| 编辑推荐: |
| 本文来自于知乎,DeemFM是17年深度学习在点击率预估、推荐这块的新的方法,有点类似于deep and wide的思想,将传统的fm来nn化,利用神经网络强大的建模能力来挖掘数据中的有效信息。 |
|
前言
前面在团队内部分享点击率相关的一些文章时,输出了一篇常见计算广告点击率预估算法总结,看了一些广告点击率的文章,从最经典的Logistic Regression到Factorization Machined,FFM,FNN,PNN到今年的DeepFM,还有文章里面没有讲的gbdt+lr这类,一直想找时间实践下,正好这次在学习paddle的时候在它的models目录下看到了DeepFM的实现,因为之前对DeepFM有过比较详细的描述,这里稍微复习一下:
DeepFM更有意思的地方是WDL和FM结合了,其实就是把PNN和WDL结合了,PNN即将FM用神经网络的方式构造了一遍,作为wide的补充,原始的Wide and Deep,Wide的部分只是LR,构造线性关系,Deep部分建模更高阶的关系,所以在Wide and Deep中还需要做一些特征的东西,如Cross Column的工作,而我们知道FM是可以建模二阶关系达到Cross column的效果,DeepFM就是把FM和NN结合,无需再对特征做诸如Cross Column的工作了,这个是我感觉最吸引人的地方,其实FM的部分感觉就是PNN的一次描述,这里只描述下结构图,PNN的部分前面都描述, FM部分:
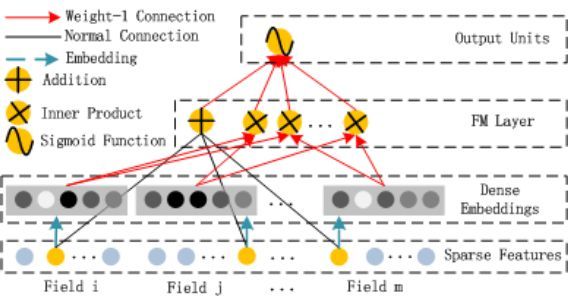
Deep部分:
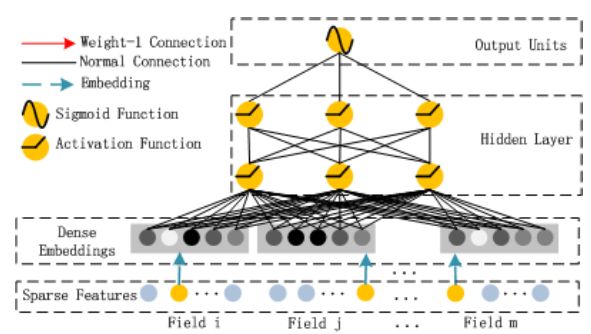
DeepFM相对于FNN、PNN,能够利用其Deep部分建模更高阶信息(二阶以上),而相对于Wide and Deep能够减少特征工程的部分工作,wide部分类似FM建模一、二阶特征间关系, 算是NN和FM的一个更完美的结合方向,另外不同的是如下图,DeepFM的wide和deep部分共享embedding向量空间,wide和deep均可以更新embedding部分,虽说wide部分纯是PNN的工作,但感觉还是蛮有意思的。
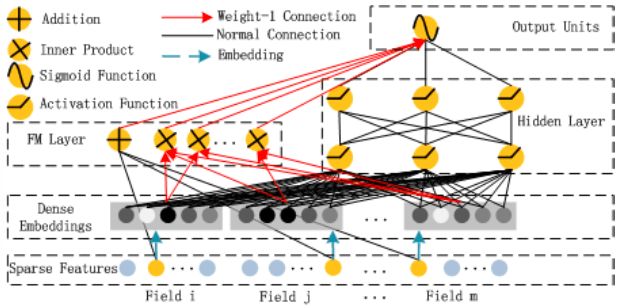
本文相关代码部分都是来自于paddlepaddle/model, 我这里走一遍流程,学习下,另外想要了解算法原理的可以仔细再看看上面的文章,今天我们来paddlepaddle上做下实验,来从代码程度学习下DeepFM怎么实现的:
数据集说明
criteo Display Advertising Challenge,数据主要来criteolab一周的业务数据,用来预测用户在访问页面时,是否会点击某广告。
wget --no-check-certificate https://s3-eu-west-1.amazonaws.com/criteo-labs/dac.tar.gz
tar zxf dac.tar.gz
rm -f dac.tar.gz
mkdir raw
mv ./*.txt raw/ |
数据有点大, 大概4.26G,慢慢等吧,数据下载完成之后,解压出train.csv,test.csv,其中训练集45840617条样本数,测试集45840617条样本,数据量还是蛮大的。 数据主要有三部分组成:
- label: 广告是否被点击;
- 连续性特征: 1-13,为各维度下的统计信息,连续性特征;
- 离散型特征:一些被脱敏处理的类目特征
Overview
整个项目主要由几个部分组成:
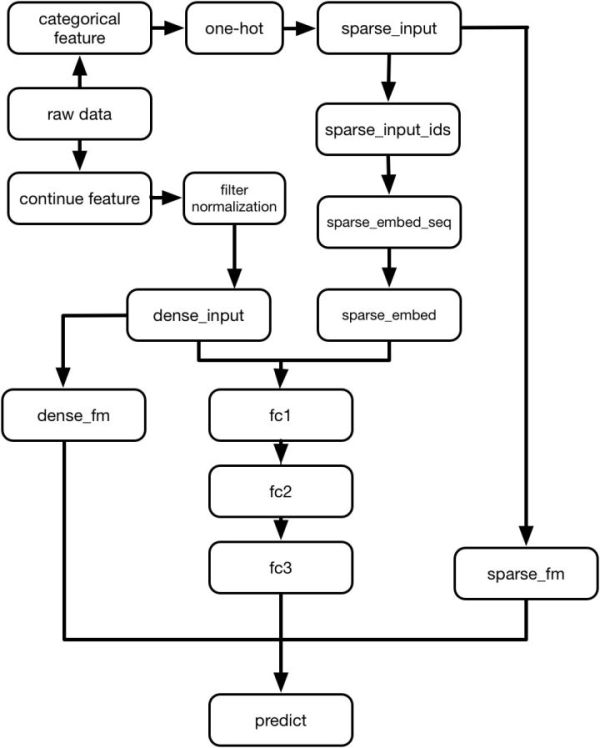
数据处理
这里数据处理主要包括两个部分:
- 连续值特征值处理:
- 滤除统计次数95%以上的数据,这样可以滤除大部分异值数据,这里的处理方式和以前我在1号店做相关工作时一致,代码里面已经做了这部分工作,直接给出了这部分的特征阈值;
- 归一化处理,这里andnew ng的课程有张图很明显,表明不同的特征的值域范围,会使得模型寻优走『之』字形,这样会增加收敛的计算和时间;
- 离散特征值处理:
- one-hot: 对应特征值映射到指定维度的只有一个值为1的稀疏变量;
- embedding: 对应特征值映射到指定的特征维度上;
具体我们来研究下代码:
class ContinuousFeatureGenerator:
"""
Normalize the integer features to [0, 1] by min-max normalization
