| БрМЭЦМі: |
БОЮФНщЩмСЫдкв§Шы
Apache Kylin ЪБЃЌДѓЪ§ОнЩЯЕФЛњЦїбЇЯАКЭЪ§ОнПЦбЇЛюЖЏШчКЮБфЕУИќМгМђЕЅВЂНщЩмСЫApache
Kylin ШчКЮгы Python МЏГЩЃЌЪЙгУ Apache Kylin зїЮЊЪ§ОндДЕФКУДІЃЌИќЖрСЫНтЧыдФЖСЯТЮФЁЃ
БОЮФРДздЫбКќЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЯжШчНёЃЌДѓЪ§ОнЁЂЪ§ОнПЦбЇКЭЛњЦїбЇЯАВЛНіЪЧММЪѕШІЕФШШУХЛАЬтЃЌвВЪЧЕБНёЩчЛсЕФживЊзщГЩЁЃЪ§ОнОЭдкУПИіШЫЩэБпЃЌЭЌЪБУПЬье§вдОЊШЫЕФЫйЖШПьЫйдіГЄЃЌОнИЃВМЫЙБЈЕРЃКЕН
2025 ФъЃЌУПФъНЋВњЩњДѓдМ 175 Иі Zettabytes ЕФЪ§ОнСПЁЃ
ФПЧАЮвУЧЫљЪьжЊЕФаавЕЖМдНРДдНвРРЕгкЖдДѓЪ§ОнЕФИпМЖДІРэКЭЗжЮіЃЌШчН№ШкЁЂвНСЦБЃНЁЁЂХЉвЕЁЂФмдДЁЂУНЬхЁЂНЬг§ЕШЫљгаживЊЕФЩчЛсЗЂеЙаавЕЃЌШЛЖјетаЉХгДѓЕФЪ§ОнМЏШУЪ§ОнЗжЮіЁЂЪ§ОнЭкОђЁЂЛњЦїбЇЯАКЭЪ§ОнПЦбЇУцСйСЫОоДѓЕФЬєеНЁЃ
Ъ§ОнПЦбЇМвКЭЗжЮіЪІдкГЂЪдЖдгкКЃСПЪ§ОнЕФЗжЮіЪБЛсУцСйЪ§ОнДІРэСїГЬИДдгЁЂБЈБэВщбЏЛКТ§ЕШЮЪЬтЃЌЕЋдкЪЕМљжаЗЂЯжПЩЭЈЙ§
Apache Kylin гы Python ЕФМЏГЩНтОіетвЛДѓФбЬтЃЌДгЖјАяжњЗжЮіЪІКЭЪ§ОнПЦбЇМвзюжеЛёЕУЖдДѓЙцФЃЃЈTB
МЖКЭ PB МЖЃЉЪ§ОнМЏЕФздгЩЗУЮЪЁЃ
