| БрМЭЦМі: |
БОЮФЪзЯШЖдЪ§ОнЪЧЪВУДЃЌгХЪЦЃЌЙЙНЈЗНЗЈЃЌlamdaМмЙЙЙЙНЈЪ§ОнКў
ЕШЕШЯрЙиЃЌИќЖрЧыПДЯТЮФЁЃ
БОЮФРДздЮЂаХЙЋжкКХЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1.Ъ§ОнКўЕЎЩњ
Ъ§ОнКўИХФюЕФЕЎЩњЃЌдДздЦѓвЕУцСйЕФвЛаЉЬєеНЃЌШчЪ§ОнгІИУвдКЮжжЗНЪНДІРэКЭДцДЂЁЃзюПЊЪМЕФЪБКђЃЌУПИігІгУГЬађЛсВњЩњЁЂДцДЂДѓСПЪ§ОнЃЌЖјетаЉЪ§ОнВЂВЛФмБЛЦфЫћгІгУГЬађЪЙгУЃЌетжжзДПіЕМжТЪ§ОнЙТЕКЕФВњЩњЁЃЫцКѓЪ§ОнМЏЪагІдЫЖјЩњЃЌгІгУГЬађВњЩњЕФЪ§ОнДцДЂдквЛИіМЏжаЪНЕФЪ§ОнВжПтжаЃЌПЩИљОнашвЊЕМГіЯрЙиЪ§ОнДЋЪфИјЦѓвЕФкашвЊИУЪ§ОнЕФВПУХЛђИіШЫЁЃШЛЖјЪ§ОнМЏЪажЛНтОіСЫВПЗжЮЪЬтЁЃЪЃгрЮЪЬтЃЌАќРЈЪ§ОнЙмРэЁЂЪ§ОнЫљгаШЈгыЗУЮЪПижЦЕШЖМиНаыНтОіЃЌвђЮЊЦѓвЕбАЧѓЛёЕУИќИпЕФЪЙгУгааЇЪ§ОнЕФФмСІЁЃЮЊСЫНтОіЧАУцЬсМАЕФИїжжЮЪЬтЃЌЦѓвЕгаКмЧПСвЕФЫпЧѓДюНЈздМКЕФЪ§ОнКўЃЌЪ§ОнКўВЛЕЋФмДцДЂДЋЭГРраЭЪ§ОнЃЌвВФмДцДЂШЮвтЦфЫћРраЭЪ§ОнЃЌВЂЧвФмдкЫќУЧжЎЩЯзіНјвЛВНЕФДІРэгыЗжЮіЃЌВњЩњзюжеЪфГіЙЉИїРрГЬађЯћЗбЁЃ
2.Ъ§ОнКўЖЈвхМАгХЪЦ
2.1 Ъ§ОнКўЕФЖЈвх
Ъ§ОнКўЪЧвЛИіДцДЂЦѓвЕЕФИїжжИїбљдЪМЪ§ОнЕФДѓаЭВжПтЃЌЦфжаЕФЪ§ОнПЩЙЉДцШЁЁЂДІРэЁЂЗжЮіМАДЋЪфЁЃ
Ъ§ОнКўДгЦѓвЕЕФЖрИіЪ§ОндДЛёШЁдЪМЪ§ОнЃЌВЂЧвеыЖдВЛЭЌЕФФПЕФЃЌЭЌвЛЗндЪМЪ§ОнЛЙПЩФмгаЖржжТњзуЬиЖЈФкВПФЃаЭИёЪНЕФЪ§ОнИББОЁЃвђДЫЃЌЪ§ОнКўжаБЛДІРэЕФЪ§ОнПЩФмЪЧШЮвтРраЭЕФаХЯЂЃЌДгНсЙЙЛЏЪ§ОнЕНЭъШЋЗЧНсЙЙЛЏЪ§ОнЁЃЦѓвЕЖдЪ§ОнКўМФгшКёЭћЃЌЯЃЭћЫќФмАяжњгУЛЇПьЫйЛёШЁгагУаХЯЂЃЌВЂФмНЋетаЉаХЯЂгУгкЪ§ОнЗжЮіКЭЛњЦїбЇЯАЫуЗЈЃЌвдЛёЕУгыЦѓвЕдЫааЯрЙиЕФЖДВьСІЁЃ
2.2 Ъ§ОнКўгХЪЦ
гаЩЯПЩжЊЪ§ОнКўИКд№ВЖЛёЪ§ОнЁЂДІРэЪ§ОнЁЂЗжЮіЪ§ОнЃЌвдМАЮЊЯћЗбепЯЕЭГЬсЙЉЪ§ОнЗўЮёЁЃ
Ъ§ОнКўФмДгвдЯТЗНУцАяжњЕНЦѓвЕЃК
ЁЄЪЕЯжЪ§ОнжЮРэЃЈdata governanceЃЉгыЪ§ОнЪРЯЕЁЃ
