| БрМЭЦМі: |
БОЮФНЋЯъЯИНщЩмImpalaЪЧШчКЮдкВщбЏжДааЙ§ГЬжаДгHDFSЛёШЁЪ§Он,вВОЭЪЧImpalaжаHdfsScanNodeЕФЪЕЯжЯИНкЁЃ
БОЮФРДздЮЂаХЙЋжкКХЃКЪ§ОнЙмРэЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ImpalaЪЧвЛИіИпадФмЕФOLAPв§ЧцЃЌImpalaБОЩэжЛЪЧвЛИіOLAP-SQLв§ЧцЃЌЫќЗУЮЪЕФЪ§ОнДцДЂдкЕкШ§ЗНв§ЧцжаЃЌЕкШ§ЗНв§ЧцАќРЈHDFSЁЂHbaseЁЂkuduЁЃЖдгкHDFSЩЯЕФЪ§ОнЃЌImpalaжЇГжЖржжЮФМўИёЪНЃЌФПЧАПЩвдЗУЮЪParquetЁЂTEXTЁЂavroЁЂsequence
fileЕШЁЃЖдгкHDFSЮФМўИёЪНЃЌImpalaВЛжЇГжИќаТВйзїЃЌетжївЊЯожЦгкHDFSЖдгкИќаТВйзїЕФжЇГжБШНЯШѕЁЃБОЮФжївЊНщЩмImpalaЪЧШчКЮЗУЮЪHDFSЪ§ОнЕФЃЌImpalaЗУЮЪHDFSАќРЈШчЯТМИжжРраЭЃК1ЁЂЪ§ОнЗУЮЪЃЈВщбЏЃЉЃЛ2ЁЂЪ§ОнаДШыЃЈВхШыЃЉЃЛ3ЁЂЪ§ОнВйзїЃЈжиУќУћЁЂвЦЖЏЮФМўЕШЃЉЁЃЕзВуДцДЂв§ЧцЕФДІРэадФмжБНгОіЖЈзХSQLВщбЏЕФЫйЖШПьТ§ЃЌФПЧАImpala+ParquetИёЪНЮФМўДцДЂЕФВщбЏадФмзіЕНКмКУЃЌПЯЖЈЪЧгаЦфЖРЬиЕФЪЕЯждРэЕФЁЃБОЮФНЋЯъЯИНщЩмImpalaЪЧШчКЮдкВщбЏжДааЙ§ГЬжаДгHDFSЛёШЁЪ§Он,вВОЭЪЧImpalaжаHdfsScanNodeЕФЪЕЯжЯИНкЁЃ
Ъ§ОнЗжЧј
ImpalaжДааВщбЏЕФЪБЪзЯШдкFEЖЫНјааВщбЏНтЮіЃЌЩњГЩЮяРэжДааМЦЛЎЃЌНјЖјЗжИєГЩЖрИіFragmentЃЈзгВщбЏЃЉЃЌШЛКѓНЛгЩCoordinatorДІРэШЮЮёЗжЗЂЃЌCoordinatorдкзіШЮЮёЗжЗЂЕФЪБКђашвЊПМТЧЕНЪ§ОнЕФБОЕиадЃЌЫќашвЊвРРЕгкУПвЛИіЮФМўЫљдкЕФДцДЂЮЛжУЃЈдкФФИіDataNodeЩЯЃЉЃЌетвВОЭЪЧЮЊЪВУДЭЈГЃНЋImpaladНкЕуВПЪ№дкDataNodeЭЌвЛХњЛњЦїЩЯЕФдвђЃЌЮЊСЫНвПЊImpalaЗУЮЪHDFSЕФУцЩДашвЊЯШДгImpalaШчКЮЗжХфЩЈУшШЮЮёЫЕЦ№ЁЃ
жкЫљжмжЊЃЌЮоТлЪЧMapReduceШЮЮёЛЙЪЧSparkШЮЮёЃЌЫќУЧжДааЕФжЎЧАЖМашвЊдкПЭЛЇЖЫНЋЪфШыЮФМўНјааЗжИюЃЌШЛКѓУПвЛИіTaskДІРэвЛЖЮЪ§ОнЗжЦЌЃЌДгЖјДяЕНВЂааДІРэЕФФПЕФЁЃImpalaЕФЪЕЯжвВЪЧРрЫЦЕФдРэЃЌдкЩњГЩЮяРэжДааМЦЛЎЕФЪБКђЃЌImpalaИљОнЪ§ОнЫљдкЕФЮЛжУНЋFragmentЗжХфЕНЖрИіBackend
ImpaladНкЕуЩЯжДааЃЌФЧУДетРяДцдкСНИіКЫаФЕФЮЪЬтЃК
ImpalaШчКЮЛёШЁУПвЛИіЮФМўЕФЮЛжУЃП
ШчКЮИљОнЪ§ОнЮЛжУЗжХфзгШЮЮёЃП
дкжЎЧАНщЩмЕФImpalaЕФзмЬхМмЙЙПЩвдПДЕНЃЌCatalogdНкЕуИКд№ећИіЯЕЭГЕФдЊЪ§ОнЃЌдЊЪ§ОнЪЧвдБэЮЊЕЅЮЛЕФЃЌетаЉдЊЪ§ОнОпгавЛИіВуМЖЕФЙиЯЕЃЌШчЯТЭМЫљЪО
