| БрМЭЦМі: |
БОЮФЪзЯШНщЩмСЫЭММЦЫуЛљДЁЃЌНгзХНщЩмСЫPregelЭММЦЫуФЃаЭЃЌPregelЕФЙЄзїдРэЃЌPregelЕФЬхЯЕНсЙЙЃЌPregelЕФгІгУЪЕР§вдМАHamaЯрЙиФкШн
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЭММЦЫуМђНщ
ЭМНсЙЙЪ§ОнЃК
аэЖрДѓЪ§ОнЖМЪЧвдДѓЙцФЃЭМЛђЭјТчЕФаЮЪНГЪЯжЁЃ
аэЖрЗЧЭМНсЙЙЕФДѓЪ§ОнЃЌвВГЃГЃЛсБЛзЊЛЛЮЊЭМФЃаЭКѓНјааЗжЮіЁЃ
ЭМЪ§ОнНсЙЙКмКУЕиБэДяСЫЪ§ОнжЎМфЕФЙиСЊадЁЃ
ЙиСЊадМЦЫуЪЧДѓЪ§ОнМЦЫуЕФКЫаФЁЊЁЊЭЈЙ§ЛёЕУЪ§ОнЕФЙиСЊадЃЌПЩвдДгдывєКмЖрЕФКЃСПЪ§ОнжаГщШЁгагУЕФаХЯЂЁЃ
ДЋЭГЭММЦЫуНтОіЗНАИЕФВЛзужЎДІЃК
КмЖрДЋЭГЕФЭММЦЫуЫуЗЈЖМДцдквдЯТМИИіЕфаЭЮЪЬтЃК
ГЃГЃБэЯжГіБШНЯВюЕФФкДцЗУЮЪОжВПад
еыЖдЕЅИіЖЅЕуЕФДІРэЙЄзїЙ§Щй
МЦЫуЙ§ГЬжаАщЫцзХВЂааЖШЕФИФБф
еыЖдДѓаЭЭМЃЈБШШчЩчНЛЭјТчКЭЭјТчЭМЃЉЕФМЦЫуЮЪЬтЃЌПЩФмЕФНтОіЗНАИМАЦфВЛзужЎДІОпЬхШчЯТЃК
ЮЊЬиЖЈЕФЭМгІгУЖЈжЦЯргІЕФЗжВМЪНЪЕЯж
ЛљгкЯжгаЕФЗжВМЪНМЦЫуЦНЬЈНјааЭММЦЫу
ЪЙгУЕЅЛњЕФЭМЫуЗЈПтЃКБШШчBGLЁЂLEADЁЂNetworkXЁЂJDSLЁЂStandford GraphBaseКЭFGLЕШ
ЪЙгУвбгаЕФВЂааЭММЦЫуЯЕЭГЃКБШШчЃЌParallel BGLКЭCGM GraphЃЌЪЕЯжСЫКмЖрВЂааЭМЫуЗЈ
ЭММЦЫуЭЈгУШэМўЃК
еыЖдДѓаЭЭМЕФМЦЫуЃЌФПЧАЭЈгУЕФЭММЦЫуШэМўжївЊАќРЈСНжжЃК
ЕквЛжжжївЊЪЧЛљгкБщРњЫуЗЈЕФЁЂЪЕЪБЕФЭМЪ§ОнПтЃЌШчNeo4jЁЂOrientDBЁЂDEXКЭ Infinite
GraphЁЃ
ЕкЖўжждђЪЧвдЭМЖЅЕуЮЊжааФЕФЁЂЛљгкЯћЯЂДЋЕнХњДІРэЕФВЂаав§ЧцЃЌШчGoldenOrbЁЂGiraphЁЂPregelКЭHamaЃЌетаЉЭМДІРэШэМўжївЊЪЧЛљгкBSPФЃаЭЪЕЯжЕФВЂааЭМДІРэЯЕЭГЁЃ
вЛДЮBSP(Bulk Synchronous Parallel Computing ModelЃЌПщЭЌВНВЂааМЦЫуФЃаЭ,гжГЦЁАДѓЭЌВНЁБФЃаЭ)МЦЫуЙ§ГЬАќРЈвЛЯЕСаШЋОжГЌВНЃЈЫљЮНЕФГЌВНОЭЪЧМЦЫужаЕФвЛДЮЕќДњЃЉЃЌУПИіГЌВНжївЊАќРЈШ§ИізщМўЃК
1.ОжВПМЦЫуЃКУПИіВЮгыЕФДІРэЦїЖМгаздЩэЕФМЦЫуШЮЮёЁЃ