ЁЄЭЈЙ§гІгУЛњЦїбЇЯАгыШЫЙЄжЧФмММЪѕЪЕЯжЩЬвЕжЧФмЁЃ
ЁЄдЄВтЗжЮіЃЌШчСьгђЬиЖЈЕФЭЦМів§ЧцЁЃ
ЁЄаХЯЂзЗзйгывЛжТадБЃеЯЁЃ
ЁЄИљОнЖдРњЪЗЕФЗжЮіЩњГЩаТЕФЪ§ОнЮЌЖШЁЃ
ЁЄгавЛИіМЏжаЪНЕФФмДцДЂЫљгаЦѓвЕЪ§ОнЕФЪ§ОнжааФЃЌгаРћгкЪЕЯжвЛИіеыЖдЪ§ОнДЋЪфгХЛЏЕФЪ§ОнЗўЮёЁЃ
ЁЄАяжњзщжЏЛђЦѓвЕзіГіИќЖрСщЛюЕФЙигкЦѓвЕдіГЄЕФОіВпЁЃ
2.3 Ъ§ОнЩњУќжмЦк
ЪзЯШЃЌСЫНтвЛЯТЪ§ОнКўжаЪ§ОнЕФЩњУќжмЦкЃК
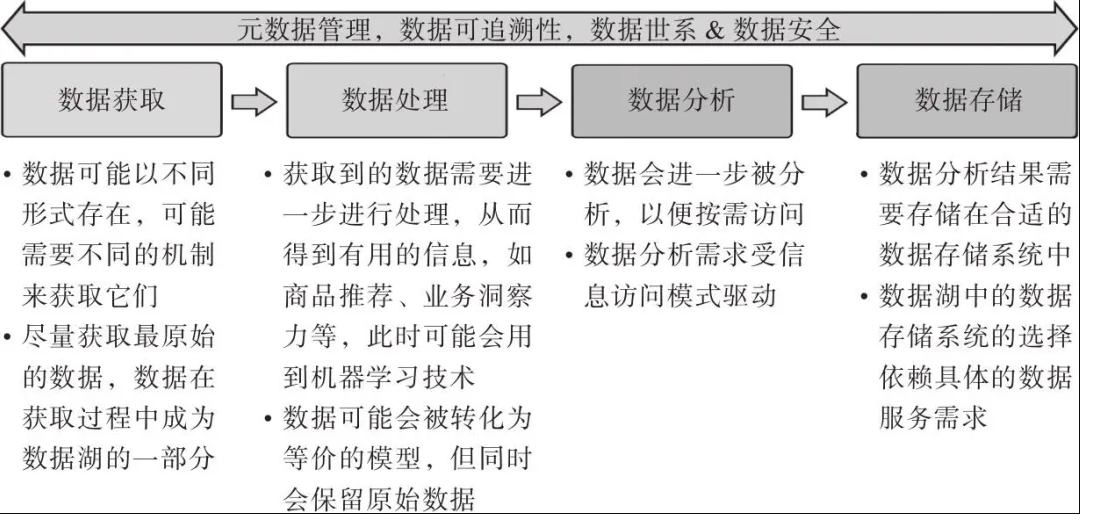
Ъ§ОнЩњУќжмЦк
Ъ§ОнКўжаЪ§ОнЕФећИіЩњУќжмЦкжаЃЌПЩвдДгдЊЪ§ОнЙмРэЃЌЪ§ОнЕФПЩзЗЫнадЃЌЪ§ОнЪРЯЕЃЌЪ§ОнАВШЋЕШМИИіЗНУцЖдЪ§ОнНјааЙмРэЁЃ
Ъ§ОнЪРЯЕБЛЖЈвхЮЊЪ§ОнЕФЩњУќжмЦкЃЌАќРЈЪ§ОнЕФЦ№дДвдМАЪ§ОнЪЧШчКЮЫцЪБМфвЦЖЏЕФЁЃЫќУшЪіСЫЪ§ОндкИїжжДІРэЙ§ГЬжаЗЂЩњСЫФФаЉБфЛЏЃЌгажњгкЬсЙЉЪ§ОнЗжЮіСїЫЎЯпЕФПЩМћадЃЌВЂМђЛЏСЫДэЮѓЫндДЁЃ
ПЩзЗЫнадЪЧЭЈЙ§БъЪЖМЧТМРДбщжЄЪ§ОнЯюЕФРњЪЗЁЂЮЛжУЛђгІгУЕФФмСІЁЃ
2.4 Ъ§ОнКўгыЪ§ОнВжПт
Ъ§ОнКўгыЪ§ОнВжПтЕФЧјБ№ЃЌШчЯТЭМЃК

Ъ§ОнКўгыЪ§ОнВжПтЕФЧјБ№

Ъ§ОнКўгыЪ§ОнВжПтЕФЧјБ№
ДгЧјБ№РДПДЃЌгІИУЪгЮЊЯрЛЅВЙГфЁЃ
2.5 Ъ§ОнКўЙЙНЈЗНЗЈ
ВЛЭЌЕФзщжЏгаВЛЭЌЕФЦЋКУЃЌвђДЫЫќУЧЙЙНЈЪ§ОнКўЕФЗНЪНвВВЛвЛбљЁЃЙЙНЈЗНЗЈгывЕЮёЁЂДІРэСїГЬМАЯжДцЯЕЭГЕШвђЫигаЙиЁЃ
МђЕЅЕФЪ§ОнКўЪЕЯжМИКѕЕШМлгкЖЈвхвЛИіжааФЪ§ОндДЃЌЫљгаЕФЯЕЭГЖМПЩвдЪЙгУетИіжааФЪ§ОндДРДТњзуЫљгаЕФЪ§ОнашЧѓЁЃЫфШЛетжжЗНЗЈПЩФмКмМђЕЅЃЌвВКмЛЎЫуЃЌЕЋЫќПЩФмВЛЪЧвЛИіЗЧГЃЪЕгУЕФЗНЗЈЃЌдвђШчЯТЃК
ЁЄжЛгаЕБетаЉзщжЏжиаТПЊЪМЙЙНЈЦфаХЯЂЯЕЭГЪБЃЌетжжЗНЗЈВХПЩааЁЃ
ЁЄетжжЗНЗЈНтОіВЛСЫгыЯжДцЯЕЭГЯрЙиЕФЮЪЬтЁЃ
ЁЄМДЪЙзщжЏОіЖЈгУетжжЗНЗЈЙЙНЈЪ§ОнКўЃЌвВШБЗІУїШЗЕФд№ШЮКЭЙизЂЕуИєРыЃЈresponsibility and
separation of concernsЃЉЁЃ
