| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ
Zeppelin ЪЧЪВУДЃЌдѕУДЪЙгУМАЪЙгУЕФВйзїЙ§ГЬЃЌЯЃЭћБОЮФЖдДѓМвгаАяжњЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1.ИХЪі дкБраД FlinkЃЌSparkЃЌHive ЕШЯрЙизївЕЪБЃЌвЊЪЧФмПьЫйЕФНЋЮвУЧЫљБраДЕФзївЕФмПЩЪгЛЏдкЮвУЧУцЧАЃЌЪЧМўШУШЫаЫЗмЕФЪБЃЌШчЙћФмДјЩЯЧїЪЦЙІФмОЭИќКУСЫЁЃНёЬьЃЌИјДѓМвНщЩметУДвЛПюЙЄОпЁЃЫќОЭФмТњзуЩЯЪівЊЧѓЃЌдкЪЙгУСЫвЛЖЮЪБМфжЎКѓЃЌетРяИјДѓМвЗжЯэвдЯТЪЙгУаФЕУЁЃ
2.How to do ЪзЯШЃЌЮвУЧРДСЫНтвЛЯТетПюЙЄОпЕФБГОАМАгУЭОЁЃZeppelin ФПЧАвбЭаЙмгк Apache ЛљН№ЛсЃЌЕЋВЂЮДСаЮЊЖЅМЖЯюФПЃЌПЩвддкЦфЙЋВМЕФ
ЙйЭјЗУЮЪЁЃЫќЬсЙЉСЫвЛИіЗЧГЃгбКУЕФ WebUI НчУцЃЌВйзїЯрЙижИСюЁЃЫќПЩвдгУгкзіЪ§ОнЗжЮіКЭПЩЪгЛЏЁЃЦфКѓУцПЩвдНгШыВЛЭЌЕФЪ§ОнДІРэв§ЧцЁЃАќРЈ
FlinkЃЌSparkЃЌHive ЕШЁЃжЇГждЩњЕФ ScalaЃЌShellЃЌMarkdown ЕШЁЃ
2.1 Install
Ждгк Zeppelin ЖјбдЃЌВЂВЛвРРЕ Hadoop МЏШКЛЗОГЃЌЮвУЧПЩвдВПЪ№ЕНЕЅЖРЕФНкЕуЩЯНјааЪЙгУЁЃЪзЯШЮвУЧЛёШЁАВзААќЃК
етРяЃЌга2жжбЁдёЃЌЦфвЛЃЌПЩвдЯТдидЮФМўЃЌздааБрвыАВзАЁЃЦфЖўЃЌжБНгЯТдиЖўНјжЦЮФМўНјааАВзАЁЃетРяЃЌЮЊСЫЗНБуЃЌБЪепжБНгЪЙгУЖўНјжЦЮФМўНјааАВзАЪЙгУЁЃетРягааЉВЮЪ§ашвЊНјааХфжУЃЌЮЊСЫБЃжЄЯЕЭГе§ГЃЦєЖЏЃЌШЗБЃЕФ
