| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ
Presto ЕФprestoЛљБОМмЙЙЃЌPrestoжаSQLдЫааЙ§ГЬЃЌPrestoМрПиКЭХфжУЃЌДѓЪ§ОнOLAPв§ЧцЖдБШЕШЯрЙиФкШнЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
prestoЪЧЪВУД ЪЧFacebookПЊдДЕФЃЌЭъШЋЛљгкФкДцЕФВЂ?МЦЫуЃЌЗжВМЪНSQLНЛЛЅЪНВщбЏв§Чц
ЪЧвЛжжMassively parallel processing (MPP)МмЙЙЃЌЖрИіНкЕуЙмЕРЪНжД?
ГжШЮвтЪ§ОндДЃЈЭЈЙ§РЉеЙЪНConnectorзщМўЃЉЃЌЪ§ОнЙцФЃGB~PBМЖ
ЪЙгУЕФММЪѕЃЌШчЯђСПМЦЫуЃЌЖЏЬЌБрвыжД?МЦЛЎЃЌгХЛЏЕФORCКЭParquet ReaderЕШ
prestoВЛЬЋжЇГжДцДЂЙ§ГЬЃЌжЇГжВПЗжБъзМsql
prestoЕФВщбЏЫйЖШБШhiveПь5-10БЖ
ЩЯУцНВЪіСЫprestoЪЧЪВУДЃЌВщбЏЫйЖШЃЌЯждкРДПДПДprestoЪЪКЯИЩЪВУД
ЪЪКЯЃКPBМЖКЃСПЪ§ОнИДдгЗжЮіЃЌНЛЛЅЪНSQLВщбЏЃЌ?ГжПчЪ§ОндДВщбЏ
ВЛЪЪКЯЃКЖрИіДѓБэЕФjoinВйзїЃЌвђЮЊprestoЪЧЛљгкФкДцЕФЃЌЖреХДѓБэдкФкДцРяПЩФмЗХВЛЯТ
КЭhiveЕФЖдБШЃК
hiveЪЧвЛИіЪ§ОнВжПтЃЌЪЧвЛИіНЛЛЅЪНБШНЯШѕвЛЕуЕФВщбЏв§ЧцЃЌНЛЛЅЪНУЛгаprestoФЧУДЧПЃЌЖјЧвжЛФмЗУЮЪhdfsЕФЪ§Он
prestoЪЧвЛИіНЛЛЅЪНВщбЏв§ЧцЃЌПЩвддкКмЖЬЕФЪБМфФкЗЕЛиВщбЏНсЙћЃЌУыМЖЃЌЗжжгМЖЃЌФмЗУЮЪКмЖрЪ§ОндД
hiveдкВщбЏ100GbМЖБ№ЕФЪ§ОнЪБЃЌЯћКФЪБМфвбОЪЧЗжжгМЖСЫ
