| БрМЭЦМі: |
ЮФеТжївЊНщЩмСЫЖЈвхЃЌЪ§ОнПтКЭЪ§ОнВжПтЧјБ№вдМАAWSЪ§ОнКўМмЙЙЁЃЯЃЭћБОЮФЖдДѓМвгаАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂШЯЪЖЪ§ОнКў
1ЁЂГѕЪЖЪ§ОнКў
Data lakeЃЌЮвЕквЛДЮНгДЅетИіИХФюЃЌЪЧдк2014ФъIBMзщжЏЕФЪ§ОнжЮРэНЛСїТлЬГЩЯЁЃЕБЪБжЛЪЧШЯЮЊЁАЪ§ОнКўЁБОЭЪЧвЛИіИХФюЃЌУЛЪВУДаТвтЃЌЁАВЛОЭЪЧАбВЛЭЌНсЙЙЕФЪ§ОнЪЕЯжЭГвЛДцДЂЃЌHadoopВЛОЭЪЧИЩетИіЛюЕФТ№ЃПБОжЪЩЯЛЙЪЧЛЛЬРВЛЛЛвЉЁЂаТЦПзАРЯОЦЃЌгжвЛИіаТИХФюЁБЃЁ
2ЁЂЪ§ОнКўЕФЖЈвх
КѓРДЗЂЯжЃЌжїСїЕФДѓЪ§ОнКЭдЦМЦЫуЙЋЫОЖМдкЭЦетИіНаЁАЪ§ОнКўЁБЕФММЪѕЁЃгкЪЧЃЌЮвЬивтЩЯЭјАйЖШСЫвЛЯТЃЌЁАЪ§ОнКўЁБЕФИХФюдРДдчдк2011ФъБЛЪзДЮЬсГіЃЌЮЌЛљАйПЦЖдЫќИјГіСЫШчЯТЕФЖЈвхЃК
Ъ§ОнКўЃЈData LakeЃЉЪЧвЛИівддЪМИёЪНДцДЂЪ§ОнЕФДцДЂПтЛђЯЕЭГЃЌЫќАДдбљДцДЂЪ§ОнЃЌЖјЮоашЪТЯШЖдЪ§ОнНјааНсЙЙЛЏДІРэЁЃвЛИіЪ§ОнКўПЩвдДцДЂНсЙЙЛЏЪ§ОнЃЈШчЙиЯЕаЭЪ§ОнПтжаЕФБэЃЉЃЌАыНсЙЙЛЏЪ§ОнЃЈШчCSVЁЂШежОЁЂXMLЁЂJSONЃЉЃЌЗЧНсЙЙЛЏЪ§ОнЃЈШчЕчзггЪМўЁЂЮФЕЕЁЂPDFЃЉКЭЖўНјжЦЪ§ОнЃЈШчЭМаЮЁЂвєЦЕЁЂЪгЦЕЃЉЁЃ
бЧТэбЗAWSЖдЪ§ОнКўзіСЫНјвЛВННтЪЭЃКЁАЪ§ОнКўЪЧвЛИіМЏжаЪНДцДЂПтЃЌдЪаэФњвдШЮвтЙцФЃДцДЂЫљгаНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнЁЃФњПЩвдАДдбљДцДЂЪ§ОнЃЈЮоашЯШЖдЪ§ОнНјааНсЙЙЛЏДІРэЃЉЃЌВЂдЫааВЛЭЌРраЭЕФЗжЮі
ЈC ДгПижЦУцАхКЭПЩЪгЛЏЕНДѓЪ§ОнДІРэЁЂЪЕЪБЗжЮіКЭЛњЦїбЇЯАЃЌвджИЕМзіГіИќКУЕФОіВпЁЃЁБ
етЪБЃЌЮвЖдЁАЪ§ОнКўЁБгаСЫИќЩювЛВНЕФШЯжЊЃКЪ§ОнКўММЪѕЪЧВЛЖЯЗЂеЙЕФЃЌЫќПЩвдвдИќЗНБуЁЂИќСЎМлЕФЗНЪННтОіВЛЭЌРраЭЪ§ОнНсЙЙЕФЭГвЛДцДЂЮЪЬтЃЌЭЌЪБЛЙФмЙЛЮЊЛњЦїбЇЯАЬсЙЉШЋОжЪ§ОнЁЃЮвУЧПЩвдНЋЁАЪ§ОнКўЁБРэНтЮЊвЛИіШкКЯСЫДѓЪ§ОнМЏГЩЁЂДцДЂЁЂДІРэЁЂЛњЦїбЇЯАЁЂЪ§ОнЭкОђЁЂЪ§ОнПЩЪгЛЏЕШММЪѕЃЌДйНјЪ§ОнМлжЕБфЯжЕФЭъећНтОіЗНАИЁЃ
