| 编辑推荐: |
本文主要介绍了Elasticsearch分布式架构的特点,自动集群发现,负载均衡,高可用,扩容以及容错性,希望对您的学习有所帮助。
本文来自csdn,由火龙果软件Alice编辑、推荐。 |
|
一、分布式架构
1、特点
开箱即用,简单粗暴
Elasticsearch天然支持分布式和集群,开箱即用,零配置,零改动。
自动分片
一个index默认5个primary shard,那么我们创建一个document,他给我们分配到哪个shard上了呢?搜索的时候又是怎么知道我们搜的这个document再哪个shard上呢?这都是es内部为我们做好的,开发者完全不用关心。
自动集群发现
英文:cluster discovery。我们本机启动两个es实例,也就是两个node节点,默认集群名称是elasticsearch,所以他会自动将这两个node凑成一个集群,我们什么都不用配置,它自动发现。
shard负载均衡
假设我们有1个index,五个primary shard,两个node,他会自动为我们将这5个shard分配到两台node上,一台三个shard,一台两个shard,我们又加了三台node,五个node凑成了一个集群,那么es会自动为我们将这五个shard平分到五台机器,每台一个shard,这些过程都自动的,开发者啥也不用管。
二、自动集群发现
我们先启动一台es实例,然后通过head插件看是如下效果
1.集群只有一个node01节点
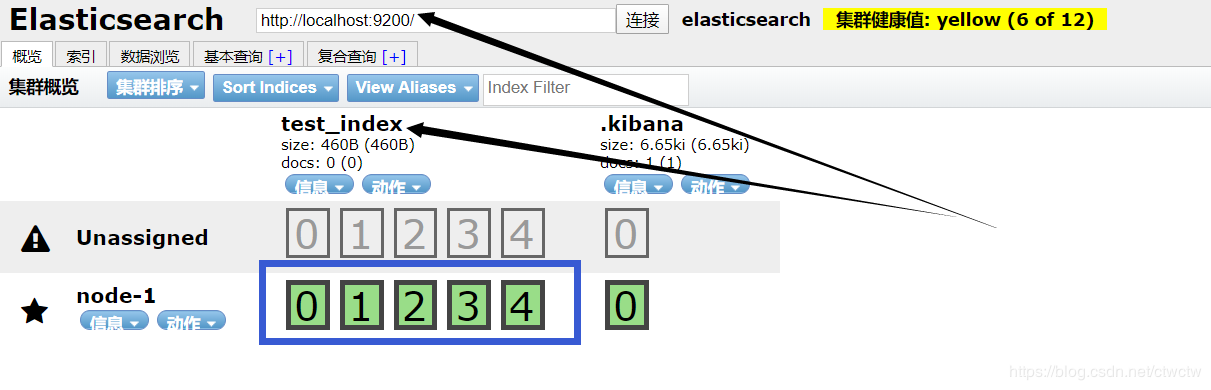
2.里面包含一个test_index索引,我们测试用的,自己建的。我们启动第二台(修改端口为9201),然后再看head插件的集群信息

1.两个node了,node1和node2自动凑了一个集群。我们查的node1的信息(端口9200)发现node2也在里面了。
