| БрМЭЦМі: |
БОЮФЯъЯИНщЩмСЫДѓЪ§ОнжЮРэЕФЛљБОИХФюКЭЭГвЛСїГЬВЮПМФЃаЭЃЌВЂВћЪіСЫИУФЃаЭЕФЕквЛВНЁАУїШЗдЊЪ§ОнЙмРэВпТдЁБКЭЕкЖўВНЁАдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁБЕШФкШнЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ДѓЪ§ОнСїГЬФЃаЭКЭдЊЪ§ОнЙмРэ-ДѓЪ§ОнжЮРэИХЪі
ЃЈЯСвхЃЉДѓЪ§ОнЪЧжИЮоЗЈЪЙгУДЋЭГСїГЬЛђЙЄОпдкКЯРэЕФЪБМфКЭГЩБОФкДІРэЛђЗжЮіЕФаХЯЂЃЌетаЉаХЯЂНЋгУРДАяжњЦѓвЕИќжЧЛлЕиОгЊКЭОіВпЁЃЖјЙувхЕФДѓЪ§ОнИќЪЧжИЦѓвЕашвЊДІРэЕФКЃСПЪ§ОнЃЌАќРЈДЋЭГЪ§ОнвдМАЯСвхЕФДѓЪ§ОнЁЃЃЈЙувхЃЉДѓЪ§ОнПЩвдЗжЮЊЮхИіРраЭЃКWeb
КЭЩчНЛУНЬхЪ§ОнЁЂЛњЦїЖдЛњЦїЃЈM2MЃЉЪ§ОнЁЂКЃСПНЛвзЪ§ОнЁЂЩњЮяМЦСПбЇЪ§ОнКЭШЫЙЄЩњГЩЕФЪ§ОнЁЃ
Web КЭЩчНЛУНЬхЪ§ОнЃКБШШчИїжжЮЂВЉЁЂВЉПЭЁЂЩчНЛЭјеОЁЂЙКЮяЭјеОжаЕФЪ§ОнКЭФкШнЁЃ
M2M Ъ§ОнЃКвВОЭЪЧЛњЦїЖдЛњЦїЕФЪ§ОнЃЌБШШч RFID Ъ§ОнЁЂGPS Ъ§ОнЁЂжЧФмвЧБэЁЂМрПиМЧТМЪ§ОнвдМАЦфЫћИїжжДЋИаЦїЁЂМрПиЦїЕФЪ§ОнЁЃ
КЃСПНЛвзЪ§ОнЃКЪЧИїжжКЃСПЕФНЛвзМЧТМвдМАНЛвзЯрЙиЕФАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЃЌБШШчЕчаХаавЕЕФ CDRЁЂ3G
ЩЯЭјМЧТМЕШЃЌН№ШкаавЕЕФЭјЩЯНЛвзМЧТМЁЂcore banking МЧТМЁЂРэВЦМЧТМЕШЃЌБЃЯеаавЕЕФИїжжРэХтЕШЁЃ
ЩњЮяМЦСПбЇЪ§ОнЃКЪЧжИКЭШЫЬхЪЖБ№ЯрЙиЕФЩњЮяЪЖБ№аХЯЂЃЌШчжИЮЦЁЂDNAЁЂКчФЄЁЂЪгЭјФЄЁЂШЫСГЁЂЩљвєФЃЪНЁЂБЪМЃЕШЁЃ
ШЫЙЄЩњГЩЕФЪ§ОнЃКБШШчИїжжЕїВщЮЪОэЁЂЕчзггЪМўЁЂжНжЪЮФМўЁЂЩЈУшМўЁЂТМвєКЭЕчзгВЁРњЕШЁЃ
дкИїааИївЕжаЃЌЫцДІПЩМћвђЪ§СПЁЂЫйЖШЁЂжжРрКЭзМШЗадНсКЯДјРДЕФДѓЪ§ОнЮЪЬтЃЌЮЊСЫИќКУЕиРћгУДѓЪ§ОнЃЌДѓЪ§ОнжЮРэж№НЅЬсЩЯШеГЬЁЃдкДЋЭГЯЕЭГжаЃЌЪ§ОнашвЊЯШДцДЂЕНЙиЯЕаЭЪ§ОнПт/Ъ§ОнВжПтКѓдйНјааИїжжВщбЏКЭЗжЮіЃЌетаЉЪ§ОнЮвУЧГЦжЎЮЊОВЬЌЪ§ОнЁЃЖјдкДѓЪ§ОнЪБДњЃЌГ§СЫОВЬЌЪ§ОнвдЭтЃЌЛЙгаКмЖрЪ§ОнЖдЪЕЪБадвЊЧѓЗЧГЃИпЃЌашвЊдкВЩМЏЪ§ОнЪБОЭНјааЯргІЕФДІРэЃЌДІРэНсЙћДцШыЕНЙиЯЕаЭЪ§ОнПт/Ъ§ОнВжПтЁЂMPP
Ъ§ОнПтЁЂHadoop ЦНЬЈЁЂИїжж NoSQL Ъ§ОнПтЕШЃЌетаЉЪ§ОнЮвУЧГЦжЎЮЊЖЏЬЌЪ§ОнЁЃБШШчИпЬњЛњГЕЕФЙиМќСуВПМўЩЯзАгаГЩАйЩЯЧЇЕФДЋИаЦїЃЌУПЪБУППЬЖМдкЩњГЩЩшБИзДЬЌаХЯЂЃЌЦѓвЕашвЊЪЕЪБЪеМЏетаЉЪ§ОнВЂНјааЗжЮіЃЌЕБЗЂЯжЩшБИПЩФмГіЯжЮЪЬтЪБМАЪБИцОЏЁЃдйБШШчдкЕчаХаавЕЃЌЛљгкгУЛЇЭЈаХааЮЊЕФОЋзМгЊЯњЁЂЮЛжУгЊЯњЕШЃЌЖМЛсЪЕЪБЕФВЩМЏгУЛЇЪ§ОнВЂИљОнвЕЮёФЃаЭНјааЯргІЕФгЊЯњЛюЖЏЁЃ
