| БрМЭЦМі: |
БОЦЊЮФеТЪзЯШМђЕЅНщЩмвЛЯТKylinЪЧЪВУДЁЂKylinЕФКЫаФИХФюЃЌЦфДЮНщЩмСЫKylinдЫаадРэвдМАKylinЗўЮёЦїФЃЪНЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1.ИХЪі
1.1 KylinЪЧЪВУД
Apache KylinЃЈExtreme OLAP Engine for Big DataЃЉЪЧвЛИіПЊдДЕФЗжВМЪНЗжЮів§ЧцЃЌЮЊHadoopЕШДѓаЭЗжВМЪНЪ§ОнЦНЬЈжЎЩЯЕФГЌДѓЙцФЃЪ§ОнМЏЭЈЙ§БъзМSQLВщбЏМАЖрЮЌЗжЮіЃЈOLAPЃЉЙІФмЃЌЬсЙЉбЧУыМЖЕФНЛЛЅЪНЗжЮіФмСІЁЃ
1.2 KylinЕФгЩРД
Apache KylinЃЌжаЮФУћїшїыЃЌЪЧHadoopЖЏЮядАЕФживЊГЩдБЁЃApache KylinЪЧвЛИіПЊдДЕФЗжВМЪНЗжЮів§ЧцЃЌзюГѕгЩeBayПЊЗЂЙБЯзжСПЊдДЩчЧјЁЃЫќЬсЙЉHadoopжЎЩЯЕФSQLВщбЏНгПкМАЖрЮЌЗжЮіЃЈOLAPЃЉФмСІвджЇГжДѓЙцФЃЪ§ОнЃЌФмЙЛДІРэTBФЫжСPBМЖБ№ЕФЗжЮіШЮЮёЃЌФмЙЛдкбЧУыМЖВщбЏОоДѓЕФHiveБэЃЌВЂжЇГжИпВЂЗЂЁЃ
Apache Kylinгк2014Фъ10дТдкgithubПЊдДЃЌВЂКмПьдк2014Фъ11дТМгШыApacheЗѕЛЏЦїЃЌгк2015Фъ11дТе§ЪНБЯвЕГЩЮЊApacheЖЅМЖЯюФПЃЌвВГЩЮЊЪзИіЭъШЋгЩжаЙњЭХЖгЩшМЦПЊЗЂЕФApacheЖЅМЖЯюФПЁЃгк2016Фъ3дТЃЌApache
KylinКЫаФПЊЗЂГЩдБДДНЈСЫKyligenceЙЋЫОЃЌСІЧѓИќКУЕиЭЦЖЏЯюФПКЭЩчЧјЕФПьЫйЗЂеЙЁЃ
1.3 ЮЊЪВУДашвЊKylin
дкДѓЪ§ОнЕФБГОАЯТЃЌHadoopЕФГіЯжНтОіСЫЪ§ОнДцДЂЮЪЬтЃЌЕЋШчКЮЖдКЃСПЪ§ОнНјааOLAPВщбЏЃЌШДвЛжБСюШЫЪЎЗжЭЗЬлЁЃ
ЦѓвЕжаДѓЪ§ОнВщбЏДѓжТЗжЮЊСНжжЃКМДЯЏВщбЏКЭЖЈжЦВщбЏЁЃ