ЛњЦїбЇЯАКЭЪ§ОнПЦбЇУцСйЕФЬєеН
ЛњЦїбЇЯАЃЈMLЃЉЙЄГЬЪІКЭЪ§ОнПЦбЇМвдкЖдДѓЪ§ОндЫааМЦЫуЪБгіЕНЕФжївЊЬєеНжЎвЛЪЧДІРэИќДѓШнСПЕФЪ§ОнЪБДјРДЕФИќДѓЕФМЦЫуИДдгЖШ
ЁЃ
вђДЫЃЌЫцзХЪ§ОнМЏЕФРЉДѓЃЌМДЪЙЪЧЮЂВЛзуЕРЕФВйзївВЛсБфЕУАКЙѓЁЃДЫЭтЃЌЫцзХЪ§ОнСПЕФдіМгЃЌЫуЗЈадФмдНРДдНвРРЕгкгУгкДцДЂКЭвЦЖЏЪ§ОнЕФММЪѕМмЙЙЃЌЭЌЪБЪ§ОнСПдНДѓЃЌВЂааЪ§ОнНсЙЙЃЌЪ§ОнЗжЧјКЭДцДЂвдМАЪ§ОнИДгУБфЕУИќМгживЊЁЃ

Apache Kylin ШчКЮНтОіетаЉЬєеНЃП
Apache KylinЪЧвЛИіПЊдДЕФЗжВМЪНДѓЪ§ОнЗжЮів§ЧцЃЌжМдкЮЊ HadoopЩЯЕФЖрЮЌЗжЮіЃЈMOLAPЃЉЬсЙЉ
SQL НгПкЁЃЫќдЪаэЦѓвЕЪЙгУКЭЦфЫћДѓЪ§ОнЗжЮіЙЄОпЯрБШИќЖЬЕФЕФЪБМфПьЫйЗжЮіКЃСПЪ§ОнМЏЁЃ
Ншжњ Apache KylinЃЌЪ§ОнЭХЖгФмЙЛДѓЗљМѕЩйЗжЮіДІРэЪБМфвдМАЯрЙиЕФ IT КЭдЫгЊГЩБОЁЃЫќПЩвдЭЈЙ§НЋДѓаЭЪ§ОнМЏдЄЯШМЦЫуЕНвЛИіЃЈЛђСэвЛИіЗЧГЃЩйСПЃЉЕФ
OLAP ЖрЮЌЪ§ОнМЏжаВЂНЋЫќУЧДцДЂдкСаЪНЪ§ОнПтжаРДЪЕЯжВщбЏМгЫйЁЃетЪЙЛњЦїбЇЯАЙЄГЬЪІЃЌЪ§ОнПЦбЇМвКЭЗжЮіЪІФмЙЛПьЫйЗУЮЪЪ§ОнВЂжДааЪ§ОнЭкОђЃЌЧсЫЩЗЂЯжЪ§ОнжавўВиЕФЧїЪЦЁЃ
ЯТЭМЯдЪОСЫдкв§Шы Apache Kylin ЪБЃЌДѓЪ§ОнЩЯЕФЛњЦїбЇЯАКЭЪ§ОнПЦбЇЛюЖЏШчКЮБфЕУИќМгМђЕЅЁЃ