ДѓЪ§ОнжЮРэЕФКЫаФЪЧЮЊвЕЮёЬсЙЉГжајЕФЁЂПЩЖШСПЕФМлжЕЁЃДѓЪ§ОнжЮРэШЫдБашвЊЖЈЦкгыЦѓвЕИпВуЙмРэШЫдБНјааЙЕЭЈЃЌБЃжЄДѓЪ§ОнжЮРэМЦЛЎПЩвдГжајЛёЕУжЇГжКЭАяжњЁЃЯраХЫцзХЪБМфЕФЭЦвЦЃЌДѓЪ§ОнНЋГЩЮЊжїСїЃЌЦѓвЕПЩвдДгКЃСПЕФЪ§ОнжаЛёЕУИќЖрЕФМлжЕЃЌЖјДѓЪ§ОнжЮРэЕФЗЖЮЇКЭбЯИёГЬЖШвВНЋж№ВНЩЯЩ§ЁЃЮЊСЫИќКУЕиАяжњЦѓвЕНјааДѓЪ§ОнжЮРэЃЌБЪепдк
IBM Ъ§ОнжЮРэЭГвЛСїГЬФЃаЭЛљДЁЩЯНсКЯдкЕчаХЁЂН№ШкЁЂеўИЎЕШаавЕНјааДѓЪ§ОнжЮРэЕФОбщЃЌећРэСЫДѓЪ§ОнжЮРэЭГвЛСїГЬВЮПМФЃаЭЃЌећИіВЮПМФЃаЭЗжЮЊБибЁВНжшКЭПЩбЁВНжшСНВПЗжЁЃ
ДѓЪ§ОнжЮРэЭГвЛСїГЬВЮПМФЃаЭ
ШчЭМ 1 ЫљЪОЃЌДѓЪ§ОнжЮРэЭГвЛСїГЬВЮПМФЃаЭБивЊВНжшЗжЮЊСНИіЗНЯђЃКвЛЬѕзгЯпЪЧдкжЦЖЈдЊЪ§ОнЙмРэВпТдКЭШЗСЂЬхЯЕНсЙЙЕФЛљДЁЩЯЪЕЪЉШЋУцЕФдЊЪ§ОнЙмРэЃЌСэвЛЬѕзгЯпЪЧдкЖЈвхвЕЮёЮЪЬтЁЂжДааГЩЪьЖШЦРЙРЕФЛљДЁЩЯЖЈвхЪ§ОнжЮРэТЗЯпЭМвдМАЖЈвхЪ§жЕжЮРэЯрЙиЕФЖШСПжЕЁЃдк
11 ИіБивЊВНжшЕФЛљДЁЩЯЃЌЦѓвЕПЩвддк 7 ИіПЩбЁВНжшжабЁдёвЛИіЛђЖрИіЭООЖНјааЬиЖЈСьгђЕФЪ§ОнжЮРэЃЌПЩбЁВНжшЮЊЃКжїЪ§ОнМрЙмЁЂЃЈЯСвхЃЉДѓЪ§ОнМрЙмЁЂаХЯЂЕЅвЛЪгЭММрЙмЁЂдЫгЊЗжЮіМрЙмЁЂдЄВтЗжЮіМрЙмЁЂЙмРэАВШЋгывўЫНвдМАМрЙмаХЯЂЩњУќжмЦкЁЃЦѓвЕашвЊЖЈЦкЖдДѓЪ§ОнжЮРэЭГвЛСїГЬНјааЖШСПВЂНЋНсЙћЗЂЫЭИјжїЙмМЖЗЂЦ№ШЫЁЃ
ЭМ 1. ДѓЪ§ОнжЮРэЭГвЛСїГЬВЮПМФЃаЭ
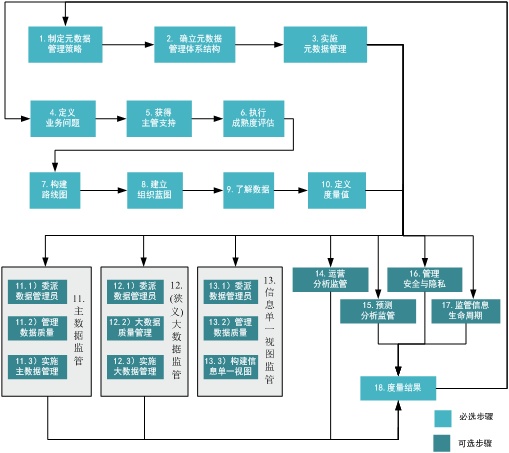
ЕквЛВНЃКУїШЗдЊЪ§ОнЙмРэВпТд
дкзюПЊЪМЕФЪБКђЃЌдЊЪ§ОнЃЈMeta DataЃЉЪЧжИУшЪіЪ§ОнЕФЪ§ОнЃЌЭЈГЃгЩаХЯЂНсЙЙЕФУшЪізщГЩЃЌЫцзХММЪѕЕФЗЂеЙдЊЪ§ОнФкКгаСЫЗЧГЃДѓЕФРЉеЙЃЌБШШч
UML ФЃаЭЁЂЪ§ОнНЛвзЙцдђЁЂгУ JavaЃЌ.NETЃЌC++ЕШБраДЕФ APIsЁЂвЕЮёСїГЬКЭЙЄзїСїФЃаЭЁЂВњЦЗХфжУУшЪіКЭЕїгХВЮЪ§вдМАИїжжвЕЮёЙцдђЁЂЪѕгяКЭЖЈвхЕШ
[1]ЁЃдкДѓЪ§ОнЪБДњЃЌдЊЪ§ОнЛЙгІИУАќРЈЖдИїжжаТЪ§ОнРраЭЕФУшЪіЃЌШчЖдЮЛжУЁЂУћзжЁЂгУЛЇЕуЛїДЮЪ§ЁЂвєЦЕЁЂЪгЦЕЁЂЭМЦЌЁЂИїжжЮоЯпИажЊЩшБИЪ§ОнКЭИїжжМрПиЩшБИЪ§ОнЕШЕФУшЪіЕШЁЃдЊЪ§ОнЭЈГЃЗжЮЊвЕЮёдЊЪ§ОнЁЂММЪѕдЊЪ§ОнКЭВйзїдЊЪ§ОнЕШЁЃвЕЮёдЊЪ§ОнжївЊАќРЈвЕЮёЙцдђЁЂЖЈвхЁЂЪѕгяЁЂЪѕгяБэЁЂдЫЫуЗЈдђКЭЯЕЭГЪЙгУвЕЮёгябдЕШЃЌжївЊЪЙгУепЪЧвЕЮёгУЛЇЁЃММЪѕдЊЪ§ОнжївЊгУРДЖЈвхаХЯЂЙЉгІСДЃЈInformation
Supply ChainЃЌISCЃЉИїРрзщГЩВПЗждЊЪ§ОнНсЙЙЃЌОпЬхАќРЈИїИіЯЕЭГБэКЭзжЖЮНсЙЙЁЂЪєадЁЂГіДІЁЂвРРЕадЕШЃЌвдМАДцДЂЙ§ГЬЁЂКЏЪ§ЁЂађСаЕШИїжжЖдЯѓЁЃВйзїдЊЪ§ОнЪЧжИгІгУГЬађдЫаааХЯЂЃЌБШШчЦфЦЕТЪЁЂМЧТМЪ§вдМАИїИізщМўЕФЗжЮіКЭЦфЫќЭГМЦаХЯЂЕШЁЃ