2.ЭЈбЖЃКДІРэЦїШКЯрЛЅНЛЛЛЪ§ОнЁЃ
3.еЄРИЭЌВН(Barrier Synchronization)ЃКЕБвЛИіДІРэЦїгіЕНЁАТЗеЯЁБЃЈЛђеЄРИЃЉЃЌЛсЕШЕНЦфЫћЫљгаДІРэЦїЭъГЩЫќУЧЕФМЦЫуВНжшЁЃ
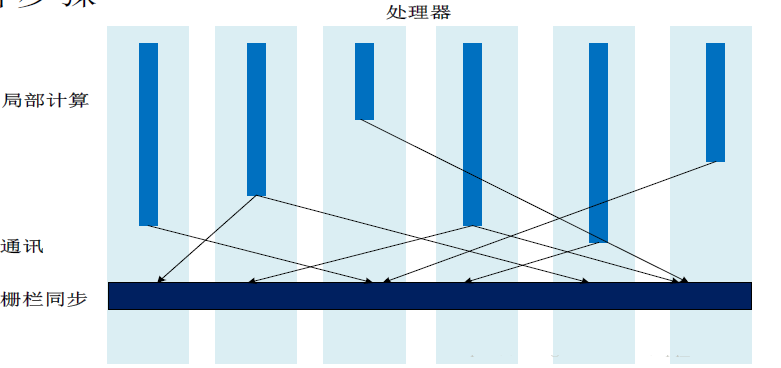
ЭМЃКвЛИіГЌВНЕФДЙжБНсЙЙЭМ
PregelЭММЦЫуФЃаЭ
PregelМђНщ:
ЙШИшЙЋЫОдк2003ФъЕН2004ФъЙЋВМСЫGFSЁЂMapReduceКЭBigTable
ЙШИшдкКѓHadoopЪБДњЕФаТЁАШ§МнТэГЕЁБ
Caffeine
Dremel
Pregel
PregelЪЧвЛжжЛљгкBSPФЃаЭЪЕЯжЕФВЂааЭМДІРэЯЕЭГЁЃ
ЮЊСЫНтОіДѓаЭЭМЕФЗжВМЪНМЦЫуЮЪЬтЃЌPregelДюНЈСЫвЛЬзПЩРЉеЙЕФЁЂгаШнДэЛњжЦЕФЦНЬЈЃЌИУЦНЬЈЬсЙЉСЫвЛЬзЗЧГЃСщЛюЕФAPIЃЌПЩвдУшЪіИїжжИїбљЕФЭММЦЫуЁЃ
PregelзїЮЊЗжВМЪНЭММЦЫуЕФМЦЫуПђМмЃЌжївЊгУгкЭМБщРњЁЂзюЖЬТЗОЖЁЂPageRankМЦЫуЕШЕШЁЃ
гаЯђЭМКЭЖЅЕуЃК
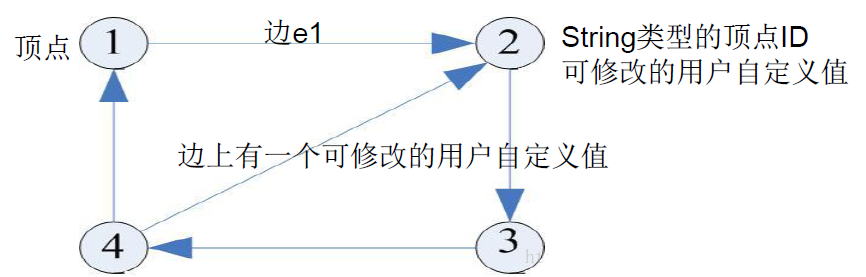
ЭМЃКгаЯђЭМКЭЖЅЕу
PregelМЦЫуФЃаЭвдгаЯђЭМзїЮЊЪфШы
гаЯђЭМЕФУПИіЖЅЕуЖМгавЛИіStringРраЭЕФЖЅЕуID
УПИіЖЅЕуЖМгавЛИіПЩаоИФЕФгУЛЇздЖЈвхжЕгыжЎЙиСЊ
УПЬѕгаЯђБпЖМКЭЦфдДЖЅЕуЙиСЊЃЌВЂМЧТМСЫЦфФПБъЖЅЕуID
БпЩЯгавЛИіПЩаоИФЕФгУЛЇздЖЈвхжЕгыжЎЙиСЊЭМЃК
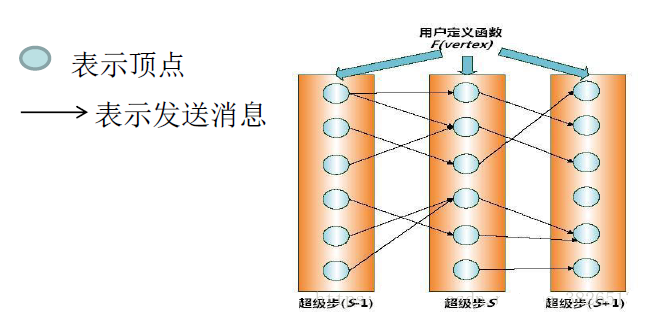
ГЌВНЪОвтЭМ
дкУПИіГЌВНSжаЃЌЭМжаЕФЫљгаЖЅЕуЖМЛсВЂаажДааЯрЭЌЕФгУЛЇздЖЈвхКЏЪ§ЁЃ
УПИіЖЅЕуПЩвдНгЪеЧАвЛИіГЌВН(S-1)жаЗЂЫЭИјЫќЕФЯћЯЂЃЌаоИФЦфздЩэМАЦфГіЩфБпЕФзДЬЌЃЌВЂЗЂЫЭЯћЯЂИјЦфЫћЖЅЕуЃЌЩѕжСЪЧаоИФећИіЭМЕФЭиЦЫНсЙЙЁЃ
дкетжжМЦЫуФЃЪНжаЃЌЁАБпЁЃЁБВЂВЛЪЧКЫаФЖдЯѓЃЌдкБпЩЯУцВЛЛсдЫааЯргІЕФМЦЫуЃЌжЛгаЖЅЕуВХЛсжДаагУЛЇздЖЈвхКЏЪ§НјааЯргІМЦЫуЁЃ
ЖЅЕужЎМфЕФЯћЯЂДЋЕн:
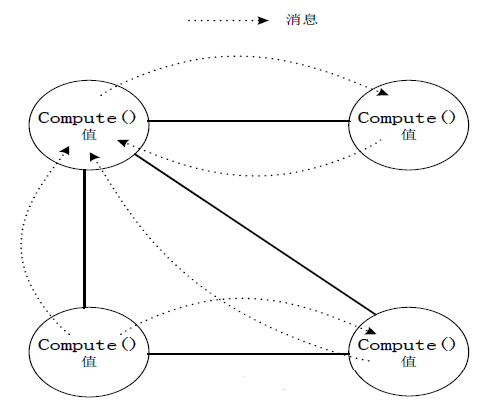
ЭМЃКДПЯћЯЂДЋЕнФЃаЭЭМ
ВЩгУЯћЯЂДЋЕнФЃаЭжївЊЛљгквдЯТСНИідвђЃК
ЯћЯЂДЋЕнОпгазуЙЛЕФБэДяФмСІЃЌУЛгаБивЊЪЙгУдЖГЬЖСШЁЛђЙВЯэФкДцЕФЗНЪН.
гажњгкЬсЩ§ЯЕЭГећЬхадФм.