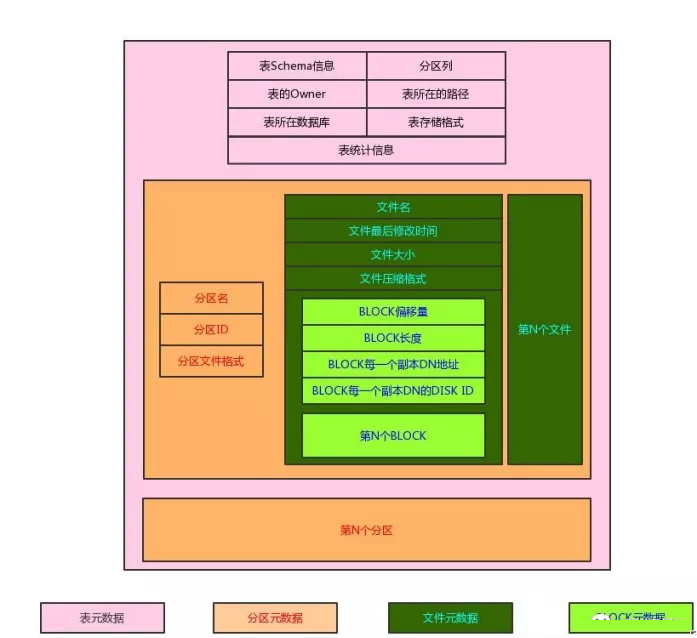
ImpalaБэдЊЪ§ОнНсЙЙ
УПвЛИіБэАќКЌШчЯТдЊЪ§ОнЃЈжЛбЁШЁБОЮФашвЊгУЕНЕФЃЉЃК
1.schemaаХЯЂЃКИУБэжаАќКЌФФаЉСаЃЌУПвЛСаЕФРраЭЪЧЪВУДЕШ
2.БэЪєадаХЯЂЃКгЕгаепЁЂЪ§ОнПтУћЁЂЗжЧјСаЁЂБэЕФИљТЗОЖЁЂБэДцДЂИёЪНЁЃ
3.БэЭГМЦаХЯЂЃКжївЊАќРЈБэжазмЕФМЧТМЪ§ЁЂЫљгаЮФМўзмДѓаЁЁЃ
4.ЗжЧјаХЯЂЃКУПвЛИіЗжЧјЕФЯъЯИаХЯЂЁЃ
УПвЛИіЗжЧјАќКЌШчЯТаХЯЂЃК
1.ЗжЧјУћЃКгЩЫљгаЕФЗжЧјСаКЭУПвЛСаЖдгІЕФжЕЮЈвЛШЗЖЈЕФ
2.ЗжЧјЮФМўИёЪНЃКУПвЛИіЗжЧјПЩвдЪЙгУВЛЭЌЕФЮФМўИёЪНДцДЂЃЌНтЮіЪБИљОнИУИёЪНЖјЗЧБэжаЕФЮФМўДцДЂИёЪНЃЌШчЙћДДНЈЗжЧјЪБВЛжИЖЈдђЮЊБэЕФДцДЂИёЪНЁЃ
3.ЗжЧјЕФЫљгаЮФМўаХЯЂЃКБЃДцСЫИУЗжЧјЯТУПвЛИіЮФМўЕФЯъЯИаХЯЂЃЌетвВЕМжТСЫжиаТаДШыЪ§ОнжЎКѓашвЊREFRESHБэЁЃ
УПвЛИіЮФМўАќКЌШчЯТЕФаХЯЂЃК
1.ИУЮФМўЕФЛљБОаХЯЂЃКЭЈЙ§FileStatusЖдЯѓБЃДцЃЌАќРЈЮФМўУћЁЂЮФМўДѓаЁЁЂзюКѓаоИФЪБМфЕШЁЃ
2.ЮФМўЕФбЙЫѕИёЪНЃКИљОнЮФМўУћЕФКѓзКОіЖЈЁЃ
3.ЮФМўжаУПвЛИіBLOCKЕФаХЯЂЃКвђЮЊHDFSДцДЂЮФМўЪЧАДееBLOCKНјааЛЎЗжЕФЃЌвђДЫImpalaвВЭЌбљДцДЂУПвЛИіПщЕФаХЯЂЁЃ
УПвЛИіBLOCKАќКЌШчЯТЕФаХЯЂЃК
1.етИіBLOCKДІгкЮФМўЕФЦЋвЦСПЁЂBLOCKГЄЖШЁЃ
2.етИіBLOCKЫљдкЕФDatanodeНкЕуЃКУПвЛИіBLOCKФЌШЯЛсБЛДцДЂЖрИіИББОЃЌЗжВМдкВЛЭЌЕФDatanodeЩЯЁЃ
3.етИіBLOCKЫљдкЕФDatanodeЕФDiskаХЯЂЃКетИіBLOCKДцДЂдкЖдгІЕФDatanodeЕФФФвЛПщДХХЬЩЯЃЌШчЙћВщбЏВЛЕНдђЗЕЛи-1БэЪОЮДжЊЁЃ
ШЮЮёЗжЗЂ
ДгЩЯУцЕФдЊЪ§ОнУшЪіПЩвдНтД№ЮвУЧЕФЕквЛИіЮЪЬтЃЌУПвЛИіБэЫљгЕгаЕФШЋВПЮФМўаХЯЂЖМдкБэМгдиЕФЪБКђгЩImpalaЛКДцВЂЧвЭЈЙ§statestoredЭЌВНЕНУПвЛИіimpaladНкЕуЛКДцЃЌдкimpaladЩњГЩHdfsScanNodeНкЕуЪБЛсЪзЯШИљОнИУБэЕФЙ§ТЫЬѕМўЙ§ТЫЕєВЛБивЊЕФЗжЧјЃЈЗжЧјМєжІЃЉЃЌШЛКѓБщРњУПвЛИіашвЊДІРэЗжЧјЮФМўЃЌЛёШЁУПвЛИіашвЊДІРэЕФBLOCKЕФЛљБОаХЯЂКЭЮЛжУаХЯЂЃЌЗЕЛиИјCoordinatorзїЮЊЗжХфHdfsScanNodeЕФЪфШыЁЃетРяЛЙгавЛИіЮЪЬтЃКУПвЛИіЗжХфЕФrangeЪЧЖрДѓФиЃПетИівРРЕгкВщбЏЕФХфжУЯюMAX_SCAN_RANGE_LENGTHЃЌетИіХфжУЯюБэЪОУПвЛИіЩЈУшЕФЕЅдЊЕФзюДѓГЄЖШЃЌИљОнИУХфжУЯюЕУЕНУПвЛИіrangeЕФДѓаЁЮЊЃК
1.MAX_SCAN_RANGE_LENGTH ЃК ШчЙћХфжУСЫИУХфжУЯюВЂЧвИУХфжУЯюаЁгкBLOCKДѓаЁЁЃ