ДгећИіЦѓвЕВуУцРДЫЕЃЌИїжжЙЄОпШэМўКЭгІгУГЬађдНРДдНИДдгЃЌЯрЛЅвРДцЖШж№ФъдіМгЃЌЯргІЕФзЗзйећИіаХЯЂЙЉгІСДИїзщМўжЎМфЪ§ОнСїЖЏЁЂСЫНтЪ§ОндЊЫиКЌвхКЭЩЯЯТЮФЕФашЧѓдНРДдНЧПСвЁЃдкДггІгУвщГЬЭљаХЯЂвщГЬЕФзЊБфЙ§ГЬжаЃЌдЊЪ§ОнЙмРэвВж№НЅДгОжВПДцДЂКЭЙмРэзЊЯђЙВЯэЁЃДгзмСПЩЯРДПДЃЌећИіЦѓвЕЕФдЊЪ§ОндНРДдНЖрЃЌЙтЯжгаЕФЪ§ОнФЃаЭжаОЭАќКЌСЫГЩЧЇЩЯЭђЕФБэЃЌЭЌЪБЛЙгаИќЖрЕФФЃаЭЕШзХЩЯЯпЃЌЭЌЪБЫцзХДѓЪ§ОнЪБДњЕФРДСйЃЌЦѓвЕашвЊДІРэЕФЪ§ОнРраЭдНРДдНЖрЁЃЮЊСЫЦѓвЕИќИпаЇЕидЫзЊЃЌЦѓвЕашвЊУїШЗдЊЪ§ОнЙмРэВпТдКЭдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЃЌвРЭаГЩЪьЕФЗНЗЈТлКЭЙЄОпЪЕЯждЊЪ§ОнЙмРэЃЌВЂгаВНжшЕФЬсЩ§ЦфдЊЪ§ОнЙмРэГЩЪьЖШЁЃ
ЮЊСЫЪЕЯжДѓЪ§ОнжЮРэЃЌЙЙНЈжЧЛлЕФЗжЮіЖДВьЃЌЦѓвЕашвЊЪЕЯжЙсДЉећИіЦѓвЕЕФдЊЪ§ОнМЏГЩЃЌНЈСЂЭъећЧввЛжТЕФдЊЪ§ОнЙмРэВпТдЃЌИУВпТдВЛНіНіеыЖдФГИіЪ§ОнВжПтЯюФПЁЂвЕЮёЗжЮіЯюФПЁЂФГИіДѓЪ§ОнЯюФПЛђФГИігІгУЕЅЖРжЦЖЈвЛИіЙмРэВпТдЃЌЖјЪЧеыЖдећИіЦѓвЕЙЙНЈЭъећЕФЙмРэВпТдЁЃдЊЪ§ОнЙмРэВпТдвВВЛЪЧММЪѕБъзМЛђФГИіШэМўЙЄОпПЩвдШЁДњЕФЃЌЮоТлШэМўЙЄОпЙІФмЖрЧПДѓЖМВЛФмЭъШЋЬцДњвЛИіЭъећвЛжТЕФдЊЪ§ОнЙмРэВпТдЃЌЗДЖјдкЖЈвхдЊЪ§ОнМЏГЩЬхЯЕНсЙЙвдМАбЁЙКдЊЪ§ОнЙмРэЙЄОпжЎЧАашвЊЖЈвхдЊЪ§ОнЙмРэВпТдЁЃ
дЊЪ§ОнЙмРэВпТдашвЊУїШЗЦѓвЕдЊЪ§ОнЙмРэЕФдИОАЁЂФПБъЁЂашЧѓЁЂдМЪјКЭВпТдЕШЃЌвРОнЦѓвЕздЩэЕБЧАвдМАЮДРДЕФашвЊШЗЖЈвЊЪЕЯжЕФдЊЪ§ОнЙмРэГЩЪьЖШвдМАЪЕЯжФПБъГЩЪьЖШЕФТЗЯпЭМЃЌЭъГЩЛљДЁБОЬхЁЂСьгђБОЬхЁЂШЮЮёБОЬхКЭгІгУБОЬхЕФЙЙНЈЃЌШЗЖЈдЊЪ§ОнЙмРэЕФАВШЋВпТдЁЂАцБОПижЦЁЂдЊЪ§ОнЖЉдФЭЦЫЭЕШЁЃЦѓвЕашвЊЖдвЕЮёЪѕгяЁЂММЪѕЪѕгяжаЕФУєИаЪ§ОнНјааБъМЧКЭЗжРрЃЌжЦЖЈЯргІЕФЪ§ОнвўЫНБЃЛЄеўВпЃЌШЗБЃЦѓвЕдквўЫНБЃЛЄЗНУцЗћКЯЕБЕивўЫНЗНУцЕФЗЈТЩЗЈЙцЃЌШчЙћЦѓвЕгаПчЙњЪ§ОнНЛЛЛЁЂдЊЪ§ОнНЛЛЛЕФашЧѓЃЌвВвЊзёбЩцМАЙњМвЕФЗЈТЩЗЈЙцвЊЧѓЁЃЦѓвЕашвЊБЃжЄУПИідЊЪ§ОндЊЫидкаХЯЂЙЉгІСДжаУПИізщМўжагявхЩЯБЃГжвЛжТЃЌвВОЭЪЧгявхЕШаЇЃЈsemantic
equivalenceЃЉЁЃгявхЕШаЇПЩвдЧПвВПЩвдШѕЃЌдквЛИідЊЪ§ОнМЏГЩЗНАИжаЃЌгявхЕШаЇЃЈЦНОљЃЉдНЧПдђећИіЗНАИЕФаЇТЪдНИпЁЃгявхЕШаЇЕФЧПШѕГЬЖШжБНггАЯьдЊЪ§ОнЕФЙВЯэКЭжигУЁЃ
БОЬхЃЈШЫЙЄжЧФмКЭМЦЫуЛњПЦбЇЃЉ