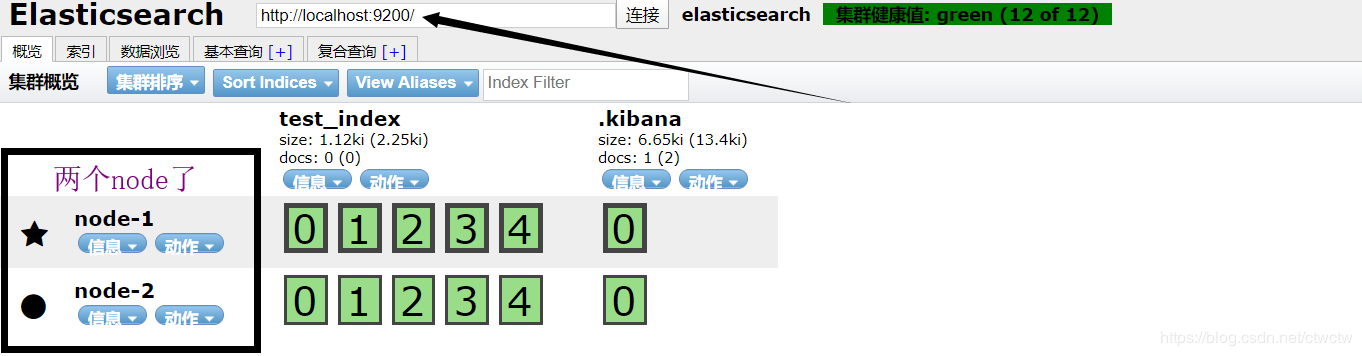
2.自动同步主节点的数据,主节点这里就是node1,因为它先启动的。当时就它自己,所以它是老大。

可以发现ES的集群如此简单,它自动寻找能凑成集群的节点,完全不用开发者关心。
三、负载均衡
1、概念
反复提到的如果只有5个shard,但是有两台实例,那么会自动为我们在某个实例上分配三个shard,另外一台分配两个,全自动进行负载均衡的分配。比如又加了一个node,这时候就会为我们在某两台上分配2个shard,另外一台一个shard,将服务器请求压力平分。不用人干预,全自动。
2、两张图带走这个知识点
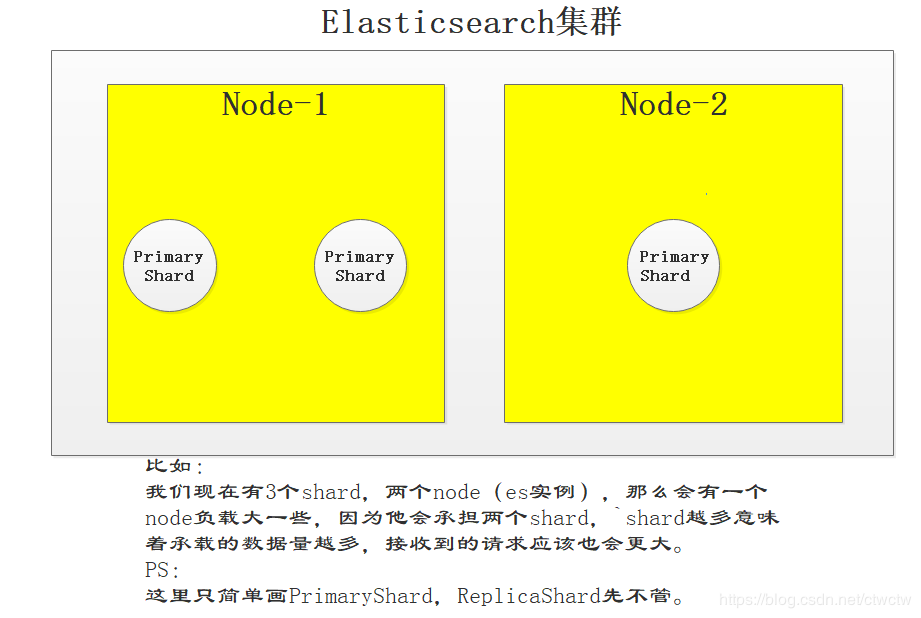
这时候公司发财了,要扩容一台node出来。我们再来看效果:

3、补充
1.我只是拿3个shard举例,实际上1个index就N个shard,而且公司不可能只有1个index,我这里只是简单说明原理。
2.问:3个shard,我四个node,这种情况会浪费一台node的性能嘛?
答:不完全正确,首先,primaryshard确实只会分配到3个node上,但是我们还有replica
shard呀,所以第4个node上会存replica shard进行提升吞吐量。并不会完全浪费掉。
3.Master节点用途
管理ES集群中的元数据:比如说索引的增删改操作,维护集群的元数据,比如节点的增加和移除。
默认情况下,会自动选择出一台节点作为master节点。Master选举下篇文章来分析。
注意:master节点不承载所有的请求,所以不会是一个单点瓶颈。也就是说Master负责增删改数据,查询请求每个节点都会收到,并不是都由Master统一处理。
四、高可用
1、复习Shard
1个index包含多个shard
