| БрМЭЦМі: |
БОЮФвЛПЊЪМНщЩмСЫ
ЮЊЪВУДбЁдёKylinЃЌ KylinЕФЪЙгУЯжзДЃЌ ЁАЮЌЖШБЌеЈЁБЮЪЬтдкЪЕМљжаЪЧПЩНтЕФЃЌ
УРЭХЭтТєЕФЪЙгУАИР§ЕШЯрЙиФкШнЁЃ
БОЮФРДздДѓЪ§ОндгЬИЮЂаХЙЋжкКХЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
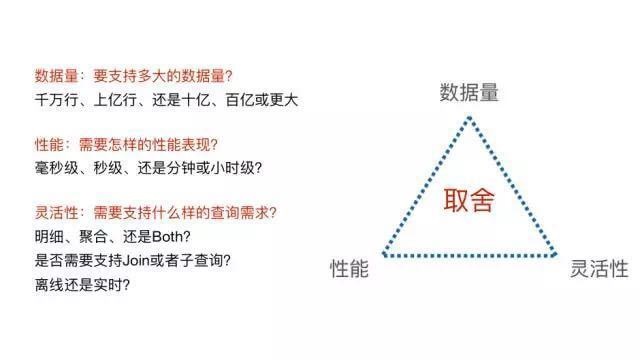
УРЭХЕуЦРЕФOLAPашЧѓДѓЬхЗжЮЊСНРрЃК
МДЯЏВщбЏЃКжИгУЛЇЭЈЙ§ЪжаДSQLРДЭъГЩвЛаЉСйЪБЕФЪ§ОнЗжЮіашЧѓЁЃетРрашЧѓЕФSQLаЮЪНЖрБфЁЂТпМИДдгЃЌЖдЯьгІЪБМфУЛгабЯИёЕФвЊЧѓЁЃ
ЙЬЛЏВщбЏЃКжИЖдвЛаЉЙЬЛЏЯТРДЕФШЁЪ§ЁЂПДЪ§ЕФашЧѓЃЌЭЈЙ§Ъ§ОнВњЦЗЕФаЮЪНЬсЙЉИјгУЛЇЃЌДгЖјЬсИпЪ§ОнЗжЮіКЭдЫгЊЕФаЇТЪЁЃетРрашЧѓЕФSQLгаЙЬЖЈЕФФЃЪНЃЌЖдЯьгІЪБМфгаБШНЯИпЕФвЊЧѓ
ЁЃ
ЮвУЧеыЖдМДЯЏВщбЏЬсЙЉСЫHiveКЭPrestoСНИів§ЧцЁЃЖјЙЬЛЏВщбЏгЩгкашвЊУыМЖЯьгІЃЌКмГЄвЛЖЮЪБМфЖМЪЧЭЈЙ§ЯШдкЪ§ВжЖдЪ§ОнзідЄОлКЯЃЌдйНЋОлКЯБэЕМШыMySQLЬсЙЉВщбЏЪЕЯжЕФЁЃЕЋЪЧЫцзХЙЋЫОвЕЮёЪ§ОнСПКЭИДдгЖШЕФВЛЖЯЬсЩ§ЃЌДг2015ФъПЊЪМЃЌетИіЗНАИГіЯжСЫШ§ИіБШНЯЭЛГіЕФЮЪЬтЃК
ЫцзХЮЌЖШЕФВЛЖЯдіМгЃЌдкЪ§ВжжаЮЌЛЄИїжжЮЌЖШзщКЯЕФОлКЯБэЕФГЩБОдНРДдНИпЃЌЪ§ОнПЊЗЂаЇТЪУїЯдЯТНЕ;
Ъ§ОнСПГЌЙ§ЧЇЭђааКѓЃЌMySQLЕФЕМШыКЭВщбЏБфЕУЗЧГЃТ§ЃЌОГЃАбMySQLИуБРЃЌDBAЕФБЇдЙКмДѓ;
гЩгкДѓЪ§ОнЦНЬЈШБЗІИќИпаЇТЪЕФВщбЏв§ЧцЃЌВщбЏашЧѓЖМХмдкHive/PrestoЩЯЃЌЕМжТМЏШКЕФМЦЫубЙСІДѓЃЌИњВЛЩЯвЕЮёашЧѓЕФдіГЄЁЃ
