| БрМЭЦМі: |
БОЮФжївЊЖдSpark
SQLНјааИХЪіЃЌВЂЯъЯИНщЩмШчКЮБраДSpark SQLГЬађЕФВйзїЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂSpark SQL
1ЃЎSpark SQLИХЪі
1.1ЃЎSpark SQLЕФЧАЪРНёЩњ
SharkЪЧвЛИіЮЊSparkЩшМЦЕФДѓЙцФЃЪ§ОнВжПтЯЕЭГЃЌЫќгыHiveМцШнЁЃSharkНЈСЂдкHiveЕФДњТыЛљДЁЩЯЃЌВЂЭЈЙ§НЋHiveЕФВПЗжЮяРэжДааМЦЛЎНЛЛЛГіРДЁЃетИіЗНЗЈЪЙЕУSharkЕФгУЛЇПЩвдМгЫйHiveЕФВщбЏЃЌЕЋЪЧSharkМЬГаСЫHiveЕФДѓЧвИДдгЕФДњТыЪЙЕУSharkКмФбгХЛЏКЭЮЌЛЄЃЌЭЌЪБSharkвРРЕгкSparkЕФАцБОЁЃЫцзХЮвУЧгіЕНСЫадФмгХЛЏЕФЩЯЯоЃЌвдМАМЏГЩSQLЕФвЛаЉИДдгЕФЗжЮіЙІФмЃЌЮвУЧЗЂЯжHiveЕФMapReduceЩшМЦЕФПђМмЯожЦСЫSharkЕФЗЂеЙЁЃдк2014Фъ7дТ1ШеЕФSparkSummitЩЯЃЌDatabricksаћВМжежЙЖдSharkЕФПЊЗЂЃЌНЋжиЕуЗХЕНSparkSQLЩЯЁЃ
1.2ЃЎЪВУДЪЧSpark SQL
Spark SQLЪЧSparkгУРДДІРэНсЙЙЛЏЪ§ОнЕФвЛИіФЃПщЃЌЫќЬсЙЉСЫвЛИіБрГЬГщЯѓНазіDataFrameВЂЧвзїЮЊЗжВМЪНSQLВщбЏв§ЧцЕФзїгУЁЃ
ЯрБШгкSpark RDD APIЃЌSpark SQLАќКЌСЫЖдНсЙЙЛЏЪ§ОнКЭдкЦфЩЯдЫЫуЕФИќЖраХЯЂЃЌSpark
SQLЪЙгУетаЉаХЯЂНјааСЫЖюЭтЕФгХЛЏЃЌЪЙЖдНсЙЙЛЏЪ§ОнЕФВйзїИќМгИпаЇКЭЗНБуЁЃ
гаЖржжЗНЪНШЅЪЙгУSpark SQLЃЌАќРЈSQLЁЂDataFrames APIКЭDatasets APIЁЃЕЋЮоТлЪЧФФжжAPIЛђепЪЧБрГЬгябдЃЌЫќУЧЖМЪЧЛљгкЭЌбљЕФжДаав§ЧцЃЌвђДЫФуПЩвддкВЛЭЌЕФAPIжЎМфЫцвтЧаЛЛЃЌЫќУЧИїгаИїЕФЬиЕуЃЌПДФуЯВЛЖФЧжжЗчИёЁЃ
1.3ЃЎЮЊЪВУДвЊбЇЯАSpark SQL
ЮвУЧвбОбЇЯАСЫHiveЃЌЫќЪЧНЋHive SQLзЊЛЛГЩMapReduceШЛКѓЬсНЛЕНМЏШКжаШЅжДааЃЌДѓДѓМђЛЏСЫБраДMapReduceГЬађЕФИДдгадЃЌгЩгкMapReduceетжжМЦЫуФЃаЭжДаааЇТЪБШНЯТ§ЃЌЫљвдSpark
SQLгІдЫЖјЩњЃЌЫќЪЧНЋSpark SQLзЊЛЛГЩRDDЃЌШЛКѓЬсНЛЕНМЏШКжаШЅдЫааЃЌжДаааЇТЪЗЧГЃПьЃЁ
1.взећКЯ

НЋsqlВщбЏгыsparkГЬађЮоЗьЛьКЯЃЌПЩвдЪЙгУjavaЁЂscalaЁЂpythonЁЂRЕШгябдЕФAPIВйзїЁЃ
2.ЭГвЛЕФЪ§ОнЗУЮЪ 
вдЯрЭЌЕФЗНЪНСЌНгЕНШЮКЮЪ§ОндДЁЃ
3.МцШнHive
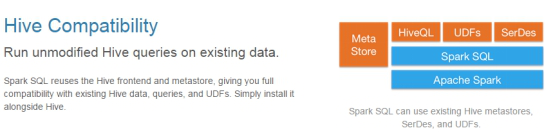
жЇГжhiveSQLЕФгяЗЈЁЃ
4.БъзМЕФЪ§ОнСЌНг