3ЁЂЪ§ОнКўгыЪ§ОнВжПтЕФЧјБ№
ЬИЕНЁАЪ§ОнКўЁБШЫУЧзмЪЧЯВЛЖгУЪ§ОнВжПтгыЦфНјааБШНЯЃЈПЩФмЪЧДгИХФюКЭгУЭОЩЯРДНВЫћУЧШЗЪЕгааЉЯрЫЦЃЉЃЌвдЯТЪЧAWSИјГіЕФЪ§ОнВжПтКЭЪ§ОнКўЕФЖдБШЃК
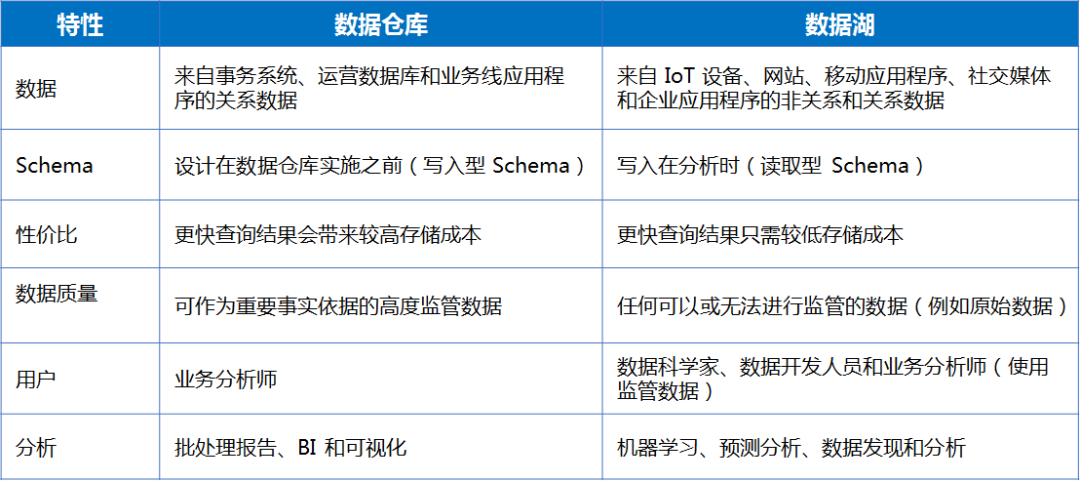
ЭЈЙ§ЩЯБэЃЌЮвУЧВЛФбЗЂЯжЁАЪ§ОнКўЁБгазХЪ§ОнВжПтЮоЗЈБШФтЕФгХЪЦЃК
ЪзЯШЃЌдкЪ§ОнДІРэКЭДцДЂФмСІЗНУцЃЌЪ§ОнКўПЩвдДІРэНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЕФЫљгаЪ§ОнНсЙЙЕФЪ§ОнЃЌЖјЪ§ОнВжПтжЛФмДІРэНсЙЙЛЏЪ§ОнЁЃ
Ъ§ОнВжПтдкДІРэЪ§ОнжЎЧАвЊЯШНјааЪ§ОнЪсРэЁЂЖЈвхЪ§ОнНсЙЙЁЂНјааЪ§ОнЧхЯДВХНјааШыПтВйзїЃЌЖјЪ§ОнКўЪЧВЛЙмЁАШ§ЦпЖўЪЎвЛЁБСЌЩЯЪ§ОндДОЭФмНЋдЪМЪ§ОнЁАвЛЙјЖЫЙ§РДЁБЃЌетОЭЮЊКѓајЪ§ОнКўЕФЛњЦїбЇЯАЁЂЪ§ОнЭкОђДјРДСЫЮоЯоПЩФмЃЁ
ЦфДЮЃЌдкЪ§ОнжЪСПКЭАВШЋЗНУцЃЌЪ§ОнВжПтзїгУЗЖЮЇгаЯоЃЌЫќжЛФмгУгкЪеМЏЁЂДІРэКЭЗжЮіЬиЖЈвЕЮёЮЪЬтЫљБиашЕФЪ§ОнЃЌЖјЪ§ОнКўШДФмЖдШЮКЮЪ§ОнЃЌЩѕжСЮоЗЈМрЙмЕФдЪМЪ§ОнЪЕЪЉЪ§ОнжЮРэЃЌвдЬсЩ§Ъ§ОнжЪСПКЭАВШЋадЁЃ
зюКѓЃЌдкСщЛюадЩЯЪ§ОнКўОпБИЬьШЛгХЪЦЁЃДЋЭГЕФЪ§ВжЃЌвђЮЊФЃаЭЗЖЪНЕФвЊЧѓЃЌвЕЮёВЛФмЫцБуЕФБфЧЈЃЌетЩцМАЕНЕзВуЪ§ОнЕФИїжжБфЛЏЃЌетЕМжТСЫДЋЭГЪ§ВжЮоЗЈжЇГжвЕЮёЕФБфЛЏЁЃЖдгкЪ§ОнКўРДЫЕЃЌМДЪЙЯёЛЅСЊЭјаавЕВЛЖЯгааТЕФгІгУЃЌвЕЮёВЛЖЯЗЂЩњБфЛЏЃЌЪ§ОнФЃаЭвВВЛЖЯЕФБфЛЏЃЌЕЋЪ§ОнвРШЛПЩвдЗЧГЃШнвзЕФНјШыЪ§ОнКўЃЌЖдгкЪ§ОнЕФВЩМЏЁЂЧхЯДЁЂЙцЗЖЛЏЕФДІРэЃЌЭъШЋПЩвдбгГйЕНвЕЮёашЧѓЕФЪБКђдйРДДІРэЁЃетИњдчЦкЕФЪ§ВжЫМЮЌОЭКмВЛвЛбљЃЌЪ§ОнКўЯрЖдгкЦѓвЕРДЫЕЃЌСщЛюадБШНЯЧПЃЌФмИќПьЫйЕФЪЪгІЧАЖЫгІгУЕФБфЛЏЁЃ