ЕЋЪЧprestoЪЧШЁДњВЛСЫhiveЕФЃЌвђЮЊpШЋВПЕФЪ§ОнЖМЪЧдкФкДцжаЃЌЯожЦСЫдкФкДцжаЕФЪ§ОнМЏДѓаЁЃЌБШШчЖрИіДѓБэЕФjoinЃЌетаЉДѓБэЪЧВЛФмЭъШЋЗХНјФкДцЕФЃЌЪЕМЪгІгУжаЃЌЖдгкдкprestoЕФВщбЏЪЧгавЛЖЈЙцЖЈЬѕМўЕФЃЌБШБШШчЫЕвЛИіВщбЏдкprestoВщбЏГЌЙ§30ЗжжгЃЌФЧОЭkillЕєАЩЃЌЫЕУїВЛЪЪКЯдкprestoЩЯЪЙгУЃЌжївЊдвђЪЧЃЌВщбЏЙ§ДѓЕФЛАЃЌЛсеМгУећИіМЏШКЕФзЪдДЃЌетЛсЕМжТФуКѓајЕФВщбЏЪЧУЛгазЪдДНјааВщбЏЕФЃЌетИњprestoЕФЩшМЦРэФюЪЧГхЭЛЕФЃЌОЭЯёЪЧФуНјаавЛИіВщбЏЃЌЕЋЪЧвЊЕШИі5ЗжжгВХгазЪдДМЬајВщбЏЃЌетЪЧКмВЛКЯРэЕФЃЌНЛЛЅЪНОЭБфЕУШѕСЫКмЖр
prestoЛљБОМмЙЙ дкЬИprestoМмЙЙжЎЧАЃЌЯШЛиЙЫЯТhiveЕФМмЙЙ
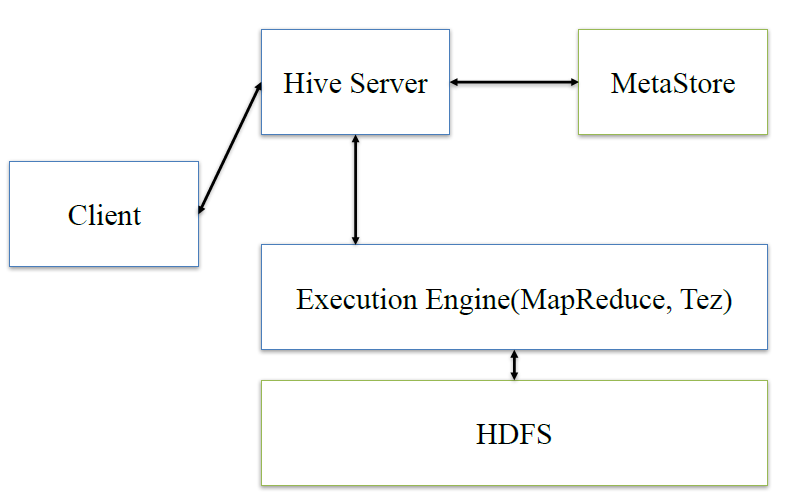
hiveЃКclientНЋВщбЏЧыЧѓЗЂЫЭЕНhive serverЃЌЫќЛсКЭmetastorНЛЛЅЃЌЛёШЁБэЕФдЊаХЯЂЃЌШчБэЕФЮЛжУНсЙЙЕШЃЌжЎКѓhive
serverЛсНјаагяЗЈНтЮіЃЌНтЮіГЩгяЗЈЪїЃЌБфГЩВщбЏМЦЛЎЃЌНјаагХЛЏКѓЃЌНЋВщбЏМЦЛЎНЛИјжДаав§ЧцЃЌФЌШЯЪЧMRЃЌШЛКѓЗвыГЩMR
prestoЃКprestoЪЧдкЫќФкВПзіhiveРрЫЦЕФТпМ
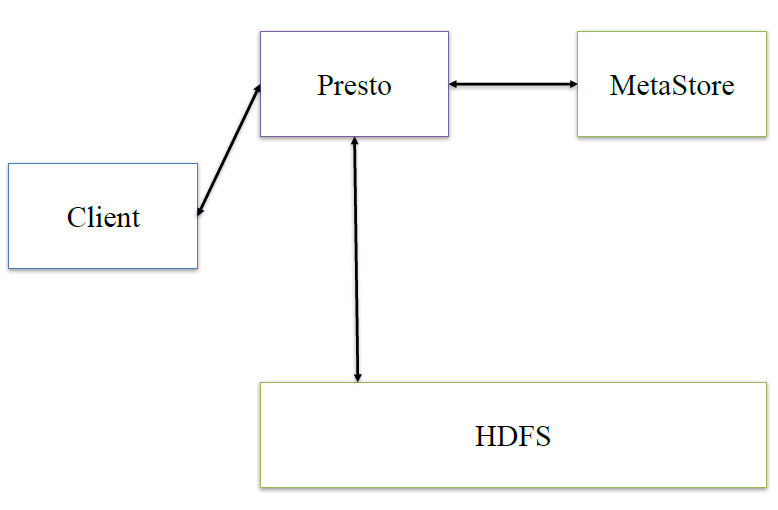
НгЯТРДЃЌЩюШыПДЯТprestoЕФФкВПМмЙЙ
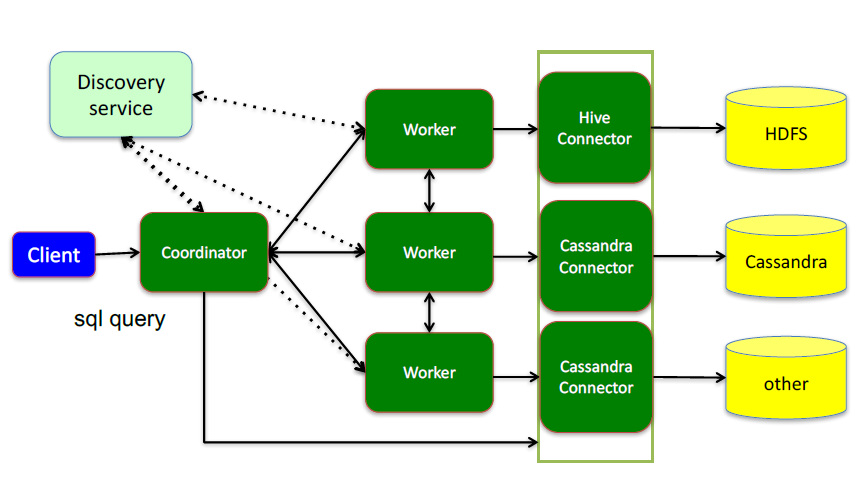
етРяУцШ§ИіЗўЮёЃК
CoordinatorЃЈПМЕкФкterЃЉЃЌЪЧвЛИіжааФЕФВщбЏНЧЩЋЃЌЫќжївЊЕФвЛИізїгУЪЧНгЪмВщбЏЧыЧѓЃЌНЋЫћУЧзЊЛЛГЩИїжжИїбљЕФШЮЮёЃЌНЋШЮЮёВ№НтКѓЗжЗЂЕНЖрИіworkerШЅжДааИїжжШЮЮёЕФНкЕу