ЮЊСЫНтОіетаЉЭДЕуЃЌЮвУЧдк2015ФъФЉПЊЪМЕїбаИќИпаЇТЪЕФOLAPв§ЧцЃЌбАевЙЬЛЏВщбЏГЁОАЕФНтОіЗНАИЁЃ
ЮЊЪВУДбЁдёKylin
дкЕїбаСЫЪаУцЩЯжїСїЕФПЊдДOLAPв§ЧцКѓЃЌЮвУЧЗЂЯжЃЌФПЧАЛЙУЛгавЛИіЯЕЭГФмЙЛТњзуИїжжГЁОАЕФВщбЏашЧѓЁЃЦфБОжЪдвђЪЧЃЌУЛгавЛИіЯЕЭГФмЭЌЪБдкЪ§ОнСПЁЂадФмЁЂКЭСщЛюадШ§ИіЗНУцзіЕНЭъУРЃЌУПИіЯЕЭГдкЩшМЦЪБЖМашвЊдкетШ§епМфзіГіШЁЩсЁЃ
Р§Шч:
MPPМмЙЙЕФЯЕЭГЃЈPresto/Impala/SparkSQL/DrillЕШЃЉгаКмКУЕФЪ§ОнСПКЭСщЛюаджЇГжЃЌЕЋЪЧЖдЯьгІЪБМфЪЧУЛгаБЃжЄЕФЁЃЕБЪ§ОнСПКЭМЦЫуИДдгЖШдіМгКѓЃЌЯьгІЪБМфЛсБфТ§ЃЌДгУыМЖЕНЗжжгМЖЃЌЩѕжСаЁЪБМЖЖМгаПЩФмЁЃ
ЫбЫїв§ЧцМмЙЙЕФЯЕЭГЃЈElasticsearchЕШЃЉЯрЖдБШMPPЯЕЭГЃЌдкШыПтЪБНЋЪ§ОнзЊЛЛЮЊЕЙХХЫїв§ЃЌВЩгУScatter-GatherМЦЫуФЃаЭЃЌЮўЩќСЫСщЛюадЛЛШЁКмКУЕФадФмЃЌдкЫбЫїРрВщбЏЩЯФмзіЕНбЧУыМЖЯьгІЁЃЕЋЪЧЖдгкЩЈУшОлКЯЮЊжїЕФВщбЏЃЌЫцзХДІРэЪ§ОнСПЕФдіМгЃЌЯьгІЪБМфвВЛсЭЫЛЏЕНЗжжгМЖЁЃ
дЄМЦЫуЯЕЭГЃЈDruid/KylinЕШЃЉдђдкШыПтЪБЖдЪ§ОнНјаадЄОлКЯЃЌНјвЛВНЮўЩќСщЛюадЛЛШЁадФмЃЌвдЪЕЯжЖдГЌДѓЪ§ОнМЏЕФУыМЖЯьгІЁЃ
гаСЫетЬзПђМмЃЌЮвУЧВЛФбНсКЯУРЭХЕуЦРЕФздЩэашЧѓЬиЕуЃЌбЁдёКЯЪЪЕФOLAPв§ЧцЁЃ