ПЩвдЪЙгУаавЕБъзМЕФJDBCЛђODBCСЌНгЁЃ
2ЃЎDataFrame
2.1ЃЎЪВУДЪЧDataFrame
DataFrameЕФЧАЩэЪЧSchemaRDDЃЌДгSpark 1.3.0ПЊЪМSchemaRDDИќУћЮЊDataFrameЁЃгыSchemaRDDЕФжївЊЧјБ№ЪЧЃКDataFrameВЛдйжБНгМЬГаздRDDЃЌЖјЪЧздМКЪЕЯжСЫRDDЕФОјДѓЖрЪ§ЙІФмЁЃФуШдОЩПЩвддкDataFrameЩЯЕїгУrddЗНЗЈНЋЦфзЊЛЛЮЊвЛИіRDDЁЃ
дкSparkжаЃЌDataFrameЪЧвЛжжвдRDDЮЊЛљДЁЕФЗжВМЪНЪ§ОнМЏЃЌРрЫЦгкДЋЭГЪ§ОнПтЕФЖўЮЌБэИёЃЌDataFrameДјгаSchemaдЊаХЯЂЃЌМДDataFrameЫљБэЪОЕФЖўЮЌБэЪ§ОнМЏЕФУПвЛСаЖМДјгаУћГЦКЭРраЭЃЌЕЋЕзВузіСЫИќЖрЕФгХЛЏЁЃDataFrameПЩвдДгКмЖрЪ§ОндДЙЙНЈЃЌБШШчЃКвбОДцдкЕФRDDЁЂНсЙЙЛЏЮФМўЁЂЭтВПЪ§ОнПтЁЂHiveБэЁЃ
2.2ЃЎDataFrameгыRDDЕФЧјБ№
RDDПЩПДзїЪЧЗжВМЪНЕФЖдЯѓЕФМЏКЯЃЌSparkВЂВЛжЊЕРЖдЯѓЕФЯъЯИФЃЪНаХЯЂЃЌDataFrameПЩПДзїЪЧЗжВМЪНЕФRowЖдЯѓЕФМЏКЯЃЌЦфЬсЙЉСЫгЩСазщГЩЕФЯъЯИФЃЪНаХЯЂЃЌЪЙЕУSpark
SQLПЩвдНјааФГаЉаЮЪНЕФжДаагХЛЏЁЃDataFrameКЭЦеЭЈЕФRDDЕФТпМПђМмЧјБ№ШчЯТЫљЪОЃК
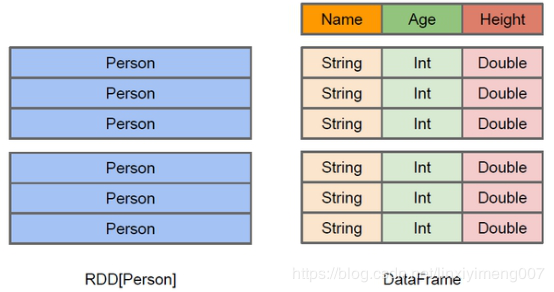
ЩЯЭМжБЙлЕиЬхЯжСЫDataFrameКЭRDDЕФЧјБ№ЁЃ
зѓВрЕФRDD[Person]ЫфШЛвдPersonЮЊРраЭВЮЪ§ЃЌЕЋSparkПђМмБОЩэВЛСЫНт PersonРрЕФФкВПНсЙЙЁЃ
ЖјгвВрЕФDataFrameШДЬсЙЉСЫЯъЯИЕФНсЙЙаХЯЂЃЌЪЙЕУSpark SQLПЩвдЧхГўЕижЊЕРИУЪ§ОнМЏжаАќКЌФФаЉСаЃЌУПСаЕФУћГЦКЭРраЭИїЪЧЪВУДЁЃDataFrameЖрСЫЪ§ОнЕФНсЙЙаХЯЂЃЌМДschemaЁЃетбљПДЦ№РДОЭЯёвЛеХБэСЫЃЌDataFrameЛЙХфЬзСЫаТЕФВйзїЪ§ОнЕФЗНЗЈЃЌDataFrame
APIЃЈШчdf.select())КЭSQL(select id, name from xx_table
where ...)ЁЃ
ДЫЭтDataFrameЛЙв§ШыСЫoff-heap,втЮЖзХJVMЖбвдЭтЕФФкДц, етаЉФкДцжБНгЪмВйзїЯЕЭГЙмРэЃЈЖјВЛЪЧJVMЃЉЁЃSparkФмЙЛвдЖўНјжЦЕФаЮЪНађСаЛЏЪ§Он(ВЛАќРЈНсЙЙ)ЕНoff-heapжа,
ЕБвЊВйзїЪ§ОнЪБ, ОЭжБНгВйзїoff-heapФкДц. гЩгкSparkРэНтschema, ЫљвджЊЕРИУШчКЮВйзїЁЃ
RDDЪЧЗжВМЪНЕФJavaЖдЯѓЕФМЏКЯЁЃDataFrameЪЧЗжВМЪНЕФRowЖдЯѓЕФМЏКЯЁЃDataFrameГ§СЫЬсЙЉСЫБШRDDИќЗсИЛЕФЫузгвдЭтЃЌИќживЊЕФЬиЕуЪЧЬсЩ§жДаааЇТЪЁЂМѕЩйЪ§ОнЖСШЁвдМАжДааМЦЛЎЕФгХЛЏЁЃ