1ЁЂНтЮіSQLгяОф
2ЁЂ?ГЩжД?МЦЛЎ
3ЁЂЗжЗЂжД?ШЮЮёИјWorkerНкЕужД?
WorkerЃЌЪЧвЛИіеце§ЕФМЦЫуЕФНкЕуЃЌжДааШЮЮёЕФНкЕуЃЌЫќНгЪеЕНtaskКѓЃЌОЭЛсЕНЖдгІЕФЪ§ОндДРяУцЃЌШЅАбЪ§ОнЬсШЁГіРДЃЌЬсШЁЗНЪНЪЧЭЈЙ§ИїжжИїбљЕФconnectorЃК
1ЁЂИКд№ЪЕМЪжД?ВщбЏШЮЮё
Discovery serviceЃЌЪЧНЋcoordinatorКЭwokerНсКЯЕНвЛЦ№ЕФЗўЮёЃК
1ЁЂWorkerНкЕуЦєЖЏКѓЯђDiscovery ServerЗўЮёзЂВс
2ЁЂCoordinatorДгDiscovery ServerЛёЕУWorkerНкЕу
coordinatorКЭwokerжЎМфЕФЙиЯЕЪЧдѕУДЮЌЛЄЕФФиЃПЪЧЭЈЙ§Discovery ServerЃЌЫљгаЕФworkerЖМАбздМКзЂВсЕНDiscovery
ServerЩЯЃЌDiscovery ServerЪЧвЛИіЗЂЯжЗўЮёЕФserviceЃЌDiscovery
ServerЗЂЯжЗўЮёжЎКѓЃЌcoordinatorБужЊЕРдкЮвЕФМЏШКжагаЖрЩйИіworkerФмЙЛИјЮвЙЄзїЃЌШЛКѓЮвЗжХфЙЄзїЕНworkerЪББугаСЫИљОн
зюКѓЃЌprestoЪЧЭЈЙ§connector pluginЛёШЁЪ§ОнКЭдЊаХЯЂЕФЃЌЫќВЛЪЧ?ИіЪ§ОнДцДЂв§ЧцЃЌВЛашвЊгаЪ§ОнЃЌprestoЮЊЦфЫћЪ§ОнДцДЂЯЕЭГЬсЙЉСЫSQLФм?ЃЌПЭЛЇЖЫавщЪЧHTTP+JSON
PrestoжЇГжЕФЪ§ОндДКЭДцДЂИёЪН Hadoop/Hive connectorгыДцДЂИёЪНЃК
HDFSЃЌORCЃЌRCFILEЃЌParquetЃЌSequenceFileЃЌText
ПЊдДЪ§ОнДцДЂЯЕЭГЃК
MySQL & PostgreSQLЃЌCassandraЃЌKafkaЃЌRedis
ЦфЫћЃК
MongoDBЃЌElasticSearchЃЌHBase
PrestoжаSQLдЫааЙ§ГЬЃКећЬхСїГЬ