БОЬхЃЈOntologyЃЉдДздембЇБОЬхТлЃЌЖјембЇБОЬхТлдђЪЧдДздембЇжаЁАаЮЖјЩЯбЇЁБЗжжЇЁЃБОЬхгаЪБвВБЛЗвыГЩБОЬхТлЃЌдкШЫЙЄжЧФмКЭМЦЫуЛњПЦбЇСьгђБОЬхзюдчдДгкЩЯЪРМЭ
70 ФъДњжаЦкЃЌЫцзХШЫЙЄжЧФмЕФЗЂеЙШЫУЧЗЂЯжжЊЪЖЕФЛёШЁЪЧЙЙНЈЧПДѓШЫЙЄжЧФмЯЕЭГЕФЙиМќЃЌгкЪЧПЊЪМНЋаТЕФБОЬхДДНЈЮЊМЦЫуЛњФЃаЭДгЖјЪЕЯжЬиЖЈРраЭЕФздЖЏЛЏЭЦРэЁЃжЎКѓЕНСЫЩЯЪРМЭ
80 ФъДњЃЌШЫЙЄжЧФмСьгђПЊЪМЪЙгУБОЬхБэЪОФЃаЭЛЏЪБМфЕФвЛжжРэТлвдМАжЊЪЖЯЕЭГЕФвЛжжзщМўЃЌШЯЮЊБОЬхЃЈШЫЙЄжЧФмЃЉЪЧвЛжжгІгУембЇЁЃ
зюдчЕФБОЬхЃЈШЫЙЄжЧФмКЭМЦЫуЛњПЦбЇЃЉЖЈвхЪЧ Neches ЕШШЫдк 1991 ИјГіЕФЃКЁАвЛИіБОЬхЖЈвхСЫзщГЩжїЬтСьгђЕФДЪЛуЕФЛљБОЪѕгяКЭЙиЯЕЃЌвдМАгУгкзщКЯЪѕгяКЭЙиЯЕвдМАЖЈвхДЪЛуЭтбгЕФЙцдђЁБЁЃЖјЕквЛДЮБЛвЕНчЙуЗКНгЪмЕФБОЬхЖЈвхГізд
Tom GruberЃЌЦфдк 1993 ФъЬсГіЃКЁАБОЬхЪЧИХФюЛЏЕФЯдЪНЕФБэЪОЃЈЙцИёЫЕУїЃЉЁБЁЃBorst
дк 1997 ФъЖд Tom Gruber ЕФБОЬхЖЈвхзіСЫНјвЛВНЕФРЉеЙЃЌШЯЮЊЃКЁАБОЬхЪЧЙВЯэЕФЁЂИХФюЛЏЕФвЛИіаЮЪНЕФЙцЗЖЫЕУїЁБЁЃдкЧАШЫЕФЛљДЁЩЯЃЌStuder
дк 1998 ФъНјвЛВНРЉеЙСЫБОЬхЕФЖЈвхЃЌетвВЪЧНёЬьБЛЙуЗКНгЪмЕФвЛИіЖЈвхЃКЁАБОЬхЪЧЙВЯэИХФюФЃаЭЕФУїШЗаЮЪНЛЏЙцЗЖЫЕУїЁБЁЃБОЬхЬсЙЉвЛИіЙВЯэДЪЛуБэЃЌПЩвдгУРДЖдвЛИіСьгђНЈФЃЃЌОпЬхАќРЈФЧаЉДцдкЕФЖдЯѓЛђИХФюЕФРраЭЁЂвдМАЫћУЧЕФЪєадКЭЙиЯЕ
[2]ЁЃвЛИіМђЕЅЕФБОЬхЪОР§ЗЂЦБИХФюМАЦфЯрЛЅЙиЯЕЫљЙЙГЩЕФгявхЭјТчШчЭМ 2 ЫљЪОЃК
ЭМ 2. МђЕЅБОЬхЃЈЗЂЦБЃЉЪОР§
ЫцзХЪБМфЕФЭЦвЦКЭММЪѕЕФЗЂеЙЃЌБОЬхДгзюПЊЪМЕФШЫЙЄжЧФмСьгђж№НЅРЉеЙЕНЭМЪщЙнбЇЁЂЧщБЈбЇЁЂШэМўЙЄГЬЁЂаХЯЂМмЙЙЁЂЩњЮявНбЇКЭаХЯЂбЇЕШдНРДдНЖрЕФбЇПЦЁЃгыембЇБОЬхТлРрЫЦЃЌБОЬхЃЈШЫЙЄжЧФмКЭМЦЫуЛњПЦбЇЃЉвРРЕФГжжРрБ№ЬхЯЕРДБэДяЪЕЬхЁЂИХФюЁЂЪТМўМАЦфЪєадКЭЙиЯЕЁЃБОЬхЕФКЫаФЪЧжЊЪЖЙВЯэКЭжигУЃЌЭЈЙ§МѕЩйЬиЖЈСьгђФкИХФюЛђЪѕгяЩЯЕФЗжЦчЃЌЪЙВЛЭЌЕФгУЛЇжЎМфПЩвдЫГГЉЕФЙЕЭЈКЭНЛСїВЂБЃГжгявхЕШаЇадЃЌЭЌЪБШУВЛЭЌЕФЙЄОпШэМўКЭгІгУЯЕЭГжЎМфЪЕЯжЛЅВйзїЁЃ
ИљОнбаОПВуДЮПЩвдНЋБОЬхЕФжжРрЛЎЗжЮЊЁАЖЅМЖБОЬхЁБЃЈtop-level ontologyЃЉЁЂгІгУБОЬхЃЈapplication
ontologyЃЉЁЂСьгђБОЬхЃЈdomain ontologyЃЉКЭШЮЮёБОЬхЃЈtask ontologyЃЉЃЌИїИіжжРржЎМфЕФВуДЮЙиЯЕШчЭМ
3 ЫљЪОЁЃ
ЭМ 3. БОЬхВуДЮЙиЯЕ
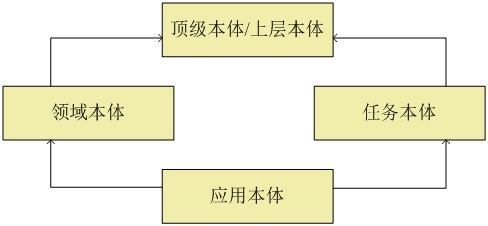
