| БрМЭЦМі: |
БОЮФжївЊНщЩмkuduЪЧЪВУДЃЌkuduдРэМмЙЙЃЌЖСаДСїГЬЕШЕШЃЌИќЖрЧыПДЯТЮФЁЃ
БОЮФРДздcnblogsЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
1ЁЂkuduНщЩм
kudu ЖЈЮЛЪЧ ЁИFast Analytics on Fast DataЁЙЃЌЪЧвЛИіМШжЇГжЫцЛњЖСаДЁЂгжжЇГж
OLAP ЗжЮіЕФДѓЪ§ОнДцДЂв§ЧцЁЃ
дЪ§ОнДцДЂгкHDFSЛђHBaseЖМгагХШБЕуЃК
жБНгДцЗХгкHDFSжаЃЌЪЪКЯРыЯпЗжЮіЃЌШДВЛРћгкМЧТММЖБ№ЕФЫцЛњЖСаДЁЃ
жБНгНЋЪ§ОнДцЗХгкHBase/CassandraжаЃЌЪЪКЯМЧТММЖБ№ЕФЫцЛњЖСаДЃЌЖдРыЯпЗжЮіШДВЛгбКУЁЃ
2ЁЂkuduдРэМмЙЙ
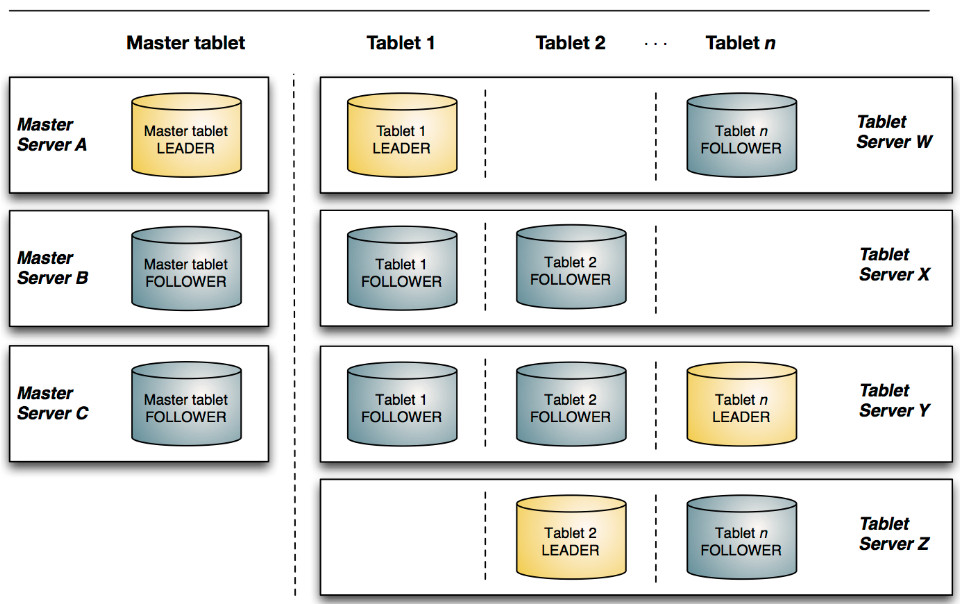
ВЩгУСЫMaster-SlaveаЮЪНЕФжааФНкЕуМмЙЙЃЌЙмРэНкЕуБЛГЦзї Master ServerЃЌЪ§ОнНкЕуБЛГЦзїTablet
ServerЃЈПЩЖдБШРэНтHBaseжаЕФRegionServerНЧЩЋЃЉЁЃ
Mater ServerЃКИКд№МЏШКЃЈTSЃЉЙмРэЁЂдЊЪ§ОнЙмРэЕШЙІФм
Tablet ServerЃКИКд№Ъ§ОнДцДЂЃЌВЂЬсЙЉЪ§ОнЖСаДЗўЮё