ЁЄетбљЕФЯЕЭГЭЈГЃГЂЪдвЛДЮадЭъГЩЫљгаЕФЙЄзїЃЌЕЋЪЧзюжеЛсЫцзХЪ§ОнЪТЮёЁЂЗжЮіКЭДІРэашЧѓЕФдіМгЖјЗжБРРыЮіЁЃ
ИќКУЕФЙЙНЈЪ§ОнКўЕФВпТдЪЧНЋЦѓвЕМАЦфаХЯЂЯЕЭГзїЮЊвЛИіећЬхРДПДД§ЃЌЖдЪ§ОнгЕгаЙиЯЕНјааЗжРрЃЌЖЈвхЭГвЛЕФЦѓвЕФЃаЭЁЃетжжЗНЗЈЫфШЛПЩФмДцдкСїГЬЯрЙиЕФЬєеНЃЌВЂЧвПЩФмашвЊЛЈЗбИќЖрЕФОЋСІРДЖдЯЕЭГдЊЫиНјааЖЈвхЃЌЕЋЪЧЫќШдШЛФмЙЛЬсЙЉЫљашЕФСщЛюадЁЂПижЦКЭЧхЮњЕФЪ§ОнЖЈвхвдМАЦѓвЕжаВЛЭЌЯЕЭГЪЕЬхжЎМфЕФЙизЂЕуИєРыЁЃетбљЕФЪ§ОнКўвВПЩвдгаЖРСЂЕФЛњжЦРДВЖЛёЁЂДІРэЁЂЗжЮіЪ§ОнЃЌВЂЮЊЯћЗбепгІгУГЬађЬсЙЉЪ§ОнЗўЮёЁЃ
3. lamdaМмЙЙЙЙНЈЪ§ОнКў
ЯТЭМИјГіСЫвЛИіЪ§ОнКўЕФЙІФмФЃПщЃЌЮвУЧгЩДЫеЙПЊа№ЪіЃК
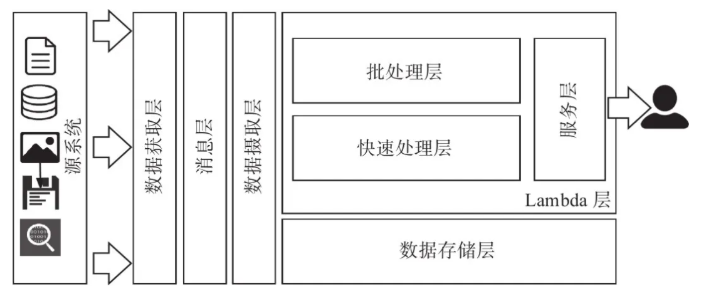
Ъ§ОнКўжаЕФЙІФмФЃПщ
3.1 Ъ§ОнЛёШЁВу
Ъ§ОнЛёШЁВуЦфЪЕОЭЪЧЪ§ОнВЩМЏВуЁЃ
ЦѓвЕжаЪ§ОнИёЪНЖржжЖрбљЃЌПЩДѓжТЗжЮЊНсЙЙЛЏЪ§ОнЁЂАыНсЙЙЛЏЪ§ОнКЭЗЧНсЙЙЛЏЪ§ОнЁЃ
НсЙЙЛЏЪ§ОнЕФГЃМћР§згАќРЈЙиЯЕЪ§ОнПтЁЂXML/JSONЁЂЯЕЭГМфДЋЕнЕФЯћЯЂЕШЁЃЦѓвЕвВЗЧГЃЧрэљАыНсЙЙЛЏЪ§ОнЃЌгШЦфЪЧE-MailЁЂСФЬьМЧТМЁЂЮФЕЕЕШЁЃЗЧНсЙЙЛЏЪ§ОнЕФЕфаЭР§згАќРЈЭМЦЌЁЂЪгЦЕЁЂдЪМЮФБОЁЂвєЦЕЮФМўЕШЁЃ
ЖдгкетаЉРраЭЕФЪ§ОнЃЌВПЗжЪ§ОнПЩФмЮоЗЈЖдЦфЖЈвхФЃЪНЃЈschemaЃЉЁЃашвЊНЋЪ§ОнзЊЛЛЮЊгавтвхЕФаХЯЂЪБЃЌФЃЪНЪЧЗЧГЃживЊЕФЁЃЮЊНсЙЙЛЏЪ§ОнЖЈвхФЃЪНЕФЗНЗЈЗЧГЃжБНгЃЌЕЋЪЧЮоЗЈЮЊАыНсЙЙЛЏЪ§ОнЛђЗЧНсЙЙЛЏЪ§ОнЖЈвхФЃЪНЁЃ
Ъ§ОнЛёШЁВуЕФвЛИіЙиМќзїгУЪЧНЋЪ§ОнзЊЛЛЮЊдкЪ§ОнКўжаПЩНјааКѓајДІРэЕФЯћЯЂЁЃвђДЫЪ§ОнЛёШЁВуБиаыЗЧГЃСщЛюЃЌФмЪЪгІЖржжЪ§ОнФЃЪНЁЃЭЌЪБЃЌЫќвВБиаыжЇГжПьЫйЕФСЌНгЛњжЦЃЌЮоЗьЕиЭЦЫЭЫљгазЊЛЛЙ§ЕФЪ§ОнЯћЯЂЕНЪ§ОнКўжаШЅЁЃ
Ъ§ОнЛёШЁВудкЪ§ОнЛёШЁЖЫгЩЖрТЗСЌНгЃЈmulti-connectorЃЉзщМўЙЙГЩЃЌШЛКѓНЋЪ§ОнЭЦЫЭЕНЬиЖЈЕФФПЕФЕиЁЃдкЪ§ОнКўЕФР§згжаЃЌФПЕФЕижИЕФЪЧЯћЯЂВуЃЌШчЯТЭМЫљЪОЃК