гаСЫDataFrameетИіИпвЛВуЕФГщЯѓКѓЃЌЮвУЧДІРэЪ§ОнИќМгМђЕЅСЫЃЌЩѕжСПЩвдгУSQLРДДІРэЪ§ОнСЫЃЌЖдПЊЗЂепРДЫЕЃЌвзгУадгаСЫКмДѓЕФЬсЩ§ЁЃ
ВЛНіШчДЫЃЌЭЈЙ§DataFrame APIЛђSQLДІРэЪ§ОнЃЌЛсздЖЏОЙ§Spark
гХЛЏЦїЃЈCatalystЃЉЕФгХЛЏЃЌМДЪЙФуаДЕФГЬађЛђSQLВЛИпаЇЃЌвВПЩвддЫааЕФКмПьЁЃ
2.3ЃЎDataFrameгыRDDЕФгХШБЕу
RDDЕФгХШБЕуЃК
гХЕу:
ЃЈ1ЃЉБрвыЪБРраЭАВШЋ
БрвыЪБОЭФмМьВщГіРраЭДэЮѓ
ЃЈ2ЃЉУцЯђЖдЯѓЕФБрГЬЗчИё
жБНгЭЈЙ§ЖдЯѓЕїгУЗНЗЈЕФаЮЪНРДВйзїЪ§Он
ШБЕу:
ЃЈ1ЃЉађСаЛЏКЭЗДађСаЛЏЕФадФмПЊЯњ
ЮоТлЪЧМЏШКМфЕФЭЈаХ, ЛЙЪЧIOВйзїЖМашвЊЖдЖдЯѓЕФНсЙЙКЭЪ§ОнНјааађСаЛЏКЭЗДађСаЛЏЁЃ
ЃЈ2ЃЉGCЕФадФмПЊЯњ
ЦЕЗБЕФДДНЈКЭЯњЛйЖдЯѓ, ЪЦБиЛсдіМгGC
DataFrameЭЈЙ§в§ШыschemaКЭoff-heapЃЈВЛдкЖбРяУцЕФФкДцЃЌжИЕФЪЧГ§СЫВЛдкЖбЕФФкДцЃЌЪЙгУВйзїЯЕЭГЩЯЕФФкДцЃЉЃЌНтОіСЫRDDЕФШБЕу,
SparkЭЈЙ§schameОЭФмЙЛЖСЖЎЪ§Он, вђДЫдкЭЈаХКЭIOЪБОЭжЛашвЊађСаЛЏКЭЗДађСаЛЏЪ§Он, ЖјНсЙЙЕФВПЗжОЭПЩвдЪЁТдСЫЃЛЭЈЙ§off-heapв§ШыЃЌПЩвдПьЫйЕФВйзїЪ§ОнЃЌБмУтДѓСПЕФGCЁЃЕЋЪЧШДЖЊСЫRDDЕФгХЕуЃЌDataFrameВЛЪЧРраЭАВШЋЕФ,
APIвВВЛЪЧУцЯђЖдЯѓЗчИёЕФЁЃ
2.4ЃЎЖСШЁЪ§ОндДДДНЈDataFrame
2.4.1 ЖСШЁЮФБОЮФМўДДНЈDataFrame
дкspark2.0АцБОжЎЧАЃЌSpark SQLжаSQLContextЪЧДДНЈDataFrameКЭжДааSQLЕФШыПкЃЌРћгУhiveContextЭЈЙ§hive
sqlгяОфВйзїhiveБэЪ§ОнЃЌМцШнhiveВйзїЃЌВЂЧвhiveContextМЬГаздSQLContextЁЃдкspark2.0жЎКѓЃЌетаЉЖМЭГвЛгкSparkSessionЃЌSparkSession
ЗтзАСЫ SparkContextЃЌSqlContextЃЌЭЈЙ§SparkSessionПЩвдЛёШЁЕН SparkConetxt,SqlContext
ЖдЯѓЁЃ
ЃЈ1ЃЉдкБОЕиДДНЈвЛИіЮФМўЃЌгаШ§СаЃЌЗжБ№ЪЧidЁЂnameЁЂageЃЌгУПеИёЗжИєЃЌШЛКѓЩЯДЋЕНhdfsЩЯЁЃperson.txtФкШнЮЊЃК
1 zhangsan
20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40 |
ЩЯДЋЪ§ОнЮФМўЕНHDFSЩЯЃК
hdfs dfs -put person.txt /
ЃЈ2ЃЉдкspark shellжДааЯТУцУќСюЃЌЖСШЁЪ§ОнЃЌНЋУПвЛааЕФЪ§ОнЪЙгУСаЗжИєЗћЗжИю
ЯШжДаа spark-shell --master local[2]
val lineRDD= sc.textFile("/person.txt").map(_.split("
"))