默认5个Primary Shard,1个Replica Shard(是每个PrimaryShard配1个ReplicaShard)
每个Shard都是一个lucene实例
每个shard都是一个最小工作单元,承载部分数据,每个shard就是一个lucune实例,完整的建立索引和处理请求的能力
shard负载均衡
增减节点时,shard会自动在nodes中负载均衡(rebalance)
1个document只能存在一个PrimaryShard里
但是可以存在于多个Replica Shard中,实现高可用、提升吞吐量。
Replica Shard是primary shard的副本
ReplicaShard用途主要是作为PrimaryShard的副本,帮PrimaryShard分担请求,和数据备份。防止node宕机后数据丢失。
Shard数量
Primary Shard的数量在创建索引的时候就固定了,Replica Shard的数量可以随时修改。
Primary Shard不能和自己的Replica Shard放在同一个节点上
否则节点宕机,primary shard和副本都丢失,起不到容错的作用。
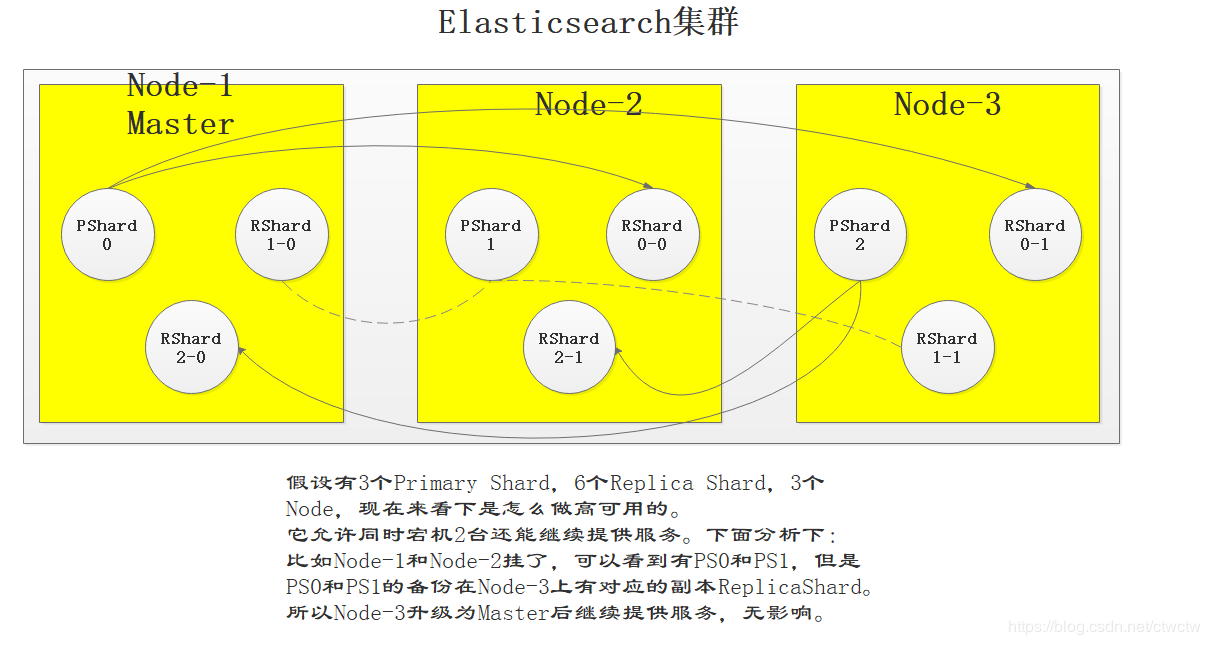
2、高可用
不想打字,一图定胜负吧。
再啰嗦一句:ES不允许同PrimaryShard和ReplicaShard在同一个node上。比如P0和R0必须在两个Node里,否则还是单点故障。
2.1、两台node
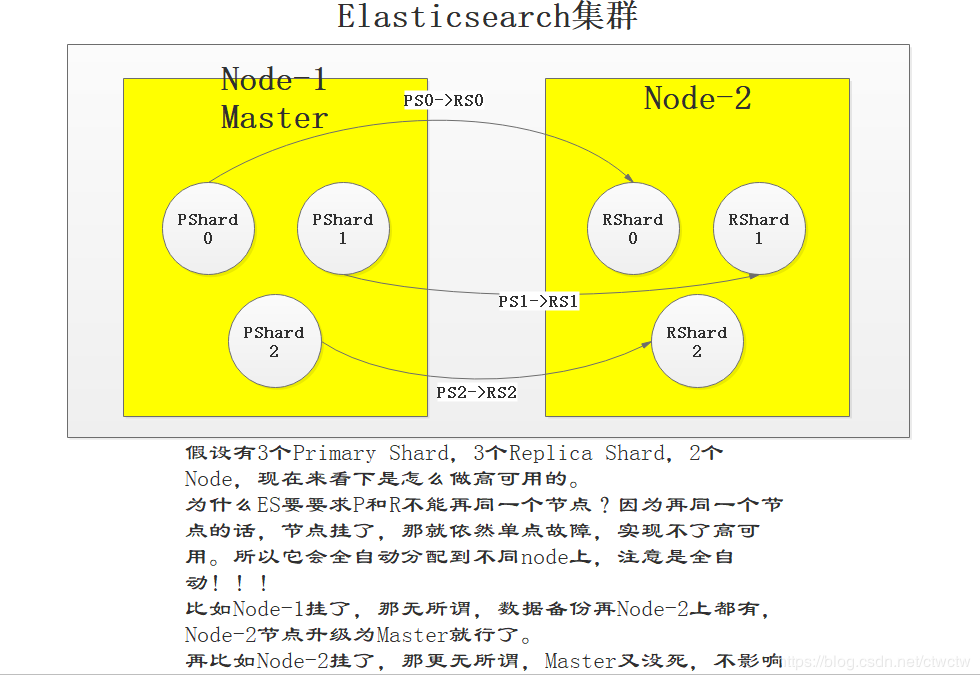
2.2、三台node
五、扩容
并不是es扩容是这两种方案,而是扩容方案是通用的,只是es天然支持水平扩容。
1、垂直扩容
买更牛逼的服务器,价钱没上限!!!而且瓶颈还会存在。比如你现在10T数据,磁盘满了,放不下了。现在业务数据总量能到达100T,那你再买个100T的磁盘?那你真有钱,100T满了咋办?