"""
def __init__(self, num_feature):
self.num_feature = num_feature
self.min = [sys.maxint] * num_feature
self.max = [-sys.maxint] * num_feature
def build(self, datafile, continous_features):
with open(datafile, 'r') as f:
for line in f:
features = line.rstrip('\n').split('\t')
for i in range(0, self.num_feature):
val = features[continous_features[i]]
if val != '':
val = int(val)
if val > continous_clip[i]:
val = continous_clip[i]
self.min[i] = min(self.min[i], val)
self.max[i] = max(self.max[i], val)
def gen(self, idx, val):
if val == '':
return 0.0
val = float(val)
return (val - self.min[idx]) / (self.max[idx] - self.min[idx])
|
连续特征是在1-13的位置,读取文件,如果值大于对应维度的特征值的95%阈值,则该特征值置为该阈值,并计算特征维度的最大、最小值,在gen时归一化处理。
class CategoryDictGenerator:
"""
Generate dictionary for each of the categorical features
"""
def __init__(self, num_feature):
self.dicts = []
self.num_feature = num_feature
for i in range(0, num_feature):
self.dicts.append(collections.defaultdict(int))
def build(self, datafile, categorial_features, cutoff=0):
with open(datafile, 'r') as f:
for line in f:
features = line.rstrip('\n').split('\t')
for i in range(0, self.num_feature):
if features[categorial_features[i]] != '':
self.dicts[i][features[categorial_features[i]]] += 1
for i in range(0, self.num_feature):
self.dicts[i] = filter(lambda x: x[1] >= cutoff,
self.dicts[i].items())
self.dicts[i] = sorted(self.dicts[i], key=lambda x: (-x[1], x[0]))
vocabs, _ = list(zip(*self.dicts[i]))
self.dicts[i] = dict(zip(vocabs, range(1, len(vocabs) + 1)))
self.dicts[i]['<unk>'] = 0
def gen(self, idx, key):
if key not in self.dicts[idx]:
res = self.dicts[idx]['<unk>']
else:
res = self.dicts[idx][key]
return res
def dicts_sizes(self):
return map(len, self.dicts)
|
类目特征的处理相对比较麻烦,需要遍历,然后得到对应维度上所有出现值的所有情况,对打上对应id,为后续类目特征赋予id。这部分耗时好大,慢慢等吧,另外强烈希望paddlepaddle的小伙伴能在输出处理期间打印下提示信息,算了,我之后有时间看看能不能提提pr。
经过上面的特征处理之后,训练集的值变为:
reader
paddle里面reader的文件,自由度很高,自己可以写生成器,然后使用batch的api,完成向网络传入batchsize大小的数据:
class Dataset:
