| 编辑推荐: |
文章主要记录了一个 Agent 开发初学者,跟着 Datawhale 的 Hello-Agent 教程一步步学习和实践的过程,希望对你的学习有帮助。
本文来自于微信公众号Datawhale,由火龙果软件Alice编辑,推荐。 |
|
写在最前:这篇文章记录了我作为一个 Agent 开发初学者,跟着 Datawhale 的 Hello-Agent 教程一步步学习和实践的过程。文中提到的很多实现方案可能并不完美,甚至可能存在更好的做法,但这些都是我真真切切踩过的坑、流过的汗。
如果你也是刚开始接触 Agent 开发,希望这篇笔记能给你一些参考;如果你已经是大佬,还请不吝赐教。
文中代码和文档地址:
https://github.com/YYHDBL/MyCodeAgent.git
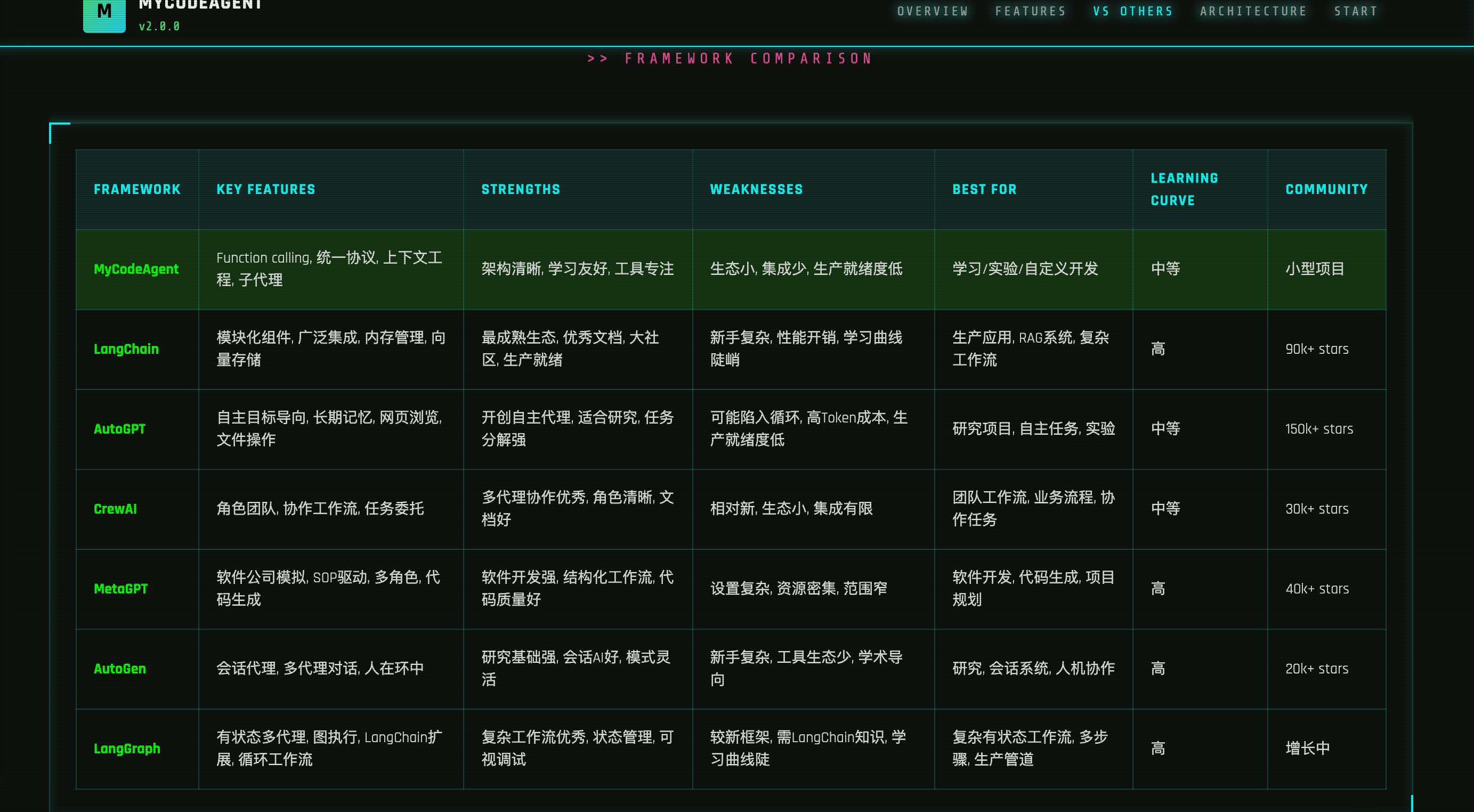
一、为什么我要自己做一个 Code Agent
这两年 AI 编程助手火得一塌糊涂。
Claude Code、 GitHub Copilot、 Cursor 、Codex……工具一个比一个强。 用自然语言描述需求,它就能写代码、改 Bug、跑测试,甚至帮你排查那些以前要绞尽脑汁的线上问题。
有意思的是, Anthropic 、OpenAI 这些前沿团队也在持续公开他们的 Agent 构建经验。虽然他们的模型在国内有门槛,但 Engineering Blog 我一直在追。每次读完都很上头——你会发现,真正拉开差距的不是"提示词写得多花",而是 工程设计是否扎实 。
看了这么多,手痒了。
正好,Datawhale 的 Hello-Agent 教程最后有一个毕业设计: 用学到的知识,做一个自己的智能体应用。
我当时就想,既然日常高强度在用各种 Code Agent,不如就做一个自己的。
说白了,自己手搓一遍,才能真正理解这些产品为什么好用,以及它们到底在工程上做对了什么。
二、先跑起来!用 Hello-Agent 骨架搭出第一个能用的 Code Agent
有了方向,我没急着追什么"最优架构"。
先给自己定了一个很接地气的目标: 用户说一句需求,Agent 能自己去仓库里找证据,给出改动方案,输出补丁,我确认后能真正落盘。
说白了,我要的不是一个会聊天的 Demo,而是一个 能干活的 CLI 。
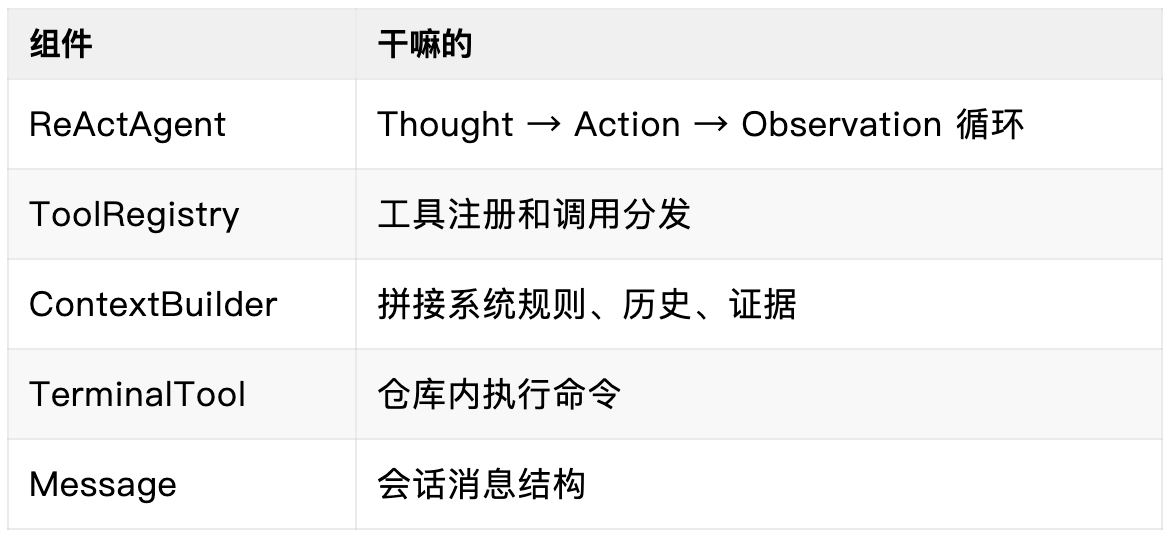
Hello-Agent 的底子正好够用—— ReActAgent 、ToolRegistry、ContextBuilder 这些核心组件都是现成的。我的策略很简单: 先复用,再改造 。
最初版本的Code Agent代码仓库:
https://github.com/YYHDBL/HelloCodeAgentCli.git
1、起手式:先复用,再改造
我的动作很克制——直接复用 Hello-Agent 的主干,把最短链路先跑通。
核心组件就这几块:
代码层面,我直接在 code_agent.py 里把它们攒起来:
self.terminal_tool = TerminalTool(
workspace=str(self.paths.repo_root),
timeout=60,
confirm_dangerous=True,
default_shell_mode=True, # 注意这个
)
self.registry = ToolRegistry()
self.registry.register_tool(self.terminal_tool)
|
这里有两个关键决策,后面都成了坑:
第一, default_shell_mode=True 。
我当时想的是"先把能力放开",让模型能直接写复杂 shell,效率优先。
第二,工具堆得挺满。
不光有 terminal ,我还把 todo 、 note 、 plan 、 context_fetch 一股脑塞进去,想让它从第一天就能处理连续任务。
现在回头看,这个取舍挺典型 —— 能力上限先拉高,控制边界后补 。
2、V0 怎么算"能用"?我定了四条
不是看"回答像不像人",而是看这四件事能不能连续跑通:
- 能稳定多步 —— 不是一句话就结束;
- 能在仓库找证据 —— 目录、文件、代码片段;
- 能给可执行的补丁 —— 不停在口头建议;
- 改动可控 —— 能确认、能备份、能撤回。
为了防跑飞,我给 ReAct 加了最基础的保险:
self.react = ReActAgent(
name="code_agent",
llm=self.llm,
tool_registry=self.registry,
max_steps=20, # 最多跑 20 步
observation_summarizer=_summarize_observation,
summarize_threshold_chars=1800,
)
|
max_steps=20 + observation 摘要,当时救了我不少次。
为啥?工具输出一旦太长,下一步提示词就会变脏,模型很容易跑偏。这套配置后来肯定不够,但 V0 阶段,它让问题 可复现、可调试 。
3、单轮流程:土,但管用
我当时最担心:每轮都走完整流程会不会太慢、太贵、太容易失控?
所以没搞"所有输入一股脑丢给 ReAct",而是先分流:
# 闲聊直接短路,不浪费 Token
if self._is_chitchat(user_input):
return direct_response
# 构建上下文,走主流程
context_text = self.context_builder.build_base(...)