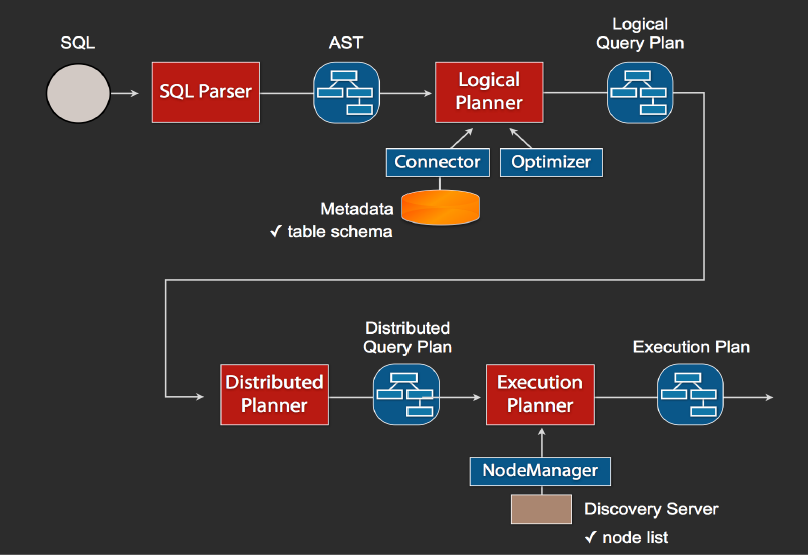
1ЁЂЕБЮвУЧжДаавЛЬѕsqlВщбЏЃЌcoordinatorНгЪеЕНетЬѕsqlгяОфвдКѓЃЌЫќЛсгавЛИіsqlЕФгяЗЈНтЮіЦїШЅАбsqlгяЗЈНтЮіБфГЩвЛИіГщЯѓЕФгяЗЈЪїASTЃЌетГщЯѓЕФгяЗЈЪщЫќРяУцжЛЪЧНјаавЛаЉгяЗЈНтЮіЃЌШчЙћФуЕФsqlгяОфРяУцЃЌБШШчЫЕЙиМќзжФугУЕФЪЧintЖјВЛЪЧIntegerЃЌОЭЛсдкгяЗЈНтЮіетРяИјБЉТЖГіРД
2ЁЂШчЙћгяЗЈЪЧЗћКЯsqlгяЗЈЙцЗЖЃЌжЎКѓЛсОЙ§вЛИіТпМВщбЏМЦЛЎЦїЕФзщМўЃЌЫћЕФжївЊзїгУЪЧЃЌБШШчЫЕФуsqlРяУцГіЯжЕФБэЃЌЫћЛсЭЈЙ§connectorЕФЗНЪНШЅmetaРяУцАбБэЕФschemaЃЌСаУћЃЌСаЕФРраЭЕШЃЌШЋВПИјевГіРДЃЌНЋетаЉаХЯЂЃЌИњгяЗЈЪїИјЖдгІЦ№РДЃЌжЎКѓЛсЩњГЩвЛИіЮяРэЕФгяЗЈЪїНкЕуЃЌетИігяЗЈЪїНкЕуРяУцЃЌВЛНігЕгаСЫЫќЕФВщбЏЙиЯЕЃЌЛЙгЕгаРраЭЕФЙиЯЕЃЌШчЙћдкетвЛВНЃЌЪ§ОнПтБэРяФГвЛСаЕФРраЭЃЌИњФуsqlЕФРраЭВЛвЛжТЃЌОЭЛсдкетРяБЈДэ
3ЁЂШчЙћЭЈЙ§ЃЌОЭЛсЕУЕНвЛИіТпМЕФВщбЏМЦЛЎЃЌШЛКѓетИіТпМВщбЏМЦЛЎЃЌЛсБЛЫЭЕНвЛИіЗжВМЪНЕФТпМВщбЏМЦЛЎЦїРяУцЃЌНјаавЛИіЗжВМЪНЕФНтЮіЃЌЗжВМЪННтЮіРяУцЃЌЫћОЭЛсШЅАбЖдгІЕФУПвЛИіВщбЏМЦЛЎзЊЛЏЮЊtask
4ЁЂдкУПвЛИіtaskРяУцЃЌЫћЛсАбЖдгІЕФЮЛжУаХЯЂШЋВПИјЬсШЁГіРДЃЌНЛИјжДааЕФplanЃЌгЩplanАбЖдгІЕФtaskЗЂИјЖдгІЕФworkerШЅжДааЃЌетОЭЪЧећИіЕФвЛИіЙ§ГЬ
етЪЧвЛИіЭЈгУЕФsqlНтЮіСїГЬЃЌЯёhiveвВЪЧзёбРрЫЦетбљЕФСїГЬЃЌВЛвЛбљЕФЕиЗНЪЧdistribution