PregelЕФМЦЫуЙ§ГЬЃК
PregelЕФМЦЫуЙ§ГЬЪЧгЩвЛЯЕСаБЛГЦЮЊЁАГЌВНЁБЕФЕќДњзщГЩЕФЁЃ
дкУПИіГЌВНжаЃЌУПИіЖЅЕуЩЯУцЖМЛсВЂаажДаагУЛЇздЖЈвхЕФКЏЪ§ЃЌИУКЏЪ§УшЪіСЫвЛИіЖЅЕуVдквЛИіГЌВНSжаашвЊжДааЕФВйзїЁЃ
ИУКЏЪ§ПЩвдЖСШЁЧАвЛИіГЌВН(S-1)жаЦфЫћЖЅЕуЗЂЫЭИјЖЅЕуVЕФЯћЯЂЃЌжДааЯргІМЦЫуКѓЃЌаоИФЖЅЕуVМАЦфГіЩфБпЕФзДЬЌЃЌШЛКѓбизХЖЅЕуVЕФГіЩфБпЗЂЫЭЯћЯЂИјЦфЫћЖЅЕуЃЌЖјЧвЃЌвЛИіЯћЯЂПЩФмОЙ§ЖрЬѕБпЕФДЋЕнКѓБЛЗЂЫЭЕНШЮвтвбжЊIDЕФФПБъЖЅЕуЩЯШЅЁЃ
етаЉЯћЯЂНЋЛсдкЯТвЛИіГЌВН(S+1)жаБЛФПБъЖЅЕуНгЪеЃЌШЛКѓЯёЩЯЪіЙ§ГЬвЛбљПЊЪМЯТвЛИіГЌВН(S+1)ЕФЕќДњЙ§ГЬЁЃ
дкPregelМЦЫуЙ§ГЬжаЃЌвЛИіЫуЗЈЪВУДЪБКђПЩвдНсЪјЃЌЪЧгЩЫљгаЖЅЕуЕФзДЬЌОіЖЈЕФЁЃ
дкЕк0ИіГЌВНЃЌЫљгаЖЅЕуДІгкЛюдОзДЬЌЁЃ
ЕБвЛИіЖЅЕуВЛашвЊМЬајжДааНјвЛВНЕФМЦЫуЪБЃЌОЭЛсАбздМКЕФзДЬЌЩшжУЮЊЁАЭЃЛњЁБЃЌНјШыЗЧЛюдОзДЬЌЁЃ
ЕБвЛИіДІгкЗЧЛюдОзДЬЌЕФЖЅЕуЪеЕНРДздЦфЫћЖЅЕуЕФЯћЯЂЪБЃЌPregelМЦЫуПђМмБиаыИљОнЬѕМўХаЖЯРДОіЖЈЪЧЗёНЋЦфЯдЪНЛНабНјШыЛюдОзДЬЌЁЃ
ЕБЭМжаЫљгаЕФЖЅЕуЖМвбОБъЪЖЦфздЩэДяЕНЁАЗЧЛюдОЃЈinactiveЃЉЁБзДЬЌЃЌВЂЧвУЛгаЯћЯЂдкДЋЫЭЕФЪБКђЃЌЫуЗЈОЭПЩвдЭЃжЙдЫааЁЃ
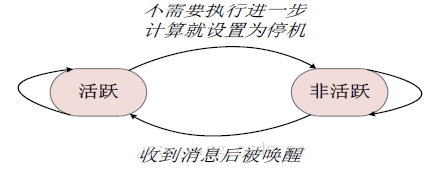
ЭМЃКвЛИіМђЕЅЕФзДЬЌЛњЭМ
вЛИіМђЕЅЪОР§ЃК
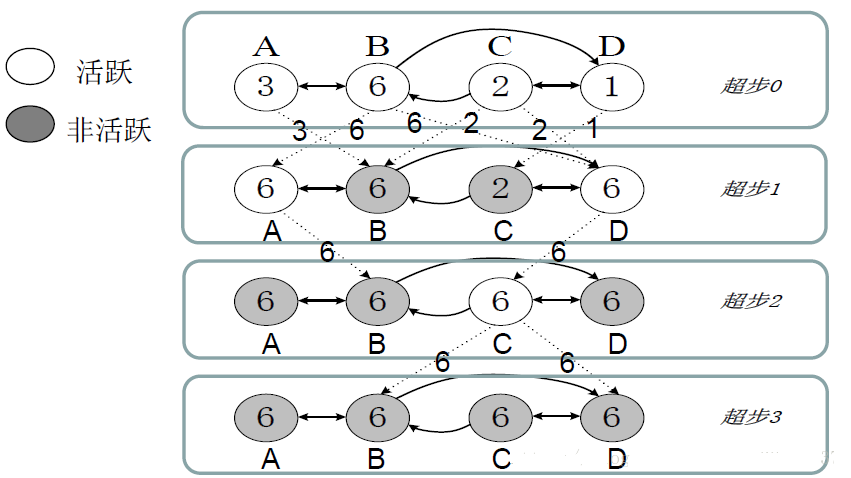
ЭМЃКвЛИіЧѓзюДѓжЕЕФPregelМЦЫуЙ§ГЬЭМ
PregelЕФЙЄзїдРэ
PregelЕФC++ APIЃК
PregelвбОдЄЯШЖЈвхКУвЛИіЛљРрЁЊЁЊVertexРрЃК
template <typename
VertexValue, typename EdgeValue, typename MessageValue>
class Vertex {
public:
//ЖЈвхЕФащКЏЪ§ЃЌComputerЃЈЃЉЃЛгУЛЇЕФДІРэТпМдкетЪЕЯж
virtual void Compute(MessageIterator* msgs) =
0;
//ВЮЪ§ЖЅЕуID
const string& vertex_id() const;
//МЧТМжДааЕФГЌВНЪ§
int64 superstep() const;
//ЛёШЁЖЅЕуЙиСЊЕФжЕ
const VertexValue& GetValue();
VertexValue* MutableValue();
//ГіЩфБпЕќДњЦїЃЌЛёШЁЫљгаЕФГіЩфБп
OutEdgeIterator GetOutEdgeIterator();
//ЗЂЫЭЯћЯЂ
void SendMessageTo (const string& dest_vertex,
const MessageValue& message);
//ЩшЮЊЭЃЛњ
void VoteToHalt();
};
|
дкVetexРржаЃЌЖЈвхСЫШ§ИіжЕРраЭВЮЪ§ЃЌЗжБ№БэЪОЖЅЕуЁЂБпКЭЯћЯЂЁЃУПвЛИіЖЅЕуЖМгавЛИіИјЖЈРраЭЕФжЕгыжЎЖдгІЁЃ
БраДPregelГЬађЪБЃЌашвЊМЬГаVertexРрЃЌВЂЧвИВаДVertexРрЕФащКЏЪ§Compute()ЁЃ
ЯћЯЂДЋЕнЛњжЦЃК