response = self.react.run(context_text, max_tokens=8000)
# 历史只留最近 50 条,粗暴但有效
if len(self.history) > 50:
self.history = self.history[-50:]
|
三件小事,当时觉得挺实用:
- 闲聊直接短路,省 Token;
- 检测到"分步/计划"关键词,轻量提示让模型先用 todo ;
- 历史粗暴截断,先控住上下文规模。
你会发现,这套思路已经在往"上下文工程"靠了,只是还比较轻。后面我会彻底重做这部分。
4、最关键的一步:补丁必须能落地
很多 Agent 演示到"建议修改"就结束了。
我明确不接受这种"嘴上会改"的状态,从第一天就把补丁执行链路接上了:
# 从模型回复里提取补丁
patch_text = _extract_patch(response)
if not patch_text:
continue # 没补丁,继续聊
# 危险操作要确认
if _patch_requires_confirmation(patch_text):
if input("confirm> ").strip().lower() not in {"y", "yes"}:
continue
# 执行
res = patch_executor.apply(patch_text)
|
真正保安全的是执行器,它有几条硬规矩:
- 临时文件 + 原子写入,不半写;
- 自动备份,能撤回;
- 限制单次改动规模;
- 解析失败直接中断,不瞎猜。
这让 V0 至少有个底线: 改动是可追、可控、可撤回的 。
5、兴奋和坑,一起来了
V0 刚跑起来那几天,确实挺爽。
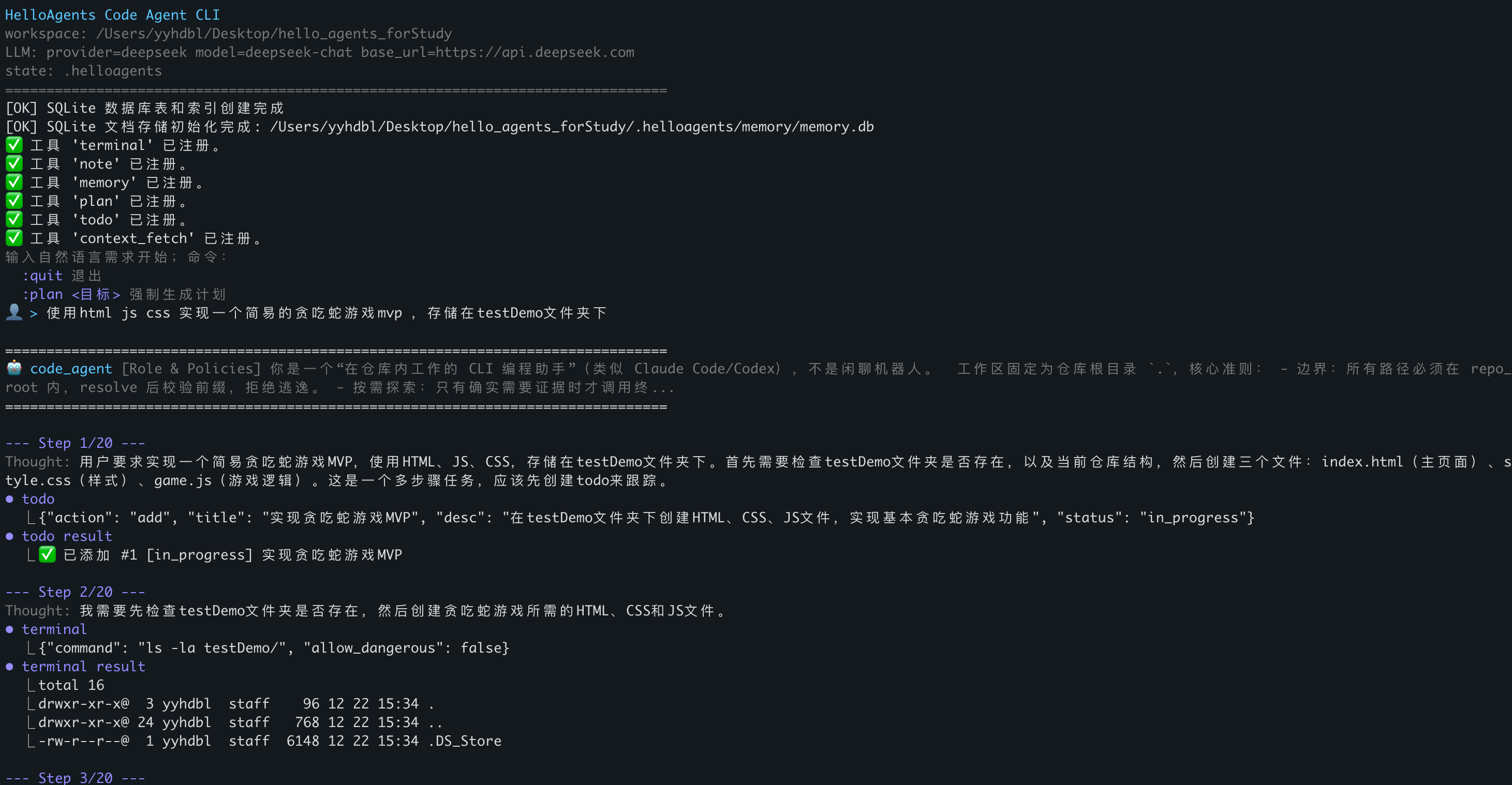
"看结构 → 搜代码 → 给补丁 → 落盘"这条链路能通,而且通得挺顺。我看着它准确的分析了我的需求,使用Todo工具拆分任务,并开始行动的时候,感觉这玩意儿 真的能干活 。
但任务强度一拉高,诸多问题很快冒头:
- 终端命令越来越长,失败时只能看到最后报错,根本不知道哪步挂了;
- ReAct 靠字符串解析,模型偶尔多说一句、少个标记,就解析失败;
- 长任务里上下文开始"变脏",噪声越来越多;
- 工具返回都是字符串,后续处理很难做强约束。
等等.....
这时候我才真正意识到:
V0 的价值不是"它已经很好",而是"它把问题暴露得足够早"。
没有这个能跑通的版本,后面的重构可能就是拍脑袋。有了它,我能拿着具体代码和复现场景去改,而不是靠感觉。
而第一个真正把我打醒的坑,就是 Terminal Tool。
三、自由是把双刃剑:我的 Te rminal Tool 是怎么失控的
V0 刚跑起来那会儿,我最自豪的其实是 Terminal Tool 。
因为它几乎等于把"人能在终端里做的事"直接交给了模型。我当时甚至觉得——只要白名单、沙盒、危险命令确认做好,模型就能像资深工程师一样操作仓库。
结果很快被现实教育了。
1、我的设计:放开自由度,效率优先
V0 里的终端工具长这样:
self.terminal_tool = TerminalTool(
workspace=str(self.paths.repo_root),
timeout=60,
confirm_dangerous=True,
default_shell_mode=True, # 关键参数
)
|
default_shell_mode=True 意味着模型不只能执行 ls 、 rg 、 cat 这种单条命令,而是可以直接写:
rg -n "foo" src/ | grep "class" | sed -n '1,120p'
|
这个能力太诱人了。它让模型能用一条命令完成多步操作,效率很高,也很"像人"。
为了安全,我还加了不少限制:
- 只允许白名单命令
- 高风险操作要确认
- 禁止 rm/chmod 这类危险命令
- 组合命令要经过安全检查
听起来挺严密,对吧?
但真正用起来,问题很快就冒出来了。
2、真实场景:命令开始"不听话"
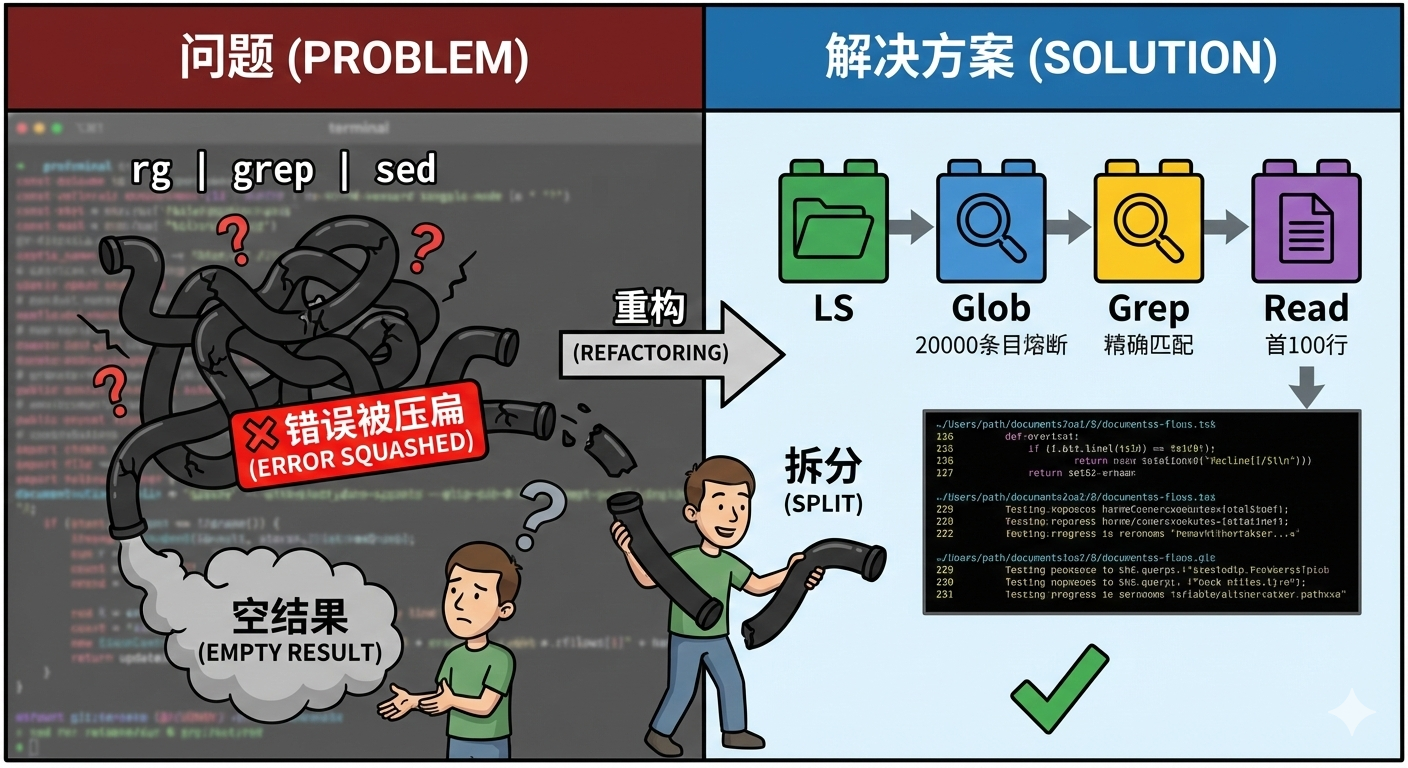
最典型的一次踩坑:
我让 Agent "搜索某个类里的函数,展示实现片段"。模型给出了一条"很聪明"的命令:
rg -n "TargetFunc" src/ | grep "class Foo" | sed -n '1,120p'
|
第一眼看,这就是老工程师常用的组合拳。但实际执行时,经常出现这些情况:
-
rg 搜出来太多, grep 过滤后什么都没剩
- rg 因为权限或编码问题直接失败,管道输入是空的
- sed 收到空输入,输出也是空的
- 最终模型看到"空结果",但它根本不知道哪一步出了问题
最坑的是:一条命令完成多步,错误被"压扁"了。
模型只能看到最终结果,看不到中间哪个环节挂了。它也没法修正策略,只能"重新拍一条命令赌运气"。
3、安全策略:越补越长的补丁战
我原以为白名单 + 沙盒 + 确认机制够安全了。但 shell 太灵活,管道、重定向、子命令全是"可绕过点"。
比如:
- > 重定向会变成写盘
- $(...) 触发子命令执行
- cmd1 || cmd2 把失败路径也带进来
- 即使限制了 rm ,还可能间接改文件
我写了大量安全检查:
SHELL_META_TOKENS = ["|", "||", "&&", ";", ">", ">>", "<", "$(", "`"]
DANGEROUS_BASE_COMMANDS = {"rm", "chmod"}
if needs_allow and not allow_dangerous:
return "❌ 该命令包含写盘/子命令替换/高风险操作..."
