| БрМЭЦМі: |
БОЮФДгЭтЕНФкЃЌвРДЮРДНщЩмpresto,ЪзЯШНщЩмprestodeЕФдРэЃЌЪ§ОнФЃаЭЃЌвдМАprestoБраДВхМўЃЌзюКѓРДНщЩмPrestoФкДцЙмРэЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДзджЊКѕЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
МђНщ
PrestoЪЧвЛИіfacebookПЊдДЕФЗжВМЪНSQLВщбЏв§ЧцЃЌЪЪгУгкНЛЛЅЪНЗжЮіВщбЏЃЌЪ§ОнСПжЇГжGBЕНPBзжНкЁЃprestoЕФМмЙЙгЩЙиЯЕаЭЪ§ОнПтЕФМмЙЙбнЛЏЖјРДЁЃprestoжЎЫљвдФмдкИїИіФкДцМЦЫуаЭЪ§ОнПтжаЭбгБЖјГіЃЌдкгквдЯТМИЕуЃК
ЧхЮњЕФМмЙЙЃЌЪЧвЛИіФмЙЛЖРСЂдЫааЕФЯЕЭГЃЌВЛвРРЕгкШЮКЮЦфЫћЭтВПЯЕЭГЁЃР§ШчЕїЖШЃЌprestoздЩэЬсЙЉСЫЖдМЏШКЕФМрПиЃЌПЩвдИљОнМрПиаХЯЂЭъГЩЕїЖШЁЃ
МђЕЅЕФЪ§ОнНсЙЙЃЌСаЪНДцДЂЃЌТпМааЃЌДѓВПЗжЪ§ОнЖМПЩвдЧсвзЕФзЊЛЏГЩprestoЫљашвЊЕФетжжЪ§ОнНсЙЙЁЃ
ЗсИЛЕФВхМўНгПкЃЌЭъУРЖдНгЭтВПДцДЂЯЕЭГЃЌЛђепЬэМгздЖЈвхЕФКЏЪ§ЁЃ
МмЙЙ
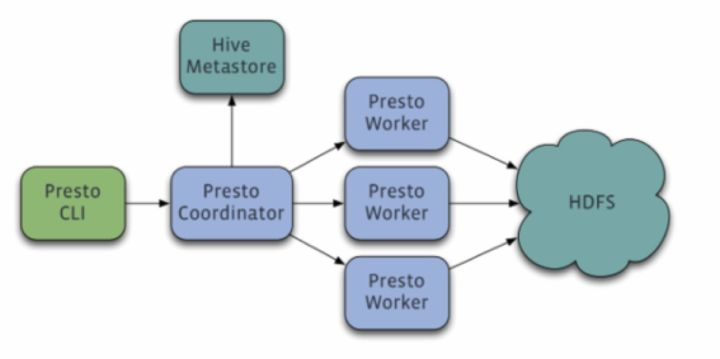
PrestoВЩгУЕфаЭЕФmaster-slaveФЃаЭЃК
coordinator(master)ИКд№metaЙмРэ,workerЙмРэЃЌqueryЕФНтЮіКЭЕїЖШ
workerдђИКд№МЦЫуКЭЖСаДЁЃ
discovery serverЃЌ ЭЈГЃФкЧЖгкcoordinatorНкЕужаЃЌвВПЩвдЕЅЖРВПЪ№ЃЌгУгкНкЕуаФЬјЁЃдкЯТЮФжаЃЌФЌШЯdiscoveryКЭcoordinatorЙВЯэвЛЬЈЛњЦїЁЃ
дкworkerЕФХфжУжаЃЌПЩвдбЁдёХфжУЃК
discoveryЕФip:portЁЃ
вЛИіhttpЕижЗЃЌФкШнЪЧservice inventoryЃЌАќКЌdiscoveryЕижЗЁЃ
вЛИіБОЕиЮФМўЕижЗ
{
"environment": "production",
"services": [
{
"id": "ffffffff-ffff-ffff-ffff-ffffffffffff",
"type": "discovery",
"location":
"/ffffffff-ffff-ffff-ffff-ffffffffffff",
"pool": "general",
"state":
"RUNNING",