ЖЅМЖБОЬхЃЌвВБЛГЦЮЊЩЯВуБОЬхЃЈupper ontologЃЉЛђЛљДЁБОЬхЃЈfoundation ontologyЃЉЃЌЪЧжИЖРСЂгкОпЬхЕФЮЪЬтЛђСьгђЃЌдкЫљгаСьгђЖМЪЪгУЕФЙВЭЌЖдЯѓЛђИХФюЫљЙЙГЩЕФФЃаЭЃЌжївЊгУРДУшЪіИпМЖБ№ЧвЭЈгУЕФИХФювдМАИХФюжЎМфЕФЙиЯЕЁЃ
СьгђБОЬхЪЧжИЖдФГИіЬиЖЈЕФСьгђНЈФЃЃЌЯдЪНЕФЪЕЯжЖдСьгђЕФЖЈвхЃЌШЗЖЈИУСьгђФкЙВЭЌШЯПЩЕФДЪЛуЁЂДЪЛувЕЮёКЌвхКЭЖдгІЕФаХЯЂзЪВњЕШЃЌЬсЙЉЖдИУСьгђжЊЪЖЕФЙВЭЌРэНтЁЃСьгђБОЬхЫљБэДяЕФЪЧЪЪКЯздМКСьгђЕФЪѕгяЕФЬиЖЈКЌвхЃЌШБЗІМцШнадЃЌвђЖјдкЦфЫћСьгђЭљЭљВЛЪЪгУЁЃдкЭЌвЛСьгђФкЃЌгЩгкЮФЛЏБГОАЁЂгябдВювьЁЂЪмНЬг§ГЬЖШЛђвтЪЖаЮЬЌЕФВювьЃЌвВПЩФмЛсГіЯжВЛЭЌЕФБОЬхЁЃКмЖрЪБКђЃЌЫцзХвРРЕСьгђБОЬхЯЕЭГЕФРЉеЙЃЌашвЊНЋВЛЭЌЕФСьгђБОЬхКЯВЂЮЊИќЭЈгУЕФЙцЗЖЫЕУїЃЌЖдВЂЗЧЛљгкЭЌвЛЖЅМЖБОЬхЫљЙЙНЈЕФБОЬхНјааКЯВЂЪЧвЛЯюЗЧГЃОпгаЬєеНЕФШЮЮёЃЌКмЖрЪБКђашвЊППЪжЙЄРДЭъГЩЃЌЯрЗДЃЌЖдФЧаЉЛљгкЭЌвЛЖЅМЖБОЬхЙЙНЈЕФСьгђБОЬхПЩвдЪЕЯжздЖЏЛЏЕФКЯВЂЁЃ
ШЮЮёБОЬхЪЧеыЖдШЮЮёдЊЫиМАЦфжЎМфЙиЯЕЕФЙцЗЖЫЕУїЛђЯъЯИЫЕУїЃЌгУРДНтЪЭШЮЮёДцдкЕФЬѕМўвдМАПЩвдБЛгУдкФФаЉСьгђЛђЛЗОГжаЁЃЪЧвЛИіЭЈгУЪѕгяЕФМЏКЯгУРДУшЪіЙигкШЮЮёЕФЖЈвхКЭИХФюЕШЁЃ
гІгУБОЬхЃК УшЪівРРЕгкЬиЖЈСьгђКЭШЮЮёЕФИХФюМАИХФюжЎМфЕФЙиЯЕЃЌЪЧгУгкЬиЖЈгІгУЛђгУЭОЕФБОЬхЃЌЦфЗЖГыПЩвдЭЈЙ§ПЩВтЪдЕФгУР§РДжИЖЈЁЃ
ДгЯъЯИГЬЖШЩЯРДЗжЃЌБОЬхгжПЩвдЗжЮЊВЮПМБОЬхЃЈreference ontologiesЃЉКЭЙВЯэБОЬхЃЈshare
ontologiesЃЉЃЌВЮПМБОЬхЕФЯъЯИГЬЖШИпЃЌЖјЙВЯэБОЬхЕФЯъЯИГЬЖШЕЭЁЃ
БОЬхЃЈембЇЃЉ
ембЇжаЕФБОЬхЃЈontologyЃЉвВБЛГЦЮЊДцдкТлЃЌдДздембЇжаЁАаЮЖјЩЯбЇЁБЗжжЇЃЌжївЊЬНЬжДцдкЕФБОжЪЃЌвВОЭЪЧДцдкЕФДцдкЁЃгЂЮФ
ontology ЪЕМЪЩЯОЭЪЧРДдДгкЯЃРАЮФЁАІЯІЭЁБЃЈДцдкЃЉКЭЁАІЫ?ІУІЯ?ЁБЃЈбЇПЦЃЉЕФзщКЯЁЃБОЬхЪЧгЩдчЦкЯЃРАембЇдкЙЋдЊЧА
6 ЪРМЭЕНЙЋдЊЧА 4 ЪРМЭЬсГіЕФЁАЪМЛљЁБбгЩьГіРДЕФЁЃЪМЛљЃЈPrincipleЃЌгжГЦБОдЃЉзюдчгЩЬЉРеЫЙЃЈУзРћЖМбЇХЩЃЉзюдчЬсГіРДЃЌШЯЮЊЭђЮягЩЫЎЖјЩњЃЌЦфбЇЩњАЂФЧПЫЮїТќЕТШЯЮЊЭђЮягЩвЛжжМђЕЅЕФджЪзщГЩЃЌИУджЪВЛЪЧЫЎ
[3]ЁЃЖјБЯДяИчРЫЙЃЈбЇХЩЃЉШЯЮЊЁАЭђЮяЖМЪЧЪ§ЁБЃЌЪ§ВЛНіБЛПДзїЭђЮяЕФБОдЃЌЖјЧвБЛПДзїЭђЮяЕФдаЭЁЂЪРНчЕФБОЬхЁЃКѓРДАЭУХФсЕТЃЈАЎРћбЧбЇХЩЃЉЬсГіСЫЁАДцдкЁБЕФИХФюЃЌШЯЮЊДцдкВХЪЧЮЈвЛеце§ДцдкЕФецРэЃЌЦфДДдьСЫвЛжжаЮЖјЩЯбЇТлжЄЗНЪНЃЌжЎКѓЕФембЇвЛжБЕННќЪБЦкЮЊжЙЃЌЖМДгАЭУХФсЕТДІНгЪмСЫЦфЁАЪЕЬхЕФВЛПЩЛйУ№адЁБЁЃЫеИёРЕзМЬГаСЫАЭУХФсЕТЕФДцдкИХФюЃЌжїеХЁАеце§ЕФЩЦЁБВЂЭъЩЦСЫАЭУХФсЕТЕмзгжЅХЕЕФБчжЄЗЈЃЌЦфбЇЩњАиРЭМЬсГіСЫЁАРэФюТлЁБЃЌШЯЮЊжЛвЊШєИЩИіИіЬхгЕгавЛИіЙВЭЌЕФУћзжЃЌЫќУЧОЭгавЛИіЙВЭЌЕФРэФюЛђаЮЪНЁЃбЧРяЪПЖрЕТЃЈАиРЭМбЇЩњЃЉзмНсСЫЯШемУЧЕФЫМЯыЃЌЭъГЩСЫЁЖаЮЖјЩЯбЇЁЗЃЌВЂНЋБОЬхзмНсЮЊЃКЖдЪРНчЩЯПЭЙлДцдкЪТЮяЕФЯЕЭГЕФУшЪіЃЌМДДцдкТлЃЌвВОЭЪЧзюаЮЖјЩЯбЇЕФжЊЪЖЁЃаЮЖјЩЯбЇВЛЪЧжИЙТСЂЁЂОВжЙжЎРрЕФвтЫМЃЌЖјЪЧжИГЌдНОпЬхаЮЬЌЕФГщЯѓвтЫМЃЌЪЧЙигкЮяжЪЪРНчзюЦеБщЕФЁЂзювЛАуЕФЁЂзюВЛОпЬхЕФЙцТЩЕФбЇЮЪЁЃ
ЕкЖўВНЃКдЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
дкУїШЗСЫдЊЪ§ОнЙмРэВпТдКѓашвЊШЗЖЈЪЕЯжИУЙмРэВпТдЫљашЕФММЪѕЬхЯЕНсЙЙЃЌМДдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЃИїИіЦѓвЕЕФдЊЪ§ОнЙмРэВпТдКЭдЊЪ§ОнЙмРэГЩЪьЖШВюБ№НЯДѓЃЌвђДЫдЊЪ§ОнМЏГЩЬхЯЕНсЙЙвВЖржжЖрбљЁЃДѓЬхЩЯдЊЪ§ОнМЏГЩЬхЯЕНсЙЙПЩвдЗжЮЊЕуЖдЕуЕФдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂжабыЗјЩфЪНдЊЪ§ОнЬхЯЕНсЙЙЁЂЛљгк
CWMЃЈCommon Warehouse MetaModelЃЌЙЋЙВВжПтдЊФЃаЭЃЉФЃаЭЧ§ЖЏЕФЕуЖдЕудЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂЛљгк
CWM ФЃаЭЧ§ЖЏЕФжабыДцДЂПтдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂЗжВМЪНЃЈСЊАюЪНЃЉдЊЪ§ОнМЏГЩЬхЯЕНсЙЙКЭВуДЮ/аЧаЭдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЕШЁЃ
еыЖдаХЯЂЙЉгІСДжаВЛЭЌЕФзщМўЃЌЮЊСЫЪЕЯжПчзщМўЕФдЊЪ§ОнНЛЛЛКЭМЏГЩЃЌзюПЊЪМШЫУЧВЩгУЕуЖдЕуЕФЗНЪННјааЃЌвВОЭЪЧУПвЛЖдзщМўжЎМфЭЈЙ§вЛИіЖРСЂЕФдЊЪ§ОнЧХЃЈmetadata
bridgeЃЉНјаадЊЪ§ОнНЛЛЛЃЌЧХвЛАуЪЧЫЋЯђЕФФмЙЛРэНтСНИіЗНЯђЕФдЊЪ§ОнгГЩф [4]ЁЃЕуЖдЕуЕФдЊЪ§ОнМЏГЩЬхЯЕНсЙЙАяжњгУЛЇЪЕЯжСЫПчЦѓвЕЕФдЊЪ§ОнМЏГЩКЭдЊЪ§ОнНЛЛЛЃЌЖдЬсЩ§аХЯЂЛЏЫЎЦНЬсЙЉСЫОоДѓАяжњЁЃетжжЬхЯЕНсЙЙдкгІгУЙ§ГЬжаЃЌвВБЉТЖСЫКмЖрЮЪЬтЃЌБШШчдЊЪ§ОнЧХЕФЙЙНЈЙЄзїСПКЭКФЪБЖМЗЧГЃДѓЃЌЖджаМфМўГЇЩЬЁЂгІгУГЇЩЬЁЂМЏГЩЩЬКЭгУЛЇРДЫЕЖМЪЧвЛИіОоДѓЕФЬєеНЃЌЖјЧвЙЙНЈдЊЪ§ОнЧХЛЙБиаыОпгаЫљгаепЕФдЊЪ§ОнФЃаЭКЭНгПкЕФЯъЯИаХЯЂЁЃЙЙНЈЭъГЩЕФЧХКмЖрЪБКђЮоЗЈдкЙЙНЈЦфЫћдЊЪ§ОнЧХЪБНјаажигУЃЌвђДЫПЊЗЂКЭЮЌЛЄЗбгУДѓЗљЖШдіМгЃЌгУЛЇЭЖзЪЛиБЈТЪЃЈROIЃЉВЛИпЁЃвдЖЏЬЌЪ§ОнВжПтЮЊР§ЃЌЦфЕуЖдЕуЕФдЊЪ§ОнМЏГЩЬхЯЕНсЙЙОпЬхШчЭМ