ПЩвдПДГіЃЌЮвУЧЖдЪ§ОнСПКЭадФмЕФвЊЧѓЪЧБШНЯИпЕФЁЃMPPКЭЫбЫїв§ЧцЯЕЭГЮоЗЈТњзуГЌДѓЪ§ОнМЏЯТЕФадФмвЊЧѓЃЌвђДЫКмздШЛЕиЛсПМТЧдЄМЦЫуЯЕЭГЁЃЖјDruidжївЊУцЯђЕФЪЧЪЕЪБTimeseriesЪ§ОнЃЌЮвУЧЫфШЛвВгаРрЫЦЕФГЁОАЃЌЕЋжїСїЕФЗжЮіЛЙЪЧУцЯђЪ§ВжжаАДЬьЩњВњЕФНсЙЙЛЏБэЃЌвђДЫKylinЕФMOLAP
CubeЗНАИЪЧзюЪЪКЯЮвУЧГЁОАЕФв§ЧцЁЃ
KylinЕФЪЙгУЯжзД
2016ФъГѕЃЌЮвУЧПЊЪМЯђИїИівЕЮёЯпЭЦЙуЛљгкKylinЕФНтОіЗНАИЁЃОЙ§вЛФъЕФХЌСІЃЌKylinвбОгІгУЕНСЫУРЭХЕуЦРЕФМИКѕЫљгажївЊвЕЮёЯпЩЯЃЌВЂЧвдкЭтТєЁЂОЦТУЕШЪ§ИівЕЮёЯпЕУЕНСЫДѓЙцФЃЕФЪЙгУЃЌKylinвбОГЩЮЊСЫетаЉвЕЮёЕФЪзбЁOLAPв§ЧцЁЃ
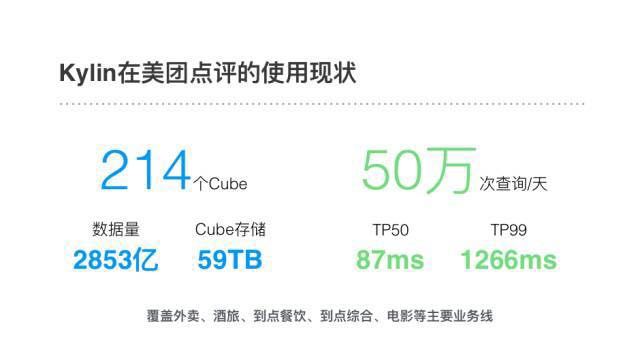
НижС16ФъЕзЃЌЩњВњЛЗОГЙВга214ИіCubeЃЌАќКЌЕФЪ§ОнзмааЪ§ЮЊ2853вкааЃЌCubeдкHBaseжаЕФДцДЂга59TBЁЃШеВщбЏДЮЪ§ГЌЙ§СЫ50ЭђДЮЃЌTP50ВщбЏЪБбг87msЃЌTP99ЪБбг1266msЃЌКмКУЕиТњзуСЫЮвУЧЖдадФмЕФвЊЧѓЁЃ
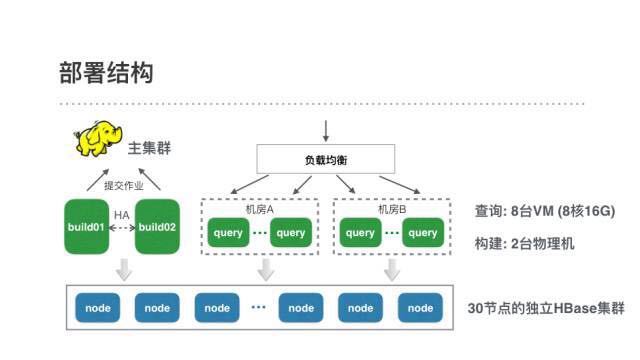
ЮЊСЫжЇГжетаЉашЧѓЃЌЮвУЧЕФЯпЩЯЛЗОГАќКЌвЛИі30НкЕуЕФKylinзЈЪєHBaseМЏШКЃЌ2ЬЈгУгкCubeЙЙНЈЕФЮяРэЛњЃЌКЭ8ЬЈ8КЫ16GЕФVMгУзїKylinЕФВщбЏЛњЁЃCubeЕФЙЙНЈЪЧдЫаадкжїМЦЫуМЏШКЕФMRзївЕЃЌИївЕЮёЯпЕФЙЙНЈШЮЮёВ№ЗжЕНСЫЫћУЧИїздЕФзЪдДЖгСаЩЯЁЃ
гЩгкKylinЖдЭтЪЧRESTНгПкЃЌЮвУЧНгШыСЫЙЋЫОЭГвЛЕФhttpЗўЮёжЮРэПђМмРДЪЕЯжИКдиОљКтКЭЦНЛЌжиЦєЁЃ
ЁАЮЌЖШБЌеЈЁБЮЪЬтдкЪЕМљжаЪЧПЩНтЕФ
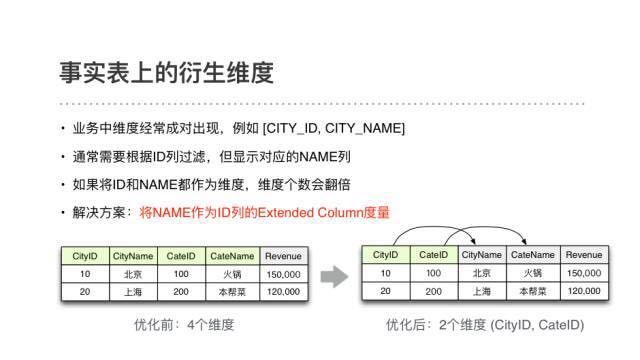
