| БрМЭЦМі: |
БОЮФжївЊЯђЖСепУЧНщЩмSequoiaDBЃЈЗжВМЪНДцДЂЃЉКЭSparkЃЈЗжВМЪНМЦЫуЃЉСНПюВњЦЗЕФЖдНгЪЙгУЃЌвдМАНщЩмдкКЃСПЪ§ОнГЁОАЯТШчКЮЬсИпЭГМЦЗжЮіадФмЁЃ
БОЮФРДздSequoiaDBЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
дкЕБЧАЦѓвЕЩњВњЪ§ОнХђеЭЕФЪБДњЃЌЪ§ОнМДЪЙЦѓвЕЕФМлжЕЫљдкЃЌвВЪЧвЛМвЦѓвЕЕФММЪѕЬєеНЫљдкЁЃЫљвддкКЃСПЪ§ОнДІРэГЁОАЩЯЃЌШЫУЧвтЪЖЕНЕЅЛњМЦЫуФмСІдйЧПвВЮоЗЈТњзуШевцдіГЄЕФЪ§ОнДІРэашЧѓЃЌЗжВМЪНВХЪЧНтОіИУРрЮЪЬтЕФИљБОНтОіЗНАИЁЃ
ЖјдкЗжВМЪНСьгђЃЌгаСНРрВњЦЗЪЧжСЙиживЊЕФЃЌЗжБ№ЗжВМЪНДцДЂКЭЗжВМЪНМЦЫуЃЌгУЛЇжЛгаНЋСНепЕФЬиадГфЗжРћгУЃЌВХПЩвдеце§ЗЂЛгЗжВМЪНМмЙЙЕФДцДЂКЭМЦЫуФмСІЁЃ
SequoiaDBНщЩм
SequoiaDBЪЧЙњФкЮЊЪ§ВЛЖрЕФзджїбаЗЂЕФЗжВМЪНЪ§ОнПтЃЌЬиЕуЪЧЭЌЪБжЇГжЮФЕЕДцДЂКЭПщДцДЂЃЌжЇГжБъзМSQLКЭЪТЮёЙІФмЃЌжЇГжИДдгЫїв§ВщбЏЁЂгыHadoopЁЂHiveЁЂSparkЖМгаНЯЩюЖШЕФМЏГЩЁЃФПЧАSequoiaDBвбОдкGithubПЊдДЁЃ
SequoiaDBдкЗжВМЪНДцДЂЙІФмЩЯЃЌНЯвЛАуЕФДѓЪ§ОнВњЦЗЬсЙЉИќЖрЕФЪ§ОнЧаЗжЙцдђЃЌАќРЈЃКЫЎЦНЧаЗжЁЂЗЖЮЇЧаЗжЁЂЖрЮЌЗжЧјЃЈРрЫЦpartitionЗжЧјЃЉКЭЖрЮЌЧаЗжЗНЪНЃЌгУЛЇПЩвдИљОнВЛгУЕФГЁОАбЁдёЯргІЕФЧаЗжЗНЪНЃЌвдЬсИпЯЕЭГЕФДцДЂФмСІКЭВйзїадФмЁЃ
Spark НщЩм
Spark НќФъРДЗЂеЙЬиБ№бИУЭЃЌЬиБ№дке§ЪНЗЂВМSpark 1.0
АцБОКѓЃЌЕУЕНСЫжкЖрЙшЙШОоЭЗжЇГжЃЌР§ШчЃКClouderaЁЂIBMЁЂHortonworksЁЂIntelЕШЃЌЖјЧвдкSpark
