| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫZeppelinЪЧЪВУДЃЌZeppelinдкЛњЦїбЇЯАСьгђЕФгІгУЃЌZeppelinЕФаТЬиадЕШЯрЙиФкШнЁЃ
БОЮФРДздЮЂаХHadoopЪЕВйЃЈgh_c4c535955d0fЃЉЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
дкЪ§зжЛЏЁЂжЧФмЛЏЕФЪБДњЃЌЭЈЙ§ЛњЦїбЇЯАЃЈMachine LearningЃЉФмЙЛЧПгаСІЕФВЙГф
Hadoop ДѓЪ§ОнЯЕЭГЕФЪ§ОнДІРэФмСІЃЌГфЗжЭкОђДѓЪ§ОнЕФКЫаФМлжЕЃЌвЛПюКУЕФЫуЗЈПЊЗЂЦНЬЈФмЙЛШУЦѓвЕЪТАыЙІБЖЃЌПьЫйЕФНјааЫуЗЈЪЕбщКЭЩњВњЪЙгУЃЌApache
Zeppelin ОЭЪЧетбљвЛИіМцОпСЫ Hadoop ДѓЪ§ОнДІРэКЭ ЛњЦїбЇЯАЃЏЩюЖШбЇЯАЫуЗЈНЛЛЅЪНПЊЗЂЕФПЊдДЯЕЭГЁЃ
Apache Zeppelin ЪЧвЛИіПЩвдНјааДѓЪ§ОнПЩЪгЛЏЗжЮіЕФНЛЛЅЪНПЊЗЂЯЕЭГЃЌдк Zeppelin
жаЛЙПЩвдЭъГЩЛњЦїбЇЯАЕФЪ§ОндЄДІРэЁЂЫуЗЈПЊЗЂКЭЕїЪдЁЂЫуЗЈзївЕЕїЖШЕФЙЄзїЃЌЭЌЪБЃЌZeppelin ЛЙЬсЙЉСЫЕЅЛњ
DockerЁЂЗжВМЪНЁЂK8sЁЂYarn ЫФжжЯЕЭГдЫааФЃЪНЃЌвдЪЪгІИїРрЭХЖгЕФашЧѓЁЃБОЮФжївЊДгзїепЙЄзїОбщГіЗЂЃЌзмНс
Zeppelin ЕФЯрЙиЪЕМљОбщЁЃ
1 ГѕЪЖZeppelin
