| БрМЭЦМі: |
дкБОЮФжаЃЌНЋЪзЯШНщЩмЪ§ОнПЦбЇжаЕФЛљБОдРэЃЌвЛАуЙ§ГЬКЭЮЪЬтРраЭЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздИіШЫЭМЪщЙнЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
2006ФъЃЌгЂЙњЪ§бЇМвClive HumblyКЭTescoОуРжВППЈЕФЩшМЦЪІДДдьСЫЁАЪ§ОнОЭЪЧаТгЭ(Data
is the new oil)ЁБетОфЛАЁЃЫћЫЕЃК
ЁАЪ§ОнЪЧаТЕФЪЏгЭЁЃЫќКмгаМлжЕЃЌЕЋШчЙћЮДОЬсСЖОЭВЛФмЪЙгУЁЃЫќБиаызЊБфЮЊЬьШЛЦјЃЌЫмСЯЃЌЛЏбЇЦЗЕШЃЌвдДДдьвЛИігаМлжЕЕФЪЕЬхЧ§ЖЏгЏРћЕФЛюЖЏ;
ЫљвдЃЌБиаыЖдЪ§ОнНјааЗжНтКЭЗжЮіЃЌВХФмЪЙЦфОпгаМлжЕЁЃЁА
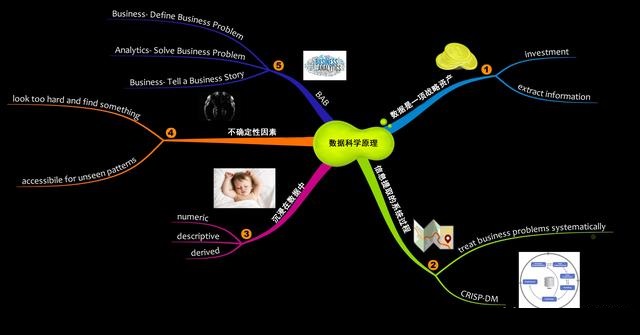
Ъ§ОнПЦбЇЪЧвЛИіЖрбЇПЦСьгђЁЃЫќЪЧвдЯТСьгђжЎМфЕФНЛМЏЃК
1.ЩЬвЕжЊЪЖ
2.ЛњЦїбЇЯА
3.МЦЫуЛњБрГЬ
ЮвУЧЕФжиЕуНЋЪЧМђЛЏЪ§ОнПЦбЇЕФЛњЦїбЇЯАЗНУцЁЃ
ЙиМќдРэ
Ъ§ОнЪЧвЛЯюеНТдзЪВњЃКетвЛИХФюЪЧвЛжжзщжЏаФЬЌЁЃвЊЮЪЕФЮЪЬтЪЧЃКЁАЮвУЧЪЧЗёе§дкЪЙгУЮвУЧЪеМЏКЭДцДЂЕФЫљгаЪ§ОнзЪВњЃПЮвУЧФмДгжаЛёШЁгавтвхЕФМћНтТ№ЃПЁА
ЮвШЗаХетаЉЮЪЬтЕФД№АИЖМЪЧЁАВЛЁБЁЃдЦМЦЫуЕФЙЋЫОБОжЪЩЯЪЧЪ§ОнЧ§ЖЏЕФЃЌНЋЪ§ОнЪгЮЊеНТдзЪВњЪЧЫћУЧЕФаФРэЃЌетжжаФЬЌЖдДѓЖрЪ§зщжЏЖМЮоаЇЁЃ
аХЯЂЬсШЁЕФЯЕЭГЙ§ГЬЃКашвЊгавЛИігаЬѕРэЕФЙ§ГЬРДДгЪ§ОнжаЬсШЁМћНтЁЃетИіЙ§ГЬгІИУгаЧхЮњУїШЗЕФНзЖЮЃЌВЂгаУїШЗЕФПЩНЛИЖГЩЙћЁЃПчаавЕБъзМЪ§ОнЭкОђСїГЬЃЈCRISP-DMЃЉОЭЪЧетбљвЛИіЙ§ГЬЁЃ