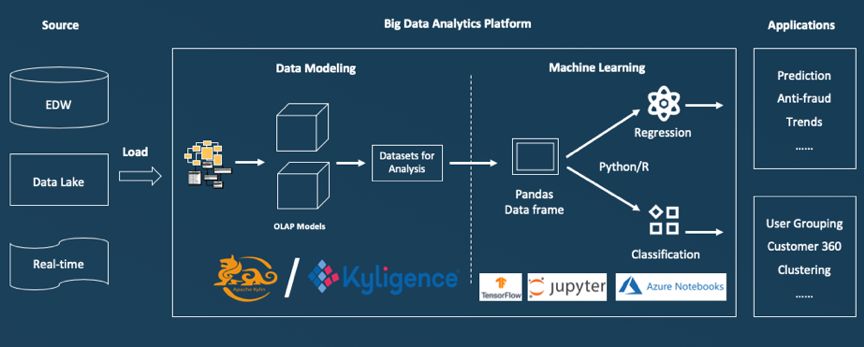
Apache Kylin ШчКЮгыДѓЪ§ОнЦНЬЈХфКЯЪЙгУ
Apache Kylin ШчКЮгы Python МЏГЩ
ФПЧА Python ЗчЭЗе§ЪЂЃЌзїЮЊСьЯШЕФБрГЬгябджЎвЛЃЌЦОНшЦфвзгУадКЭЗсИЛЕФПтЃЌPython вбОдкДѓЪ§ОнжаБЛЙуЗКгІгУЁЃ
Python ЛЙЬсЙЉСЫДѓСПЪ§ОнЭкОђЙЄОпРДажњДІРэЪ§ОнЃЌЭЌЪБвВЬсЙЉвбОдкЛњЦїбЇЯАКЭЪ§ОнПЦбЇЩчЧјдЫааЕФгІгУГЬађЁЃМђЖјбджЎЃЌШчЙћФње§дкЪЙгУДѓЪ§ОнЃЌФЧУД
Python ПЩФмЛсШУФњЕФЙЄзїБфЕУИќЧсЫЩЁЃ
ЪЙгУ Kylinpy ПтЃЌApache Kylin ПЩвдЧсЫЩгы Python МЏГЩЁЃKylinpyЃЈhttps://github.com/Kyligence/kylinpyЃЉЪЧвЛИіЬсЙЉ
SQLAlchemy ЗНбдЪЕЯжЕФ Python ПтЁЃвђДЫЃЌШЮКЮЪЙгУ SQLAlchemy ЕФгІгУГЬађЯждкЖМПЩвдВщбЏ
Kylin OLAP ЖрЮЌЪ§ОнМЏЁЃДЫЭтЃЌЫќЛЙдЪаэгУЛЇЭЈЙ§ Pandas Ъ§ОнжЁЗУЮЪЪ§ОнЁЃ
ЭЈЙ§ Pandas ЗУЮЪЪ§ОнЕФЪОР§ДњТыЃК

ЪЙгУ Pandas СЌНг Apache Kylin
ЪЙгУ Apache Kylin зїЮЊЪ§ОндДЕФКУДІ
ЧсЫЩЗУЮЪКЃСПЪ§ОнМЏЃКНЛЛЅЪНДІРэДѓСПЃЈTB / PBЃЉЪ§ОнЁЃ
ЬсЙЉБъзМ JDBC НгПкЁЃ
ГЌИпадФмЃКДѓЪ§ОнВщбЏбЧУыМЖЯьгІЁЃ