Apache Zeppelin ЪЧвЛИіПЩвдНјааДѓЪ§ОнПЩЪгЛЏЗжЮіЕФНЛЛЅЪНПЊЗЂЯЕЭГЃЌПЩвдГаЕЃЪ§ОнНгШыЁЂЪ§ОнЗЂЯжЁЂЪ§ОнЗжЮіЁЂЪ§ОнПЩЪгЛЏЁЂЪ§ОназїЕШШЮЮёЃЌЦфЧАЖЫЬсЙЉЗсИЛЕФПЩЪгЛЏЭМаЮПтЃЌВЛЯогкSparkSQLЃЌКѓЖЫжЇГжHBaseЁЂFlink
ЕШДѓЪ§ОнЯЕЭГвдВхМўРЉеЙЕФЗНЪНЃЌВЂжЇГжSparkЁЂPythonЁЂJDBCЁЂMarkdownЁЂShell
ЕШИїжжГЃгУInterpreterЃЌетЪЙЕУПЊЗЂепПЩвдЗНБуЕиЪЙгУSQL дк Zeppelin жазіЪ§ОнПЊЗЂЁЃ
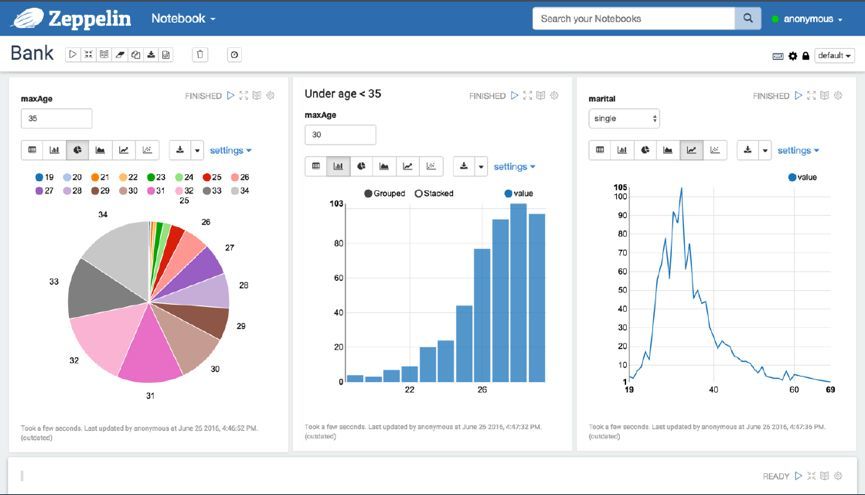
ЖдгкЛњЦїбЇЯАЫуЗЈЙЄГЬЪІРДЫЕЃЌЫћУЧПЩвддк Zeppelin жаПЩвдЭъГЩЛњЦїбЇЯАЕФЪ§ОндЄДІРэЁЂЫуЗЈПЊЗЂКЭЕїЪдЁЂЫуЗЈзївЕЕїЖШЕФЙЄзїЃЌАќРЈЕБЧАдкИїРрШЮЮёжаБэЯжЭЛГіЕФЩюЖШбЇЯАЫуЗЈЃЌвђЮЊ
Zeppelin ЕФзюаТЕФАцБОжадіМгСЫЖдTensorFlowЁЂPyTorch ЕШжїСїЩюЖШбЇЯАПђМмЕФжЇГжЃЌДЫЭтЃЌZeppelinНЋРДЛЙЛсЬсЙЉЫуЗЈЕФФЃаЭ
Serving ЗўЮёЁЂWorkflow ЙЄзїСїБрХХЕШаТЬиадЃЌЪЙЕУ ZeppelinПЩвдЭъШЋИВИЧЛњЦїбЇЯАЕФШЋСїГЬЙЄзїЁЃ
ЖјдкЦНЬЈВПЪ№КЭдЫЮЌЗНУцЃЌZeppelinЛЙЬсЙЉСЫЕЅЛњ DockerЁЂЗжВМЪНЁЂK8sЁЂYarn ЫФжжЯЕЭГдЫааФЃЪНЃЌЮоТлФуЪЧаЁЙцФЃЕФПЊЗЂЭХЖгЃЌЛЙЪЧ
Hadoop ММЪѕеЛЕФДѓЪ§ОнЭХЖгЁЂK8s ММЪѕеЛЕФдЦМЦЫуЭХЖгЃЌZeppelin ЖМПЩвдШУЪ§ОнПЦбЇЭХЖгЧсЫЩЕФНјааВПЪ№КЭЪЙгУ
ZeppelinЗсИЛЕФЪ§ОнКЭЫуЗЈЕФПЊЗЂФмСІЁЃ
2 ZeppelinдкЛњЦїбЇЯАСьгђЕФгІгУ
Zeppelin ећЬхМмЙЙШчЭМЫљЪОЃЌЕзВуЛљДЁЩшЪЉжЇГжHDFSЁЂS3ЁЂDockerЁЂCPUЁЂGPU
ЕШЃЛЗжВМЪНзЪдДЙмРэжЇГжKubernetesЁЂYARN КЭZeppelin ЮяРэМЏШКЕФдЫааФЃЪНЃЌЗжБ№ЖдгІИїжжГЁОАЕФВЛЭЌашЧѓЃЛМЦЫув§ЧцВужЇГжЃЌжЇГжTensorFlowЁЂPyTorch
ЩюЖШбЇЯАПЊЗЂМАPythonЁЂRЁЂScala ДЋЭГЫуЗЈПЊЗЂЃЌПЩНгШыДѓЪ§ОнЕФХњДІРэ/СїМЦЫуПђМмЃЛзюЩЯУцЕФНЛЛЅПЊЗЂВужЇГжЭЈЙ§ПЩЪгЛЏЕФЗНЪНЪЙгУДѓЪ§Онв§ЧцКЭПЊЗЂИїжжЫуЗЈЁЃ
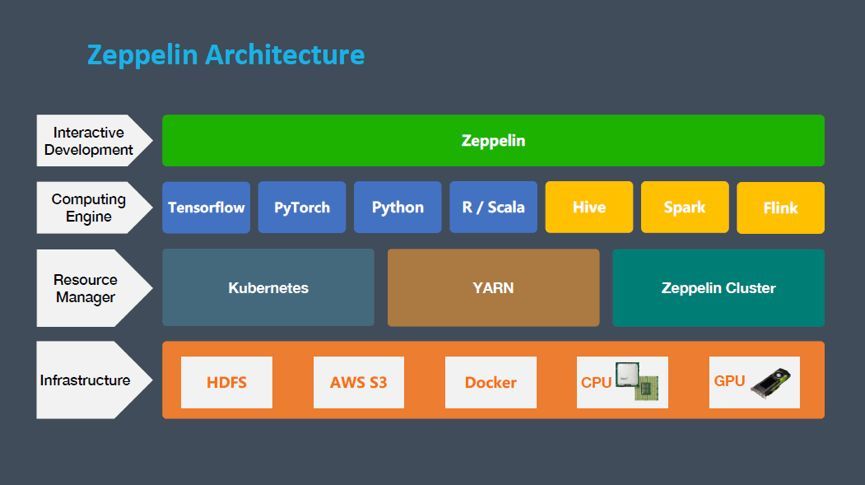
ЖдгкЛњЦїбЇЯАШЮЮёЃЌзюКЫаФЕФЮугЙжУвЩЪЧ ML ПтЃЌШЛЖјДгећИіЛњЦїбЇЯАЦНЬЈДІРэСїГЬРДПДЃЌML ПтЫљеМЕФБШжиЦфЪЕВЛДѓЃЌЦфгрЕФВПЗжЃЌАќРЈХфжУЁЂЪ§ОнЪеМЏЁЂЪ§ОнаЃбщЁЂЬиеїГщШЁЁЂЗжЮіЙЄОпЁЂСїГЬЙмРэЙЄОпЁЂзЪдДЙмРэЁЂМрПиЕШЛЗНкЃЌвВЖМЪЧетИізлКЯадЯЕЭГгІЕБНтОіЕФЮЪЬтЁЃ
ДЫЭтЃЌдкЛњЦїбЇЯАЫуЗЈдЫаажЎЧАЃЌЮвУЧашвЊзіЪ§ОндЄДІРэЁЂЬиеїЙЄГЬЁЂЪ§ОнЧхЯДЃЌШЛКѓВХФмзіЃЈЭЈЙ§ЛњЦїбЇЯАПђМмЃЉбЕСЗФЃаЭЃЌЖјбЕСЗГіРДЕФФЃаЭашвЊДцДЂЃЌШЛКѓЖдЭтЬсЙЉдкЯпЗўЮёЃЌЭъГЩдЄВтЗжЮіЁЃЭЌЪБЃЌФЃаЭЕФЪ§ОнПтЙмРэЁЂЗўЮёЕФМрПиЁЂЖЏЬЌРЉЫѕШнЕШЃЌЪЧЦфЮШЖЈдЫааЕФБЃеЯЁЃДгећИіЙЄзїСїРДПДЃЌЙЄГЬСПЗЧГЃХгДѓЁЃКУЯћЯЂЪЧЃЌZeppelin