ГСНўдкЪ§ОнжаЃКзщжЏашвЊЭЖзЪгкЖдЪ§ОнГфТњШШЧщЕФШЫЁЃНЋЪ§ОнзЊЛЏЮЊМћНтВЂВЛЪЧФЇЗЈЃЌЫћУЧашвЊСЫНтЪ§ОнЫљВњЩњЕФМлжЕЃЌЫћУЧашвЊФмЙЛСЌНгЪ§ОнЃЌММЪѕКЭвЕЮёЕФШЫдБЁЃ
ВЛШЗЖЈадвђЫиЃКЪ§ОнПЦбЇВЛЪЧСщЕЄУювЉЃЌЫќВЛЪЧвЛИіЫЎОЇЧђЁЃгыБЈИцКЭKPIвЛбљЃЌЫќЪЧОіВпДйГЩвђЫиЁЃЪ§ОнПЦбЇЪЧвЛжжЙЄОпЃЌЖјВЛЪЧНсЪјЕФЪжЖЮЃЌЫќВЛЪєгкОјЖдСьгђЃЌЫќЪєгкИХТЪСьгђЃЌЙмРэепКЭОіВпепашвЊНгЪметвЛЪТЪЕЁЃЫћУЧашвЊдкОіВпЙ§ГЬжаНгЪмСПЛЏЕФВЛШЗЖЈадЃЌШчЙћзщжЏВЩгУЪЇАмЕФПьЫйбЇЯАЗНЗЈЃЌетжжВЛШЗЖЈаджЛФмИљЩюЕйЙЬЁЃжЛгазщжЏбЁдёЪЕбщЮФЛЏЃЌЫќВХЛсХюВЊЗЂеЙЁЃ
BABддђЃКЮвШЯЮЊетЪЧзюживЊЕФддђЁЃаэЖрЪ§ОнПЦбЇЮФЯзЕФжиЕуЪЧФЃаЭКЭЫуЗЈЃЌетИіЕШЪНУЛгаЩЬвЕБГОАЁЃвЕЮёЗжЮі
- вЕЮёЃЈBABЃЉЪЧЧПЕївЕЮёВПЗжЕФддђЃЌНЋЫќУЧжУгквЕЮёЛЗОГжаЪЧжСЙиживЊЕФЁЃЖЈвхвЕЮёЮЪЬтЃЌЪЙгУЗжЮіРДНтОіЫќЁЃНЋЪфГіМЏГЩЕНвЕЮёСїГЬжаЁЃBABЁЃ
ДІРэ
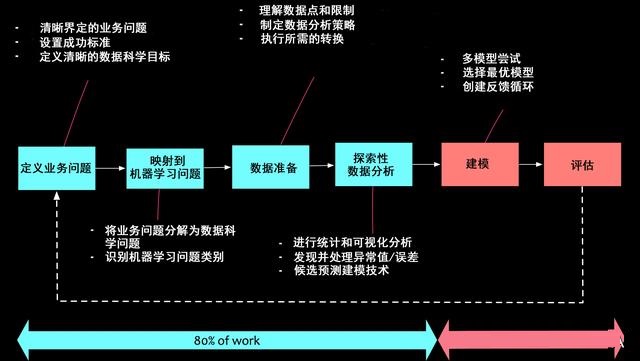
ИљОнЕкЖўЬѕддђЃЌЯждкШУЮвЧПЕївЛЯТЪ§ОнПЦбЇЕФЙ§ГЬВПЗжЁЃвдЯТЪЧвЛИіЕфаЭЕФЪ§ОнПЦбЇЯюФПЕФНзЖЮЃК
1.ЖЈвхвЕЮёЮЪЬт
АЂЖћВЎЬиАЎвђЫЙЬЙдјв§гУЁАУПМўЪТЖМгІИУОЁПЩФмЕиМђЕЅЃЌЕЋВЛФмдНМђЕЅдНКУЁБЁЃетОфЛАЪЧЖЈвхвЕЮёЮЪЬтЕФЙиМќЁЃашвЊПЊЗЂКЭЙЙНЈЮЪЬтГТЪіЃЌашвЊНЈСЂУїШЗЕФГЩЙІБъзМЁЃИљОнЮвЕФОбщЃЌвЕЮёЭХЖгУІгкДІРэЫћУЧЕФВйзїШЮЮёЁЃетВЂВЛвтЮЖзХЫћУЧУЛгаашвЊНтОіЕФЬєеНЁЃЭЗФдЗчБЉЛсвщЃЌбаЬжЛсКЭЗУЬИПЩвдАяжњЗЂЯжетаЉЬєеНВЂЬсГіМйЩшЁЃШУЮвгУвЛИіР§згРДЫЕУїетвЛЕуЁЃШУЮвУЧМйЩшвЛМвЕчаХЙЋЫОгЩгкПЭЛЇШКМѕЩйЖјЕМжТЦфЭЌБШЪеШыЯТНЕЁЃдкетжжЧщПіЯТЃЌвЕЮёЮЪЬтПЩФмЖЈвхЮЊЃК
ИУЙЋЫОашвЊЭЈЙ§ЖЈЮЛаТЕФЯИЗжЪаГЁКЭМѕЩйПЭЛЇСїЪЇРДРЉДѓПЭЛЇШКЁЃ
2.ЗжНтЮЊЛњЦїбЇЯАШЮЮё
вЕЮёЮЪЬтвЛЕЉЖЈвхЃЌОЭашвЊЗжНтЮЊЛњЦїбЇЯАШЮЮёЁЃШУЮвУЧЯъЯИЫЕУїЮвУЧдкЩЯУцЩшжУЕФЪОР§ЁЃШчЙћзщжЏашвЊЭЈЙ§ЖЈЮЛаТЕФЯИЗжЪаГЁВЂМѕЩйПЭЛЇСїЪЇРДРЉДѓПЭЛЇШКЃЌФЧУДЮвУЧШчКЮНЋЦфЗжНтЮЊЛњЦїбЇЯАЮЪЬтЃПвдЯТЪЧЗжНтЕФЪОР§ЃК
НЋПЭЛЇСїЪЇТЪНЕЕЭxЃЅЁЃ
ЮЊФПБъЪаГЁШЗЖЈаТЕФПЭЛЇШКЁЃ
3.Ъ§ОнзМБИ
вЛЕЉЮвУЧЖЈвхСЫвЕЮёЮЪЬтВЂНЋЦфЗжНтЮЊЛњЦїбЇЯАЮЪЬтЃЌЮвУЧОЭашвЊЩюШыбаОПЪ§ОнЁЃЪ§ОнРэНтгІИУУїШЗЪжЭЗЕФЮЪЬтЁЃЫќгІИУгажњгкЮвУЧжЦЖЈе§ШЗЕФЗжЮіВпТдЁЃашвЊзЂвтЕФЙиМќЪТЯюЪЧЪ§ОнРДдДЃЌЪ§ОнжЪСПЃЌЪ§ОнЦЋВюЕШЁЃ
4.ЬНЫїадЪ§ОнЗжЮі
гюКНдБДЉдНгюжцЕФЮДжЊЁЃЭЌбљЃЌЪ§ОнПЦбЇМвБщРњЪ§ОнФЃЪНЕФЮДжЊЃЌПњЬНЦфЬиеїЕФАТУиВЂжЦЖЈГіЮДБЛЬНЫїЕФФкШнЁЃЬНЫїадЪ§ОнЗжЮіЃЈEDAЃЉЪЧвЛЯюСюШЫаЫЗмЕФШЮЮёЁЃЮвУЧПЩвдИќКУЕиРэНтЪ§ОнЃЌбаОПЦфжаЕФЯИЮЂВюБ№ЃЌЗЂЯжвўВиЕФФЃЪНЃЌПЊЗЂаТЬиадВЂжЦЖЈНЈФЃВпТдЁЃ
5.НЈФЃ