вЛИіБэЕФЪ§ОнЃЌБЛЗжИюГЩ1ИіЛђЖрИіTabletЃЌTabletБЛВПЪ№дкTablet ServerРДЬсЙЉЪ§ОнЖСаДЗўЮёЁЃ
Kudu MasterдкKuduМЏШКжаЃЌЗЂЛгШчЯТЕФвЛаЉзїгУЃК
гУРДДцЗХвЛаЉБэЕФSchemaаХЯЂЃЌЧвИКд№ДІРэНЈБэЕШЧыЧѓЁЃ
ИњзйЙмРэМЏШКжаЕФЫљгаЕФTablet ServerЃЌВЂЧвдкTablet ServerвьГЃжЎКѓаЕїЪ§ОнЕФжиВПЪ№ЁЃ
ДцЗХTabletЕНTablet ServerЕФВПЪ№аХЯЂЁЃ
tablets дк Kudu РяУцБЛЧаЗжГЩИќаЁЕФЕЅдЊ RowSetsЃК
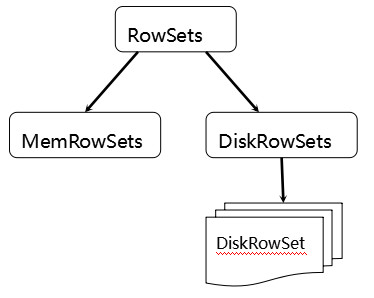
MemRowSetsПЩвдЖдБШРэНтГЩHBaseжаЕФMemStore, ЖјDiskRowSetsПЩРэНтГЩHBaseжаЕФHFileЁЃMemRowSetsжаЕФЪ§ОнАДееааЪдЭМНјааДцДЂЃЌЪ§ОнНсЙЙЮЊB-TreeЁЃMemRowSetsжаЕФЪ§ОнБЛFlushЕНДХХЬжЎКѓЃЌаЮГЩDiskRowSetsЁЃ
DiskRowSetжаЕФЪ§ОнАДееColumnНјаазщжЏЃЌгыParquetРрЫЦЁЃетЪЧKuduПЩжЇГжвЛаЉЗжЮіадВщбЏЕФЛљДЁЁЃ
вЛИіDiskRowSetАќКЌСНВПЗжЪ§ОнЃКЛљДЁЪ§Он(Base Data)ЃЌвдМАБфИќЪ§Он(Delta
Stores)ЁЃИќаТ/ЩОГ§ВйзїЫљЩњГЩЕФЪ§ОнМЧТМЃЌБЛБЃДцдкБфИќЪ§ОнВПЗжЁЃ