ЖўЁЂAWSЪ§ОнКўМмЙЙ
бЧТэбЗAWSЫуЪЧЁАЪ§ОнКўЁБММЪѕЕФБЧзцСЫЃЌдчдк2006Фъ3дТЃЌбЧТэбЗОЭЭЦГіСЫШЋЧђЪзПюЙЋгадЦЗўЮёAmazon
S3ЃЌЦфЧПДѓЕФЪ§ОнДцДЂФмСІЃЌЕьЖЈСЫAWSЪ§ОнКўСьЕМЕиЮЛЕФЛљДЁЁЃ
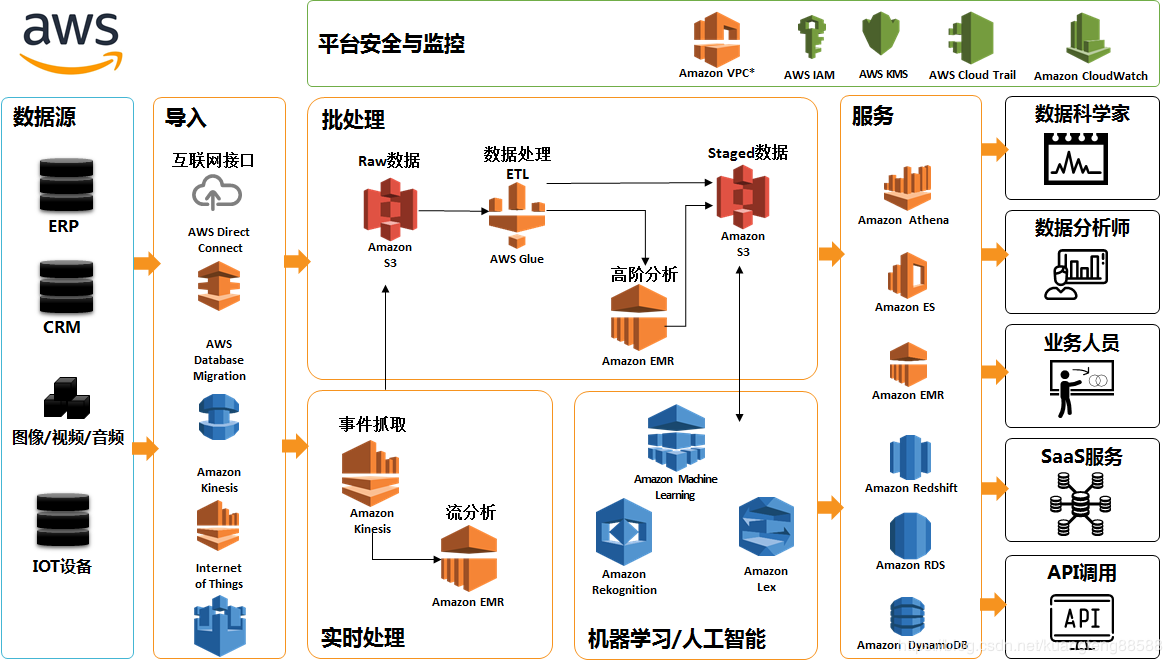
ЩЯЭМЪЧAWSЪ§ОнКўЕФвЛИіЕфаЭМмЙЙЃЌЮвУЧПДЕНЪ§ОнКўВЂВЛЪЧвЛИіВњЦЗЁЂвВВЛЪЧвЛЯюММЪѕЃЌЖјЪЧгЩЖрИіДѓЪ§ОнзщМўЁЂдЦЗўЮёзщГЩЕФвЛИіНтОіЗНАИЁЃ
ЕБШЛЃЌзюКЫаФЕФзщМўЪЧAmazon S3ЃЌЫќПЩвдДцДЂЖўНјЮЛЮЊЛљДЁЕФШЮКЮаХЯЂЃЌАќКЌНсЙЙЛЏКЭЗЧНсЙЙЛЏЕФЪ§ОнЃЌР§ШчЃКЦѓвЕаХЯЂЯЕЭГERPЁЂCRMЕШЯЕЭГжаЕФЙиЯЕаЭЪ§ОнЃЌДгЪжЛњЁЂЩуЯёЛњРДЕФееЦЌЁЂвєЪгЦЕЮФМўЃЌДгЦћГЕЩЯЁЂЗчСІЗЂЕчЛњЕШИїжжЩшБИРДЕФЪ§ОнЮФМўЕШЕШЁЃ
Ъ§ОндДСЌНгЃЌAWS ЬсЙЉСЫвЛИіНаAWS GlueВњЦЗЃЌGlueЪЧНКЫЎЕФвтЫМЃЌжЇГжВЛЭЌЕФЪ§ОнПтЗўЮёжЎМфЕФСЌНгЁЃGlueжївЊгаСНИіЙІФмЃЌвЛИіЪЧETLЃЌМДЃЌЪ§ОнЕФГщШЁЁЂзЊЛЛКЭМгдиЁЃСэвЛИіЙІФмЃЌЪЧЪ§ОнФПТМЗўЮёЕФЙІФмЃЌвђЮЊАбетаЉЪ§ОнЖМДцдкЪ§ОнКўРяУцЃЌдкетИіЙ§ГЬжаЃЌвЊЖдетаЉЪ§ОнДђЩЯБъЧЉЃЌАбЫќзіЗжРрЕФЙЄзїЁЃGlueОЭЯёХРГцвЛбљЖдЪ§ОнКўРяЕФКЃСПЪ§ОнЃЌНјааздЖЏХРШЁЃЌЩњГЩЪ§ОнФПТМЕФЙІФмЁЃ
ДѓЪ§ОнДІРэЃЌAWSЪ§ОнКўПЩвдЗжЮЊШ§ИіНзЖЮЖдЪ§ОнНјааДІРэЁЃЕквЛНзЖЮХњДІРэЃКЭЈЙ§АбИїжжРраЭЕФдЪМЪ§ОнМгдиЕНAmazon
S3ЩЯЃЌШЛКѓЭЈЙ§AWS GlueЖдЪ§ОнКўжаЕФЪ§ОнНјааЪ§ОнДІРэЃЌвВПЩвдЪЙгУAmazon EMRНјааЪ§ОнЕФИпМЖДІРэЗжЮіЁЃЕкЖўНзЖЮСїДІРэКЭЗжЮіЃЌетИіШЮЮёЪЧЛљгкAmazon
EMRЁЂAmazon KinesisРДЭъГЩЕФЁЃЕкШ§НзЮЊЛњЦїбЇЯАЃЌЪ§ОнЭЈЙ§ Amazon Machine
LearningЁЂAmazon LexЁЂAmazon RekognitionНјааЩюЖШМгЙЄЃЌаЮГЩПЩРћгУЕФЪ§ОнЗўЮёЁЃ