дкEDAжЎКѓЃЌЮвУЧНјШыНЈФЃНзЖЮЁЃдкетРяЃЌЮвУЧИљОнОпЬхЕФЛњЦїбЇЯАЮЪЬтЃЌЮвУЧгІгУгагУЕФЫуЗЈЃЌШчЛиЙщЃЌОіВпЪїЃЌЫцЛњЩСжЕШЁЃ
6.ВПЪ№КЭЦРЙР
зюКѓЃЌЖдЫљПЊЗЂЕФФЃаЭНјааСЫВПЪ№ЁЃЫќУЧБЛГжајМрВтЃЌвдЙлВьЫќУЧдкЯжЪЕЪРНчжаЕФааЮЊЃЌВЂОнДЫНјаааЃзМЁЃ
ЭЈГЃЃЌНЈФЃКЭВПЪ№ВПЗжНіеМЙЄзїСПЕФ20ЃЅЁЃ80ЃЅЕФЙЄзїЪЧНгДЅЪ§ОнЃЌЬНЫїЪ§ОнВЂРэНтЪ§ОнЁЃ
ЛњЦїбЇЯАЮЪЬтРраЭ
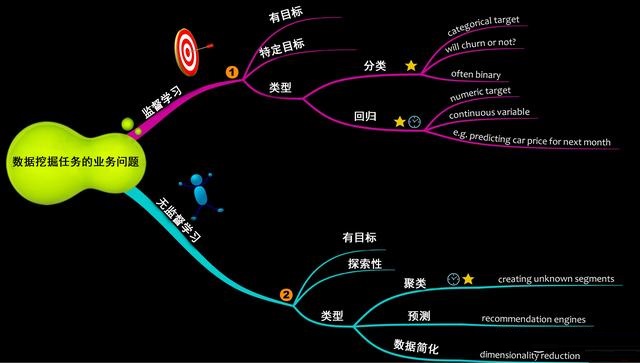
вЛАуРДЫЕЃЌЛњЦїбЇЯАгаСНжжШЮЮёЃК
МрЖНбЇЯА
МрЖНбЇЯАЪЧвЛжжЛњЦїбЇЯАШЮЮёЃЌЦфжаДцдквбЖЈвхЕФФПБъЁЃДгИХФюЩЯНВЃЌНЈФЃепНЋМрЖНЛњЦїбЇЯАФЃаЭвдЪЕЯжЬиЖЈФПБъЁЃМрЖНбЇЯАПЩвдНјвЛВНЗжЮЊСНРрЃК
ЛиЙщ
ЛиЙщЪЧЛњЦїбЇЯАШЮЮёЕФжїСІЁЃЫќУЧгУгкЙРМЦЛђдЄВтЪ§жЕБфСПЁЃЛиЙщФЃаЭЕФМИИіР§згПЩвдЪЧЃК
ЯТИіМОЖШЧБдкЪеШыЕФдЄВтЃП
УїФъФмЙЛЭъГЩЖрЩйБЪНЛвзЃП
ЗжРр
ЙЫУћЫМвхЃЌЗжРрФЃаЭЖдФГаЉЪТЮяНјааСЫЗжРрЁЃЙРМЦФФИізюКЯЪЪЁЃЗжРрФЃаЭОГЃгУгкЫљгаРраЭЕФгІгУГЬађЁЃЗжРрФЃаЭЕФР§згКмЩйЃК
РЌЛјгЪМўЙ§ТЫЪЧЗжРрФЃаЭЕФСїааЪЕЯжЁЃдкетРяЃЌИљОнЬиЖЈЬиеїЃЌУПИіДЋШыЕФЕчзггЪМўЖМБЛЙщРрЮЊРЌЛјгЪМўЛђЗЧРЌЛјгЪМўЁЃ
ПЭЛЇСїЪЇдЄВтЪЧЗжРрФЃаЭЕФСэвЛИіживЊгІгУЁЃдкЕчаХЙЋЫОжаЙуЗКЪЙгУЕФСїЪЇФЃаЭПЩвдЖдИјЖЈПЭЛЇЪЧЗёЛсСїЪЇЃЈМДЭЃжЙЪЙгУЗўЮёЃЉНјааЗжРрЁЃ
ЮоМрЖНбЇЯА