ЖЅЕужЎМфЕФЭЈбЖЪЧНшжњгкЯћЯЂДЋЕнЛњжЦРДЪЕЯжЕФЃЌУПЬѕЯћЯЂЖМАќКЌСЫЯћЯЂжЕКЭашвЊЕНДяЕФФПБъЖЅЕуIDЁЃгУЛЇПЩвдЭЈЙ§VertexРрЕФФЃАхВЮЪ§РДЩшЖЈЯћЯЂжЕЕФЪ§ОнРраЭЁЃ
дквЛИіГЌВНSжаЃЌвЛИіЖЅЕуПЩвдЗЂЫЭШЮвтЪ§СПЕФЯћЯЂЃЌетаЉЯћЯЂНЋдкЯТвЛИіГЌВНЃЈS+1ЃЉжаБЛЦфЫћЖЅЕуНгЪеЁЃ
вЛИіЖЅЕуVЭЈЙ§гыжЎЙиСЊЕФГіЩфБпЯђЭтЗЂЫЭЯћЯЂЃЌВЂЧвЃЌЯћЯЂвЊЕНДяЕФФПБъЖЅЕуВЂВЛвЛЖЈЪЧгыЖЅЕуVЯрСкЕФЖЅЕуЃЌвЛИіЯћЯЂПЩвдСЌајОЙ§ЖрЬѕСЌЭЈЕФБпЕНДяФГИігыЖЅЕуVВЛЯрСкЕФЖЅЕуUЃЌUПЩвдДгНгЪеЕФЯћЯЂжаЛёШЁЕНгыЦфВЛЯрСкЕФЖЅЕуVЕФIDЁЃ
CombinerЃК
PregelМЦЫуПђМмдкЯћЯЂЗЂГіШЅжЎЧАЃЌCombinerПЩвдНЋЗЂЭљЭЌвЛИіЖЅЕуЕФЖрИіећаЭжЕНјааЧѓКЭЕУЕНвЛИіжЕЃЌжЛашЯђЭтЗЂЫЭетИіЁАЧѓКЭНсЙћЁБЃЌДгЖјЪЕЯжСЫгЩЖрИіЯћЯЂКЯВЂГЩвЛИіЯћЯЂЃЌДѓДѓМѕЩйСЫДЋЪфКЭЛКДцЕФПЊЯњЁЃ
дкФЌШЯЧщПіЯТЃЌPregelМЦЫуПђМмВЂВЛЛсПЊЦєCombinerЙІФмЁЃ
ЕБгУЛЇДђЫуПЊЦєCombinerЙІФмЪБЃЌПЩвдМЬГаCombinerРрВЂИВаДащКЏЪ§Combine()ЁЃ
ДЫЭтЃЌЭЈГЃжЛЖдФЧаЉТњзуНЛЛЛТЩКЭНсКЯТЩЕФВйзїВХПЩвдШЅПЊЦєCombinerЙІФмЁЃ
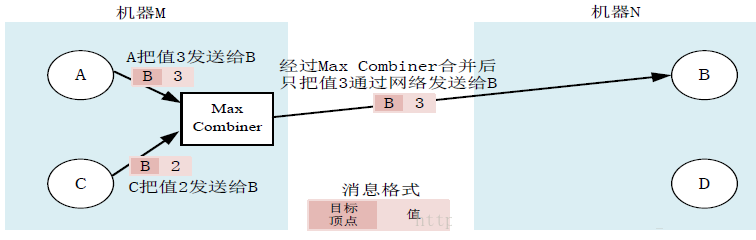
ЭМЃКCombinerгІгУЕФР§зг
Aggregator:
AggregatorЬсЙЉСЫвЛжжШЋОжЭЈаХЁЂМрПиКЭЪ§ОнВщПДЕФЛњжЦЁЃ
дквЛИіГЌВНSжаЃЌУПвЛИіЖЅЕуЖМПЩвдЯђвЛИіAggregatorЬсЙЉвЛИіЪ§ОнЃЌPregelМЦЫуПђМмЛсЖдетаЉжЕНјааОлКЯВйзїВњЩњвЛИіжЕЃЌдкЯТвЛИіГЌВНЃЈS+1ЃЉжаЃЌЭМжаЕФЫљгаЖЅЕуЖМПЩвдПДМћетИіжЕЁЃ
AggregatorЕФОлКЯЙІФмЃЌдЪаэдкећаЭКЭзжЗћДЎРраЭЩЯжДаазюДѓжЕЁЂзюаЁжЕЁЂЧѓКЭВйзїЃЌБШШчЃЌПЩвдЖЈвхвЛИіЁАSumЁБAggregatorРДЭГМЦУПИіЖЅЕуЕФГіЩфБпЪ§СПЃЌзюКѓЯрМгПЩвдЕУЕНећИіЭМЕФБпЕФЪ§СПЁЃ
AggregatorЛЙПЩвдЪЕЯжШЋОжаЭЌЕФЙІФмЃЌБШШчЃЌПЩвдЩшМЦЁАandЁБ AggregatorРДОіЖЈдкФГИіГЌВНжаCompute()КЏЪ§ЪЧЗёжДааФГаЉТпМЗжжЇЃЌжЛгаЕБЁАandЁБ
AggregatorЯдЪОЫљгаЖЅЕуЖМТњзуСЫФГЬѕМўЪБЃЌВХШЅжДааетаЉТпМЗжжЇЁЃ
ЭиЦЫИФБфЃК
PregelМЦЫуПђМмдЪаэгУЛЇдкздЖЈвхКЏЪ§Compute()жаЖЈвхВйзїЃЌаоИФЭМЕФЭиЦЫНсЙЙЃЌБШШчдкЭМжадіМгЃЈЛђЩОГ§ЃЉБпЛђЖЅЕуЁЃ
ЖдгкШЋОжЭиЦЫИФБфЃЌPregelВЩгУСЫЖшадаЕїЛњжЦЁЃ
ЖдгкБОЕиЕФОжВПЭиЦЫИФБфЃЌЪЧВЛЛсв§ЗЂГхЭЛЕФЃЌЖЅЕуЛђБпЕФБОЕидіМѕФмЙЛСЂМДЩњаЇЃЌКмДѓГЬЖШЩЯМђЛЏСЫЗжВМЪНБрГЬЁЃ
ЪфШыКЭЪфГіЃК
дкPregelМЦЫуПђМмжаЃЌЭМЕФБЃДцИёЪНЖржжЖрбљЃЌАќРЈЮФБОЮФМўЁЂЙиЯЕЪ§ОнПтЛђМќжЕЪ§ОнПтЕШЁЃ
дкPregelжаЃЌЁАДгЪфШыЮФМўЩњГЩЕУЕНЭМНсЙЙЁБКЭЁАжДааЭММЦЫуЁБетСНИіЙ§ГЬЪЧЗжРыЕФЃЌДгЖјВЛЛсЯожЦЪфШыЮФМўЕФИёЪНЁЃ
ЖдгкЪфГіЃЌPregelвВВЩгУСЫСщЛюЕФЗНЪНЃЌПЩвдвдЖржжЗНЪННјааЪфГіЁЃ
