| БрМЭЦМі: |
БОЮФЯШНВMapReduce
1.xЕФПђМмЁЃдйНВMapReduce 1.xЩ§МЖИФНјКѓMapReduce 2.x/YarnЕФПђМмЁЃФПЧАжївЊЪЧгУMapReduce
2.x/YarnЕФПђМмЁЃ
БОЮФРДздcodertw.comЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
MapReduce 1.x
MapReduce 1.xжиЕуИХФю
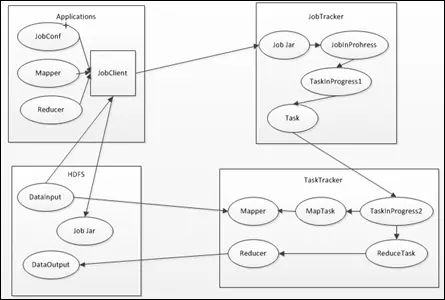
JobClient
гУєОЕФMapReduceГЬађЭЈп^ClientЬсНЛЕНJobTrackerЖЫЃЛЭЌrЃЌгУєПЩЭЈп^ClientЬсЙЉЕФвЛаЉНгПкВщПДзїIп\аа юBЁЃдкHadoopШВПгУЁАзїIЁБ
ЃЈJobЃЉБэЪОMapReduceГЬађЁЃУПвЛJobЖМўдкгУєЖЫЭЈп^ClientюЂЊгУГЬађвдМА
ЂЕХфжУConfigurationДђАќГЩJarЮФМўДцІдкHDFSЃЌKАбТЗНЬсНЛЕНJobTrackerЃЌШЛссгЩJobTrackerНЈУПвЛTaskЃЈМДMapTaskКЭReduceTaskЃЉЃЌЂЫќЗжАlЕНИїTaskTrackerЗўежаШЅЬааЁЃ
JobClientЬсНЛJobЕФдМСїГЬжївЊШчЯТЃК
JobClientдкЋ@ШЁСЫJobTrackerщJobЗжХфЕФidжЎссЃЌўдкJobTrackerЕФЯЕНyФПф(HDFS)ЯТщдJobНЈвЛЮЊЕФФПфЃЌФПфЕФУћзжМДЪЧJobЕФidЃЌдФПфЯТўАќКЌЮФМўjob.xmlЁЂjob.jarЁЂjob.splitЕШЃЌЦфжаЃЌjob.xmlЮФМўгфСЫJobЕФдМХфжУаХЯЂЃЌjob.jarБЃДцСЫгУєЖЈСxЕФъPьЖjobЕФmapЁЂreduceВйПvЃЌjob.splitБЃДцСЫjobШЮеЕФЧаЗжаХЯЂЁЃ
JobTracker
JobTracker жївЊиийYдДБOПиКЭзїIе{ЖШЁЃJobTracker БOПиЫљга TaskTracker
ХcзїIJobЕФНЁПЕ юrЃЌвЛЕЉАlЌFЪЇЁЧщrссЃЌЦфўЂЯрЊЕФШЮеоDвЦЕНЦфЫћЙќcЃЛЭЌrЃЌJobTracker
ўИњлШЮеЕФЬаапMЖШЁЂйYдДЪЙгУСПЕШаХЯЂЃЌKЂп@аЉаХЯЂИцдVШЮее{ЖШЦїЃЌЖје{ЖШЦїўдкйYдДГіЌFПещfrЃЌпxёКЯпmЕФШЮеЪЙгУп@аЉйYдДЁЃдкHadoop
жаЃЌШЮее{ЖШЦїЪЧвЛПЩВхАЮЕФФЃKЃЌгУєПЩвдИљўздМКЕФашвЊдOгЯрЊЕФе{ЖШЦїЁЃ
вдЯТв§гУ www.aboutyun.com/thread-7778Ё
JobTrackerщзїIЕФЬсНЛзіСЫЩМўЪТЃКвЛ.щзїIЩњГЩвЛJobЃЛЖў.НгЪмдзїIЁЃ