Ђй МДЯЏВщбЏ
HiveЁЂSparkSQLЕШOLAPв§ЧцЃЌЫфШЛдкКмДѓГЬЖШЩЯНЕЕЭСЫЪ§ОнЗжЮіЕФФбЖШЃЌЕЋЫќУЧЖМжЛЪЪгУгкМДЯЏВщбЏЕФГЁОАЁЃЫќУЧЕФгХЕуЪЧВщбЏСщЛюЃЌЕЋЪЧЫцзХЪ§ОнСПКЭМЦЫуИДдгЖШЕФдіГЄЃЌЯьгІЪБМфВЛФмЕУЕНБЃжЄЁЃ
Ђк ЖЈжЦВщбЏ
ЖрЪ§ЧщПіЯТЪЧЖдгУЛЇЕФВйзїзіГіЪЕЪБЗДгІЃЌHiveЕШВщбЏв§ЧцКмФбТњзуЪЕЪБВщбЏЃЌвЛАужЛФмЖдЪ§ОнВжПтжаЕФЪ§ОнНјааЬсЧАМЦЫуЃЌШЛКѓНЋНсЙћДцШыMysqlЕШЙиЯЕаЭЪ§ОнПтЃЌзюКѓЬсЙЉИјгУЛЇНјааВщбЏЁЃ
дкЩЯЪіБГОАЯТЃЌApache KylinгІдЫЖјЩњЁЃВЛЭЌгк"ДѓЙцФЃВЂааДІРэ"HiveЕШМмЙЙЃЌApache
KylinВЩгУ"дЄМЦЫу"ЕФФЃЪНЃЌгУЛЇжЛашвЊЬсЧАЖЈвхКУВщбЏЮЌЖШЃЌKylinНЋАяжњЮвУЧНјааМЦЫуЃЌВЂНЋНсЙћДцДЂЕНHBaseжаЃЌЮЊКЃСПЪ§ОнЕФВщбЏКЭЗжЮіЬсЙЉбЧУыМЖЗЕЛиЃЌЪЧвЛжжЕфаЭЕФ"ПеМфЛЛЪБМф"ЕФНтОіЗНАИЁЃApache
KylinЕФГіЯжВЛНіКмКУЕиНтОіСЫКЃСПЪ§ОнПьЫйВщбЏЕФЮЪЬтЃЌвВБмУтСЫЪжЖЏПЊЗЂКЭЮЌЛЄЬсЧАМЦЫуГЬађДјРДЕФвЛЯЕСаТщЗГЁЃ
2.КЫаФИХФю
2.1 Ъ§ОнВжПт
Data WarehouseЃЌМђГЦDWЃЌжаЮФУћЪ§ОнВжПтЃЌЪЧЩЬвЕжЧФмЃЈBIЃЉжаЕФКЫаФВПЗжЁЃжївЊЪЧНЋВЛЭЌЪ§ОндДЕФЪ§ОнећКЯЕНвЛЦ№ЃЌЭЈЙ§ЖрЮЌЗжЮіЕШЗНЪНЮЊЦѓвЕЬсЙЉОіВпжЇГжКЭБЈБэЩњГЩЁЃ
Ъ§ОнВжПтгыЪ§ОнПтжївЊЧјБ№ЃКгУЭОВЛЭЌ
ЂйЁЂЪ§ОнПтУцЯђЪТЮёЃЌЖјЪ§ОнВжПтУцЯђЗжЮіЁЃ
