| БрМЭЦМі: |
БОЮФЪєгкЛљДЁЮФеТЃЌЪЪКЯШыУХЕФаЁЛяАщУЧЃЌжївЊНщЩмKuduЪЧЪВУДЃЌгаЪВУДЃЌзюКѓвЛИіаЁАИР§ЃЌЯЃЭћЖдДѓМвгаАяжњЁЃ
БОЮФРДздcnblogsЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Cloudera KuduЪЧЪВУДЃП
kuduЪЧclouderaдк2012ПЊЪМУиУмбаЗЂЕФвЛПюНщгкhdfsКЭhbaseжЎМфЕФИпЫйЗжВМЪНСаЪНДцДЂЪ§ОнПтЁЃМцОпСЫhbaseЕФЪЕЪБадЁЂhdfsЕФИпЭЬЭТЃЌвдМАДЋЭГЪ§ОнПтЕФsqlжЇГжЁЃзїЮЊвЛПюЪЕЪБЁЂРыЯпжЎМфЕФДцДЂЯЕЭГЁЃЖЈЮЛКЭsparkдкМЦЫуЯЕЭГжаЕФЕиЮЛЗЧГЃЯрЫЦЁЃШчЙћАбmr+hdfsзїЮЊРыЯпМЦЫуБъХфЃЌstorm+hbaseзїЮЊЪЕЪБМЦЫуБъХфЁЃspark+kuduгаПЩФмГЩЮЊЮДРДзюгаОКељСІЕФвЛжжМмЙЙЁЃ
вВОЭЪЧkafka -> spark -> kuduетжжМмЙЙЃЌЮДРДДЫМмЙЙЪЧЗёЛсЗчУвЃЌднЧвВЛбдТлЁЃШУЮвУЧЪУФПвдД§АЩЃЁ
KuduЪЧClouderaПЊдДЕФаТаЭСаЪНДцДЂЯЕЭГЃЌЪЧApache HadoopЩњЬЌШІЕФаТГЩдБжЎвЛЃЈincubatingЃЉЃЌзЈУХЮЊСЫЖдПьЫйБфЛЏЕФЪ§ОнНјааПьЫйЕФЗжЮіЃЌЬюВЙСЫвдЭљHadoopДцДЂВуЕФПеШБЁЃ
KuduЪЧTodd Lipcon@ClouderaДјЭЗПЊЗЂЕФДцДЂЯЕЭГЃЌЦфећЬхгІгУФЃЪНКЭHBaseБШНЯНгНќЃЌМДжЇГжааМЖБ№ЕФЫцЛњЖСаДЃЌВЂжЇГжХњСПЫГађМьЫїЙІФмЁЃ
Kudu ЪЧвЛИіеыЖд Apache Hadoop ЦНЬЈЖјПЊЗЂЕФСаЪНДцДЂЙмРэЦїЁЃKudu ЙВЯэ Hadoop
ЩњЬЌЯЕЭГгІгУЕФГЃМћММЪѕЬиад:Ыќдкcommodity hardwareЃЈЩЬЦЗгВМўЃЉЩЯдЫааЃЌhorizontally
scalableЃЈЫЎЦНПЩРЉеЙЃЉЃЌВЂжЇГж highly availableЃЈИпПЩгУЃЉадВйзїЁЃ
KuduЕФФПБъЪЧЃКЬсЙЉПьЫйЕФШЋСПЪ§ОнЗжЮігыЪЕЪБДІРэЙІФмЃЛГфЗжРћгУЯШНјCPUгыIOзЪдДЃЛжЇГжЪ§ОнИќаТЃЛМђЕЅЁЂПЩРЉеЙЕФЪ§ОнФЃаЭЁЃ
KuduЕФЙйЭј

A new addition to the open source Apache Hadoop
ecosystem, Apache Kudu completes Hadoop's storage
layer to enablefast analytics on fast data.