def _reader_creator(self, path, is_infer):
def reader():
with open(path, 'r') as f:
for line in f:
features = line.rstrip('\n').split('\t')
dense_feature = map(float, features[0].split(','))
sparse_feature = map(int, features[1].split(','))
if not is_infer:
label = [float(features[2])]
yield [dense_feature, sparse_feature
] + sparse_feature + [label]
else:
yield [dense_feature, sparse_feature] + sparse_feature
return reader
def train(self, path):
return self._reader_creator(path, False)
def test(self, path):
return self._reader_creator(path, False)
def infer(self, path):
return self._reader_creator(path, True) |
主要逻辑在兑入文件,然后yield对应的网络数据的输入格式
模型构造
模型构造,DeepFM在paddlepaddle里面比较简单,因为有专门的fm层,这个据我所知在TensorFlow或MXNet里面没有专门的fm层,但是值得注意的是,在paddlepaddle里面的fm层,只建模二阶关系,需要再加入fc才是完整的fm,实现代码如下:
def fm_layer(input, factor_size, fm_param_attr):
first_order = paddle.layer.fc(
input=input, size=1, act=paddle.activation.Linear())
second_order = paddle.layer.factorization_machine(
input=input,
factor_size=factor_size,
act=paddle.activation.Linear(),
param_attr=fm_param_attr)
out = paddle.layer.addto(
input=[first_order, second_order],
act=paddle.activation.Linear(),
bias_attr=False)
return out |
然后就是构造DeepFM,这里根据下面的代码画出前面的图,除去数据处理的部分,就是DeepFM的网络结构:
def DeepFM(factor_size, infer=False):
dense_input = paddle.layer.data(
name="dense_input",
type=paddle.data_type.dense_vector(dense_feature_dim))
sparse_input = paddle.layer.data(
name="sparse_input",
type=paddle.data_type.sparse_binary_vector(sparse_feature_dim))
sparse_input_ids = [
paddle.layer.data(
name="C" + str(i),
type=s(sparse_feature_dim))
for i in range(1, 27)
]
dense_fm = fm_layer(
dense_input,
factor_size,
fm_param_attr=paddle.attr.Param(name="DenseFeatFactors"))
sparse_fm = fm_layer(
sparse_input,
factor_size,
fm_param_attr=paddle.attr.Param(name="SparseFeatFactors"))
def embedding_layer(input):
return paddle.layer.embedding(
input=input,
size=factor_size,
param_attr=paddle.attr.Param(name="SparseFeatFactors"))