zeppelin.server.port ЪєадЕФЖЫПкВЛБЛеМгУЃЌФЌШЯЪЧ8080ЃЌЦфЫћЪєадДѓМвПЩАДашХфжУМДПЩЁЃЃлХфжУСДНгЃн
2.2 Start/Stop
дкЭъГЩЩЯЪіВНжшКѓЃЌЦєЖЏЖдгІЕФНјГЬЁЃЖЈЮЛЕН Zeppelin АВзАФПТМЕФbinЮФМўМаЯТЃЌЪЙгУвдЯТУќСюЦєЖЏНјГЬЃК
| ./zeppelin-daemon.sh
start |
ШєашвЊЭЃжЙЃЌПЩвдЪЙгУвдЯТУќСюЭЃжЙНјГЬЃК
| ./zeppelin-daemon.sh
stop |
СэЭтЃЌЭЈЙ§дФЖС zeppelin-daemon.sh НХБОЕФФкШнЃЌПЩвдЗЂЯжЃЌЮвУЧЛЙПЩвдЪЙгУЯрЙижиЦєЃЌВщПДзДЬЌЕШУќСюЁЃФкШнШчЯТЃК
case "${1}"
in
start)
start
;;
stop)
stop
;;
reload)
stop
start
;;
restart)
stop
start
;;
status)
find_zeppelin_process
;;
*)
echo ${USAGE} |
3.How to use
дкЦєЖЏЯрЙиНјГЬКѓЃЌПЩвдЪЙгУвдЯТЕижЗдкфЏРРЦїжаЗУЮЪЃК
| http://<Your_<IP/Host>:Port> |
ЦєЖЏжЎКѓЕФНчУцШчЯТЫљЪОЃК
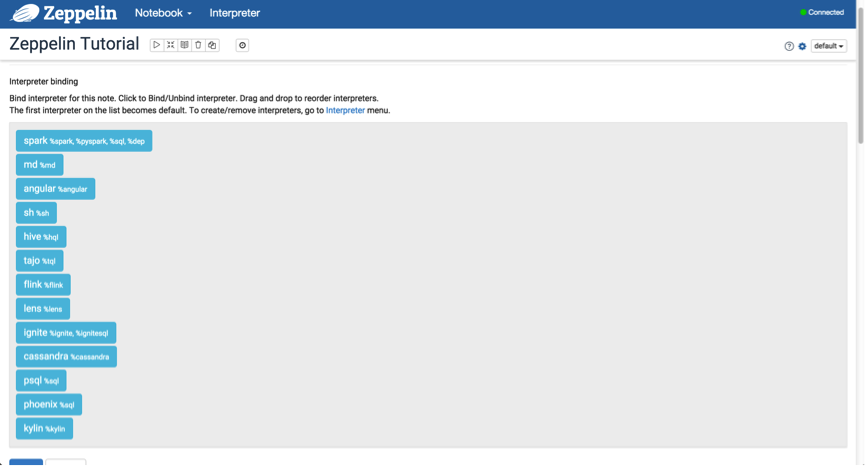
ИУНчУцТоСаГіВхМўАѓЖЈЯюЁЃШчЭМжаЕФ sparkЃЌmdЃЌsh ЕШЁЃФЧЮвШчКЮЪЙгУетаЉРДЭъГЩвЛаЉЙЄзїЁЃдкЪЙгУвЛаЉЪ§Онв§ЧцЪБЃЌШч
FlinkЃЌSparkЃЌHive ЕШЃЌЪЧашвЊХфжУЖдгІЕФСЌНгаХЯЂЕФЁЃдк Interpreter РИДІНјааХфжУЁЃетРяИјДѓМвСаОйвЛаЉХфжУЪОР§ЃК
3.1 Flink ПЩвдевЕН Flink ЕФХфжУЯюЃЌШчЯТЭМЫљЪОЃК

ШЛКѓжИЖЈЖдгІЕФ IP КЭЕижЗМДПЩЁЃ
3.2 Hive етРя Hive ХфжУашвЊжИЯђЦф Thrift ЗўЮёЕижЗЃЌШчЯТЭМЫљЪОЃК