ЂкЁЂЪ§ОнПтвЛАуДцДЂдкЯпЕФвЕЮёЪ§ОнЃЌашвЊЖдЩЯВувЕЮёЕФИФБфзіГіЪЕЪБЗДгІЃЌЩцМАЕНдіЩОВщИФЕШВйзїЃЌЫљвдашвЊзёбШ§ДѓЗЖЪНЃЌашвЊACIDЁЃЖјЪ§ОнВжПтжаДцДЂЕФдђжївЊЪЧРњЪЗЪ§ОнЃЌжївЊФПЕФЪЧЮЊЦѓвЕОіВпЬсЙЉжЇГжЃЌЫљвдПЩФмДцдкДѓСПЪ§ОнШпгрЃЌЕЋРћгкЖрИіЮЌЖШВщбЏЃЌЮЊОіВпепЬсЙЉИќЖрЙлВьЪгНЧЁЃ
дкДЋЭГBIСьгђжаЃЌЪ§ОнВжПтЕФЪ§ОнЭЌбљДцДЂдкOracleЁЂMySQLЕШЪ§ОнПтжаЃЌЖјдкДѓЪ§ОнСьгђжазюГЃгУЕФЪ§ОнВжПтОЭЪЧApache
HiveЃЌHiveвВЪЧApache KylinФЌШЯЕФЪ§ОндДЁЃ
2.2 OLAPгыOLTP
OLAPЃЈOnline Analytical ProcessЃЉЃЌСЊЛњЗжЮіДІРэЃЌвдЖрЮЌЖШЕФЗНЪНЗжЮіЪ§ОнЃЌвЛАуДјгажїЙлЕФВщбЏашЧѓЃЌЖргІгУдкЪ§ОнВжПтЁЃ
OLTPЃЈOnline Transaction ProcessЃЉЃЌСЊЛњЪТЮёДІРэЃЌВржигкЪ§ОнПтЕФдіЩОВщИФЕШГЃгУвЕЮёВйзїЁЃ
2.3 ЮЌЖШКЭЖШСП
ЮЌЖШКЭЖШСПЪЧЪ§ОнЗжЮіСьгђжаСНИіГЃгУЕФИХФюЁЃ
МђЕЅЕиЫЕЃЌЮЌЖШОЭЪЧЙлВьЪ§ОнЕФНЧЖШЁЃБШШчЦјЯѓеОЕФВЩМЏЪ§ОнЃЌПЩвдДгЪБМфЕФЮЌЖШРДЙлВьЃК
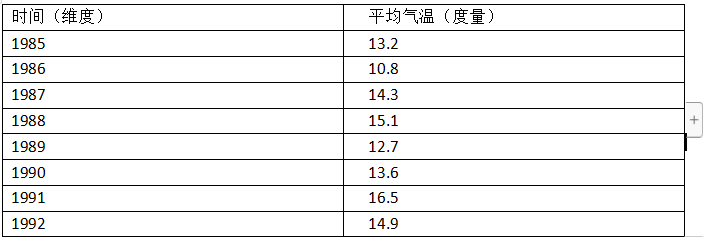
вВПЩвдДгЪБМфКЭЦјЯѓеОСНИіНЧЖШРДЙлВьЃК
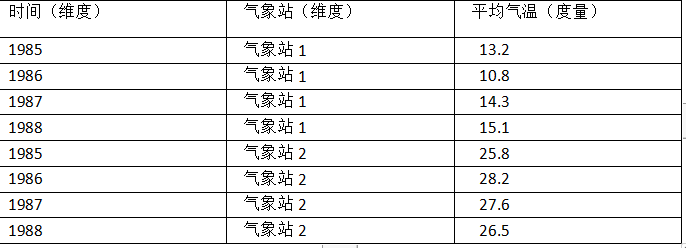
ЮЌЖШвЛАуЪЧРыЩЂЕФжЕЃЌБШШчЪБМфЮЌЖШЩЯЕФУПвЛИіЖРСЂЕФШеЦкЃЌЛђепЦјЯѓеОЮЌЖШЩЯЕФУПвЛИіЖРСЂЕФЦјЯѓеОIDЁЃвђДЫЭГМЦЪБПЩвдАбЮЌЖШЯрЭЌЕФМЧТМОлКЯдквЛЦ№ЃЌШЛКѓгІгУОлКЯКЏЪ§зіРлМгЁЂОљжЕЁЂзюДѓжЕЁЂзюаЁжЕЕШОлКЯМЦЫуЁЃ
