| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЭМИХФюЪѕгяЁЂЭМДІРэММЪѕЁЂЭМДцДЂФЃЪНЁЂЭММЦЫуФЃЪНЕШЯрЙиФкШнЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЭМИХФюЪѕгя 1.1 ЛљБОИХФю ЭМЪЧгЩЖЅЕуМЏКЯ(vertex)МАЖЅЕуМфЕФЙиЯЕМЏКЯЃЈБпedgeЃЉзщГЩЕФвЛжжЪ§ОнНсЙЙЁЃ
етРяЕФЭМВЂЗЧжИДњЪ§жаЕФЭМЁЃЭМПЩвдЖдЪТЮявдМАЪТЮяжЎМфЕФЙиЯЕНЈФЃЃЌЭМПЩвдгУРДБэЪОздШЛЗЂЩњЕФСЌНгЪ§ОнЃЌШчЃКЩчНЛЭјТчЁЂЛЅСЊЭјwebвГУц
ГЃгУЕФгІгУгаЃКдкЕиЭМгІгУжаевЕНзюЖЬТЗОЖЁЂЛљгкгыЫћШЫЕФЯрЫЦЖШЭМЃЌЭЦМіВњЦЗЁЂЗўЮёЁЂШЫМЪЙиЯЕЛђУНЬх
1.2 Ъѕгя 1.2.1ЖЅЕуКЭБп вЛАуЙиЯЕЭМжаЃЌЪТЮяЮЊЖЅЕуЃЌЙиЯЕЮЊБп
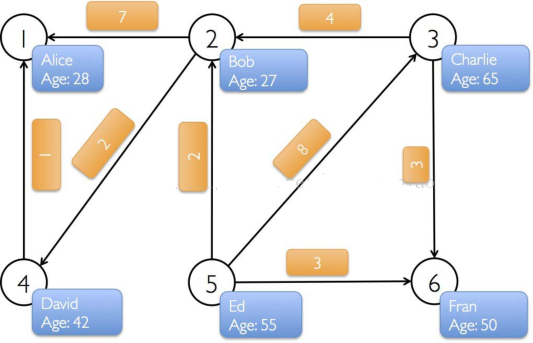
1.2.2гаЯђЭМКЭЮоЯђЭМ дкгаЯђЭМжаЃЌвЛЬѕБпЕФСНИіЖЅЕувЛАуАчбнепВЛЭЌЕФНЧЩЋЃЌБШШчИИзгЙиЯЕЁЂвГУцAСЌНгЯђвГУцBЃЛ
дквЛИіЮоЯђЭМжаЃЌБпУЛгаЗНЯђЃЌМДЙиЯЕЖМЪЧЖдЕШЕФЃЌБШШчqqжаЕФКУгбЁЃ
GraphXжагавЛИіживЊИХФюЃЌЫљгаЕФБпЖМгавЛИіЗНЯђЃЌФЧУДЭМОЭЪЧгаЯђЭМЃЌШчЙћКіТдБпЕФЗНЯђЃЌОЭЪЧЮоЯђЭМЁЃ
1.2.3гаЛЗЭМКЭЮоЛЗЭМ гаЛЗЭМЪЧАќКЌбЛЗЕФЃЌвЛЯЕСаЖЅЕуСЌНгГЩвЛИіЛЗЁЃЮоЛЗЭМУЛгаЛЗЁЃдкгаЛЗЭМжаЃЌШчЙћВЛЙиаФжежЙЬѕМўЃЌЫуЗЈПЩФмгРдЖдкЛЗЩЯжДааЃЌЮоЗЈЭЫГіЁЃ
1.2.4ЖШЁЂГіБпЁЂШыБпЁЂГіЖШЁЂШыЖШ ЖШБэЪОвЛИіЖЅЕуЕФЫљгаБпЕФЪ§СП
ГіБпЪЧжИДгЕБЧАЖЅЕужИЯђЦфЫћЖЅЕуЕФБп
ШыБпБэЪОЦфЫћЖЅЕужИЯђЕБЧАЖЅЕуЕФБп
ГіЖШЪЧвЛИіЖЅЕуГіБпЕФЪ§СП
ШыЖШЪЧвЛИіЖЅЕуШыБпЕФЪ§СП
1.2.5ГЌВН ЭМНјааЕќДњМЦЫуЪБЃЌУПвЛТжЕФЕќДњНазівЛИіГЌВН
ЖўЁЂЭМДІРэММЪѕ ЭМДІРэММЪѕАќРЈЭМЪ§ОнПтЁЂЭМЪ§ОнВщбЏЁЂЭМЪ§ОнЗжЮіКЭЭМЪ§ОнПЩЪгЛЏЁЃ
2.1ЁЁЭМЪ§ОнПт Neo4jЁЂTitanЁЂOrientDBЁЂDEXКЭInfiniteGraphЕШЛљгкБщРњЫуЗЈЕФЁЂЪЕЪБЕФЭМЪ§ОнПтЃЛ