|
但讲真, 一旦你允许 shell 语法,你就永远在和组合复杂度做对抗 。
逻辑越写越长,模型越容易生成"刚好在边界上"的命令。而你要是全封死,能力也就残了。
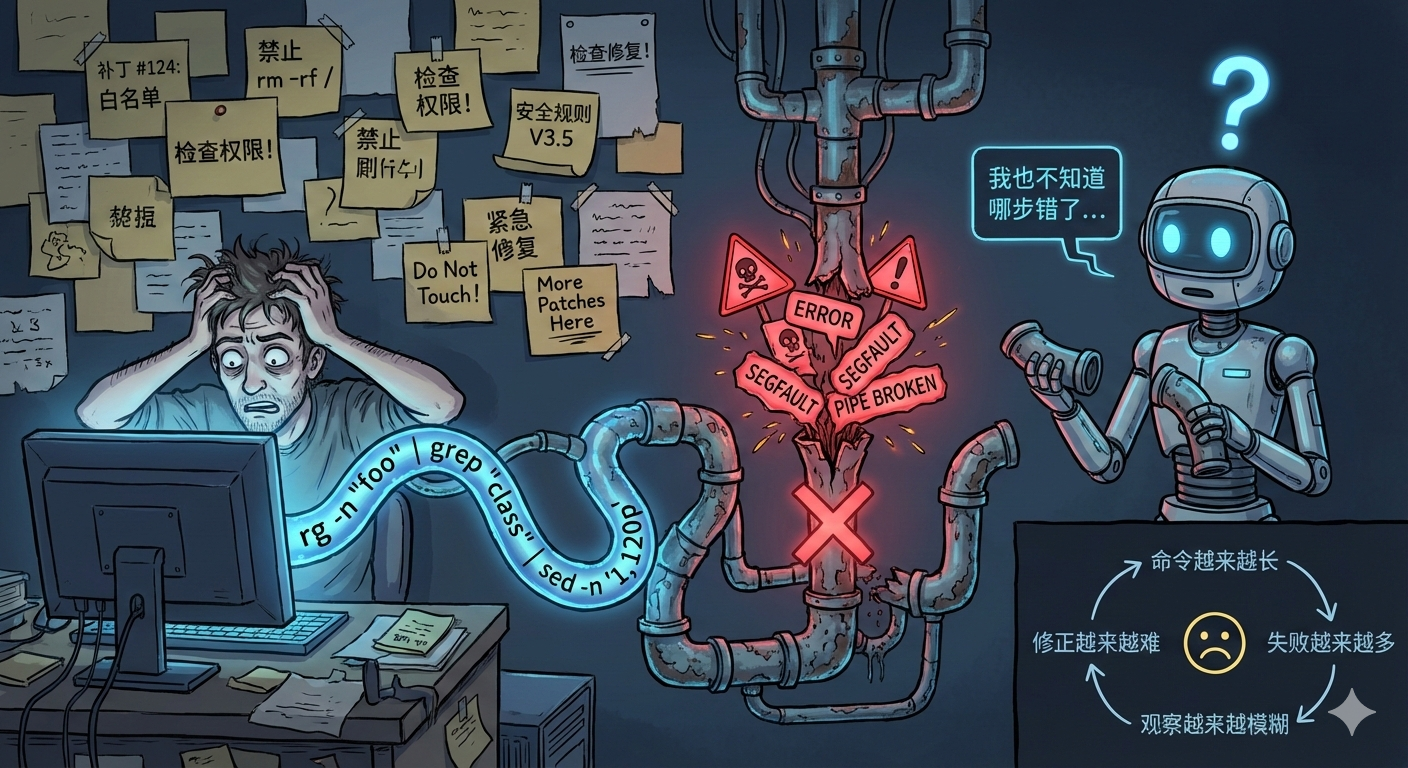
4、最致命的:错误不可定位,模型没法纠错
我后来总结,Terminal Tool 最大的问题不是"不安全",而是 没法诊断 。
在 Agent 体系里,模型需要靠"观察"来修正动作。但一个 Action 里塞了 3~5 个子命令时:
- 观察结果只有一个
- 失败信息混在一起
- 模型根本不知道 rg 、 grep 、 sed 谁出了问题
- 下一步只能瞎猜着重写
这就形成了一个坏循环:
命令越来越长 → 失败越来越多 → 观察越来越模糊 → 修正越来越难
这也是我决定"拆工具"的真正原因。因为在 Agent 里, 可控性比一次性完成更重要 。
5、认知转变:自由不是能力上限
这一坑让我彻底转变了想法。
以前我觉得:给模型自由度 = 提高能力上限
后来我发现: 给模型自由度,往往是在放大不确定性
说白了,模型强是强,但它不是工程师。它会生成看起来很聪明的命令,但并不一定能稳定执行,更难自己定位问题。
这一章的结论:
Terminal Tool 不能只靠"白名单 + 沙盒",更得把复杂行为拆成一组可观测、可控的原子工具。
接下来,我开始把 Terminal Tool 拆开,走向了"工具化"而不是"脚本化"。
四、把"自由命令"拆成"可控工具":我的工具体系重构实录
踩完 Terminal Tool 的坑,我才意识到:问题不是"工具不够多",而是 工具不 够可控 。
当时读到一篇解读 Claude Code 的文章,讲工具分层,说"高频动作更需要确定性"。这一下把我点醒了。
我的问题,恰恰是把所有能力塞进了一个"无限自由"的 Terminal Tool。低频场景确实灵活,但在高频动作上反而成了 噪音制造机 。
是时候重新设计了。
1、重构目标:每一步都有结构化证据
核心原则:
工具化的核心不是"更多工具",而是"每一步都有结构化证据"。
按"频率"和"确定性"重新分类:
说白了,不是为了多造轮子,而是 让每一步都可观察、可判断、可纠错 。
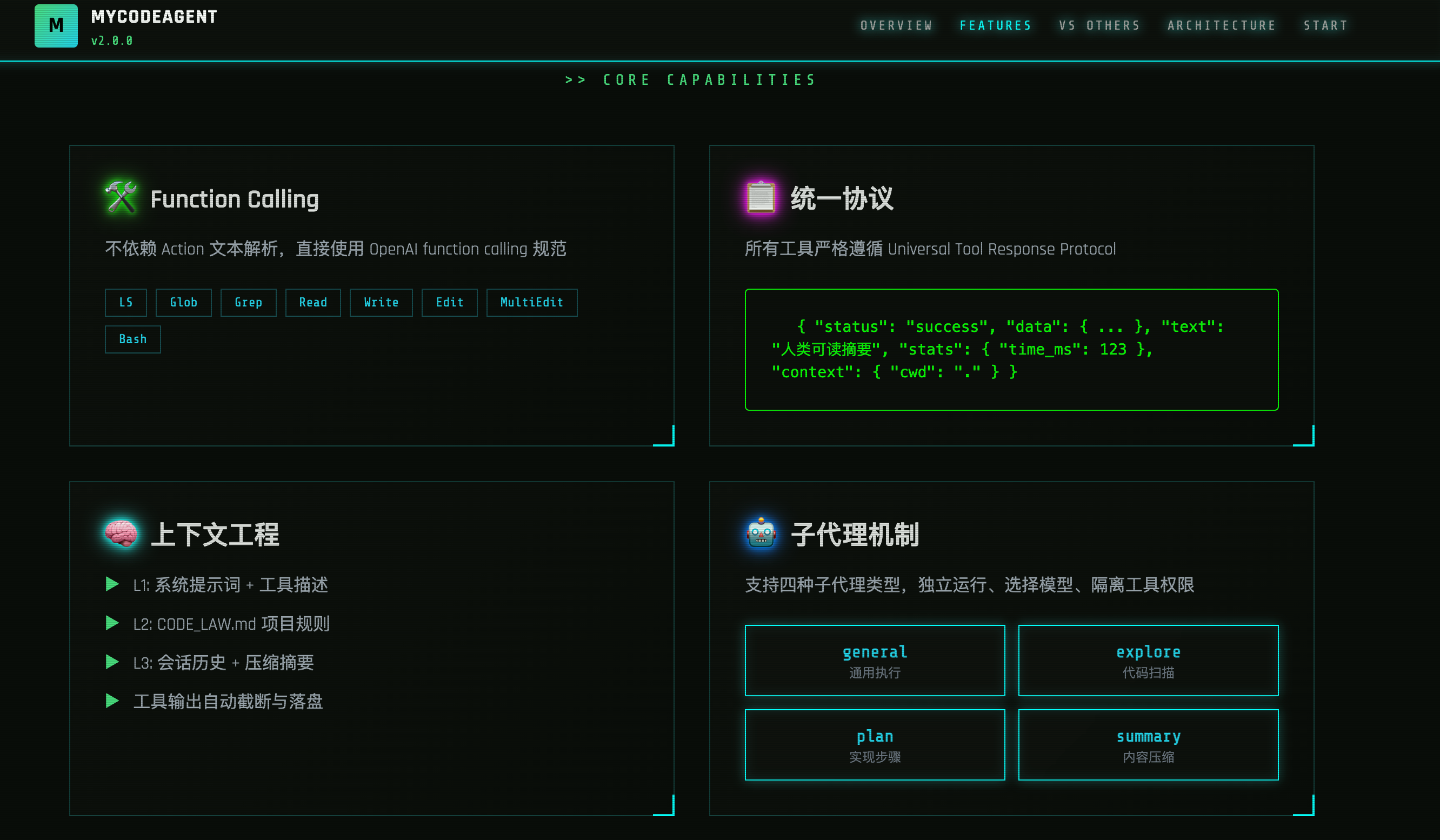
2、先统一协议:所有工具说同一种"语言"
Hello-Agent 里工具返回偏自由文本,模型还得"理解"每个工具的输出结构。
我现在搞的是 标准化信封(Standard Envelope) : status / data / text / stats / context 五件套。
以Glob工具的返回结果为例:
{
"status": "partial",
"data": {
"paths": ["core/llm.py", "agents/codeAgent.py"],
"truncated": true
},
"text": "Found 2 files matching '**/*.py' (Scanned 12000 items, timed out)",
"stats": {"time_ms": 2010, "matched": 2},
"context": {"cwd": ".", "params_input": {"pattern": "**/*.py"}}
}
|
模型不用猜"这是成功还是失败",直接看 status 和 data 就 知道下一步干嘛。
把"工具输出"从"杂乱文本"升级成"可推理信号"——这是质变。
3、ToolRegistry:工具体系的"中枢神经"
工具不是零散功能块,而是统一调度系统。入口是 tools/registry.py ,它干三件关键的事:
Schema 汇总:把工具"变成函数"
每个 Tool 的参数转成 JSON Schema,通过 get_openai_tools() 汇总给模型。
模型不再"自由拼字符串",而是被 schema 约束在合法参数里。
乐观锁自动注入:Write/Edit 不再裸奔
Read 过的文件,ToolRegistry 会缓存 file_mtime_ms 和 file_size_bytes ,后续 Write/Edit/MultiEdit 自动注入:
if name in {"Write", "Edit", "MultiEdit"}:
parameters = self._inject_optimistic_lock_params(name, parameters)
|
不 Read 就不能改,Read 过再改也有冲突检测。
熔断器:工具连续失败会被禁用
tools/circuit_breaker.py 默认 3 次失败熔断、300 秒恢复 。工具进入 open 状态后,ToolRegistry 直接返回结构化错误,防止模型在坏工具上死循环。
4、搜索链路:从"一条大命令"到"原子动作"
V0 里模型可能写一条命令干完所有事:
rg -n "TargetFunc" src/ | grep "class Foo" | sed -n '1,120p'
|
看着挺酷,但失败时你只看到一个"空结果",根本不知道哪步挂了。
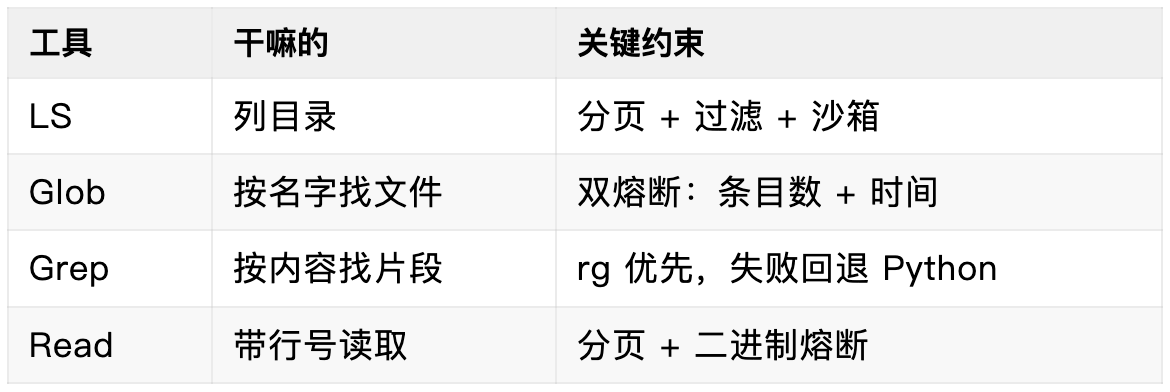
重构后拆成四个原子动作:
Glob 把"找文 件"变成确定动作:
- pattern 永远相对 path ,不让模型猜"从哪搜"
- 双熔断:最大 20000 条目、最多 2 秒
- ** 才能跨目录, * 不跨
- 返回相对路径,方便后续 Read/Edit 直接接
Grep 把"找符号"变成可推理的证据:
- 优 先 rg , 失 败回退 Python(必须标明 fallback)
- 输出固定为 file/line/text , 按 mtime 排序
讲真,模型不需要理解"输出是什么意思",只需要判断"下一步读哪一行"。 5、编辑链路:Read → Edit/MultiEdit → Write 工具体系最重要的闭环。设计成"读前约束 + 可预览 + 可回滚":
- Rea d : 带行号读取指定范围,返回 file_mtime_ms / file_size_bytes 作为乐观锁
- Edit / MultiEdit : 锚点替换 + diff 预览
编辑变成"可验证动作",而不是"赌命写文件"。
{
"path": "core/llm.py",
"old_string": "def invoke_raw(self, messages: list[dict], **kwargs):",
"new_string": "def invoke_raw(self, messages: list[dict], **kwargs) -> Any:",
"dry_run": true
}
|
6、Bash 从"默认"变 成"兜底"
Bash 没被删掉,而是被降级为"最后手段"。 硬约束:
- 禁止读/搜/列 : ls / cat / head / grep / find / rg
- 禁止交互 :vim、nano、top、ssh
- 禁止网络(默认):curl/wget 被禁
- 黑名单:rm -rf /、sudo/su、mkfs/fdisk
- 超时与截断:输出过大直接截断
Bash 不会成为"绕过工具体系的后门"。
这套改造让我明白一个道理:Code Agent 的"聪明",不是模型聪明,而是工具设计够不够可控。 从"能跑"到"能稳",靠的不是更严的提示词,而是更清晰的工程边界。
工具可控了,但调用协议还是个大问题——字符串解析太不靠谱,是时候转向 Function Calling 了。
五、从"修作文"到"走协议":我为什么放弃字符串 ReAct
工具体系改造完成后,我以为问题已经解决了一大半。
工具更可控了、返回协议也统一了,但真正跑起来还是会"偶发翻车"。
翻车的根源不在工具,而在 工具是怎么被调用的 。
那时候我沿用的是 Hello-Agent 的 ReAct:模型输出 Thought/Action 字符串,框架用正则解析。工具变精细了,但调用协议还是"自由文本"——只要模型多说一句、少一个符号,链路就断。
1、旧版 Re Act:全 靠"字符串纪律"
Hello-Agent 的 ReAct Prompt 写得很死,要求模型必须输出 Thought 和 Action 两行:
Thought: <你的思考(简短)>
Action: <以下二选一>
- tool_name[tool_input]
- Finish[最终回答]
|
表面上是强约束,本质还是 字符串协定 。模型多写一句解释、或者把 Action 放错位置,解析就开始出错。
看看解析代码才知道它有多脆:
m = re.search(
r"(?:\*\*)?(Thought|思考)(?:\*\*)?\s*[::]\s*(.*?)\n"
r"(?:\*\*)?(Action|行动)(?:\*\*)?\s*[::]\s*(.*)\s*$",
t,
flags=re.DOTALL,
)
|
这个正则已经很"照顾模型"了:兼容中英文、全角冒号、Markdown 加粗。但如果模型输出是多轮 Thought/Action,就会把后面的全部吞进第一个 Action,导致参数乱飞。