ЖШСПОЭЪЧБЛОлКЯЕФЭГМЦжЕЃЌвВОЭЪЧОлКЯдЫЫуЕФНсЙћЃЌЫќвЛАуЪЧСЌајЕФжЕЃЌШчвдЩЯСНИіЭМжаЕФЮТЖШжЕЃЌЛђЪЧЦфЫћВтСПЕуЃЌБШШчЗчЫйЁЂЪЊЖШЁЂНЕгъСПЕШЕШЁЃЭЈЙ§ЖдЖШСПЕФБШНЯКЭЗжЮіЃЌЮвУЧОЭПЩвдЖдЪ§ОнзіГіЦРЙРЃЌБШШчНёФъЦНОљЦјЮТЪЧЗёдке§ГЃЗЖЮЇЃЌФГИіЦјЯѓеОЕФЦНОљЦјЮТЪЧЗёУїЯдИпгкЭљФъЦНОљЦјЮТЕШЕШЁЃ
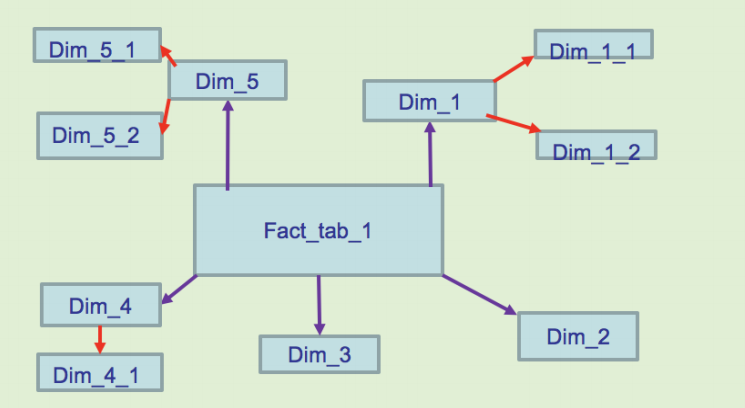
2.4 CubeКЭCuboid
ШЗЖЈКУСЫЮЌЖШКЭЖШСПжЎКѓЃЌШЛКѓИљОнЖЈвхКУЕФЮЌЖШКЭЖШСПЃЌЮвУЧОЭПЩвдЙЙНЈCubeЁЃЖдгквЛИіИјЖЈЕФЪ§ОнФЃаЭЃЌЮвУЧПЩвдЖдЦфЩЯЕФЫљгаЮЌЖШНјаазщКЯЁЃЖдгкNИіЮЌЖШРДЫЕЃЌзщКЯЫљгаПЩФмадЙВга2ЕФNДЮЗНжжЁЃЖдгкУПвЛжжЮЌЖШЕФзщКЯЃЌНЋЖШСПзіОлКЯМЦЫуЃЌШЛКѓНЋдЫЫуЕФНсЙћБЃДцЮЊвЛИіЮяЛЏЪгЭМЃЌГЦЮЊCuboidЁЃЫљгаЮЌЖШзщКЯЕФCuboidзїЮЊвЛИіећЬхЃЌБЛГЦЮЊCubeЁЃ
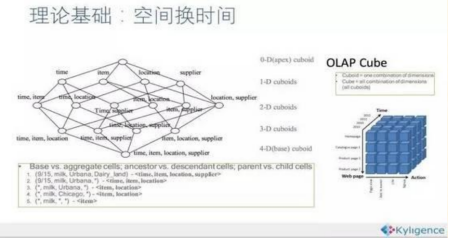
1МйЩшгавЛИіЕчЩЬЕФЯњЪлЪ§ОнМЏЃЌЦфжаЮЌЖШАќРЈЪБМфЃЈTimeЃЉЁЂЩЬЦЗЃЈItemЃЉЁЂЕиЕуЃЈLocationЃЉКЭЙЉгІ
2.ЩЬЃЈSupplierЃЉЃЌЖШСПЮЊЯњЪлЖюЃЈGMVЃЉЁЃФЧУДЫљгаЮЌЖШЕФзщКЯОЭга2ЕФ4ДЮЗНЃЌМД16жжЁЃ
3.вЛЮЌЖШЃЈ1DЃЉЕФзщКЯЃКга[Time]ЁЂ[Item]ЁЂ[Location]ЁЂ[Supplier]4жжЁЃ
4.ЖўЮЌЖШЃЈ2DЃЉЕФзщКЯЃКга[Time Item]ЁЂ[Time Location]ЁЂ[Time
Supplier]ЁЂ[Item Location]ЁЂ[Item Supplier]ЁЂ[Location
Supplier]6жжЁЃ
5.Ш§ЮЌЖШЃЈ3DЃЉЕФзщКЯЃКга[Time Item Location][Item
Location Supplier][Time Location Supplier][Time Item
