| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ
Presto ЪЧЪВУДЃПPresto дкгадоЕФЪЙгУГЁОАЃЌPresto дкгадоЕФбнНјжЎТЗЕШЯрЙиФкШнЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂPresto НщЩм
Presto ЪЧгЩ Facebook ПЊЗЂЕФПЊдДДѓЪ§ОнЗжВМЪНИпадФм SQL ВщбЏв§ЧцЁЃЦ№ГѕЃЌFacebook
ЪЙгУ Hive РДНјааНЛЛЅЪНВщбЏЗжЮіЃЌЕЋ Hive ЪЧЛљгк MapReduce ЮЊХњДІРэЖјЩшМЦЕФЃЌбгЪБКмИпЃЌТњзуВЛСЫгУЛЇЖдгкНЛЛЅЪНВщбЏЯывЊПьЫйГіНсЙћЕФГЁОАЁЃЮЊСЫНтОі
Hive ВЂВЛЩУГЄЕФНЛЛЅЪНВщбЏСьгђЃЌFacebook ПЊЗЂСЫ PrestoЃЌзЈУХЮЊНЛЛЅЪНВщбЏЫљЩшМЦЃЌЬсЙЉЗжжгМЖФЫжСбЧУыМЖЕЭбгЪБЕФВщбЏадФмЁЃ
1.1 Presto МмЙЙ
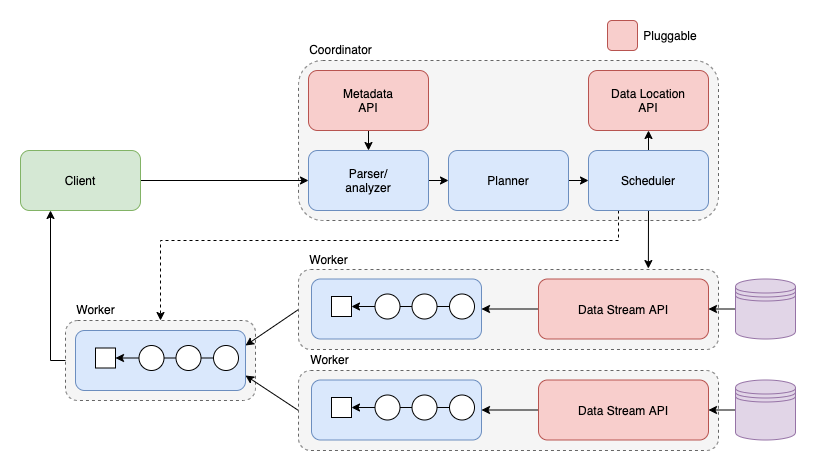
1.2 Presto жДааВщбЏЙ§ГЬ
Client ЗЂЫЭЧыЧѓИј CoordinatorЁЃ
SQL ЭЈЙ§ ANTLR НјааНтЮіЩњГЩ ASTЁЃ
AST ЭЈЙ§дЊЪ§ОнНјаагявхНтЮіЁЃ
гявхНтЮіКѓЕФЪ§ОнЩњГЩТпМжДааМЦЛЎЃЌВЂЧвЭЈЙ§ЙцдђНјаагХЛЏЁЃ
ЧаЗжТпМжДааМЦЛЎЮЊВЛЭЌ StageЃЌВЂЕїЖШ Worker НкЕуШЅЩњГЩ TaskЁЃ
Task ЩњГЩЯргІЮяРэжДааМЦЛЎЁЃ
ЕїЖШЭъКѓИљОнЕїЖШНсЙћ Coordinator НЋ Stage ДЎСЊЦ№РДЁЃ
Worker жДааЯргІЕФЮяРэжДааМЦЛЎЁЃ
Client ВЛЖЯЕиЯђ Coordinator РШЁВщбЏНсЙћЃЌCoordinator ДгзюжеЛуОлЪфГіЕФ
Worker НкЕуРШЁВщбЏНсЙћЁЃ
1.3 Presto ЮЊКЮИпадФм
Pipeline, ШЋФкДцМЦЫуЁЃ
SQL ВщбЏМЦЛЎЙцдђгХЛЏЁЃ
ЖЏЬЌДњТыЩњГЩММЪѕЁЃ
Ъ§ОнЕїЖШБОЕиЛЏЃЌзЂжиФкДцПЊЯњаЇТЪЃЌгХЛЏЪ§ОнНсЙЙЃЌCacheЃЌЗЧОЋШЗВщбЏЕШЦфЫќММЪѕЁЃ
ЖўЁЂPresto дкгадоЕФЪЙгУГЁОА
Ъ§ОнЦНЬЈ(DP)ЕФСйЪБВщбЏ: гадоЕФДѓЪ§ОнЭХЖгЪЙгУСйЪБВщбЏНјааЬНЫїадЕФЪ§ОнЗжЮіЕФЭГвЛШыПкЃЌЭЌЪБвВЬсЙЉСЫЭбУєЃЌЩѓМЦЕШЙІФмЁЃ