PregelЕФЬхЯЕНсЙЙ
PregelЕФжДааЙ§ГЬЃК
ЭМЃКЭМЕФЛЎЗжЭМ
дкPregelМЦЫуПђМмжаЃЌвЛИіДѓаЭЭМЛсБЛЛЎЗжГЩаэЖрИіЗжЧјЃЌУПИіЗжЧјЖМАќКЌСЫвЛВПЗжЖЅЕувдМАвдЦфЮЊЦ№ЕуЕФБпЁЃ
вЛИіЖЅЕугІИУБЛЗжХфЕНФФИіЗжЧјЩЯЃЌЪЧгЩвЛИіКЏЪ§ОіЖЈЕФЃЌЯЕЭГФЌШЯКЏЪ§ЮЊhash(ID) mod NЃЌЦфжаЃЌNЮЊЫљгаЗжЧјзмЪ§ЃЌIDЪЧетИіЖЅЕуЕФБъЪЖЗћЃЛЕБШЛЃЌгУЛЇвВПЩвдздМКЖЈвхетИіКЏЪ§ЁЃ
етбљЃЌЮоТлдкФФЬЈЛњЦїЩЯЃЌЖМПЩвдМђЕЅИљОнЖЅЕуIDХаЖЯГіИУЖЅЕуЪєгкФФИіЗжЧјЃЌМДЪЙИУЖЅЕуПЩФмвбОВЛДцдкСЫЁЃ
ЭМЃКPregelЕФжДааЙ§ГЬ
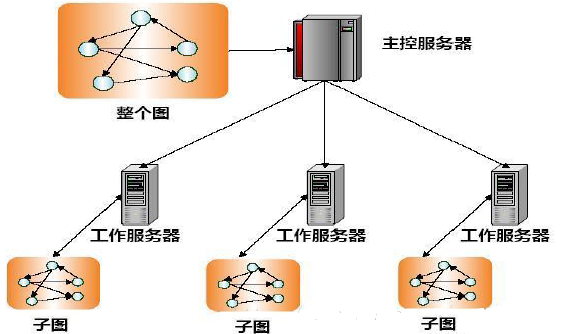
дкРэЯыЕФЧщПіЯТЃЈВЛЗЂЩњШЮКЮДэЮѓЃЉЃЌвЛИіPregelгУЛЇГЬађЕФжДааЙ§ГЬШчЯТЃК
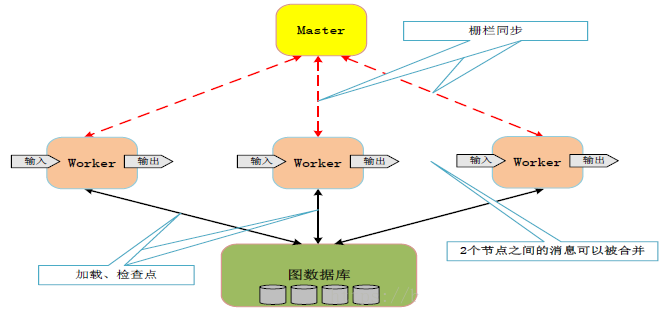
бЁдёМЏШКжаЕФЖрЬЈЛњЦїжДааЭММЦЫуШЮЮёЃЌгавЛЬЈЛњЦїЛсБЛбЁЮЊMasterЃЌЦфЫћЛњЦїзїЮЊWorkerЁЃ
MasterАбвЛИіЭМЗжГЩЖрИіЗжЧјЃЌВЂАбЗжЧјЗжХфЕНЖрИіWorkerЁЃвЛИіWorkerЛсСьЕНвЛИіЛђЖрИіЗжЧјЃЌУПИіWorkerжЊЕРЫљгаЦфЫћWorkerЫљЗжХфЕНЕФЗжЧјЧщПіЁЃ
MasterЛсАбгУЛЇЪфШыЛЎЗжГЩЖрИіВПЗжЁЃШЛКѓЃЌMasterЛс
ЮЊУПИіWorkerЗжХфгУЛЇЪфШыЕФвЛВПЗжЁЃШчЙћвЛИіWorkerДгЪфШыФкШнжаМгдиЕНЕФЖЅЕуЃЌИеКУЪЧздМКЫљЗжХфЕНЕФЗжЧјжаЕФЖЅЕуЃЌОЭЛсСЂМДИќаТЯргІЕФЪ§ОнНсЙЙЁЃЗёдђЃЌИУWorkerЛсИљОнМгдиЕНЕФЖЅЕуЕФIDЃЌАбЫќЗЂЫЭЕНЦфЫљЪєЕФЗжЧјЫљдкЕФWorkerЩЯЁЃЕБЫљгаЕФЪфШыЖМБЛМгдиКѓЃЌЭМжаЕФЫљгаЖЅЕуЖМЛсБЛБъМЧЮЊЁАЛюдОЁБзДЬЌЁЃ
MasterЯђУПИіWorkerЗЂЫЭжИСюЃЌWorkerЪеЕНжИСюКѓЃЌПЊЪМдЫаавЛИіГЌВНЁЃЕБвЛИіГЌВНжаЕФЫљгаЙЄзїЖМЭъГЩвдКѓЃЌWorkerЛсЭЈжЊMasterЃЌВЂАбздМКдкЯТвЛИіГЌВНЛЙДІгкЁАЛюдОЁБзДЬЌЕФЖЅЕуЕФЪ§СПБЈИцИјMasterЁЃЩЯЪіВНжшЛсБЛВЛЖЯжиИДЃЌжБЕНЫљгаЖЅЕуЖМВЛдйЛюдОВЂЧвЯЕЭГжаВЛЛсгаШЮКЮЯћЯЂдкДЋЪфЃЌетЪБЃЌжДааЙ§ГЬВХЛсНсЪјЁЃ
МЦЫуЙ§ГЬНсЪјКѓЃЌMasterЛсИјЫљгаЕФWorkerЗЂЫЭжИСюЃЌЭЈжЊУПИіWorkerЖдздМКЕФМЦЫуНсЙћНјааГжОУЛЏДцДЂЁЃ
ШнДэадЃК
PregelВЩгУМьВщЕуЛњжЦРДЪЕЯжШнДэЁЃдкУПИіГЌВНЕФПЊЪМЃЌMasterЛсЭЈжЊЫљгаЕФWorkerАбздМКЙмЯНЕФЗжЧјЕФзДЬЌаДШыЕНГжОУЛЏДцДЂЩшБИЁЃ
MasterЛсжмЦкадЕиЯђУПИіWorkerЗЂЫЭpingЯћЯЂЃЌWorkerЪеЕНpingЯћЯЂКѓЛсИјMasterЗЂЫЭЗДРЁЯћЯЂЁЃ
УПИіWorkerЩЯЖМБЃДцСЫвЛИіЛђЖрИіЗжЧјЕФзДЬЌаХЯЂЃЌЕБвЛИіWorkerЗЂЩњЙЪеЯЪБЃЌЫќЫљИКд№ЮЌЛЄЕФЗжЧјЕФЕБЧАзДЬЌаХЯЂОЭЛсЖЊЪЇЁЃMasterМрВтЕНвЛИіWorkerЗЂЩњЙЪеЯЁАЪЇаЇЁБКѓЃЌЛсАбЪЇаЇWorkerЫљЗжХфЕНЕФЗжЧјЃЌжиаТЗжХфЕНЦфЫћДІгке§ГЃЙЄзїзДЬЌЕФWorkerМЏКЯЩЯЃЌШЛКѓЃЌЫљгаетаЉЗжЧјЛсДгзюНќЕФФГГЌВНSПЊЪМЪБаДГіЕФМьВщЕужаЃЌжиаТМгдизДЬЌаХЯЂЁЃ