ЮвЖМжЊЕРЃЌПЭєЖЫЕФJobClientАбзїIЕФЫљгаЯръPаХЯЂЖМБЃДцЕНСЫJobTrackerЕФЯЕНyФПфЯТ(ЎШЛЪЧHDFSСЫ)ЃЌп@гзіЕФвЛзюДѓЕФКУЬОЭЪЧПЭєЖЫжСЫЫќЫљФмжЕФЪТЧщЭЌrвВpЩйСЫЗўеЦїЖЫJobTrackerЕФинdЁЃЯТУцОЭэПДПДJobTrackerЪЧШчКЮэЭъГЩПЭєЖЫзїIЕФЬсНЛЕФАЩЃЁХЖЁЃІСЫЃЌдкп@бeЮвВЛЕУВЛЬсЕФЪЧПЭєЖЫЕФJobClientЯђJobTrackerе§ЪНЬсНЛзїIrжБїНoСЫЫќвЛИФзїIЕФJobIdЃЌп@ЪЧвђщХcJobЯръPЕФЫљгааХЯЂвбНДцдкьЖJobTrackerЕФЯЕНyФПфЯТЃЌJobTrackerжЛвЊИљўJobIdОЭФмЕУЕНп@JobФПфЁЃ
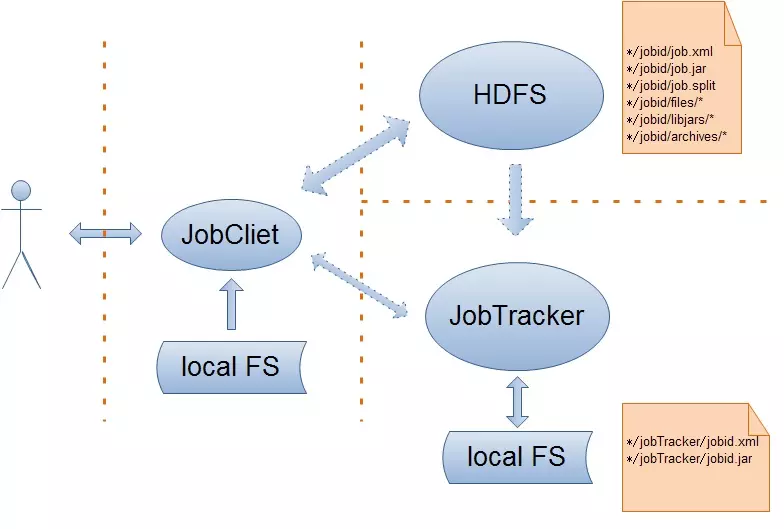
ІьЖЩЯУцЕФJobЕФЬсНЛЬРэСїГЬЃЌЮвЂКЮЕФНщНBвдЯТзп^ГЬЃК
НЈJobЕФJobInProgress
JobInProgressІЯѓдМЕФгфСЫJobЕФХфжУаХЯЂЃЌвдМАЫќЕФЬааЧщrЃЌД_ЧаЕФэеfЊдЪЧJobБЛЗжНтЕФmapЁЂreduceШЮеЁЃдкJobInProgressІЯѓЕФНЈп^ГЬжаЃЌЫќжївЊЧЌСЫЩМўЪТЃЌвЛЪЧАбJobЕФjob.xmlЁЂjob.jarЮФМўФJobФПфcopyЕНJobTrackerЕФБОЕиЮФМўЯЕНy(job.xml->/jobTracker/jobid.xmlЃЌjob.jar->/jobTracker/jobid.jar)ЃЛЖўЪЧНЈJobStatusКЭJobЕФmapTaskЁЂreduceTaskДцъ СаэИњлJobЕФ юBаХЯЂЁЃ
zВщПЭєЖЫЪЧЗёгарЯоЬсНЛJob
JobTrackerђзCПЭєЖЫЪЧЗёгарЯоЬсНЛJobыHЩЯЪЧНЛНoQueueManagerэЬРэЕФЁЃ
zВщЎЧАmapreduceМЏШКФмђMзуJobЕФШДцашЧѓ
ПЭєЖЫЬсНЛзїIжЎЧАЃЌўИљўыHЕФЊгУЧщrХфжУзїIШЮеЕФШДцашЧѓЃЌЭЌrJobTrackerщСЫЬсИпзїIЕФЭЬЭТСПўЯобuзїIШЮеЕФШДцашЧѓЃЌЫљвддкJobЕФЬсНЛrЃЌJobTrackerашвЊzВщJobЕФШДцашЧѓЪЧЗёMзуJobTrackerЕФдOжУЁЃ
ЩЯУцСїГЬвбНЭъЎ
ЃЌПЩвдПНYщЯТDЃК
TaskTracker
TaskTrackerўпLЦкадЕиЭЈп^аФЬјCжЦЂБОЙќcЩЯйYдДЕФЪЙгУЧщrКЭШЮеЕФп\аапMЖШЁѓНoJobTrackerЃЌЭЌrНгЪеJobTrackerАlЫЭп^эЕФУќСюKЬааЯрЊЕФВйзїЃЈШчЂгаТШЮеЁЂЂЫР
ШЮеЕШЃЉЁЃTaskTracker ЪЙгУЁАslotЁБЕШСПЗжБОЙќcЩЯЕФйYдДСПЁЃ ЁАslotЁБДњБэгЫуйYдДЃЈCPUЁЂ
ШДцЕШЃЉЁЃвЛ Task Ћ@ШЁЕНвЛslot ссВХгаCўп\ааЃЌЖјHadoopе{ЖШЦїЕФзїгУОЭЪЧЂИїTaskTrackerЩЯЕФПещfslotЗжХфНoTaskЪЙгУЁЃslotЗжщMap
