| 编辑推荐: |
本文主要探讨了大语言模型( LLM )的高级架构,将其分为三个关键阶段:输入、处理和输出,希望对你的学习有帮助。
本文来自于Vizuara’s Substack,由火龙果软件Alice编辑,推荐。 |
|
说明:本文中的图示采用 建模工具 EA 进行了建模。
目录
1.引言 —— 理解大语言模型架构的重要性。
2.为什么要学习 LLM 架构? ——DeepSeek 的关键创新。
3.LLM 作为下一个单词预测引擎 —— 它们如何生成文本。
4.大语言模型的关键组成部分 —— 输入、处理( transformer 模块)和输出。
5.分词与嵌入 —— 如何将原始文本转换为模型输入。
6.Transformer 模块 —— 多头注意力机制、前馈神经网络与归一化层。
7.Deepseek 的创新 —— 多头潜在注意力( MLA )与专家混合( MoE )。
8.结论 —— 总结。
简介
如果你对像“ DeepSeek ”这样的大语言模型在幕后是如何运作的感到好奇,那么您来对地方了!了解大型语言模型的架构能够帮助您更深入地理解这些模型如何处理和生成文本。
在本文中,将更深入地探讨 LLM 架构的关键组成部分,帮助您为未来讨论中理解更高级的 DeepSeek 相关概念打下坚实的基础。
为什么要学习 LLM 架构?
DeepSeek 在众多语言模型中脱颖而出,这得益于其采用了创新的技术,这些技术可以分为四个主要阶段,每个阶段都对其出色的性能起到了推动作用。
具体如下:
1.创新架构
- 多头潜在注意力( Multi-Head Latent Attention, MLA )
- 专家混合( MoE )
- Multi-token 预测
- 量化
- 旋转位置编码( RoPE )
2.训练方法
3.GPU 优化技巧
4.模型生态系统
DeepSeek 创新架构的第一个关键要素是多头潜在注意力( Multi-Head Latent Attention, MLA )。
然而,在深入探讨注意力机制之前,首先需要了解语言模型架构本身。这就是我们今天要探讨的内容。
大语言模型的架构
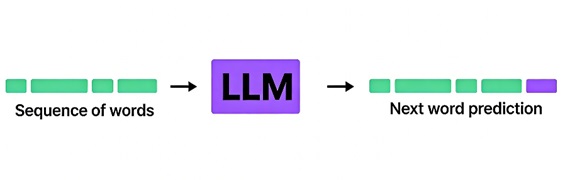
LLMs 作为下一个单词的预测引擎的核心功能。给定一串单词,它们根据学习到的模式预测最可能出现的下一个单词。
但这个引擎是如何工作的?
大语言模型拥有数以万亿计的参数,但这些参数究竟是什么,它们又是如何发挥作用的呢?
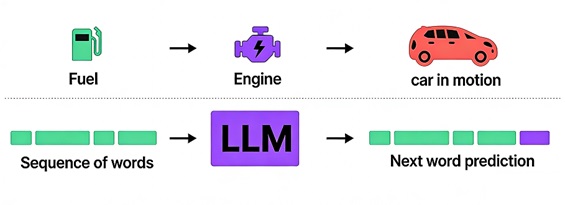
我们可以通过一个与汽车的类比来理解这一点。汽车需要燃料来驱动发动机,而发动机又使汽车能够前进。同样,在大语言模型中, tokens (单词)充当燃料,驱动模型内部机制生成有意义的文本。正如燃料在产生运动前经过引擎的复杂过程, tokens 也经过 LLM 架构的各个层次,生成下一个预测的单词。
LLM 这个 “ 黑盒 ” 内部究竟隐藏着什么?