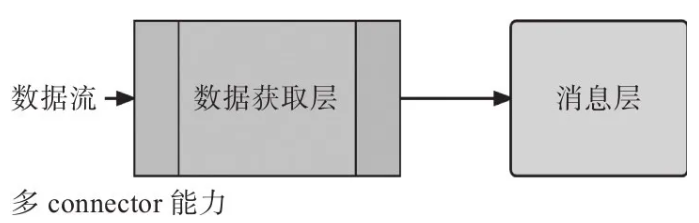
Ъ§ОнЛёШЁзщМў
КмЖрММЪѕПђМмПЩвдгУгкЙЙНЈФмжЇГжЖржждДЯЕЭГЕФЕЭбгГйЕФЪ§ОнЛёШЁВуЁЃЖдгкУПжждДЯЕЭГРраЭЃЌЪ§ОнЛёШЁВуЕФСЌНгЖМашвЊИљОнЫљвРРЕЕФЕзВуПђМмНјааЬиЪтХфжУЁЃЪ§ОнЛёШЁВуЛсЖдвбЛёШЁЕФЪ§ОнзіЩйСПзЊЛЛЃЌЦфФПЕФЪЧзюаЁЛЏДЋЪфбгГйЁЃетРяЕФЪ§ОнзЊЛЛжИЕФЪЧНЋвбЛёШЁЕФЪ§ОнзЊЛЛЮЊЯћЯЂЛђЪТМўЃЌЫќУЧПЩвдЗЂЫЭИјЯћЯЂВуЁЃ
ШчЙћЯћЯЂВуЮоЗЈЕНДяЃЈгЩгкЭјТчжаЖЯЛђЯћЯЂВуДІгкЭЃЛњЦкМфЃЉЃЌдђЪ§ОнЛёШЁВуЛЙБиаыЬсЙЉЫљашЕФАВШЋадБЃеЯКЭЙЪеЯЛжИДЛњжЦЁЃ
ЮЊСЫШЗБЃИУВуЕФАВШЋадЃЌЫќгІИУФмЙЛжЇГжБОЕиГжОУЛЏЕФЯћЯЂЛКГхЃЌетбљЃЌШчЙћашвЊЃЌВЂЧвЕБЯћЯЂВудйДЮПЩгУЪБЃЌЯћЯЂПЩвдДгБОЕиЛКГхЧјжаЛжИДЁЃИУФЃПщЛЙгІИУжЇГжЙЪеЯзЊвЦЃЌШчЙћЦфжавЛИіЪ§ОнЛёШЁНјГЬЪЇАмЃЌСэвЛИіНјГЬНЋЮоЗьНгЙмЃЌШчЯТЭМЫљЪОЁЃ
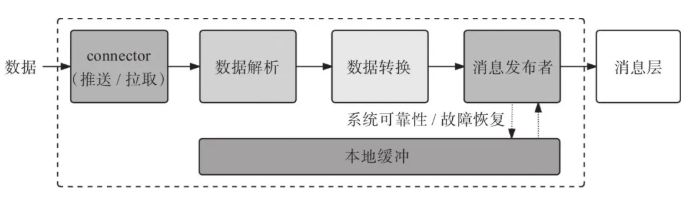
Ъ§ОнЛёШЁВуЕФзщМў
3.2 ЯћЯЂВу
ЯћЯЂВуЦфЪЕОЭЪЧЪ§ОнКўМмЙЙРяЕФЯћЯЂжаМфМўЃЌИУВуЕФжївЊзїгУЪЧШУЪ§ОнКўИїВузщМўжЎМфНтёюЃЌЭЌЪББЃжЄЯћЯЂДЋЕнЕФАВШЋадЁЃ
ЮЊСЫШЗБЃЯћЯЂФмБЛе§ШЗДЋЪфЕНФПЕФЕиЃЌЯћЯЂНЋЛсБЛГжОУЛЏЕНФГжжДцДЂЩшБИжаШЅЁЃБЛбЁгУЕФДцДЂЩшБИашвЊгыЯћЯЂДІРэашЧѓЦЅХфЃЈНсКЯЯћЯЂДѓаЁМАЪ§СПЕШвђЫиЃЉЁЃИќНјвЛВНРДПДЃЌВЛТлЪЧЖСВйзїЛЙЪЧаДВйзїЃЌЯћЯЂжаМфМўЖМЪЧАДЖгСаЃЈqueueЃЉЗНЪНРДДІРэЕФЃЌЖгСаЬьШЛЪЪКЯДІРэДЎааДцШЁЃЌЛњаЕгВХЬзувдгІИЖДЫРрI/OВйзїЁЃЖдгкФЧаЉашвЊУПУыДІРэАйЭђМЖЕФЯћЯЂЕФДѓаЭгІгУГЬађРДЫЕЃЌSSDФмЬсЙЉИќКУЕФI/OадФмЁЃ
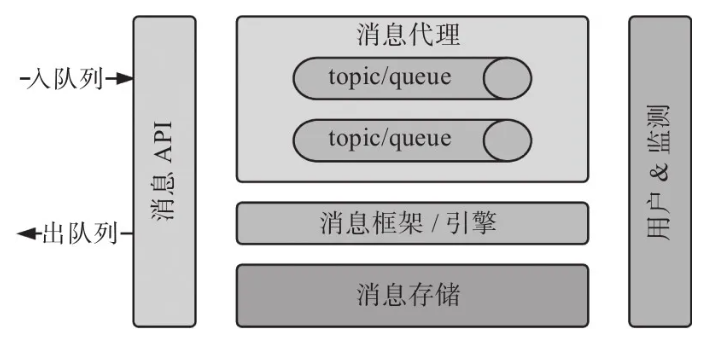
ЯћЯЂВузщМўБиаыФмЖдЯћЯЂЖгСаНјааШыЖгСаКЭГіЖгСаВйзїЃЌШчЭМ2-5ЫљЪОЁЃЖдгкДѓЖрЪ§ЯћЯЂДІРэПђМмРДЫЕЃЌШыЖгСаКЭГіЖгСаВйзїЖдгІЕФЪЧЯћЯЂЗЂВМгыЯћЯЂЯћЗбЁЃУПИіЯћЯЂДІРэПђМмЖМЬсЙЉСЫвЛЯЕСаПтКЏЪ§ЃЌгУгкгыЯћЯЂЖгСаЕФзЪдДСЌНгЃЈШчtopic/queueЃЉЁЃ