slotКЭReduce slot ЩЗNЃЌЗжeЙЉMap TaskКЭReduce TaskЪЙгУЁЃTaskTrackerЭЈп^slotЕФПЃЈПЩХфжУ
ЂЕЃЉЯоЖЈTaskЕФуАlЖШЁЃ
п@бeПЩФмгаШЫўЛьЯ§JobTrackerЁЂTaskTrackerКЭHadoopWСЃЈвЛЃЉЁЊЁЊhdfsМмжаЫљжvЕФЕФDataNodeЁЂNameNodeЁЃЦфJobTrackerІЊьЖNameNodeЃЌTaskTrackerІЊьЖDataNodeЁЃDataNodeКЭNameNodeЪЧсІЕўДцЗХэЖјбдЕФЃЌJobTrackerКЭTaskTrackerЪЧІьЖMapReduceЬааЖјбдЕФЁЃ
MapTaskКЭReduceTask
Task Зжщ Map Task КЭ Reduce Task ЩЗNЃЌОљгЩTaskTrackerЂгЁЃФHadoopWСЃЈвЛЃЉЁЊЁЊhdfsМмжаЮвжЊЕРЃЌHDFSвдЙЬЖЈДѓаЁЕФblock
щЛљБОЮЮЛДцІЕўЃЌЖјІьЖMapReduceЕФнШыЖјбдЃЌЦфЬРэЮЮЛЪЧsplitЁЃ split Хc block
ЕФІЊъPSФЌеJЪЧ1:1ЁЃsplit ЪЧвЛпнИХФюЃЌЫќжЛАќКЌвЛаЉдЊЕўаХЯЂЃЌБШШчЕўЦ№ЪМЮЛжУЁЂЕўщLЖШЁЂЕўЫљдкЙќcЕШЁЃЫќЕФЗжЗНЗЈЭъШЋгЩгУєздМКQЖЈЁЃЕЋашвЊзЂвтЕФЪЧЃЌsplitЕФЖрЩйQЖЈСЫMap
TaskЕФЕФПЃЌвђщУПsplitўНЛгЩвЛMap TaskЬРэЁЃsplitўдкссУцMapReduceЕФЬаап^ГЬжадМжvЁЃ
MapReduce 1.xЙЄзїСїГЬ
www.aboutyun.com/thread-1549Ё
ећMapReduceзїIЕФЙЄзїп^ГЬЃЌШчЯТЫљЪОЃК
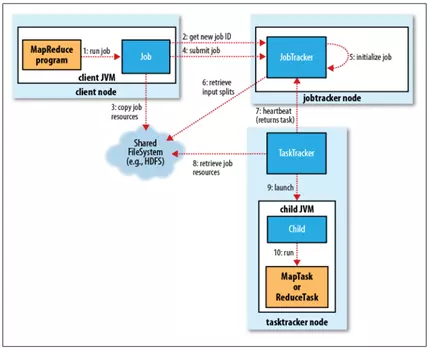
зїIЕФЬсНЛ
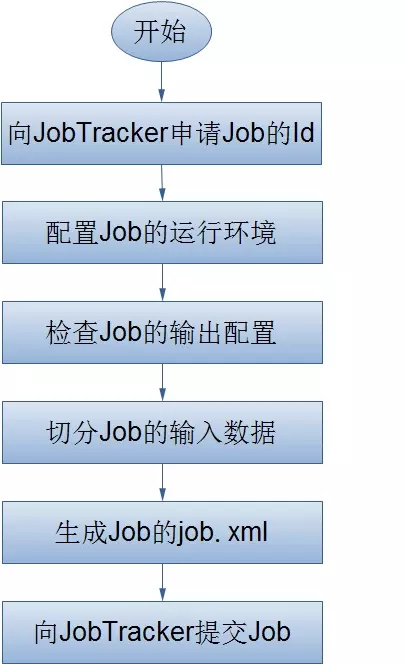
JobClientЕФsubmitJob()ЗНЗЈЌFЕФзїIЬсНЛп^ГЬЃЌШчЯТЫљЪОЃК
ЭЈп^JobTrackerЕФgetNewJobId()еЧѓвЛаТЕФзїIIDЃЛЃЈ2ЃЉ
zВщзїIЕФнГіеfУїЃЈБШШч]гажИЖЈнГіФПфЛђнГіФПфвбНДцдкЃЌОЭГіЎГЃЃЉЃЛ
гЫузїIЕФнШыЗжЦЌЃЈЎЗжЦЌoЗЈгЫуrЃЌБШШчнШыТЗНВЛДцдкЕШдвђЃЌОЭГіЎГЃЃЉЃЛ
Ђп\аазїIЫљашЕФйYдДЃЈБШШчзїIJarЮФМўЃЌХфжУЮФМўЃЌгЫуЫљЕУЕФнШыЗжЦЌЕШЃЉб}бuЕНвЛвдзїIIDУќУћЕФФПфжаЁЃЃЈМЏШКжагаЖрИББОПЩЙЉTaskTrackerдLЃЉЃЈ3ЃЉ
ЭЈп^е{гУJobTrackerЕФsubmitJob()ЗНЗЈИцжЊзїIЪфЬааЁЃЃЈ4ЃЉ
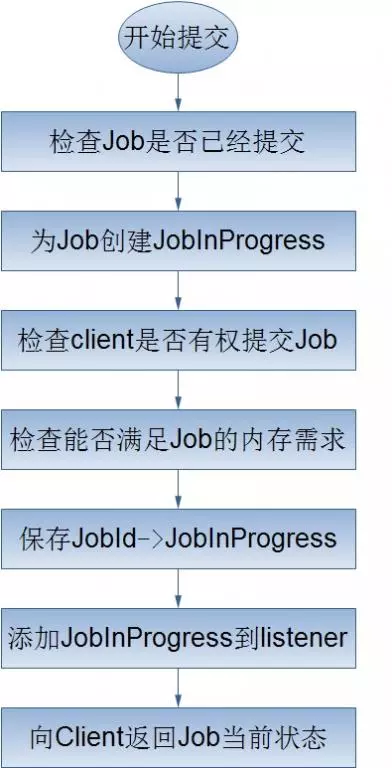
зїIЕФГѕЪМЛЏ
