| 编辑推荐: |
本文从需求出发,探索Zeppelin的架构设计、技术选型、代码的模块划分等相关内容。
本文来自微信程序员王小闲,由火龙果软件Anna编辑、推荐。 |
|
Apache Zeppelin 是一个基于Web的交互式数据分析开源框架,提供了数据分析、数据可视化等功能。支持多种语言,包括Scala、Python、SparkSQL、Hive、Markdown、Shell等。
本文从需求出发,探索Zeppelin的架构设计、技术选型、代码的模块划分和依赖关系的最初“出发点”,从而我们可以了解到Zeppelin为什么是这样设计的。
Zeppelin的最核心的功能,用一句话总结就是:支持多语言repl的解释器。开发者可以自定义开发更多的解释器为Zeppelin添加执行引擎。官方支持的执行引擎用一幅图描述如下:

Zeppelin这种支持多语言解释器的设计理念,核心价值体现在:
从使用者的角度来看:
可以在一个Note中混合使用多种语言,不受限于单个语言的特性。
数据分析和机器学习是一个不断迭代优化的过程。解释器REPL相对于“拖拽式”的数据分析平台,偏底层,更加灵活,相对于“纯黑盒”的拖拽式数据分析工具,REPL为数据科学家和算法工程师提供更多自主编程和实现自己想法的能力。而且基于REPL可以轻松的构建出“拖拽式”、自动化数据分析、自动化数据建模等上层应用。
从管理者的角度来看:
团队可以使用统一的工具环境。数据分析团队中,各成员擅长不同的开发语言,通过集中式的分析工具,在服务端统一配置R、Python、Spark、Hadoop、Hive等开发环境,显著降低运维成本。
可进行统一的安全控制。B/S系统,方便进行集中式的用户权限该控制和多用户在线协作,可以限制数据导出,保障数据的安全性,不必把数据拿到本地进行分析。
现在抛开Zeppelin已有的架构设计,假设让我们重新设计一个这样的平台,实现上面的核心功能,会面临哪些问题,有哪些解决方案,这些解决方案有什么优劣,从而探索zeppelin的设计理念和出发点。
首先,我们看一下该平台应用的主要场景:
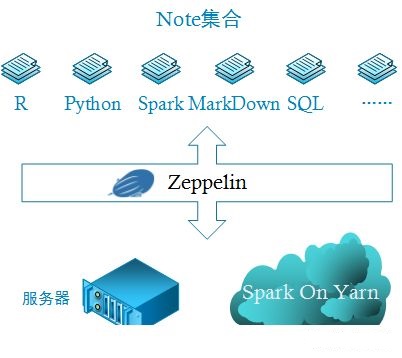
该平台需要解决在服务器资源一定的情况下,尽可能高效地执行多个用户混合多种语言的Notes问题。
由于我们要实现Notebook式的B/S架构的共享式分析工具,所以至少需要一台Web服务器。而Zeppelin典型的使用方式是与Spark一起使用,而Spark
on Yarn 又是常见的 Spark 部署方式,所以上图就是生产环境下Zeppelin最小配置。确定了部署方式后,我们需要需要解决软件设计问题,每种问题的解决方案都会影响到该平台的技术选型和架构设计,主要问题如下:
各种语言的代码在哪里执行?