2.2ЁЁЭМЪ§ОнВщбЏ ЖдЭМЪ§ОнПтжаЕФФкШнНјааВщбЏ
2.3ЁЁЭМЪ§ОнЗжЮі Google PregelЁЂSpark GraphXЁЂGraphLabЕШЭММЦЫуШэМўЁЃДЋЭГЕФЪ§ОнЗжЮіЗНЗЈВржигкЪТЮяБОЩэЃЌМДЪЕЬхЃЌР§ШчвјааНЛвзЁЂзЪВњзЂВсЕШЕШЁЃЖјЭМЪ§ОнВЛНіЙизЂЪТЮяЃЌЛЙЙизЂЪТЮяжЎМфЕФСЊЯЕЁЃР§ШчЃЌШчЙћдкЭЈЛАМЧТМжаЗЂЯжеХШ§дјДђЕчЛАИјРюЫФЃЌОЭПЩвдНЋеХШ§КЭРюЫФЙиСЊЦ№РДЃЌетжжЙиСЊЙиЯЕЬсЙЉСЫгыСНепЯрЙиЕФгаМлжЕЕФаХЯЂЃЌетбљЕФаХЯЂЪЧВЛПЩФмНіДгСНепЕЅДПЕФИіЬхЪ§ОнжаЛёШЁЕФЁЃ
2.4ЁЁЭМЪ§ОнПЩЪгЛЏ OLTPЗчИёЕФЭМЪ§ОнПтЛђепOLAPЗчИёЕФЭМЪ§ОнЗжЮіЯЕЭГЃЈЛђГЦЮЊЭММЦЫуШэМўЃЉЃЌЖМПЩвдгІгУЭМЪ§ОнПтПЩЪгЛЏММЪѕЁЃашвЊзЂвтЕФЪЧЃЌЭМПЩЪгЛЏгыЙиЯЕЪ§ОнПЩЪгЛЏжЎМфгаКмДѓЕФВювьЃЌЙиЯЕЪ§ОнПЩЪгЛЏЕФФПБъЪЧЖдЪ§ОнШЁЕУжБЙлЕФСЫНтЃЌЖјЭМЪ§ОнПЩЪгЛЏЕФФПБъдкгкЖдЪ§ОнЛђЫуЗЈНјааЕїЪдЁЃ
Ш§ЁЂЭМДцДЂФЃЪН дкСЫНтGraphXжЎЧАЃЌашвЊЯШСЫНтЙигкЭЈгУЕФЗжВМЪНЭММЦЫуПђМмЕФСНИіГЃМћЮЪЬтЃКЭМДцДЂФЃЪНКЭЭММЦЫуФЃЪНЁЃ
ОоаЭЭМЕФДцДЂзмЬхЩЯгаБпЗжИюКЭЕуЗжИюСНжжДцДЂЗНЪНЁЃ2013ФъЃЌGraphLab2.0НЋЦфДцДЂЗНЪНгЩБпЗжИюБфЮЊЕуЗжИюЃЌдкадФмЩЯШЁЕУжиДѓЬсЩ§ЃЌФПЧАЛљБОЩЯБЛвЕНчЙуЗКНгЪмВЂЪЙгУЁЃ
3.1ЁЁБпЗжИюЃЈEdge-CutЃЉ УПИіЖЅЕуЖМДцДЂвЛДЮЃЌЕЋгаЕФБпЛсБЛДђЖЯЗжЕНСНЬЈЛњЦїЩЯЁЃетбљзіЕФКУДІЪЧНкЪЁДцДЂПеМфЃЛЛЕДІЪЧЖдЭМНјааЛљгкБпЕФМЦЫуЪБЃЌЖдгквЛЬѕСНИіЖЅЕуБЛЗжЕНВЛЭЌЛњЦїЩЯЕФБпРДЫЕЃЌвЊПчЛњЦїЭЈаХДЋЪфЪ§ОнЃЌФкЭјЭЈаХСїСПДѓЁЃ
3.2ЁЁЕуЗжИюЃЈVertex-CutЃЉ УПЬѕБпжЛДцДЂвЛДЮЃЌЖМжЛЛсГіЯждквЛЬЈЛњЦїЩЯЁЃСкОгЖрЕФЕуЛсБЛИДжЦЕНЖрЬЈЛњЦїЩЯЃЌдіМгСЫДцДЂПЊЯњЃЌЭЌЪБЛсв§ЗЂЪ§ОнЭЌВНЮЪЬтЁЃКУДІЪЧПЩвдДѓЗљМѕЩйФкЭјЭЈаХСПЁЃ