"properties":
{
"http": "http://192.168.1.1:8080"
}
}
]
} |
2КЭ3ЕФдРэЪЧЛљгкservice inventory, worker ЛсЖЏЬЌМрЬ§етИіЮФМўЃЌШчЙћгаБфЛЏЃЌloadГізюаТЕФХфжУЃЌжИЯђзюаТЕФdiscoveryНкЕуЁЃ
дкЩшМЦЩЯЃЌdiscoveryКЭcoordinatorЖМЪЧЕЅНкЕуЁЃШчЙћгаЖрИіcoordinatorЭЌЪБДцЛюЃЌworker
ЛсЫцЛњЕФЯђЦфжавЛИіЛуБЈНјГЬКЭtaskзДЬЌЃЌЕМжТФдСбЁЃЕїЖШqueryЪБгаПЩФмЛсЗЂЩњЫРЫјЁЃ
discoveryКЭcoordinatorПЩгУадЩшМЦЁЃгЩгкservice inventoryЕФЪЙгУЃЌМрПиГЬађПЩвддкЗЂЯжdiscoveryЙвЕєКѓЃЌаоИФservice
inventoryжаЕФФкШнЃЌжИЯђБИЛњЕФdiscoveryЁЃЮоЗьЕФЭъГЩЧаЛЛЁЃcoordiantorЕФХфжУБиаывЊдкНјГЬЦєЖЏЪБжИЖЈЃЌЭЌвЛИіМЏШКжаЮоЗЈДцЛюЖрИіcoordinatorЁЃвђДЫзюКУЕФАьЗЈЪЧКЭdiscoveryХфжУЕНвЛЬЈЛњЦїЁЃ
secondaryЛњЦїВПЪ№БИгУЕФdiscoveryКЭcoordinatorЁЃдкЦНЪБЃЌsecondaryЛњЦїЪЧвЛИіжЛАќКЌвЛЬЈЛњЦїЕФМЏШКЃЌдкprimaryхДЛњЪБЃЌworkerЕФаФЬјЫВМфЧаЛЛЕНsecondaryЁЃ
Ъ§ОнФЃаЭ
prestoВЩШЁШ§ВуБэНсЙЙЃК
1.catalog ЖдгІФГвЛРрЪ§ОндДЃЌР§ШчhiveЕФЪ§ОнЃЌЛђmysqlЕФЪ§Он
2.schema ЖдгІmysqlжаЕФЪ§ОнПт
3.table ЖдгІmysqlжаЕФБэ

prestoЕФДцДЂЕЅдЊАќРЈЃК
PageЃК ЖрааЪ§ОнЕФМЏКЯЃЌАќКЌЖрИіСаЕФЪ§ОнЃЌФкВПНіЬсЙЉТпМааЃЌЪЕМЪвдСаЪНДцДЂЁЃ
BlockЃКвЛСаЪ§ОнЃЌИљОнВЛЭЌРраЭЕФЪ§ОнЃЌЭЈГЃВЩШЁВЛЭЌЕФБрТыЗНЪНЃЌСЫНтетаЉБрТыЗНЪНЃЌгажњгкздМКЕФДцДЂЯЕЭГЖдНгprestoЁЃ
ВЛЭЌРраЭЕФblockЃК
arrayРраЭblockЃЌгІгУгкЙЬЖЈПэЖШЕФРраЭЃЌР§ШчintЃЌlongЃЌdoubleЁЃblockгЩСНВПЗжзщГЩ
boolean valueIsNull[]БэЪОУПвЛааЪЧЗёгажЕЁЃ
T values[] УПвЛааЕФОпЬхжЕЁЃ
2. ПЩБфПэЖШЕФblockЃЌгІгУгкstringРрЪ§ОнЃЌгЩШ§ВПЗжаХЯЂзщГЩ