2.0аћВМжЇГжTPC-DS99КѓЃЌЪЙгУSparkSQLзіДѓЪ§ОнДІРэКЭЗжЮіЕФПЊЗЂепдНРДдНЖрЃЌПЩвддЄМћЃЌSparkНЋЛсГЩЮЊМЬHadoopжЎКѓзюживЊКЭСїааЕФЗжВМЪНМЦЫуПђМмЁЃ
SparkSQLНщЩм
SparkSQLЪЧSparkВњЦЗжавЛИізщГЩВПЗжЃЌSQLЕФжДаав§ЧцЪЙгУSparkЕФRDDКЭDataframeЪЕЯжЁЃФПЧАSparkSQLвбОПЩвдЭъећдЫааTPC-DS99ВтЪдЃЌБъжОзХSparkSQLдкЪ§ОнЗжЮіКЭЪ§ОнДІРэГЁОАЩЯММЪѕНјвЛВНГЩЪьЁЃ
SparkSQLКЭСэЭтвЛПюСїааЕФДѓЪ§ОнSQLВњЦЗ--HiveгаЯрЫЦжЎДІЃЌР§ШчСНепЖМЪЙгУThriftserverзїЮЊJDBCЗўЮёЃЌСНИіВњЦЗЖМЪЙгУЯрЭЌЕФmetadataДњТыЃЈЪЕМЪЩЯSparkSQLИДгУСЫHiveЕФmetadataДњТыЃЉЁЃЕЋЪЧСНПюВњЦЗЛЙЪЧгаБОжЪЩЯЕФЧјБ№ЃЌзюДѓЕФВЛЭЌЕудкгкжДаав§ЧцЃЌHiveФЌШЯжЇГжHadoopКЭTezМЦЫуПђМмЃЌЖјSparkSQLжЛжЇГжSpark
RDDМЦЫуПђМмЃЌЕЋЪЧSparkSQLЕФгЕгаИќМгЩюЖШЕФжДааМЦЛЎгХЛЏКЭДІРэв§ЧцгХЛЏЁЃ
SparkSQLгыSequoiaDBећКЯ
дРэНщЩм
СЫНтSparkММЪѕдРэЕФЖСепУЧгІИУЧхГўЃЌSparkБОЩэЪЧвЛПюЗжВМЪНМЦЫуПђМмЁЃЫќВЛЯёHadoopвЛбљЃЌЭЌЪБЮЊПЊЗЂепЬсЙЉЗжВМЪНМЦЫуКЭЗжВМЪНДцДЂЃЌЖјЪЧПЊЗХСЫДцДЂВуЕФПЊЗЂНгПкЃЌжЛвЊПЊЗЂепАДееSparkЕФНгПкЙцЗЖЪЕЯжСЫНгПкЗНЗЈЃЌШЮКЮДцДЂВњЦЗЖМПЩвдГЩЮЊSparkЪ§ОнМЦЫуЕФРДдДЃЌЭЌЪБвВАќРЈSparkSQLЕФЪ§ОнРДдДЁЃ
SequoiaDBЪЧвЛПюЗжВМЪНЪ§ОнПтЃЌФмЙЛЮЊгУЛЇДцДЂКЃСПЕФЪ§ОнЃЌЕЋЪЧШчЙћвЊЖдКЃСПЪ§ОнзіЭГМЦЁЂЗжЮіЃЌЛЙЪЧашвЊНшжњЗжВМЪНМЦЫуПђМмЕФВЂЗЂМЦЫуадФмЃЌЬсИпМЦЫуаЇТЪЁЃ
ЫљвдSequoiaDBЮЊSparkПЊЗЂСЫSequoiaDB for
SparkЕФСЌНгЦїЃЌШУSparkжЇГжДгSequoiaDBжаВЂЗЂЛёШЁЪ§ОнЃЌдйЭъГЩЯргІЕФЪ§ОнМЦЫуЁЃ