4 ЫљЪОЃЌаХЯЂЙЉгІСДИїзщМўжЎМфЕФПеаФМ§ЭЗБэЪОШЋВПЕФЪ§ОнСїЃЌЪЕаФМ§ЭЗБэЪОВЛЭЌЕФдЊЪ§ОнЧХКЭгыжЎЙиСЊЕФдЊЪ§ОнСїЁЃ
ЭМ 4. ЕуЖдЕуЕФдЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
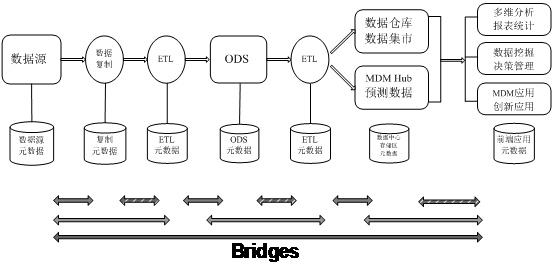
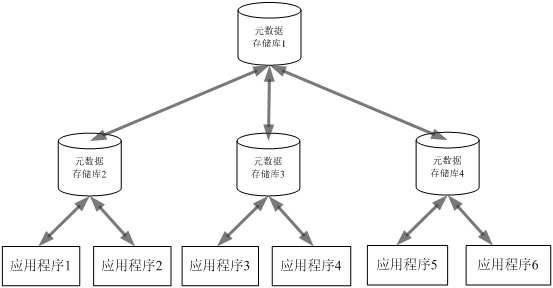
ЭЈЙ§ЪЙгУжабыдЊЪ§ОнДцДЂПтЃЈcentral metadata repositoryЃЉШЁДњИїИіЙЄОпШэМўКЭгІгУГЬађжЎМфЕФЕуЖдЕуСЌНгЗНЪНЃЌИФГЩжабыдЊЪ§ОнДцДЂПтгыИїИіЙЄОпШэМўКЭгІгУГЬађЪЕЯждЊЪ§ОнНЛЛЛЕФЗУЮЪВуЃЈвВЪЧвЛжжЧХЃЉЃЌПЩвдгааЇНЕЕЭзмГЩБОЃЌМѕЩйНЈСЂЕуЖдЕудЊЪ§ОнЧХЕФЙЄзїЃЌЬсИпЭЖзЪЛиБЈТЪЁЃаХЯЂЙЉгІСДИїзщМўПЩвдДгДцДЂПтЗУЮЪдЊЪ§ОнЃЌВЛБигыЦфЫћВњЦЗНјааЕуЖдЕуНЛЛЅЁЃетжжЪЙгУжабыдЊЪ§ОнДцДЂПтЗНЪННјаадЊЪ§ОнМЏГЩЕФЗНЪНОЭЪЧжабыЗјЩфЪНдЊЪ§ОнЬхЯЕНсЙЙЃЈhub-and-spoke
meta data architectureЃЉЃЌОпЬхШчЭМ 5 ЫљЪОЁЃгЩгкЬиЖЈЕФдЊЪ§ОнДцДЂПтЪЧЮЇШЦЦфздЩэЕФдЊФЃаЭЁЂНгПкКЭНЛИЖЗўЮёНЈСЂЕФЃЌЫљвдШдашвЊНЈСЂдЊЪ§ОнЧХЪЕЯжгы
ISC ИїзщМўЕФЛЅЯрЗУЮЪЁЃ
ЭМ 5. жабыЗјЩфЪНдЊЪ§ОнЬхЯЕНсЙЙ

ВЩгУФЃаЭЧ§ЖЏЕФдЊЪ§ОнМЏГЩЗНЗЈЃЈБШШчЪЙгУ CWMЃЉПЩвдгааЇНЕЕЭдЊЪ§ОнМЏГЩЕФГЩБОКЭИДдгЖШЃЌЮоТлЕуЖдЕудЊЪ§ОнМЏГЩЬхЯЕНсЙЙЛЙЪЧжабыЗјЩфЪНдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЖМПЩвдвђДЫЪмвцЁЃдкЕуЖдЕуЬхЯЕНсЙЙжаЃЌЭЈЙ§ЪЙгУЛљгкФЃаЭЕФЗНЗЈПЩвдВЛБидкУПвЛЖдашвЊМЏГЩЕФВњЦЗжЎМфЙЙНЈдЊЪ§ОнЧХЃЌУПИіВњЦЗжЛашвЊЬсЙЉвЛИіЪЪХфЦїЃЈadapterЃЉМДПЩЪЕЯжИїИіВњЦЗжЎМфЕФдЊЪ§ОнНЛЛЛЃЌЪЪХфЦїМШСЫНтЙЋЙВЕФдЊФЃаЭвВСЫНтБОВњЦЗдЊФЃаЭЕФФкВПЪЕЯжЁЃШчЭМ
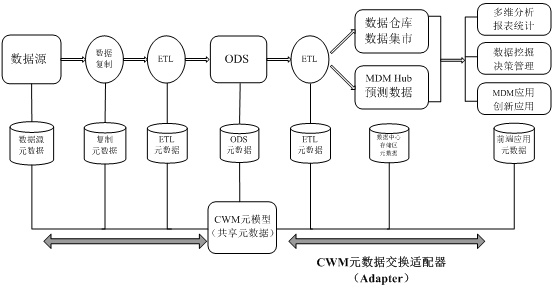
6 ЫљЪОЃЌЛљгк CWM ФЃаЭЧ§ЖЏЕуЖдЕудЊЪ§ОнМЏГЩЬхЯЕНсЙЙЪЙгУЭЈгУдЊФЃаЭЃЌВЛдйашвЊдкИїИіВњЦЗМфНЈСЂдЊЪ§ОнЧХЃЌдкИїИіВњЦЗжЎМфЭЈЙ§ЪЪХфЦїЪЕЯжСЫгявхЕШМладЁЃ
ЭМ 6. Лљгк CWM ФЃаЭЧ§ЖЏЕФЕуЖдЕудЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
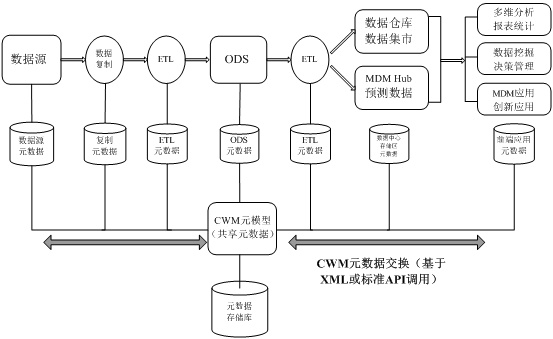
ШчЭМ 7 ЫљЪОЃЌдкЛљгкФЃаЭЧ§ЖЏЃЈБШШч CWMЃЉЕФжабыЗјЩфЪНдЊЪ§ОнЬхЯЕНсЙЙжаЃЌжабыДцДЂПтАќКЌЙЋЙВдЊФЃаЭКЭећИіСьгђЃЈdomainЃЉгУЕНЕФИУдЊФЃаЭЕФИїИіЪЕР§ЃЈФЃаЭЃЉЁЂДцДЂПтздЩэдЊФЃаЭМАЦфЪЕР§ЁЂРэНтдЊФЃаЭЃЈЙЋЙВдЊФЃаЭКЭздЩэдЊФЃаЭЃЉЕФЪЪХфЦїВуЃЌЕБШЛДцДЂПтвВПЩвджБНгЪЕЯжЙЋЙВдЊФЃаЭЕФФГаЉФкВПБэЪОЁЃ