Worker:
дквЛИіWorkerжаЃЌЫќЫљЙмЯНЕФЗжЧјЕФзДЬЌаХЯЂЪЧБЃДцдкФкДцжаЕФЁЃЗжЧјжаЕФЖЅЕуЕФзДЬЌаХЯЂАќРЈЃК
ЖЅЕуЕФЕБЧАжЕЁЃ
вдИУЖЅЕуЮЊЦ№ЕуЕФГіЩфБпСаБэЃЌУПЬѕГіЩфБпАќКЌСЫФПБъЖЅЕуIDКЭБпЕФжЕЁЃ
ЯћЯЂЖгСаЃЌАќКЌСЫЫљгаНгЪеЕНЕФЁЂЗЂЫЭИјИУЖЅЕуЕФЯћЯЂЁЃ
БъжОЮЛЃЌгУРДБъМЧЖЅЕуЪЧЗёДІгкЛюдОзДЬЌЁЃ
дкУПИіГЌВНжаЃЌWorkerЛсЖдздМКЫљЙмЯНЕФЗжЧјжаЕФУПИіЖЅЕуНјааБщРњЃЌВЂЕїгУЖЅЕуЩЯЕФCompute()КЏЪ§ЃЌдкЕїгУЪБЃЌЛсАбвдЯТШ§ИіВЮЪ§ДЋЕнНјШЅЃК
ИУЖЅЕуЕФЕБЧАжЕ
вЛИіНгЪеЕНЕФЯћЯЂЕФЕќДњЦї
вЛИіГіЩфБпЕФЕќДњЦї
дкPregelжаЃЌЮЊСЫЛёЕУИќКУЕФадФмЃЌЁАБъжОЮЛЁБКЭЪфШыЯћЯЂЖгСаЪЧЗжПЊБЃДцЕФЁЃ
ЖдгкУПИіЖЅЕуЖјбдЃЌPregelжЛБЃДцвЛЗнЖЅЕужЕКЭБпжЕЃЌЕЋЪЧЃЌЛсБЃДцСНЗнЁАБъжОЮЛЁБКЭЪфШыЯћЯЂЖгСаЃЌЗжБ№гУгкЕБЧАГЌВНКЭЯТвЛИіГЌВНЁЃ
ШчЙћвЛИіЖЅЕуVдкГЌВНSНгЪеЕНЯћЯЂЃЌФЧУДЃЌЫќБэЪОVНЋЛсдкЯТвЛИіГЌВНS+1жаЃЈЖјВЛЪЧЕБЧАГЌВНSжаЃЉДІгкЁАЛюдОЁБзДЬЌЁЃ
ЕБвЛИіWorkerЩЯЕФвЛИіЖЅЕуVашвЊЗЂЫЭЯћЯЂЕНЦфЫћЖЅЕуUЪБЃЌИУWorkerЛсЪзЯШХаЖЯФПБъЖЅЕуUЪЧЗёЮЛгкздМКЛњЦїЩЯЁЃ
ШчЙћФПБъЖЅЕуUдкздМКЕФЛњЦїЩЯЃЌОЭжБНгАбЯћЯЂЗХШыЕНгыФПБъЖЅЕуUЖдгІЕФЪфШыЯћЯЂЖгСажаЁЃ
ШчЙћЗЂЯжФПБъЖЅЕуUдкдЖГЬЛњЦїЩЯЃЌетИіЯћЯЂОЭЛсБЛднЪБЛКДцЕНБОЕиЃЌЕБЛКДцжаЕФЯћЯЂЪ§ФПДяЕНвЛИіЪТЯШЩшЖЈЕФуажЕЪБЃЌетаЉЛКДцЯћЯЂЛсБЛХњСПвьВНЗЂЫЭГіШЅЃЌДЋЪфЕНФПБъЖЅЕуЫљдкЕФWorkerЩЯЁЃ
MasterЃК
MasterЕФжївЊзїгУЃК
MasterжївЊИКд№аЕїИїИіWorkerжДааШЮЮёЃЌУПИіWorkerЛсНшжњгкУћГЦЗўЮёЯЕЭГЖЈЮЛЕНMasterЕФЮЛжУЃЌВЂЯђMasterЗЂЫЭздМКЕФзЂВсаХЯЂЃЌMasterЛсЮЊУПИіWorkerЗжХфвЛИіЮЈвЛЕФIDЁЃ
MasterЮЌЛЄзХЙигкЕБЧАДІгкЁАгааЇЁБзДЬЌЕФЫљгаWorkerЕФИїжжаХЯЂЃЌАќРЈУПИіWorkerЕФIDКЭЕижЗаХЯЂЃЌвдМАУПИіWorkerБЛЗжХфЕНЕФЗжЧјаХЯЂЁЃ
MasterжаБЃДцетаЉаХЯЂЕФЪ§ОнНсЙЙЕФДѓаЁЃЌжЛгыЗжЧјЕФЪ§СПгаЙиЃЌЖјгыЖЅЕуКЭБпЕФЪ§СПЮоЙиЁЃ
MasterгыWorkerЕФНЛЛЅЃК
вЛИіДѓЙцФЃЭММЦЫуШЮЮёЛсБЛMasterЗжНтЕНЖрИіWorkerШЅжДааЃЌдкУПИіГЌВНПЊЪМЪБЃЌMasterЖМЛсЯђЫљгаДІгкЁАгааЇЁБзДЬЌЕФWorkerЗЂЫЭЯрЭЌЕФжИСюЃЌШЛКѓЕШД§етаЉWorkerЕФЛигІЁЃ
ШчЙћдкжИЖЈЪБМфФкЪеВЛЕНФГИіWorkerЕФЗДРЁЃЌMasterОЭШЯЮЊетИіWorkerЪЇаЇЁЃ
ШчЙћВЮгыШЮЮёжДааЕФЖрИіWorkerжаЕФШЮвтвЛИіЗЂЩњСЫЙЪеЯЪЇаЇЃЌMasterОЭЛсНјШыЛжИДФЃЪНЁЃ