ЖдНгЗНЪН
SparkКЭSequoiaDBЖдНгЗНЪНБШНЯМђЕЅЃЌгУЛЇжЛвЊНЋSequoiaDB for Spark
СЌНгЦїspark-sequoiadb.jar КЭSequoiaDBЕФjava Ч§ЖЏsequoiadb.jar
МгШыЕНУПИіSpark WorkerЕФCLASSPATH жаМДПЩЁЃ
Р§ШчЃЌгУЛЇЯЃЭћSparkSQLЖдНгЕНSequoiaDBЃЌПЩвдЮЊspark-env.sh ХфжУЮФМўжадіМгSPARK_CLASSPATHВЮЪ§ЃЌШчЙћИУВЮЪ§вбОДцдкЃЌдђНЋаТjar
АќЬэМгЕНSPARK_CLASSPATH ВЮЪ§ЩЯЃЌШчЃК
SPARK_CLASSPATH="/media/psf/mnt/sequoiadb-driver-2.9.0-SNAPSHOT.jar:/media/psf/mnt/spark-sequoiadb_2.11-2.9.0-SNAPSHOT.jar"
гУЛЇаоИФЭъspark-env.sh ХфжУКѓЃЌжиЦєspark-sql
Лђеп thriftserver ОЭЭъГЩСЫSparkКЭSequoiaDBЕФЖдНгЁЃ
SparkSQL+SequoiaDBадФмгХЛЏ
Spark SQL+SequoiaDBЕФадФмгХЛЏНЋЛсДгconnector
МЦЫуММЪѕдРэЁЂSparkSQLгХЛЏЁЂSequoiaDBгХЛЏКЭconnectorВЮЪ§гХЛЏ4ИіЗНУцНјааНщЩмЁЃ
SequoiaDB for SparkSQL connectorНщЩм
1ЃЉconnectorЙЄзїдРэ
SparkВњЦЗЫфШЛЮЊгУЛЇЬсЙЉСЫЖржжЙІФмФЃПщЃЌЕЋЪЧЖМжЛЪЧЪ§ОнМЦЫуЕФЙІФмФЃПщЁЃSparkВњЦЗБОЩэУЛгаШЮКЮЕФДцДЂЙІФмЃЌдкФЌШЯЧщПіЯТЃЌSparkЪЧДгБОЕиЮФМўЗўЮёЦїЛђепHDFSЩЯЖСШЁЪ§ОнЁЃЖјSparkвВНЋЫќгыДцДЂВуЕФНгПкПЊЗХИјЙуДѓПЊЗЂепЃЌПЊЗЂепжЛвЊАДееSparkНгПкЙцЗЖЪЕЯжЦфДцДЂВуСЌНгЦїЃЌШЮКЮЪ§ОндДОљПЩГЦЮЊSparkМЦЫуЕФЪ§ОнРДдДЁЃ
ЯТЭМЮЊSpark workerгыДцДЂВужаdatanodeЕФЙиЯЕЁЃ
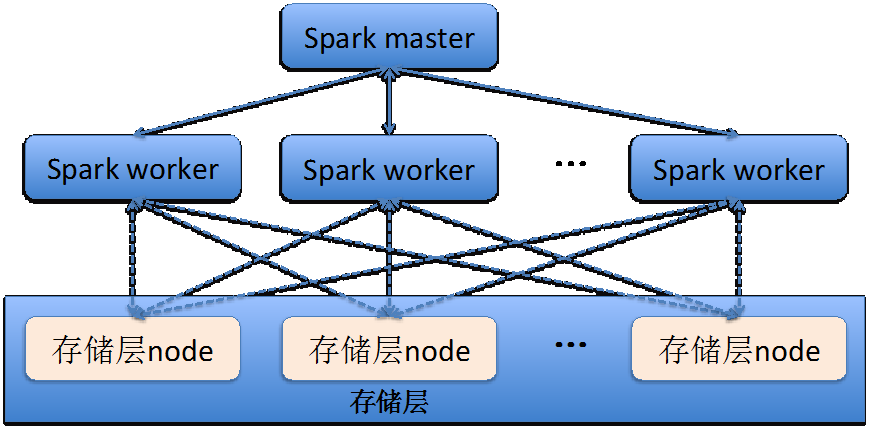
SparkМЦЫуПђМмгыДцДЂВуЕФЙиЯЕЃЌПЩвдДгЯТЭМжаСЫНтЦфдРэЁЃ