大语言模型的架构
构建一个真正理解语言的引擎并不容易 —— 这也是大语言模型架构复杂的原因,多头注意力( Multi-Head Latent Attention )和深层次驱动下一个 Token 的预测。
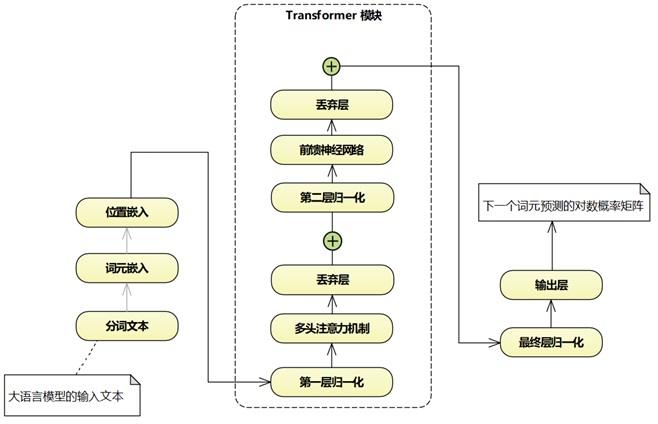
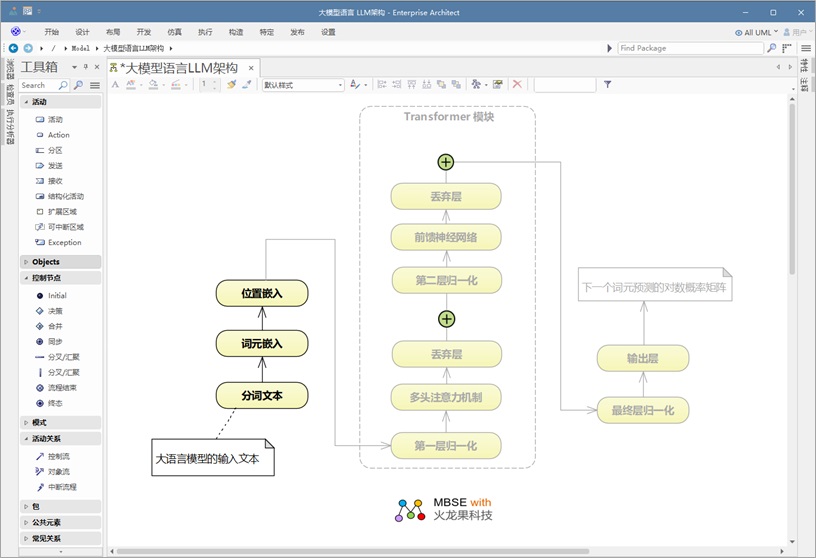
LLM 的架构可以分为三部分:
LLM 的输入阶段
输入模块
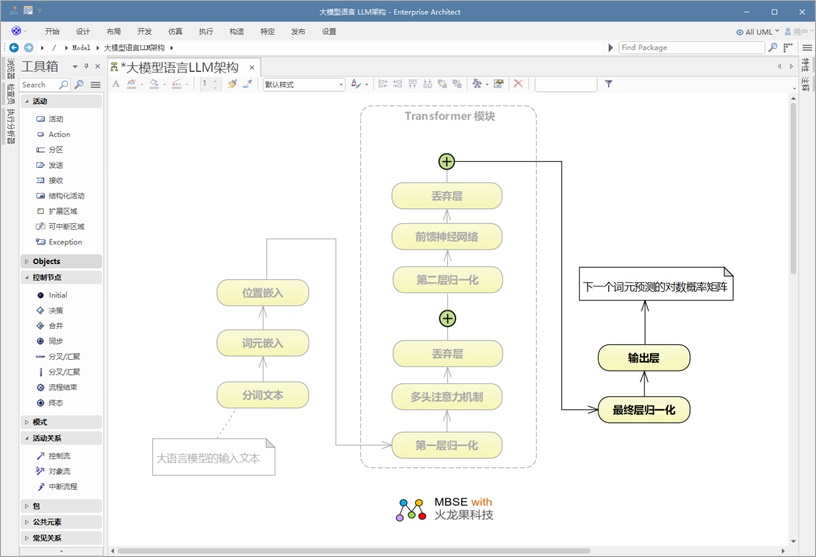
一个句子在大语言模型( LLM )中的处理过程始于输入阶段,在此阶段会发生一系列关键的转换操作,之后该句子才会进入处理单元,也就是通常所说的“ Transformer ”模块。
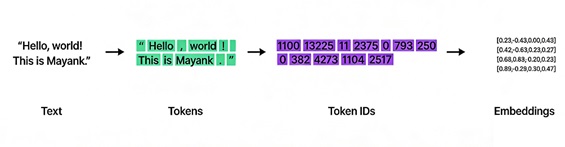
首先,原始文本会经过 分词 处理。这个过程会将句子分解成更小的单元,称为 词元 —— 根据所使用的分词方法,这些词元可以是单词、子词或字符。这一步确保了模型能够高效地处理语言。
接下来,每个 tokens (标记)都会通过 Token Embeddings (标记嵌入)转换为数值表示形式。这些 Embeddings (嵌入)为每个 token 分配一个唯一的向量,能够捕捉词语之间的语义含义和关系。然而,由于 token embeddings 本身并不能保留序列顺序,所以我们引入了位置 Embeddings (嵌入)。这些 Embeddings (嵌入)对每个 tokens (标记)在句子中的位置进行编码,使模型能够理解输入的顺序和结构。
通过引入标记化、 Token Embeddings (标记嵌入)和 positional embeddings (位置嵌入),输入数据现已完全准备好进入 Transformer 模块。在此处,深度学习机制(如 Multi-Head Latent Attention 和前馈神经网络)会对文本进行处理,以生成有意义的预测结果。