2、水平扩容
业界经常采用的方案,采购越来越多的10T服务器,性能比较一般,但是很多10T服务器组织在一起,就能构成强大的存储能力。(推荐。划算,还不会瓶颈)
3、例如
假设:3台服务器,每台容纳1T数据,马上数据量要增长到5T,这时候两个方案:
(1)垂直扩容:重新购置两台服务器,每台服务器的容量是2T,替换到老的两台服务器,那么现在是6台服务器的总容量就是1
* 1T + 2 * 2T = 5T
(2)水平扩容:重新购置两台服务器,每台服务器的容量是1T,直接加入到集群中去,那么现在是5台服务器,总容量就是5
* 1T = 5T。(业界几乎都采取这种方式。)
4、为什么说这个
ES天然支持shard负载均衡和自动集群发现机制,磁盘满了加同等配置的机器就行了,会自动发现集群以及自动负载均衡平分shard(数据在shard上)。
再次把上面的【三、负载均衡# 3、补充】里的内容拿出来。
问:3个shard,我4个node,这种情况会浪费一台node的性能嘛?
答:不完全正确,首先,primaryshard确实只会分配到3个node上,但是我们还有replica
shard呀,所以第4个node上会存replica shard进行提升吞吐量。并不会完全浪费掉。
六、容错性 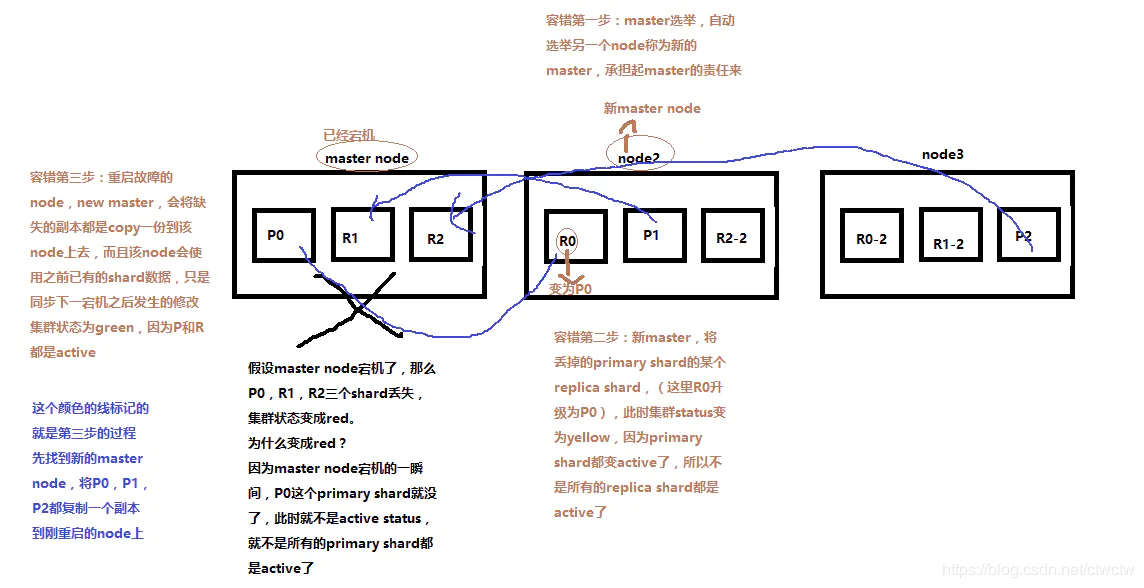
|