ЮоМрЖНбЇЯАЪЧвЛРрУЛгаФПБъЕФЛњЦїбЇЯАШЮЮёЁЃгЩгкЮоМрЖНбЇЯАУЛгаШЮКЮЬиЖЈФПБъЃЌвђДЫгаЪБФбвдНтЪЭЦфВњЩњЕФНсЙћЁЃгааэЖрРраЭЕФЮоМрЖНбЇЯАШЮЮёЁЃЙиМќЪЧЃК
ОлРрЃКОлРрЪЧНЋРрЫЦЪТЮязщКЯдквЛЦ№ЕФЙ§ГЬЁЃПЭЛЇЯИЗжЪЙгУОлРрЗНЗЈЁЃ
ЙиСЊЃКЙиСЊЪЧвЛжжбАевОГЃЯрЛЅЦЅХфЕФВњЦЗЕФЗНЗЈЁЃСуЪлЪаГЁЗжЮіЪЙгУЙиСЊЗНЗЈНЋВњЦЗРІАѓдквЛЦ№ЁЃ
дЄВтЃКдЄВтгУгкЗЂЯжЪ§ОнЯюжЎМфЕФСЌНгЁЃFacebookЃЌбЧТэбЗКЭNetflixВЩгУЕФЭЦМів§ЧцДѓСПЪЙгУСДНгдЄВтЫуЗЈРДЗжБ№ЯђЮвУЧЭЦМіХѓгбЁЂвЊЙКТђЕФЩЬЦЗКЭЕчгАЁЃ
Ъ§ОнМђЛЏЃКЪ§ОнМђЛЏЗНЗЈгУгкМђЛЏДгаэЖрЬиеїЕНЩйЪ§ЬиеїЕФЪ§ОнМЏЁЃЫќЪЙгУОпгааэЖрЪєадЕФДѓаЭЪ§ОнМЏЃЌВЂевЕНгУИќЩйЕФЪєадБэЪОЫќУЧЕФЗНЗЈЁЃ
ЛњЦїбЇЯАШЮЮёДгФЃаЭЕНЫуЗЈ
вЛЕЉЮвУЧНЋвЕЮёЮЪЬтЗжНтЮЊЛњЦїбЇЯАШЮЮёЃЌвЛИіЛђЖрИіЫуЗЈОЭПЩвдНтОіИјЖЈЕФЛњЦїбЇЯАШЮЮёЁЃЭЈГЃЃЌФЃаЭЪЧдкЖржжЫуЗЈЩЯбЕСЗЕФЁЃбЁдёЬсЙЉзюМбНсЙћЕФЫуЗЈЛђЫуЗЈМЏгУгкВПЪ№ЁЃ
Azure Machine LearningОпга30ЖржждЄЯШЙЙНЈЕФЫуЗЈЃЌПЩгУгкбЕСЗЛњЦїбЇЯАФЃаЭЁЃ
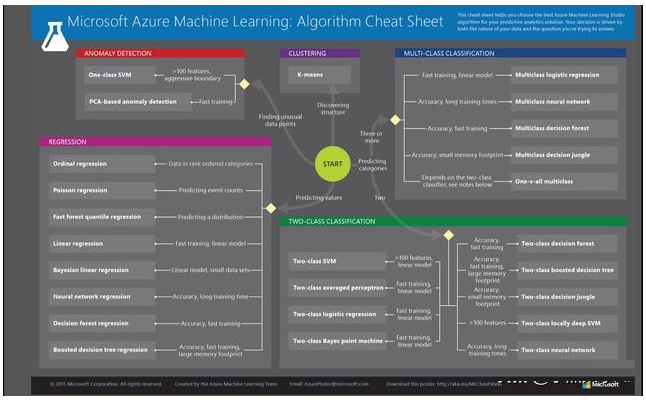
Azure Machine LearningБИЭќТМНЋгажњгкфЏРРЫќЁЃ
НсТл
Ъ§ОнПЦбЇЪЧвЛИіЙуРЋЕФСьгђЁЃетЪЧвЛИіСюШЫаЫЗмЕФСьгђЁЃетЪЧвЛУХвеЪѕЃЌетЪЧвЛУХПЦбЇЁЃдкБОЮФжаЃЌЮвУЧИеИеЬНЬжСЫБљЩНЕФБэУцЁЃШчЙћВЛжЊЕРЁАЮЊЪВУДЁБЃЌФЧУДЁАШчКЮЁБНЋЪЧЭНРЭЕФЁЃдкЫцКѓЕФЮФеТжаЃЌЮвУЧНЋЬНЬжЛњЦїбЇЯАЕФЁАдРэЁБЁЃ
|