Ъ§ОнЗўЮёЃКAWSЪ§ОнКўПЩЮЊВЛЭЌНЧЩЋЕФгУЛЇЬсЙЉВЛЭЌЕФЪ§ОнЗўЮёЃЌЪ§ОнПЦбЇМвПЩвдЛљгкЪ§ОнКўНјааЪ§ОнЬНЫїКЭЪ§ОнЭкОђЃЌЪ§ОнЗжЮіЪІПЩвдЛљгкЪ§ОнНјааЪ§ОнНЈФЃЁЂЪ§ОнЗжЮіЕШЃЛвЕЮёШЫдБПЩвдВщбЏЁЂфЏРРЪ§ОнЗжЮіЪІЕФЗжЮіНсЙћЃЌвВЛљгкЪ§ОнФПТМзджњЪННјааЪ§ОнЗжЮіЁЃЛљгкЪ§ОнКўПЩвдПЊЗЂИїРрSaaSгІгУЃЌЭЌЪБЪ§ОнКўЬсЙЉЪ§ОнПЊЗХФмСІЃЌжЇГжНЋЪ§ОнвдAPIНгПкЕФаЮЪНПЊЗХГіШЅвдЙЉЭтВПгІгУЕїгУЁЃ
АВШЋгыдЫЮЌЃКгЩгкAWSЪ§ОнКўдЫаадкдЦЖЫЃЌЪ§ОнАВШЋШЫУЧЙизЂЕФжиЕуЁЃбЧТэбЗЕФAmazon VPCЮЊдЦЖЫЪ§ОнКўЬсЙЉСЫЙмРэКЭМрПиЙІФмЃЌ
VPC жЇГжжИЖЈ IP ЕижЗЗЖЮЇЁЂЬэМгзгЭјЁЂЙиСЊАВШЋзщвдМАХфжУТЗгЩБэЃЌAWS IAMЁЂAWS KMSЮЊЪ§ОнКўЕФАВШЋБЃМнЛЄКНЃЌЮЊЙЙНЈГівЛИіАВШЋЕФдЦЪ§ОнКўЬсЙЉжЇГХЁЃ
Ш§ЁЂШчКЮЙЙНЈЪ§ОнКў
Ъ§ОнКўДгММЪѕВуУцвВЪЧвЛИіДѓЪ§ОнЦНЬЈЃЌДЋЭГЩЯДюНЈвЛИіМЏЪ§ОнДцДЂЁЂЪ§ОнДІРэЁЂЛњЦїбЇЯАЁЂЪ§ОнЗжЮіЕШгІгУЮЊвЛЬхЕФДѓЪ§ОнЦНЬЈашвЊЪЎМИИіЩѕжСМИЪЎИіДѓЪ§ОнзщМўЃЌЭЌЪБЛЙашвЊЮЊЯрЙизщМўЙЙНЈМЏШКЃЌвдТњзуДѓХњСПЪ§ОнДІРэЁЂМЦЫуКЭДцДЂЕФашвЊЁЃетИіЙ§ГЬЭљЭљЪЧЗЧГЃИДдгЕФЃЌПЩФмашвЊЪ§дТВХФмЭъГЩЁЃ
2018ФъЃЌAWS ЭЦГіСЫLakeFormationЃЌОнЫЕЪЧПЩвдАяжњЦѓвЕдкМИЬьФкОЭФмЙЙНЈГіАВШЋЕФЪ§ОнКўЁЃЦкД§КмПьдкЙњФкЭЦГіЃЌЮвЖМЯыШЅВтЪдвЛАбСЫЃЁ
КУСЫЃЌЯТУцЮвУЧЬИвЛЬИЛљгкAWSЪ§ОнЗўЮёзщМўЃЌЕНЕзИУШчКЮЙЙНЈГівЛИіЁАЪ§ОнКўЁБЃПAWSЙйЭјжаИјГіЁАЪ§ОнКўЁБДгДДНЈЕНгІгУЕФЮхИіВНжшЃЌШчЯТЭМЫљЪОЃК
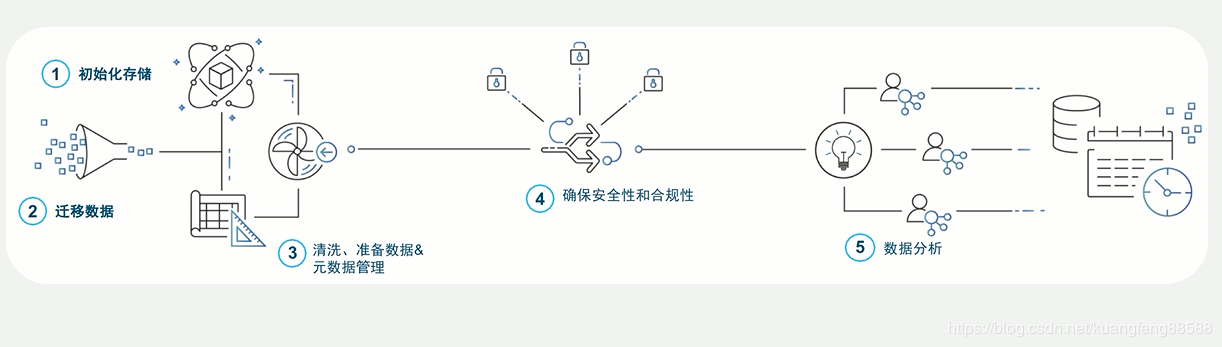
БЪепНЋетЮхИіВНжшЙщФЩЮЊЁАНЈКўЁЂОлЪ§ЁЂжЮЪ§ЁЂгУЪ§ЁБАЫИізжЃКНЈКўМДГѕЪМЛЏДцДЂЃЌОлЪ§МДЧЈвЦЪ§ОнЃЌжЮЪ§МДЪ§ОнЧхЯДЁЂЪ§ОнзМБИЁЂдЊЪ§ОнЙмРэЁЂЪ§ОнАВШЋКЭКЯЙцадЙмРэЃЌгУЪ§МДЪ§ОнЗжЮіЁЂЪ§ОнЗўЮёЁЃ