sparse_embed_seq = map(embedding_layer, sparse_input_ids)
sparse_embed = paddle.layer.concat(sparse_embed_seq)
fc1 = paddle.layer.fc(
input=[sparse_embed, dense_input],
size=400,
act=paddle.activation.Relu())
fc2 = paddle.layer.fc(input=fc1, size=400, act=paddle.activation.Relu())
fc3 = paddle.layer.fc(input=fc2, size=400, act=paddle.activation.Relu())
predict = paddle.layer.fc(
input=[dense_fm, sparse_fm, fc3],
size=1,
act=paddle.activation.Sigmoid())
if not infer:
label = paddle.layer.data(
name="label", type=paddle.data_type.dense_vector(1))
cost = paddle.layer.multi_binary_label_cross_entropy_cost(
input=predict, label=label)
paddle.evaluator.classification_error(
name="classification_error", input=predict, label=label)
paddle.evaluator.auc(name="auc", input=predict, label=label)
return cost
else:
return predict
|
其中,主要包括三个部分,一个是多个fc组成的deep部分,第二个是sparse fm部分,然后是dense fm部分,如图:
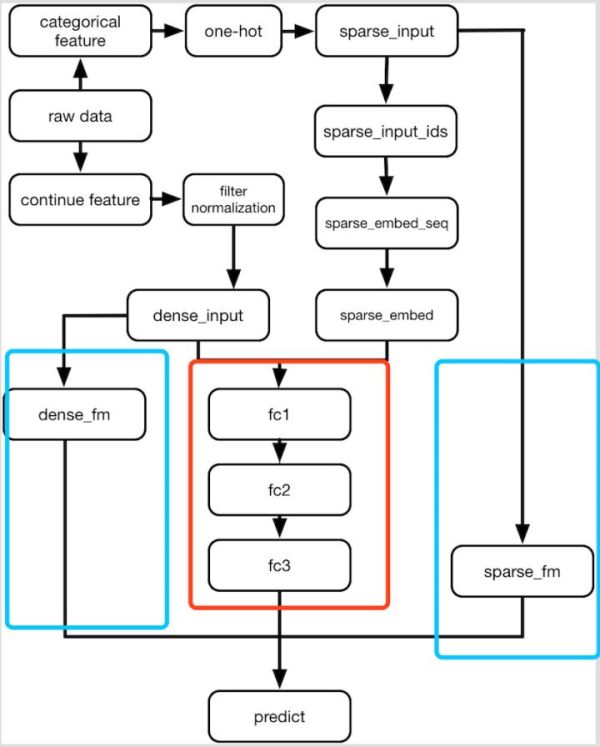
这里蛮简单的,具体的api去查下文档就可以了,这里稍微说明一下的是,sparse feature这块有两部分一块是embedding的处理,这里是先生成对应的id,然后用id来做embedding,用作后面fc的输出,然后sparse_input是onehot表示用来作为fm的输出,fm来计算一阶和二阶隐变量关系。
模型训练
数据量太大,单机上跑是没有问题,可以正常运行成功,在我内部机器上,可以运行成功,但是有两个问题:
- fm由于处理的特征为稀疏表示,而paddlepaddle在这块的FM层的支持只有在cpu上,速度很慢,分析原因其实不是fm的速度的问题,因为deepfm有设计多个fc,应该是这里的速度影响, 在paddlepaddle github上有提一个issue,得知暂时paddlepaddle不能把部分放到gpu上面跑,给了一个解决方案把所有的sparse改成dense,发现在这里gpu显存hold不住;
- 我的机器太渣,因为有开发任务不能长期占用;
所以综上,我打算研究下在百度云上怎么通过k8s来布置paddlepaddle的分布式集群。
文档https://cloud.baidu.com/doc/CCE/GettingStarted.html#.E9.85.8D.E7.BD.AEpaddlecloud
研究来研究去,第一步加卡主了,不知道怎么回事,那个页面就是出不来...出师未捷身先死,提了个issue: https://github.com/PaddlePaddle/cloud/issues/542,等后面解决了再来更新分布式训练的部分。
单机的训练没有什么大的问题,由上面所说,因为fm的sparse不支持gpu,所以很慢,拉的百度云上16核的机器,大概36s/100 batch,总共样本4000多w,一个epoch预计4个小时,MMP,等吧,分布式的必要性就在这里。
另外有在paddlepaddle里面提一个issue:
https://github.com/PaddlePaddle/Paddle/issues/7010,说把sparse转成dense的话可以直接在gpu上跑起来,这个看起来不值得去尝试,sparse整个维度还是挺高的,期待对sparse op 有更好的解决方案,更期待在能够把单层单层的放在gpu,多设备一起跑,这方面,TensorFlow和MXNet要好太多。