ЃЈ3ЃЉЖЈвхcase classЃЈЯрЕБгкБэЕФschemaЃЉ
case class Person(id:Int, name:String, age:Int)

ЃЈ4ЃЉНЋRDDКЭcase classЙиСЊ
val personRDD = lineRDD.map(x =>
Person( x(0).toInt, x(1) , x(2).toInt ))

ЃЈ5ЃЉНЋRDDзЊЛЛГЩDataFrame
val personDF = personRDD.toDF

ЃЈ6ЃЉЖдDataFrameНјааДІРэ
personDF.show

personDF.printSchema

ЃЈ7ЃЉЁЂЭЈЙ§SparkSessionЙЙНЈDataFrame
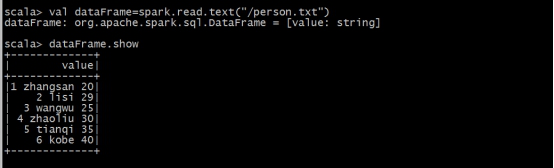
ЪЙгУspark-shellжавбОГѕЪМЛЏКУЕФSparkSessionЖдЯѓsparkЩњГЩDataFrame
val dataFrame=spark.read.text("/person.txt")
2.4.2 ЖСШЁjsonЮФМўДДНЈDataFrame
ЃЈ1ЃЉЪ§ОнЮФМў
ЪЙгУsparkАВзААќЯТЕФ
/opt/bigdata/spark/examples/src/main/resources
/ people.json ЮФМў
ЃЈ2ЃЉдкspark shellжДааЯТУцУќСюЃЌЖСШЁЪ§Он

ЃЈ3ЃЉНгЯТРДОЭПЩвдЪЙгУDataFrameЕФКЏЪ§Вйзї


2.4.3 ЖСШЁparquetСаЪНДцДЂИёЪНЮФМўДДНЈDataFrame
ЃЈ3ЃЉЪ§ОнЮФМў
ЪЙгУsparkАВзААќЯТЕФ
/opt/bigdata/spark/examples/src/main/resources
/ users.parquet ЮФМў
ЃЈ2ЃЉдкspark shellжДааЯТУцУќСюЃЌЖСШЁЪ§Он

ЃЈ3ЃЉНгЯТРДОЭПЩвдЪЙгУDataFrameЕФКЏЪ§Вйзї


3.DataFrameГЃгУВйзї
3.1. DSLЗчИёгяЗЈ
DataFrameЬсЙЉСЫвЛИіСьгђЬиЖЈгябд(DSL)вдЗНБуВйзїНсЙЙЛЏЪ§ОнЁЃЯТУцЪЧвЛаЉЪЙгУЪОР§
ЃЈ1ЃЉВщПДDataFrameжаЕФФкШнЃЌЭЈЙ§ЕїгУshowЗНЗЈ
personDF.show

ЃЈ2ЃЉВщПДDataFrameВПЗжСажаЕФФкШн
ВщПДnameзжЖЮЕФЪ§Он
personDF.select(personDF.col("name")).show

ВщПДnameзжЖЮЕФСэвЛжжаДЗЈ

ВщПД name КЭageзжЖЮЪ§ОнpersonDF.select(col("name")
, col("age")) .show

ЃЈ3ЃЉДђгЁDataFrameЕФSchemaаХЯЂ
personDF.printSchema

ЃЈ4ЃЉВщбЏЫљгаЕФnameКЭageЃЌВЂНЋage+1
personDF.select(col("id"),
col("name"), col ("age") + 1)
. show

вВПЩвдетбљЃК
personDF.select(personDF("id"),
personDF("name") , personDF("age")
+ 1) . show

ЃЈ5ЃЉЙ§ТЫageДѓгкЕШгк25ЕФЃЌЪЙгУfilterЗНЗЈЙ§ТЫ
personDF.filter(col("age")
>= 25).show

ЃЈ6ЃЉЭГМЦФъСфДѓгк30ЕФШЫЪ§
personDF.filter(col("age")>30).count()

ЃЈ7ЃЉАДФъСфНјааЗжзщВЂЭГМЦЯрЭЌФъСфЕФШЫЪ§
personDF.groupBy("age").count().show

3.2. SQLЗчИёгяЗЈ
ЁЁDataFrameЕФвЛИіЧПДѓжЎДІОЭЪЧЮвУЧПЩвдНЋЫќПДзїЪЧвЛИіЙиЯЕаЭЪ§ОнБэЃЌШЛКѓПЩвдЭЈЙ§дкГЬађжаЪЙгУspark.sql()РДжДааSQLВщбЏЃЌНсЙћНЋзїЮЊвЛИіDataFrameЗЕЛиЁЃ
ШчЙћЯыЪЙгУSQLЗчИёЕФгяЗЈЃЌашвЊНЋDataFrameзЂВсГЩБэ,ВЩгУШчЯТЕФЗНЪНЃК
personDF.registerTempTable("t_person")
ЃЈ1ЃЉВщбЏФъСфзюДѓЕФЧАСНУћ
spark.sql("select * from t_person
order by age desc limit 2" ). show

ЃЈ2ЃЉЯдЪОБэЕФSchemaаХЯЂ
spark.sql("desc t_person").show

ЃЈ3ЃЉВщбЏФъСфДѓгк30ЕФШЫЕФаХЯЂ
spark.sql("select * from t_personwhere
age > 30 ") .show