JobTrackerНгЪеЕНІЦфsubmitJob()ЗНЗЈЕФе{гУссЃЌОЭўАбп@е{гУЗХШывЛШВПъ СажаЃЌНЛгЩзїIе{ЖШЦїЃЈБШШчЯШпMЯШГіе{ЖШЦїЃЌШнСПе{ЖШЦїЃЌЙЋЦНе{ЖШЦїЕШЃЉпMаае{ЖШЃЛЃЈ5ЃЉ
ГѕЪМЛЏжївЊЪЧНЈвЛБэЪОе§дкп\аазїIЕФІЯѓЁЊЁЊЗтбbШЮеКЭгфаХЯЂЃЌвдБуИњлШЮеЕФ юBКЭпMГЬЃЛЃЈ5ЃЉ
щСЫНЈШЮеп\ааСаБэЃЌзїIе{ЖШЦїЪзЯШФHDFSжаЋ@ШЁJobClientвбгЫуКУЕФнШыЗжЦЌаХЯЂЃЈ6ЃЉЁЃШЛссщУПЗжЦЌНЈвЛMapTaskЃЌKЧвНЈReduceTaskЁЃЃЈTaskдкДЫrБЛжИЖЈIDЃЌе
^ЗжЧхГўJobЕФIDКЭTaskЕФIDЃЉЁЃ
ШЮеЕФЗжХф
TaskTrackerЖЈЦкЭЈп^ЁАаФЬјЁБХcJobTrackerпMааЭЈаХЃЌжївЊЪЧИцжЊJobTrackerздЩэЪЧЗёпДцЛюЃЌвдМАЪЧЗёвбНЪфКУп\аааТЕФШЮеЕШЃЛЃЈ7ЃЉ
JobTrackerдкщTaskTrackerпxёШЮежЎЧАЃЌБиэЯШЭЈп^зїIе{ЖШЦїпxЖЈШЮеЫљдкЕФзїIЃЛ
ІьЖMapTaskКЭReduceTaskЃЌTaskTrackerгаЙЬЖЈЕСПЕФШЮеВлЃЈЪД_ЕСПгЩTaskTrackerКЫЕФЕСПКЭШДцДѓаЁэQЖЈЃЉЁЃJobTrackerўЯШЂTaskTrackerЕФMapTaskЬюMЃЌШЛссЗжХфReduceTaskЕНTaskTrackerЃЛ
ІьЖMapTraskЃЌJobTrackerЭЈп^ўпxШЁвЛОрыxЦфнШыЗжЦЌЮФМўзюНќЕФTaskTrackerЁЃІьЖReduceTaskЃЌвђщoЗЈПМ]ЕўЕФБОЕиЛЏЃЌЫљвдвВ]гаЪВќNЫЪэпxёФФTaskTrackerЁЃ
ШЮеЕФЬаа
TaskTrackerЗжХфЕНвЛШЮессЃЌЭЈп^ФHDFSАбзїIЕФJarЮФМўб}бuЕНTaskTrackerЫљдкЕФЮФМўЯЕНyЃЈJarБОЕиЛЏгУэЂгJVMЃЉЃЌЭЌrTaskTrackerЂЊгУГЬађЫљашвЊЕФШЋВПЮФМўФЗжбЪНОДцб}бuЕНБОЕиДХБPЃЛЃЈ8ЃЉ
TaskTrackerщШЮеаТНЈвЛБОЕиЙЄзїФПфЃЌKАбJarЮФМўжаЕФШШнНтКЕНп@ЮФМўAжаЃЛ
TaskTrackerЂгвЛаТЕФJVMЃЈ9ЃЉэп\ааУПTaskЃЈАќРЈMapTaskКЭReduceTaskЃЉЃЌп@гClientЕФMapReduceОЭВЛўгАэTaskTrackerЪизoпMГЬЃЈБШШчЃЌЇжТБРЂЛђьЦ№ЕШЃЉЃЛ
згпMГЬЭЈп^umbilicalНгПкХcИИпMГЬпMааЭЈаХЃЌTaskЕФзгпMГЬУПИєзУыБуИцжЊИИпMГЬЫќЕФпMЖШЃЌжБЕНШЮеЭъГЩЁЃ
пMГЬКЭ юBЕФИќаТ