plannerКЭexecutor panЃЌетРяЪЧИїИів§ЧцВЛвЛбљЕФЕиЗНЃЌЧАУцЛљБОЩЯЖМвЛжТЕФ
PrestoжаSQLдЫааЙ§ГЬЃКMapReduce vs Presto
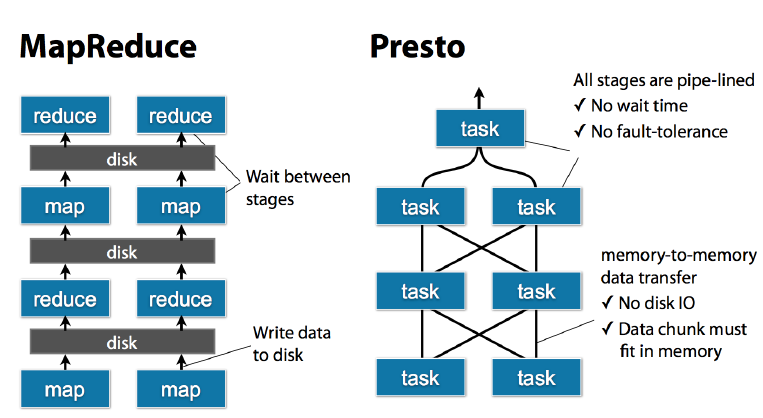
taskЪЧЗХдкУПИіworkerЩЯИУжДааЕФЃЌУПИіtaskжДааЭъжЎКѓЃЌЪ§ОнЪЧДцЗХдкФкДцРяСЫЃЌЖјВЛЯёmrвЊаДДХХЬЃЌШЛКѓЕБЖрИіtaskжЎМфвЊНјааЪ§ОнНЛЛЛЃЌБШШчshuffleЕФЪБКђЃЌжБНгДгФкДцРяДІРэ
PrestoМрПиКЭХфжУЃКМрПи Web UI
QueryЛљБОзДЬЌЕФВщбЏ
JMX HTTP API
GET /v1/jmx/mbean[/{objectName}] com.facebook.presto.execution:name=TaskManager com.facebook.presto.execution:name=QueryManager com.facebook.presto.execution:name=NodeScheduler ЪТМўЭЈжЊ Event Listener query start, query complete
PrestoМрПиКЭХфжУЃКХфжУ жДааМЦЛЎМЦЛЎЃЈCoordinatorЃЉ node-scheduler.include-coordinator
ЪЧЗёШУcoordinatorдЫааtask
query.initial-hash-partitions
УПИіGROUP BYВйзїЪЙ?ЕФhash bucket(=tasks)зюДѓЪ§ФП(default:
8)
node-scheduler.min-candidates
УПИіstageВЂЗЂдЫааЙ§ГЬжаПЩЪЙгУЕФзюДѓworkerЪ§ФПЃЈdefaultЃК10ЃЉ
query.schedule-split-batch-size
УПИіsplitЪ§ОнСП
ШЮЮёжДааЃЈWorkerЃЉ query.max-memory (default: 20 GB)
вЛИіВщбЏПЩвдЪЙгУЕФзюДѓМЏШКФкДц