4.DataSet
4.1. ЪВУДЪЧDataSet
DataSetЪЧЗжВМЪНЕФЪ§ОнМЏКЯЁЃDataSetЪЧдкSpark1.6жаЬэМгЕФаТЕФНгПкЁЃЫќМЏжаСЫRDDЕФгХЕуЃЈЧПРраЭКЭПЩвдгУЧПДѓlambdaКЏЪ§ЃЉвдМАSpark
SQLгХЛЏЕФжДаав§ЧцЁЃDataSetПЩвдЭЈЙ§JVMЕФЖдЯѓНјааЙЙНЈЃЌПЩвдгУКЏЪ§ЪНЕФзЊЛЛЃЈ map/flatmap/filter
ЃЉНјааЖржжВйзїЁЃ
4.2. DataFrameЁЂDataSetЁЂRDDЕФЧјБ№
МйЩшRDDжаЕФСНааЪ§ОнГЄетбљЃК

ФЧУДDataFrameжаЕФЪ§ОнГЄетбљ:

ФЧУДDatasetжаЕФЪ§ОнГЄетбљ:
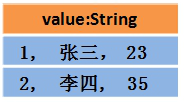
ЛђепГЄетбљЃЈУПааЪ§ОнЪЧИіObjectЃЉ:

DataSetАќКЌСЫDataFrameЕФЙІФмЃЌSpark2.0жаСНепЭГвЛЃЌDataFrameБэЪОЮЊDataSet[Row]ЃЌМДDataSetЕФзгМЏЁЃ
ЃЈ1ЃЉDataSetПЩвддкБрвыЪБМьВщРраЭ
ЃЈ2ЃЉВЂЧвЪЧУцЯђЖдЯѓЕФБрГЬНгПк
ЯрБШDataFrameЃЌDatasetЬсЙЉСЫБрвыЪБРраЭМьВщЃЌЖдгкЗжВМЪНГЬађРДНВЃЌЬсНЛвЛДЮзївЕЬЋЗбОЂСЫЃЈвЊБрвыЁЂДђАќЁЂЩЯДЋЁЂдЫааЃЉЃЌЕНЬсНЛЕНМЏШКдЫааЪБВХЗЂЯжДэЮѓЃЌетЛсРЫЗбДѓСПЕФЪБМфЃЌетвВЪЧв§ШыDatasetЕФвЛИіживЊдвђЁЃ
4.3. DataFrameгыDataSetЕФЛЅзЊ
DataFrameКЭDataSetПЩвдЯрЛЅзЊЛЏЁЃ
ЃЈ1ЃЉDataFrameзЊЮЊ DataSet
df.as[ElementType]етбљПЩвдАбDataFrameзЊЛЏЮЊDataSetЁЃ
ЃЈ2ЃЉDataSetзЊЮЊDataFrame
ds.toDF()етбљПЩвдАбDataSetзЊЛЏЮЊDataFrameЁЃ
4.4. ДДНЈDataSet
ЃЈ1ЃЉЭЈЙ§spark.createDatasetДДНЈ
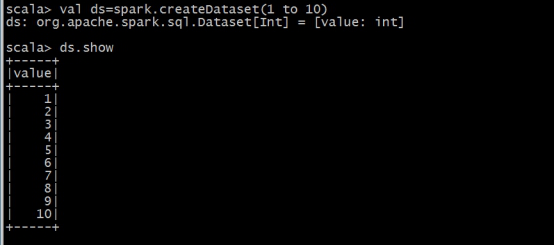
ЃЈ2ЃЉЭЈtoDSЗНЗЈЩњГЩDataSet
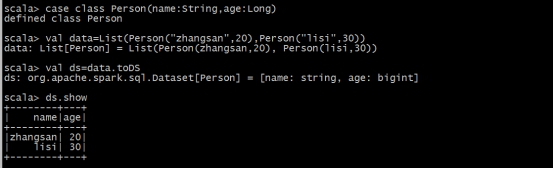
ЃЈ3ЃЉЭЈЙ§DataFrameзЊЛЏЩњГЩ
ЪЙгУas[]зЊЛЛЮЊDataSet
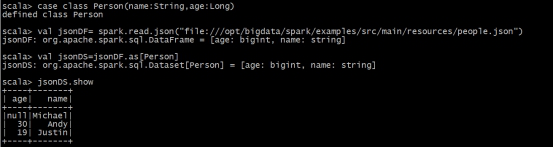
Ш§ЁЂвдБрГЬЗНЪНжДааSpark SQLВщбЏ
1ЃЎБраДSpark SQLГЬађЪЕЯжRDDзЊЛЛDataFrame
ЧАУцЮвУЧбЇЯАСЫШчКЮдкSpark ShellжаЪЙгУSQLЭъГЩВщбЏЃЌЯждкЮвУЧРДЪЕЯждкздЖЈвхЕФГЬађжаБраДSpark
SQLВщбЏГЬађЁЃ
дкSpark SQLжагаСНжжЗНЪНПЩвддкDataFrameКЭRDDНјаазЊЛЛЃЌЕквЛжжЗНЗЈЪЧРћгУЗДЩфЛњжЦЃЌЭЦЕМАќКЌФГжжРраЭЕФRDDЃЌЭЈЙ§ЗДЩфНЋЦфзЊЛЛЮЊжИЖЈРраЭЕФDataFrameЃЌЪЪгУгкЬсЧАжЊЕРRDDЕФschemaЁЃ
ЕкЖўжжЗНЗЈЭЈЙ§БрГЬНгПкгыRDDНјааНЛЛЅЛёШЁschemaЃЌВЂЖЏЬЌДДНЈDataFrameЃЌдкдЫааЪБОіЖЈСаМАЦфРраЭЁЃ
ЪзЯШдкmavenЯюФПЕФpom.xmlжаЬэМгSpark SQLЕФвРРЕ
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.0.2</version>
</dependency> |
1.1ЃЎЭЈЙ§ЗДЩфЭЦЖЯSchema
ScalaжЇГжЪЙгУcase classРраЭЕМШыRDDзЊЛЛЮЊDataFrameЃЌЭЈЙ§case classДДНЈschemaЃЌcase
classЕФВЮЪ§УћГЦЛсБЛЗДЩфЖСШЁВЂГЩЮЊБэЕФСаУћЁЃетжжRDDПЩвдИпаЇЕФзЊЛЛЮЊDataFrameВЂзЂВсЮЊБэЁЃ
ДњТыШчЯТЃК
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* RDDзЊЛЏГЩDataFrame:РћгУЗДЩфЛњжЦ
*/
//todo:ЖЈвхвЛИібљР§РрPerson
case class Person(id:Int,name:String,age:Int)
extends Serializable
object InferringSchema {
def main(args: Array[String]): Unit = {
//todoЃК1ЁЂЙЙНЈsparkSession жИЖЈ
appNameКЭmasterЕФЕижЗ
val spark: SparkSession = SparkSession.builder()
.appName("InferringSchema")
.master("local[2]").getOrCreate()
//todo:2ЁЂДгsparkSessionЛёШЁsparkContextЖдЯѓ
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")//ЩшжУШежОЪфГіМЖБ№
//todo:3ЁЂМгдиЪ§Он
val dataRDD: RDD[String] = sc.textFile
("D:\\person.txt")
//todo:4ЁЂЧаЗжУПвЛааМЧТМ
val lineArrayRDD: RDD[Array[String]] =
dataRDD.map(_.split(" "))