ЩчЧјж№ВНЭъГЩСЫЖдЛњЦїбЇЯАЦНЬЈЙЄзїСїЕФЩјЭИЃЌЬсЙЉСЫНЯЮЊЭъећЕФПЩЪгЛЏНЛЛЅЕФжЇГжЁЃ
ЪзЯШЃЌдкЪ§ОндЄДІРэКЭЬиеїЙЄГЬЗНУцЃЌДгЪ§ОнЕМШыЁЂЪ§ОнДІРэЁЂЪ§ОнЬНЫїЁЂЪ§ОнГщбљЕНЪ§ОнбЕСЗЃЌZeppelin
вбОЪЕЯжСЫШЋИВИЧЃКЪ§ОнЕМШыжЇГж HDFSЁЂS3КЭRDNMSЃЌЪ§ОнОлКЯМгЙЄДІРэжЇГж HiveЁЂSparkЃЌЪ§ОнЬНЫїЪЧ
Zeppelin ЕФЧПЯюжЎвЛЃЌЪ§ОнГщбљЁЂФЃаЭбЕСЗКЭA/BВтЪддђжЇГжSparkЁЃ
ЦфДЮЃЌдкФЃаЭбЕСЗЗНУцЃЌАќРЈТпМЛиЙщЃЈLRЃЉЁЂЬнЖШЬсЩ§ЪїЃЈGDBTЃЉЕШДЋЭГЛњЦїбЇЯАФЃаЭЃЌвдМАЕШОэЛ§ЩёОЭјТчЃЈCNNЃЉЁЂбЛЗЩёОЭјТчЃЈRNNЃЉЁЂГЄЖЬЦкМЧвфЭјТчЃЈLSTMЃЉЕШГЃгУгкЭМЯёЁЂгявєЁЂЪгЦЕЕФЩюЖШбЇЯАФЃаЭЃЌZeppelin
ЖМжЇГжИїжжжїСїЕФПтЃЌеыЖдЧАепШчPython ПтЁЂSpark MLlibЁЂXGBoostЃЌеыЖдКѓепАќРЈTensorFlowЁЂPyTorchЁЂMXNetЕШЁЃгЩгкЛњЦїбЇЯАДгвЕепГЃгУгябдАќРЈPythonЁЂScalaЁЂR
ЕШЃЌИїжжЛЗОГЁЂАцБОЕФГхЭЛЪЧвЛИіКмДѓЕФЬєеНЃЌZeppelin ВЩгУ Docker ЕФВПЪ№НтОіСЫетИіЮЪЬтЁЃ