2.BLOCKДѓаЁ ЃК ШчЙћХфжУСЫMAX_SCAN_RANGE_LENGTHЕЋЪЧИУХфжУжЕДѓгкHDFSЕФBLOCKДѓаЁЁЃ
3.BLOCKДѓаЁ ЃК ШчЙћУЛгаХфжУMAX_SCAN_RANGE_LENGTH
4.ећИіЮФМўДѓаЁ ЃК ШчЙћЮФМўЕФДѓаЁаЁгквЛИіHDFSЕФBLOCKДѓаЁЁЃ
ЕНетвЛВНЕУЕНСЫУПвЛИіHdfsScanNodeЩЈУшЕФrangeСаБэЃЌУПвЛИіrangeАќКЌЫљЪєЕФЮФМўЁЂИУrangeЕФЦ№ЪМЦЋвЦСПКЭГЄЖШЃЌвдМАИУrangeЫљЪєЕФBLOCKЫљдкЕФDataNodeЕижЗЁЂдкDataNodeЕФDisk
idвдМАИУBLOCKЪЧЗёвбБЛHDFSЛКДцЕШаХЯЂЁЃ
ЭъГЩСЫSQLНтЮіЃЌCoordinatorЛсИљОнЗжХфЕФзгШЮЮёЃЈБОЮФжЛЙиаФHdfsScanNodeЃЉКЭЪ§ОнЗжВМНјааШЮЮёЕФЗжЗЂЃЌЗжЗЂЕФТпМгЩCoordinatorЕФScheduler::
ComputeScanRangeAssignmentКЏЪ§ЭъГЩЃЌгЩгкУПвЛИіrangeАќКЌСЫДцДЂЮЛжУЃЌImpalaЛсЪзЯШИљОнУПвЛИіBLOCKЪЧЗёвбБЛЛКДцЃЌЛђепЪЧЗёДцДЂдкФГвЛИіimpaladБОЕиНкЕуЩЯЃЌЧАепБэЪОПЩвджБНгДгЛКДцЃЈФкДцЃЉжаЖСШЁЪ§ОнЃЌКѓепвтЮЖзХПЩвдЭЈЙ§shortcutЕФЗНЪНЖСШЁHDFSЪ§ОнЃЌетРяашвЊЬсЕНвЛИіЖСШЁОрРыЕФИХФюЃЌImpalaжаНЋОрРыДгНќЕНдЖЗжЮЊШчЯТМИжжЃК
1.CACHE_LOCAL : ИУrangeвбЛКДцЃЌВЂЧвЛКДцЕФDataNodeЪЧвЛИіimpaladНкЕу
2.CACHE_RACK : ИУrangeвбЛКДцЃЌВЂЧвЛКДцдкЯрЭЌЛњМмЕФDataNodeЩЯЃЌФПЧАУЛгаЪЙгУЁЃ
3.DISK_LOCAL : ИУrangeПЩвдДгБОЕиЖСШЁЃЌвтЮЖзХИУBLOCKЫљдкЕФDataNodeКЭДІРэИУBLOCKЕФimpalaдкЭЌвЛИіЛњЦїЩЯЁЃ
4.DISK_RACK : ИУrangeПЩвдДгЭЌвЛИіЛњМмЕФДХХЬЖСШЁЃЌФПЧАУЛгаЪЙгУЁЃ
5.REMOTE : ИУrangeВЛФмЭЈЙ§БОЕиЖСШЁЃЌжЛФмЭЈЙ§HDFSдЖГЬЖСШЁЕФЗНЪНЛёШЁЁЃ
ПЭЛЇЖЫВщбЏЕФЪБКђПЩвдЩшжУREPLICA_PREFERENCEХфжУЯюЃЌИУХфжУЯюБэЪОБОДЮВщбЏИќЧуЯђгкЪЙгУФФжжОрРыЕФИББОЃЌФЌШЯЮЊ0БэЪОCACHE_LOCALЃЌЦфЫћЕФХфжУга3КЭ5ЃЌЗжБ№БэЪОDISK_LOCALКЭREMOTEЁЃСэЭтПЩвдХфжУDISABLE_CACHED_READSЩшжУЪЧЗёПЩвдДгЛКДцжаЖСШЁЃЌГ§ДЫжЎЭтЃЌПЩвддкSQLЕФhintsжаЩшжУФЌШЯЖСШЁЕФОрРыЁЃзюКѓЃЌПЩвддкSQLЕФhintsжаЩшжУЪЧЗёЫцЛњбЁдёИББОЃЌгаСЫетСНИіХфжУНгЯТРДОЭПЩвдИљОнrangeЕФЮЛжУМЦЫуУПвЛИіrangeгІИУБЛФФИіimpaladДІРэЁЃ
ДІРэrangeЕФЗжХфЪзЯШашвЊМЦЫуГіИУrangeЕФзюЖЬОрРыЃЌЗжЮЊСНжжЧщПіЃК
1.ШчЙћзюЖЬЕФОрРыЪЧREMOTEЃЌБэЪОИУrangeЫљдкЕФDataNodeУЛгаВПЪ№impaladНкЕуЃЌетжжrangeДгЫљгаimpaladжабЁдёвЛИіФПЧАвбЗжХфЕФrangeзжНкЪ§зюЩйЕФimpaladЁЃ