//todo:5ЁЂНЋRDDгыPersonРрЙиСЊ
val personRDD: RDD[Person] = lineArrayRDD.map(x=>Person(x(0).toInt,
x(1),x(2).toInt))
//todo:6ЁЂДДНЈdataFrame,ашвЊЕМШывўЪНзЊЛЛ
import spark.implicits._
val personDF: DataFrame = personRDD.toDF()
//todo
-------------------DSLгяЗЈВйзї start--------------
//1ЁЂЯдЪОDataFrameЕФЪ§ОнЃЌФЌШЯЯдЪО20аа
personDF.show()
//2ЁЂЯдЪОDataFrameЕФschemaаХЯЂ
personDF.printSchema()
//3ЁЂЯдЪОDataFrameМЧТМЪ§
println(personDF.count())
//4ЁЂЯдЪОDataFrameЕФЫљгазжЖЮ
personDF.columns.foreach(println)
//5ЁЂШЁГіDataFrameЕФЕквЛааМЧТМ
println(personDF.head())
//6ЁЂЯдЪОDataFrameжаnameзжЖЮЕФЫљгажЕ
personDF.select("name").show()
//7ЁЂЙ§ТЫГіDataFrameжаФъСфДѓгк30ЕФМЧТМ
personDF.filter($"age" > 30).show()
//8ЁЂЭГМЦDataFrameжаФъСфДѓгк30ЕФШЫЪ§
println(personDF.filter($"age">30).count())
//9ЁЂЭГМЦDataFrameжаАДееФъСфНјааЗжзщЃЌ
ЧѓУПИізщЕФШЫЪ§
personDF.groupBy("age").count().show()
//todo
-------------------DSLгяЗЈВйзї end-------------
//todo
--------------------SQLВйзїЗчИё start-----------
//todo:НЋDataFrameзЂВсГЩБэ
personDF.createOrReplaceTempView("t_person")
//todo:ДЋШыsqlгяОфЃЌНјааВйзї
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where
name='zhangsan'").show()
spark.sql("select * from t_person order
by age desc")
.show()
//todo
--------------------SQLВйзїЗчИё end-------------
sc.stop()
}
}
|
1.2ЃЎЭЈЙ§StructTypeжБНгжИЖЈSchema
ЕБcase classВЛФмЬсЧАЖЈвхКУЪБЃЌПЩвдЭЈЙ§вдЯТШ§ВНЭЈЙ§ДњТыДДНЈDataFrame
ЃЈ1ЃЉНЋRDDзЊЮЊАќКЌrowЖдЯѓЕФRDD
ЃЈ2ЃЉЛљгкstructTypeРраЭДДНЈschemaЃЌгыЕквЛВНДДНЈЕФRDDЯрЦЅХф
ЃЈ3ЃЉЭЈЙ§sparkSessionЕФcreateDataFrameЗНЗЈЖдЕквЛВНЕФRDDгІгУ
schemaДДНЈDataFrame
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.
{IntegerType,
StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row,
SparkSession}
/**
* RDDзЊЛЛГЩDataFrame:ЭЈЙ§жИЖЈschemaЙЙНЈDataFrame
*/
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
//todo:1ЁЂДДНЈSparkSession,жИЖЈappNameКЭmaster
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//todo:2ЁЂЛёШЁsparkContextЖдЯѓ
val sc: SparkContext = spark.sparkContext
//todo:3ЁЂМгдиЪ§Он
val dataRDD: RDD[String] = sc.textFile
("d:\\person.txt")
//todo:4ЁЂЧаЗжУПвЛаа
val dataArrayRDD: RDD[Array[String]] = dataRDD.map
(_.split("
"))
//todo:5ЁЂМгдиЪ§ОнЕНRowЖдЯѓжа
val personRDD: RDD[Row] = dataArrayRDD.map(x=>Row(x(0).toInt,x(1),x(2).toInt))
//todo:6ЁЂДДНЈschema
val schema:StructType= StructType(Seq(
StructField("id", IntegerType, false),
StructField("name", StringType, false),
StructField("age", IntegerType, false)
))
//todo:7ЁЂРћгУpersonRDDгыschemaДДНЈDataFrame
val personDF: DataFrame = spark.createDataFrame
(personRDD,schema)
//todo:8ЁЂDSLВйзїЯдЪОDataFrameЕФЪ§ОнНсЙћ
personDF.show()
//todo:9ЁЂНЋDataFrameзЂВсГЩБэ
personDF.createOrReplaceTempView("t_person")
//todo:10ЁЂsqlгяОфВйзї