Spark masterдкНгЪеЕНвЛИіМЦЫуШЮЮёКѓЃЌЪзЯШЛсгыДцДЂВузівЛДЮЭЈбЖЃЌДгДцДЂВуЕФЗУЮЪПьееЛђепЪЧДцДЂЙцЛЎжаЃЌЕУЕНБОДЮМЦЫуШЮЮёЫљЩшМЦЕФЫљгаЪ§ОнЕФДцДЂЧщПіЁЃДцДЂВуЗЕЛиИјSpark
masterЕФНсЙћЮЊЪ§ОнДцДЂЕФpartitionЖгСаЁЃ
ШЛКѓSpark masterЛсНЋЪ§ОнДцДЂЕФpartitionЖгСажаЕФpartitionж№ИіЗжХфИјИјSpark
workerЁЃSpark workдкНгЪеЕНЪ§ОнЕФpartitionаХЯЂКѓЃЌОЭФмЙЛСЫНтШчКЮЛёШЁМЦЫуЪ§ОнЁЃШЛКѓSpark
workЛсжїЖЏгыДцДЂВуЕФnodeНкЕуНјааСЌНгЃЌЛёШЁЪ§ОнЃЌдйНсКЯSpark masterЯТЗЂИјSpark
workerЕФМЦЫуШЮЮёЃЌПЊЪМЪ§ОнМЦЫуЙЄзїЁЃ
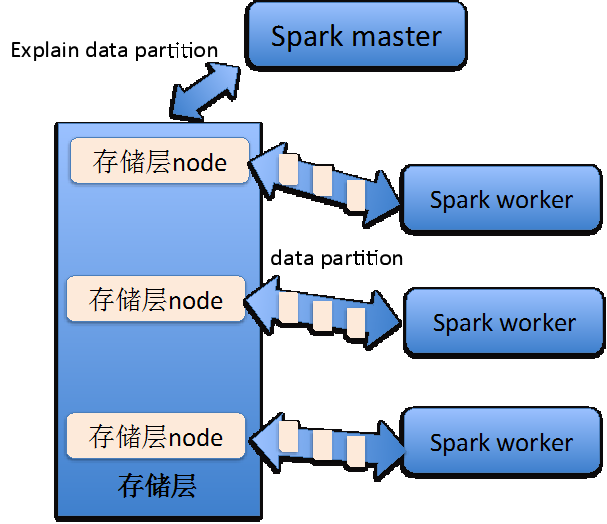
SequoiaDB for SparkЕФСЌНгЦїЕФЪЕЯждРэКЭЩЯЪіУшЪіЛљБОвЛжТЃЌжЛЪЧдкЩњГЩЪ§ОнМЦЫуЕФpartitionШЮЮёЪБЃЌСЌНгЦїЛсИљОнSparkЯТбЙЕФВщбЏЬѕМўЕНSequoiaDBжаЩњГЩВщбЏМЦЛЎЁЃ
ШчЙћSequoiaDBФмЙЛИљОнВщбЏЬѕМўзіЫїв§ЩЈУшЃЌСЌНгЦїЩњГЩЕФpartitionШЮЮёНЋЪЧШУSpark
workжБНгСЌНгSequoiaDBЕФЪ§ОнНкЕуЁЃ
ШчЙћSequoiaDBЮоЗЈИљОнВщбЏЬѕМўзіЫїв§ЩЈУшЃЌСЌНгЦїНЋЛёШЁЯрЙиЪ§ОнБэЕФЫљгаЪ§ОнПщаХЯЂЃЌШЛКѓИљОнpartitionblocknumКЭpartitionmaxnumВЮЪ§ЩњГЩАќКЌШєИЩИіЪ§ОнПщСЌНгаХЯЂЕФpartititonМЦЫуШЮЮёЁЃ
2ЃЉconnectorВЮЪ§ЫЕУї
SequoiaDB for Spark СЌНгЦїдкSequoiaDB 2.10жЎКѓНјааСЫжиЙЙЃЌЬсИпSparkВЂЗЂДгSequoiaDBЛёШЁЪ§ОнЕФадФмЃЌВЮЪ§вВгаЯргІЕФЕїећЁЃ
гУЛЇдкSparkSQLЩЯДДНЈЪ§ОндДЮЊSequoiaDBЕФtableЃЌНЈБэФЃАцШчЯТЃК
| create [temporary]