1ЁЂНЈКў--ЯаЭЅаХВНжўЪ§Кў
ЪзЯШЃЌЛљгкAWS IdentityЁЂIAMЗўЮёДДНЈЪ§ОнКўдЫааЙЄзїСїЕФЫљашЕФЙмРэдБКЭШЈЯоВпТдЫљашЕФНЧЩЋЃЌМДЃКЮЊЪ§ОнКўДДНЈЙмРэдБКЭжИЖЈгУЛЇзщЁЃ
ШЛКѓЃЌзЂВсЪ§ОнКўЃЌжИЖЈЪ§ОнКўДцДЂжааФAmazon S3ЕФТЗОЖЃЌВЂЩшжУЁАЪ§ОнКўЁБШЈЯоЃЌвддЪаэЦфЫћШЫЙмРэЁАЪ§ОнФПТМЁБКЭЪ§ОнКўжаЕФЪ§ОнЁЃ
зюКѓЃЌЩшжУAmazon AthenaвдБуВщбЏЕМШыЕНAmazon S3Ъ§ОнКўжаЕФЪ§ОнЁЃ
жСДЫЃЌвЛИіМђЕЅЕФЪ§ОнКўОЭЙЙНЈЭъГЩСЫЁЃЕБШЛВЛЭЌЕФгІгУГЁОАЯТЮвУЧЛЙашвЊЩшжУВЛЭЌЗўЮёЃЌЖдгкЯЃЭћАбДцЗХдкЪ§ОнКўКЭRedshiftЪ§ОнВжПтжаЕФЪ§ОнзіНЛВцШкКЯЗжЮіЕФгУЛЇЃЌПЩвдЭЈЙ§ЩшжУAmazon
Redshift SpectrumЃЌЪЙЕУRedshiftПЩвдВщбЏДцДЂдкAmazon S3жаЕФЪ§ОнЃЌДгЖјЪЕЯжЪ§ОнВжПтгыЪ§ОнКўЕФЪ§ОнШкКЯЗжЮіЁЃ
2ЁЂОлЪ§--АйЬѕДѓДЈжеЙщКЃ
ЫцзХДѓЪ§ОнЪБДњЕФЕНРДЃЌЦѓвЕЪ§ОнСПЕФУїЯдМЄдіЃЌИїжжИїбљЕФЪ§ОнЦЬЬьИЧЕиЖјРДЁЃгаРДздЦѓвЕФкВПаХЯЂЯЕЭГЕФЪ§ОнЃЌР§ШчЃКERPЯЕЭГЁЂCRMЯЕЭГЕШЃЌОЙ§ЖрФъЕФГСЕэЃЌЦѓвЕЛ§РлЕФДѓСПЕФРњЪЗЪ§ОнЃЌЪЧЦѓвЕЪ§ОнЗжЮіЕФжївЊРДдДЁЃгаРДздгкИїжжIoTЩшБИВњЩњЕФЪЕЪБЪ§ОнЃЌЖјЧветаЉЪ§ОнГЃвдЛьКЯЪ§ОнИёЪНЩњГЩЕФЃЌАќРЈНсЙЙЛЏЪ§ОнЁЂАыНсЙЙЛЏЪ§ОнКЭЗЧНсЙЙЛЏЪ§ОнЁЃгаРДздЦѓвЕЕФЛЅСЊЭјЪ§ОнЃЌАќРЈЛЅСЊЭјвЕЮёВњЩњЕФЪ§ОнЃЌвдМАЭЈЙ§ЭјвГХРГцВЩМЏЕФЦфЫћЭјеОЕФЪ§ОнЁЁЃЌетаЉаТЕФДѓЙцФЃЕФКЃСПЕФЪ§ОнЃЌВЛНіСПДѓЁЂжжРрЗБЖрЃЌЖјЧвРДЕФгжЗЧГЃУЭЃЌгЬШчЁАКщЫЎУЭЪоЁБЁЃ
AWSЮЊЪЕЯжВЛЭЌЪ§ОнРраЭЪ§ОнЕФЪ§ОнВЩМЏЁЂДІРэЬсЙЉСЫЖржжЙЄОпЃЌР§ШчЃКAWS GlueЁЂDatabase
MigrationЁЂKinesisЁЂInternet of ThingsЕШЃЌжЇГжНЋИїжжРраЭЕФЪ§ОнЧсЫЩЧЈвЦжСAmazon