СэЭтЃЌЦфЫћЕФВхМўЃЌШч SparkЃЌKylinЃЌphoenixЕШХфжУРрЫЦЃЌХфжУЭъГЩКѓЃЌМЧЕУЕуЛї
ЁАrestartЁБ АДХЅЁЃ
3.3 Use md and sh ЯТУцЃЌЮвУЧПЩвдДДНЈвЛИі Notebook РДЪЙгУЃЌЮвУЧФУзюМђЕЅЕФ Shell КЭ Markdown
РДбнЪОЃЌШчЯТЭМЫљЪОЃК
3.4 SQL ЕБШЛЃЌЮвУЧЕФФПЕФВЂВЛЪЧНіНіЪЙгУ Shell КЭ MarkdownЃЌЮвУЧашвЊФмЙЛЪЙгУ SQL РДЛёШЁЮвУЧЯывЊЕФНсЙћЁЃ
3.4.1 Spark SQL ЯТУцЃЌЮвУЧЪЙгУ Spark SQL ШЅЛёШЁЯывЊЕФНсЙћЁЃШчЯТЭМЫљЪОЃК
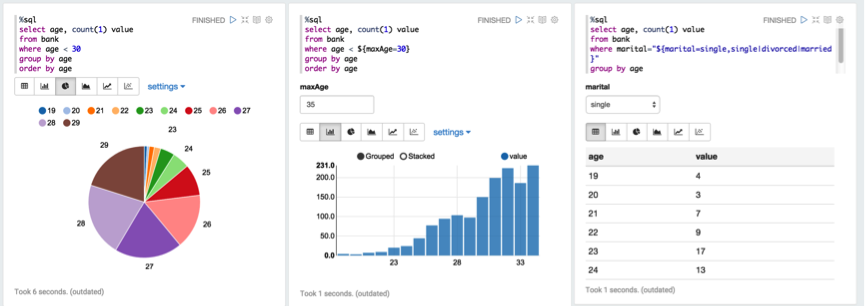
етРяЃЌПЩвдНЋНсЙћвдВЛЭЌЕФаЮЪНРДПЩЪгЛЏЃЌСПЛЏЃЌЧїЪЦЃЌвЛФПСЫШЛЁЃ
3.4.2 Hive SQL
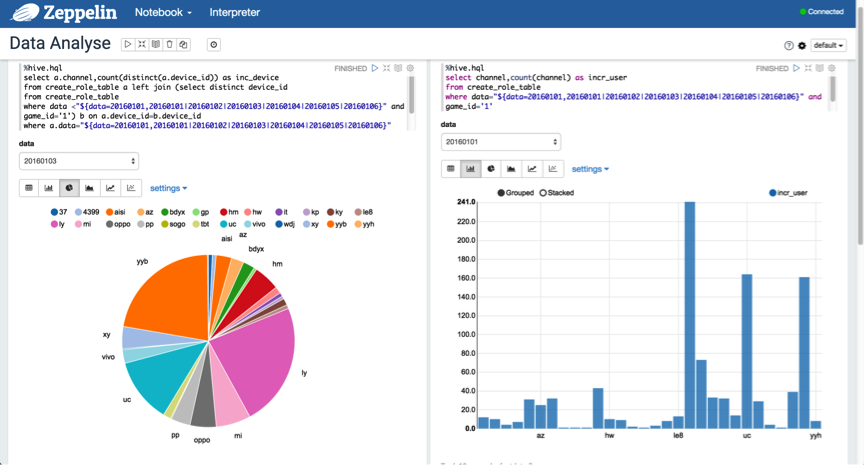
СэЭтЃЌПЩвдЪЙгУЖЏЬЌИёЪНРДВщбЏЗжЧјЪ§ОнЃЌвд"${partition_col=
20160101, 20160102 |20160103 |20160104 |20160105 |
20160106}"ЕФИёЪННјааБэЪОЁЃШчЯТЭМЫљЪОЃК
3.5 Video Guide СэЭтЃЌЙйЗНвВИјГіСЫвЛИіПьЫйжИЕМЕФШыУХЪгЦЕЃЌЙлПДЕижЗЃК[ШыПк]
4.змНс дкЪЙгУЕФЙ§ГЬЕБжаЃЌгааЉЕиЗНашвЊзЂвтЃЌБиаыдкБраД Hive SQL ЪБЃЌ%hql ашвЊЬцЛЛЮЊ %hive.sql
ЕФИёЪНЃЛСэЭтЃЌдкдЫаа Scala ДњТыЪБЃЌШчЙћГіЯжвдЯТвьГЃЃЌШчЯТЭМЫљЪОЃК

НтОіЗНАИЃЌдк zeppelin-env.sh ЮФМўжаЬэМгвдЯТФкШнЃК
| export ZEPPELIN_MEM=-Xmx4g |
ИУ BUG дк 0.5.6 АцБОЕУЕНаоИДЃЌВЮПМТыЃКЃлZEPPELIN-305Ѓн |