spark.sql("select * from t_person").show()
spark.sql("select count(*) from t_person").show()
sc.stop()
}
} |
2ЃЎБраДSpark SQLГЬађВйзїHiveContext
HiveContextЪЧЖдгІspark-hiveетИіЯюФП,гыhiveгаВПЗжёюКЯ, жЇГжhql,ЪЧSqlContextЕФзгРр,вВОЭЪЧЫЕМцШнSqlContext;
2.1ЃЎЬэМгpomвРРЕ
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.0.2</version>
</dependency>
|
2.2ЃЎДњТыЪЕЯж
package itcast.sql
import org.apache.spark.sql.SparkSession
/**
* todo:жЇГжhiveЕФsqlВйзї
*/
object HiveSupport {
def main(args: Array[String]): Unit = {
val warehouseLocation = "D:\\workSpace
_IDEA_NEW\\day2017-10-12\\spark-warehouse"
//todo:1ЁЂДДНЈsparkSession
val spark: SparkSession = SparkSession.builder()
.appName("HiveSupport")
.master("local[2]")
.config("spark.sql.warehouse.dir",
warehouseLocation)
.enableHiveSupport() //ПЊЦєжЇГжhive
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//ЩшжУШежОЪфГіМЖБ№
import spark.implicits._
import spark.sql
//todo:2ЁЂВйзїsqlгяОф
sql("CREATE TABLE IF NOT EXISTS person
(id int, name string, age int) row format delimited
fields
terminated by ' '")
sql("LOAD DATA LOCAL INPATH '/person.txt'
INTO TABLE person")
sql("select * from person ").show()
spark.stop()
}
} |
ЫФЁЂЪ§ОндД
1ЃЎJDBC
Spark SQLПЩвдЭЈЙ§JDBCДгЙиЯЕаЭЪ§ОнПтжаЖСШЁЪ§ОнЕФЗНЪНДДНЈDataFrameЃЌЭЈЙ§ЖдDataFrameвЛЯЕСаЕФМЦЫуКѓЃЌЛЙПЩвдНЋЪ§ОндйаДЛиЙиЯЕаЭЪ§ОнПтжаЁЃ
1.1ЃЎSparkSqlДгMySQLжаМгдиЪ§Он
1.1.1 ЭЈЙ§IDEAБраДSparkSqlДњТы
package itcast.sql
import java.util.Properties
import org.apache.spark.sql.{DataFrame,
SparkSession}
/**
* todo:SparksqlДгmysqlжаМгдиЪ§Он
*/
object DataFromMysql {
def main(args: Array[String]): Unit = {
//todo:1ЁЂДДНЈsparkSessionЖдЯѓ
val spark: SparkSession = SparkSession.builder()
.appName("DataFromMysql")
.master("local[2]")
.getOrCreate()
//todo:2ЁЂДДНЈPropertiesЖдЯѓЃЌЩшжУСЌНгmysql
ЕФгУЛЇУћКЭУмТы
val properties: Properties =new Properties()
properties.setProperty("user","root")
properties.setProperty("password","123456")
//todo:3ЁЂЖСШЁmysqlжаЕФЪ§Он
val mysqlDF: DataFrame = spark.read.jdbc("jdbc:mysql
://192.168.200.150:3306/spark","iplocaltion",properties)
//todo:4ЁЂЯдЪОmysqlжаБэЕФЪ§Он
mysqlDF.show()
spark.stop()
}
}
|
жДааВщПДаЇЙћЃК
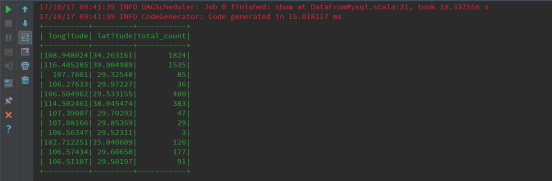
1.1.2 ЭЈЙ§spark-shellдЫаа
ЃЈ1ЃЉЁЂЦєЖЏspark-shell(БиаыжИЖЈmysqlЕФСЌНгЧ§ЖЏАќ)
spark-shell
\
--master spark://hdp-node-01:7077 \
--executor-memory 1g\
--total-executor-cores 2\
--jars /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar\
--driver-class-path/opt/bigdata/hive/lib/mysql
-connector-java-5.1.35.jar
|
ЃЈ2ЃЉЁЂДгmysqlжаМгдиЪ§Он
val mysqlDF
= spark.read.format("jdbc").options
(Map("url"
-> "jdbc:mysql://192.168.200.100:3306/spark",
"driver" -> "com.mysql.jdbc.Driver",
"dbtable" -> "iplocaltion",
"user" -> "root", "password"
-> "123456")).load() |
ЃЈ3ЃЉЁЂжДааВщбЏ