Supplier]4жжЁЃ
6.зюКѓСуЮЌЖШЃЈ0DЃЉКЭЫФЮЌЖШЃЈ4DЃЉЕФзщКЯИїга[]КЭ[Time
Item Location Supplier]1жжЁЃМЦЫуCubiodЃЌМДАДЮЌЖШРДОлКЯЯњЪлЖюЁЃШчЙћгУSQLгяОфРДБэДяМЦЫуCuboid
[Time, Item]ЃЌФЧУДSQLгяОфЮЊЃКselect Time, Item, Sum(GMV)
as GMV from Sales group by Time, ItemНЋМЦЫуЕФНсЙћБЃДцЮЊЮяЛЏЪгЭМЃЌЫљгаCuboidЮяЛЏЪгЭМЕФзмГЦОЭЪЧCubeЁЃ
2.5 ЪТЪЕБэКЭЮЌЖШБэ
ЪТЪЕБэЃЈFact TableЃЉЪЧжИДцДЂгаЪТЪЕМЧТМЕФБэЃЌШчЯЕЭГШежОЁЂЯњЪлМЧТМЁЂгУЛЇЗУЮЪМЧТМЕШЁЃЪТЪЕБэЕФМЧТМЪЧЖЏЬЌдіГЄЕФЃЌЫљвдЫќЕФЬхЛ§ЭЈГЃдЖДѓгкЮЌЖШБэЁЃ
ЮЌЖШБэЃЈDimension TableЃЉЛђЮЌБэЃЌвВГЦЮЊВщевБэЃЈLookup TableЃЉЃЌЪЧгыЪТЪЕБэЯрЖдгІЕФвЛжжБэЁЃЫќБЃДцСЫЮЌЖШЕФЪєаджЕЃЌПЩвдИњЪТЪЕБэзіЙиСЊЃЛЯрЕБгкНЋЪТЪЕБэЩЯОГЃжиИДЕФЪєадГщШЁЁЂЙцЗЖГіРДгУвЛеХБэНјааЙмРэЁЃГЃМћЕФЮЌЖШБэгаЃКШеЦкБэЃЈДцДЂгыШеЦкЖдгІЕФжмЁЂдТЁЂМОЖШЕШЪєадЃЉЁЂЕиЧјБэЃЈАќКЌЙњМвЁЂЪЁ/жнЁЂГЧЪаЕШЪєадЃЉЕШЁЃЮЌЖШБэЕФБфЛЏЭЈГЃВЛЛсЬЋДѓЁЃ
ЪЙгУЮЌЖШБэгааэЖрКУДІЃК
ЂйЁЂЫѕаЁСЫЪТЪЕБэЕФДѓаЁЁЃ
ЂкЁЂБугкЮЌЖШЕФЙмРэКЭЮЌЛЄЃЌдіМгЁЂЩОГ§КЭаоИФЮЌЖШЕФЪєадЃЌВЛБиЖдЪТЪЕБэЕФДѓСПМЧТМНјааИФЖЏЁЃ
ЂлЁЂ ЮЌЖШБэПЩвдЮЊЖрИіЪТЪЕБэжигУЁЃ
2.6 аЧаЮФЃаЭ
ЮЌЖШНЈФЃЭЈГЃгжЗжЮЊаЧаЭФЃаЭЁЂбЉЛЈФЃаЭЃК