于是又加"截断补丁"。这个逻辑挺聪明,但它暴露了一个事实: 我们不是在做协议调用,而是在"修作文"。
2、救火式解析:补丁越打越多,问题还在
当 Action 输入是 JSON 时,麻烦更大。模型一旦输出了 }] 、或者多了个括号,工具就直接报错。
旧版 ToolRegistry 里堆了一堆 JSON 容错:
# 常见模型输出尾部多了一个 ']' 的容错
if obj is None and raw.startswith("{") and raw.endswith("}]"):
obj = _try_json(raw[:-1].strip())
# 模型输出为数组包裹一个对象
if obj is None and raw.startswith("[") and raw.endswith("]"):
arr = _try_json(raw)
if isinstance(arr, list) and len(arr) == 1:
obj = arr[0]
|
我把它叫作 "救火式解析" 。它能提高成功率,但解决不了根本问题:
输入漂移永远存在,只是被容错暂时遮住了。
3、调研后的顿悟:文本解析 → 结构化协议
后来系统读了一遍主流 Code Agent 的实 现,发现大家几乎都在做同一件事:
把 ReAct 的 Action 从"字符串协议"升级为 Function Calling。
讲真,这不是"把格式写得更严",而是 彻底换了通信方式 ——模型不再输出 tool_name[...] ,而是输出结构化 tool_calls ,框架再把结果和 tool_call_id 精确绑定。
于是开干,把整条链路换成 function calling。
4、改造三件套:Schema → tool_calls → tool_call_id
Schema:参数被强约束
每个 Tool 的参数自动转成 JSON Schema,模型只能在 schema 里填值,而不是自由拼字符串。
tool_calls:模型输出变结构化
不再解析 Action 字符串,直接抽取 tool_calls 。把"文本解析"变成"结构读取"。
tool_call_id:调用和结果强绑定
最关键的一环:每个 tool_call 都有 id,写入 assistant 消息后再执行工具,结果用相同 id 回填。
assistant_msg["tool_calls"] = [{
"id": call_id,
"type": "function",
"function": {"name": name, "arguments": args_str},
}]
messages.append({
"role": "tool",
"tool_call_id": tool_call_id,
"content": msg.content,
})
|
每一次工具调用都能精确对应结果,链路不会再断。
回过头看,旧版为了"能跑"写的大量容错补丁,现在都被协议层替代了。 ReAct 的稳定性不是靠"写更严的提示词",而是靠"让模型说协议话" ——标准格式天然可控,省去无数补丁。
调用协议稳定之后,新的问题又冒出来了——长对话一多,模型开始"变笨"。上下文工程,成了下一个要解决的大问题。
六、长 对话的困境:我的上下文工程 改造
调用协议稳定之后,问题很快转移到了另一块: 长对话一多,模型开始"变笨" 。
症状挺明显的——明明刚确认过的约束,过几轮就忘;会话越长,越容易用错工具;工具输出堆成山,最终答案越来越水。
这其实就是业界讨论最多的上下文腐烂问题,在看了Manus、Anthropic、 Langchain 等分享的关于上下文工程的博文之后,我总结出了以下几点:上下文隔离+上下文卸载+上下文压缩。
上下文隔离就是主 Agent 将复杂任务拆分为子任务,派发给专属子 Agent 处理,每个子 Agent 拥有独立的上下文窗口,实现 “关注点分离。
上下文卸载借鉴虚拟内存思想,将大模型中非活跃、大体积、低价值的上下文数据从显存 / 核心内存迁移至磁盘 / SSD 等低速存储,仅保留轻量引用,供模型按需调取。在Code Agent中卸载掉内容便是工具的返回结果了。
上下文压缩是在 不损失关键语义 的前提下,通过算法剔除冗余信息、精简数据量,降低 Token 消耗和内存占用的技术,分为 无损压缩 (仅剔除无意义符号 / 连接词)和 有损压缩 (剔除低价值信息,保留核心语义,大模型场景主流),核心目标是提升上下文的信息密度。
我的改造思路是: 从堆消息到分层治理,从工具输出堆积到统一截断,从无限历史到可控压缩。
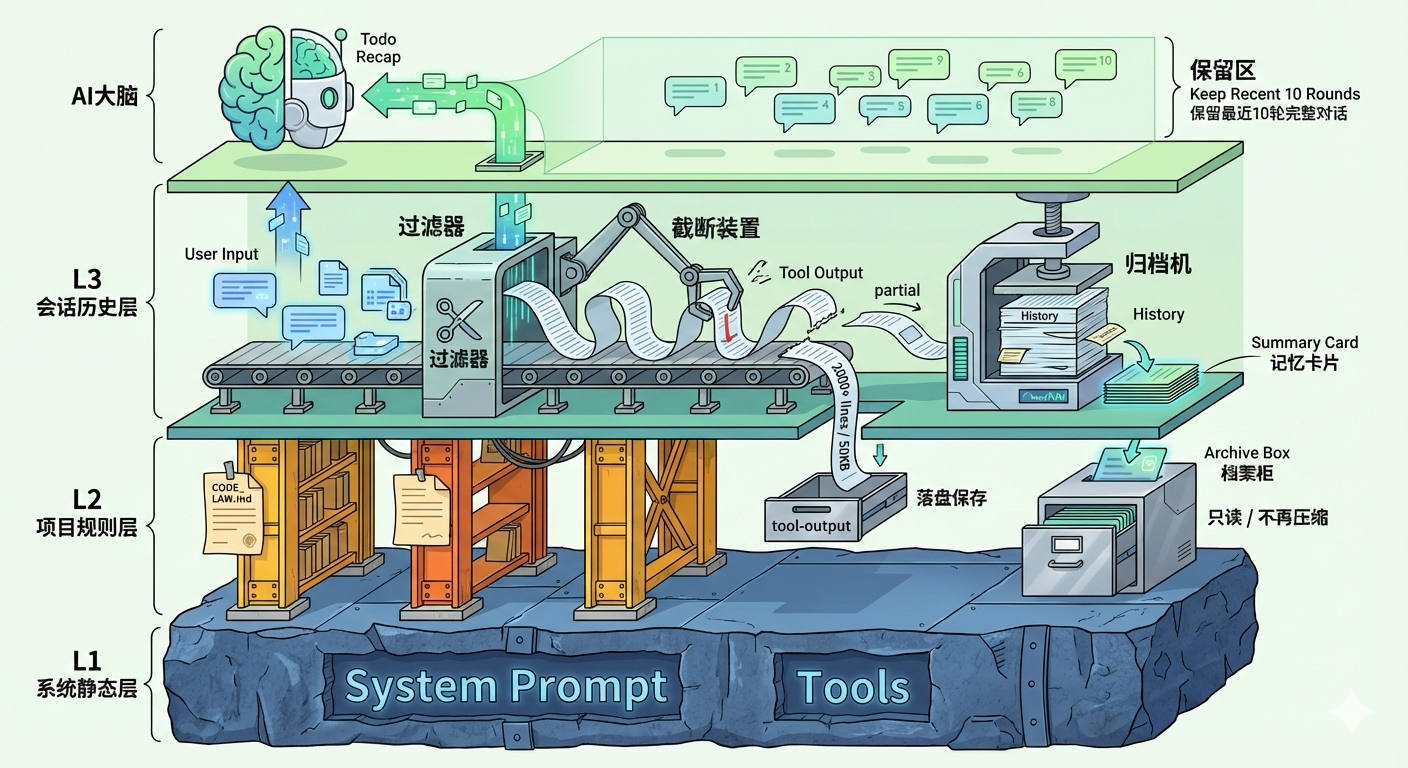
1、先把上下文分层:L1 / L2 / L3 的稳定结构
参考上下文工程的分层思路,我把上下文拆成三层:
拼接顺序固定: L1 → L2 → L3 → 当前 user → Todo recap
L1/L2 稳定,L3 才能稳定 ,模型需要知道什 么是永远不变的规则。
2、统一截断:Observation 进历史前必须"瘦身"
上下文膨胀的最大来源,不是用户说的话,而 是 工具输出 。
一次 Grep / Read 打出来几千行,如果不截断,历史很快就被"证据垃圾"淹没。
为什么需要"统一"截断?
最初我给每个工具设计了特化的压缩策略——Read 怎么截、Grep 怎么截、LS 怎么截,各自有各自的逻辑。结果维护成本极高,新增一个工具就要重新设计一套规则,还容易遗漏。
后来我参考了 Opencode 的做法,决定 完全替换为统一截断机制 :
- 不再为每个工具设计特化压缩
- 所有工具输出使用同一套截断规则
- 完整输出落盘保存,随时可回溯
统一截断规则
默认限制(通过环境变量可配置):
- TOOL_OUTPUT_MAX_LINES = 2000
- TOOL_OUTPUT_MAX_BYTES = 51200 (50KB)
截断方向有三种:
- head (默认):保留前 2000 行
- tail :保留后 2000 行
- head_tail :保留头尾各 40 行(适合需要看开头和结尾的场景)
处理流程很简单:
- 若行数 ≤ 2000 且字节数 ≤ 50KB → 原样返回
- 否则 → 截断 + 落盘保存 + 返回提示路径
落盘策略
截断不是丢 弃,而是"另存为":
- 目录 : tool-output/ (项目根目录下)
- 文件名 : tool_<timestamp>_<toolname>.json
- 内容 : 完整工具原始 JSON 输出
- 清理 : 默认保留 7 天,过期自动删除
这样设计的好处是—— 上下文保持精简,但完整证据始终可查 。
截断后的返回格式
截断后的响应仍然遵循《通用工具响应协议》,但 status 变为 partial ,并附加截断元信息:
{
"status": "partial",
"data": {
"truncated": true,
"truncation": {
"direction": "head",
"max_lines": 2000,
"max_bytes": 51200,
"original_lines": 5234,
"original_bytes": 182345,
"kept_lines": 2000,
"kept_bytes": 49872,
"full_output_path": "tool-output/tool_20260113_153045_Grep.json"
},
"preview": "(截断后的内容预览)"
},
"text": "⚠️ 输出过大已截断,完整 5234 行内容见 tool-output/tool_20260113_153045_Grep.json"
}
|
模型看到 partial 状态 ,就知道 内容被截断了。如果它发现关键信息可能在被截掉的部分,会收到明确的提示去读取完整文件。
截断后的回查流程
工具输出超长 → 被截断 → 返回 full_output_path → 模型判断 → 用 Read/Grep 回查
|
举个实际例子:
我让 Agent Grep 搜索 "class" 关键词,结果命中了 5000+ 行。工具自动截断前 2000 行返回,并在 text 中提示:
“⚠️ 输出过大已截断,完整 5234 行内容见 tool-output/tool_20260113_153045_Grep.json”
Agent 分 析后发现:"前面这些都不是我要找的 ,目标可能在后面。"
于是它调用 Read 读取完整落盘文件,或者用更精确的 Grep 在落盘文件里进一步筛选—— 既拿到了结果,又没让上下文爆炸 。
智能提示
当发生截断时,我还会在 text 里附加提示,引导模型 后续行动 :
- 如果存在 Task 工具:"Use Task to have a subagent process the full output file..."
- 否则:"Use Read with pagination or Grep to search the full output file..."