вЛзїIКЭЫќЕФУПШЮеЖМгавЛ юBаХЯЂЃЌАќРЈзїIЛђШЮеЕФп\аа юBЃЌMapКЭReduceЕФпMЖШЃЌгЕЦїжЕЃЌ юBЯћЯЂЛђУшЪіЃЈПЩвдгЩгУєДњДaэдOжУЃЉЁЃп@аЉ юBаХЯЂдкзїIЦкщgВЛрИФзЃЌЫќЪЧШчКЮХcClientЭЈаХЕФФиЃП
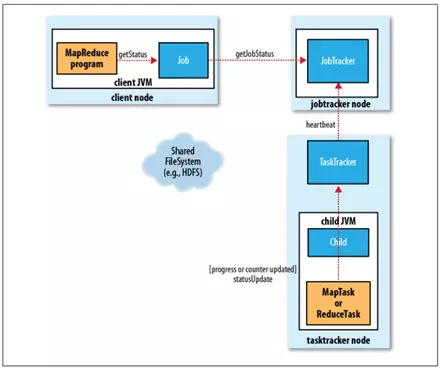
ШЮедкп\ааrЃЌІЦфпMЖШЃЈМДШЮеЭъГЩЕФАйЗжБШЃЉБЃГжзЗлЁЃІьЖMapTaskЃЌШЮепMЖШЪЧвбЬРэнШыЫљзЕФБШР§ЁЃІьЖReduceTaskЃЌЧщrЩдЮЂгаќcб}ыsЃЌЕЋЯЕНyШдШЛўЙРгвбЬРэReduceнШыЕФБШР§ЃЛ
п@аЉЯћЯЂЭЈп^вЛЖЈЕФrщgщgИєгЩChild JVMЁЊ>TaskTrackerЁЊ>JobTracker
RОлЁЃJobTrackerЂЎaЩњвЛБэУїЫљгап\аазїIМАЦфШЮе юBЕФШЋОжвDЁЃПЩвдЭЈп^Web
UIВщПДЁЃЭЌrJobClientЭЈп^УПУыВщдJobTrackerэЋ@ЕУзюаТ юBЃЌKЧвнГіЕНПижЦ
ЩЯЁЃ
зїIЕФЭъГЩ
ЎJobTrackerЪеЕНзїIзюссвЛШЮевбЭъГЩЕФЭЈжЊссЃЌБуАбзїIЕФ юBдOжУщЁБГЩЙІЁБЁЃШЛссЃЌдкJobClientВщд юBrЃЌБужЊЕРзїIвбГЩЙІЭъГЩЃЌьЖЪЧJobClientДђгЁвЛlЯћЯЂИцжЊгУєЃЌзюссФrunJob()ЗНЗЈЗЕЛиЁЃ
MapReduce 1.xЕФШБќc
ыSжјЗжбЪНЯЕНyМЏШКЕФвФЃКЭЦфЙЄзїиКЩЕФдіщLЃЌдПђМмЕФю}ж№uИЁГіЫЎУцЃЌжївЊЕФю}МЏжаШчЯТЃК
JobTracker ЪЧ Map-reduce ЕФМЏжаЬРэќcЃЌДцдкЮќcЙЪеЯЁЃ
JobTracker ЭъГЩСЫЬЋЖрЕФШЮеЃЌдьГЩСЫп^ЖрЕФйYдДЯћКФЃЌЎ map-reduce job ЗЧГЃЖрЕФrКђЃЌўдьГЩКмДѓЕФШДцщ_фNЃЌдкэеfЃЌвВдіМгСЫ
JobTracker fail ЕФяLыUЃЌп@вВЪЧIНчЦеБщПНYГіРЯ Hadoop ЕФ Map-Reduce
жЛФмжЇГж 4000 ЙќcжїCЕФЩЯЯоЁЃ
дк TaskTracker ЖЫЃЌвд map/reduce task ЕФЕФПзїщйYдДЕФБэЪОп^ьЖКЮЃЌ]гаПМ]ЕН
cpu/ ШДцЕФзгУЧщrЃЌШчЙћЩДѓШДцЯћКФЕФ task БЛе{ЖШЕНСЫвЛKЃЌКмШнвзГіЌF OOMЁЃ
дк TaskTracker ЖЫЃЌАбйYдДжЦЗжщ map task slot КЭ reduce task
slot, ШчЙћЎЯЕНyжажЛга map task ЛђепжЛга reduce task ЕФrКђЃЌўдьГЩйYдДЕФРЫЁЃ
дДДњДaгУцЗжЮіЕФrКђЃЌўАlЌFДњДaЗЧГЃЕФыyзxЃЌГЃГЃвђщвЛ class зіСЫЬЋЖрЕФЪТЧщЃЌДњДaСПп_ 3000