дйДЮЃЌдкФЃаЭдкЯпЗўЮёЗНУцЃЌФЃаЭЕФЙмРэжЇГж HadoopЃЌФЃаЭВПЪ№жЇГж Hadoop КЭ KubernetesЃЌФЃаЭПтЕФХњДІРэВЩгУ
SparkЃЌдіСПИќаТдђВЩгУадФмИќКУЕФ Flink СїМЦЫуЃЈвдБЃГжФЃаЭгыЪБОуНјЃЉЁЃ
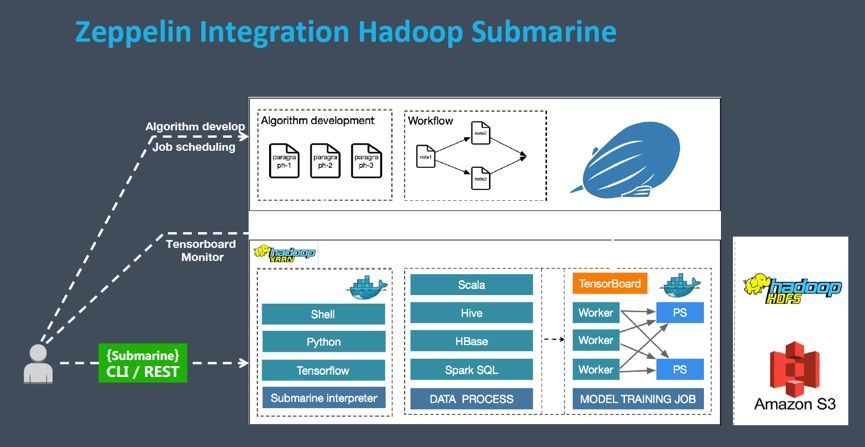
ДЫЭтЃЌдкЩњЬЌЗНУцЃЌZeppelinЛЙКЭ Hadoop Submarine зіСЫМЏГЩЃЌКѓепЪЧ Hadoop
ЩчЧјПЊЗЂЕФвЛПюЛњЦїбЇЯАв§ЧцЃЌжМдкНтОіЛњЦїбЇЯАЫуЗЈдкKubernetes / YARN ЦНЬЈЩЯЕФХњСПзївЕДІРэЁЃЖўепЕФМЏГЩЃЌПЩвдНЋ
Zeppelin ДгжЇГжЕЅШЮЮёПЊЗЂРЉеЙЕНСЫжЇГжЗжВМЪНШЮЮёЕїЖШЕФГЁОАЁЃ
3 ZeppelinЕФаТЬиад
ЮЊСЫжЇГжЛњЦїбЇЯАЙЄзїИКдиЃЌZeppelinЩчЧјПЊЗЂГіСЫКмЖрЯрЙиЕФЬиадЃЌАќРЈZeppelin МЏШКФЃЪНЃЈCluster
ModeЃЉЁЂZeppelin Cluster + DockerЁЂZeppelin On YarnЁЂЖрМЏШКжЇГжЁЂЖЏЬЌХфжУЁЂФЃаЭдЄВтгыдіСПбЕСЗЁЂПЩЪгЛЏЕїВЮКЭ
Zeppelin WorkFlow ЕШживЊЬиадЁЃ
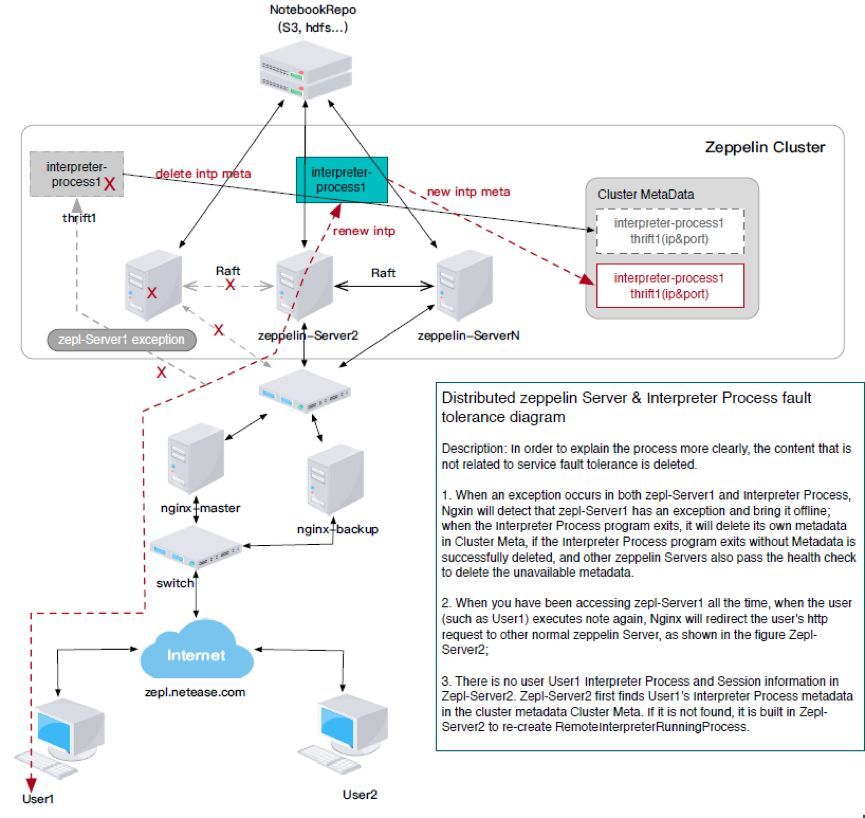
Zeppelin МЏШКФЃЪНЃЈCluster ModeЃЉЁЃЗЧМЏШКФЃЪНЃЌМДжЛгавЛИі ZeppelinServerЃЌНтЪЭЦїПЩвддЫаадкетИіServer
ЩЯЃЌЕЋШєЫуЗЈЙЄГЬЪІЪ§СПКмЖрЃЌгУЛЇЖдЗўЮёПЩгУадЕФвЊЧѓПЩФмЮоЗЈТњзуЁЃМЏШКФЃЪНЯТЃЌЮвУЧПЩвдЭЌЪБЦєЖЏЖрИіZeppelin