代码的执行是会消耗服务器资源的,资源是共享的,有限的,合理的分配代码的执行环境,对平台的扩展能力至关重要。
在有web服务器的前提下,显然不会每个用户直接连接spark集群,提交任务(否则,就退化成了每个用户在本地启动一个spark-shell了,这也就是失去了集中共享式数据分析平台建设的意义),web服务器自然成了spark集群唯一的客户端,所有用户的任务都间接通过web服务器向spark集群提交。但是,并不是所有语言写的代码都需要提交的spark集群上执行,各种不同的语言的代码“理想”的执行位置如下:
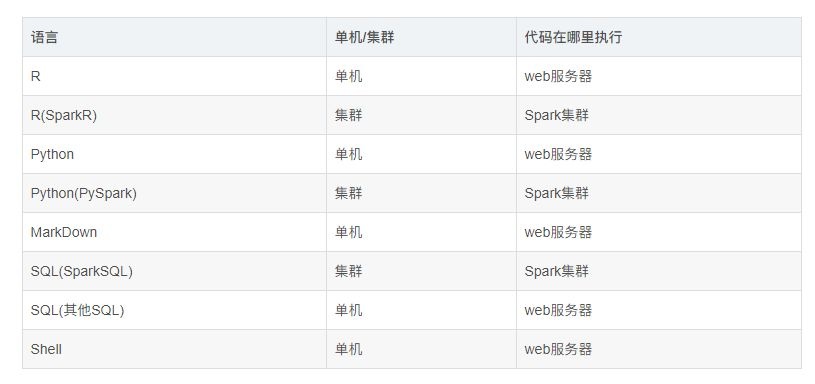
通过上表可以看出:
Spark集群有自己独立的资源管理器Yarn。任务的调度和资源的分配都由该资源管理器接管,这里不讨论。
还有很多语言代码是在Web服务器执行。一台Web服务器的资源是有限的,会成为限制该平台横向扩展的瓶颈。因此,需要在web服务器端,对用户执行代码的频率进行限制,如:进行排队。或者将代码的执行环境从web服务器端抽取出来,额外建立一个集群(这个集群与Spark集群不同),该集群的目标很单一,就是执行web服务器发过来的各种语言的代码。它可以是“无中心”节点的方式,各自向Web服务器报告,或者是类似Yarn集群的方式,只不过获取到的Container专门用来执行一段代码。
多用户支持问题
每个用户创建的note及note执行的结果,都属于该用户,其他用户未经授权是不能访问的。repl解释器应该实现用户之间的隔离,因为repl解释器执行过程中会保存context,如果不进行用户的隔离,repl解释器是共享的,即一个用户定义的变量会被其他用户访问到,用户之间会相互影响。所以必须不同用户的repl解释器必须是隔离的。那么同一个用户的不同note,如果语言相同,是否可以共享用一个解释器呢?将该问题进行抽象,就是repl解释器粒度问题,是per-user级别还是per-note级别的问题,二者各有优劣:
per-user级别:同一个用户不同note的相同语言代码发送到同一个解释器,节省服务器资源。解释器保留代码执行的上下文,可以实现跨note的数据交换。但由于多个note共用一个解释器,解释器繁忙,会导致响应时间变长。
per-note级别:耗费服务器资源,执行代码速度快,用户体验好。
既然两种方式各有优劣,怎么办呢?平台应该将选择权交给用户,平台提供灵活的配置功能。
Note中paragraph执行的顺序问题
同一Note中paragraph是并行还是串行呢?这要根据代码是否具有上下文相关性而定。
下图是Note的组成逻辑图,一个Note由多个paragraph(代码段)组成,代码段是有序的,每个代码段只能使用一种语言,不同的代码段可以使用不同语言。
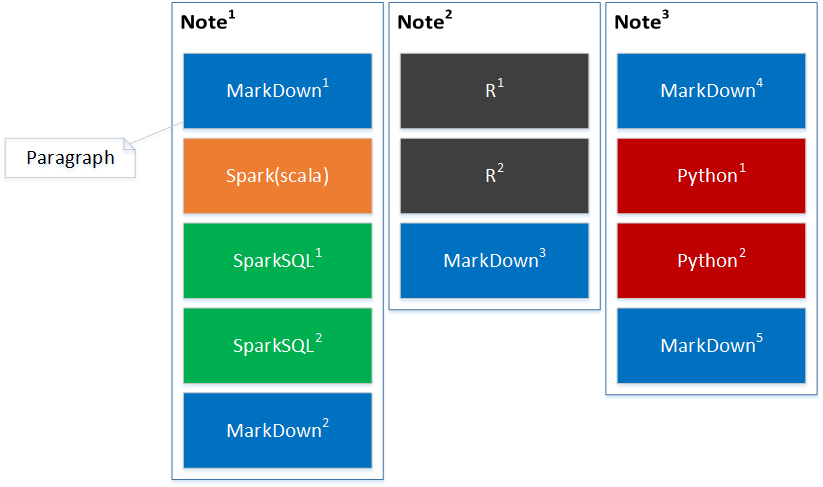
如果所有paragraph都并行执行,服务器压力会增加,执行效率会提高,但由于很多语言前后代码之间存在上下文相关性,是不能并行的,所以要根据不同语言进一步分析。各种语言代码段之间是否能并行如下表所示:

从上表可以看出,只有MarkDown可以并行执行。当然,其它语言在不存在上下文相关性的时候,是可以并行的。
因此,需要提供每个repl解释器级别的代码段并行执行设置,对于能够确定并行执行的代码,能够显示启用该设置,以提高运行速度。