这套统一截断策略,让我从"为每个工具写压缩逻辑"的泥潭里解脱出来,同时保持了可追溯性与上下文可控性。
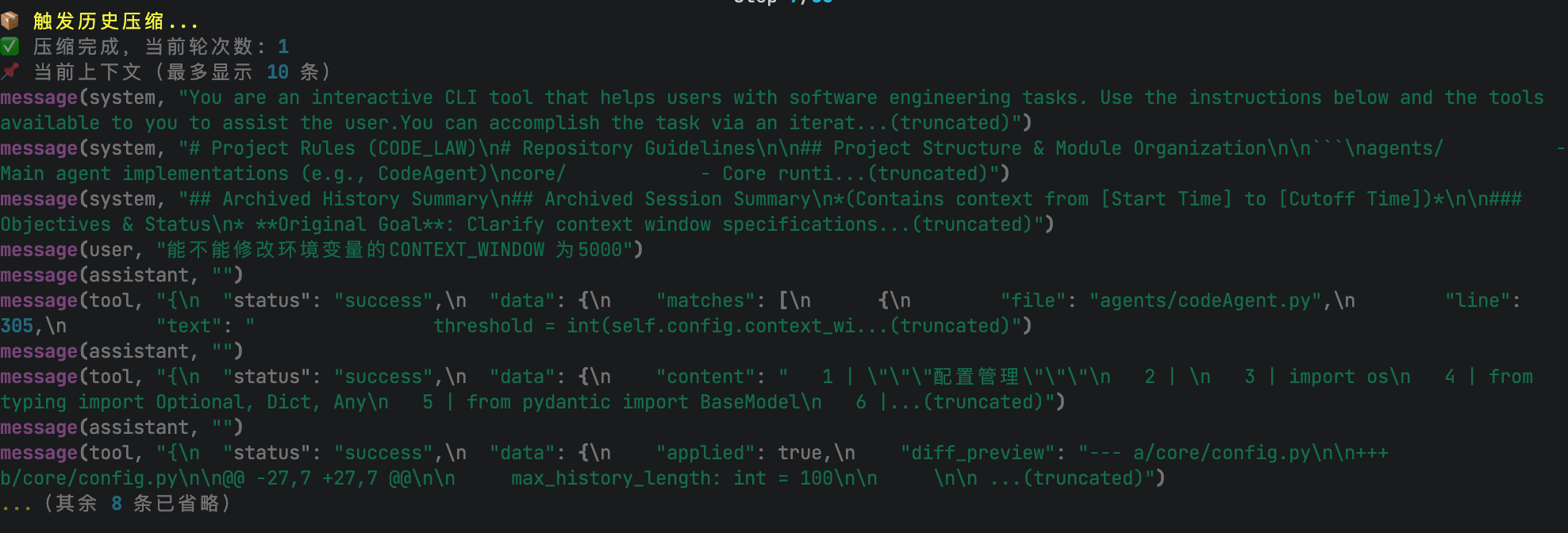
3、压缩触发:明确阈值,自动收敛
历史越积越多,模型会被噪声淹没。
我设定的压缩触发条件:
- estimated_tokens >= 0.8 * context_window (超过 8k token)
- messages >= 3
- 至少保留最近 10 轮完整对话
“保留完整轮次”非常关键:一轮必须从 user 发起到 assistant 完成,中间的工具调用链不能拆。这是保证 Agent 行为连贯性的底线。 4、Summary 归档:旧历史压缩成"记忆卡片"
压缩不是删除,而是归档。我用 Summary 把旧历史提炼成关键信息,让模型既能"看到过去",又不被"过去淹没"。
Summary 的核心定位
Summary 只用于旧历史归档,不包含当前任务进度。
这是个关键区分:
- Todo Recap : 告诉模型"现在正在做什么"(当前进度)
- Summary : 告诉模型"之前做过什么"(历史归档)
HistoryManager 把 Summary 作为 role=summary 的消息存入 L3,序列化时变成 system message 注入 上下文。最重要的是: Summary 永远不再压缩 ——它是"旧历史的档案",一旦生成就是只读的"记忆卡片"。
Summary 生成机制
触发时机 : 当历史消息超过 token 阈值(默认 0.8 × context_window)时触发压缩。
生成方式 : 调用新的模型会话(可配置模型)来生成 Summary,输入是待压缩的历史消息 + 专用的 SUMMARY_PROMPT 。
超时与降级 : 生成过程同步阻塞,用户会看到压缩进度提示。如果超过 120 秒还没生成完,就跳过 Summary 生成,仅保留最近 N 轮历史,并提示用户:"Summary generation timed out, keeping recent history only."
固定模板结构
Summary 必须按固定模板生成,确保关键信息不遗漏:
## 📌 Archived Session Summary
*(Contains context from [Start Time] to [Cutoff Time])*
### 🎯 Objectives & Status
* **Original Goal**: [用户最初想做什么]
### 🏗️ Technical Context (Static)
* **Stack**: [语言, 框架, 版本]
* **Environment**: [OS, Shell, 关键环境变量]
### ✅ Completed Milestones (The "Done" Pile)
* [✓] [已完成的任务1] - [简述结果]
* [✓] [已完成的任务2] - [简述结果]
### 🧠 Key Insights & Decisions (Persistent Memory)
* **Decisions**: [关键技术选型或放弃的方案]
* **Learnings**: [特殊配置、API 格式或坑]
* **User Preferences**: [用户强调的习惯]
### 📂 File System State (Snapshot)
*(Modified files in this archive segment)*
* `src/utils/auth.ts`: Implemented login logic.
* `package.json`: Added `zod` dependency.
|
这个模板的妙处在于: 不同层次的信息分开存放 ,模型能快速定位需要的内容。想查改了哪些文件?看 File System State。想查当时为什么选这个方案?看 Key Insights & Decisions。
一个实际的 Summary 例子
假设用户让 Agent 实现一个登录功能,中间经过了多轮调试和重构,历史膨胀到需要压缩。生成的 Summary 可能是:
## 📌 Archived Session Summary
*(Contains context from 14:32 to 15:47)*
### 🎯 Objectives & Status
* **Original Goal**: 实现 JWT 登录功能,包含登录接口和前端表单
### 🏗️ Technical Context
* **Stack**: Node.js + Express + React + TypeScript
* **Environment**: macOS, Node 18, PostgreSQL 14
### ✅ Completed Milestones
* [✓] 设计数据库 schema(users 表,含 password_hash 字段)
* [✓] 实现 /api/login 接口(JWT 签名,7天过期)
* [✓] 实现密码 bcrypt 加密(salt rounds: 10)
* [✓] 前端登录表单(React Hook Form + Zod 校验)
### 🧠 Key Insights & Decisions
* **Decisions**: 选用 jsonwebtoken 而非 passport-jwt(更轻量)
* **Learnings**: bcrypt 异步方法比同步方法快 3 倍
* **User Preferences**: 用户强调错误信息不要暴露具体字段
### 📂 File System State
* `src/routes/auth.ts`: 新增登录路由
* `src/middleware/jwt.ts`: 新增鉴权中间件
* `src/components/LoginForm.tsx`: 新增登录表单
* `.env`: 新增 JWT_SECRET(未提交)
|
当这个 Summary 被注入上下文后,模型即使忘记了中间具体的调试过程,也能知道:"哦,登录功能已经做完了,用了 JWT,数据库 schema 也定好了,现在应该在搞其他模块。"
为什么 Summary 不再压缩?
这是个关键设计决策。
如果 Summary 还能被压缩,那就会出现"Summary 的 Summary",信息会层层失真,最后变成一堆没有上下文的碎片。
Summary 是压缩的终点。 它像是一本相册——你把几百张照片(历史消息)精选成一本相册(Summary),以后翻这本相册就够了,不需要再压缩相册本身。
这也解释了为什么 Summary 模板要固定结构:只有结构固定,才能在一次读取中高效提取信息,而不需要反复翻找。
与 Todo Recap 的配合
Summary 和 Todo Recap 是互补的:
上下文结构:
L1 System Prompt
L2 CODE_LAW.md
L3 History:
- [旧历史] → 被压缩成 Summary(只读档案)
- [保留区] 最近 10 轮完整对话
- [当前轮] user 输入 + assistant 思考中...
- Todo Recap: [1/3] In progress: 实现注册接口
|
Summary 让模型知道"从哪来",Todo Recap 让模型知道"现在在哪",两者配合,模型才不会迷失。
5、噪声控制:@file 不再直接塞内容
以前做 @file 时,我习惯直接把文件内容拼进上下文:
User: @file:src/main.py 帮我分析一下这个文件
[文件内容300行...]
|
结果就是:上下文里多了一大段代码,但用户可能只是想问"这个文件是干嘛的"。
模型看着这 300 行代码,头都大了。
现在改成: 只插入 system-reminder,不直接注入内容 。
用户输入: 请看一下 @core/llm.py 和 @agents/codeAgent.py
最终会被改写成:
<system-reminder>
The user mentioned @core/llm.py, @agents/codeAgent.py.
You MUST read these files with the Read tool before answering.
</system-reminder>
|
上下文里只留下"提醒",而不是"垃圾"。
这一轮改造的效果很明显:工具输出不会无限堆积,历史能在阈值时自动收敛,Summary 把旧历史压成"稳定记忆",@file 不再制造垃圾上下文。 上下文不是塞得越多越好,而是要治理得清晰、可追溯。
但治理好上下文,还有一个更大的痛点——Agent 出错时,我完全不知道它经历了什么。可观测性,成了下一个坎。
七、把黑盒拆开:可观测性、日志与会话回放
工具、协议和上下文都稳定之后,我才真正遇到一个硬伤: Agent 出错时,我无法还原"它到底做了什么" 。
有一次模型连续失败 3 步,最后干脆自己放弃了。我翻控制台日志,只看到一句: tool failed
没有完整参数、没有前后文、也看不到之前几步的决策链。 我只能瞎猜:路径写错了?权限不够?还是工具本身有 bug?
那一刻我才 意识到: 没有审计轨迹的 Agent,就像没有行车记录仪的自动驾驶——出事了你只能干瞪眼。
于是我补上了可观测性这一层:Trace 轨迹 + 会话快照。
1、TraceLogger:会话级审计轨迹
我不再用"散乱的运行日志",而是做了一个会话级轨迹记录器: TraceLogger 。
它只做一件事: 把一次会话的每一步,按顺序完整记下来 。
双格式输出:机器可读 + 人类可读
TraceLogger 同时输出两份文件,放在 memory/traces/ 目录下:
JSONL 格式 (面向机器处理):
- 路径: memory/traces/trace-s-20260103-201533-a3f2.jsonl
- 每一步一个 JSON 对象,便于流式追加与后处理
- 可以写脚本批量分析、统计 token 用量、检测异常模式
{
"ts": "2026-01-19T08:39:41.557283Z",
"session_id": "s-20260119-163933-3d33",
"step": 0,
"event": "message_written",
"payload": {
"role": "user",
"content": "请快速理解这个仓库是做什么的,并输出一份“项目概览”文档(可以使用subagent,如果有必要的话):
\n - 简要说明目标、核心模块、主要功能;\n - 引用真实文件路径作为依据;\n - 输出一个结构清晰的 Markdown
文件放在 demo/ 项下(文件名你定)。\n - 可以使用mcp工具来进行搜索同类产品的功能点,进行对比总结",
"metadata": {}
}
}
{
"ts": "2026-01-19T08:40:12.926898Z",
"session_id": "s-20260119-163933-3d33",
"step": 1,
"event": "message_written",
"payload": {
"role": "assistant",
"content": "",
"metadata": {
"action_type": "tool_call",
"tool_calls": [{
"id": "call_-7965161296454289305",
"name": "TodoWrite",
"arguments": "{\"summary\":\"分析仓库并生成项目概览文档\",\"todos\":[{\"content\": \"探索仓库结构和核心文件\",
\"status\": \"in_progress\"}, {\"content\": \"搜索同类 AI Agent 产品进行对比\", \"status\": \"pending\"},
{\"content\": \"生成项目概览 Markdown 文档\", \"status\": \"pending\"}]}"
}]
}
}
}
|
HTML 格式 (面向人类审计):
- 路径: memory/traces/trace-s-20260103-201533-a3f2.html
- 可直接用浏览器打开,可视化展示每一步
- 支持点击展开/折叠,像在"逐帧回放"
文件名中 的 s-20260103-201533-a3f2 是会话唯一标识( s-YYYYMMDD-HHMMSS-随机4位 ),方便按时间检索。
统一事件 结构
所有事件都遵循统一结构:
{
"ts": "2026-01-03T20:15:33.112Z",
"session_id": "s-20260103-201533-a3f2",
"step": 4,
"event": "tool_call",
"payload": {}
}
|
字段说明 :
- ts :ISO8601 时间戳,精确到毫秒
- session_id :会话唯一标识
- step :ReAct 循环的 step 序号
- event :事件类型
- payload :事件数据体
关键事件类型
我定义了以下关键事件类型,覆盖 Agent 运行的完整生命周期:
有了统一结构,问题就不再是"有没有日志",而是"你想看哪一步"。
2、关键证据链:每一步都打点
Trace 的核心价值是"证据链"——每一步都有迹可循,调用和结果能精确对应。
tool_call_id:调用与结果的强绑定
在 Function Calling 架构下,每个 tool_call 都有唯一 ID。TraceLogger 用这个 ID 把"调用"和"结果"串成一条链:
# Step 1: 记录工具调用
trace_logger.log_event(
"tool_call",
{
"tool": "Read",
"args": {"path": "core/llm.py"},
"tool_call_id": "call_abc123xyz"# 关键:唯一标识
},
step=4,
)
# 执行工具...
# Step 2: 记录工具结果,使用相同的 tool_call_id
trace_logger.log_event(
"tool_result",
{
"tool": "Read",
"tool_call_id": "call_abc123xyz", # 与调用对应
"result": {
"status": "success",
"data": {"content": "..."},
"text": "Read 120 lines from core/llm.py"
}
},
step=4,
)
|
在 HTML 可视化中,这两个事件会被渲染成一对可折叠的卡片,一眼就能看出调用和结果的对应关系。
model_output:记录 Token 用量
每次模型输出,Trace 都会记录 usage 信息:
{
"event": "model_output",
"payload": {
"raw": "...",
"tool_calls": [...],
"usage": {
"prompt_tokens": 3456,
"completion_tokens": 892,
"total_tokens": 4348
}
}
}
|
这帮我解决了一个老大难问题: "为什么突然变慢 / 为什么 token 暴涨?"
打开 Trace 一看,就能定位到哪一步 的上下文突然膨胀了。
3、HTML 可视化:把轨迹变成"可读回放"
JSONL 适合程序分析,但人类复盘需要"看得懂"。TraceLogger 会同步生成一份 HTML,可直接用浏览器打开。
HTML 界面结构
点开每一步,就能看到完整的 input / output / token / 截断提示,像在逐帧回放。
脱敏保护
生产环境中,Trace 可能包含敏感信息(API Key、Token、文件路径)。 TraceSanitizer 默认开启( TRACE_SANITIZE=true ):
- API Key: sk-*** / Bearer ***
- 敏感字段: api_key 、 token 、 session_id 、 tool_call_id
- 路径脱敏: /Users/yyhdbl/... → /Users/***/...