1.2ЃЎSparkSqlНЋЪ§ОнаДШыЕНMySQLжа
1.2.1 ЭЈЙ§IDEAБраДSparkSqlДњТы
ЃЈ1ЃЉБраДДњТы
package itcast.sql
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset,
SaveMode, SparkSession}
/**
* todo:sparksqlаДШыЪ§ОнЕНmysqlжа
*/
object SparkSqlToMysql {
def main(args: Array[String]): Unit = {
//todo:1ЁЂДДНЈsparkSessionЖдЯѓ
val spark: SparkSession = SparkSession.builder()
.appName("SparkSqlToMysql")
.getOrCreate()
//todo:2ЁЂЖСШЁЪ§Он
val data: RDD[String] = spark.sparkContext
.textFile(args(0))
//todo:3ЁЂЧаЗжУПвЛаа,
val arrRDD: RDD[Array[String]] = data.map(_.split("
"))
//todo:4ЁЂRDDЙиСЊStudent
val studentRDD: RDD[Student] = arrRDD.map
(x=>Student(x(0).
toInt,x(1),x(2).toInt))
//todo:ЕМШывўЪНзЊЛЛ
import spark.implicits._
//todo:5ЁЂНЋRDDзЊЛЛГЩDataFrame
val studentDF: DataFrame = studentRDD.toDF()
//todo:6ЁЂНЋDataFrameзЂВсГЩБэ
studentDF.createOrReplaceTempView("student")
//todo:7ЁЂВйзїstudentБэ ,АДееФъСфНјааНЕађХХСа
val resultDF: DataFrame = spark.sql("select
*
from student order by age desc")
//todo:8ЁЂАбНсЙћБЃДцдкmysqlБэжа
//todo:ДДНЈPropertiesЖдЯѓЃЌХфжУСЌНгmysqlЕФ
гУЛЇУћКЭУмТы
val prop =new Properties()
prop.setProperty("user","root")
prop.setProperty("password","123456")
resultDF.write.jdbc("jdbc:mysql://192.168.200.150:3306/
spark","student",prop)
//todo:аДШыmysqlЪБЃЌПЩвдХфжУВхШыmodeЃЌoverwriteИВИЧЃЌ
appendзЗМгЃЌ
ignoreКіТдЃЌerrorФЌШЯБэДцдкБЈДэ
//resultDF.write.mode(SaveMode.Overwrite).jdbc
("jdbc:mysql://192.168.200.150:3306/spark",
"student",prop)
spark.stop()
}
}
//todo:ДДНЈбљР§РрStudent
case class Student(id:Int,name:String,age:Int)
|
ЃЈ2ЃЉгУmavenНЋГЬађДђАќ
ЭЈЙ§IDEAЙЄОпДђАќМДПЩ
ЃЈ3ЃЉНЋJarАќЬсНЛЕНsparkМЏШК
spark-submit
\
--class itcast.sql.SparkSqlToMysql \
--master spark://hdp-node-01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
--jars/opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar
\
--driver-class-path /opt/bigdata/hive/lib/mysql-connector-java-5.1.35.jar\
/root/original-spark-2.0.2.jar /person.txt
|

ЃЈ4ЃЉВщПДmysqlжаБэЕФЪ§Он
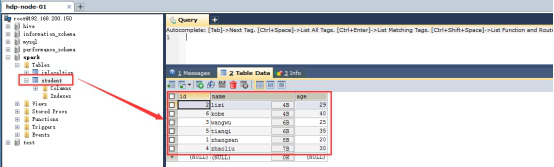
|