ЯћЯЂЖгСа
ШЮвтЯћЯЂжаМфМўЖМжЇГжСНРргыЖгСаЭЈаХЕФЗНЪНвдМАtopicЯћЯЂНсЙЙЃЌШчЯТЫљСаЃК
ЁЄЖгСаЭЈГЃгУгкЕуЖдЕуЃЈpoint-to-pointЃЉЭЈаХЃЌУПИіЯћЯЂгІИУжЛБЛФГИіЯћЗбепЯћЗбвЛДЮЁЃ
ЁЄtopicИХФюОГЃГіЯжгкЗЂВМ/ЖЉдФЛњжЦжаЃЌдкетРяЃЌвЛИіЯћЯЂБЛЗЂВМвЛДЮЃЌЕЋЪЧБЛЖрИіЖЉдФепЃЈЯћЗбепЃЉЯћЗбЁЃвЛЬѕЯћЯЂЛсБЛЖрДЮЯћЗбЃЌЕЋЪЧУПИіЯћЗбепЯћЗбвЛДЮЁЃдкЯћЯЂЯЕЭГФкВПЃЌtopicЛљгкЖгСаРДЙЙНЈЃЛЯћЯЂв§ЧцЃЈmessage
engineЃЉЖдетаЉЖгСаНјааВювьЛЏЙмРэЃЌвдЪЕЯжвЛИіЗЂВМ/ЖЉдФЛњжЦЁЃ
ЖгСагыtopicЖМПЩвдИљОнашвЊХфжУЮЊГжОУЛЏЛђЗЧГжОУЛЏЁЃГігкБЃеЯЪ§ОнЗЂВМАВШЋЕФФПЕФЃЌЧПСвНЈвщНЋЖгСаХфжУЮЊГжОУЛЏЃЌетбљЯћЯЂНЋВЛЛсЖЊЪЇЁЃ
ДгНЯИпЕФВуДЮРДПДЃЌЯћЯЂжаМфМўПЩвдГщЯѓЮЊгЩЯћЯЂДњРэЃЈmessage brokerЃЉЁЂЯћЯЂДцДЂЁЂtopic/queueЕШзщМўзщГЩЕФПђМмЛђв§ЧцЁЃ
ЯТЭМДгНЯИпЕФГщЯѓНЧЖШУшЪіСЫЃЌЯћЯЂЖгСаЕФФкВПФЃПщЃК
ЯћЯЂЖгСаЕФФкВПФЃПщ
ГЃМћбЁаЭЪЧkafkaЃЌrmqЃЌpulsarЕШ
3.3 Ъ§ОнЩуШЁВу
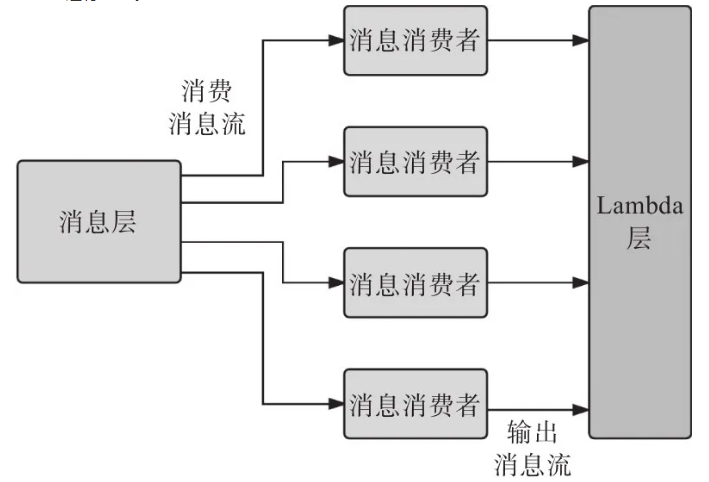
Ъ§ОнЩуШЁВуИКд№ЯћЗбЯћЯЂВужаЕФЯћЯЂЃЌЖдЯћЯЂзіЪЪЕБЕФзЊЛЛЃЌДгжаЬсШЁЫљЦкЭћЕФаХЯЂЃЌШЛКѓДЋЪфИјLambdaВуЙЉЦфДІРэЁЃЪ§ОнЩуШЁВуЕФЪфГіБиаыгыЦкЭћЕФЪ§ОнДцДЂЛђДІРэИёЪНвЛжТЁЃИУВувВБиаыБЃжЄЯћЯЂвдвЛжТадЕФЗНЪНЯћЗбЕєЃЌМДУЛгаЯћЯЂЖЊЪЇВЂЧвУПЬѕЯћЯЂжСЩйБЛЯћЗбвЛДЮЁЃ
Ъ§ОнЩуШЁВуБЛЦкЭћФмжЇГжЖрИіЯћЗбеп/ЯпГЬРДВЂааЯћЗбЯћЯЂЁЃУПИіЯћЗбепБиаыЪЧЮозДЬЌЕФЃЌВЂЧвФмПьЫйДІРэСїЪНЪ§ОнЁЃДгЯћЯЂВуЕМГіЕФЖрИіЪ§ОнСїжаЕФЪ§ОнЛсдДдДВЛЖЯЕигПШыLambdaВуЁЃЪ§ОнЩуШЁВуБиаыШЗБЃЯћЯЂЯћЗбЫйЖШВЛЕЭгкЯћЯЂЩњГЩЫйЖШЃЌетбљЯћЯЂ/ЪТМўДІРэОЭВЛЛсгабгГйЁЃНЯТ§ЕФДІРэЫйЖШЛсЕМжТЯћЯЂВужаЯћЯЂЕФЖбЛ§ЃЌЛсЖдЯЕЭГДІРэЯћЯЂ/ЪТМўЕФНќЪЕЪБЬиаддьГЩЩЫКІЁЃИУВугІжЇГжПьЫйЯћЗбВпТдЃЌдкБивЊЪБЛжИДвђЯћЯЂЖбЛ§ЖјЕМжТЕФЯЕЭГЙЪеЯЁЃ