BI БЈБэв§ЧцЃКЮЊЩЬМвЬсЙЉСЫИїРрЗжЮіаЭЕФБЈБэЁЃ
дЊЪ§ОнЪ§ОнжЪСПаЃбщЕШЃКдЊЪ§ОнЯЕЭГЛсЪЙгУ Presto НјааЪ§ОнжЪСПаЃбщЁЃ
Ъ§ОнВњЦЗЃКБШШч CRM Ъ§ОнЗжЮіЃЌШЫШКЛЯёЕШЛсЪЙгУ Presto НјааМЦЫуЁЃ
Ш§ЁЂPresto дкгадоЕФбнНјжЎТЗ
ЕквЛНзЖЮ: Presto КЭ Hadoop ЛьКЯВПЪ№НзЖЮ:
Ц№ГѕЃЌPresto ЪЧКЭ Hadoop РыЯпМЏШКЛьКЯдквЛЦ№ВПЪ№ЕФЁЃЕЋЪЧФЧЪБКђгУЛЇОГЃЛсБЇдЙ Presto
жДааадФмВЛЮШЖЈЃЌЖдгкЭЌбљЕФ SQLЃЌЪБПьЪБТ§ЁЃЮвУЧЙлВьЕНЭЌбљЕФ TaskЃЌДІРэЕФЪ§ОнСПКЭЛЈЗбЕФCPU
Time РрЫЦЃЌЕЋЪЧгаЪБКђОЭЛсГіЯжФГаЉЬиБ№ГЄЕФElapsed TimeЕФTaskЃЌДгЖјЭЯТ§ећЬхЕФВщбЏадФмЁЃОЗжЮіЃЌЪЧвђЮЊдкетИіЪБМфЕуДХХЬ
IO ДјПэБЛ Hadoop РыЯпШЮЮёДђТњЕМжТЕФЁЃЫфШЛ Hadoop РыЯпМЏШКвЛАуШЮЮёЖМЛсдкСшГПНјааЕїЖШЃЌЕЋЪЧ
вВгавЛаЉШЮЮёЛсдкАзЬьВЛЖЈЦкЕиХмЃЌетжжЪБКђЭљЭљЛсБШНЯгАЯьадФмЁЃгкЪЧЮвУЧОіЖЈЭъШЋЖРСЂ Presto МЏШКЃЌВЂЧвЕЅЖРАВзА
HDFS ЛЗОГЁЃ
ЕкЖўНзЖЮ: Presto МЏШКЭъШЋЖРСЂНзЖЮ:
ЮвУЧзМБИНЋ Presto ЕЅЖРЙцЛЎГівЛИіМЏШКЃЌВЂЧвЕЅЖРАВзА HDFS ЛЗОГЃЌЖјРыЯп Hadoop МЏШКжЛашвЊНЋЪ§ОнУПЬьЕМШыЕНетИі
HDFS ЛЗОГжаЃЌДЫКѓРыЯп Hadoop МЏШКЫљгаЕФШЮЮёЖМВЛЛсгАЯь Presto МЏШКЁЃЕквЛИіЮЪЬтОЭгіЕНСЫЮвУЧШчКЮШЅНЋЯжгаРыЯп
Hadoop МЏШКЕФЪ§ОнБэЕМШыЕНаТЕФМЏШКЁЃФПЧАЮвУЧЕФЗНАИЪЧЙВЭЌЪЙгУвЛИі HiveЃЌЭЈЙ§ЮЊзЈУХаТНЈвЛИіПтЃЌдкДДНЈПтЕФЪБКђжИЖЈLocationЕФЗНЪНШЅЙиСЊЕН
Presto МЏШКЕФ HDFS NameServiceЁЃКѓУцгУЛЇдкетИіПтЯТУцНЈБэОЭЛсНЋ Hive БэДцДЂЕН
Presto МЏШКЁЃетЪБКђЮвУЧЕФ Presto адФмОЭЛсЯрЖдЮШЖЈЕУЖрЃЌЛљБОВЛдйЛсЭЌбљЕФtaskДІРэВюВЛЖрЪ§ОнСПЕФЪБКђгаМИИі
Elapsed Time ЬиБ№ИпЕФЧщПіСЫЁЃ