дкУПИіГЌВНжаЃЌЭММЦЫуЕФИїжжЙЄзїЃЌБШШчЪфШыЁЂЪфГіЁЂМЦЫуЁЂБЃДцКЭДгМьВщЕужаЛжИДЃЌЖМЛсдкЁАТЗеЯЃЈbarrierЃЉЁБжЎЧАНсЪјЁЃ
MasterдкФкВПдЫааСЫвЛИіHTTPЗўЮёЦїРДЯдЪОЭММЦЫуЙ§ГЬЕФИїжжаХЯЂЁЃгУЛЇПЩвдЭЈЙ§ЭјвГЫцЪБМрПиЭММЦЫужДааЙ§ГЬИїИіЯИНкЃК
ЭМЕФДѓаЁ
ЙигкГіЖШЗжВМЕФжљзДЭМ
ДІгкЛюдОзДЬЌЕФЖЅЕуЪ§СП
дкЕБЧАГЌВНЕФЪБМфаХЯЂКЭЯћЯЂСїСП
ЫљгагУЛЇздЖЈвхAggregatorЕФжЕ
AggregatorЃК
УПИігУЛЇздЖЈвхЕФAggregatorЖМЛсВЩгУОлКЯКЏЪ§ЖдвЛИіжЕМЏКЯНјааОлКЯМЦЫуЕУЕНвЛИіШЋОжжЕЁЃ
УПИіWorkerЖМБЃДцСЫвЛИіAggregatorЕФЪЕР§МЏЃЌЦфжаЕФУПИіЪЕР§ЖМЪЧгЩРраЭУћГЦКЭЪЕР§УћГЦРДБъЪЖЕФЁЃ
дкжДааЭММЦЫуЙ§ГЬЕФФГИіГЌВНSжаЃЌУПИіWorkerЛсРћгУвЛИіAggregatorЖдЕБЧАБОЕиЗжЧјжаАќКЌЕФЫљгаЖЅЕуЕФжЕНјааЙщдМЃЌЕУЕНвЛИіБОЕиЕФОжВПЙщдМжЕЁЃ
дкГЌВНSНсЪјЪБЃЌЫљгаWorkerЛсНЋЫљгаАќКЌОжВПЙщдМжЕЕФAggregatorЕФжЕНјаазюКѓЕФЛузмЃЌЕУЕНШЋОжжЕЃЌШЛКѓЬсНЛИјMasterЁЃ
дкЯТвЛИіГЌВНS+1ПЊЪМЪБЃЌMasterОЭЛсНЋAggregatorЕФШЋОжжЕЗЂЫЭИјУПИіWorkerЁЃ
PregelЕФгІгУЪЕР§ЁЊЕЅдДзюЖЬТЗОЖ
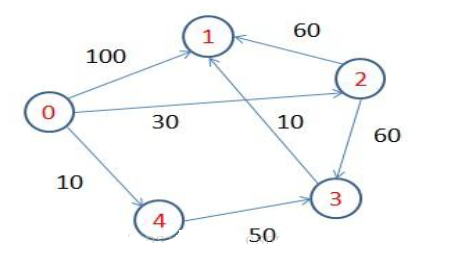
ЭМЃКDijkstraЫуЗЈЪЧНтОіЕЅдДзюЖЬТЗОЖЮЪЬтЕФЬАРЗЫуЗЈ
PregelЗЧГЃЪЪКЯгУРДНтОіЕЅдДзюЖЬТЗОЖЮЪЬтЃЌЪЕЯжДњТыШчЯТЃК
class ShortestPathVertex
: public Vertex<int, int, int> {
void Compute(MessageIterator* msgs) {
int mindist = IsSource(vertex_id()) ? 0 : INF;
for (; !msgs->Done(); msgs->Next())
mindist = min(mindist, msgs->Value());
if (mindist < GetValue()) {
*MutableValue() = mindist;
OutEdgeIterator iter = GetOutEdgeIterator();
for (; !iter.Done(); iter.Next())
SendMessageTo(iter.Target(),
mindist + iter.GetValue());
}
VoteToHalt();
}
};
|
HamaМђНщ
HamaИХЪіЃК
HamaЪЧGoogle PregelЕФПЊдДЪЕЯжЁЃ
гыHadoopЪЪКЯгкЗжВМЪНДѓЪ§ОнДІРэВЛЭЌЃЌHamaжївЊгУгкЗжВМЪНЕФОиеѓЁЂgraphЁЂЭјТчЫуЗЈЕФМЦЫуЁЃ
HamaЪЧдкHDFSЩЯЪЕЯжЕФBSP(Bulk Synchronous Parallel)МЦЫуПђМмЃЌУжВЙHadoopдкМЦЫуФмСІЩЯЕФВЛзуЁЃ
HamaЪЧЛљгкBSP(BulkSynchronous Parallel)МЦЫуММЪѕЕФВЂааМЦЫуПђМмЃЌгУгкДѓСПЕФПЦбЇМЦЫуЃЈБШШчОиеѓЁЂЭМТлЁЂЭјТчЕШЃЉЁЃBSPМЦЫуММЪѕзюДѓЕФгХЪЦЪЧМгПьЕќДњЃЌдкНтОізюаЁТЗОЖЕШЮЪЬтжаПЩвдПьЫйЕУЕНПЩааНтЁЃЭЌЪБЃЌHamaЬсЙЉМђЕЅЕФБрГЬЃЌБШШчflexibleФЃаЭЁЂДЋЭГЕФЯћЯЂДЋЕнФЃаЭЃЌЖјЧвМцШнКмЖрЗжВМЪНЮФМўЯЕЭГЃЌБШШчHDFSЁЂHbaseЕШЁЃгУЛЇПЩвдЪЙгУЯжгаЕФHadoopМЏШКНјааHama
BSP.