S3жаНјааЭГвЛЙмРэЁЃетИіЙ§ГЬЃЌОЭе§КУЯёОЭЯёЁАЪ§ОнКўЁБзжУцКЌвхЃЌЮвУЧОЭеввЛДѓЦЌЪЊЕиЃЈS3ЃЉЃЌШЛКѓетаЉЯёКщЫЎвЛбљРДздЁАЫФУцАЫЗНЁБЕФЪ§ОнЯШаюдкетИіКўРяУцЃЌаЮГЩЪ§ОнЁААйДЈЙщКЃЁБжЎЪЦЃЌШЛКѓдкРћгУвЛаЉЙЄОпРДЖдЫќНјаажЮРэЁЂВщбЏКЭЗжЮіЁЃ
3ЁЂжЮЪ§--ЪшДЈЕМжЭАДашСї
Ъ§ОнКўгазХзПдНЕФЪ§ОнДцДЂФмСІЃЌжЇГжДѓСПЕФЁЂЖржжРраЭЕФДѓЪ§ОнЭГвЛДцДЂЁЃШЛЖјЃЌЦѓвЕЕФвЕЮёЪЧЪЕЪБдкБфЛЏЕФЃЌетДњБэзХГСЛ§дкЪ§ОнКўжаЕФЪ§ОнЖЈвхЁЂЪ§ОнИёЪНЪЕЪБЖМдкЗЂЩњзХзЊБфЃЌШчЙћВЛМгвджЮРэЃЌЦѓвЕЕФЁАЪ§ОнКўЁБОЭгаПЩФмБфГЩЁАРЌЛјЁБЖбЛ§ЕФЁАЪ§ОнегдѓЁБЃЌЖјЮоЗЈжЇГХЦѓвЕЕФЪ§ОнЗжЮіКЭЪЙгУЁЃ
ЁАСїЫЎВЛИЏЃЌЛЇЪрВЛѓМЁБЃЌЮвУЧжЛгаШУЁАЪ§ОнКўЁБжаЕФЁАЫЎЁБСїЖЏЦ№РДЃЌВХПЩвдШУЁАЪ§ОнКўЁБВЛБфГЩЁАЪ§ОнегдѓЁБЁЃAWS
GlueЬсЙЉETLКЭЪ§ОнФПТМФмСІЃЌШУЪ§ОнДгЪ§ОндДЧЈвЦЙ§РДЕФЪБКђОЭФмзівЛЖЈЕФЪ§ОнзЊЛЛЃЌВЂаЮГЩЧхЮњЕФЪ§ОнФПТМЁЃAmazon
EMRЁЂAmazon GlueжЇГжЖдЪ§ОнКўжаЕФЪ§ОнЗжЧјгђЁЂЗжНзЖЮЕФНјааЧхЯДКЭДІРэЃЌНјвЛВНОЛЛЏКўжаЕФЁАЫЎдДЁБЁЃжЎКѓЃЌЪ§ОнЭЈЙ§
Amazon Machine LearningЁЂAmazon LexЁЂAmazon RekognitionНјааЩюЖШМгЙЄЃЌаЮГЩПЩРћгУЕФЪ§ОнЗўЮёЃЌетбљбЛЗЭљИДЃЌГжајЬсЩ§Ъ§ОнКўжаЕФЁАЫЎжЪЁБЁЃ
ЭЌЪБЃЌAmazon S3ЁЂDynamoDBЁЂRedshiftОпБИКмКУЕФЪ§ОнАВШЋЛњжЦЃЌЪ§ОнЕФДЋЪфКЭДцДЂЖМЪЧМгУмЕФЃЌМгУмУмдПжЛгаПЭЛЇздМКеЦЮеЃЌЗРжЙЪ§ОнаЙТЖДјРДЕФЗчЯеЁЃСэЭтЃЌЛЙгаAmazon
VPCАВШЋВпТдЁЂAWS IAMЁЂAWS KMSЕШАВШЋзщМўЮЊAWSЪ§ОнКўБЃМнЛЄКНЃЌЮЊЦѓвЕЪ§ОнЕФДцДЂЁЂДІРэЁЂЪЙгУЬсЙЉвЛИіАВШЋЁЂКЯЙцЕФЪ§ОнЛЗОГЁЃ
змжЎЃЌЭЈЙ§дкЪ§ОнКўЕФЩшМЦЁЂМгдиКЭЮЌЛЄЙ§ГЬжаМгШыЧПДѓЕФЪ§ОнДІРэЁЂдЊЪ§ОнЙмРэЁЂЪ§ОнжЪСПМьКЫКЭЪ§ОнАВШЋЕФЯрЙизщМўЃЌВЂгЩЫљгаетаЉСьгђЕФОбщЗсИЛЕФзЈвЕШЫдБЛ§МЋВЮгыЃЌПЩЯджјЬсИпЪ§ОнКўЕФМлжЕЁЃЗёдђЃЌФуЕФЪ§ОнКўПЩФмЛсБфГЩЪ§ОнегдѓЁЃ