ЕкШ§НзЖЮ: ЕЭбгЪБвЕЮёзЈгУ Presto МЏШКНзЖЮ:
дкЕкЖўНзЖЮЮвУЧЕФвЕЮёжЎМфЕФзЪдДИєРыжївЊЛЙЪЧПП Resource GroupЃЌЕЋЪЧетжжИєРыЗНЪНЯрЖдБШНЯШѕЃЌВЛФмЬсЙЉЯИСЃЖШЕФИєРыЃЌШЮЮёжЎМфЛЙЪЧЛсЛЅЯргАЯьЁЃДЫЭтЃЌВЛЭЌвЕЮёЕФsqlРраЭЃЌВщбЏЪ§ОнСПЃЌВщбЏЪБМфЃЌПЩШнШЬЕФ
SLAЃЌПЩЬсЙЉЕФзюгХХфжУЖМЪЧВЛвЛбљЕФЁЃгааЉвЕЮёЗНашвЊвЛИіЬиБ№ЕЭЕФЯьгІЪБМфБЃжЄЃЌгкЪЧЮвУЧИјетРрвЕЮёВПЪ№СЫзЈУХЕФМЏШКШЅДІРэЁЃВПЪ№дкетИіМЏШКЩЯЕФвЕЮёвЊЧѓЕЭбгЪБЃЌЭЈГЃЪЧ3УыФкЃЌЩѕжСгааЉФмЙЛДяЕН1УыФкЃЌЖјЧвЛсгавЛЖЈСПЕФВЂЗЂЁЃВЛЙ§етРрвЕЮёЭЈГЃЪ§ОнСПВЛЪЧЗЧГЃДѓЃЌЖјЧвЭЈГЃЖМЪЧДѓПэБэЃЌвВОЭВЛашвЊдйШЅ
Join Б№ЕФЪ§ОнЃЌGroup By аЮГЩЕФ Group ЛљЪ§КЭВњЩњЕФОлКЯЪ§ОнСПВЛЪЧЬиБ№ДѓЃЌВщбЏЪБМфжївЊЯћКФдкЪ§ОнЩЈУшЖСШЁЪБМфЩЯЁЃЮвУЧЭЌбљвВЬсЙЉСЫзЪдДЭъШЋЖРСЂЃЌОпгаБОЕи
HDFS ЕФзЈгУ Presto МЏШКИјетРрвЕЮёЗНШЅЪЙгУЁЃДЫЭтЃЌЮвУЧЛсЮЊетжжвЕЮёЬсЙЉЩюЖШЕФадФмВтЪдЃЌЕїећЯргІЕФХфжУЃЌБШШчНЋ
Task Concurrency ИФГЩ1ЃЌдкВЂЗЂСПИпЕФВтЪдГЁОАжаЃЌЗДЖјгЩгкМѕЩйСЫЯпГЬМфЧаЛЛЃЌадФмЛсИќКУЁЃ
ЫФЁЂPresto дкгадоЪЙгУжаЕФгіЕНЕФЮЪЬт
4.1 HDFS аЁЮФМўЮЪЬт
HDFS аЁЮФМўЮЪЬтдкДѓЪ§ОнСьгђЪЧИіГЃМћЕФЮЪЬтЁЃЮвУЧЗЂЯжЮвУЧЕФЪ§Вж
Hive БэгааЉБэЕФЮФМўгаМИЧЇИіЃЌВщбЏЬиБ№Т§ЁЃPresto етСНИіВЮЪ§ЯожЦСЫ Presto УПИіНкЕуУПИі
Task ПЩжДааЕФзюДѓ Split Ъ§ФПЁЃ
node-scheduler.max-splits-per-node=100
node-scheduler.max-pending-splits-per-task=10 |
вђДЫЕБВщбЏгааэЖраЁЮФМўЕФБэЕФЪБКђЃЌЮЪЬтОЭБЌЗЂГіРДСЫЃЌВщбЏЦ№РДЬиБ№Т§ЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧЗжСНВНзп:
ЪЪЕБЕїДѓСЫетСНИіВЮЪ§.