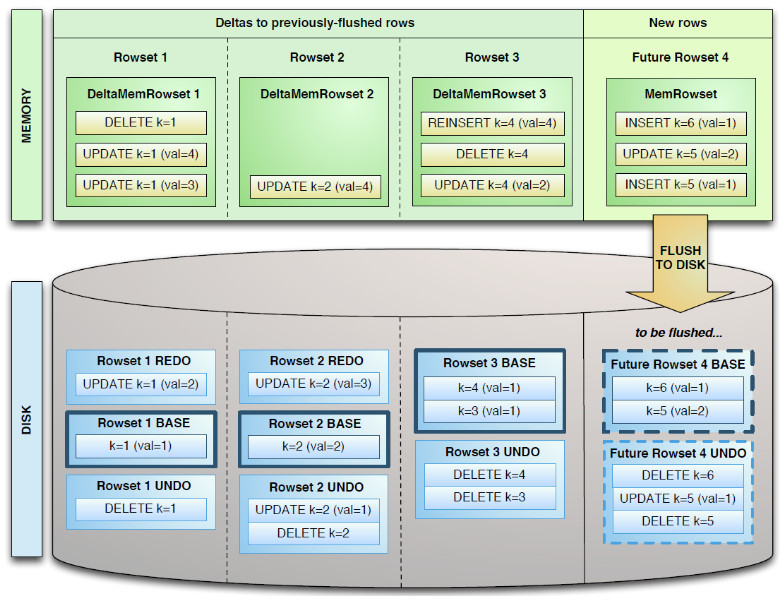
DeltaЪ§ОнВПЗжАќКЌREDOгыUNDOСНВПЗжЃК
REDO Delta FilesАќКЌСЫBase DataздЩЯвЛДЮБЛFlush/CompactionжЎКѓЕФБфИќжЕЁЃREDO
Delta FilesАДееTimestampЫГађХХСаЁЃ
UNDO Delta FilesАќКЌСЫBase DataздЩЯвЛДЮFlush/CompactionжЎЧАЕФБфИќжЕЁЃетбљВХПЩвдБЃеЯЛљгквЛИіОЩTimestampЕФВщбЏФмЙЛПДЕНвЛИівЛжТадЪгЭМЁЃUNDOАДееTimestampЕЙађХХСаЁЃ
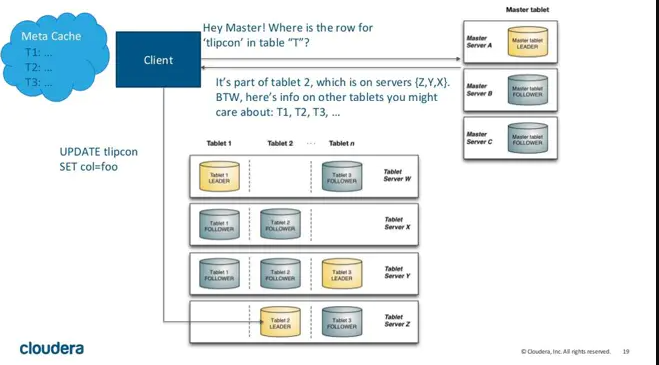
kudu client гы ЗўЮёЖЫНЛЛЅЃЌЯШДг Master Server
ЛёШЁдЊЪ§ОнаХЯЂЃЌШЛКѓШЅ Tablet Server ЖСаДЪ§ОнЃЌШчЯТЭМЃК
3ЁЂЖСаДСїГЬ
3.1ЁЂаДЪ§Он
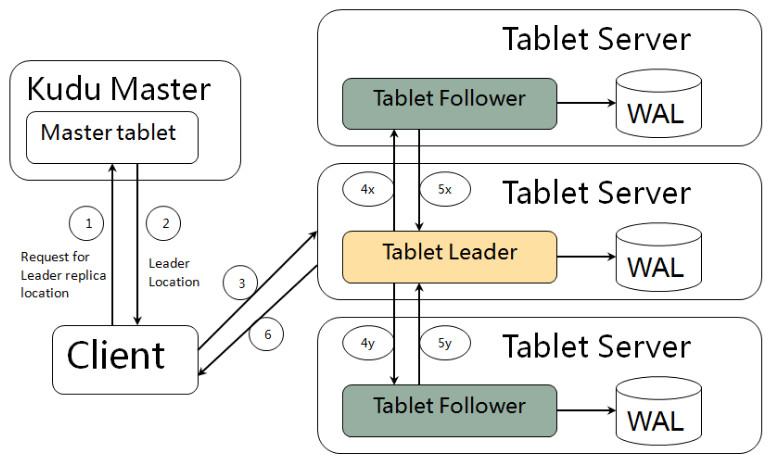
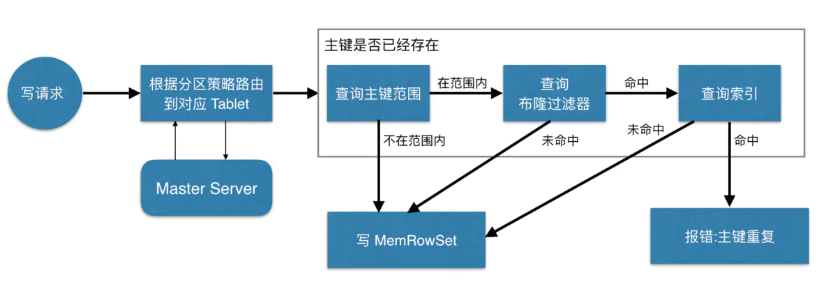
ЕБ Client ЧыЧѓаДЪ§ОнЪБЃЌЯШИљОнжїМќДг Mater Server жаЛёШЁвЊЗУЮЪЕФФПБъ TabletsЃЌШЛКѓЕНвРДЮЖдгІЕФ
Tablet ЛёШЁЪ§ОнЁЃвђЮЊ KUDU БэДцдкжїМќдМЪјЃЌЫљвдашвЊНјаажїМќЪЧЗёвбОДцдкЕФХаЖЯЃЌетРяОЭЩцМАЕНжЎЧАЫЕЕФЫїв§НсЙЙЖдЖСаДЕФгХЛЏСЫЁЃвЛИі