ПижЦМЏШКзЪдДЪЙгУЃЌЗРжЙвЛИіДѓВщбЏеМзЁМЏШКЫљгазЪдД
ЪЙгУresource_overcommitПЩвдЭЛЦЦЯожЦ
query.max-memory-per-node (default: 1 GB)
вЛИіВщбЏдквЛИіНкЕуЩЯПЩвдЪЙгУЕФзюДѓФкДц
ОйР§
PrestoМЏШКХфжУЃК 120G * 40
query.max-memory=1 TB
query.max-memory-per-node=20 GB
query.max-run-time (default: 100 d)
вЛИіВщбЏПЩвддЫааЕФзюДѓЪБМф
ЗРжЙгУЛЇЬсНЛвЛИіГЄЪБМфВщбЏзшШћЦфЫћВщбЏ
task.max-worker-threads (default: Node CPUs * 4)
УПИіworkerЭЌЪБдЫааЕФsplitИіЪ§
ЕїДѓПЩвддіМгЭЬЭТТЪЃЌЕЋЪЧЛсдіМгФкДцЕФЯћКФ
ЖгСаЃЈQueueЃЉ ШЮЮёЬсНЛЛђепзЪдДЪЙгУЕФвЛаЉХфжУЃЌЪЧЭЈЙ§ЖгСаЕФХфжУРДЪЕЯжЕФ
зЪдДИєРыЃЌВщбЏПЩвдЬсНЛЕНЯргІЖгСажа
зЪдДИєРыЃЌВщбЏПЩвдЬсНЛЕНЯргІЖгСажа УПИіЖгСаПЩвдХфжУACLЃЈШЈЯоЃЉ УПИіЖгСаПЩвдХфжУQuota ПЩвдВЂЗЂдЫааВщбЏЕФЪ§СП ХХЖгЕФзюДѓЪ§СП

ДѓЪ§ОнOLAPв§ЧцЖдБШ PrestoЃКФкДцМЦЫуЃЌmppМмЙЙ
DruidЃКЪБађЃЌЪ§ОнЗХФкДцЃЌЫїв§ЃЌдЄМЦЫу
Spark SQLЃКЛљгкSpark CoreЃЌmppМмЙЙ
KylinЃКCubeдЄМЦЫуЁЁЁЁ
зюКѓЃЌвЛаЉСуЩЂЕФжЊЪЖЕуs
prestoЪЪКЯpbМЖЕФКЃСПЪ§ОнВщбЏЗжЮіЃЌВЛЪЧЫЕАбpbЕФЪ§ОнЗХНјФкДцЃЌБШШчвЛеХpbБэЃЌВщбЏcountЃЌvagетжжгаИіЬиЕуЃЌЫфШЛЪ§ОнКмЖрЃЌЕЋЪЧзюжеЕФВщбЏНсЙћКмаЁЃЌетжжОЭВЛЛсАбЪ§ОнЖМЗХЕНФкДцРяУцЃЌжЛЪЧдкдЫЫуЕФЙ§ГЬжаЃЌФУГівЛаЉЪ§ОнЗХФкДцЃЌШЛКѓМЦЫуЃЌдкХзГіЃЌдкФУЃЌетжжЕФФкДцеМгУСПЪЧКмаЁЕФЃЌЕЋЪЧjoinетжжЃЌдкдЫЫуЕФжаМфЙ§ГЬЛсВњЩњДѓСПЕФЪ§ОнЃЌЛђепЫЕФЧжжВщбЏЕФЪ§ОнВЛДѓЃЌЕЋЪЧЩњГЩЕФЪ§ОнСПКмДѓЃЌетжжвВЪЧВЛКЯЪЪгУprestoЕФЃЌЕЋВЛЪЧЫЕВЛФмзіЃЌжЛЪЧЛсеМгУДѓСПФкДцЃЌЯћКФКмГЄЕФЪБМфЃЌетжжhiveКЯЪЪЕу
prestoЫуЪЧhiveЕФвЛИіВЙГфЃЌашвЊОЁПьЕУГіНсЙћЕФгУprestoЃЌЗёдђгУhive
workЪЧВПЪ№ЕФЪБКђОЭЪТЯШВПЪ№КУЕФЃЌworkЦєЖЏ100ИіЃЌЪЙгУЕФworkВЛвЛЖЈ100ИіЃЌЖјЪЧИљОнcoordinatorРДОіЖЈВ№ЗжГЩЖрЩйИіtaskЃЌШЛКѓЗжЗЂЕНЖрЩйИіworkШЅ
вЛИіcoordinatorПЩФмЭЌЪБгжЖрИігУЛЇдкЧыЧѓqueryЃЌШЛКѓЙВЯэworkЕФШЅжДааЃЌетЪЧвЛИіЙВЯэЕФМЏШК
coordinatorКЭdiscovery serverПЩвдЦєЖЏдквЛИіНкЕувЛИіНјГЬЃЌвВПЩвдЗХдкВЛЭЌЕФnodeЩЯЃЌЕЋЪЧЯждкЙЋЫОДѓВПЗжЖМЪЧЗХдквЛИіНкЕуЩЯЃЌвЛИіlauncher
startЛсЭЌЪБАбЩЯЪіСНИіЦєЖЏЦ№РД
ЖдгкprestoЕФШнДэЃЌШчЙћФГИіworkerЙвЕєСЫЃЌdiscovery serverЛсЗЂЯжВЂЭЈжЊcoordinator
ЕЋЪЧЖдгквЛИіqueryЃЌЪЧУЛгаШнДэЕФЃЌвЛЕЉвЛИіworkЙвСЫЃЌФЧУДећИіqureyОЭЪЧАмСЫ
вђЮЊЖдгкprestoЃЌЫћЕФВщбЏЪБМфЪЧКмЖЬЕФЃЌгыЦфВщбЏетРязіШнДэФмСІЃЌВЛШчжиаТжДааРДЕФПьРДЕФМђЕЅ
ЖдгкcoordinatorКЭdiscovery serverНкЕуЕФЕЅЕуЙЪеЯЃЌprestoЛЙУЛгаПЊЪМДІРэетИіЮЪЬтУВЫЦ
|