<table|view> <name>[(schema)] using
com.sequoiadb.spark options (<options>); |
SparkSQLДДБэУќСюЕФЙиМќзжНщЩмЃК
1. temporary ЙиМќзжЃЌДњБэИУБэЛђепЪгЭМЪЧЗёЮЊСкЪБДДНЈЕФЃЌШчЙћгУЛЇБъМЧСЫtemporary
ЙиМќзжЃЌдђИУБэЛђепЪгЭМдкПЭЛЇЖЫжиЦєКѓНЋздЖЏБЛЩОГ§ЃЛ
2. НЈБэЪБгУЛЇПЩвдбЁдёВЛжИЖЈБэНсЙЙЃЌвђЮЊШчЙћгУЛЇВЛЯдЪНжИЖЈБэНсЙЙЃЌSparkSQLНЋдкНЈБэЪБздЖЏМьВтвбОДцдкЪ§ОнЕФБэНсЙЙЃЛ
3. com.sequoiadb.spark ЙиМќзжЮЊSequoiaDB for Spark connector
ЕФШыПкРрЃЛ
4. options ЮЊSequoiaDB for Spark connectorЕФХфжУВЮЪ§ЃЛ
SparkSQLНЈБэР§згШчЯТЃК
| create table
tableName (name string, id int) using com.sequoiadb.spark
options (host 'sdb1:11810,sdb2:11810,sdb3:11810',
collectionspace 'foo', collection 'bar', username
'sdbadmin', password 'sdbadmin'); |
SparkSQL for SequoiaDBЕФНЈБэoptionsВЮЪ§СаБэШчЯТЃК
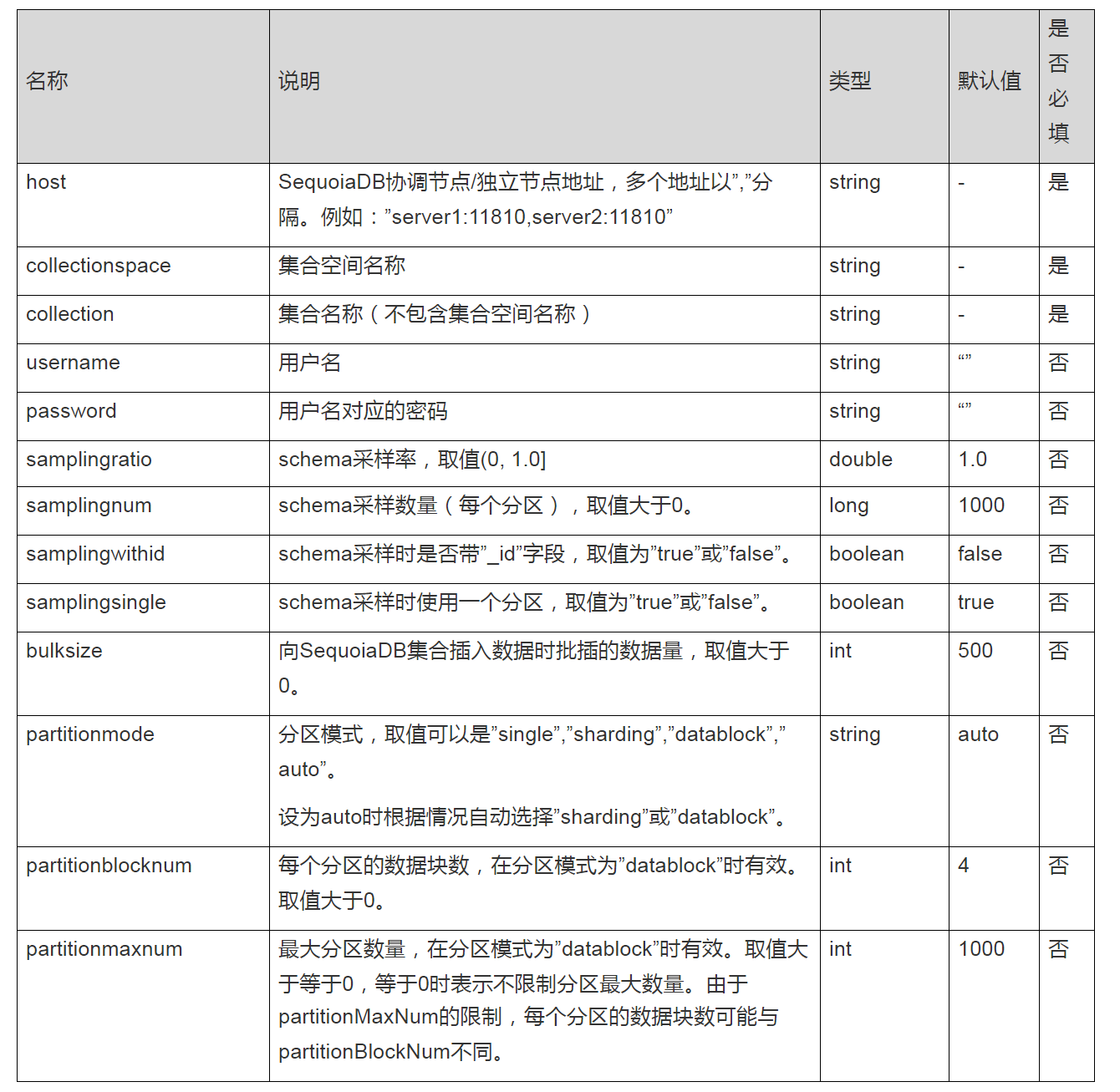
SparkSQLгХЛЏ
гУЛЇШчЙћвЊЪЙгУSparkSQLЖдКЃСПЪ§ОнзіЭГМЦЗжЮіВйзїЃЌФЧУДгІИУДг3ИіЗНУцНјааадФмЕїгХ
1. ЕїДѓSpark Worker зюДѓПЩгУФкДцДѓаЁЃЌЗРжЙдкМЦЫуЙ§ГЬжаЪ§ОнГЌГіФкДцЗЖЮЇЃЌашвЊНЋВПЗжЪ§ОнаДШыЕНСйЪБЮФМўЩЯЃЛ
2. діМгSpark Worker Ъ§ФПЃЌВЂЧвЩшжУУПИіWorkerОљПЩвдЪЙгУЕБЧАЗўЮёЦїзѓгвCPUзЪдДЃЌвдЬсИпВЂЗЂФмСІЃЛ
3. ЕїећSparkЕФдЫааВЮЪ§ЃЛ
гУЛЇПЩвдЖдspark-env.sh ХфжУЮФМўНјааЩшжУЃЌSPARK_WORKER_MEMORYЮЊПижЦWorkerПЩгУФкДцЕФВЮЪ§ЃЌSPARK_WORKER_INSTANCESЮЊУПЬЈЗўЮёЦїЦєЖЏЖрЩйИіWorkerЕФВЮЪ§ЁЃ