2.CACHE_LOCALКЭDISK_LOCALЕФЧјБ№дкгкЧАепПЩвдЫцЛњбЁдёЃЌДЫЪБПЩвдДгЫљгаТњзуЬѕМўЕФИББОЃЈИУИББОЕФОрРыЕШгкзюЖЬОрРыЃЉЫцЛњбЁдёвЛИіimpaladЗжХфЃЌЗёдђЗжХфЕНвбЗжХфЕФзжНкЪ§зюЩйЕФimpaladЁЃ
НВЕНетРяЃЌвВОЭЛиД№СЫЩЯУцЕФЕкЖўИіЮЪЬтЃЌImpalaИљОнУПвЛИіrangeЫљдкЕФЮЛжУЗжХфЕНimpaladЩЯЃЌОЁПЩФмЕФзіЕНrangeЕФЗжХфИќОљКтВЂЧвОЁПЩФмЕФДгБОЕиЩѕжСЛКДцжаЖСШЁЁЃНгЯТРДашвЊПДвЛЯТHdfsScanNodeЪЧШчКЮдЫааЕФЁЃ
HdfsScanNodeЕФЪЕЯж
ЧАУцЮвУЧЬсЕНЙ§ЃЌHdfsScanNodeЕФзїгУЪЧДгБЃДцдкHDFSЩЯЕФЬиЖЈИёЪНЕФЮФМўЖСШЁЪ§ОнЃЌШЛКѓЖдЦфНјааНтЮізЊЛЛГЩвЛЬѕЬѕМЧТМЃЌНЋЫќУЧДЋЕнИјИИжДааНкЕуДІРэЃЌвђДЫЯТУцНщЩмЕФЙ§ГЬжївЊЪЧдквбжЊЩЈУшФФаЉЪ§ОнЕФЧщПіЯТЗЕЛиЫљгаашвЊЛёШЁЕФМЧТМЁЃдкетжЎЧАЃЌПЩвдЯШПДвЛЯТBEФЃПщЕФScanNodeЕФРрНсЙЙЃК
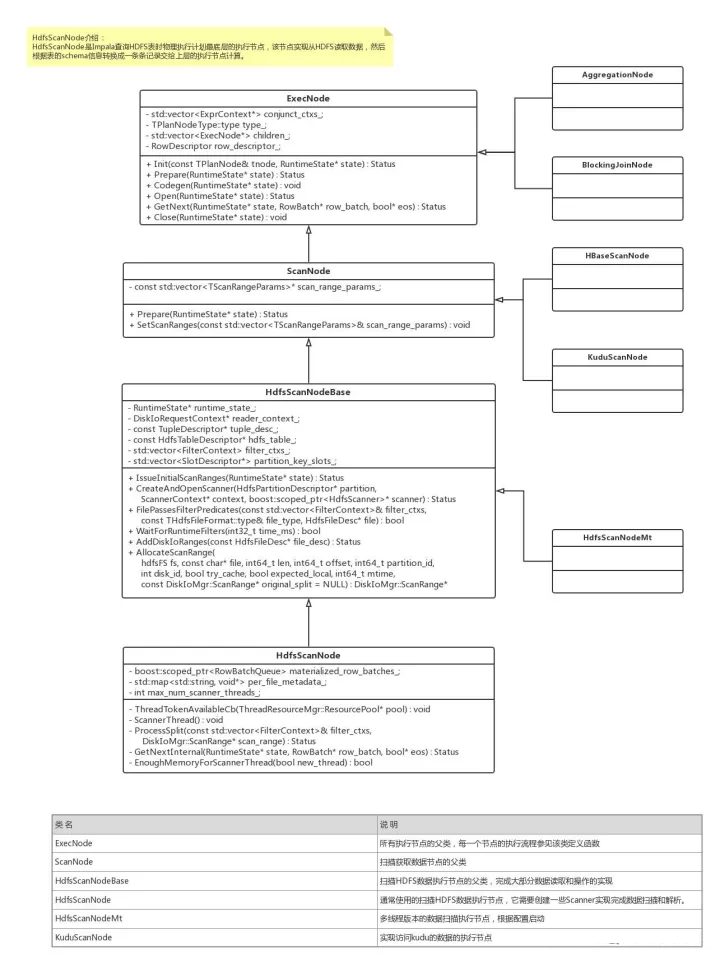
ImpalaжДааНкЕуРрВуДЮ
МЏКЯЩЯЭМКЭImpalaжДааТпМЃЌSQLЩњГЩЕФЮяРэжДааМЦЛЎжаУПвЛИіНкЕуЖМЪЧExecNodeЕФзгРрЃЌИУРрЬсЙЉСЫ6ИіНгПкЃК
InitКЏЪ§ЃКИУКЏЪ§дкДДНЈExecNodeНкЕуЕФЪБКђБЛЕїгУЃЌВЮЪ§ЗжБ№ЪЧИУжДааНкЕуЕФЯъЯИУшЪіаХЯЂКЭећИіFragmentЕФЩЯЯТЮФЁЃHdfsScanNodeГѕЪМЛЏЕФЪБКђЛсНтЮіruntime
filterаХЯЂКЭВщбЏжажИЖЈЕФИУБэЕФfilterЬѕМўЁЃСэЭтЛЙГѕЪМЛЏвЛаЉИУНкЕуЕФЭГМЦжИБъЁЃ
PrepareКЏЪ§ЃКИУКЏЪ§дкFragmentжДааPrepareКЏЪ§ЕФЪБКђЕнЙщЕФЕїгУИУзгЪїЫљгаНкЕуЕФPrepareКЏЪ§ЃЌHdfsScanNodeЕФPrepareКЏЪ§ГѕЪМЛЏИУБэЕФУшЪіаХЯЂвдМАашвЊЖСШЁВЂНЛИјИИНкЕуЕФМЧТМАќКЌФФаЉСаЃЌГѕЪМЛЏУПвЛИіrangeЩЈУшЕФаХЯЂЃЈДДНЈHdfs
handlerЕШЃЉЁЃ
CodegenКЏЪ§ЃКИУКЏЪ§ЪЕЯжУПвЛИіНкЕуЕФcodegenЃЌImpalaРћгУLLVMЪЕЯжcodegenЕФЙІФмЃЌМѕЩйащКЏЪ§ЕФЕїгУЃЌвЛЖЈГЬЖШЩЯЬсЩ§СЫВщбЏадФмЃЌHdfsScanNodeдкCodegenжаЩњГЩУПвЛжжЮФМўИёЪНЕФcodegenЁЃ
OpenКЏЪ§ЃКИУКЏЪ§дкжДаажЎЧАБЛЕїгУЃЌЭъГЩжДаажЎЧАЕФГѕЪМЛЏЙЄзїЃЌдкHdfsScanNodeЕФOpenКЏЪ§жаГѕЪМЛЏзюДѓЕФscannerЯпГЬЪ§ЃЌВЂЧвзЂВсThreadTokenAvailableCbКЏЪ§гУгкЦєЖЏаТЕФscannerЯпГЬЁЃ
GetNextКЏЪ§ЃКИУКЏЪ§УПДЮЪфГівЛИіrow_batchЃЌВЂЧвДЋШыeosБфСПгУгкЩшжУИУНкЕуЪЧЗёжДааЭъГЩЃЌHdfsScanNodeЛсБЛИИНкЕубЛЗЕФЕїгУЃЌУПДЮЗЕЛивЛИіrow_batchЁЃ