LLM 的处理器阶段:Transformer 模块
处理器:Transformer 模块
一旦输入经过 tokenization (标记化)和 embedding (嵌入处理),就会进入大语言模型( LLM )的核心处理单元—— Transformer 模块。在这个模块中,多层协同工作,以提取文本中的模式、上下文关系和依赖关系。
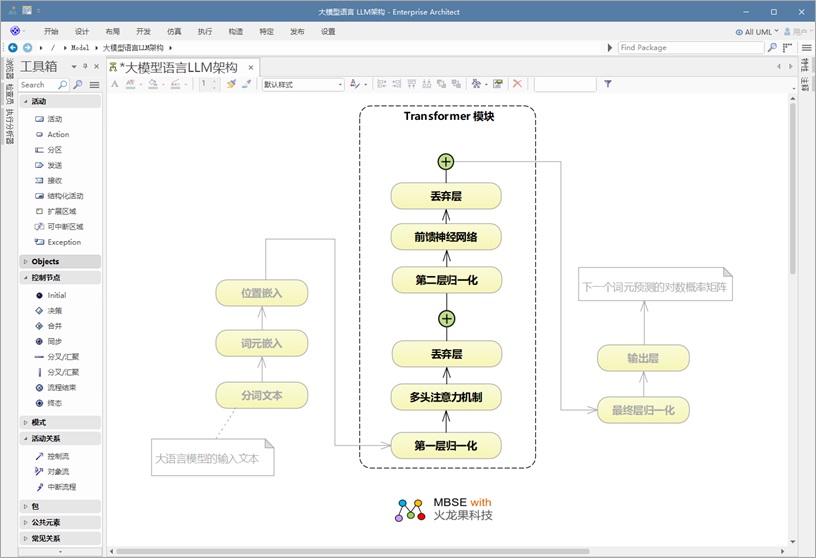
“ Transformer 模块”由六个关键组件构成,这些组件会依次对输入信息进行处理:
1.Normalization Layers (归一化层) —— 通过标准化激活确保训练稳定高效。
2.Multi-Head Attention Layer (多头注意力层) —— 通过让模型同时聚焦输入的不同部分,捕捉句子中单词之间的关系,包括那些相距较远的词语之间的关系。
3.Dropout Layer (丢弃层)——通过在训练过程中随机使部分神经元停止工作,有助于防止模型过拟合。
4.Normalization Layers 2 (归一化层) - 另一层归一化操作,以保持稳定性。
5.前馈神经网络( FFNN )——一个完全连接的层,用于对由注意力机制提取的信息进行转换和优化。
6.Dropout Layer2 (丢弃层)——增加了另一层正则化措施,以确保模型的稳定性。
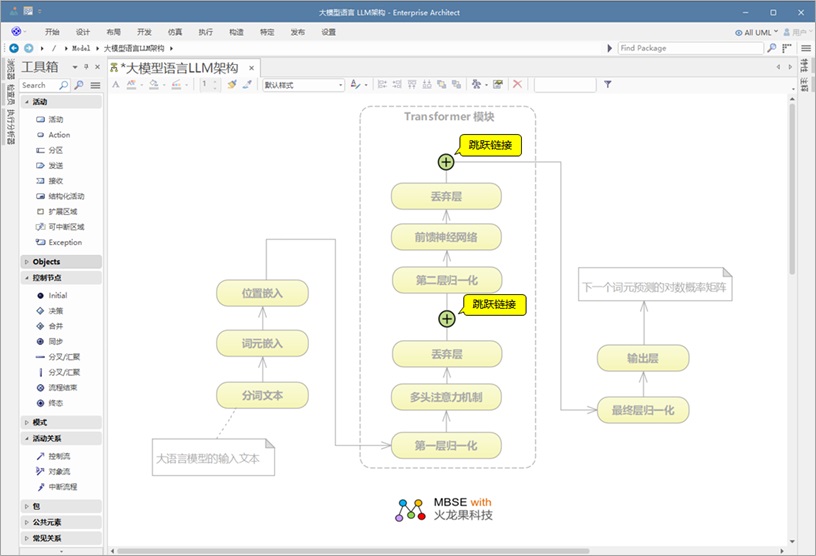
此外,架构图中的加号( + )代表跳跃连接(或捷径连接)。这些连接使模型能够跳过某些层,并保留早期阶段的关键信息,从而实现更平滑的梯度流动,并在训练过程中提高性能。 这些组件共同构成了“ Transformer 模块”的核心结构,使其能够高效处理语言数据并学习文本中的复杂模式。
LLM 架构中的输出块
输出模块
输入通过 Transformer 模块 后,这里发生了多头潜在注意力( Multi-Head Latent Attention, MLA )和前馈神经网络等复杂计算,我们进入 输出块 —— 大语言模型( LLM )处理的最终阶段。