ЭМ 7. Лљгк CWM ФЃаЭЧ§ЖЏЕФжабыДцДЂПтдЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
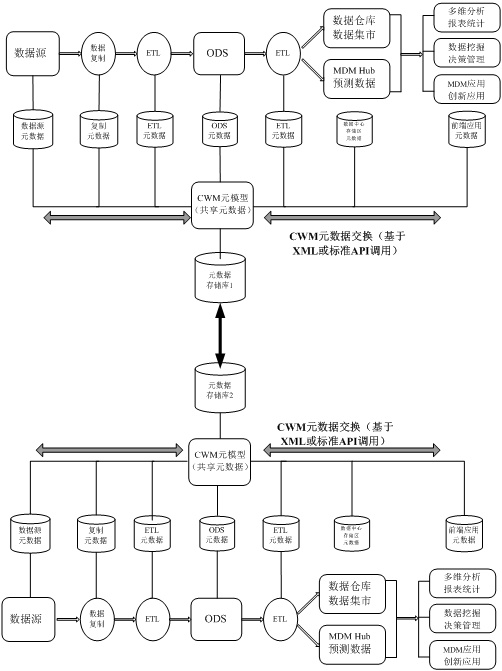
ШчЭМ 8 ЫљЪОЃЌетжжЬхЯЕМмЙЙЪЧЛљгк CWM ФЃаЭЧ§ЖЏЕФжабыДцДЂПтдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЕФвЛИіБфжжЃЌСНИіжабыЗјЩфЪНЕФЭиЦЫНсЙЙЭЈЙ§ИїздЕФдЊЪ§ОнДцДЂПтСЌНгЦ№РДЃЌвВБЛГЦЮЊЗжВМЪНЃЈDistributedЃЉЛђСЊАюЃЈFederatedЃЉЬхЯЕНсЙЙЁЃСНИідЊЪ§ОнДцДЂПтжЎМфЭЈЙ§дЊЪ§ОнЧХСЌНгЃЌСНИіДцДЂПтЪЙгУЯрЭЌЕФдЊФЃаЭКЭНгПкЃЌвВПЩвдЪЙгУВЛЭЌЕФдЊФЃаЭКЭНгПкЁЃНЈСЂЗжВМЪНдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЕФдвђгаКмЖржжЃЌБШШчЦѓвЕЛљгкЖрИіЧјгђЕЅЖРВПЪ№здМКЕФгІгУЃЌУПИіЧјгђгаздМКЕФЪ§ОнжааФЁЃ
ЭМ 8. ЗжВМЪНЃЈСЊАюЪНЃЉдЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
ШчЭМ 9 ЫљЪОЃЌетжжЬхЯЕНсЙЙЪЧЗжВМЪНЬхЯЕНсЙЙЕФБфЬхЃЌИљДцДЂПтЪЕЯжСЫдЊФЃаЭЕФЙЋЙВВПЗжЃЈКсПчећИіЦѓвЕЃЉЃЌвЖзгДцДЂПтЪЕЯжСЫвЛИіЛђЖрИіЬиЖЈЕФЙЋЙВдЊФЃаЭзгМЏЃЌВЂжЛБЃДцетаЉздМКЫљЖдгІЕФдЊЪ§ОнЪЕР§ЁЃЬиЖЈПЭЛЇПЩвджївЊЗУЮЪЦфИааЫШЄЕФдЊЪ§ОнЫљдкЕФвЖзгДцДЂПтЃЌвВПЩвдЗУЮЪЦфЫќвЖзгДцДЂПтКЭИљДцДЂПтЁЃетжжЬхЯЕНсЙЙБЛГЦЮЊВуДЮЛђаЧаЭЭиЦЫНсЙЙЁЃ
ЭМ 9. ВуДЮЛђаЧаЭдЊЪ§ОнМЏГЩЬхЯЕНсЙЙ
НсЪјгя
дкЕквЛВНЁАУїШЗдЊЪ§ОнЙмРэВпТдЁБжаНВЪіСЫдЊЪ§ОнЕФЛљБОИХФювдМАБОЬхдкШЫЙЄжЧФм/МЦЫуЛњПЦбЇКЭембЇжаЕФКЌвхЁЃдкЕкЖўВНЁАдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁБНВЪіСЫдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЕФСљжжЪОР§ЃЌЗжБ№ЮЊЃКЕуЖдЕуЕФдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂжабыЗјЩфЪНдЊЪ§ОнЬхЯЕНсЙЙЁЂЛљгк
CWM ФЃаЭЧ§ЖЏЕФЕуЖдЕудЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂЛљгк CWM ФЃаЭЧ§ЖЏЕФжабыДцДЂПтдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЂЗжВМЪНЃЈСЊАюЪНЃЉдЊЪ§ОнМЏГЩЬхЯЕНсЙЙКЭВуДЮ/аЧаЭдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁЃдкБОЯЕСаЮФеТЕФЯТвЛВПЗжНЋМЬајНщЩмДѓЪ§ОнжЮРэЭГвЛСїГЬВЮПМФЃаЭЕкЖўВНЁАдЊЪ§ОнМЏГЩЬхЯЕНсЙЙЁБЃЌОпЬхАќРЈдЊФЃаЭЁЂдЊ-дЊФЃаЭЁЂЙЋЙВВжПтдЊФЃаЭЃЈCWMЃЉЁЂCWM
ЗЂеЙЪЗЁЂOMG ЕФФЃаЭЧ§ЖЏЬхЯЕНсЙЙЃЈModel Driven ArchitectureЃЌMDAЃЉЁЃ
|