вђДЫЃЌИУВугавЛИівўКЌЕФвЊЧѓЃЌМДетвЛВуашвЊвЛжББЃГжНќЪЕЪБадЃЌОпгазюаЁбгГйЃЌетбљЯћЯЂВуОЭВЛЛсЖбЛ§ШЮКЮЯћЯЂЁЃЮЊСЫБЃеЯНќЪЕЪБадЃЌИУВуБиаыгаФмСІГжајЕиЯћЗбЯћЯЂ/ЪТМўЃЌМАЖдЙЪеЯНјааЛжИДЁЃ
ЯћЯЂЯћЗбеп
ЯћЯЂЯћЗбепАчбнСЫЯђLambdaВуЕнЫЭЯћЯЂЙЉЦфДІРэЕФЙиМќНЧЩЋЃЌШчЩЯЭМЫљЪОЃЌвђДЫЯћЯЂЯћЗбепЕФФкВПзщМўгыЪ§ОнЛёШЁВуЗЧГЃЯрЫЦЃЌВюБ№дкгкЯћЯЂЯћЗбепжЊЕРДгЯћЯЂВуЃЈдДЃЉЛёШЁЕФЯћЯЂМАЗЂЫЭжСLambdaВуЃЈФПЕФЕиЃЉЕФЯћЯЂЕФИёЪНЁЃЯћЯЂЕФЯћЗбааЮЊПЩФмЪЧвдЮЂХњСПЃЈmicro-batchesЃЉЗНЪНРДДІРэЃЌетбљФмЪЕЯжзЪдДЕФзюгХРћгУЃЌЪЙЯЕЭГаЇТЪИќИпЁЃ
ДЫДІЃЌЮЊСЫНтёюЃЌРЫМтОѕЕУдкЪ§ОнЩуШЁВуКЭlambdaжЎМфгІИУдйМгвЛВуЯћЯЂЖгСаЁЃ
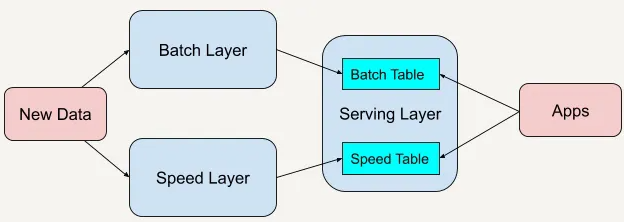
3.4 lambdaМмЙЙ
ЩуШЁВуКѓОЭЪЧРыЯпДІРэКЭЪЕЪБДІРэзщГЩЕФlambdaМмЙЙЁЃ
lambdaМмЙЙЭМ-ЭјТч
1).РыЯпДІРэ
ХњДІРэВуЃЈbatch layerЃЉЪЧLambdaМмЙЙжаЖдвбЬсШЁЪ§ОнНјааХњСПДІРэЕФВуЃЌвдШЗБЃЯЕЭГзЪдДЕФзюМбРћгУЃЌЭЌЪБвВПЩНЋГЄЪБМфдЫааЕФВйзїгІгУгкЪ§ОнЃЌвдШЗБЃЪфГіЪ§ОнЕФИпжЪСПЁЃЪфГіЪ§ОнвВГЦЮЊФЃаЭЪ§ОнЃЈmodeled
dataЃЉЁЃНЋдЪМЪ§ОнзЊЛЛЮЊФЃаЭЪ§ОнЪЧХњДІРэВуЕФжївЊжАд№ЃЌЦфжаЃЌФЃаЭЪ§ОнжадЬКЌСЫLambdaМмЙЙжаЗўЮёВуЃЈserving
layerЃЉЯђЭтЬсЙЉЪ§ОнЕФЪ§ОнФЃаЭЁЃИУВужївЊжАд№ШчЯТЫљСаЃК
ЁЄИУВуБиаыФмдквбЩуШЁЕФдЪМЪ§ОнжЎЩЯжДааЪ§ОнЧхРэЁЂЪ§ОнДІРэЁЂЪ§ОнНЈФЃЫуЗЈЁЃ
ЁЄИУВуБиаыЬсЙЉжиаТжДааЃЈreplay/rerunЃЉФГаЉВйзїЕФЛњжЦЃЌвдЪЕЯжЙЪеЯЛжИДЁЃ
ЁЄИУВуБиаыжЇГждквбЩуШЁЕФдЪМЪ§ОнжЎЩЯжДааЛњЦїбЇЯАЫуЗЈЛђЪ§ОнПЦбЇДІРэЃЌвдВњЩњИпжЪСПЕФФЃаЭЪ§ОнЁЃ
ЁЄИУВуПЩФмашвЊжДаавЛаЉЦфЫћВйзїЃЌвдЦкЭЈЙ§вЦГ§жиИДЪ§ОнЁЂМьВтДэЮѓЪ§ОнКЭЬсЙЉЪ§ОнЪРЯЕЪгЭМРДЬсИпФЃаЭЪ§ОнЕФећЬхжЪСПЁЃ