输出模块 由两个关键部分组成:
- 最终层归一化——这一操作确保了来自 Transformer 模块的处理信息在进行预测前已得到适当的缩放和稳定处理。它能够避免数值出现极端波动,并有助于保持一致性。
- 输出层 - 此层生成一个“逻辑值”矩阵,该矩阵代表了下一个词预测的概率分布。从本质上讲,它会为所有可能的下一个词计算得分,得分最高的那个词将被选为序列中最有可能的下一个单词。
在这一阶段,该模型已成功处理了输入文本,理解了其上下文语境,并预测了下一个词,从而有助于生成有意义且连贯的文本。
DeepSeek 做了什么?
高性能跑车
想象一下,你是一个汽车爱好者,遇到一辆高性能跑车,它一直在打破纪录。你自然会好奇 —— 是什么让这辆车如此快速高效?
汽车发动机
你打开引擎盖,开始检查发动机。你会注意到,虽然它拥有许多与其他车辆相同的零件,但有两个关键部件经过了大幅提升速度和效率的升级。也许是先进的涡轮增压器,或更高效的燃油喷射系统 —— 这些都让它在竞争中占据优势。
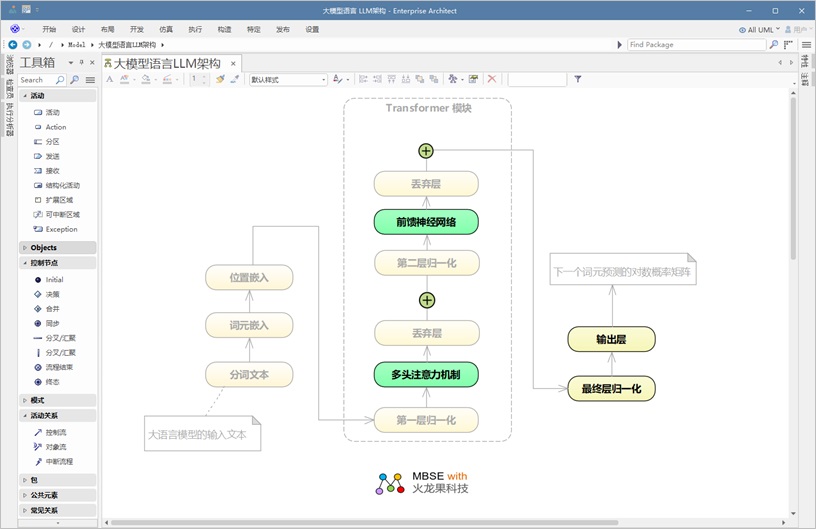
这正是 DeepSeek 在大语言模型领域正在发生的事情。它与之前的模型保持基础结构相同,但引入 了特定的架构改进 以提升其性能, DeepSeek 在传统的 Transformer 模型的 两个关键领域 引入了创新:
传统 Transformer 模块中的深度探索创新
- 多头注意力模块( Multi-Head Attention Block )
- 前馈神经网络( FFNN )
一个关键的重点是多头注意力( Multi-Head Attention ),因为多头潜在注意力( MLA )在该
架构部分扮演重要角色。
多头潜在注意力( MLA )的创新 被引入于多头注意力( Multi-Head Attention )模块,而专家混合( MoE )则在 传统 LLM 架构的前馈神经网络( FFNN )层实现。
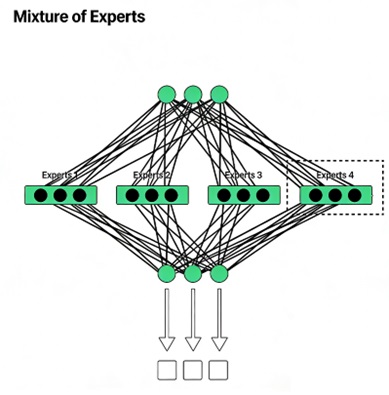