аЧаЮФЃаЭЃЈStar SchemaЃЉЪЧЪ§ОнЭкОђжаГЃгУЕФМИжжЖрЮЌЪ§ОнФЃаЭжЎвЛЁЃЫќЕФЬиЕуЪЧжЛгавЛеХЪТЪЕБэЃЌвдМАСуЕНЖрИіЮЌЖШБэЃЌЪТЪЕБэгыЮЌЖШБэЭЈЙ§жїЭтМќЯрЙиСЊЃЌЮЌЖШБэжЎМфУЛгаЙиСЊЃЌОЭЯёаэЖраЁаЧаЧЮЇШЦдквЛПХКуаЧжмЮЇЃЌЫљвдУћЮЊаЧаЮФЃаЭЁЃ
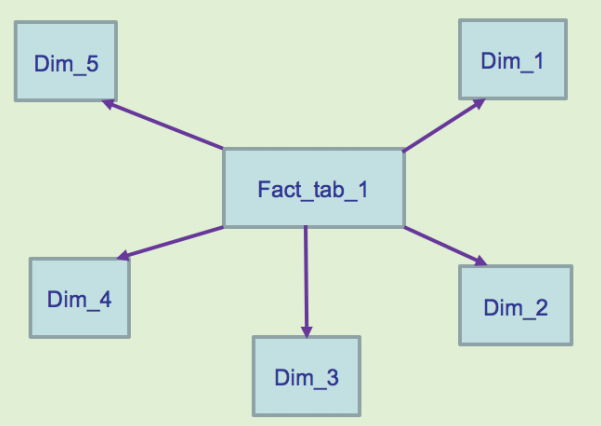
бЉЛЈФЃаЭЃЈSnowFlake SchemaЃЉЃЌОЭЪЧНЋаЧаЮФЃаЭжаЕФФГаЉЮЌБэГщШЁГЩИќЯИСЃЖШЕФЮЌБэЃЌШЛКѓШУЮЌБэжЎМфвВНјааЙиСЊЃЌетжжаЮзДПсЫЦбЉЛЈЕФЕФФЃаЭГЦЮЊбЉЛЈФЃаЭ
3.дЫаадРэ
KylinЕФКЫаФЫМЯыЪЧдЄМЦЫуЃЌМДЖдЖрЮЌЗжЮіПЩФмгУЕНЕФЖШСПНјаадЄМЦЫуЃЌНЋМЦЫуКУЕФНсЙћБЃДцГЩCubeЃЌЙЉВщбЏЪБжБНгЗУЮЪЁЃАбИпИДдгЖШЕФОлКЯдЫЫуЁЂЖрБэСЌНгЕШВйзїзЊЛЛГЩЖддЄМЦЫуНсЙћЕФВщбЏЃЌетОіЖЈСЫKylinФмЙЛгЕгаКмКУЕФПьЫйВщбЏКЭИпВЂЗЂФмСІЁЃ
3.1 ММЪѕМмЙЙ
Apache KylinЯЕЭГжївЊПЩвдЗжЮЊдкЯпВщбЏКЭРыЯпЙЙНЈСНВПЗжЃЌОпЬхМмЙЙЭМШчЯТЃК
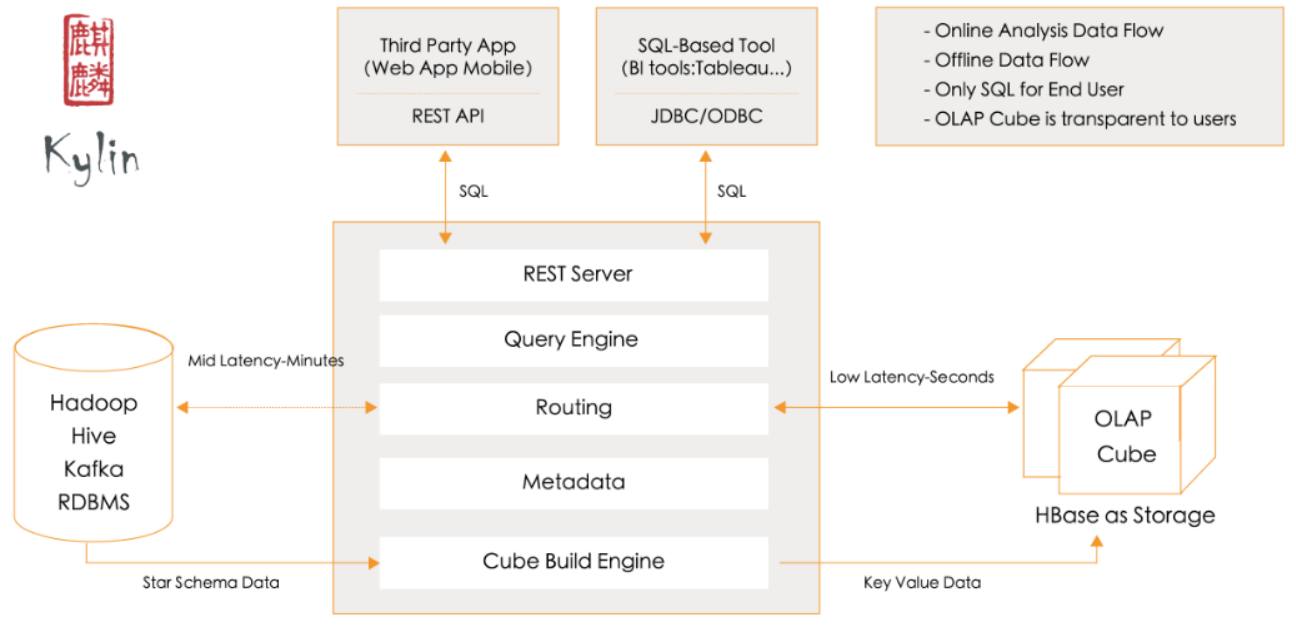
KylinЬсЙЉСЫвЛИіГЦзїLayer CubingЕФЫуЗЈЃЌРДЙЙНЈCubeЁЃМђЕЅРДЫЕЃЌОЭЪЧАДееdimensionЪ§СПДгДѓЕНаЁЕФЫГађЃЌДгBase
CuboidПЊЪМЃЌвРДЮЛљгкЩЯвЛВуCuboidЕФНсЙћНјаадйОлКЯЁЃУПвЛВуЕФМЦЫуЖМЪЧвЛИіЕЅЖРЕФMap ReduceЃЈSparkЃЉШЮЮёЁЃ
MapReduceЕФМЦЫуНсЙћзюжеБЃДцЕНHBaseжаЃЌHBaseжаУПааМЧТМЕФRowkeyгЩdimensionзщГЩЃЌ
measureЛсБЃДцдкcolumn familyжаЁЃЮЊСЫМѕаЁДцДЂДњМлЃЌетРяЛсЖдdimensionКЭmeasureНјааБрТыЁЃВщбЏНзЖЮЃЌРћгУHBaseСаДцДЂЕФЬиадОЭПЩвдБЃжЄKylinгаСМКУЕФПьЫйЯьгІКЭИпВЂЗЂЁЃ