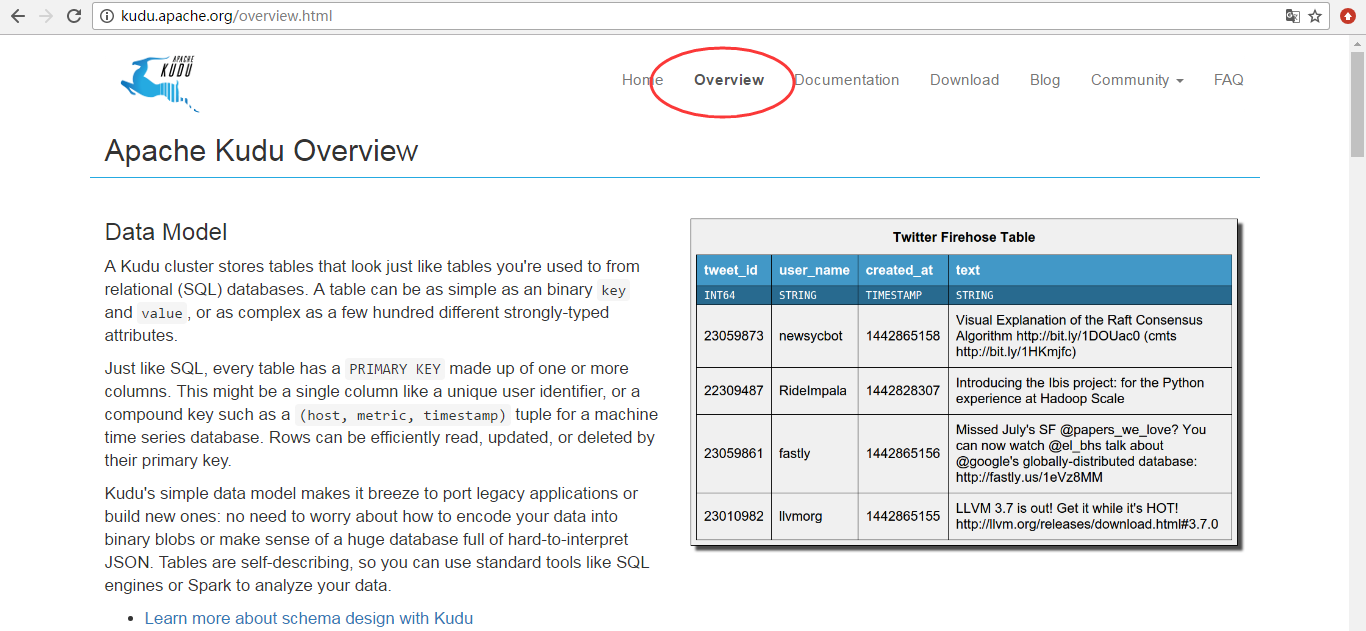
БГОАЁЊЁЊЙІФмЩЯЕФПеАз
Hadoop ЩњЬЌЯЕЭГгаКмЖрзщМўЃЌУПвЛИізщМўгаВЛЭЌЕФЙІФмЁЃдкЯжЪЕГЁОАжаЃЌгУЛЇЭљЭљашвЊЭЌЪБВПЪ№КмЖр
Hadoop ЙЄОпРДНтОіЭЌвЛИіЮЪЬтЃЌетжжМмЙЙГЦЮЊ ЛьКЯМмЙЙ (hybrid architecture)
ЁЃ БШШчЃЌгУЛЇашвЊРћгУ Hbase ЕФПьЫйВхШыЁЂПьЖС random access ЕФЬиадРДЕМШыЪ§ОнЃЌ
HBase вВдЪаэгУЛЇЖдЪ§ОнНјаааоИФЃЌ HBase ЖдгкДѓСПаЁЙцФЃВщбЏвВЗЧГЃбИЫйЁЃЭЌЪБЃЌгУЛЇЪЙгУ HDFS/Parquet
+ Impala/Hive РДЖдГЌДѓЕФЪ§ОнМЏНјааВщбЏЗжЮіЃЌЖдгкетРрГЁОАЃЌ Parquet етжжСаЪНДцДЂЮФМўИёЪНОпгаМЋДѓЕФгХЪЦЁЃ
КмЖрЙЋЫОЖМГЩЙІЕиВПЪ№СЫ HDFS/Parquet + HBase ЛьКЯМмЙЙЃЌШЛЖјетжжМмЙЙНЯЮЊИДдгЃЌЖјЧвдкЮЌЛЄЩЯвВЪЎЗжРЇФбЁЃЪзЯШЃЌгУЛЇгУ
Flume Лђ Kafka ЕШЪ§Он Ingest ЙЄОпНЋЪ§ОнЕМШы HBase ЃЌгУЛЇПЩФмдк HBase
ЩЯЖдЪ§ОнзівЛаЉаоИФЁЃШЛКѓУПИєвЛЖЮЪБМф ( УПЬьЛђУПжм ) НЋЪ§ОнДг Hbase жаЕМШыЕН Parquet
ЮФМўЃЌзїЮЊвЛИіаТЕФ partition ЗХдк HDFS ЩЯЃЌзюКѓЪЙгУ Impala ЕШМЦЫув§ЧцНјааВщбЏЃЌЩњГЩзюжеБЈБэЁЃ

етбљвЛЬѕЙЄОпСДЗБЫіЖјИДдгЃЌЖјЧвЛЙДцдкКмЖрЮЪЬтЃЌБШШчЃК
ЃЈ1ЃЉШчКЮДІРэФГвЛЙ§ГЬГіЯжЪЇАмЃПЁЁЁЁ
ЃЈ2ЃЉДг HBase НЋЪ§ОнЕМГіЕНЮФМўЃЌЖрОУЕФЦЕТЪБШНЯКЯЪЪЃП