ClodeКЏЪ§ЃКИУКЏЪ§дкЭъГЩЪББЛЕїгУЃЌДІРэвЛаЉзЪдДЪЭЗХКЭЭГМЦЕФВйзїЁЃ
ЖдгкУПвЛИіExecNodeЃЌеце§жДааТпМвЛАуЪЧдкOpenКЭGetNextКЏЪ§жаЃЌдкHdfsScanNodeНкЕужавВЪЧШчДЫЃЌИеВХЬсЕНOpenКЏЪ§жаЛсзЂВсвЛИіЛиЕїКЏЪ§ЃЌИУКЏЪ§БЛЕїгУЪБЛсХаЖЯЕБЧАЪЧЗёашвЊЦєЖЏаТЕФscannerЯпГЬЃЌФЧУДЪЧscannerЯпГЬгжЪЧЪВУДФиЃПетРяОЭашвЊНщЩмвЛЯТimpaladжДааЪ§ОнЩЈУшЕФФЃаЭЃЌimpaladжДааЙ§ГЬжаЛсНЋЪ§ОнЖСШЁКЭЪ§ОнЩЈУшЗжПЊЃЌЪ§ОнЖСШЁЪЧжИДгдЖГЬHDFSЛђепБОЕиДХХЬЖСШЁЪ§ОнЃЌЪ§ОнЩЈУшЪЧжИЛљгкЖСШЁЕФдЪМЪ§ОнЖдЦфНјаазЊЛЛЃЌзЊЛЛжЎКѓЕФОЭЪЧвЛЬѕЬѕМЧТМЪ§ОнЁЃЫќУЧЕФЯпГЬФЃаЭКЭЙиЯЕШчЯТЭМЫљЪОЃК
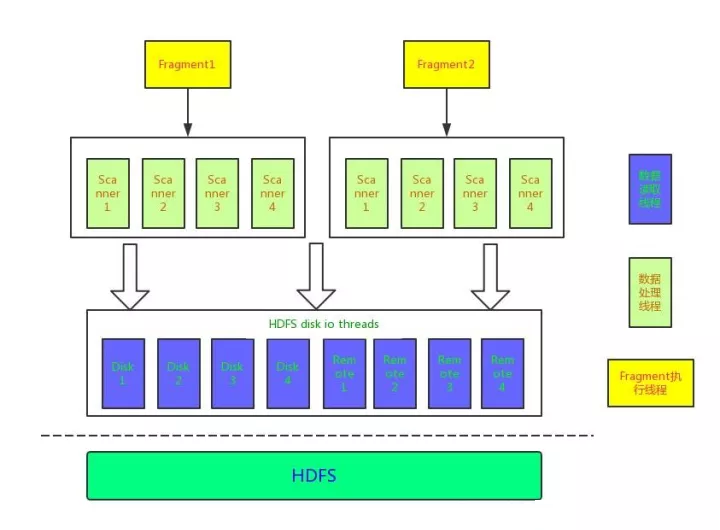
ImpalaЪ§ОнДІРэЯпГЬФЃаЭ
ЮвУЧДгЯТЭљЩЯПДетИіДІРэФЃаЭЃЌзюЕзВуЕФЯпГЬГиЪЧHDFSЪ§ОнI/OЯпГЬГиЃЌетИіЯпГЬГидкimpaladГѕЪМЛЏЕФЪБКђЦєЖЏКЭГѕЪМЛЏЃЌimpaladНЋетаЉЯпГЬЗжЮЊБОЕиДХХЬЯпГЬКЭдЖГЬЗУЮЪЪ§ОнЯпГЬЃЌБОЕиДХХЬЯпГЬашвЊЮЊУПвЛИіДХХЬЦєЖЏвЛзщЯпГЬЃЌЫќИљОнЯЕЭГХфжУnum_threads_per_diskЯюОіЖЈЃЌФЌШЯЧщПіЯТЖдгкУПвЛИіЛњаЕДХХЬЦєЖЏ1ИіЯпГЬЃЌетбљПЩвдБмУтДѓСПЕФЫцЛњЖСШЁЃЈБмУтДѓСПЕФДХХЬбАЕРЃЉЃЛЖдгкFLASHДХХЬЃЈSSDЃЉЃЌФЌШЯЧщПіЖдгкУПвЛПщДХХЬЦєЖЏ8ИіЯпГЬЁЃдЖГЬЪ§ОнЗУЮЪЯпГЬЪ§гЩЯЕЭГХфжУnum_remote_hdfs_io_threadsОіЖЈЃЌФЌШЯЧщПіЯТЦєЖЏ8ИіЯпГЬЃЌУПвЛИіЯпГЬгЕгавЛИізшШћЖгСаЃЌScannerЯпГЬЭЈЙ§ДЋЕнЙВЯэБфСПScanRangeЖдЯѓЃЌИУЖдЯѓАќКЌЖСШЁЪ§ОнЕФЪфШыЃКЮФМўЁЂrangeЕФЦЋвЦСПЃЌrangeЕФГЄЖШЃЌДХХЬIDЕШЃЌдкЖСШЁЕФЙ§ГЬжаЛсЯђИУЖдЯѓжаЬюГфЖСШЁЕФвЛИіИіФкДцПщЃЌФкДцПщЕФДѓаЁОіЖЈСЫУПДЮДгHDFSжаЖСШЁЕФЪ§ОнЕФДѓаЁЃЌФЌШЯЪЧ8MBЃЈЯЕЭГХфжУЯюread_sizeХфжУЃЉЃЌВЂЧвдкScanRangeЖдЯѓжаМЧТМБОЕиЖСШЁЪ§ОнКЭдЖГЬЖСШЁЪ§ОнДѓаЁЃЌБугкЩњГЩИУВщбЏЕФЭГМЦаХЯЂЁЃ
НЋЪ§ОнЖСШЁКЭЪ§ОнНтЮіЗжРыЪЧЮЊСЫБЃжЄБОЕиДХХЬЖСаДЕФЫГађадвдМАдЖГЬЪ§ОнЖСШЁВЛеМгУЙ§СПЕФCPUЃЌЖјScannerЯпГЬЕФжДааашвЊвРРЕгкDiskЯпГЬЃЌScannerЯпГЬЕФЦєЖЏЪЧгЩЛиЕїКЏЪ§ThreadTokenAvailableCbДЅЗЂЕФЃЌЮвУЧЯТУцдкзіНщЩмЃЌЕБЕїгУgetNextЗНЗЈЛёШЁвЛИіИіrow_batchЪБЃЌHdfsScanNodeЛсХаЖЯЪЧЗёЪЧЕквЛДЮЕїгУЃЌШчЙћЪЧЕквЛДЮЕїгУЛсДЅЗЂЫљгаашвЊЩЈУшЕФrangeЕФЧыЧѓЯТЗЂЕНDisk