排查问题够用,但不会把敏感信息原样写盘。
4、一个真实复盘案例:Trace 怎么救了我
还记得那次“编辑后结果不生效”的问题吗?
当时 Agent Read 完就去 Edit,但 Edit 一直失败,我在控制台只看到 tool failed ,根本不知道原因。
后来我用 Trace 复盘,打开 HTML 一看:
Step 2 - tool_call (Read):
{
"tool": "Read",
"args": {"path": "core/llm.py"},
"tool_call_id": "call_021"
}
|
Step 3 - tool_call (Edit):
{
"tool": "Read",
"args": {"path": "core/llm.py"},
"tool_call_id": "call_021"
}
|
Step 3 - tool_result (Edit):
{
"status": "error",
"error": {
"code": "CONFLICT",
"message": "File changed since last read."
}
}
|
Step 4- model_output:
模型没理解冲突原因,继续用旧的 mtime 重试……
这时我才明白:不是 Edit 工具出 bug,而是文件在 Read 后被格式化/自动保存改过了。
有了这条证据链,我在提示词里加了“遇到 CONFLICT 必须重新 Read”这一条,问题立刻消失。
这就是 Trace 的价值: 你不是在猜错误,而是在看证据 。
5、会话快照:断点续跑的秘密
Trace 解决"事后复盘",会话快照解决"断点续跑"。
CLI 操作
# 手动保存
/save my-session-backup
# 自动保存(exit 或 Ctrl+C 时触发)
# 默认路径:memory/sessions/session-latest.json
# 加载恢复
/load my-session-backup
|
我经常让 Agent 跑 30 分钟的长任务,断网或退出后用 /load 继续跑, 基本不会丢上下文 。
快照存的不只是历史
Session 快照不是简 单的"存对话",而是 存环境 :
{
"session_id": "s-20260103-201533-a3f2",
"messages": [...],
"tool_schema_hash": "a3f2d8e...",
"read_cache": {
"core/llm.py": {"mtime": 1234567890, "size": 3456},
"agents/codeAgent.py": {"mtime": 1234567891, "size": 5678}
},
"prompt_hashes": {
"code_law": "b5e7c9d...",
"skills": "f1a2b3c...",
"mcp": "d4e5f6a..."
}
}
|
- tool_schema_hash :工具的 JSON Schema 哈希,检测工具定义是否变化
- read_cache :乐观锁元信息(mtime + size),确保恢复后能检测文件是否被外部修改
- prompt_hashes :各种提示词的哈希,确保上下文环境一致
这保证了你恢复会话时,工具版本、上下文状态、读前约束都和之前完全一致。
6、配置与性能
Trace 是可配置的,不会成为性能负担:
# 开关控制
TRACE_ENABLED=true|false # 默认 true
TRACE_DIR=memory/traces # 输出目录
TRACE_SANITIZE=true|false # 脱敏,默认 true
TRACE_HTML_INCLUDE_RAW_RESPONSE=true|false # 是否包含原始响应,默认 false
|
性能考虑 :
- JSONL 追加写入,开销极低
- 默认开启脱敏,生产环境需配合权限控制
- HTML 生成在会话结束时批量处理,不影响运行时性能
从"猜错误"到"看证据",这一层是工程化的分水岭。 V0 时 Agent 挂了只能瞎猜,现在打开 Trace 5 分钟就能定位问题。可观测性不是锦上添花,而是复杂系统必备的"行车记录仪"。
八、扩展期:让 Agent 从"单兵作战"变成"专业团队"
工具、协议、上下文、可观测性——这些都让 MyCodeAgent 成了一个"靠谱的员工"。但一个员工再靠谱,终究只有一双手。面对复杂任务时,单打独斗的效率总是有限的。
真正让我眼前一亮的是: 如果 Agent 能像一个"专业团队"那样协作呢?
- 有人专门负责"向外看"——搜索外部信息
- 有人专门负责"向内看"——分析代码结构
- 有人专门负责"盯进度"——确保不偏离主线
- 还有人随时准备"传授经验"——特定领域知道怎么干
这就是 MCP / Task / Todo / Skills 的出发点。它们不是给 Agent 增加负担,而是帮它 拆解负担、专注专长 。
1、MCP:给 Agent 装上"外部触角"
MCP(Model Context Protocol)是 Anthropic 推出的开放协议,简单说就是 让 Agent 能调用外部工具的通用插槽 。
我第一时间集成它,是因为不想重复造轮子。比如要做竞品调研,自己写搜索工具太麻烦,直接用社区现成的 tavily-mcp 多好。
集成方式很简洁:
// mcp_servers.json
{
"mcpServers": {
"tavily": {
"command": "npx",
"args": ["-y", "@tavily/mcp"],
"env": {"TAVILY_API_KEY": "..."}
}
}
}
|
启动时 tools/mcp/loader.py 自动连接、注册,这些外部工具就变成和内置工具一样的标准接口。Agent 不需要知道谁是"亲生的"谁是"外来的",统一用 Function Calling 调用。
MCP 的价值在于:Agent 的能力边界不再受限于我写了多少内置工具。
2、Task:把"脏活累活"外包给子代理
长程任务最头疼的是上下文污染。让主 Agent 一边统筹全局,一边深入细节搜索文件,结果就是 主线思路被打断,上下文被无关信息塞爆 。
Task 工具的设计思路很简单: 像老板派活儿一样,把子任务外包出去 。
# Task 工具调用示例
{
"description": "分析项目核心架构",
"prompt": "深入分析 core/ 目录下的上下文工程实现,包括:\n1. HistoryManager 的压缩策略
\n2. ContextBuilder 的分层设计\n3. 输入预处理器的工作原理\n返回结构化的架构分析报告",
"subagent_type": "explore",
"model": "light"
}
|
子代理启动时,会创建一个 完全独立的会话 :
- 干净的消息历史,只包含任务相关的上下文
- 受限的工具集,只能只读(LS/Glob/Grep/Read/TodoWrite)
- 严格禁止:Task/Write/Edit/MultiEdit/Bash, 以及 MCP 工具
为什么限制这么严格?
DENIED_TOOLS = frozenset({"Task", "Write", "Edit", "MultiEdit", "Bash"})
# MCP 工具也不在 ALLOWED_TOOLS 中
ALLOWED_TOOLS = frozenset({"LS", "TodoWrite", "Glob", "Grep", "Read"})
|
- 禁止 Task : 防止"子生子,孙生孙"无限套娃
- 禁止写操作 : 防止子代理"越界改代码"
- 禁止 MCP : 外部搜索涉及网络调用和 API Key,子代理隔离失败可能导致密钥泄露
它只负责 代码分析和信息整理 ,决策权牢牢握在主 Agent 手里。
子代理还支持 四种专业角色 :
- general :通用型,处理常规任务
- explore :探索型,擅长代码库分析
- summary :总结型,擅长信息归纳
- plan :规划型,擅长任务拆解
以及 双模型路由 :
- light :轻量模型(默认),省 Token、速度快
- main :主力模型,复杂任务用
一个典型的外包流程是这样的:
- 主 Agent 发现需要深入分析某个模块的代码
- 启动 Task,指定 subagent_type=explore ,限定分析范围
- 子代理独立运行 10-20 步,只读相关文件,整理结构
- 返回结构化报告,主 Agent 继续主线决策
上下文隔离 + 工具限制 + 模型分级 ,这套组合拳让主 Agent 可以"用人不疑"地委派任务。
3、TodoWrite:给 Agent 一张"路线图"
人同时干多件事会手忙脚乱,Agent 也一样。
TodoWrite 不是简单的任务清单,它是一个 状态机 + 进度追踪器 。
核心约束:
- 声明式覆盖 : 每次提交完整列表,不是 diff
- 最多 1 个 in_progress : 强制单线程专注
- 自动 Recap : 把 [2/5] In progress: xxx. Pending: yyy; zzz. 压缩到上下文末尾
- 完成后自动持久化 : 写入 memory/todos/todoList-YYYYMMDD-HHMMSS.md
为什么强制单线程?因为我发现,一旦允许多个"进行中",Agent 就开始"东一榔头西一棒槌",最后啥都没干完。
Recap 的设计也很关键——它像一张贴在桌角的便利贴,时刻提醒 Agent "你现在该干嘛"。
4、Skills:给 Agent 装上"领域大脑"
工具给了 Agent "手",但 光有手不知道咋干活 。
Skills 解决的是"Know How"问题。它的核心思想是: 把个人经验写成 SOP,让 Agent 按需调用 。
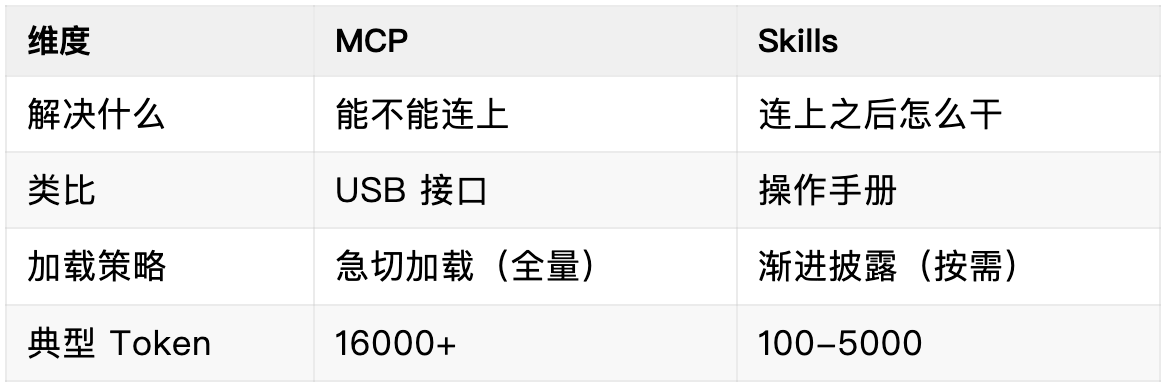
Skills vs MCP:渐进披露 vs 急切加载
MCP 的问题是"急切加载"——一连接就把所有 Schema、文档塞进上下文。Skills 采用 渐进式披露 :
- 第一层 : 启动只加载元数据(name/description)→ ~100 Token/技能
- 第二层 : 命中时才加载完整 SOP → 1000-5000 Token
- 第三层 : 附加资源按需加载
Token 节省 90% 以上 。
三层实现架构
文件层:SKILL.md
---
name: ui-ux-pro-max
description: UI/UX设计专家,提供50+风格、21+配色、字体搭配等
---
#### UI/UX 设计指南(示例)
**可用风格:**
- Glassmorphism(玻璃拟态)
- Claymorphism(粘土拟态)
- Minimalism(极简主义)
...