Slice ЃК ЫљгаааЕФЪ§ОнЦДНгЦ№РДЕФзжЗћДЎЁЃ
int offsets[] :УПвЛааЪ§ОнЕФЦ№ЪМБувЫЮЛжУЁЃУПвЛааЕФГЄЖШЕШгкЯТвЛааЕФЦ№ЪМБувЫМѕШЅЕБЧАааЕФЦ№ЪМБувЫЁЃ
boolean valueIsNull[] БэЪОФГвЛааЪЧЗёгажЕЁЃШчЙћгаФГвЛааЮожЕЃЌФЧУДетвЛааЕФБувЫСПЕШгкЩЯвЛааЕФЦЋвЦСПЁЃ
3. ЙЬЖЈПэЖШЕФstringРраЭЕФblockЃЌЫљгаааЕФЪ§ОнЦДНгГЩвЛГЄДЎSliceЃЌУПвЛааЕФГЄЖШЙЬЖЈЁЃ
4. зжЕфblockЃКЖдгкФГаЉСаЃЌdistinctжЕНЯЩйЃЌЪЪКЯЪЙгУзжЕфБЃДцЁЃжївЊгаСНВПЗжзщГЩЃК
зжЕфЃЌПЩвдЪЧШЮвтвЛжжРраЭЕФblock(ЩѕжСПЩвдЧЖЬзвЛИізжЕфblock)ЃЌblockжаЕФУПвЛааАДееЫГађХХађБрКХЁЃ
int ids[] БэЪОУПвЛааЪ§ОнЖдгІЕФvalueдкзжЕфжаЕФБрКХЁЃдкВщевЪБЃЌЪзЯШевЕНФГвЛааЕФidЃЌШЛКѓЕНзжЕфжаЛёШЁецЪЕЕФжЕЁЃ
ВхМў
СЫНтСЫprestoЕФЪ§ОнФЃаЭЃЌОЭПЩвдИјprestoБраДВхМўЃЌРДЖдНгздМКЕФДцДЂЯЕЭГЁЃprestoЬсЙЉСЫвЛЬзconnectorНгПкЃЌДгздЖЈвхДцДЂжаЖСШЁдЊЪ§ОнЃЌвдМАСаДцДЂЪ§ОнЁЃЯШПДconnectorЕФЛљБОИХФюЃК
ConnectorMetadata: ЙмРэБэЕФдЊЪ§ОнЃЌБэЕФдЊЪ§ОнЃЌpartitionЕШаХЯЂЁЃдкДІРэЧыЧѓЪБЃЌашвЊЛёШЁдЊаХЯЂЃЌвдБуШЗШЯЖСШЁЕФЪ§ОнЕФЮЛжУЁЃPrestoЛсДЋШыfilterЬѕМўЃЌвдБуМѕЩйЖСШЁЕФЪ§ОнЕФЗЖЮЇЁЃдЊаХЯЂПЩвдДгДХХЬЩЯЖСШЁЃЌвВПЩвдЛКДцдкФкДцжаЁЃ
ConnectorSplit: вЛИіIO TaskДІРэЕФЪ§ОнЕФМЏКЯЃЌЪЧЕїЖШЕФЕЅдЊЁЃвЛИіsplitПЩвдЖдгІвЛИіpartitionЃЌЛђЖрИіpartitionЁЃ
SplitManager : ИљОнБэЕФmetaЃЌЙЙдьsplitЁЃ
SlsPageSource : ИљОнsplitЕФаХЯЂвдМАвЊЖСШЁЕФСааХЯЂЃЌДгДХХЬЩЯЖСШЁ0ИіЛђЖрИіpageЃЌЙЉМЦЫув§ЧцМЦЫуЁЃ
ВхМўФмЙЛАяжњПЊЗЂепЬэМгетаЉЙІФмЃК
ЖдНгздМКЕФДцДЂЯЕЭГЁЃ
ЬэМгздЖЈвхЪ§ОнРраЭЁЃ
ЬэМгздЖЈвхДІРэКЏЪ§ЁЃ
здЖЈвхШЈЯоПижЦЁЃ
здЖЈвхзЪдДПижЦЁЃ