3.3ЁЁЖдБШ ЫфШЛСНжжЗНЗЈЛЅгаРћБзЃЌЕЋЯждкЪЧЕуЗжИюеМЩЯЗчЃЌИїжжЗжВМЪНЭММЦЫуПђМмЖМНЋздМКЕзВуЕФДцДЂаЮЪНБфГЩСЫЕуЗжИюЁЃжївЊдвђгавдЯТСНИіЁЃ
ДХХЬМлИёЯТНЕЃЌДцДЂПеМфВЛдйЪЧЮЪЬтЃЌЖјФкЭјЕФЭЈаХзЪдДУЛгаЭЛЦЦадНјеЙЃЌМЏШКМЦЫуЪБФкЭјДјПэЪЧБІЙѓЕФЃЌЪБМфБШДХХЬИќефЙѓЁЃетЕуОЭРрЫЦгкГЃМћЕФПеМфЛЛЪБМфЕФВпТдЁЃ
дкЕБЧАЕФгІгУГЁОАжаЃЌОјДѓЖрЪ§ЭјТчЖМЪЧЁАЮоГпЖШЭјТчЁБЃЌзёбУнТЩЗжВМЃЌВЛЭЌЕуЕФСкОгЪ§СПЯрВюЗЧГЃаќЪтЁЃЖјБпЗжИюЛсЪЙФЧаЉЖрСкОгЕФЕуЫљЯрСЌЕФБпДѓЖрЪ§БЛЗжЕНВЛЭЌЕФЛњЦїЩЯЃЌетбљЕФЪ§ОнЗжВМЛсЪЙЕУФкЭјДјПэИќМгзННѓМћжтЃЌгкЪЧБпЗжИюДцДЂЗНЪНБЛНЅНЅХзЦњСЫЁЃ
ЫФЁЂЭММЦЫуФЃЪН ФПЧАЕФЭММЦЫуПђМмЛљБОЩЯЖМзёбBSPЃЈBulk Synchronous ParallellЃЉМЦЫуФЃЪНЁЃBulk
Synchronous ParallellЃЌМДећЬхЭЌВНВЂааЃЌЫќНЋМЦЫуЗжГЩвЛЯЕСаЕФГЌВНЃЈsuperstepЃЉЕФЕќДњЃЈiterationЃЉЁЃДгзнЯђЩЯПДЃЌЫќЪЧвЛИіДЎааФЃаЭЃЌЖјДгКсЯђЩЯПДЃЌЫќЪЧвЛИіВЂааЕФФЃаЭЃЌУПСНИіsuperstepжЎМфЩшжУвЛИіеЄРИЃЈbarrierЃЉЃЌМДећЬхЭЌВНЕуЃЌШЗЖЈЫљгаВЂааЕФМЦЫуЖМЭъГЩКѓдйЦєЖЏЯТвЛТжsuperstepЁЃ
4.1ЁЁГЌВН УПвЛИіГЌВНЃЈsuperstepЃЉАќКЌШ§ВПЗжФкШнЃК
1.МЦЫуcomputeЃЌУПвЛИіprocessorРћгУЩЯвЛИіsuperstepДЋЙ§РДЕФЯћЯЂКЭБОЕиЕФЪ§ОнНјааБОЕиМЦЫуЃЛ
2.ЯћЯЂДЋЕнЃЌУПвЛИіprocessorМЦЫуЭъБЯКѓЃЌНЋЯћЯЂДЋЕнИігыжЎЙиСЊЕФЦфЫќprocessorsЃЛ
3.ећЬхЭЌВНЕуЃЌгУгкећЬхЭЌВНЃЌШЗЖЈЫљгаЕФМЦЫуКЭЯћЯЂДЋЕнЖМНјааЭъБЯКѓЃЌНјШыЯТвЛИіsuperstepЁЃ
4.2ЁЁPregelФЃаЭЁЊЁЊЯёЖЅЕувЛбљЫМПМ PregelНшМјMapReduceЕФЫМЯыЃЌВЩгУЯћЯЂдкЕужЎМфДЋЕнЪ§ОнЕФЗНЪНЃЌЬсГіСЫЁАЯёЖЅЕувЛбљЫМПМЁБЃЈThink