相同的repl解释器不同的runtime依赖的问题
一个典型的场景是JDBC repl解释器,使用的都是SQL语句,后台配置不同的连接就可以访问不同的数据库,如:RDBMS、NoSQL等。每次启动解释器的时候,根据需要加载不同的runtime依赖,完成Driver的加载、Conncetion的获取及SQL语句的执行。这就要求repl解释器具有运行时动态查找、加载依赖的能力。同时也引出了下面的问题。
repl解释器进程管理问题
由于同一个JVM的class加载是根据classpath定义的顺序决定的,一旦找到就终止查找。因此,要支持不同的runtime依赖,需要启动独立的JVM,以实现依赖的隔离。但这样又出现新的问题,我们常用的在操作系统中启动一个R或者Python的repl进程,该进程的生命周期只受操作系统控制,而平台需要对repl解释器进行管控,即:解释器的启动、停止、解释执行代码、输出反馈等过程都要在平台的管控下进行,以实现自动化的进程控制,同时避免资源泄露。不同语言的repl进程,如何与JVM-Based平台的进程进行跨语言通信,也是需要考虑的问题。常见IPC(nter-Process-Communication)机制有Shared-Memory、Pipe、Socket这三种,考虑到未来支持repl解释器集群化部署,基于Socket通信方式是扩展性最好的。此外,我们需要尽可能复用多种语言的repl进程的生命周期控制逻辑,实现通用的控制逻辑,避免增加扩展解释器的开发工作量。
上述需求是zeppelin的核心需求,zeppelin已给出了相应的解决方案:
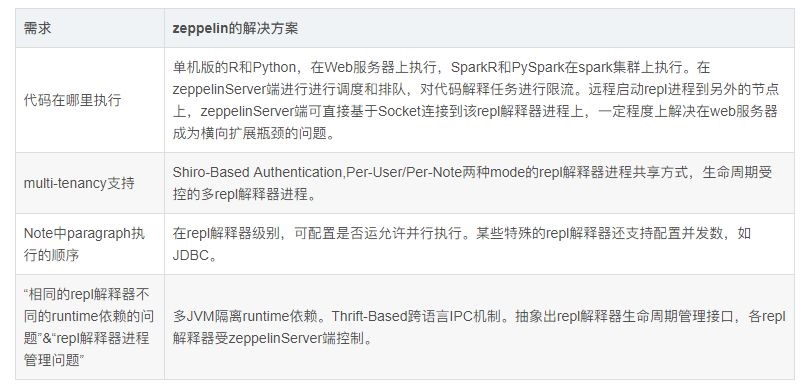
除了上述核心功能,zeppelin还提供了以下功能:
1、支持自定义解释器
作为一个数据分析工具,只有建立起良好的生态圈,才能保证长久的生命力。所以必须支持二次开发和自定义解释器的扩展。
2、将后台解释器进程的输出发送到前端
python和R有大量的可视化包,将这些后端输出发送到前端,就跟用户在自己本机打开R和Python解释器进程一样,实现前后端一致的用户体验。
3、前端实时反馈能力
大数据分析,任务运行时间长,前端必须能实时地反馈执行结果,显示进度和日志,允许用户终止正在执行的任务,是很重要的用户体验。
Zeppelin不具备和需要完善的功能:
1、集群化部署
Interpreter Process 是制约Zeppelin横向扩展的关键,需要解决如何在多个节点上动态分布Interpreter进程,并且保持Zeppelin与这些进程的通信。目前有一些蹩脚的实现方式,可以勉强实现zeppelin的集群化部署,但却不够优雅。
2、安全性问题
这里说的安全问题是除用户权限外的安全问题,包括系统安全和数据安全。可以写代码,对数据分析师来说是最灵活的方式,但对系统开发者来讲,要执行用户输入的各种代码,保证系统的稳定,却是“噩梦”一般。几行简单的代码,就可以让操作系统资源耗尽。本来可以很“优雅”地表达的代码,却被写地很低效、bug频出,占用大量的后端资源,使得repl进程迟迟没有响应。数据是资产,已经成为行业共识,作为一个共享式的大数据分析工具,所有的数据操作必须是在线的,数据资产不能导出。此外,数据的加密和脱敏问题,也属于此范畴的问题。
|