Tablet жаДцдкКмЖрИі RowSetsЃЌЮЊСЫЬсЩ§адФмЃЌЮвУЧвЊОЁПЩФмЕиМѕЩйвЊЩЈУшЕФ RowSets
Ъ§СПЁЃЪзЯШЃЌЮвУЧЯШЭЈЙ§УПИі RowSet жаМЧТМЕФжїМќЕФЃЈзюДѓзюаЁЃЉЗЖЮЇЃЌЙ§ТЫЕєвЛХњВЛДцдкФПБъжїМќЕФ
RowSetsЃЌШЛКѓдкИљОн RowSet жаЕФВМТЁЙ§ТЫЦїЃЌЙ§ТЫЕєШЗЖЈВЛДцдкФПБъжїМќЕФ RowSetsЃЌзюКѓдйЭЈЙ§
RowSets жаЕФ B-ЪїЫїв§ЃЌОЋШЗЖЈЮЛФПБъжїМќЪЧЗёДцдкЁЃШчЙћжїМќвбОДцдкЃЌдђБЈДэЃЈжїМќжиИДЃЉЃЌЗёдђОЭНјаааДЪ§ОнЃЈаД
MemRowSetЃЉЁЃ
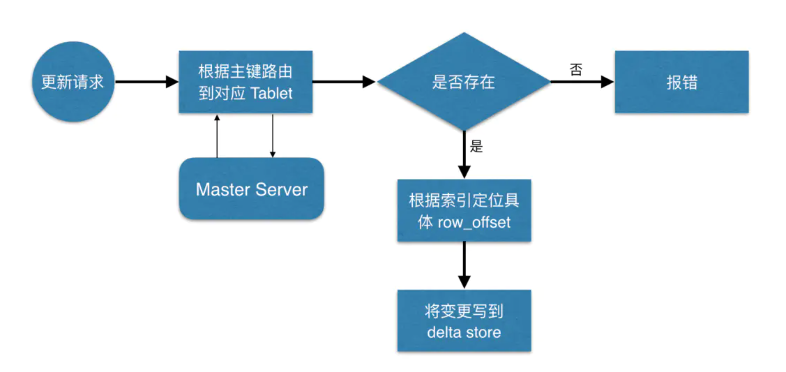
3.2ЁЂИќаТЪ§Он
ЖЈЮЛЕНОпЬхЮЛжУКѓЃЌШЛКѓНЋБфИќаДЕНЖдгІЕФ delta store жаЁЃ
3.3ЁЂЖСЪ§Он
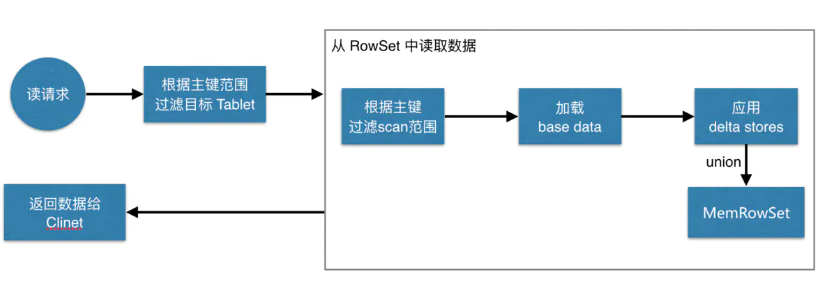
ЯШИљОнвЊЩЈУшЪ§ОнЕФжїМќЗЖЮЇЃЌЖЈЮЛЕНФПБъЕФ TabletsЃЌШЛКѓЖСШЁ Tablets жаЕФ RowSetsЁЃдкЖСШЁУПИі
RowSet ЪБЃЌЯШИљОнжїМќЙ§ТЫвЊ scan ЗЖЮЇЃЌШЛКѓМгдиЗЖЮЇФкЕФ base dataЃЌдйевЕНЖдгІЕФ