ЬсЕНMOLAP CubeЗНАИЃЌКмЖрУЛНгДЅЙ§KylinЕФШЫЛсЕЃаФЁАЮЌЖШБЌеЈЁБЕФЮЪЬтЃЌМДУПдіМгвЛИіЮЌЖШЃЌгЩгкЮЌЖШзщКЯЪ§ЗБЖЃЌCubeЕФМЦЫуКЭДцДЂСПвВЛсГЩБЖдіГЄЁЃЮвУЧЦ№ГѕЦфЪЕвВгаЭЌбљЕФЕЃаФЃЌЕЋЕїбаКЭЪЙгУKylinвЛеѓзгКѓЗЂЯжЃЌетИіЮЪЬтдкЪЕМљжаВЂУЛгаЯыЯѓЕФбЯжиЁЃетжївЊЪЧвђЮЊ
KylinжЇГжPartial CubeЃЌВЛашвЊЖдЫљгаЮЌЖШзщКЯЖМНјаадЄМЦЫуЃЛ
ЪЕМЪвЕЮёжаЃЌЮЌЖШжЎМфЭљЭљДцдкбмЩњЙиЯЕЃЌЖјKylinПЩвдАббмЩњЮЌЖШЕФМЦЫуДгдЄМЦЫуЭЦГйЕНВщбЏДІРэНзЖЮЁЃ

вдЪТЪЕБэЩЯЕФбмЩњЮЌЖШЮЊР§ЃЌЮвУЧвЕЮёжаЕФКмЖрЮЌЖШЖМЪЧ(ID, NAME)ГЩЖдГіЯжЕФЁЃВщбЏЪБашвЊЖдIDСаНјааЙ§ТЫЃЌЕЋЯдЪОЪБжЛашвЊШЁЖдгІЕФNAMEСаЁЃШчЙћАбетСНСаЖМзїЮЊЮЌЖШЃЌЮЌЖШИіЪ§ЛсЗБЖЁЃЖјдкKylinжаЃЌПЩвдАбNAMEзїЮЊIDСаЕФextendedcolumnжИБъЃЌетбљCubeжаЕФЮЌЖШИіЪ§ОЭМѕАыСЫЁЃ
ЯТУцЗжЯэвЛаЉЮвУЧЯпЩЯCubeЕФЭГМЦЪ§ОнЁЃ
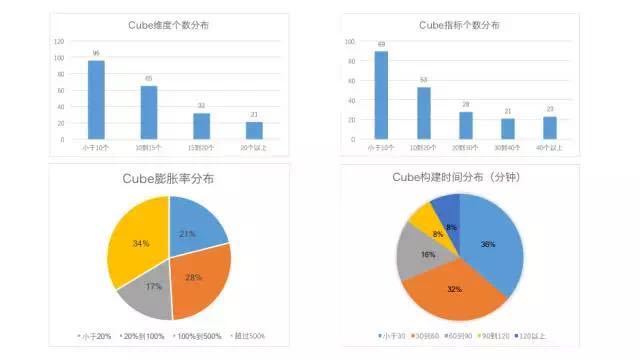
ПЩвдПДЕНЃЌВЩгУбмЩњЮЌЖШКѓЃЌ90%ЕФГЁОАПЩвдАбCubeжаЕФЮЌЖШИіЪ§ЃЈRowkeyСаЪ§ЃЉПижЦдк20ИівдФкЁЃжИБъИіЪ§ГЪЯжГЄЮВЗжВМЃЌаЁгк10ИіжИБъЕФCubeЪЧзюЖрЕФЃЌВЛЙ§вВгаНќвЛАыЕФCubeжИБъЪ§ГЌЙ§20ЁЃзмЙВга382ИіШЅжижИБъЃЌеМЕНСЫзмжИБъЪ§ЕФ10%ЃЌОјДѓЖрЪ§ЖМЪЧОЋШЗШЅжижИБъЁЃ49%ЕФCubeХђеЭТЪаЁгк100%ЃЌМДCubeДцДЂСПВЛГЌЙ§ЩЯгЮHiveБэЁЃ68%ЕФCubeФмЙЛдк1аЁЪБФкЭъГЩЙЙНЈЃЌ92%дк2аЁЪБФкЭъГЩЙЙНЈЁЃ