ИпРЉеЙадЃКНшжњ Kylin ЕФКсЯђРЉеЙадЃЌПЩвдРЉеЙЪ§ОнЃЌЮоашЕЃаФадФмЮЪЬтЁЃ
ЛЅСЊЭјМЖВЂЗЂЃКжЇГжЪ§ЧЇИігУЛЇВЂЗЂВщбЏЁЃ
МЋМђПЊЗЂЃКЪЭЗХПЊЗЂШЫСІЃЌзЈзЂЪ§ОнЖДВьЁЃ
гУР§ЃКЪЙгУ Apache Kylin НјааИпМЖЗжЮі
Ъ§ОнМЏЃК
ЮвУЧНЋвЛИі IMDB ЕчгАЪ§ОнМЏЃЈРДдДЃКMovielens https://grouplens.org/datasets/movielens/ЃЉЕМШыЮвУЧЕФ
Kylin OLAP ЖрЮЌЪ§ОнМЏЃЌВЂЪЙгУ Python ЖСШЁЪ§ОнВЂжДааЬНЫїадЗжЮіЃЌвдБудкжИЖЈЪБМфЖЮФкВщевВЛЭЌСїХЩЕФЕчгАЦРМЖЧїЪЦЁЃ
ФПЕФЃК
1.ШЗЖЈЦРЗжзюИпЕФЕчгАЁЃ
2.БШНЯФаадгыХЎадЖдВЛЭЌЕчгАРраЭЕФЦЋКУЁЃ
3.евГіЙлгАШЫжАвЕгыЕчгАСїХЩжЎМфЕФЯрЙиадЁЃ
4.ЗжЮіМИжмФкВЛЭЌРраЭЕФЕчгАЦРМЖЧїЪЦЁЃ
5.БШНЯФаХЎЦНОљЦРЗжЁЃ
Ъ§ОнЩњУќжмЦк
ЮЊСЫЭЈЙ§ Python ЗжЮіЪ§ОнЃЌЪЙгУСЫ Kylinpy ПтВЂБраДСЫ SQL РДЮЊЯрЙиЗжЮіЬсШЁЯрЙиЪ§ОнЁЃЭЈЙ§
SQL ЗЕЛиЕФЪ§ОнМЏДцДЂЮЊ Pandas Ъ§ОнжЁЃЌШЛКѓЖдЪ§ОнжЁНјааЪ§ОнДІРэЃЌвдЪЙЪ§ОнаЮГЩЪЪКЯЮвУЧЗжЮіЕФНсЙЙЁЃЮвУЧРћгУ
Matplotlib КЭ Seaborn ПтРДПЩЪгЛЏЪ§ОнЁЃЯТЭМЫЕУїСЫУПИіНзЖЮЕФЪ§ОнЩњУќжмЦкЁЃ
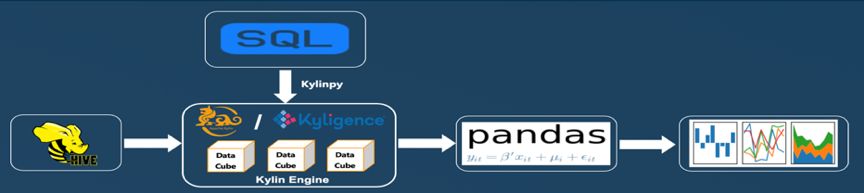
Apache Kylin Ъ§ОнЩњУќжмЦк
ЗжЮі