delta storesЃЌгІгУЫљгаБфИќЃЌзюКѓ union ЩЯ MenRowSet жаЕФФкШнЃЌЗЕЛиЪ§ОнИј
ClientЁЃ
4ЁЂДцДЂЩшМЦ
СаЪНДцДЂ
гХЪЦ**
ВщбЏЩйСПСаЪБ IO ЩйЃЌЫйЖШПь
Ъ§ОнбЙЫѕБШИп
БугкВщбЏв§ЧцадФмгХЛЏЃКбгГйЮяЛЏЁЂжБНгВйзїбЙЫѕЪ§ОнЁЂЯђСПЛЏжДаа
СгЪЦ
ВщбЏСаЬЋЖрЪБадФмЯТНЕЃЈKUDU НЈвщСаЪ§ВЛГЌЙ§ 300 ЃЉ
ВЛЪЪКЯ OLTP ГЁОА
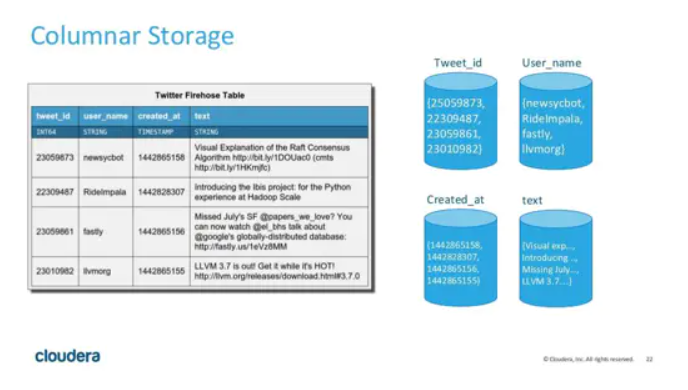
ЗжЧј
гыДѓЖрЪ§ДѓЪ§ОнДцДЂв§ЧцРрЫЦЃЌKUDU ЖдБэНјааКсЯђЗжЧјЃЌKUDU БэЛсБЛКсЯђЧаЗжДцДЂдкЖрИі tablets
жаЁЃВЛЙ§ЯрБШгыЦфЫћДцДЂв§ЧцЃЌKUDU ЬсЙЉСЫИќМгЗсИЛСщЛюЕФЪ§ОнЗжЧјВпТдЁЃ
вЛАуЪ§ОнЗжЧјВпТджївЊгаСНжжЃЌвЛжжЪЧ Range PartitioningЃЌАДеезжЖЮжЕЗЖЮЇНјааЗжЧјЃЌHBase
ОЭВЩгУСЫетжжЗНЪНЃЌШчЯТЭМЃК
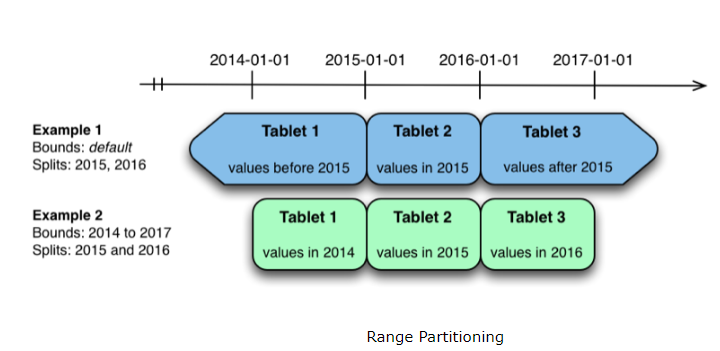
Range Partitioning ЕФгХЪЦЪЧдкЪ§ОнНјааХњСПЖСЕФЪБКђЃЌПЩвдАбДѓВПЗжЕФЖСБфГЩЭЌвЛИі