Like A VertexЃЉЕФЭММЦЫуФЃЪНЃЌВЩгУЯћЯЂдкЕужЎМфДЋЕнЪ§ОнЕФЗНЪНЃЌШУгУЛЇЮоашПМТЧВЂааЗжВМЪНМЦЫуЕФЯИНкЃЌжЛашвЊЪЕЯжвЛИіЖЅЕуИќаТКЏЪ§ЃЌШУПђМмдкБщРњЖЅЕуЪБНјааЕїгУМДПЩЁЃ
ГЃМћЕФДњТыФЃАхШчЯТЃК

ЩЯЭММђвЊЕиУшЪіСЫPregelЕФМЦЫуФЃаЭЃК
1.masterНЋЭМНјааЗжЧјЃЌШЛКѓНЋвЛИіЛђЖрИіpartitionЗжИјworkerЃЛ
2.workerЮЊУПвЛИіpartitionЦєЖЏвЛИіЯпГЬЃЌИУЯпГЬТжбЏpartitionжаЕФЖЅЕуЃЌЮЊУПвЛИіactiveзДЬЌЕФЖЅЕуЕїгУcomputeЗНЗЈЃЛ
3.computeЭъГЩКѓЃЌАДееedgeЕФаХЯЂНЋМЦЫуНсЙћЭЈЙ§ЯћЯЂДЋЕнЗНЪНДЋИјЦфЫќЖЅЕуЃЛ
4.ЭъГЩЭЌВНКѓЃЌжиИДжДаа2,3ВйзїЃЌжБЕНУЛгаactiveзДЬЌЖЅЕуЛђепЕќДњДЮЪ§ЕНДяжИЖЈЪ§ФПЁЃ
етИіФЃаЭЫфШЛМђНрЃЌЕЋКмШнвзЗЂЯжЫќЕФШБЯнЁЃЖдгкСкОгЪ§КмЖрЕФЖЅЕуЃЌЫќашвЊДІРэЕФЯћЯЂЗЧГЃХгДѓЃЌЖјЧвдкетИіФЃЪНЯТЃЌЫќУЧЪЧЮоЗЈБЛВЂЗЂДІРэЕФЁЃЫљвдЖдгкЗћКЯУнТЩЗжВМЕФздШЛЭМЃЌетжжМЦЫуФЃаЭЯТКмШнвзЗЂЩњМйЫРЛђепБРРЃЁЃ
зїЮЊЕквЛИіЭЈгУЕФДѓЙцФЃЭМДІРэЯЕЭГЃЌpregelвбОЮЊЗжВМЪНЭМДІРэТѕНјСЫВЛаЁЕФвЛВНЃЌетЕуВЛШнжУвЩЃЌЕЋЪЧpregelдквЛаЉЕиЗНвВВЛОЁШчШЫвтЃК
1.дкЭМЕФЛЎЗжЩЯЃЌВЩгУЕФЪЧМђЕЅЕФhashЗНЪНЃЌетбљЙЬШЛФмЙЛТњзуИКдиОљКтЃЌЕЋЪЧhashЗНЪНВЂВЛФмИљОнЭМЕФСЌЭЈЬиадНјааЛЎЗжЃЌЕМжТГЌВНжЎМфЕФЯћЯЂДЋЕнПЊЯњПЩФмЛсЪЧгАЯьадФмЕФзюДѓвўЛМЁЃ
2.МђЕЅЕФcheckpointЛњжЦжЛФмЯђКѓЪНЕиНЋзДЬЌЛжИДЕНЕБЧАSГЌВНЕФМИИіГЌВНжЎЧАЃЌвЊЕНДяSЛЙашвЊжиИДМЦЫуЃЌетЦфЪЕвВРЫЗбСЫКмЖрЪБМфЃЌвђДЫШчКЮЩшМЦcheckpointЃЌЪЙЕУжЛашжиИДМЦЫуЙЪеЯworkerЕФpartitionЕФМЦЫуНкЪЁМЦЫуЩѕжСПЩвдЭЈЙ§checkpointжБНгЕНДяЙЪеЯЗЂЩњЧАвЛГЌВНSЃЌвВЪЧвЛИіКмашвЊбаОПЕФЕиЗНЁЃ
3.BSPФЃаЭБОЩэгаЦфОжЯоадЃЌећЬхЭЌВНВЂааЖдгкМЦЫуПьЕФworkerГЄЦкЕШД§ЕФЮЪЬтЮоЗЈНтОіЁЃ