3.2 Ьиад
SQLНгПк
KylinжївЊЕФЖдЭтНгПкОЭЪЧвдSQLЕФаЮЪНЬсЙЉЕФЁЃSQLМђЕЅвзгУЕФЬиадМЋДѓЕиНЕЕЭСЫKylinЕФбЇЯАГЩБОЃЌВЛТлЪЧЪ§ОнЗжЮіЪІЛЙЪЧWebПЊЗЂГЬађдБЖМФмДгжаЪевцЁЃ
жЇГжКЃСПЪ§ОнМЏ
ВЛТлЪЧHiveЁЂSparkSQLЃЌЛЙЪЧImpalaЃЌЫќУЧЕФВщбЏЪБМфЖМЫцзХЪ§ОнСПЕФдіГЄЖјЯпаддіГЄЁЃЖјApache
KylinЪЙгУдЄМЦЫуММЪѕДђЦЦСЫетвЛЕуЁЃKylinдкЪ§ОнМЏЙцФЃЩЯЕФОжЯоаджївЊШЁОігкЮЌЖШЕФИіЪ§КЭЛљЪ§ЃЌЖјВЛЪЧЪ§ОнМЏЕФДѓаЁЃЌЫљвдKylinФмИќКУЕижЇГжКЃСПЪ§ОнМЏЕФВщбЏЁЃ
бЧУыМЖЯьгІ
ЪмвцгкдЄМЦЫуММЪѕЃЌKylinЕФВщбЏЫйЖШЗЧГЃПьЃЌвђЮЊИДдгЕФСЌНгЁЂОлКЯЕШВйзїЖМдкCubeЕФЙЙНЈЙ§ГЬжавбОЭъГЩСЫЁЃ
ЫЎЦНРЉеЙ
Apache KylinЭЌбљПЩвдЪЙгУМЏШКВПЪ№ЗНЪННјааЫЎЦНРЉеЙЁЃЕЋВПЪ№ЖрИіНкЕужЛФмЬсИпKylinДІРэВщбЏЕФФмСІЃЌЖјВЛФмЬсЩ§ЫќЕФдЄМЦЫуФмСІЁЃ
ПЩЪгЛЏМЏГЩ
KylinЬсЙЉгыBIЙЄОпЕФећКЯФмСІЃЌШчTableauЃЌPowerBI/ExcelЃЌMSTRЃЌQlikSenseЃЌHueКЭSuperSetЁЃ
ЙЙНЈЖрЮЌСЂЗНЬхЃЈCubeЃЉ
гУЛЇФмЙЛдкKylinРяЮЊАйвквдЩЯЪ§ОнМЏЖЈвхЪ§ОнФЃаЭВЂЙЙНЈСЂЗНЬхЁЃ
4.KylinЗўЮёЦїФЃЪН
Kylin ЪЕР§ЪЧЮозДЬЌЕФЃЌЦфдЫааЪБзДЬЌДцДЂдк HBase (гЩ conf/kylin.properties
жаЕФ kylin.metadata.url жИЖЈ) жаЕФ metadata жаЁЃГігкИКдиОљКтЕФПМТЧЃЌНЈвщдЫааЖрИіKylin