**使用方式:** 根据项目类型选择合适的风格,提供具体实现代码。
$ARGUMENTS
|
格式要求:
- YAML frontmatter 定义元数据
- Markdown 正文写 SOP
- $ARGUMENTS 是参数占位符
加载层:SkillLoader
# 扫描 skills/ 目录
skill_loader.scan()
# 获取元数据列表(仅 name + description)
skill_loader.list_skills() # 低成本
# 加载完整 Skill(按需)
skill_loader.get_skill("ui-ux-pro-max") # 高成本,只在使用时触发
|
缓存策略基于 mtime ,文件没变就不重新扫描。
工具层:Skill Tool
{
"name": "Skill",
"arguments": {
"name": "ui-ux-pro-max",
"args": "科技感项目介绍页,深蓝主色调"
}
}
|
执行时 解 析 $ARGUMENTS ,把用户参数注入 SOP,然后塞进当前上下文。Agent 瞬间拥有了"领域专家的记忆"。
5、实战:一个长程任务的完整协作流程
说了那么多,来看个真实例子。我给 MyCodeAgent 安装了 tavily-mcp ,然后布置了一个任务:
任务:
基于对全项目的理解,输出一个“面对新人开发者的项目介绍网页”
要求:
1. 内容需包含:项目概览、核心能力、架构/流程、注意事项
2. 网页风格你自行决定(科技感/赛博科技等均可)
3. 若你有 UI/UX 相关 Skill 可用,建议调用
4. 可以使用 MCP 工具搜索同类产品的功能点,在网页上进行对比
这个任务横跨了所有扩展能力。来看 Agent 是怎么"团队协作"的:
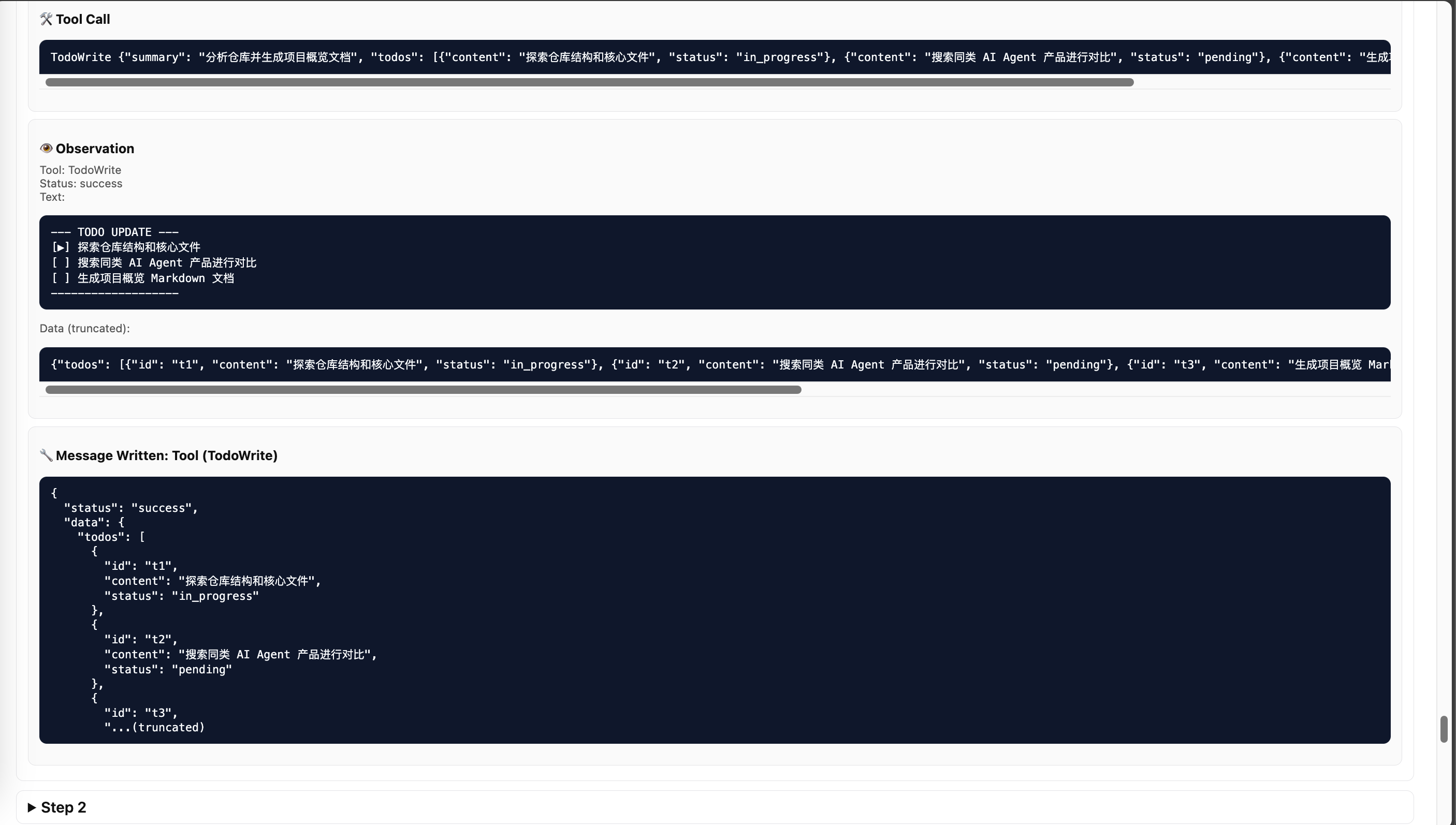
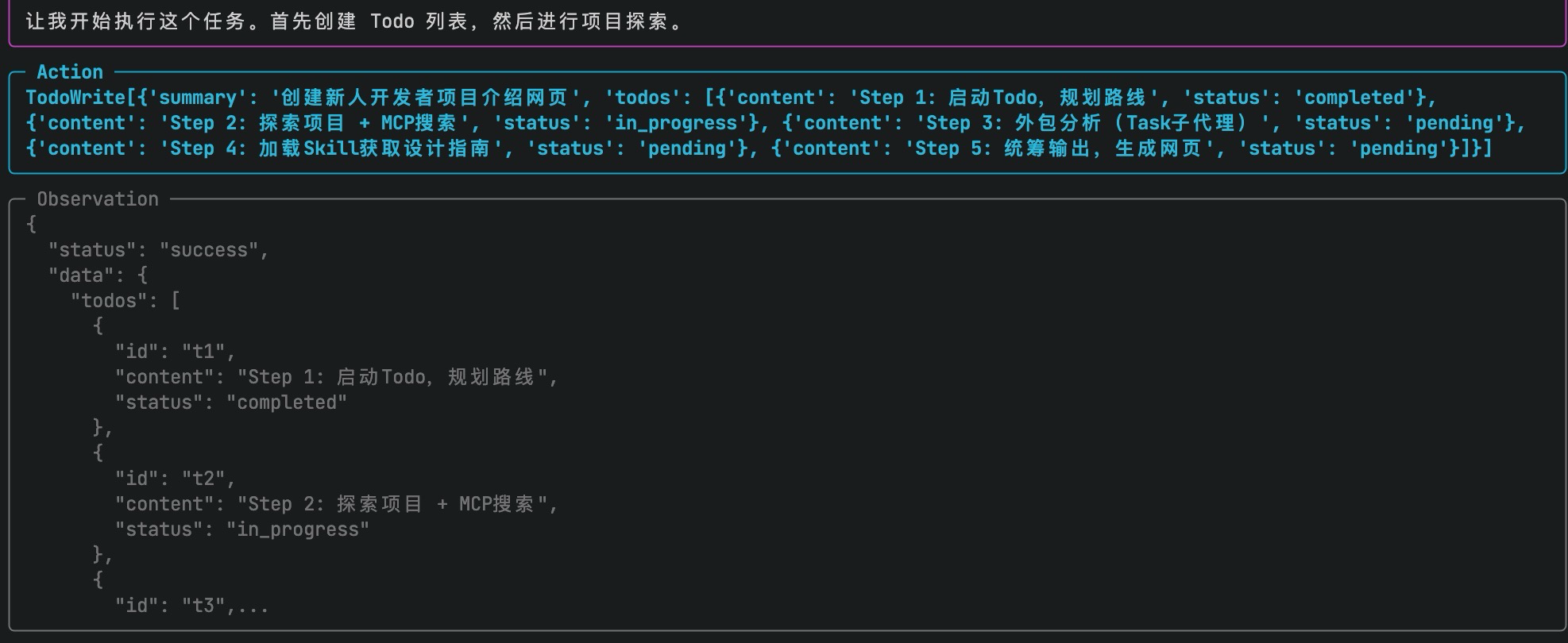
Step 1:启动 Todo,规划路线
Agent 首先调用 TodoWrite,拆解任务:
好,路线图有了。
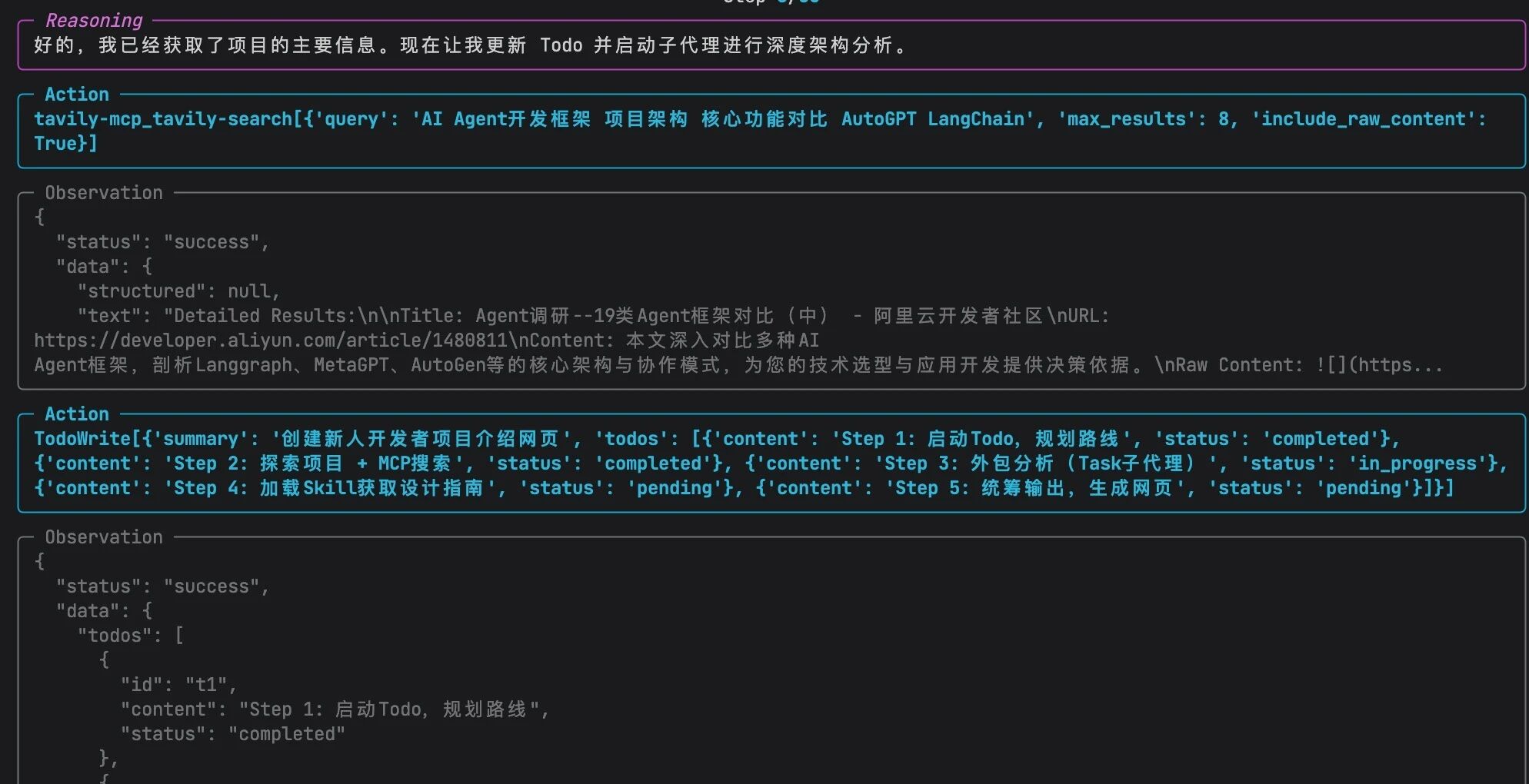
Step 2:探索项目 + MCP 搜索
主 Agent 首先进行:
外部搜索(MCP)
- 调用 tavily_search ,搜索竞品
- 获取功能对比信息
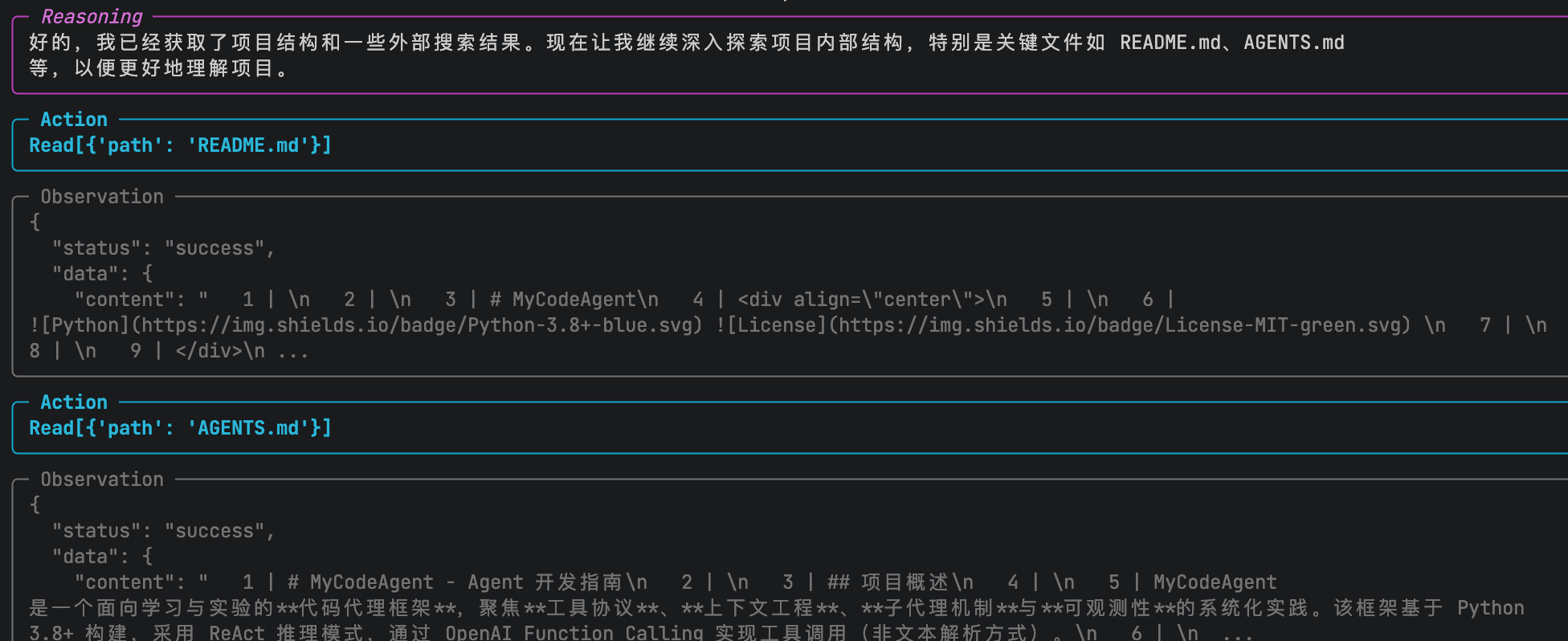
随后进行内部探索
- 用 LS 、 Read 扫描项目结构
- 读取 README.md 、核心模块文档
- 建立整体认知
Step 3:外包分析(Task 子代理)
"深入分析架构细节"这个活儿,主 Agent 不想亲自干——太琐碎,而且需要遍历大量文件。
于是启动 Task:
主 Agent 拿到报告, 上下文依然干净 ——这些技术细节没有污染主会话。
Step 4:加载 Skill,获取设计指南
Agent 发现自己有 ui-ux-pro-max 这个 Skill,果断调用:
Skill 返回 设计指南:
- 风格:Cyberpunk / Tech-Noir
- 字体:Rajdhani(科技)+ Share Tech Mono(终端)
- 配色:深黑底 + 霓虹绿/青/粉/蓝
- 特效:CRT扫描线、屏幕闪烁、故障艺术、霓虹发光
Agent 瞬间从"盲人摸象"变成"有设计规范可依"。
Step 5:统筹输出
现在主 Agent 手里有:
- ✅ 项目整体理解(自己探索)
- ✅ 竞品对比信息(MCP 搜索)
- ✅ 技术架构细节(Task 分析报告)
- ✅ 设计规范(Skill 加载)
开始写 HTML:
最终产出放在 demo/mycodeagent_intro.html 。
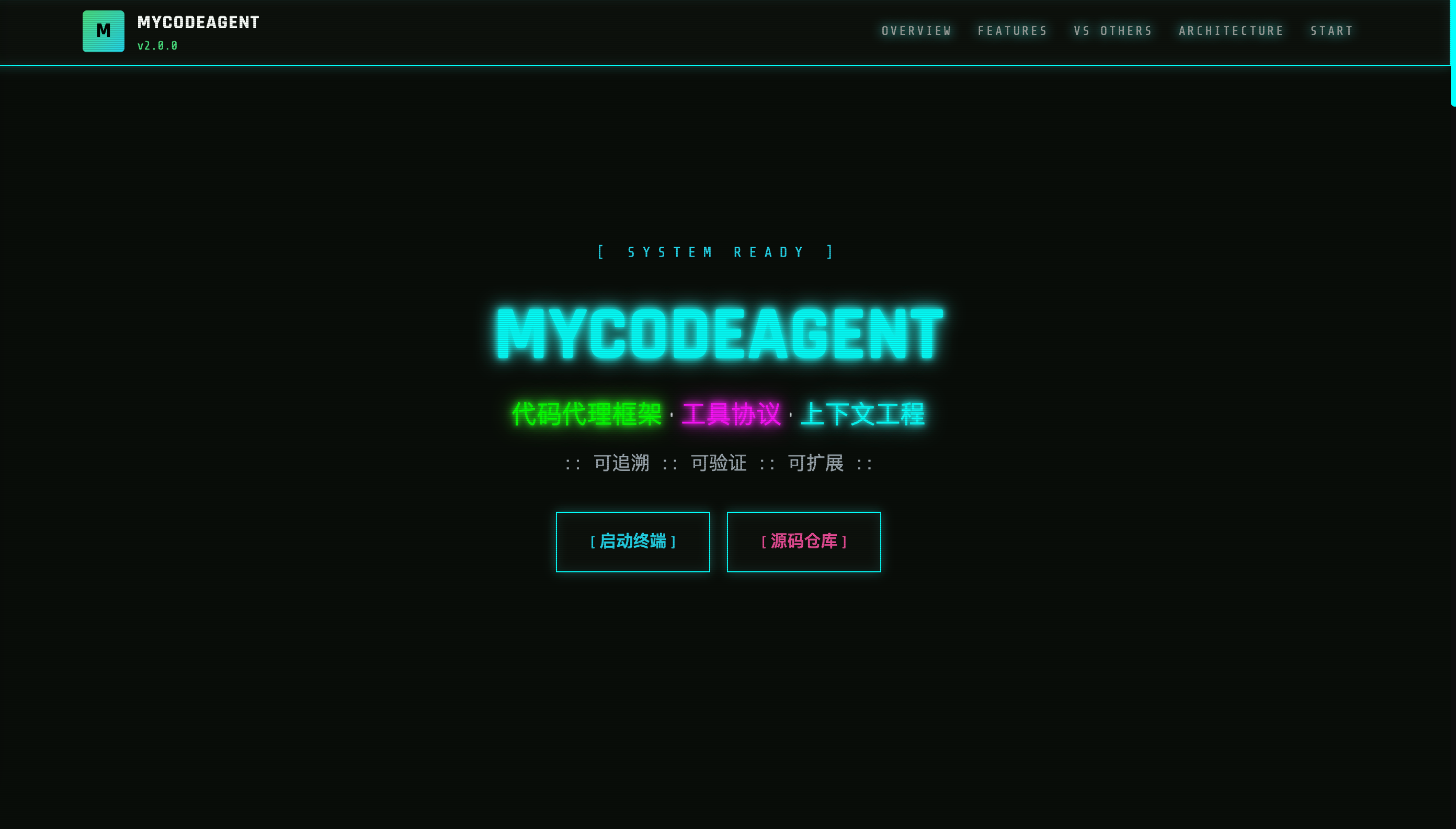
成果展示
页面顶部的 Hero 区如同巨型霓虹灯 牌:
- "MYCODEAGENT" 标题采用 Rajdhani 字体,被青色霓虹光晕(text-shadow 三层叠加)包裹,hover 时触发 故障艺术(Glitch) 动画——文字像老式电视信号不稳定般微微抖动
- 副标题用等宽字体 Share Tech Mono 打出":: 可追溯 :: 可验证 :: 可扩展 ::",模仿系统启动日志的样式
- 底部两个 CTA 按钮采用 玻璃态(Glassmorphism) 设计:半透明黑底 + 青色边框发光,hover 时边框光晕扩散
四大核心能力以 悬浮卡片 形式呈现:
- 每张卡片顶部有一条渐变色条(绿→青→粉),默认收缩,hover 时横向展开
- 卡片边框采用 赛博边框 设计:四角有独立的装饰角标,hover 时角标延伸成完整边框