ServerЃЌЛљгкRaft ЫуЗЈбЁжїЃЈMasterЃЉЁЂЭЌВНЃЌЙВЭЌЖдЭтЬсЙЉЗўЮёЁЃгУЛЇЭЈЙ§ Nginx
ЗДЯђДњРэгђУћЗУЮЪетаЉ Zeppelin ЗўЮёЁЃЭЌЪБЃЌМЏШКФЃЪНЛЙЬсЙЉСЫ Cluster дЊЪ§ОнЙмРэЕФФмСІЃЌМЏШКжаЫљгаЕФ
Zeppelin Server ЕФдЫаазДПіЃЌвдМАЫљгаЕФНтЪЭЦїНјГЬЃЌЖМЛсМЧТМдкдЊЪ§ОнжаЃЌгУЛЇПЩвдЭЈЙ§Nginx
ХфжУЗУЮЪВЛЭЌЕФ ServerЃЌДДНЈВЛЭЌЕФНтЪЭЦїЁЃНтЪЭЦїНјГЬПЩвддкМЏШКжаздЖЏбАевзЪдДзюЮЊИЛгрЕФ Server
РДдЫааЃЌЖјЕБФГИі Server ЙвСЫЧвФбвдЛжИДЃЌгУЛЇШдШЛПЩвдЭЈЙ§дЊЪ§ОнЦєЖЏСэЭтвЛИі ServerЃЌМЬајЮДЭъГЩЕФЙЄзїЁЃZeppelin
МЏШКФЃЪНжЛашдкВЮЪ§жаХфжУ3ИіЗўЮёЦїЕФСаБэЃЌВЂНЋЦфЦєЖЏЃЌМДПЩздЖЏзщНЈ Zeppelin МЏШКЃЌВЛашвЊНшжњ
ZooKeeperЁЃЭЈЙ§зЈУХЕФМЏШКЙмРэвГУцЃЌгУЛЇПЩвдЧхЮњПДЕНМЏШКжаЕФЗўЮёЦїЁЂНтЪЭЦїЕФЪ§СПКЭдЫаазДЬЌЁЃ
БОЛњ DockerЁЃЮоТлЪЧЕЅЛњФЃЪНЛЙЪЧМЏШКФЃЪНЃЌгУЛЇЖМПЩвддкБОЛњ Docker ЩЯДДНЈНтЪЭЦїНјГЬЁЃЭЈЙ§МЏШКФЃЪН+
DockerЃЌгУЛЇВЛашвЊ Yarn Лђеп KubernetesЃЌМДПЩДДНЈ Zeppelin МЏШКЃЌЬсЙЉИпПЩгУЗўЮёЃЌКЫаФЙІФмКЭZeppelin