ШчЙћгУЛЇашвЊЕїећSparkЕФдЫааВЮЪ§ЃЌдђгІИУаоИФspark-defaults.conf ХфжУЮФМўЃЌЖдгХЛЏКЃСПЪ§ОнЭГМЦМЦЫугаНЯУїЯдЬсЩ§ЕФВЮЪ§га
1) spark.storage.memoryFractionЃЌИУВЮЪ§ПижЦWorkerЖрЩйФкДцБШР§гУЛЇДцДЂСйЪБМЦЫуЪ§ОнЃЌФЌШЯЮЊ0.6ЃЌДњБэ60%ЕФКЌвхЃЛ
2) spark.shuffle.memoryFractionЃЌИУВЮЪ§ПижЦМЦЫуЙ§ГЬжаshuffleЪБФмЙЛеМгУУПИіWorkerЕФФкДцБШР§ЃЌФЌШЯЮЊ0.2ЃЌДњБэ20%ЕФКЌвхЃЌШчЙћСйЪБДцДЂЕФМЦЫуЪ§ОнНЯЩйЃЌЖјМЦЫужагаНЯЖрЕФgroup
byЁЂsortЁЂjoinЕШВйзїЃЌгІИУПМТЧНЋspark.shuffle.memoryFraction
ЕїДѓЃЌspark.storage.memoryFractionЕїаЁЃЌБмУтГЌГіФкДцВПЗжашвЊаДШыСйЪБЮФМўжаЃЛ
3) spark.serializerЃЌИУВЮЪ§ЩшжУSparkдкдЫааЪБЪЙгУФФжжађСаЛЏЗНЗЈЃЌФЌШЯЮЊorg.apache.spark.serializer.JavaSerializerЃЌЕЋЪЧЮЊСЫЬсЩ§адФмЃЌгІИУбЁдёorg.apache.spark.serializer.KryoSerializer
ађСаЛЏ
SequoiaDBгХЛЏ
SparkSQL+SequoiaDBетжжзщКЯЃЌгЩгкЪ§ОнЖСШЁЪЧДгSequoiaDBжаНјааЃЌЫљвддкадФмгХЛЏгІИУПМТЧШ§Еу
1. ОЁПЩФмНЋДѓБэЕФЪ§ОнЗжВМЪНДцДЂЃЌЫљвдНЈвщЗћКЯЖўЮЌЧаЗжЬѕМўЕФtableгІИУВЩгУЖрЮЌ+HashЧаЗжСНжжЪ§ОнОљКтЗНЪННјааЪ§ОнЗжВМЪНДцДЂЃЛ
2. Ъ§ОнЕМШыЪБЃЌгІИУБмУтЭЌЪБЖдЯрЭЌМЏКЯПеМфЕФЖрИіМЏКЯзіЪ§ОнЕМШыЃЌвђЮЊЭЌвЛИіМЏКЯПеМфЯТЕФЖрИіМЏКЯЪЧЙВгУЯрЭЌвЛИіЪ§ОнЮФМўЃЌШчЙћЭЌЪБЯђЯрЭЌМЏКЯПеМфЕФЖрИіМЏКЯзіЪ§ОнЕМШыЃЌЛсЕМжТУПИіМЏКЯЯТЕФЪ§ОнПщДцДЂЙ§гкРыЩЂЃЌДгЖјЕМжТдкSpark