- 图标使用霓虹色 emoji,在深色背景上形成高对比度视觉锚点
同类产品对比( 好像有点小bug,agent搜索的是agent开发框架 ):
扩展能力的真正价值
回顾这个任务,如果没有这些扩展能力:
- 没有 MCP : Agent 只能基于内部知识"拍脑袋"对比,信息过时且容易幻觉
- 没有 Task : 主 Agent 亲自分析架构细节,上下文被技术琐碎塞爆,主线思路断裂
- 没有 Todo : Agent 可能在写到一半时突然去优化某个细节,最后忘了主线目标
- 没有 Skills : Agent 凭"感觉"设计网页,风格可能不统一、不专业
有了它们,Agent 才能:
- MCP 提供外部信息
- Task 实现代码分析外包(子代理只读,安全隔离)
- Todo 保持专注与进度追踪
- Skills 提供专业领域知识
合理的分工是:主 Agent 控制 MCP 和最终决策,Task 处理内部代码分析,Skill 提供专业指导,Todo 串联全程。
这才是"像团队一样协作"——不是让 Agent 变复杂,而是让复杂变得可控。
写在最后:一个初学者的碎碎念
回顾整个系列:V0 → 工具重构 → Function Calling → 上下文工程 → 可观测性 → 扩展能力 → Skills。
这八篇文章,记录了我从一个 Agent 开发小白,跟着 Datawhale 的 Hello-Agent 教程一步步摸索过来的全过程。
首先要特别感谢 Datawhale 的开源教程。 如果没有 Hello-Agent 这个扎实的入门项目,我可能到现在还在各种"智能体框架"的概念里打转,而不会真正动手去写一个能跑起来的 Agent。正是教程最后那个"毕业设计"的推动,让我有了这个项目,也有了这八篇学习笔记。
说实话,写完这八篇,我越发觉得自己的渺小。
Agent 开发这个领域发展太快了,我文中提到的很多方案——比如上下文压缩策略、Skills 的设计、MCP 的集成方式——可能都还有更好的做法。我只是一个初学者,在实践中踩坑、总结、记录,分享的更多是一个"小白视角"的踩坑实录,而不是什么"最佳实践"。
如果你发现文中有错误,或者有更好的实现思路,非常欢迎在评论区指出。 我很希望能和大家交流,也很期待能向各位大佬请教。
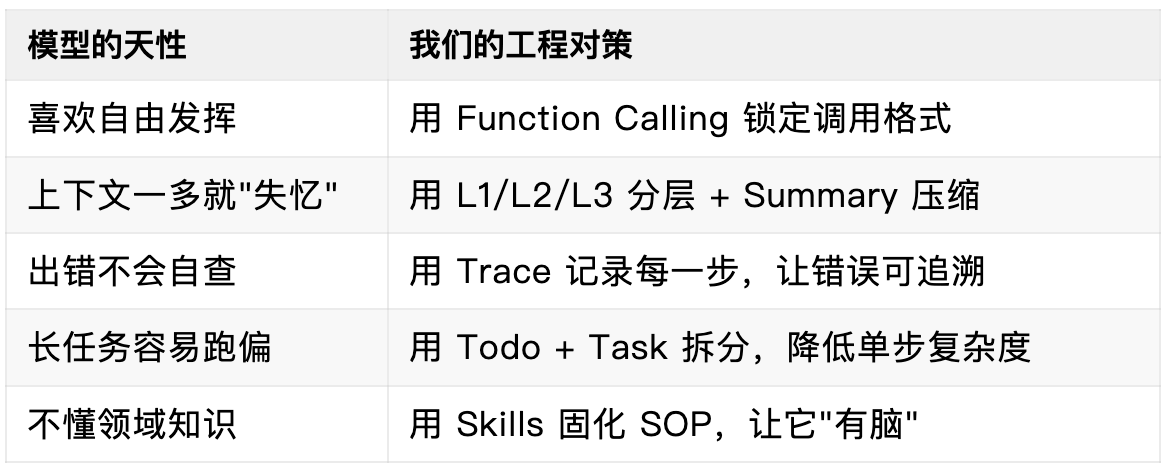
一点真心话:我们都是在给 LLM "擦屁股"
做完这个项目,我有个特别深的感触,可能听起来有点糙,但话糙理不糙:
Agent 开发的核心,不是让模型更自由,而是通过工程设计,把模型"不确定的能力"约束在"最小可控的范围"里。说白了,我们就是在给 LLM 擦屁股。
为什么这么说?
你看啊,LLM 很强,能写代码、能读文档、能推理。但它就像一个特别聪明但特别不靠谱的实习生——
- 你让它去打印文件,它可能把全公司的打印机都调用一遍;
- 你让它整理会议纪要,它可能把上周的会议也掺和进来;
- 你让它写个函数,它写得贼溜,但变量命名全是 a 、 b 、 c , 还顺带改了 你没让改的文件。
它的"强"是能力上的强,但"不靠谱"是确定性上的不靠谱。
而我们做 Agent 工程,本质上就是在解决这个矛盾。
你看这八章的内容,从工具原子化到上下文工程,从可观测性到子代理—— 每一层都是在给模型"打补丁",帮它收拾烂摊子。
但这恰恰是最有意思的地方。
以前我觉得,AI 时代工程师的价值会下降。现在我觉得恰恰相反: 模型越强大,越需要工程能力来驾驭它。 就像汽车引擎越来越强,但好的底盘、刹车、悬挂系统反而更重要。
我们不是在和模型竞争,而是在和模型协作——它负责"能做什么",我们负责"怎么让它稳定地做对"。
所以,如果你问我做完这个项目最大的收获是什么?
不是学会了什么高大上的架构,而是想明白了一个朴素的道理: 优秀的 Agent 不是"让模型更自由"的产物,而是"把不确定性约束到最小"的结果。
讲真,这个认知转变,可能比所有代码都值钱。
未来的打算
MyCodeAgent 还只是一个"能跑"的玩具,离真正生产可用还有很长的路要走。接下来我想继续完善的方向:
- 多 Agent 协作 ——Task 只是简单的子代理,能不能做更复杂的多 Agent 编排?
- 视觉能力集成 ——让 Agent 能看懂 UI、能截图分析,这是我特别想做的方向
- 更完善的测试体系 ——现在的测试还比较简陋,需要补全协议合规性和行为测试
如果你也对 Agent 开发感兴趣,或者正在学习相关技术,欢迎一起交流。我的 GitHub 仓库地址是:https://github.com/YYHDBL(欢迎 Star 和 PR!)
Agent 开发这条路还很长,希望能和志同道合的朋友一起走下去。
| 






 订阅
订阅