УРЭХЭтТєЕФЪЙгУАИР§
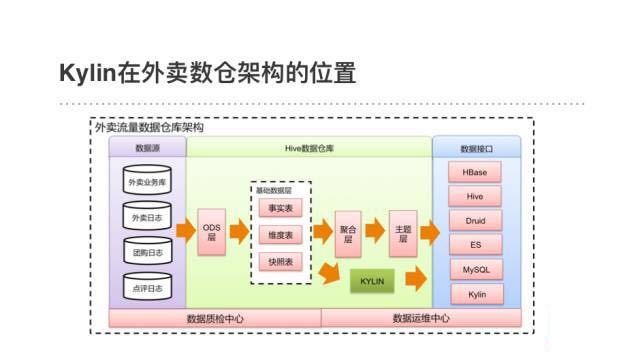
ЯТУцЗжЯэвЛЯТKylinдкУРЭХЭтТєЕФЪЙгУАИР§ЃЌИааЛЭтТєЕФЭЌЪТ НљЙњЮРКЭЛнУї ЬсЙЉВФСЯЁЃ
ЭтТєЪ§ОнвЕЮёЖдНЛЛЅЪНЕФOLAPЗжЮігазХКмЧПЕФашЧѓЁЃдкЪЙгУKylinвдЧАЃЌВЩгУЕФЪЧдкHiveжаПЊЗЂОлКЯБэдйЕМШыMySQLЕФЗНАИЁЃЫцзХвЕЮёЪ§ОнСПИпЫйдіГЄКЭашЧѓЕФВЛЖЯЩ§МЖЃЌетЬзЗНАИгіЕНСЫПЊЭЗЬсЕНЕФВщбЏаЇТЪКЭПЊЗЂаЇТЪЕФЫЋжиЮЪЬтЁЃ

дкЪЙгУKylinКѓЃЌГ§СЫВщбЏадФмЕФЯджјЬсЩ§ЃЌЭтТєЕФЪ§ОнПЊЗЂЗНЪНЗЂЩњСЫКмДѓЕФИФБфЁЃдРДашвЊзіЗБЫіЕФОлКЯВуКЭжїЬтВуЪ§ОнЃЌЯждкжЛашвЊАбжиЕуЗХЕНЛљДЁЪ§ОнЕФНЈЩшЩЯЃЌдЄМЦЫуЕФЙЄзїНЛИјKylinОЭааСЫЁЃдкЖдЭЌвЛИіашЧѓЭЌЪБВЩгУРЯЗНАИКЭKylinЗНАИЪЕЪЉКѓЗЂЯжЃЌЪЙгУKylinКѓЕФЪ§ОнПЊЗЂаЇТЪЬсЩ§СЫ3БЖЁЃ
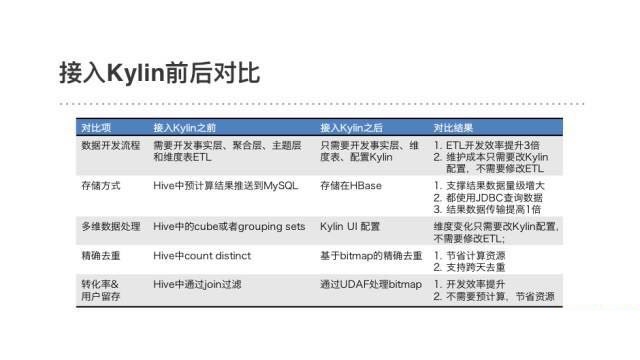
ЯТУцЪЧвЛИіЖдСїСПЪ§ОнгІгУKylinЕФОпЬхАИР§ЁЃЮвУЧдкKylin 1.5.3АцБОЬэМгСЫШЋОжзжЕфЃЌЪЕЯжСЫЩЯвкЛљЪ§ЁЂШЮвтРраЭзжЖЮЃЈР§ШчЩшБИIDЃЉЕФОЋШЗШЅжиМЦЪ§ЃЌАбKylinЕФЪЙгУГЁОАРЉПэЕНСЫСїСПЪ§ОнЁЃ



ЦНЬЈЛЏОбщгыЫМПМ
вЛИіПЊдДЯюФПДгrunЦ№РДЕНеце§зїЮЊЦНЬЈЛЏЕФЗўЮёЬсЙЉГіШЅЃЌжаМфЛсгіЕНКмЖрЕФЬєеНКЭЮЪЬташвЊНтОіЁЃЯТУцЪЧЮвУЧзмНсЕФвЛаЉОбщЃЌдкетРяЗжЯэИјДѓМвЃЌвВЛЖгЭЌааУЧКЭЮвУЧвЛЦ№ЬНЬжЁЃ




|