ШУЮвУЧЪзЯШПДвЛЯТХХУћППЧАЕФМИВПЕчгАЁЃПЩвдПДГіЃЌЧА 15 ВПЕчгАжаЃЌГ§СЫЧА 2 ВПжЎЭтЃЌ13 ВПЕчгАЕФЦРЗжШЫЪ§МИКѕЯрЭЌЁЃДЫаХЯЂЪЧЯрЙиЗЂЯжЕФЦ№ЕуЃЌПЩвдНјвЛВНЩюШыВщевЮвУЧЦРЗжШЫЪ§НЯИпЕФЕчгАжЎМфЕФЯрЙиадЁЃ
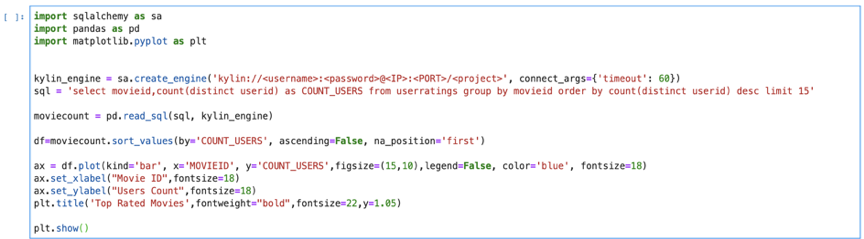
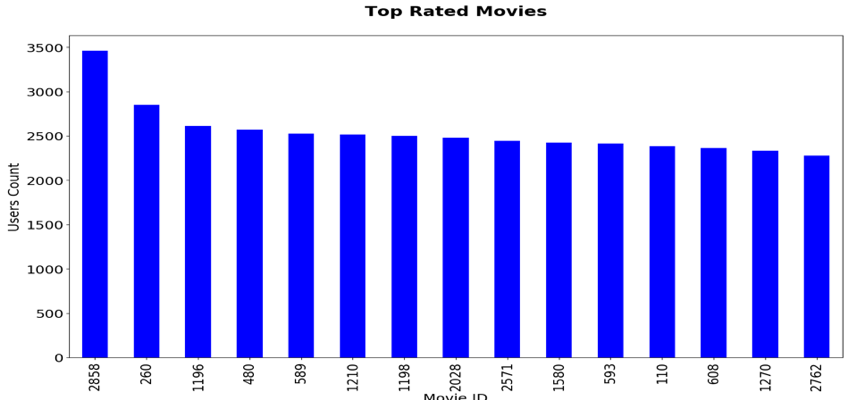
ЭЌбљЃЌЯТУцЕФжљзДЭМЯдЪОСЫУПжжСїХЩЕчгАЕФЦРЗжШЫЕФадБ№БШНЯЁЃетЯдЪОСЫФаХЎЙлгАЪБЖдВЛЭЌСїХЩЕчгАЕФЦЋКУЁЃ
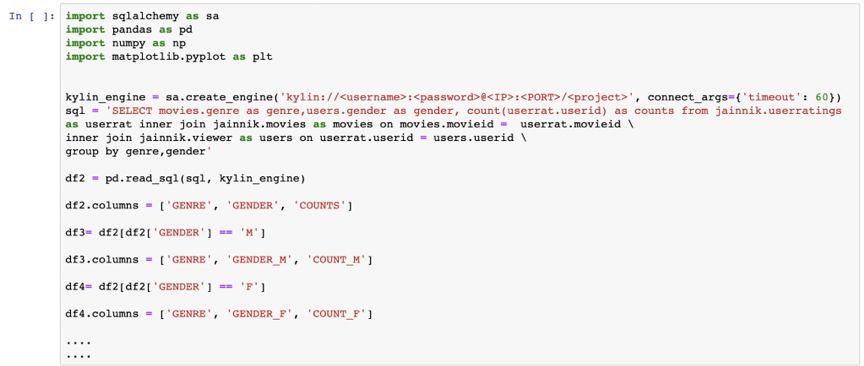
ДгЯТУцЕФЯрЙиОиеѓЃЈШШЭМЃЉжаЃЌЮвУЧПЩвдЫЕГіЙлгАШЫжАвЕКЭЕчгАСїХЩжЎМфЕФЙиЯЕЁЃР§ШчЃКХЉУёВЛЯВЛЖЙлПДаќвЩЦЌЃЌЖјДѓбЇЩњИќЯВЛЖеьЬНЦЌЛђМЭТМЦЌЁЃ
ЯТЭМЯдЪОСЫФГЬиЖЈФъЗнУПжмгУЛЇЖдВЛЭЌСїХЩЕчгАЕФЦНОљЦРЗжЧїЪЦЁЃДгЭМБэжаПЩвдПДГіЃЌМЭТМЦЌКЭЗИзяЕчгАЪЧШЫУЧЕФзюАЎЃЌЖјЖљЭЏЕчгАЕФЦНОљЦРЗжзмЪЧзюЕЭЕФЁЃ
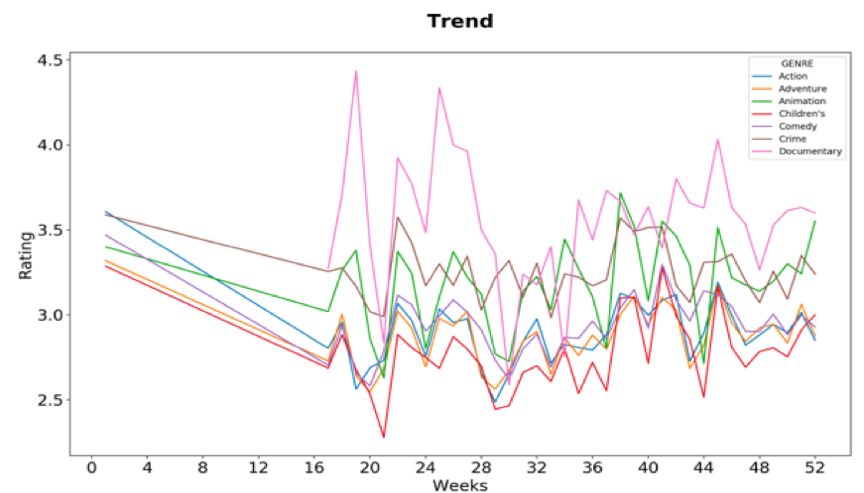
Apache Kylin Python SQL ЧїЪЦЯпЭМ
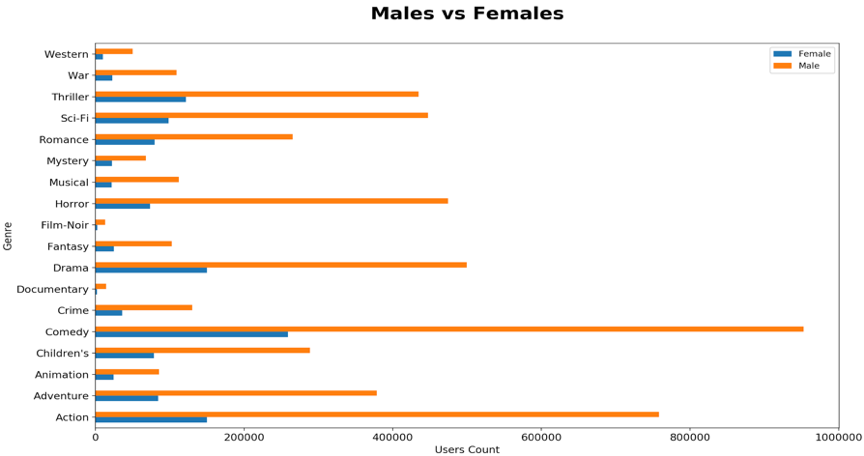
ЯТУцЕФСНИіЩЂЕуЭМгУгкВЂХХБШНЯЃЌвдЭЦЖЯФаадКЭХЎадЕФЦРМЖжЎМфЕФЯрЙиадЁЃ
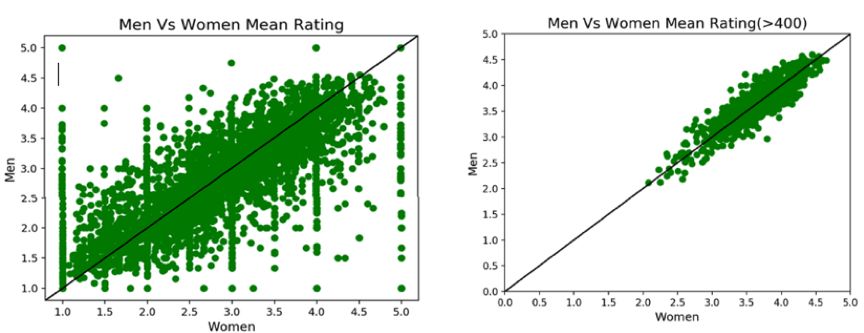