On Yarn/ Kubernetes ВЂЮоЖўжТЃЌЖјЧвВПЪ№КЭЮЌЛЄвВКмМђЕЅЃЌЮоашИДдгЕФЭјТчХфжУЁЃ
Zeppelin On YarnЁЃZeppelin ЕФНтЪЭЦїПЩвдДДНЈдк Yarn ЕФдЫааЛЗОГжаЃЌжЇГжYarn
2.7МАвдЩЯЕФАцБОЁЃZeppelin ШнЦїЕФЮЌЛЄашвЊФЃФтжеЖЫЃЌZeppelin жЇГжЭЈЙ§shell
УќСюНјШы Docker НјааЮЌЛЄЃЌШчАВзАЫљашЕФ Python ПтЁЂаоИФЛЗОГБфСПЕШЁЃ
Жр Hadoop МЏШКЁЃZeppelin жЇГжЭЈЙ§ХфжУЃЌМДжИЖЈВЛЭЌЕФ Hadoop / Spark
Conf ЮФМўЃЌМДПЩгУвЛИі Zeppelin МЏШКЃЌШЅСЌНгЫљгаЕФ Hadoop МЏШКЃЌЖјЮоашЮЊЫљга
Hadoop МЏШКЗжБ№ДДНЈЖрИі Zeppelin ЗўЮёЃЌДгЖјМђЛЏЙмРэКЭЮЌЛЄЕФИДдгЖШЃЌЭЌЪББЃжЄЗўЮёЕФПЩППадЁЃ
ЖЏЬЌХфжУЁЃZeppelin ЬсЙЉЗўЮёНгПкЃЌгУЛЇПЩвдСЌНгЕНздМКЕФ KDC Лђеп LDAP ШЯжЄЯЕЭГЃЌЛёШЁЫљашЕФаХЯЂЃЌвдБуЭъГЩдкВЛЭЌЕФ
Hadoop МЏШКЩЯЕФВйзїЁЃ
ФЃаЭдЄВтгыдіСПбЕСЗЁЃZeppelin жЇГжЭЈЙ§ Spark Лђеп Flink ЕФНтЪЭЦїЃЌЪЙгУХњДІРэЛђепСїДІРэЕФЗНЪНЃЌАбгУЛЇаТВњЩњЕФЪ§ОнНсКЯКѓЬЈЕФФЃаЭбЕСЗЗўЮёНјаадіСПбЕСЗЃЌВЂАббЕСЗГіРДЕФаТФЃаЭБЃДцЕНФЃаЭПтжаЁЃ
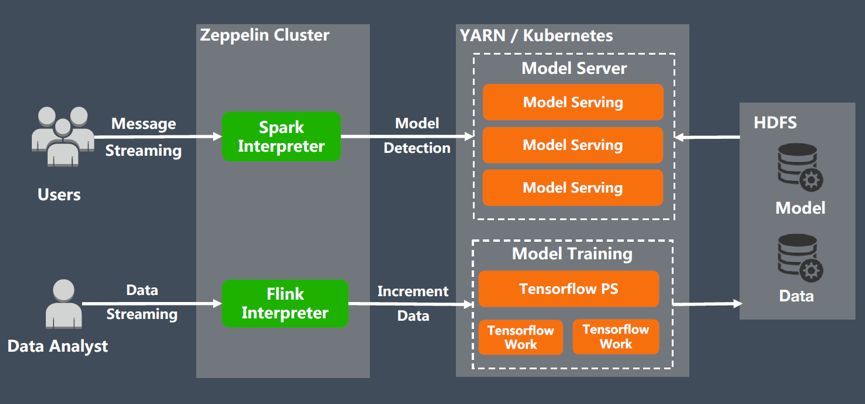