етВуГЃМћЕФДІРэМмЙЙОЭЪЧЃКmapreduceЃЌspark coreЃЌspark sqlЕШЁЃ
2).ЪЕЪБДІРэ
НќЪЕЪБДІРэВуЃЈspeed layerЃЉНЋЖдДгЪ§ОнЩуШЁВуНгЪеЕФЪ§ОнжДааНќЪЕЪБДІРэЁЃгЩгкДІРэдЄЦкНгНќЪЕЪБЃЌвђДЫетаЉЪ§ОнЕФДІРэашвЊПьЫйЁЂИпаЇЃЌЮЊИпВЂЗЂГЁОАЬсЙЉжЇГжКЭЯргІЕФОЋаФЩшМЦЃЌВЂЧвзюжеВњЩњТњзувЛжТадвЊЧѓЕФЪфГіНсЙћЁЃКмЖрвђЫиПЩвдгАЯьПьЫйДІРэВуЕФЬиадЃЌетаЉНЋдкБОЪщЕФКѓУцВПЗжЯъЯИЬжТлЁЃМђЕЅРДЫЕЃЌИУВугІАќКЌвдЯТЙІФмЃК
ЁЄБиаыжЇГждкЬиЖЈЪ§ОнСїжЎЩЯЕФПьЫйВйзїЁЃ
ЁЄБиаыФмЩњГЩТњзуНќЪЕЪБДІРэашЧѓЕФЪ§ОнФЃаЭЁЃЫљгаашвЊГЄЪБМфдЫааЕФДІРэБиаыБЛЮЏЭаИјХњДІРэФЃЪНЁЃ
ЁЄБиаыгаПьЫйЗУЮЪФмСІКЭДцДЂВуЕФжЇГжЃЌетбљОЭВЛЛсвђЮЊДІРэФмСІЖјЕМжТЪТМўЕФЖбЛ§ЁЃ
ЁЄБиаыгыЪ§ОнЩуШЁВуЕФХњДІРэЙ§ГЬЗжРыЁЃ
ФПЧАГЃгУЕФЪЕЪБДІРэЛђепНќЪЕЪБДІРэЗНАИЪЧЃКflinkЃЌspark streamingЁЃ
ЦфЪЕЃЌгыжЎЯрЖдЕФЛЙгавЛИіkappaМмЙЙЃЌКѓУцРЫМтЛсМЬајНщЩмЁЃ
3.5 ДцДЂВу
дкLambdaМмЙЙФЃЪНжаЃЌЪ§ОнДцДЂВуЃЈdata storage layerЃЉЗЧГЃв§ШЫзЂФПЃЌвђЮЊИУВуЖЈвхСЫећИіНтОіЗНАИЖдДЋШыЪТМў/Ъ§ОнСїЕФЗДгІЁЃгЩМмЙЙГЃЪЖПЩжЊЃЌвЛИіЯЕЭГЕФЫйЖШзюЖргыДІРэСДжазюТ§ЕФзгЯЕЭГвЛбљПьЃЌвђДЫЃЌШчЙћДцДЂВуВЛЙЛПьЃЌгЩНќЪЕЪБДІРэВужДааЕФВйзїНЋЛсБфЕУКмТ§ЃЌДгЖјзшАСЫИУМмЙЙДяЕННќЪЕЪБЕФаЇЙћЁЃ
дкLambdaЕФзмЬхМмЙЙжаЃЌеыЖдвбЩуШЁЕФЪ§ОнгаСНжжжїЖЏВйзїЃКХњДІРэКЭНќЪЕЪБДІРэЁЃХњДІРэКЭНќЪЕЪБДІРэЕФЪ§ОнашЧѓВюБ№КмДѓЁЃР§ШчЃЌдкДѓЖрЪ§ЧщПіЯТЃЌХњДІРэФЃЪНашвЊжДааДЎааЖСКЭДЎаааДВйзїЃЌДЫЪБЪЙгУHadoopДцДЂВуОЭзуЙЛСЫЃЌЕЋЪЧШчЙћЮвУЧПМТЧНќЪЕЪБДІРэЃЌашвЊПьЫйВщевКЭПьЫйаДШыЃЌФЧУДHadoopДцДЂВуПЩФмЪЧВЛКЯЪЪЕФЃЈМћБэ2-2ЃЉЁЃЮЊСЫжЇГжНќЪЕЪБДІРэЃЌашвЊЪ§ОнВужЇГжФГаЉРраЭЕФЫїв§Ъ§ОнДцДЂЁЃ
Бэ2-2 HadoopДцДЂВуЖдХњДІРэКЭНќЪЕЪБДІРэФЃЪНЕФЪЪгУЧщПіЁЃ

ДцДЂВу
LambdaМмЙЙЕФЕфаЭЙІФмШчЯТЫљСаЃК
ЁЄЭЌЪБжЇГжДЎааЖСаДМАЫцЛњЖСаДЁЃ
ЁЄеыЖдгУЛЇЕФЪЙгУЧщПіЃЌЬсЙЉКЯЪЪЕФВуДЮадЕФНтОіЗНАИЁЃ
ЁЄжЇГжвдХњСПФЃЪНЛђНќЪЕЪБФЃЪНДІРэКЃСПЪ§ОнЁЃ
ЁЄвдСщЛюЁЂПЩРЉеЙЕФЗНЪНжЇГжЖржжЪ§ОнНсЙЙЕФДцДЂЁЃ
3.6 ЗўЮёВуЁЊЁЊЪ§ОнНЛИЖгыЕМГі
LambdaМмЙЙвВЧПЕїСЫЮЊЯћЗбепГЬађЬсЙЉЪ§ОнДЋЪфЗўЮёЕФживЊадЁЃжкЫљжмжЊЃЌЪ§ОнПЩвдвдЖржжЗНЪНдкЯЕЭГМфДЋЕнЁЃЦфжазюживЊЕФвЛжжЗНЪНЪЧЭЈЙ§ЗўЮёЃЈserviceЃЉДЋЕнЁЃдкЪ§ОнКўБГОАжаЃЌетаЉЗўЮёБЛГЦЮЊЪ§ОнЗўЮёЃЈdata
serviceЃЉЃЌвђЮЊЫќУЧЕФжївЊЙІФмЪЧДЋЪфЪ§ОнЁЃ
СэЭтвЛжжДЋЪфЪ§ОнЕФЗНЪНЪЧЪ§ОнЕМГіЃЈexportЃЉЁЃЪ§ОнзюжеПЩЕМГіЮЊЖржжИёЪНЃЌШчЯћЯЂЁЂЮФМўЁЂЪ§ОнБИЗнЕШЃЌЕМГіЕФЪ§ОнЙЉЦфЫћЯЕЭГЯћЗбЁЃ
Ъ§ОнДЋЪф/ЗўЮёжївЊЙизЂЕФЪЧШчКЮНЋЪ§ОнзЊЛЛЮЊдЄЦкЕФИёЪНЁЃетжжИёЪНПЩвдЧПжЦдМЖЈЮЊЪ§ОнЦѕдМЃЈdata contractЃЉЃЌЪ§ОнЗўЮёдкЖдЭтЬсЙЉЗўЮёЪБзёбИУдМЖЈЁЃШЛЖјЃЌдкжДааЪ§ОнДЋЪфВйзїЪБЃЌКЯВЂХњСПДІРэМАНќЪЕЪБДІРэВњЩњЕФЪ§ОнЗЧГЃживЊЃЌвђЮЊетСНРрЪ§ОнжаЖМПЩФмАќКЌгызщжЏЛњЙЙЯрЙиЕФЙиМќаХЯЂЁЃЪ§ОнЗўЮёВуБиаыБЃжЄЪ§ОнгыЪ§ОнЦѕдМЃЈгыЯћЗбепГЬађдМЖЈЃЉЕФвЛжТадЁЃ
ДгНЯИпЕФВуДЮРДПДЃЌЪ§ОнЗўЮёВугІТњзуЯТСаЬиадЃК
ЁЄжЇГжЖржжЛњжЦЮЊЯћЗбепГЬађЬсЙЉЪ§ОнЗўЮёЁЃ
ЁЄУПжжжЇГжЪ§ОнЗўЮёЕФЛњжЦЃЌБиаыгыЯћЗбепГЬађЕФЪ§ОнЦѕдММцШнЁЃ
ЁЄжЇГжХњСПДІРэМАНќЪЕЪБДІРэЪ§ОнЪгЭМЕФКЯВЂЁЃ
ЁЄЮЊЯћЗбепГЬађЬсЙЉПЩРЉеЙЁЂПьЫйЯьгІЕФЪ§ОнЗўЮёЁЃ
вђЮЊЪ§ОнЗўЮёВуЕФКЫаФжАд№ЪЧЯђЪ§ОнКўвдЭтЕФЯћЗбепЬсЙЉЪ§ОнЗўЮёЃЌГігкдіЧПЪ§ОнБэЯжЕФПМТЧЃЌИУВуПЩФмЛсбЁдёадЕиНјааЪ§ОнКЯВЂЁЃ
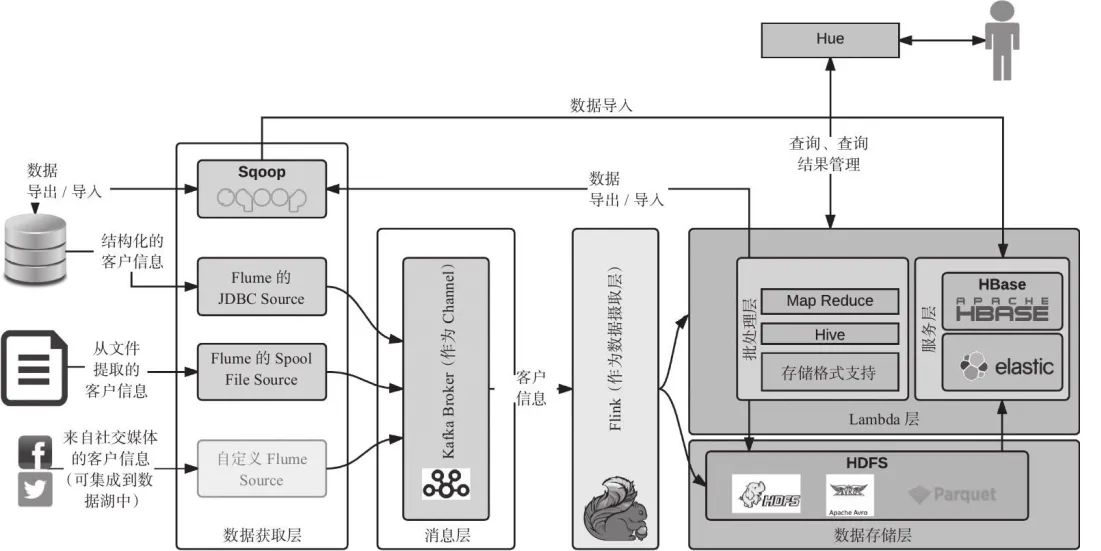
ЦѓвЕЪ§ОнКўЪЕЯжЕФЪ§ОнКўМмЙЙ
ДцДЂВуГЃгУЕФДцДЂМмЙЙЃКicebergЃЌhudiЃЌdeltaЃЌРЫМтКѓУцЪсРэИјГіИїИіМмЙЙЬиЕуМАШчКЮбЁдёЁЃ
|