ЃЈ3ЃЉЕБЩњГЩзюжеБЈБэЪБЃЌзюНќЕФЪ§ОнВЂЮоЗЈЬхЯждкзюжеВщбЏНсЙћЩЯЁЃ
ЃЈ4ЃЉЮЌЛЄМЏШКЪБЃЌШчКЮБЃжЄЙиМќШЮЮёВЛЪЇАмЃП
ЃЈ5ЃЉParquet ЪЧ immutable ЃЌвђДЫЕБ HBase жаЩОИФФГаЉРњЪЗЪ§ОнЪБЃЌЭљЭљашвЊШЫЙЄИЩдЄНјааЭЌВНЁЃ
етЪБКђЃЌгУЛЇОЭЯЃЭћФмЙЛгавЛжжгХбХЕФДцДЂНтОіЗНАИЃЌРДгІИЖВЛЭЌРраЭЕФЙЄзїСїЃЌВЂБЃГжИпадФмЕФМЦЫуФмСІЁЃ
Cloudera КмдчОЭвтЪЖЕНетИіЮЪЬтЃЌдк 2012 ФъОЭПЊЪММЦЛЎПЊЗЂ Kudu етИіДцДЂЯЕЭГЃЌжегкдк
2015 ФъЗЂВМВЂПЊдДГіРДЁЃ Kudu ЪЧЖд HDFS КЭ HBase ЙІФмЩЯЕФВЙГфЃЌФмЬсЙЉПьЫйЕФЗжЮіКЭЪЕЪБМЦЫуФмСІЃЌВЂЧвГфЗжРћгУ
CPU КЭ I/O зЪдДЃЌжЇГжЪ§ОндЕиаоИФЃЌжЇГжМђЕЅЕФЁЂПЩРЉеЙЕФЪ§ОнФЃаЭЁЃ
БГОАЁЊЁЊаТЕФгВМўЩшБИ RAM ЕФММЪѕЗЂеЙЗЧГЃПьЃЌЫќБфЕУдНРДдНБувЫЃЌШнСПвВдНРДдНДѓЁЃ Cloudera ЕФПЭЛЇЪ§ОнЯдЪОЃЌЫћУЧЕФПЭЛЇЫљВПЪ№ЕФЗўЮёЦїЃЌ
2012 ФъУПИіНкЕуНіга 32GB RAM ЃЌЯжШчНёдіГЄЕНУПИіНкЕуга 128GB Лђ 256GB RAM
ЁЃДцДЂЩшБИЩЯИќаТвВЗЧГЃПьЃЌ дкКмЖрЦеЭЈЗўЮёЦїжаВПЪ№ SSD вВЪЧТХМћВЛЯЪЁЃ HBase ЁЂ HDFS
ЁЂвдМАЦфЫћЕФ Hadoop ЙЄОпЖМдкВЛЖЯздЮвЭъЩЦЃЌДгЖјЪЪгІгВМўЩЯЕФЩ§МЖЛЛДњЁЃШЛЖјЃЌДгИљБОЩЯЃЌ HDFS
Лљгк 03 Фъ GFS ЃЌ HBase Лљгк 05 Фъ BigTable ЃЌдкЕБЪБЯЕЭГЦПОБжївЊШЁОігкЕзВуДХХЬЫйЖШЁЃЕБДХХЬЫйЖШНЯТ§ЪБЃЌ