ЬэМгqueryЪТМўДІРэТпМЁЃ
PrestoЬсЙЉСЫвЛИіМђЕЅЕФconnector : local file connector ,ПЩгУгкВЮПМШчКЮЪЕЯжздМКЕФconnectorЁЃВЛЙ§local
file connectorжаЪЙгУЕФБщРњЪ§ОнЕФЕЅдЊЪЧcursor,МДвЛааЪ§ОнЃЌЖјВЛЪЧвЛИіpageЁЃ
hive ЕФconnectorжаЪЕЯжСЫШ§жжРраЭЃЌparquet connector, orc connector,
rc file connectorЁЃ

ЩЯЮФДгКъЙлЩЯНщЩмСЫprestoЕФвЛаЉдРэЃЌНгЯТРДМИЦЊЮФеТШУЮвУЧЩюШыpresto ФкВПЃЌСЫНтвЛаЉФкВПЕФЩшМЦЃЌетЖдадФмЕїгХЛсгаБШНЯДѓЕФгУДІЃЌвВгажњгкЬэМгздЖЈвхЕФoperatorЁЃ
ФкДцЙмРэ
PrestoЪЧвЛПюФкДцМЦЫуаЭЕФв§ЧцЃЌЫљвдЖдгкФкДцЙмРэБиаызіЕНОЋЯИЃЌВХФмБЃжЄqueryгаађЁЂЫГРћЕФжДааЃЌВПЗжЗЂЩњЖіЫРЁЂЫРЫјЕШЧщПіЁЃ
ФкДцГи
PrestoВЩгУТпМЕФФкДцГиЃЌРДЙмРэВЛЭЌРраЭЕФФкДцашЧѓЁЃ
PrestoАбећИіФкДцЛЎЗжГЩШ§ИіФкДцГиЃЌЗжБ№ЪЧSystem Pool ,Reserved Pool,
General PoolЁЃ
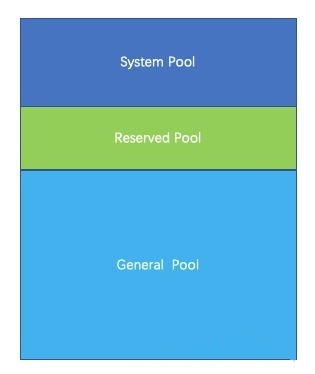
System Pool ЪЧгУРДБЃСєИјЯЕЭГЪЙгУЕФЃЌФЌШЯЮЊ40%ЕФФкДцПеМфСєИјЯЕЭГЪЙгУЁЃ
Reserved PoolКЭGeneral Pool ЪЧгУРДЗжХфqueryдЫааЪБФкДцЕФЁЃ
ЦфжаДѓВПЗжЕФqueryЪЙгУgeneral PoolЁЃ ЖјзюДѓЕФвЛИіqueryЃЌЪЙгУReserved
PoolЃЌ ЫљвдReserved PoolЕФПеМфЕШЭЌгквЛИіqueryдквЛИіЛњЦїЩЯдЫааЪЙгУЕФзюДѓПеМфДѓаЁЃЌФЌШЯЪЧ10%ЕФПеМфЁЃ
GeneralдђЯэгаГ§СЫSystem PoolКЭGeneral PoolжЎЭтЕФЦфЫћФкДцПеМфЁЃ
ЮЊЪВУДвЊЪЙгУФкДцГи
System PoolгУгкЯЕЭГЪЙгУЕФФкДцЃЌР§ШчЛњЦїжЎМфДЋЕнЪ§ОнЃЌдкФкДцжаЛсЮЌЛЄbufferЃЌетВПЗжФкДцЙвдиsystemУћЯТЁЃ
ФЧУДЃЌЮЊЪВУДашвЊБЃСєЧјФкДцФиЃПВЂЧвБЃСєЧјФкДце§КУЕШгкqueryдкЛњЦїЩЯЪЙгУЕФзюДѓФкДцЃП