SQLДгSequoiaDBЛёШЁКЃСПЪ§ОнЪБЃЌашвЊЖСШЁЕФЪ§ОнПщЙ§ЖрЃЛ
3. ШчЙћSparkSQLЕФВщбЏУќСюжаАќКЌВщбЏЬѕМўЃЌгІИУЖдгІЕидкSequoiaDBжаНЈСЂЖдгІзжЖЮЕФЫїв§ЃЛ
connectorгХЛЏ
SequoiaDB for Spark СЌНгЦїЕФВЮЪ§гХЛЏЃЌжївЊЗжСНИіГЁОАЃЌвЛЪЧЪ§ОнЖСЃЌСэЭтвЛИіЪЧЪ§ОнаДШыЁЃ
Ъ§ОнаДШыЕФгХЛЏПеМфНЯЩйЃЌжЛгавЛИіВЮЪ§ПЩвдЕїећЃЌМДbulksizeВЮЪ§ЃЌИУВЮЪ§ФЌШЯжЕЮЊ500ЃЌДњБэСЌНгЦїЯђSequoiaDBаДШыЪ§ОнЪБЃЌвд500ЬѕМЧТМзщГЩвЛИіЭјТчАќЃЌдйЯђSequoiaDBЗЂЫЭаДШыЧыЧѓЃЌЭЈГЃЩшжУbulksizeВЮЪ§ЃЌвдвЛИіЭјТчАќВЛГЌЙ§2MBЮЊзМЁЃ
Ъ§ОнЖСШЁЕФВЮЪ§гХЛЏЃЌгУЛЇдђашвЊЙизЂpartitionmodeЁЂpartitionblocknumКЭpartitionmaxnumШ§ИіВЮЪ§ЁЃ
partitionmodeЃЌСЌНгЦїЕФЗжЧјФЃЪНЃЌПЩбЁжЕгаsingleЁЂshardingЁЂdatablockЁЂautoЃЌФЌШЯжЕЮЊautoЃЌДњБэСЌНгЦїжЧФмЪЖБ№ЁЃ
1. singleжЕДњБэSparkSQLдкЗУЮЪSequoiaDBЪ§ОнЪБЃЌВЛПМТЧВЂЗЂадФмЃЌжЛгУвЛИіЯпГЬСЌНгSequoiaDBЕФCoordНкЕуЃЌвЛАуИУВЮЪ§дкНЈБэзіБэНсЙЙЪ§ОнГщбљЪБВЩгУЃЛ
2. shardingжЕДњБэSparkSQLЗУЮЪSequoiaDBЪ§ОнЪБЃЌВЩгУжБНгСЌНгSequoiaDBИїИіdatanodeЕФЗНЪНЃЌИУВЮЪ§вЛАуВЩгУдкSQLУќСюАќКЌВщбЏЬѕМўЃЌВЂЧвИУВщбЏПЩвддкSequoiaDBжаЪЙгУЫїв§ВщбЏЕФГЁОАЃЛ
3. datablockжЕДњБэSparkSQLЗУЮЪSequoiaDBЪ§ОнЪБЃЌВЩгУВЂЗЂСЌНгSequoiaDBЕФЪ§ОнПщНјааЪ§ОнЖСШЁЃЌИУВЮЪ§вЛАуЪЙгУдкSQLУќСюЮоЗЈдкSequoiaDBжаЪЙгУЫїв§ВщбЏЃЌВЂЧвВщбЏЕФЪ§ОнСПНЯДѓЕФГЁОАЃЛ