CPU РћгУТЪВЛзуЕФИљБОдвђЪЧДХХЬЫйЖШЕМжТЕФЦПОБЃЌЕБДХХЬЫйЖШЬсИпСЫжЎКѓЃЌ CPU РћгУТЪЬсИпЃЌетЪБКђ
CPU ЭљЭљГЩЮЊЯЕЭГЕФЦПОБЁЃ HBase ЁЂ HDFS гЩгкФъДњОУдЖЃЌвбОКмФбДгЛљБОМмЙЙЩЯНјаааоИФЃЌЖј
Kudu ЪЧЛљгкШЋаТЕФЩшМЦЃЌвђДЫПЩвдИќГфЗжЕиРћгУ RAM ЁЂ I/O зЪдДЃЌВЂгХЛЏ CPU РћгУТЪЁЃЮвУЧПЩвдРэНтЮЊЃЌ
Kudu ЯрБШгывдЭљЕФЯЕЭГЃЌ CPU ЪЙгУНЕЕЭСЫЃЌ I/O ЕФЪЙгУЬсИпСЫЃЌ RAM ЕФРћгУИќГфЗжСЫЁЃ
1. KuduЕФМђНщ Kudu ЩшМЦжЎГѕЃЌЪЧЮЊСЫНтОівЛЯТЮЪЬтЃК
ЖдЪ§ОнЩЈУш (scan) КЭЫцЛњЗУЮЪ (random access) ЭЌЪБОпгаИпадФмЃЌМђЛЏгУЛЇИДдгЕФЛьКЯМмЙЙЃЛ Ип CPU аЇТЪЃЌЪЙгУЛЇЙКТђЕФЯШНјДІРэЦїЕФЕФЛЈЗбЕУЕНзюДѓЛиБЈЃЛИп IO адФмЃЌГфЗжРћгУЯШНјДцДЂНщжЪЃЛжЇГжЪ§ОнЕФдЕиИќаТЃЌБмУтЖюЭтЕФЪ§ОнДІРэЁЂЪ§ОнвЦЖЏЁЃ
2. KuduжЇГжПчЪ§ОнжааФ replication
Kudu ЕФКмЖрЬиадИњ HBase КмЯёЃЌЫќжЇГжЫїв§МќЕФВщбЏКЭаоИФЁЃ
Cloudera дјОЯыЙ§Лљгк Hbase НјаааоИФЃЌШЛЖјНсТлЪЧЖд HBase ЕФИФЖЏЗЧГЃДѓЃЌ Kudu
ЕФЪ§ОнФЃаЭКЭДХХЬДцДЂЖМгы Hbase ВЛЭЌЁЃ HBase БОЩэГЩЙІЕФЪЪгУгкДѓСПЕФЦфЫќГЁОАЃЌвђДЫаоИФ
HBase КмПЩФмГдСІВЛЬжКУЁЃзюКѓ Cloudera ОіЖЈПЊЗЂвЛИіШЋаТЕФДцДЂЯЕЭГЁЃ
3. KuduЕФЖдЭтНгПк Kudu ЬсЙЉ C++ КЭ JAVA API ЃЌПЩвдНјааЕЅЬѕЛђХњСПЕФЪ§ОнЖСаДЃЌ schema ЕФДДНЈаоИФЁЃГ§ДЫжЎЭтЃЌ