ШчЙћУЛгаReserved PoolЃЌ ФЧУДЕБqueryЗЧГЃЖрЃЌВЂЧвАбФкДцПеМфМИКѕПьвЊеМЭъЕФЪБКђЃЌФГвЛИіФкДцЯћКФБШНЯДѓЕФqueryПЊЪМдЫааЁЃЕЋЪЧетЪБКђвбОУЛгаФкДцПеМфПЩЙЉетИіqueryдЫааСЫЃЌетИіqueryвЛжБДІгкЙвЦ№зДЬЌЃЌЕШД§ПЩгУЕФФкДцЁЃ
ЕЋЪЧЦфЫћЕФаЁФкДцqueryХмЭъКѓЃЌгжгааТЕФаЁФкДцqueryМгНјРДЁЃгЩгкаЁФкДцqueryеМгУФкДцаЁЃЌКмШнвзевЕНПЩгУФкДцЁЃ
етжжЧщПіЯТЃЌДѓФкДцqueryОЭвЛжБЙвЦ№жБЕНЖіЫРЁЃ
ЫљвдЮЊСЫЗРжЙГіЯжетжжЖіЫРЕФЧщПіЃЌБиаыдЄСєГіРДвЛПщПеМфЃЌЙВДѓФкДцqueryдЫааЁЃ дЄСєЕФПеМфДѓаЁЕШгкqueryдЪаэЪЙгУЕФзюДѓФкДцЁЃPrestoУПУыжгЃЌЬєГіРДвЛИіФкДцеМгУзюДѓЕФqueryЃЌдЪаэЫќЪЙгУreserved
poolЃЌБмУтвЛжБУЛгаПЩгУФкДцЙЉИУqueryдЫааЁЃ
ФкДцЙмРэ
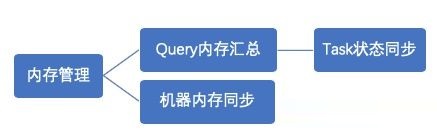
PrestoФкДцЙмРэЃЌЗжСНВПЗжЃК
1.queryФкДцЙмРэ
queryЛЎЗжГЩКмЖрtaskЃЌ УПИіtaskЛсгавЛИіЯпГЬбЛЗЛёШЁtaskЕФзДЬЌЃЌАќРЈtaskЫљгУФкДцЁЃЛузмГЩqueryЫљгУФкДцЁЃ
ШчЙћqueryЕФЛузмФкДцГЌЙ§вЛЖЈДѓаЁЃЌдђЧПжЦжежЙИУqueryЁЃ
2.ЛњЦїФкДцЙмРэ
coordinatorгавЛИіЯпГЬЃЌЖЈЪБЕФТжбЕУПЬЈЛњЦїЃЌВщПДЕБЧАЕФЛњЦїФкДцзДЬЌЁЃ
ЕБqueryФкДцКЭЛњЦїФкДцЛузмжЎКѓЃЌcoordinatorЛсЬєбЁГівЛИіФкДцЪЙгУзюДѓЕФqueryЃЌЗжХфИјReserved
PoolЁЃ
ФкДцЙмРэЪЧгЩcoordinatorРДЙмРэЕФЃЌ coordinatorУПУыжгзівЛДЮХаЖЯЃЌжИЖЈФГИіqueryдкЫљгаЕФЛњЦїЩЯЖМФмЪЙгУreserved
ФкДцЁЃФЧУДЮЪЬтРДСЫЃЌШчЙћФГЬЈЛњЦїЩЯЃЌЃЌУЛгадЫааИУqueryЃЌФЧЦёВЛЪЧИУЛњЦїдЄСєЕФФкДцРЫЗбСЫЃПЮЊЪВУДВЛдкЕЅЬЈЛњЦїЩЯЬєГіРДвЛИізюДѓЕФtaskжДааЁЃдвђЛЙЪЧЫРЫјЃЌМйШчqueryЃЌдкЦфЫћЛњЦїЩЯЯэгаreservedФкДцЃЌКмПьжДааНсЪјЁЃЕЋЪЧдкФГвЛЬЈЛњЦїЩЯВЛЪЧзюДѓЕФtaskЃЌвЛжБЕУВЛЕНдЫааЃЌЕМжТИУqueryЮоЗЈНсЪјЁЃ |