4. autoжЕДњБэSparkSQLдкЯђSequoiaDBВщбЏЪ§ОнЪБЃЌЗУЮЪSequoiaDBЕФЗНЪННЋгЩСЌНгЦїИљОнВЛЭЌЕФЧщПіЗжЮіОіЖЈЃЛ
partitionblocknumЃЌИУВЮЪ§жЛгадкpartitionmode=datablockЪБВХЛсЩњаЇЃЌДњБэУПИіWorkerдкзіЪ§ОнМЦЫуЪБЃЌвЛДЮЛёШЁЖрЩйИіSequoiaDBЪ§ОнПщЖСШЁШЮЮёЃЌИУВЮЪ§ФЌШЯжЕЮЊ4ЁЃШчЙћSequoiaDBжаДцДЂЕФЪ§ОнСПНЯДѓЃЌМЦЫуЪБЩцМАЕНЕФЪ§ОнПщНЯЖрЃЌгУЛЇгІИУЕїДѓИУВЮЪ§ЃЌЪЙЕУSparkSQLЕФМЦЫуШЮЮёБЃГждквЛИіКЯРэЗЖЮЇЃЌЬсИпЪ§ОнЖСШЁаЇТЪЁЃ
partitionmaxnumЃЌИУВЮЪ§жЛгадкpartitionmode=datablockЪБВХЛсЩњаЇЃЌДњБэСЌНгЦїзюЖрФмЙЛЩњГЩЖрЩйИіЪ§ОнПщЖСШЁШЮЮёЃЌИУВЮЪ§ЕФФЌШЯжЕЮЊ1000ЁЃИУВЮЪ§жївЊЪЧЮЊСЫБмУтгЩгкSequoiaDBжаЕФЪ§ОнСПЙ§ДѓЃЌЕМжТзмЕФЪ§ОнПщЪ§СПЬЋДѓЃЌДгЖјЕМжТSparkSQLЕФМЦЫуШЮЮёЙ§ЖрЃЌЖјЕМжТзмЬхМЦЫуадФмЯТНЕЁЃ
змНс
БОЮФДгSparkЁЂSequoiaDBвдМАSequoiaDB for Spark connectorШ§ИіЗНУцЯђЖСепУЧНщЩмСЫКЃСПЪ§ОнЯТЪЙгУSparkSQL+SequoiaDBЕФадФмЕїгХЗНЗЈЁЃ
ЮФеТжаНщЩмЕФЗНЗЈОпгавЛЖЈЕФВЮПМвтвхЃЌЕЋЪЧадФмЕїгХвЛжБЖМЪЧзюПМбщММЪѕШЫдБЕФЙЄзїЁЃММЪѕШЫдБдкЖдЗжВМЪНЛЗОГзіадФмЕїгХЪБЃЌашвЊзлКЯПМТЧЖрИіЗНУцЕФЪ§ОнЃЌР§ШчЃКЗўЮёЦїЕФгВМўзЪдДЪЙгУЧщПіЁЂSparkдЫаазДПіЁЂSequoiaDBЪ§ОнЗжВМЪЧЗёКЯРэЁЂСЌЛњЦїЕФВЮЪ§ЩшжУЪЧЗёе§ШЗЁЂSQLУќСюЪЧЗёгаЕїгХЕФПеМфЕШЃЌвЊЯыадФмЬсЩ§ЃЌжиЕуЪЧвЊЧѓММЪѕШЫдБевЕНећИіЯЕЭГжаЕФадФмЖЬАхЃЌШЛКѓЭЈЙ§ЕїећВЛЭЌЕФВЮЪ§ЛђепаоИФДцДЂЗНАИЃЌДгЖјШУЯЕЭГдЫааЕУИќМгИпаЇЁЃ
|