I/OЯпГЬГиЃЌЩЈУшВйзїашвЊИљОнЮФМўРраЭЩЈУшВЛЭЌЕФЧјгђЃЌР§ШчЖдгкparquetзмЪЧашвЊЩЈУшЮФМўЕФfooterаХЯЂЁЃетРяашвЊЬсЕНвЛИіВхЧњЃЌШчЙћИУБэашвЊЪЙгУruntime
filterашвЊдкЩЈУшЮФМўжЎЧАЕШД§runtime filterЕНДяЃЈГЌЪБЪБМфФЌШЯЪЧ1sЃЉЁЃ
ЮвУЧПЩвдМйЩшЃЌдкЕквЛИіgetNextЕїгУжЎКѓЃЌЫљгаЕФЪ§ОнЖМвбОБЛЖСШЁСЫЃЌЫфШЛПЩФмгаЕФrangeЕФЪ§ОнЖСШЁБЛblockСЫЃЈПЩФмЮДБЛЕїЖШЛђепФкДцвбОЪЙгУЕНСЫЩЯЯпЃЉЃЌЕЋЪЧетаЉЖдгкscannerЯпГЬЪЧЭИУїЕФЃЌscannerЯпГЬжЛашвЊДгreadercontextЖдЯѓжаЛёШЁвбЖСШЁЕФЪ§ОнЃЈЛёШЁЪ§ОнЕФВйзїПЩФмзшШћЃЉНјааНтЮіЕФДІРэЁЃЕНетРяЃЌЪ§ОнвбОБЛI/OЯпГЬЖСШЁСЫЃЌФЧУДЪВУДЪБКђЛсЦєЖЏScannerЯпГЬФиЃП
Ъ§ОнНтЮіКЭДІРэ
ЧАУцЬсЕНScannerЯпГЬЕФЦєЖЏЪЧThreadTokenAvailableCbКЏЪ§ДЅЗЂЕФЃЌЕБУПДЮЯђDiskЯпГЬГижаЧыЧѓRangeScanЧыЧѓЪБЛсДЅЗЂИУКЏЪ§ЃЌИУКЏЪ§ашвЊИљОнЕБЧАFragmentКЭЯЕЭГжазЪдДЪЙгУЕФЧщПіОіЖЈЦєЖЏЖрЩйScannerЯпГЬЃЌЕБУПвЛИіScannerЯпГЬжДааЭъГЩжЎКѓЛсжиаТДЅЗЂИУЛиЕїКЏЪ§ЦєЖЏаТЕФScannerЯпГЬЁЃУПвЛИіScannerЯпГЬЗжХфвЛИіScanRangeЖдЯѓЃЌИУЖдЯѓжаБЃДцСЫвЛИіЗжЧјЕФШЋВПЪ§ОнЁЃзюКѓЕїгУProcessSplitКЏЪ§ЃЌИУКЏЪ§ДІРэетИіЗжЧјЕФЪ§ОнНтЮіЁЃ
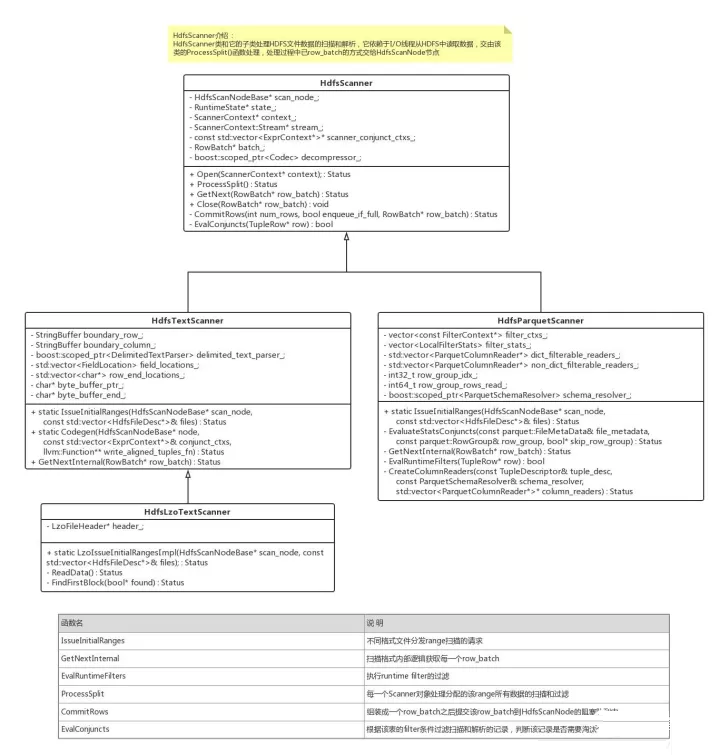
HDFSЮФМўЪ§ОнДІРэРрВуДЮ
ЩЯЭМУшЪіСЫВЛЭЌHDFSЮФМўРраЭЕФScannerРрНсЙЙЃЌВЛЭЌЕФЮФМўРраЭЪЙгУВЛЭЌЕФScannerНјааЩЈУшКЭНтЮіЃЌетРяЮвУЧвдБШНЯМђЕЅЕФTEXTИёЪНЮЊР§РДЫЕУїИУСїГЬЃЌTEXTИёЪНЕФБэашвЊдкНЈБэЕФЪБКђжИЖЈааЗжИєЗћЁЂСаЗжИєЗћЕШдЊЪ§ОнЃЌЗжЧјЪ§ОнЕФНтЮівРРЕгкетаЉЗжИєЗћХфжУЁЃЮЊСЫЬсЩ§НтЮіадФмЃЌImpalaЪЙгУСЫCodegenМЦЪ§КЭSSE4жИСюЃЌЕЋЪЧгЩгкЗжЧјЕФЛЎЗжЪЧАДееBLOCKРДЕФЃЌЖјУПвЛИіBLOCKОјДѓВПЗжЧщПіЯТЦфЪЕКЭНсЪјЖМДІгквЛЬѕМЧТМЕФжаМфЃЌЖјЧвУПДЮЖСШЁЪ§ОнЕФЛКДцЪЧ8MBДѓаЁЃЌУПвЛПщЛКДцжаЕФЪ§ОнЛЙЪЧПЩФмДІгкМЧТМЕФжаМфЃЌетаЉЧщПіЖМашвЊЬиЪтДІРэЁЃImpalaДІРэУПвЛИіЗжЧјЕФЪБКђЪзЯШЩЈУшЕНИУЗжЧјЕФЕквЛЬѕМЧТМЃЌЕБДІРэЭъГЩИУЗжЧјЃЌШчЙћЗжЧјЕФНсЮВЪЧвЛЬѕВЛЭъећЕФМЧТМдђМЬајЭљЯТЩЈУшЕНИУМЧТМНсЪјЮЛжУЁЃЖје§ГЃЧщПіЯТЃЌScannerжЛашвЊИљОнааЗжИєЗћНтЮіГіУПвЛааЃЌЖдгкУПвЛааИљОнашвЊНтЮіЕФСаНЋЦфБЃДцЃЌЖјжБНгЬјЙ§ВЛашвЊНтЮіЕФСаЃЌЕЋЪЧЖдгкTEXTетжжааЪНДцДЂЕФЮФМўИёЪНашвЊЪзЯШЖСШЁШЋВПЕФЪ§ОнЃЌШЛКѓБщРњШЋВПЕФЪ§ОнЃЌЖјЖдгкParquetжЎРрЕФСаЪНДцДЂЃЌЫфШЛвВашвЊЖСШЁУПвЛИіЗжЧјЕФЪ§ОнЃЌЕЋЪЧгЩгкУПвЛСаЕФЪ§ОнДцДЂдквЛЦ№ЃЌЩЈУшЕФЪБКђжЛашвЊЩЈУшашвЊЕФСаЁЃетВХЪЧСаЪНДцДЂПЩвдМѕЩйЪ§ОнЕФЩЈУшЃЌЖјВЛЪЧНЯЩйЪ§ОнЕФЖСШЁЁЃЕБШЛParquetЮФМўвЛАуЪЙгУЪ§ОнбЙЫѕЫуЗЈЪЙЕУЪ§ОнСПдЖаЁгкTEXTИёЪНЁЃ
ЮоТлЪЧФФжжЮФМўИёЪНЃЌЭЈЙ§НтЮіЦїНтЮіГівЛЬѕЬѕМЧТМЃЌУПвЛЬѕМЧТМжажЛАќКЌИУБэашвЊЖСШЁЕФСаЕФФкШнЃЌзщзАГЩвЛЬѕМЧТМжЎКѓЛсЭЈЙ§ИУБэЕФfilterЬѕМўКЭruntime
filterХаЖЯИУЬѕМЧТМЪЧЗёашвЊБЛЬдЬЁЃПЩвдПДГіЃЌScanNodeжДааСЫProjectКЭЮНДЪЯТЭЦЕФЙІФмЁЃЫљгаУЛБЛЬдЬЕФМЧТМАДееrow_batchЕФНсЙЙзщзАдквЛЦ№ЃЌУПвЛИіrow_batchФЌШЯЧщПіЯТЪЧ1024ааЃЌВщбЏПЭЛЇЖЫПЩвдЪЙгУBATCH_SIZEХфжУЯюЩшжУЁЃЕЋЪЧЙ§ДѓЕФrow_batchДѓаЁашвЊеМгУИќДѓЕФФкДцЃЌПЩФмНЕЕЭExecNodeжЎМфЕФВЂЗЂЖШЃЌвђЮЊExecNodeашвЊЕШЕНзгНкЕуЭъГЩвЛИіrow_batchЕФзщзАВХНјааБОНкЕуЕФМЦЫуЁЃгЩгкScanВйзїЪЧгЩScannerЯпГЬжаЭъГЩЕФЃЌУПДЮScannerзщзАЭъГЩжЎКѓНЋЦфЗХЕНвЛИіBlockingQueueжаЃЌЕШД§ИИНкЕуДгИУQueueжаЛёШЁНјааздЩэЕФДІРэТпМЃЌЕБШЛПЩФмДцдкИИНкЕуКЭзгНкЕужДааЦЕТЪВЛвЛжТЕФЧщПіЃЌЕМжТBlockingQueueЖгСаБЛЗХТњЃЌДЫЪБScannerЯпГЬНЋБЛзшШћЃЌВЂЧввВВЛЛсДДНЈаТЕФScannerЯпГЬЁЃ
Ъ§ОнбЙЫѕ
зюКѓЮвУЧМђЕЅЕФСФвЛЯТЮФМўбЙЫѕЃЌЭЈГЃдкСФЕНOLAPгХЛЏЗНЪНЕФЪБКђЖМЛсЬсЕНЪ§ОнбЙЫѕЃЌЯрЭЌЕФЪ§ОнбЙЫѕжЎКѓПЩвдгаКмДѓГЬЖШЕФЪ§ОнЬхЛ§ЕФНЕЕЭЃЌЕЋЪЧЭЈЙ§бЇЯАimpalaЕФЪ§ОнЖСШЁСїГЬЃЌimpalaЭЈЙ§ЮФМўУћЕФКѓзКХаЖЯЮФМўЪЙгУСЫФФжжбЙЫѕЫуЗЈЃЌЖдгкЪЙгУСЫбЙЫѕЕФЮФМўЃЌЫфШЛЖСШЁЕФЪ§ОнСПМѕЩйСЫаэЖрЃЌЕЋЪЧашвЊЯћКФДѓСПЕФCPUзЪдДНјааНтбЙЫѕЃЌНтбЙЫѕжЎКѓЕФЪ§ОнЦфЪЕКЭЗЧбЙЫѕЕФЪ§ОнЪЧвЛбљЕФЃЌвђДЫЖдгкНтЮіВйзїДІРэЕФЪ§ОнСПСНепВЂУЛгаШЮКЮВювьЁЃвђДЫЪЙгУЪ§ОнбЙЫѕжЛВЛЙ§ЪЧвЛИіI/OзЪдДЛЛШЁCPUзЪдДЕФГЃгУЪжЖЮЃЌЕБвЛИіМЏШКжаI/OИКдиБШНЯИпПЩвдПМТЧЪЙгУЪ§ОнбЙЫѕНЕЕЭI/OЯћКФЃЌЖјЯрЗДCPUИКдиБШНЯИпЕФЯЕЭГдђЭЈГЃВЛашвЊНјааЪ§ОнбЙЫѕЁЃ
змНс