дк SparkЃЌHive ETL ВуУцв§Шы Adaptive Spark КЭаЁЮФМўКЯВЂЙЄОпШЅНтОіетИіаЁЮФМўЮЪЬтЁЃ
4.2 е§дђБэДяЪНжИЪ§МЖБ№ЛиЫнЮЪЬт
гавЛЬьЃЌгаИігУЛЇвЛИіСйЪБВщбЏХмСЫ1ИіаЁЪБвВУЛЭЫГіЃЌЭЈЙ§ jstackЃЌевЕНСЫЖдгІДњТыЃЌЗЂОѕЪЧдкдЫаа
Presto РяУцЕФе§дђБэДяЪНв§Чц Joni ПтЦЅХфЕФДњТыЃЌКѓРДЗЂЯжЫћаДЕФЪЧвЛИіЛсВњЩњжИЪ§МЖБ№ЛиЫнЕФе§дђБэДяЪНЁЃЩчЧјЕФЗДРЁЪЧПЩвдНЋ
Presto ЕФе§дђБэДяЪНХфжУГЩ Google RE2JЃЌЕЋЪЧ RE2J ЛсЮўЩќЕєвЛаЉе§дђБэДяЪНЕФгяЗЈЁЃКѓРДЮвУЧОЁЙм
Presto ЪЧИіЖрЯпГЬжДаав§ЧцЃЌЕЋЪЧ Joni в§ЧцдкЩшМЦЩЯЛЙЪЧПЩвдБЛ Interrupt ЕФЃЌгкЪЧМгЩЯСЫВщбЏзюДѓдЫааЪБМфЕФЯожЦЃЌВЂЧвЭЈжЊСЫЯрЙиЕФгУЛЇЁЃЯъМћ
(https://github.com/prestodb/presto/issues/12191)
4.3 ЖрИіСа Distinct ЕФЮЪЬт
гавЛаЉБЈБэвЕЮёЪЧЪЙгУ Presto жБНгРДЫузЊЛЏТЪЕФЃЌетбљЕФБЈБэОЭЛсв§Ц№вЛИіВщбЏгяОфжагаЖрИі count
distinct СаЕФЮЪЬтЁЃШЛЖјВщПДадФмЕФЪБКђЛсЗЂОѕетжжгяОфЬиБ№Т§ЃЌКѓРДЗЂОѕЃЌОЭЫуЮвЪжЖЏНЋетИіВщбЏгяОфЗжГЩЖрИігяОфЃЌУПИігяОфШЅжДаавЛИі
count distinct ЪБЃЌвВБШКЯЦ№РДвЊПьЁЃгкЪЧЩюШыЕїбаСЫЯТЃЌSparkЃЌHive TEZЃЌCalcite
жЎРрЕФЗЂОѕ count distinct дк SQL гХЛЏЦїФЧБпЛсБЛгХЛЏЕєЃЌРДНтОіЪ§ОнЧуаБЕФЮЪЬтЁЃ
МђЕЅРДЫЕ: ЕЅСаЕФ count distinct:
select A, count(distinct
B) from T group by A.