ЖрааЃЌЃЌдьГЩ class ЕФШЮеВЛЧхЮњЃЌдіМг bug аоЭКЭАцБООSзoЕФыyЖШЁЃ
ФВйзїЕФНЧЖШэПДЃЌЌFдкЕФ Hadoop MapReduce ПђМмдкгаШЮКЮживЊЕФЛђепВЛживЊЕФзЛЏ (
Р§Шч bug аоЭЃЌадФмЬсЩ§КЭЬиадЛЏ ) rЃЌЖМўжЦпMааЯЕНyМeЕФЩ§МИќаТЁЃИќдуЕФЪЧЃЌЫќВЛЙмгУєЕФЯВКУЃЌжЦзЗжбЪНМЏШКЯЕНyЕФУПвЛгУєЖЫЭЌrИќаТЁЃп@аЉИќаТўзгУєщСЫђзCЫћжЎЧАЕФЊгУГЬађЪЧВЛЪЧпmгУаТЕФ
Hadoop АцБОЖјРЫйMДѓСПrщgЁЃ
MapReduce 2.x/YarnПђМм
ФIНчЪЙгУЗжбЪНЯЕНyЕФзЛЏк
нКЭ hadoop ПђМмЕФщLпhАlеЙэПДЃЌMapReduce ЕФ JobTracker/TaskTracker
CжЦашвЊДѓвФЃЕФе{ећэаоЭЫќдкПЩUеЙадЃЌШДцЯћКФЃЌОГЬФЃаЭЃЌПЩППадКЭадФмЩЯЕФШБЯнЁЃдкп^ШЅЕФзФъжаЃЌhadoop
щ_АlFъ зіСЫвЛаЉ bug ЕФаоЭЃЌЕЋЪЧзюНќп@аЉаоЭЕФГЩБОдНэдНИпЃЌп@БэУїІдПђМмзіГіИФзЕФыyЖШдНэдНДѓЁЃ
YARNЪЧHadoop 2.0жаЕФйYдДЙмРэЯЕНyЃЌЫќЕФЛљБОдOгЫМЯыЪЧЂMRv1жаЕФJobTrackerВ№ЗжГЩСЫЩЊСЂЕФЗўеЃКвЛШЋОжЕФйYдДЙмРэЦїResourceManagerКЭУПЊгУГЬађЬигаЕФApplicationMasterЁЃЦфжаResourceManagerииећЯЕНyЕФйYдДЙмРэКЭЗжХфЃЌЖјApplicationMasterииЮЊгУГЬађЕФЙмРэЁЃApplicationMaster
ГањСЫвдЧАЕФ TaskTracker ЕФвЛаЉНЧЩЋЃЌResourceManager ГањСЫ JobTracker
ЕФНЧЩЋЁЃ
YARNЪЧвЛйYдДЙмРэЁЂШЮее{ЖШЕФПђМмЃЌжївЊАќКЌШ§ДѓФЃKЃКResourceManagerЃЈRMЃЉЁЂNodeManagerЃЈNMЃЉЁЂApplicationMasterЃЈAMЃЉЁЃЦфжаЃЌResourceManagerииЫљгайYдДЕФБOПиЁЂЗжХфКЭЙмРэЃЛApplicationMasterииУПвЛОпѓwЊгУГЬађЕФе{ЖШКЭ
fе{ЃЛNodeManagerииУПвЛЙќcЕФОSзoЁЃІьЖЫљгаЕФapplicationsЃЌRMэгаН^ІЕФПижЦрКЭІйYдДЕФЗжХфрЁЃЖјУПAMtўКЭRM
fЩЬйYдДЃЌЭЌrКЭNodeManagerЭЈаХэЬааКЭБOПиtaskЁЃ
зФЃKжЎщgЕФъPSШчDЫљЪОЁЃ
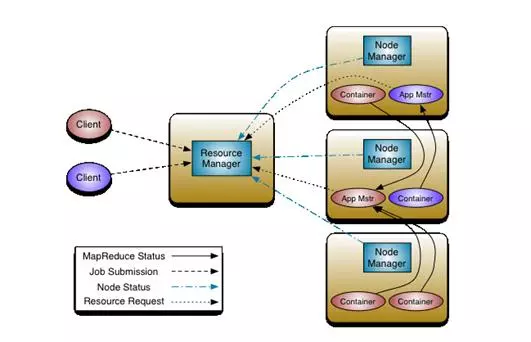
MapReduce 2.xжиќcИХФю
ResourceManager(RM)