Kudu ЛЙНЋгы hadoop ЩњЬЌШІЕФЦфЫќЙЄОпНјааећКЯЁЃФПЧАЃЌ kudu beta АцБОЖд Impala
жЇГжНЯЮЊЭъЩЦЃЌжЇГжгУ Impala НјааДДНЈБэЁЂЩОИФЪ§ОнЕШДѓВПЗжВйзїЁЃ Kudu ЛЙЪЕЯжСЫ KuduTableInputFormat
КЭ KuduTableOutputFormat ЃЌДгЖјжЇГж Mapreduce ЕФЖСаДВйзїЁЃЭЌЪБжЇГжЪ§ОнЕФ
localityЃЈБОЕиадЃЉ ЁЃФПЧАЖд spark ЕФжЇГжЛЙВЛЙЛЭъЩЦЃЌ spark жЛФмНјааЪ§ОнЕФЖСВйзїЁЃ
4. НкЕу Kudu-masterЃКжїНкЕуЃЌЮЌЛЄДцДЂБэдЊЪ§ОнЃЌИњзйаЕїЫљгаЕФtserverЕФзДЬЌКЭЪ§ОнЃЌАВзАЦцЪ§НкЕу(зюЩйШ§Иі)ЁЃ
Kudu-tserverЃКДгНкЕуЃЌДцДЂОпЬхБэЪ§ОнЕФНкЕуЃЌвЛИіБэЪ§ОнПЩвдгаЖрИіИББОЃЌЕЋжЛгавЛИіleaderВХФмИКд№аДЧыЧѓЃЌleaderКЭfollowerЖМПЩвдИКд№ЖСЧыЧѓЁЃАВзАзюЩйШ§ИіНкЕуЁЃ
ЪЙгУАИР§ЁЊЁЊаЁУз
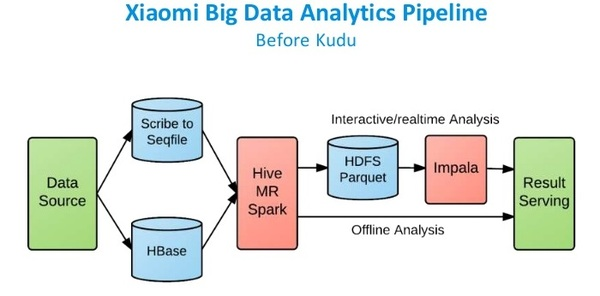
ЮЊЪВУДетРягУаЁУзРДзїЮЊАИР§ЃЌЪЧвђЮЊаЁУздкKuduзпдкЧАСаЁЃ
аЁУзЪЧHbaseЕФжиЖШгУЛЇЃЌЫћУЧУПЬьгадМ50вкЬѕгУЛЇМЧТМЁЃаЁУзФПЧАЪЙгУЕФвВЪЧHDFS
+ HBaseетбљЕФЛьКЯМмЙЙЁЃПЩМћИУСїЫЎЯпЯрЖдБШНЯИДдгЃЌЦфЪ§ОнДцДЂЗжЮЊSequenceFileЃЌHbaseКЭParquetЁЃ
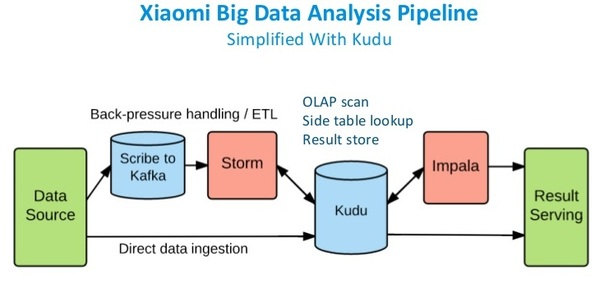
дкЪЙгУKuduвдКѓЃЌKuduзїЮЊЭГвЛЕФЪ§ОнВжПтЃЌПЩвдЭЌЪБжЇГжРыЯпЗжЮіКЭЪЕЪБНЛЛЅЗжЮіЁЃШчЯТЃК
|