зѓЭМЃКЩЂЕуЭМЯдЪОФаадКЭХЎадЃЈЫљгаЕчгАЃЉЕФЦНОљЦРЗжГЪЯпаддіГЄЧїЪЦЃЌЭМжаИпЖШМЏжаЕФВПЗжОљдШЗжВМдкВЮПМЯпЕФСНВрЃЌетБэУїГ§СЫЩйЪ§ЕчгАЪеЪгТЪЃЌФаадКЭХЎадЙлгАЦЋКУЧїЭЌЁЃ
гвЭМЃКЩЂЕуЭМЪЧЭЈЙ§НіИєРыЦРМЖГЌЙ§ 400 ДЮЕФЕчгАЖјВњЩњЕФЁЃдкетжжЧщПіЯТЃЌЮвУЧвВПЩвдПДЕНФаадКЭХЎадЕФЦРЗжЯрЫЦЃЌетБэУїЮвУЧЕФГѕВНЭЦТлЪЧзМШЗЕФЁЃ
дк Apache Kylin ЩЯПЊЪМЪЙгУ Python
ЮвУЧЬжТлСЫ Python ШчКЮЪЙгУ Kylinpy ПтЧсЫЩЕигы Apache Kylin ЕФ OLAP
ММЪѕМЏГЩЃЌЖј Kylinpy ПтгжгУгкдкЮвУЧЕФЪОР§ЕчгАЪ§ОнМЏЩЯдЫааИпМЖЗжЮіЁЃЮвУЧЛЙЪЙгУ PandasЃЌMatplotlib
КЭ Seaborn ПтРДВйзїКЭПЩЪгЛЏ Apache Kylin ЖрЮЌЪ§ОнМЏжаЕФЪ§ОнЁЃ
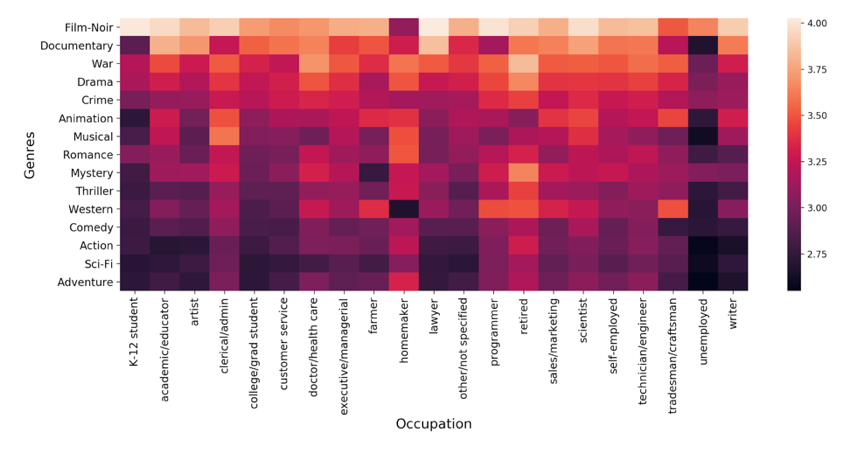
етбљЕФЗжЮіШУЮвУЧЩюШыСЫНтШЫУЧЖдВЛЭЌЕчгАРраЭЕФЯВКУЫцзХЪБМфЕФЭЦвЦЖјБфЛЏЁЃЫќЛЙИцЫпЮвУЧВЛЭЌЕчгАРраЭБфЛЏЧїЪЦжЎМфЕФЙиСЊЖШЁЃЯёетбљЕФМћНтПЩФмЖдЕчгАЦРТлМвгагУЁЃ
ШчЙћФњЛђФњЕФЭХЖгдкЗУЮЪДѓСПЪ§ОнМЏЪБгіЕНЮЪЬтЃЌВЂЯЃЭћРћгУ Kylin ЕФДѓЪ§Он OLAP ЗНЗЈНјааЛњЦїбЇЯАЛђЪ§ОнПЦбЇВйзїЃЌФЧУД
Apache KylinЃЈМАЦфЯрЙиЦѓвЕДѓЪ§ОнЦНЬЈ KyligenceЃЉНЋЮЊФњЬсЙЉАяжњЁЃ |