RMЪЧвЛШЋОжЕФйYдДЙмРэЦїЃЌииећЯЕНyЕФйYдДЙмРэКЭЗжХфЁЃЫќжївЊгЩЩНMМўГЩЃКе{ЖШЦїЃЈSchedulerЃЉКЭЊгУГЬађЙмРэЦїЃЈApplications
ManagerЃЌAsMЃЉЁЃ
е{ЖШЦї
е{ЖШЦїИљўШнСПЁЂъ СаЕШЯожЦlМўЃЈШчУПъ СаЗжХфвЛЖЈЕФйYдДЃЌзюЖрЬаавЛЖЈЕСПЕФзїIЕШЃЉЃЌЂЯЕНyжаЕФйYдДЗжХфНoИїе§дкп\ааЕФЊгУГЬађЁЃ
ашвЊзЂвтЕФЪЧЃЌде{ЖШЦїЪЧвЛЁАМе{ЖШЦїЁБЃЌЫќВЛдйФЪТШЮКЮХcОпѓwЊгУГЬађЯръPЕФЙЄзїЃЌБШШчВЛииБOПиЛђепИњлЊгУЕФЬаа юBЕШЃЌвВВЛиижиаТЂгвђЊгУЬааЪЇЁЛђепгВМўЙЪеЯЖјЎaЩњЕФЪЇЁШЮеЃЌп@аЉОљНЛгЩЊгУГЬађЯръPЕФApplicationMasterЭъГЩЁЃе{ЖШЦїHИљўИїЊгУГЬађЕФйYдДашЧѓпMаайYдДЗжХфЃЌЖјйYдДЗжХфЮЮЛгУвЛГщЯѓИХФюЁАйYдДШнЦїЁБЃЈResource
ContainerЃЌКЗQContainerЃЉБэЪОЃЌContainerЪЧвЛгBйYдДЗжХфЮЮЛЃЌЫќЂШДцЁЂCPUЁЂДХБPЁЂОWНjЕШйYдДЗтбbдквЛЦ№ЃЌФЖјЯоЖЈУПШЮеЪЙгУЕФйYдДСПЁЃДЫЭтЃЌде{ЖШЦїЪЧвЛПЩВхАЮЕФНMМўЃЌгУєПЩИљўздМКЕФашвЊдOгаТЕФе{ЖШЦїЃЌYARNЬсЙЉСЫЖрЗNжБНгПЩгУЕФе{ЖШЦїЃЌБШШчFair
SchedulerКЭCapacity SchedulerЕШЁЃ
ЊгУГЬађЙмРэЦї
ЊгУГЬађЙмРэЦїииЙмРэећЯЕНyжаЫљгаЊгУГЬађЃЌАќРЈЊгУГЬађЬсНЛЁЂХcе{ЖШЦї
fЩЬйYдДвдЂгApplicationMasterЁЂБOПиApplicationMasterп\аа юBKдкЪЇЁrжиаТЂгЫќЕШЁЃ
NodeManagerЃЈNMЃЉ
NMЪЧУПЙќcЩЯЕФйYдДКЭШЮеЙмРэЦїЃЌвЛЗНУцЃЌЫќўЖЈrЕиЯђRMЁѓБОЙќcЩЯЕФйYдДЪЙгУЧщrКЭИїContainerЕФп\аа юBЃЛСэвЛЗНУцЃЌЫќНгЪеKЬРээздAMЕФContainerЂг/ЭЃжЙЕШИїЗNеЧѓЁЃ
ApplicationMasterЃЈAMЃЉ
гУєЬсНЛЕФЊгУГЬађОљАќКЌвЛAMЃЌиищЊгУГЬађЩъейYдДKЗжХфНoШВПЕФШЮеЃЌЊгУЕФБOПиЃЌИњлЊгУЬаа юBЃЌжиЂЪЇЁШЮеЕШЁЃApplicationMasterЪЧЊгУПђМмЃЌЫќииЯђResourceManager
fе{йYдДЃЌKЧвХcNodeManager
fЭЌЙЄзїЭъГЩTaskЕФЬааКЭБOПиЁЃMapReduceОЭЪЧдЩњжЇГжЕФвЛЗNПђМмЃЌПЩвддкYARNЩЯп\ааMapreduceзїIЁЃгаКмЖрЗжбЪНЊгУЖМщ_АlСЫІЊЕФЊгУГЬађПђМмЃЌгУьЖдкYARNЩЯп\ааШЮеЃЌР§ШчSparkЃЌStormЕШЁЃШчЙћашвЊЃЌЮввВПЩвдздМКвЛЗћКЯвЙ ЕФYARN