4ЁЂгУЪ§--ЫЎЕНЧўГЩМлжЕді
Ъ§ОнКўЕФГіЯжЃЌзюГѕОЭЪЧЮЊСЫВЙГфЪ§ОнВжПтЕФШБЯнКЭВЛзуЃЌЮЊСЫНтОіЪ§ОнВжПтТўГЄЕФПЊЗЂжмЦкЃЌИпАКЕФПЊЗЂГЩБОЃЌЯИНкЪ§ОнЖЊЪЇЁЂаХЯЂЙТЕКЮоЗЈГЙЕзНтОіЁЂГіЯжЮЪЬтЮоЗЈеце§ЫндДЕШЮЪЬтЁЃЕЋЪЧЫцзХДѓЪ§ОнММЪѕЕФЗЂеЙЃЌЪ§ОнКўВЛЖЯбнБфЃЌЛуМЏСЫИїжжММЪѕЃЌАќРЈЪ§ОнВжПтЁЂЪЕЪБКЭИпЫйЪ§ОнСїММЪѕЁЂЛњЦїбЇЯАЁЂЗжВМЪНДцДЂКЭЦфЫћММЪѕЁЃЪ§ОнКўж№НЅЗЂеЙГЩЮЊвЛИіПЩвдДцДЂЫљгаНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнЃЌЖдЪ§ОнНјааДѓЪ§ОнДІРэЁЂЪЕЪБЗжЮіКЭЛњЦїбЇЯАЕШВйзїЕФЭГвЛЪ§ОнЙмРэЦНЬЈЃЌЮЊЦѓвЕЬсЙЉЪ§ОнЁАВЩМЏЁЂДцДЂЁЂжЮРэЁЂЗжЮіЁЂЭкОђЁЂЗўЮёЁБЕФЭъећНтОіЗНАИЃЌДгЖјЪЕЯжЁАЫЎЕНЧўГЩЁБЕФЪ§ОнМлжЕЖДВьЁЃ
AWS ЬсЙЉСЫдкЪ§ОнКўЩЯдЫааЕФзюЙуЗКЁЂзюОпГЩБОаЇвцЕФЗжЮіЗўЮёМЏКЯЃЌУПЯюЗжЮіЗўЮёЖМзЈУХЮЊЙуЗКЕФЗжЮігУР§ЖјЙЙНЈЃК
РћгУAmazon AthenaЃЌЪЙгУБъзМ SQL жБНгВщбЏДцДЂдкS3жаЕФЪ§ОнЃЌЪЕЯжНЛЛЅЪНЗжЮіЃЛ
РћгУAmazon EMRТњзуЖдЪЙгУSparkКЭHadoopПђМмЕФДѓЪ§ОнДІРэЃЌAmazon EMR ЬсЙЉСЫвЛжжЭаЙмЗўЮёЃЌПЩвдЧсЫЩЁЂПьЫйЧвОМУИпаЇЕиДІРэКЃСПЪ§ОнЃЛ
РћгУAmazon Redshift ПЩПьЫйЙЙНЈPBМЖНсЙЙЛЏЪ§ОндЫааЁЂИДдгЗжЮіВщбЏЙІФмЕФЪ§ОнВжПтЃЛ
РћгУAmazon KinesisЃЌЧсЫЩЪеМЏЁЂДІРэКЭЗжЮіЪЕЪБЕФСїЪ§ОнЃЌШч IoT вЃВтЪ§ОнЁЂгІгУГЬађШежОКЭЭјеОЕуЛїСїЃЛ
РћгУAmazonQuickSightЧсЫЩЙЙНЈПЩДгШЮКЮфЏРРЦїЛђвЦЖЏЩшБИЗУЮЪЕФОЋжТПЩЪгЛЏаЇЙћКЭФкШнЗсИЛЕФПижЦУцАхЃЛ
ЭЌЪБЃЌAWS ЬсЙЉСЫвЛЯЕСаЙуЗКЕФЛњЦїбЇЯАЗўЮёКЭЙЄОпЃЌжЇГждкAWSЪ§ОнКўЩЯдЫааЛњЦїбЇЯАЫуЗЈЃЌЩюЖШЭкОђЪ§ОнМлжЕЁЃ