зЊЛЛГЩ
select A, count(B) from (select A, B from T group
by A, B) group by A |
ЖјЖрИі count distinct СаЕФдРэРрЫЦЃЌОЭЪЧЛсЪЙгУ grouping
sets ШЅНЋЖрИі group by ећКЯЕНвЛЦ№РДЬсЩ§
SELECT a1, a2,...,
an, F1(b1), F2(b2), F3(b3), ...., Fm(bm), F1(distinct
c1), ...., Fm(distinct cm) FROM Table GROUP BY
a1, a2, ..., an
зЊЛЛЮЊ
SELECT a1, a2,..., an, arbitrary (if(group = 0,
f1)),...., arbitrary (if(group = 0, fm)), F(if(group
= 1, c1)), ...., F(if(group = m, cm)) FROM
SELECT a1, a2,..., an, F1(b1) as f1, F2(b2) as
f2,...., Fm(bm) as fm, c1,..., cm group FROM
SELECT a1, a2,..., an, b1, b2, ... ,bn, c1,...,
cm FROM Table GROUP BY GROUPING SETS ((a1, a2,...,
an, b1, b2, ... ,bn), (a1, a2,..., an, c1), ...,
((a1, a2,..., an, cm)))
GROUP BY a1, a2,..., an, c1,..., cm group
GROUP BY a1, a2,..., an |
Presto ЖдгкЖрИі count distinct СаетЗНУцВЂУЛгаШЅЪЕЯжЁЃ
етБпЮвУЧФПЧАВЩгУЕФЗНАИЪЧ:
аоИФДњТыШЅЪЕЯжЃЌВЂЧвЬсНЛСЫ Issue КЭ PR ИјЩчЧјЃЌвЛИіБЛ merge СЫЃЌЛЙгавЛИіЛЙдк review
жаЃЌКѓајЛЙЛсМЬајИњНјЁЃ
Issue: [Optimize distinct aggregation on multi column
PR1: Fix Count(*) on empty relation returns NULL
when optimizemixeddistinct_aggregation is turned on
Merged
PR2: [Optimize distinct aggregation on multiple columns
Reviewing
ШУвЕЮёЗНПЩвдШнШЬЗЧОЋШЗШЅжиЕФбЁгУ approxmate_distinct ШЅЪЕЯжЁЃ
4.4 HDFS Namenode ЕМжТгаЩйЪ§ВщбЏЛсЯрЖдТ§вЛЕу
дкЮвУЧИјгУЛЇзізЈгУprestoМЏШКЖРСЂЕФадФмВтЪдЪБЃЌЮвУЧЗЂЯжЭЌбљЕФSQLЛсгаКмЩйЪ§ВщбЏТ§вЛЕуЃЌКѓРДбаОПСЫЯТЗЂЯж
Presto Coordinator ШЅЭЈЙ§
| public RemoteIterator< LocatedFileStatus>
listLocatedStatus(final Path f) |
ЕїгУЧыЧѓ HDFS NameNode ЕФЪБКђЃЌгаЪБКђЛсбгГй1УыКѓЗЕЛиЁЃКѓРДЗЂОѕетИіЪБКђе§КУЪЧ NameNode
дкзі Edit Log Rolling ЕФЪБКђЃЌгЩгкетИіЪБКђ NameNode ЛсШЅФУЖСаДЫјЕФаДЫјЃЌДгЖјзшШћСЫЖСЧыЧѓЛёЕУЖСЫјЃЌвђДЫгаЪБКђбгГй1УыКѓЗЕЛиЁЃ