tablet жаЕФЫГађЖСЃЌФмЙЛЬсЩ§Ъ§ОнЖСШЁЕФЭЬЭТСПЁЃВЂЧвАДееЗЖЮЇНјааЗжЧјЃЌЮвУЧПЩвдКмЗНБуЕФНјааЗжЧјРЉеЙЁЃЦфСгЪЦЪЧЭЌвЛИіЗЖЮЇФкЕФЪ§ОнаДШыЖМЛсТфдкЕЅИі
tablet ЩЯЃЌаДЕФбЙСІДѓЃЌЫйЖШТ§ЁЃ
СэвЛжжЗжЧјВпТдЪЧ Hash PartitioningЃЌАДеезжЖЮЕФ Hash жЕНјааЗжЧјЃЌCassandra
ВЩгУСЫетИіЗНЪНЃЌМћЯТЭМЃК 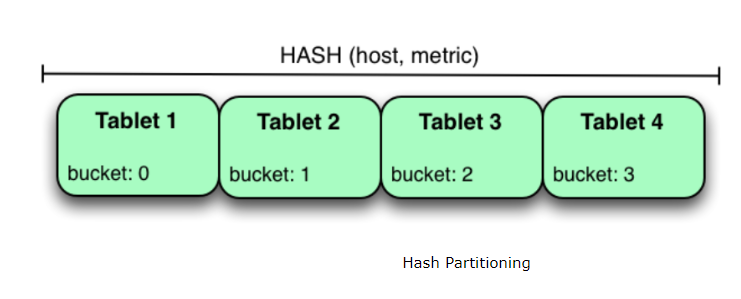
гы Range Partitioning ЯрЗДЃЌгЩгкЪЧ Hash ЗжЧјЃЌЪ§ОнЕФаДШыЛсБЛОљдШЕФЗжЩЂЕНИїИі
tablet жаЃЌаДШыЫйЖШПьЁЃЕЋЪЧЖдгкЫГађЖСЕФГЁОАетвЛВпТдОЭВЛЬЋЪЪгУСЫЃЌвђЮЊЪ§ОнЗжЩЂЃЌвЛДЮЫГађЖСашвЊНЋИїИі
tablet жаЕФЪ§ОнЗжБ№ЖСШЁВЂзщКЯЃЌЭЬЭТСПЕЭЁЃВЂЧв Hash ЗжЧјЮоЗЈгІЖдЗжЧјРЉеЙЕФЧщПіЁЃ
ИїжжЗжЧјВпТдЕФгХСгЖдБШМћЯТЭМЃК

МШШЛИїЗжЧјВпТдИїгагХСгЃЌФмЗёНЋВЛЭЌЗжЧјВпТдНјаазщКЯЃЌШЁГЄВЙЖЬФиЃПетвВЪЧ KUDU ЕФЫМТЗЃЌKUDU
жЇГжгУЛЇЖдвЛИіБэжИЖЈвЛИіЗЖЮЇЗжЧјЙцдђКЭЖрИі Hash ЗжЧјЙцдђЃЌШчЯТЭМЃК
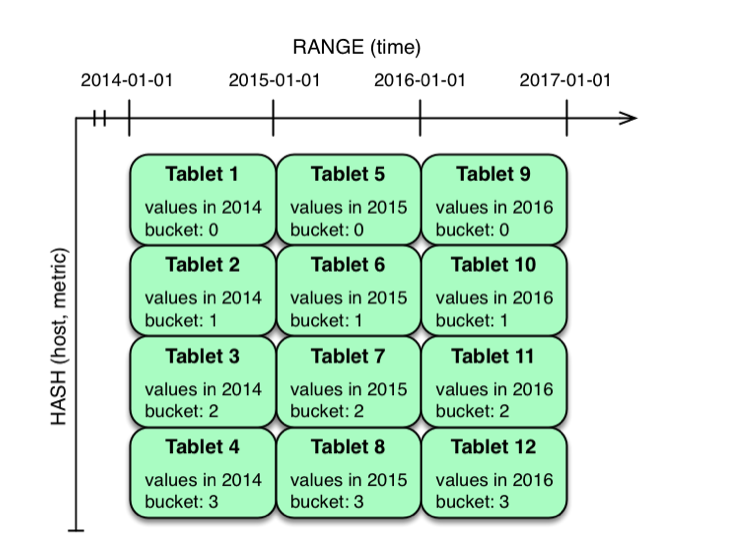
|