ПЩЪгЛЏЕїВЮЁЃВЛЭЌЕФЛњЦїбЇЯАПђМмгаВЛЭЌЕФВЮЪ§ХфжУЃЌЩѕжСВЛЭЌЕФЫуЗЈВЮЪ§ЖМВЛЭЌЃЌДЋЭГУќСюааЕФЗНЪНШнвзХфжУГіДэЃЌZeppelin
ЛљгкЦфЧАЖЫПЩЪгЛЏеЙЪОФмСІЃЌНЋжЇГжеыЖдУПИіЫуЗЈздааЩшжУвЛИіВЮЪ§ЕїећНчУцЃЌКЭФЃаЭвЛЦ№ЗЂВМЃЌФЃаЭЪЙгУепПЩвдЪЙгУИУПЩЪгЛЏНчУцЃЌИљОнашвЊЖЏЬЌЕиЕїећВЮЪ§ЁЃ
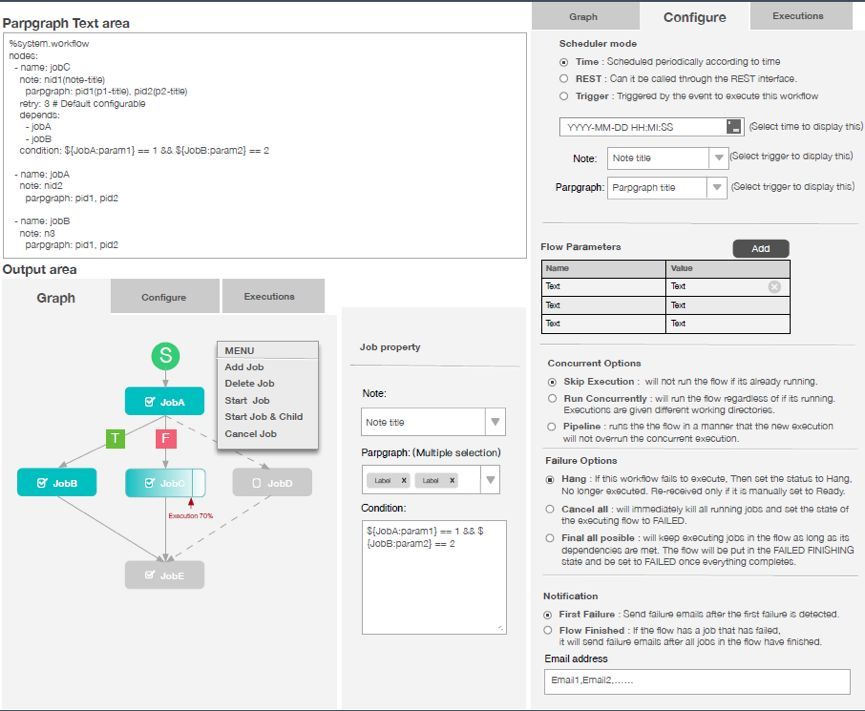
Zeppelin WorkFlowЁЃгУЛЇПЩвддкАДее Zeppelin ЬсЙЉЕФвЛжжРрЫЦ Azkaban
ЕФЪ§ОнИёЪНЃЌБраД Node жЎМфЕФвРРЕЃЌЯТЗНаЮГЩвЛИіПЩЪгЛЏЕФ WorkFlow ЭМЃЌЭЈЙ§ЭЯзЇЕФЗНЪНПЩвдБрХХећИіЙЄзїСїЃЌЩшжУУПИіНкЕуЕФЖЏзїЁЃНсКЯВЮЪ§ЕФХфжУЃЌгУЛЇПЩвдБраДвЛИіИДдгЕФ
Zeppelin ЙЄзїСїЃЌдкгвБпЩшжУДЅЗЂЕФЬѕМўЃЌШчАДЪБМфЕуЁЂRest НгПкЪжЖЏДЅЗЂЃЌЛђепАДеежмЦкадЪБМфЁЂЪ§ОнБфЛЏРДЩшжУЁЃ
4змНс
Apache Zeppelin ИВИЧЛњЦїбЇЯАШЋСїГЬЃЌШУЪ§ОнПЦбЇЙЄзїепФмЙЛвдПЩЪгЛЏЕФЗНЪНЃЌЗНБуЕиБраДЛњЦїбЇЯАЫуЗЈЁЂЕїВЮКЭНјааЛњЦїбЇЯАШЮЮёЙмРэЁЃеыЖдДѓЪ§ОнШЮЮёЕФЬиЕуЃЌZeppelin
вВзіСЫЗжВМЪНЕФгХЛЏЁЃЭЌЪБЃЌZeppelin ЛЙФмгыЦфЫћ Apache ДѓЪ§ОнЩњЬЌЯюФПвВФмКмКУЕиМЏГЩЃЌПЩвдИќКУЕиТњзуВЛЭЌЭХЖгЕФашЧѓЁЃ
|