КУСЫЃЌдкНсЪјжЎЧАЮвУЧзмНсвЛЯТImpalaЖСШЁHDFSЪ§ОнЕФТпМЃЌЪзЯШImpalaЛсНЋЪ§ОнЩЈУшКЭЪ§ОнЖСШЁЯпГЬЗжРыЃЌImpaladдкЦєЖЏЕФЪБКђГѕЪМЛЏЫљгаДХХЬКЭдЖГЬHDFSЗУЮЪЕФЯпГЬЃЌетаЉЯпГЬИКд№ЫљгаЪ§ОнЗжЧјЕФЖСШЁЁЃImpalaЖдгкУПвЛИіSQLВщбЏИљОнБэЕФдЊЪ§ОнаХЯЂЖдУПвЛИіБэЩЈУшЕФЪ§ОнНјааЗжЧјЃЈОЙ§ЗжЧјМєжІжЎКѓЃЉЃЌВЂМЧТМУПвЛИіЗжЧјЕФЮЛжУаХЯЂЁЃBEИљОнУПвЛИіЗжЧјЕФЮЛжУаХЯЂЖдзгШЮЮёНјааЗжХфЃЌОЁПЩФмБЃжЄЪ§ОнЕФБОЕиЖСШЁКЭШЮЮёЗжХфЕФОљКтадЁЃУПвЛИізгШЮЮёНЛИјВЛЭЌЕФBackendФЃПщжДааЃЌЪзЯШЛсЮЊзгШЮЮёДДНЈжДааЪїЃЌHdfsScanNodeНкЕуИКд№Ъ§ОнЕФЖСШЁКЭЩЈУшЃЌЭЈГЃЪЧжДааЪїЕФКЂзгНкЕуЃЌжДааЪБЪзЯШНЋИУHdfsScanNodeашвЊЩЈУшЕФЗжЧјЧыЧѓDisk
I/OЯпГЬГижДааЪ§ОнЖСШЁЃЌШЛКѓДДНЈScannerЯпГЬДІРэЪ§ОнЩЈУшКЭНтЮіЃЌНтЮіЪБИљОнВЛЭЌЕФЮФМўРраЭДДНЈГіВЛЭЌЕФScannerЖдЯѓЃЌИУЖдЯѓДІРэЪ§ОнЕФНтЮіЃЌзщзАГЩвЛИіИіЕФrow_batchЖдЯѓНЛИјИИНкЕужДааЁЃжБЕНЫљгаЕФЗжЧјЖМвбОБЛЖСШЁВЂЭъГЩЩЈУшКЭНтЮіЁЃ
змНсЯТРДЃЌImpalaДІРэHdfsScanNodeЕФадФмЛЙЪЧгаЦфЖРЕНжЎДІЕФЃЌетвВДйЪЙСЫImpalaжавЛАуЪ§ОнЖСШЁКЭЩЈУшВЛЛсГЩЮЊВщбЏЕФЦПОБЃЌЗДЖјОлКЯКЭJOINВйзїгаЪБЛсЭЯТ§ВщбЏЫйЖШЃЌДгБОЮФЕФЗжЮіжаПЩвдПДЕНImpalaДІРэHDFSЪ§ОндДЪБгаШчЯТМИЕугХЛЏЃК
Ъ§ОнЮЛжУзїЮЊБэдЊЪ§ОнДцДЂЃЌШЮЮёЗжХфЪБГфЗжПМТЧЕНЪ§ОнБОЕиааКЭШЮЮёЗжХфЕФОљКтадЁЃ
Ъ§ОнЖСШЁЯпГЬКЭЪ§ОнДІРэЯпГЬЗжРыЃЌСНепПЩвдВЂааДІРэЁЃ
ЭЈЙ§HDFSЕФshortcutЛњжЦЪЕЯжБОЕиЪ§ОнЖСШЁЃЌЬсЩ§БОЕиЖСЕФадФм
дкScanНкЕуЩЯжДааprojectКЭfilterДІРэЃЌМѕЩйЩЯВуНкЕуЕФФкДцПНБДКЭЭјТчДЋЪф
ЪЙгУcodegenММЪѕНЕЕЭдЫаажаЕФащКЏЪ§ЕїгУЫ№КФКЭЩњГЩЬиЖЈЕФДњТыЃЌЪЙгУSSEжИСюЬсЩ§Ъ§ОнДІРэадФмЁЃ
ЪЙгУbatchЛњжЦХњСПДІРэЪ§ОнЃЌМѕЩйКЏЪ§ЕїгУДЮЪ§ЁЃ
БОЮФЯъЯИНщЩмСЫImpalaШчКЮЪЕЯжHdfsScanNodeжДааНкЕуЃЌИУНкЕуЪЧЫљгаВщбЏSQLЛёШЁЪ§ОнЕФдДЭЗЃЌвђДЫЪЧЪЎЗжживЊЕФЃЌЕБШЛImpalaжЇГжЕФHDFSИёЪНЛЙЪЧБШНЯгаЯоЕФЃЌЖдгкORCИёЪНВЛФмЙЛжЇГжЃЌЖјЖдгкJSONИёЪНЕФЩЈУшЮвУЧЭъГЩИїФкВПЕФПЊЗЂАцБОЃЌгаД§гкНјвЛВНадФмгХЛЏЃЌБОЮФжаЬсЕНСЫЪ§ОнЩЈУшЙ§ГЬжаЛсИљОнЙ§ТЫЬѕМўКЭruntime
filterНјааЪ§ОнЕФЙ§ТЫЃЌетжжЮНДЪЯТЭЦвВЪЧИїжжДѓЪ§Онв§ЧцадФмгХЛЏЕФвЛДѓвЊЕуЃЌЖјruntime filterПЩЮНЪЧimpalaЕФЖРМвУиѓХЁЃ
|