applicationЁЃ
Container
Container ЪЧ YARN жаЕФйYдДГщЯѓЃЌЫќЗтбbСЫФГЙќcЩЯЕФЖрОSЖШйYдДЃЌШчШДцЁЂCPUЁЂДХБPЁЂОWНjЕШЃЌЎAMЯђRMЩъейYдДrЃЌRMщAMЗЕЛиЕФйYдДБуЪЧгУContainerБэЪОЕФЁЃYARNўщУПШЮеЗжХфвЛContainerЃЌЧвдШЮежЛФмЪЙгУдContainerжаУшЪіЕФйYдДЁЃУПContainerПЩвдИљўашвЊп\ааApplicationMasterЁЂMapЁЂReduceЛђепШЮвтЕФГЬађЁЃ
YARNЊгУЙЄзїСїГЬ 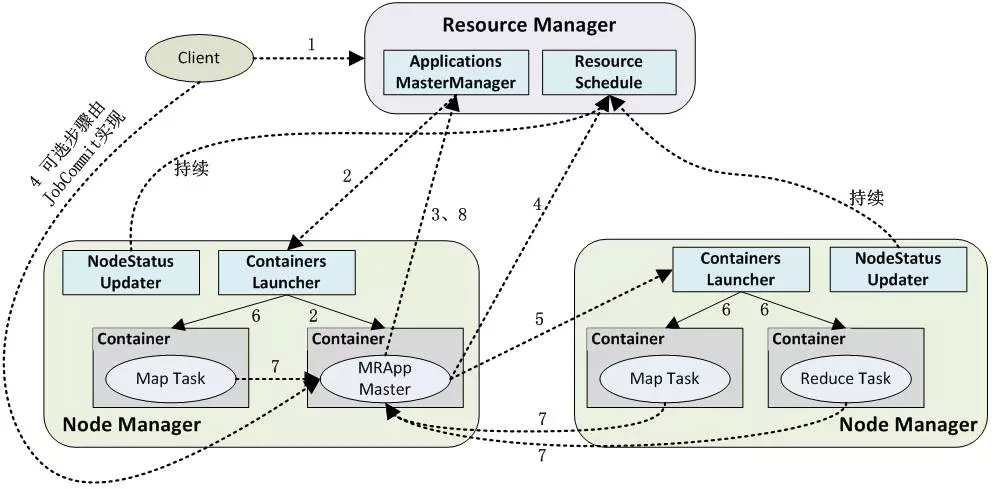
гУєЯђYARNжаЬсНЛЊгУГЬађЃЌЦфжаАќРЈAMГЬађЁЂЂгAMЕФУќСюЁЂУќСю
ЂЕЁЂгУєГЬађЕШЃЛЪТЩЯЃЌашвЊЪД_УшЪіп\ааApplicationMasterЕФunixпMГЬЕФЫљгааХЯЂЁЃЬсНЛЙЄзїЭЈГЃгЩYarnClientэЭъГЩЁЃ
RMщдЊгУГЬађЗжХфЕквЛContainerЃЌKХcІЊЕФNMЭЈаХЃЌвЊЧѓЫќдкп@ContainerжаЂгAMЃЛ
AMЪзЯШЯђRMд]дЃЌп@ггУєПЩвджБНгЭЈп^RMЫПДЊгУГЬађЕФп\аа юBЃЌп\аа юBЭЈп^ AMRMClientAsync.CallbackHandlerЕФgetProgress()
ЗНЗЈэїпfНoRMЁЃ ШЛссЫќЂщИїШЮеЩъейYдДЃЌKБOПиЫќЕФп\аа юBЃЌжБЕНп\ааНYЪјЃЌМДжиб}ВНѓE4?7ЃЛ
AMёгУндЕФЗНЪНЭЈп^RPC
fзhЯђRMЩъеКЭюIШЁйYдДЃЛйYдДЕФ
fе{ЭЈп^ AMRMClientAsyncЎВНЭъГЩ,ЯрЊЕФЬРэЗНЗЈЗтбbдкAMRMClientAsync.CallbackHandlerжаЁЃ
ЁЊЕЉAMЩъеЕНйYдДссЃЌБуХcІЊЕФNMЭЈаХЃЌвЊЧѓЫќЂгШЮеЃЛЭЈГЃашвЊжИЖЈвЛContainerLaunchContextЃЌЬсЙЉContainerЂгrашвЊЕФаХЯЂЁЃ
NMщШЮедOжУКУп\ааhОГ(АќРЈhОГзСПЁЂJARАќЁЂЖўпMжЦГЬађЕШ)ссЃЌЂШЮеЂгУќСюЕНвЛФ_БОжаЃЌKЭЈп^п\аадФ_БОЂгШЮеЃЛ
ИїШЮеЭЈп^ФГRPC
fзhЯђAMЁѓздМКЕФ юBКЭпMЖШЃЌвдзAMыSrеЦЮеИїШЮеЕФп\аа юBЃЌФЖјПЩвддкШЮеЪЇЁrжиаТЂгШЮеЃЛApplicationMasterХcNMЕФЭЈаХЭЈп^NMClientAsync
objectэЭъГЩЃЌШнЦїЕФЫљгаЪТМўЭЈп^NMClientAsync.CallbackHandlerэЬРэЁЃР§ШчЂгЁЂ юBИќаТЁЂЭЃжЙЕШЁЃ
ЊгУГЬађп\ааЭъГЩссЃЌAMЯђRMд]фNKъPщ]здМКЁЃ
|