етаЉЙЄОпКЭЗўЮёЃЌФмЙЛЮЊВЛЭЌНЧЩЋЕФгУЛЇЃЌР§ШчЪ§ОнПЦбЇМвЁЂЪ§ОнЗжЮіЪІЁЂвЕЮёШЫдБЁЂЪ§ОнЙмРэдБЕШЬсЙЉЧПДѓЕФЙІФмжЇГжЃЌДгЖјАяжњЦѓвЕЪЕЯжвдЁАЪ§ОнЮЊЧ§ЖЏЁБЕФЪ§зжЛЏзЊаЭЁЃ
ЫФЁЂзмНс
ДЋЭГаХЯЂЯЕЭГЪЧгЩСїГЬЧ§ЖЏЕФЃЌЦѓвЕЕФЫљгавЕЮёЖМЪЧЮЇШЦзХСїГЬЖјНјааЕФЃЌетИіНзЖЮЪ§ОнВЂУЛгав§Ц№ШЫУЧЕФжиЪгЁЃЕНСЫЪ§ОнВжПтНзЖЮЃЌЦѓвЕЖдЪ§ОнЕФгІгУвВНіЪЧДІгкИЈжњВуУцЃЌЦѓвЕЕФЙмРэОіВпЁЂвЕЮёДДаТжївЊЛЙЪЧППШЫЕФОбщЃЌЪ§ОнжЛЪЧвЛИіВЮПМЁЃЕЋЫцзХЪ§зжЛЏЪБДњЕФРДСйЃЌДѓЪ§ОнММЪѕВЛЖЯЕФЩюШыгІгУЃЌШЫУЧЗЂЯжДѓЪ§ОнЕФЮЪЬтЗЂЯжФмСІЁЂдЄВтФмСІвЊдЖдЖГЌЙ§ШЫУЧЕФОбщЁЃдНРДдНЖрЕФЦѓвЕбЁдёЛљгкЪ§ОнНјааЦѓвЕЕФОгЊОіВпЃЌЛљгкЪ§ОнЬсЩ§зщжЏМЈаЇЃЌЛљгкЪ§ОнзіВњЦЗЕФДДаТЁЃЦѓвЕе§дкДгЁАСїГЬЧ§ЖЏЁБЕФаХЯЂЛЏЪБДњЃЌзпЯђЁАЪ§ОнЧ§ЖЏЁБЕФЪ§зжЛЏЪБДњЁЃ
ЁАЪ§ОнКўЁБЪЧгІЪБДњЖјЩњЕФвЛИіВњЮяЃЌЫќЕФМлжЕВЛНідкгкПЩвдНЋКЃСПЕФЁЂВЛЭЌРраЭЕФЪ§ОнНјааЭГвЛДцДЂЃЌВЂЬсЙЉЪ§ОнФПТМКЭВщбЏЗўЮёЁЃЪ§зжЛЏЕФЪБДњЃЌЪ§ОнИќМгДѓСПЁЂИќМгЪЕЪБЁЂИќМгУцЯђЮДРДЃЌЛњЦїбЇЯАЁЂШЫЙЄжЧФмГЩЮЊвЛИіЦѓвЕЪ§зжЛЏзЊаЭЕФЙиМќадвђЫиЁЃЪ§ОнКўжЇГжКЃСПЕФЁЂЪЕЪБЕФЪ§ОнДІРэКЭЗжЮіЃЌЩѕжСетжжЪ§ОнДІРэгыЗжЮіЖМВЛашвЊдЄЖЈвхЪ§ОнФЃаЭЃЌдіЧПСЫЪ§ОнЕФЖДВьФмСІЃЌЫќЪЙЕУетаЉКЃСПЪ§ОнЕФМлжЕОЭИќМгБШвдЧАгаЫљЬсИпЃЌАяжњШЫУЧдкОжВПЕФЪ§ОнРяУцевЕНИќЖрЕФЙцТЩЁЃПЩвдЫЕЁАЪ§ОнКўЁБМђжБЪЧЮЊЁАЛњЦїбЇЯАЁБЖјЩњЁЃ
гааЇЕФРћгУЁАЪ§ОнКўЁБЃЌГфЗжЕФЭкОђЪ§ОнЧБдкМлжЕЃЌФмАяжњЦѓвЕИќКУЕФЯИЗжЪаГЁЃЌвджњгкЦѓвЕФмгаеыЖдадЕФЮЊЦѓвЕЗЂеЙЬсЙЉОіВпжЇГХЃЌИќКУЕФеЦЮеЪаГЁЖЏЯђЃЌИќКУЕФЖдЪаГЁЗДгІВњЩњаТЕФЖДМћЃЌИќКУЕФЩшМЦЙцЛЎЛђИФНјВњЦЗЃЌИќКУЕФЮЊПЭЛЇЬсЙЉЗўЮёЁЃДгЖјЃЌЬсЩ§ЦѓвЕЕФОКељСІЃЌЩѕжСДДаТЦѓвЕЕФЩЬвЕФЃЪНЃЁ
|