ЪЕР§ЙВЯэвЛИі metadata ЃЌвђДЫЫћУЧдкБэНсЙЙжаЙВЯэЭЌвЛИізДЬЌЃЌБШШчjob зДЬЌ, Cube зДЬЌ,
ЕШЕШЁЃ
УПвЛИі Kylin ЪЕР§дк conf/kylin.properties жаЖМгавЛИі ЁАkylin.server.modeЁБ
entryЃЌжИЖЈСЫдЫааЪБЕФФЃЪНЃЌга 3 ИібЁЯю:
job : дкЪЕР§жадЫаа job engine; Kylin job engine ЙмРэМЏШК ЕФ jobsЁЃ
query : жЛдЫаа query engine; Kylin query engine НгЪеКЭЛигІФуЕФ
SQL ВщбЏЁЃ
all : дкЪЕР§жаМШдЫаа job engine вВдЫаа query enginesЁЃ
зЂвтФЌШЯЧщПіЯТжЛгавЛИіЪЕР§ПЩвддЫаа job engine (ЁАallЁБ
Лђ ЁАjobЁБ ФЃЪН), ЦфЫќашвЊЪЧ ЁАqueryЁБ ФЃЪН
5. ЦѓвЕгІгУАИР§
Apache KylinЫфШЛЛЙКмФъЧсЃЌЕЋвбОдкЖрИіЦѓвЕЕФЩњВњЯюФПжаЕУЕНСЫгІгУЁЃЯТУцЮвУЧРДПДвЛПДKylinдкЙњФкСНИіжјУћЦѓвЕФкЕФгІгУЁЃ
АйЖШЕиЭМ
ДѓЪ§ОнМЦЫуЗжЮіЕФШ§ДѓЭДЕуЃК
1.АйвкМЖКЃСПЪ§ОнЖрЮЌжИБъЖЏЬЌМЦЫуКФЪБЮЪЬтЃЌApache KylinЭЈЙ§дЄМЦЫуЩњГЩCubeНсЙћЪ§ОнМЏВЂДцДЂЕНHBaseЕФЗНЪННтОі;
2.ИДдгЬѕМўЩИбЁЮЪЬтЃЌгУЛЇВщбЏЪБЃЌApache KylinРћгУrouterВщевЫуЗЈМАгХЛЏЕФHBase
CoprocessorНтОіЃЛ
3.ПчдТЁЂМОЖШЁЂФъЕШДѓЪБМфЧјМфВщбЏЮЪЬтЃЌЖдгкдЄМЦЫуНсЙћЕФДцДЂЃЌApache KylinРћгУCubeЕФData
SegmentЗжЧјДцДЂЙмРэНтОіЁЃ
ет3ИіЭДЕуЕФНтОіЃЌЪЙАйЖШЕиЭМдкАйвкМЖДѓЪ§ОнЙцФЃЯТЃЌЧвЪ§ОнФЃаЭШЗЖЈЕФОпЬхЖрЮЌЗжЮіВњЦЗжаЃЌДяЕНЕЅЬѕSQLКСУыМЖЯьгІЁЃ
|