ЯждкHamaзюаТЕФАцБОЮЊ2012Фъ6дТ31КХЗЂааЕФ0.5.0.етЪЧ Hama зіЮЊ Apache ЖЅМЖЯюФПКѓЪзДЮЗЂВМЕФАцБОЃЌИУАцБОАќКЌСНИіЯджјЕФаТЬиадЃЌЗжБ№ЪЧЯћЯЂбЙЫѕЦїКЭЭъећЕФ
Google Pregel ПЫТЁЃЌСэЭтдкМЦЫуЯЕЭГадФмКЭПЩГжајадЩЯЖМЕУвдЬсЩ§ЁЃ
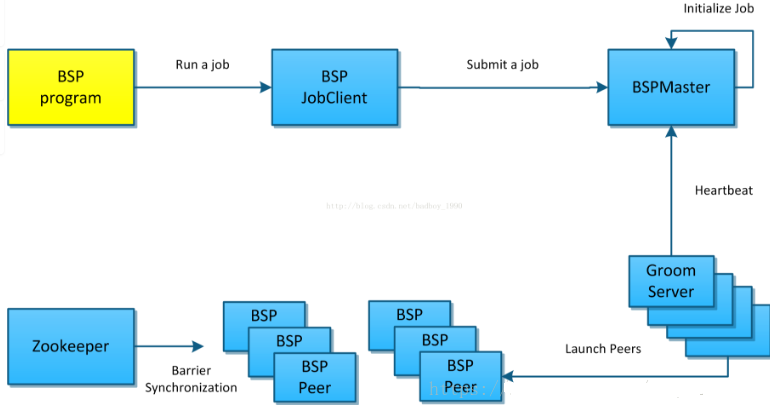
HamaНсЙЙЃК
HamaжївЊгаШ§ВПЗжЙЙГЩЃКBSPMasterЁЂGroomServers КЭZookeeperЁЃгыHadoopНсЙЙКмЯрЫЦЃЌЕЋУЛгаЭЈаХКЭЭЌВНЛњжЦЕФВПЗжЁЃ
HamaЕФМЏШКгЩвЛИіBSPMasterКЭЖрИіЛЅВЛЙиСЊЕФGroomServerзїМЦЫуНсЕузщГЩЃЌHDFSКЭZookeeperЖМПЩвдЪЧЖРСЂЕФМЏШКЁЃЦєЖЏДгBSPMasterПЊЪМЃЌШчЙћЪЧmasterЛсЦєЖЏBSPMasterЁЂGroomServerСНИіНјГЬЃЌШчЙћжЛЪЧМЦЫуНсЕудђжЛЛсЦєЖЏGroomServerЃЌЦєЖЏ/ЙиБеНХБОЖМЪЧMasterЛњЦїдЖГЬдкGroomServerЛњЦїЩЯжДааЁЃ
ЭМЃКHamaЬхЯЕНсЙЙ
BSPMaster:
BSPMaster МДМЏШКЕФжїЃЌИКд№СЫМЏШКИїGroomServerНсЕуЕФЙмРэгызївЕЕФЕїЖШЃЌОЭЮвЫљжЊЫќЛЙДцдкЕЅЕуЕФЮЪЬтЁЃЯрЕБгкHadoopЕФJobTrackerЛђHDFSЕФNameNodeЁЃЦфЛљБОзїгУШчЯТЃК
ЮЌГжGroomЗўЮёЦїзДЬЌЁЃ
ЮЌЛЄsuperstepsКЭМЏШКжаЕФМЦЪ§ЦїЁЃ
ЮЌЛЄJobЕФНјЖШаХЯЂЁЃ
ЕїЖШзївЕКЭШЮЮёЗжХфИјGroomЗўЮёЦї
ЗжХфжДааЕФРрКЭХфжУЃЌећИіGroomЗўЮёЦїЁЃ
ЮЊгУЛЇЬсЙЉМЏШКПижЦНгПкЃЈWebКЭЛљгкПижЦЬЈЃЉЁЃ
GroomServerЃК
GroomServerЪЧвЛИіprocessЃЌЭЈЙ§BSPMasterЦєЖЏBSPШЮЮёЁЃУПвЛИіGroomЖМгаBSPMasterЭЈаХЃЌПЩвдЭЈЙ§BSPMasterЛёШЁШЮЮёЃЌБЈИцзДЬЌЁЃGroomServerдкHDFSЛђепЦфЫћЮФМўЯЕЭГЩЯдЫааЃЌЭЈГЃЃЌGroomServerгыгыЪ§ОнНсЕудквЛИіЮяРэНсЕуЩЯдЫааЃЌвдБЃжЄЛёЕУзюМбадФмЁЃ
ZookeeperЃК
ZookeeperгУРДЙмРэBSPPeerЕФЭЌВНЃЌгУгкЪЕЯжBarrierSynchronisationЛњжЦЁЃдкZKЩЯЃЌНјШыBSPPeerжївЊгаНјШыBarrierКЭРыПЊBarrierВйзїЃЌЫљгаНјШыBarrierЕФPeerЛсдкzkЩЯДДНЈвЛИіEPHEMERALЕФnodeЃЈ/bsp/JobID/Superstep
NO./TaskIDЃЉЃЌзюКѓвЛИіНјШыBarrierЕФPeerЭЌЪБЛЙЛсДДНЈвЛИіreadynode(/bsp/JobID/Superstep
NO./ready)ЃЌPeerНјШызшШћзДЬЌЕШД§zkЩЯЫљгаtaskЕФnodeЖМЩОГ§КѓЭЫГіBarrierЁЃ
BSP Programming ModelЃК
BSP(BulkSynchronous ParallelЃЌећЬхЭЌВНВЂааМЦЫуФЃаЭ)ЪЧгЂЙњМЦЫуЛњПЦбЇМвViliantдкЩЯЪРМЭ80ФъДњЬсГіЕФвЛжжВЂааМЦЫуФЃаЭЁЃGoogleЗЂВМЕФвЛЭљЦЊТлЮФ(ЁЖPregel:
A System for Large-Scale Graph ProcessingЁЗ)ЪЙЕУетвЛИХФюБЛИќЖрШЫЫљШЯЪЖЃЌОнЫЕдкGoogle
80%ЕФГЬађдЫаадкMapReduceЩЯЃЌ20%ЕФГЬађдЫаадкPregelЩЯЁЃКЭMapReduceвЛбљЃЌGoogleВЂУЛгаПЊдДPregelЃЌApacheАДPregelЕФЫМЯыЬсЙЉСЫРрЫЦПђМмHamaЁЃ
|









