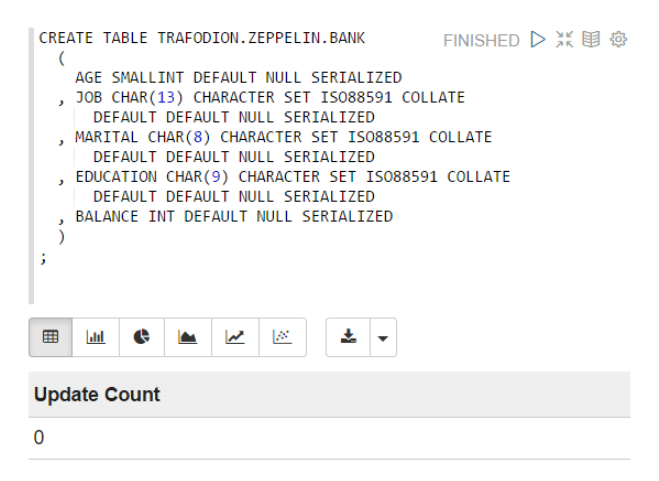
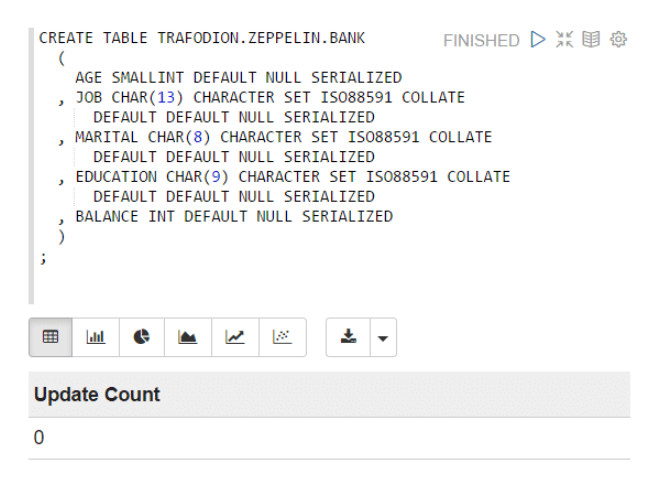
1.ДДНЈФПБъTrafodionБэЁЃ
ЪЙгУJDBCНтЪЭЦїдЫааCREATE DDLгяОфЁЃ
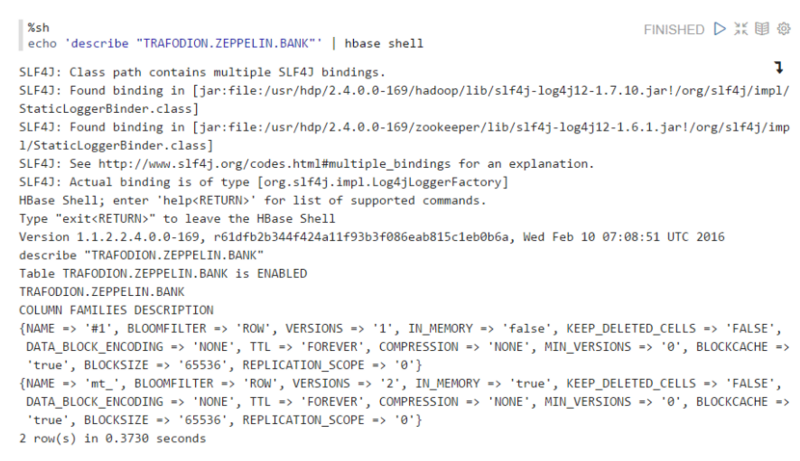
2.ЪЙгУHBase ShellУќСюЃЌВщПДБэЕФHBaseЪєадЁЃ
ЪЙгУshellНтЪЭЦїЃЌдЫааhbase shellУќСюЁЃ
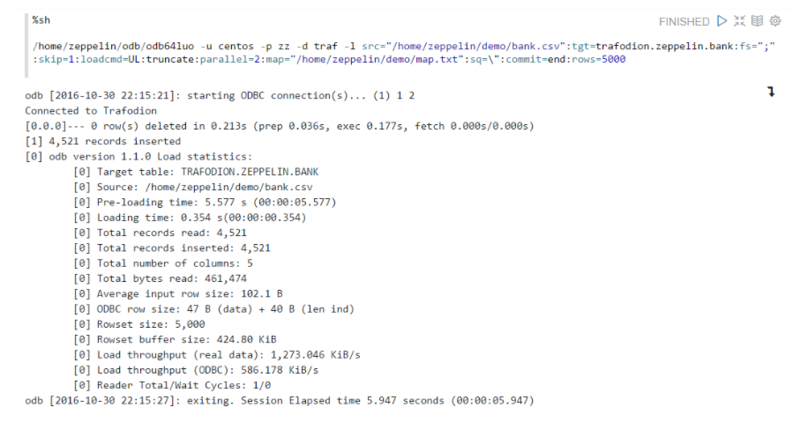
3.ЪЙгУODBКЭCSVЮФМўЃЌНЋЪ§ОнМгдиЕНБэЁЃ
ЪЙгУshellНтЪЭЦїЃЌдкEsgynDBЪЕР§ЩЯдЫааODBЙЄОпЁЃ
4.дЫаавбМгдиЪ§ОнЕФБЈИцЁЃ
ЪЙгУJDBCНтЪЭЦїЃЌдЫааSQLВщбЏЁЃ
|