这里我遇到一个问题,我使用paddle的docker镜像的时候,可以很稳定的占用16个cpu的大部分计算力,但是我在云主机上自己装的时候,cpu占用率很低,可能是和我环境配置有点问题,这个问题不大,之后为了不污染环境主要用docker来做相关的开发工作,所以这里问题不大。
cpu占有率有比较明显的跳动,这里从主观上比TensorFlow稳定性要差一些,不排除是sparse op的影响,印象中,TensorFlow cpu的占用率很稳定。
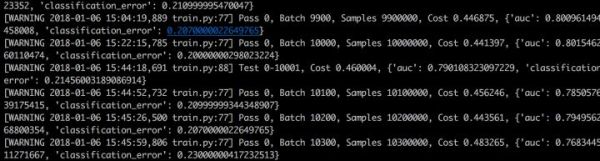
到发这篇文章位置,跑到17300个batch,基本能达到auc为0.8左右,loss为0.208左右。
预测
预测代码和前一篇将paddle里面的demo一样,只需要,重新定义一下网络,然后绑定好模型训练得到的参数,然后传入数据即可完成inference,paddle,有专门的Inference接口,只要传入output_layer,和训练学习到的parameters,就可以很容易的新建一个模型的前向inference网络。
def infer():
args = parse_args()
paddle.init(use_gpu=False, trainer_count=1)
model = DeepFM(args.factor_size, infer=True)
parameters = paddle.parameters.Parameters.from_tar(
gzip.open(args.model_gz_path, 'r'))
inferer = paddle.inference.Inference(
output_layer=model, parameters=parameters)
dataset = reader.Dataset()
infer_reader = paddle.batch(dataset.infer(args.data_path), batch_size=1000)
with open(args.prediction_output_path, 'w') as out:
for id, batch in enumerate(infer_reader()):
res = inferer.infer(input=batch)
predictions = [x for x in itertools.chain.from_iterable(res)]
out.write('\n'.join(map(str, predictions)) + '\n') |
总结
照例总结一下,DeemFM是17年深度学习在点击率预估、推荐这块的新的方法,有点类似于deep and wide的思想,将传统的fm来nn化,利用神经网络强大的建模能力来挖掘数据中的有效信息,paddlepaddle在这块有现成的deepfm模型,单机部署起来比较容易,分布式,这里我按照百度云上的教程还未成功,后续会持续关注。另外,因为最近在做大规模机器学习框架相关的工作,越发觉得别说成熟的,仅仅能够work的框架就很不错了,而比较好用的如现在的TensorFlow\MXNet,开发起来真的难上加难,以前光是做调包侠时没有体验,现在深入到这块的工作时,才知道其中的难度,也从另一个角度开始审视现在的各种大规模机器学习框架,比如TensorFlow、MXNet,在深度学习的支持上,确实很棒,但是也有瓶颈,对于大规模海量的feature,尤其是sparse op的支持上,至少现在还未看到特别好的支持,就比如这里的FM,可能大家都会吐槽为啥这么慢,没做框架之前,我也会吐槽,但是开始接触了一些的时候,才知道FM,主要focus在sparse相关的数据对象,而这部分数据很难在gpu上完成比较高性能的计算,所以前面经过paddle的开发者解释sparse相关的计算不支持gpu的时候,才感同身受,一个好的大规模机器学习框架必须要从不同目标来评价,如果需求是大规律数据,那稳定性、可扩展性是重点,如果是更多算法、模型的支持,可能现在的TensorFlow、MXNet才是标杆,多么希望现在大规模机器学习框架能够多元化的发展,有深度学习支持力度大的,也有传统算法上,把数据量、训练规模、并行化加速并做到极致的,这样的发展才或许称得上百花齐放,其实我们不需要太多不同长相的TensorFlow、MXNet锤子,有时候我们就需要把镰刀而已,希望大规模机器学习框架的发展,不应该仅仅像TensorFlow、MXNet一样,希望有一个专注把做大规模、大数据量、极致并行化加速作为roadmap的新标杆,加油。
|