前馈网络中的专家混合( MoE )
DeepSeek 的一项重大创新在于其前馈网络中的“专家混合”( MoE )架构。与一次性激活所有参数不同, MoE 每个词元仅选择一组专门的“专家”网络,从而提高了计算效率。
• MoE 根据输入的标记动态激活不同的“专家” FFN 层,从而确保仅执行相关计算。
• 这种方法显著降低了计算成本,同时又保持了模型的表达能力。
通过利用“专家混合模型”,大语言模型( LLM )能够扩展至数万亿个参数,同时无需大量计算资源,从而使其更高效,同时仍能保持高水平的语言理解能力。
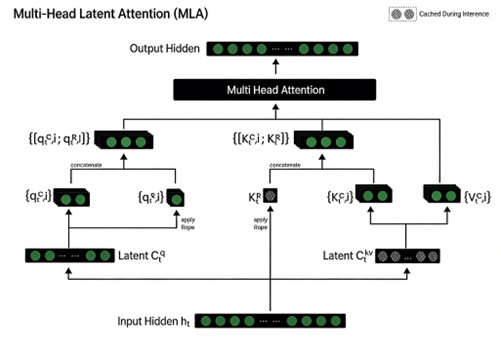
多头潜在注意力( MLA )
Multi-Head Latent Attention
多头潜在注意力( MLA )是 transformer 模型中的一种机制,使模型能够通过使用多个注意力头同时聚焦输入的不同部分。每个头独立处理输入,捕捉上下文的不同方面,然后将输出组合以增强模型的理解。然而, MHA 在推理过程中计算成本较高,因为需要存储和处理大量键值对。多头潜在注意力( MLA )通过将注意力输入压缩到更小的潜在空间,显著减少内存使用,同时保持强劲的性能。这通过向下投影到低维表示,然后在计算注意力分数时再进行上投影实现,在效率与准确性之间取得平衡。
结论
在文本中,我们探讨了大语言模型( LLM )的高级架构,将其分为三个关键阶段:输入、处理和输出。我们讨论了如何将 tokens 转换为数值表示形式,通过使用多头注意力和前馈网络的 transformer 模块进行处理,最后将其转化为有意义的文本预测。此外,我们强调了 DeepSeek 的创新之处,特别是多头潜在注意力( MLA )和专家混合( MoE ),这些技术提高了效率和可扩展性。不过,这只是一个概述,并非深入的技术剖析。 本文模型图示部分采用建模工具 EA 进行了重新建模,欢迎试用 EA ( UML 和 SysML 建模工具) | 






 订阅
订阅