4.гЩгкpregelФПЧАЕФМЦЫузДЬЌЖМЪЧГЃзЄФкДцЕФЃЌЖдгкЙцФЃМЬајдіДѓЕФЭМДІРэПЩФмЛсЕМжТФкДцВЛзуЃЌШчКЮНтОіЩаД§баОПЁЃ
4.3ЁЁGASФЃаЭЁЊЁЊСкОгИќаТФЃаЭ ЯрБШPregelФЃаЭЕФЯћЯЂЭЈаХЗЖЪНЃЌGraphLabЕФGASФЃаЭИќЦЋЯђЙВЯэФкДцЗчИёЁЃЫќдЪаэгУЛЇЕФздЖЈвхКЏЪ§ЗУЮЪЕБЧАЖЅЕуЕФећИіСкгђЃЌПЩГщЯѓГЩGatherЁЂApplyКЭScatterШ§ИіНзЖЮЃЌМђГЦЮЊGASЁЃЯрЖдгІЃЌгУЛЇашвЊЪЕЯжШ§ИіЖРСЂЕФКЏЪ§gatherЁЂapplyКЭscatterЁЃГЃМћЕФДњТыФЃАхШчЯТЫљЪОЃК

гЩгкgather/scatterКЏЪ§ЪЧвдЕЅЬѕБпЮЊВйзїСЃЖШЃЌЫљвдЖдгквЛИіЖЅЕуЕФжкЖрСкБпЃЌПЩвдЗжБ№гЩЯргІЕФworkerЖРСЂЕїгУgather/scatterКЏЪ§ЁЃетвЛЩшМЦжївЊЪЧЮЊСЫЪЪгІЕуЗжИюЕФЭМДцДЂФЃЪНЃЌДгЖјБмУтPregelФЃаЭЛсгіЕНЕФЮЪЬтЁЃ
1.GatherНзЖЮ
ЙЄзїЖЅЕуЕФБп(ПЩФмЪЧЫљгаБпЃЌвВгаПЩФмЪЧШыБпЛђепГіБп)ДгСьНгЖЅЕуКЭздЩэЪеМЏЪ§ОнЃЌМЧЮЊgather_data_iЃЌИїИіБпЕФЪ§ОнgraphlabЛсЧѓКЭЃЌМЧЮЊsum_dataЁЃетвЛНзЖЮЖдЙЄзїЖЅЕуЁЂБпЖМЪЧжЛЖСЕФЁЃ
2.ApplyНзЖЮ
MirrorНЋgatherМЦЫуЕФНсЙћsum_dataЗЂЫЭИјmasterЖЅЕуЃЌmasterНјааЛузмЮЊtotalЁЃMasterРћгУtotalКЭЩЯвЛВНЕФЖЅЕуЪ§ОнЃЌАДеевЕЮёашЧѓНјааНјвЛВНЕФМЦЫуЃЌШЛКѓИќаТmasterЕФЖЅЕуЪ§ОнЃЌВЂЭЌВНmirrorЁЃApplyНзЖЮжаЃЌЙЄзїЖЅЕуПЩаоИФЃЌБпВЛПЩаоИФЁЃ
3.ScatterНзЖЮ
ЙЄзїЖЅЕуИќаТЭъГЩжЎКѓЃЌИќаТБпЩЯЕФЪ§ОнЃЌВЂЭЈжЊЖдЦфгавРРЕЕФСкНсЖЅЕуИќаТзДЬЌЁЃетscatterЙ§ГЬжаЃЌЙЄзїЖЅЕужЛЖСЃЌБпЩЯЪ§ОнПЩаДЁЃ
дкжДааФЃаЭжаЃЌgraphlabЭЈЙ§ПижЦШ§ИіНзЖЮЕФЖСаДШЈЯоРДДяЕНЛЅГтЕФФПЕФЁЃдкgatherНзЖЮжЛЖСЃЌapplyЖдЖЅЕужЛаДЃЌscatterЖдБпжЛаДЁЃВЂааМЦЫуЕФЭЌВНЭЈЙ§masterКЭmirrorРДЪЕЯжЃЌmirrorЯрЕБгкУПИіЖЅЕуЖдЭтЕФвЛИіНгПкШЫЃЌНЋИДдгЕФЪ§ОнЭЈаХГщЯѓГЩЖЅЕуЕФааЮЊЁЃ
|