етИіЮЪЬтФПЧАгЩгкЛљБОПЩШнШЬЃЌЯжНзЖЮвВТњзуСЫвЕЮёЗНЕФ SLAЃЌЫљвдКѓУцУЛгаШЅНтОі: ЮвИіШЫОѕЕУЃЌHDFS
ВЂВЛЪЧЮЊСЫдкЯпЗўЮёЩшМЦЕФЃЌвЊЬсИп HDFS RPC ЧыЧѓЕФЮШЖЈадЃЌгавдЯТМИжжЗНЪН:
ВЮПМ[
Uber в§ШыСЫ Observer NameNode ]ЁЃ
ЪЙгУ AlluxioЃЌЮвУЧМђЕЅВтЪдСЫЯТ AlluxioЃЌAlluxio Master КУЯёВЛЛсГіЯжетжжЮЪЬтЃЌдкКѓУцЖдЮДРДЕФеЙЭћаЁНкжаЃЌЮвУЧЬсЕНСЫ
Alluxio + Presto ЕФвтвхЁЃ
ГЂЪдИќЛЛ NameNode ЕФХЬЮЊ SSD ХЬЃЌМѕЩй Edit Log Rolling ЕФЪБМфЁЃ
ЮхЁЂЖдЮДРДЕФеЙЭћ
5.1 Presto + Alluxio
Alluxio ЭЈЙ§ФмЙЛЯИСЃЖШЕФШЅПижЦФкДцЃЌЛсБШДПДтЕФПП OS Page Cache ШЅПижЦвГМЖБ№ЛКДцИќОпгагХЪЦЁЃФуПЩвдНЋвЛИіБэМгдиЕН
Alluxio РяУцЃЌШЛКѓУПДЮЖдЫќЕФЗУЮЪ IO етПщЛЈЗбЕФЪБМфЛљБОПЩвдЫЕЪЧПьЫйЧвКуЖЈЕФЁЃЕБШЛЃЌЮвУЧвВашвЊРэадПДД§
AlluxioЃЌДгдРэБОжЪЩЯРДНВЃЌОЭ Presto ЖСШЁЪ§ОнетПщЃЌетИівЊЪгЧщПіЖјТл. ЮвУЧВтЪдЙ§ Presto
ЬсЙЉЕФ HiveFileFormatBenchmarkЃЌДѓМввВПЩвдздМКХмвЛЯТЃЌНсТлОЭЪЧЕЅИі CPU
КЫЖСШЁ TPCH ЕФвЛИі Lineitem БэЃЌORC ZLIB бЙЫѕЗНЪНДѓИХЪЧдк40MB/s, ЕБШЛВЛЭЌЪ§ОнИёЪНЃЌВЛЭЌбЙЫѕБШЛсгаЫљВЛЭЌЁЃвђДЫЃЌЯжДњДХХЬЫГађЖСаДЕФЫйЖШПЩвдДяЕН150MB/sЃЌШчЙћОЭвЛИіШЮЮёЪЧВЛЛсгаЦПОБЕФЁЃетЪБКђ
CPU ЪЧЦПОБЃЌ ЕЋЪЧЯжЪЕЪЧвЛИіВщбЏЖрИіШЮЮёХмЃЌЖрИіВщбЏВЂааХмЃЌФуетИіЪБКђОЭКмФбБЃжЄДХХЬЫГађЖСаДЃЌЭЬЭТЃЌвдМАЪЧЗёдк
OS Page Cache жаЃЌетИіЪБКђОЭКмгаПЩФмДХХЬ IO ЪЧЦПОБСЫЁЃвђДЫ Alluxio ЛЙЪЧгагУЮфжЎЕиЕФЃЌжСЩйПЩвдАбДХХЬ
IO етИіВЛПЩПивђЫиИјКуЖЈЯТРДЁЃ
5.2 Presto session property managers
аТАцБОЕФ Presto ЪЕЯжСЫ Session property manager ЖдгкВЛЭЌЕФ WorkLoadЃЌВЛЭЌЕФвЕЮё
SQL РраЭЃЌЪ§ОнСПЃЌЭЈЙ§ВЛЭЌЕФХфжУФмЙЛДяЕНзюКУЕФаЇЙћЁЃетИіППгУЛЇздМКШЅЩшжУ Session Property
ЪЧВЛЬЋЯжЪЕЕФЃЌБиаыдк Presto ЗўЮёЖЫНјааЙмРэЁЃ
5.3 PrestoЖрзтЛЇИєРы
ФПЧА Presto ЙйЗНВЂУЛгаЪЕЯжКЭ Apache Ranger НсКЯЕФЖрзтЛЇИєРыЛњжЦЃЌЮвУЧФПЧАгавЛИі
Sql ParserЗўЮёЃЌШЅНтЮі PrestoЃЌHiveЃЌSpark Ш§жжв§ЧцЕФгяЗЈЃЌШЅзіЭбУєЃЌЩѓМЦЃЌжЧФмбЁдёЕШЙІФмЃЌКѓУцЛсШЅзіНсКЯ
Apache Ranger ЭЈЙ§ sql жиаДРДЪЕЯжЪ§ОнИєРыЃЌРрЫЦгкЯждкЕФЭбУєЪЕЯжЁЃ
|









